
LRU-GENACO: A Hybrid Cached Data Optimization Based on the Least Used Method Improved Using Ant Colony and Genetic Algorithms



Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. GENACO Framework
3.2. Discussion of Cache Pollution
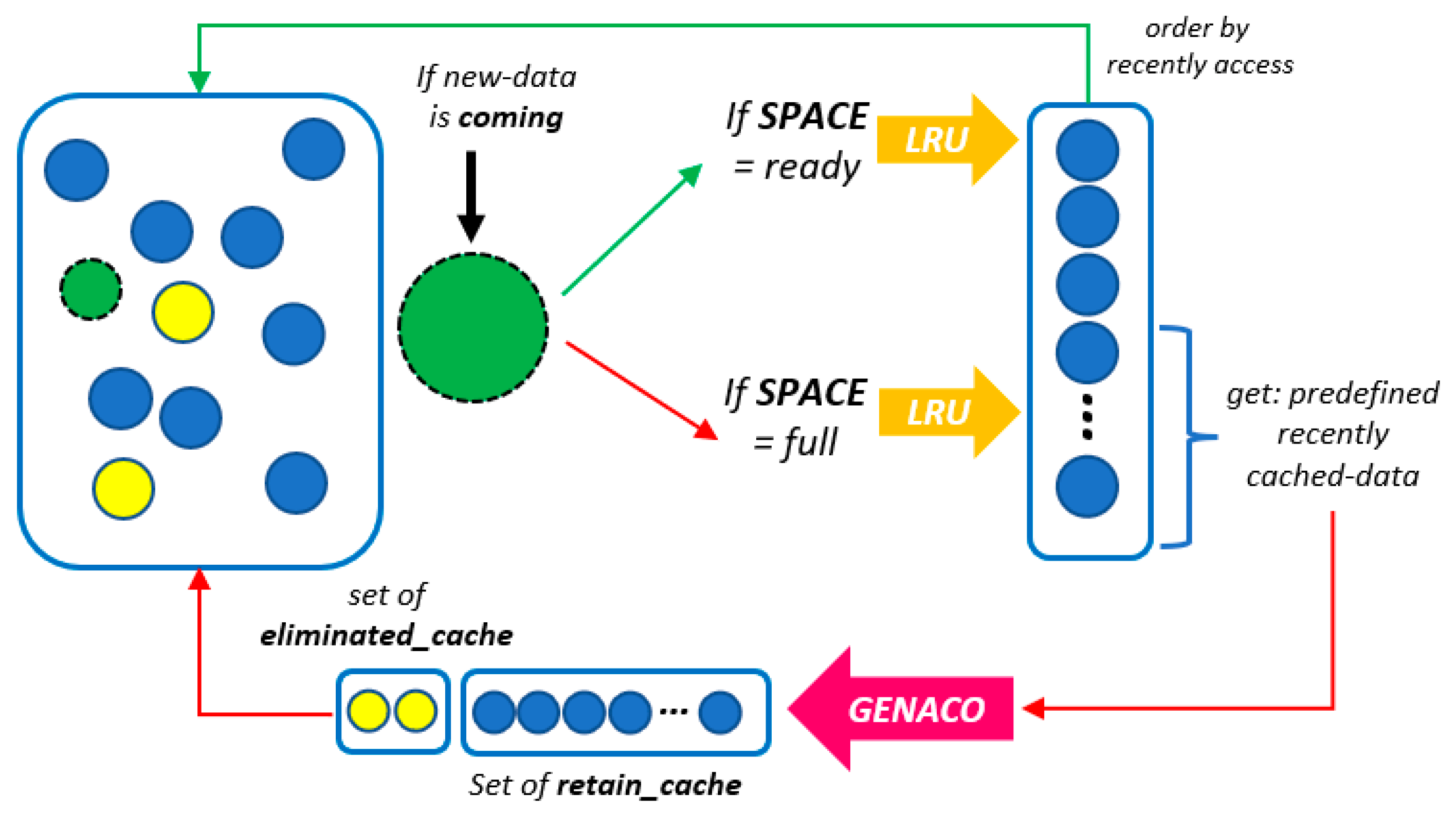
3.3. The Proposed LRU-GENACO Method
| Algorithm 1 Pseudo-code the proposed LRU-GENACO method |
| Input: GENACO, LRU, n new cached_data Output: set of eliminated_cache, set of retain_cache |
| if n is coming then check cache_archive(n); if isReady(n) then # cache hits update(stat(n)); update(info(ct,tm,sz)); else # cache miss and space ready if size(n) < remaining_cache_capacity then insert(n); update(stat(ct)); update(info(ct,tm,sz)); else # cache miss and space full, do optimization if sum_cache < 20 then set_n = all cached data run(LRU,n); remove(set_em); else set_n = get(20 recently used cached data) run(GENACO,set_n); screen_out(set_ren); remove(set_em); insert(n); update(stat(ct)); update(info(ct,tm,sz)); endif endif endif endif |
4. Simulation and Datasets
4.1. Performance Metrics
4.2. Datasets
5. Result and Discussion
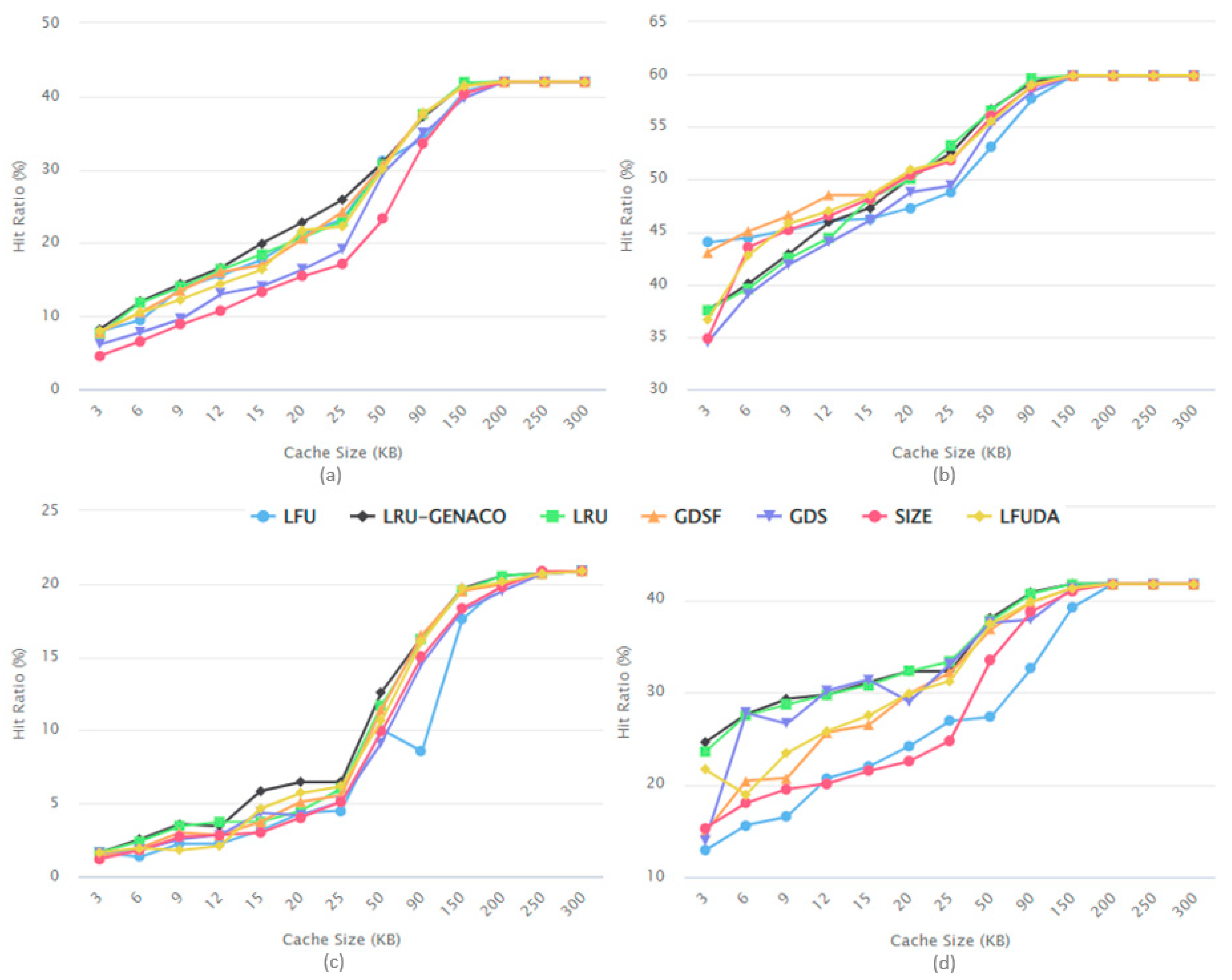
5.1. Impact of Cache Size on HR Performance
5.2. Reduced Latency Ratio by LRU-GENACO
5.3. Improvement Ratio by LRU-GENACO
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ha, K.; Chen, Z.; Hu, W.; Richter, W.; Pillai, P.; Satyanarayanan, M. Towards wearable cognitive assistance. In Proceedings of the 12th Annual International Conference on Mobile Systems, Applications, and Services, Bretton Woods, NH, USA, 16–19 June 2014; pp. 68–81. [Google Scholar] [CrossRef]
- He, W.; Zhang, Z.; Li, W. Information technology solutions, challenges, and suggestions for tackling the COVID-19 pandemic. Int. J. Inf. Manag. 2020, 57, 102287. [Google Scholar] [CrossRef] [PubMed]
- Secundo, G.; Shams, S.R.; Nucci, F. Digital technologies and collective intelligence for healthcare ecosystem: Optimizing Internet of Things adoption for pandemic management. J. Bus. Res. 2021, 131, 563–572. [Google Scholar] [CrossRef]
- De’, R.; Pandey, N.; Pal, A. Impact of digital surge during Covid-19 pandemic: A viewpoint on research and practice. Int. J. Inf. Manag. 2020, 55, 102171. [Google Scholar] [CrossRef] [PubMed]
- Nimrod, G. Changes in Internet Use When Coping WITH Stress: Older Adults during the COVID-19 Pandemic. Am. J. Geriatr. Psychiatry 2020, 28, 1020–1024. [Google Scholar] [CrossRef]
- Azlan, C.A.; Wong, J.H.D.; Tan, L.K.; Huri, M.S.N.A.; Ung, N.M.; Pallath, V.; Tan, C.P.L.; Yeong, C.H.; Ng, K.H. Teaching and learning of postgraduate medical physics using Internet-based e-learning during the COVID-19 pandemic—A case study from Malaysia. Phys. Med. 2020, 80, 10–16. [Google Scholar] [CrossRef]
- Naeem, M.; Ozuem, W. The role of social media in internet banking transition during COVID-19 pandemic: Using multiple methods and sources in qualitative research. J. Retail. Consum. Serv. 2021, 60, 102483. [Google Scholar] [CrossRef]
- Sai, Y.; Fan, D.-Z.; Fan, M.-Y. Cooperative and efficient content caching and distribution mechanism in 5G network. Comput. Commun. 2020, 161, 183–190. [Google Scholar] [CrossRef]
- Ayuba, D.; Ismail, A.; Hamzah, M.I. Evaluation of Page Response Time between Partial and Full Rendering in a Web-based Catalog System. Procedia Technol. 2013, 11, 807–814. [Google Scholar] [CrossRef]
- Carvalho, G.; Cabral, B.; Pereira, V.; Bernardino, J. Computation offloading in Edge Computing environments using Artificial Intelligence techniques. Eng. Appl. Artif. Intell. 2020, 95, 103840. [Google Scholar] [CrossRef]
- Wang, D.; An, X.; Zhou, X.; Lü, X. Data cache optimization model based on cyclic genetic ant colony algorithm in edge computing environment. Int. J. Distrib. Sens. Netw. 2019, 15, 155014771986786. [Google Scholar] [CrossRef]
- Ali, W.; Shamsuddin, S.M.; Ismail, A.S. A Survey of Web Caching and Prefetching. Int. J. Adv. Soft Comput. Appl. 2011, 3, 1–27. [Google Scholar]
- Zulfa, M.I.; Fadli, A.; Wardhana, A.W. Application caching strategy based on in-memory using Redis server to accelerate relational data access. J. Teknol. Dan Sist. Komput. 2020, 8, 157–163. [Google Scholar] [CrossRef]
- Baskaran, K.R.; Kalaiarasan, C. Pre-eminence of Combined Web Pre-fetching and Web Caching Based on Machine Learning Technique. Arab. J. Sci. Eng. 2014, 39, 7895–7906. [Google Scholar] [CrossRef]
- Zulfa, M.I.; Hartanto, R.; Permanasari, A.E.; Ali, W. GenACO a multi-objective cached data offloading optimization based on genetic algorithm and ant colony optimization. PeerJ Comput. Sci. 2021, 7, e729. [Google Scholar] [CrossRef]
- Ying, C.; Wang, X.; Luo, Y. Optimization on data offloading ratio of designed caching in heterogeneous mobile wireless networks. Inf. Sci. 2021, 545, 663–687. [Google Scholar] [CrossRef]
- Shi, H. Solution to 0/1 Knapsack Problem Based on Improved Ant Colony Algorithm. In Proceedings of the 2006 IEEE International Conference on Information Acquisition, Shandong, China, 20–23 August 2006; pp. 1062–1066. [Google Scholar] [CrossRef]
- Fidanova, S. Ant Colony Optimization for Multiple Knapsack Problem and Model Bias. Lect. Notes Comput. Sci. 2005, 3401, 280–287. [Google Scholar] [CrossRef]
- Liu, Y.; Gao, C.; Zhang, Z.; Lu, Y.; Chen, S.; Liang, M.; Tao, L. Solving NP-Hard Problems with Physarum-Based Ant Colony System. IEEE/ACM Trans. Comput. Biol. Bioinform. 2017, 14, 108–120. [Google Scholar] [CrossRef]
- Ansari, A.Q.; Ibraheem; Katiyar, S. Comparison and analysis of solving travelling salesman problem using GA, ACO and hybrid of ACO with GA and CS. In Proceedings of the 2015 IEEE Workshop on Computational Intelligence: Theories, Applications and Future Directions (WCI), Kanpur, India, 14–17 December 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Lin, F.-T. Solving the knapsack problem with imprecise weight coefficients using genetic algorithms. Eur. J. Oper. Res. 2008, 185, 133–145. [Google Scholar] [CrossRef]
- Zulfa, M.I.; Hartanto, R.; Permanasari, A.E. Performance Comparison of Swarm Intelligence Algorithms for Web Caching Strategy. In Proceedings of the 2021 IEEE International Conference on Communication, Networks and Satellite (COMNETSAT), Online, 17–18 July 2021; pp. 45–51. [Google Scholar] [CrossRef]
- Zulfa, M.I.; Hartanto, R.; Permanasari, A.E. Caching strategy for Web application—A systematic literature review. Int. J. Web Inf. Syst. 2020, 16, 545–569. [Google Scholar] [CrossRef]
- Ma, T.; Qu, J.; Shen, W.; Tian, Y.; Al-Dhelaan, A.; Al-Rodhaan, M. Weighted Greedy Dual Size Frequency Based Caching Replacement Algorithm. IEEE Access 2018, 6, 7214–7223. [Google Scholar] [CrossRef]
- Ali, W.; Shamsuddin, S.M.; Ismail, A.S. Intelligent Web proxy caching approaches based on machine learning techniques. Decis. Support. Syst. 2012, 53, 565–579. [Google Scholar] [CrossRef]
- Bengar, D.A.; Ebrahimnejad, A.; Motameni, H.; Golsorkhtabaramiri, M. A page replacement algorithm based on a fuzzy approach to improve cache memory performance. Soft Comput. 2020, 24, 955–963. [Google Scholar] [CrossRef]
- Hou, B.; Chen, F. GDS-LC: A latency-and cost-aware client caching scheme for cloud storage. ACM Trans. Storage 2017, 13, 1–33. [Google Scholar] [CrossRef]
- Ma, T.; Hao, Y.; Shen, W.; Tian, Y.; Al-Rodhaan, M. An Improved Web Cache Replacement Algorithm Based on Weighting and Cost. IEEE Access 2018, 6, 27010–27017. [Google Scholar] [CrossRef]
- Aimtongkham, P.; So-In, C.; Sanguanpong, S. A novel web caching scheme using hybrid least frequently used and support vector machine. In Proceedings of the 2016 13th International Joint Conference on Computer Science and Software Engineering, JCSSE 2016, Khon Kaen, Thailand, 13–15 July 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Patel, D. Threshold based partial partitioning fuzzy means clustering algorithm (TPPFMCA) for pattern discovery. Int. J. Inf. Technol. 2020, 12, 215–222. [Google Scholar] [CrossRef]
- Nimishan, S.; Shriparen, S. An Approach to Improve the Performance of Web Proxy Cache Replacement Using Machine Learning Techniques. In Proceedings of the 2018 IEEE 9th International Conference on Information and Automation for Sustainability, ICIAfS 2018, Colombo, Sri Lanka, 21–22 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, Z.; Hao, W. Development of a new cloudlet content caching algorithm based on web mining. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference, CCWC 2018, Las Vegas, NV, USA, 8–10 January 2018; Volume 2018, pp. 329–335. [Google Scholar] [CrossRef]
- Pernabas, J.B.; Fidele, S.F. Enhancements to greedy web proxy caching algorithms using data mining method and weight assignment policy. Int. J. Innov. Comput. Inf. Control 2018, 14, 1311–1326. [Google Scholar] [CrossRef]
- Ali, W.; Shamsuddin, S.M.; Ismail, A.S. Intelligent Naïve Bayes-based approaches for Web proxy caching. Knowl.-Based Syst. 2012, 31, 162–175. [Google Scholar] [CrossRef]
- Ali, W.; Sulaiman, S.; Ahmad, N. Performance improvement of least-recently-used policy in web proxy cache replacement using supervised machine learning. Int. J. Adv. Soft Comput. Its Appl. 2014, 6, 1–38. [Google Scholar]
- Ibrahim, H.; Yasin, W.; Udzir, N.I.; Hamid, N.A.W.A. Intelligent cooperative web caching policies for media objects based on J48 decision tree and Naïve Bayes supervised machine learning algorithms in structured peer-to-peer systems. J. Inf. Commun. Technol. 2016, 15, 85–116. [Google Scholar] [CrossRef]
- Pernabas, J.B.; Fidele, S.F.; Vaithinathan, K.K. Enhancing Greedy Web Proxy caching using Weighted Random Indexing based Data Mining Classifier. Egypt. Inform. J. 2019, 20, 117–130. [Google Scholar] [CrossRef]
- Mertz, J.; Nunes, I. Automation of application-level caching in a seamless way. Softw. Pract. Exp. 2018, 48, 1218–1237. [Google Scholar] [CrossRef]
- Ezugwu, A.E.; Pillay, V.; Hirasen, D.; Sivanarain, K.; Govender, M. A Comparative Study of Meta-Heuristic Optimization Algorithms for 0–1 Knapsack Problem: Some Initial Results. IEEE Access 2019, 7, 43979–44001. [Google Scholar] [CrossRef]
- Rashkovits, R. Preference-based content replacement using recency-latency tradeoff. World Wide Web 2016, 19, 323–350. [Google Scholar] [CrossRef]
- Hashemi, A.; Joodaki, M.; Joodaki, N.Z.; Dowlatshahi, M.B. Ant colony optimization equipped with an ensemble of heuristics through multi-criteria decision making: A case study in ensemble feature selection. Appl. Soft Comput. 2022, 124, 109046. [Google Scholar] [CrossRef]
- Paniri, M.; Dowlatshahi, M.B.; Nezamabadi-Pour, H. Ant-TD: Ant colony optimization plus temporal difference reinforcement learning for multi-label feature selection. Swarm Evol. Comput. 2021, 64, 100892. [Google Scholar] [CrossRef]
- Paniri, M.; Dowlatshahi, M.B.; Nezamabadi-Pour, H. MLACO: A multi-label feature selection algorithm based on ant colony optimization. Knowl.-Based Syst. 2020, 192, 105285. [Google Scholar] [CrossRef]
- Ali, W.; Shamsuddin, S.M. Intelligent Dynamic Aging Approaches in Web Proxy Cache Replacement. J. Intell. Learn. Syst. Appl. 2015, 7, 117–127. [Google Scholar] [CrossRef]
- Mertz, J.; Nunes, I. Understanding Application-Level Caching in Web Applications. ACM Comput. Surv. 2017, 50, 1–34. [Google Scholar] [CrossRef]
- Chen, T.-H.; Shang, W.; Hassan, A.E.; Nasser, M.; Flora, P. CacheOptimizer: Helping developers configure caching frameworks for hibernate-based database-centric web applications. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Seattle, WA, USA, 13–18 November 2016; pp. 666–677. [Google Scholar] [CrossRef]
- Kroeger, T.M.; Long, D.D.E. Exploring the Bounds of Web Latency Reduction from Caching and Prefetching. In Symposium on Internet Technologies and Systems on USENIX, 1997, no. September 2012, [Online]. Available online: https://dl.acm.org/citation.cfm?id=1267281 (accessed on 29 September 2020).
- Teng, W.-G.; Chang, C.-Y.; Chen, M.-S. Integrating Web caching and Web prefetching in client-side proxies. IEEE Trans. Parallel Distrib. Syst. 2005, 16, 444–455. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| No | Info | BO2 | SV | UC | NY |
|---|---|---|---|---|---|
| 1 | Proxy Location | Boulder, Colorado | Silicon Valley, California | Urbana Champaign | New York |
| 2 | Total requests | 666 | 666 | 666 | 666 |
| 3 | Cacheable requests | 110 | 87 | 141 | 74 |
| 4 | Cacheable bytes | 57,629 | 44,480 | 71,583 | 37,218 |
| 5 | Unique requests | 386 | 527 | 388 | 267 |
| No | Datasets | HR Average | ||||||
|---|---|---|---|---|---|---|---|---|
| LRU | LFU | LFUDA | SIZE | GDS | GDSF | LRU-GENACO | ||
| 1 | BO2 | 26.78 | 26.25 | 26.23 | 23.1 | 24.36 | 26.59 | 27.39 |
| 2 | NY | 51.65 | 51.73 | 52.14 | 51.93 | 50.54 | 52.97 | 51.71 |
| 3 | SV | 10.39 | 9.02 | 10.16 | 9.66 | 9.65 | 10.2 | 10.83 |
| 4 | UC | 34.71 | 27.93 | 32.47 | 29.24 | 33.37 | 31.79 | 34.82 |
| AVG | 30.88 | 28.73 | 30.25 | 28.48 | 29.48 | 30.39 | 31.19 | |
| No | Datasets | Average LSR | ||||||
|---|---|---|---|---|---|---|---|---|
| LRU | LFU | LFUDA | SIZE | GDS | GDSF | LRU-GENACO | ||
| 1 | BO2 | 18.99 | 11.38 | 16.29 | 13.75 | 8.22 | 12.56 | 22.07 |
| 2 | SV | 1.31 | 1.05 | 1.8 | 1.45 | 1.39 | 1.96 | 3.13 |
| 3 | UC | 17.86 | 5.86 | 16.422 | 5.41 | 8.72 | 13.99 | 18.17 |
| 4 | NY | 24.56 | 23.97 | 26.08 | 25.9 | 25.97 | 26.52 | 25.27 |
| AVG | 15.68 | 10.57 | 15.15 | 11.63 | 11.08 | 13.76 | 17.16 | |
| No | Cache Size | Hit Ratio (HR) | |||||
|---|---|---|---|---|---|---|---|
| LRU | LFU | LFUDA | SIZE | GDS | GDSF | ||
| 1 | 3000 | 7.83 | 3.77 | 3.77 | 77.63 | 34.09 | 5.76 |
| 2 | 6000 | 1.26 | 26.96 | 14.27 | 81.69 | 53.78 | 14.27 |
| 3 | 9000 | 3.22 | 4.34 | 17.06 | 62.64 | 49.95 | 6.66 |
| 4 | 12,000 | 1.83 | 6.72 | 15.68 | 54.21 | 27.64 | 3.73 |
| 5 | 15,000 | 8.12 | 12.7 | 21.99 | 49.48 | 41.53 | 17.68 |
| 6 | 20,000 | 10.14 | 7.79 | 4.82 | 47.51 | 39.4 | 10.94 |
| 7 | 25,000 | 13.1 | 11.65 | 16.92 | 51.75 | 36.23 | 6.83 |
| 8 | 50,000 | 1.47 | −0.48 | 2.98 | 33.56 | 5.07 | 1.47 |
| 9 | 90,000 | −0.8 | 8.79 | −1.19 | 10.73 | 6.46 | −1.19 |
| 10 | 150,000 | −1 | 1.92 | 0.07 | 2.67 | 4.22 | 0.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zulfa, M.I.; Hartanto, R.; Permanasari, A.E.; Ali, W. LRU-GENACO: A Hybrid Cached Data Optimization Based on the Least Used Method Improved Using Ant Colony and Genetic Algorithms. Electronics 2022, 11, 2978. https://doi.org/10.3390/electronics11192978
Zulfa MI, Hartanto R, Permanasari AE, Ali W. LRU-GENACO: A Hybrid Cached Data Optimization Based on the Least Used Method Improved Using Ant Colony and Genetic Algorithms. Electronics. 2022; 11(19):2978. https://doi.org/10.3390/electronics11192978
Chicago/Turabian StyleZulfa, Mulki Indana, Rudy Hartanto, Adhistya Erna Permanasari, and Waleed Ali. 2022. "LRU-GENACO: A Hybrid Cached Data Optimization Based on the Least Used Method Improved Using Ant Colony and Genetic Algorithms" Electronics 11, no. 19: 2978. https://doi.org/10.3390/electronics11192978