1. Introduction
Since they were first proposed in the 1960s [
1], reflectarray antennas have evolved from bulky waveguide array profiles to microstrip low-profile antennas, introducingg an important reduction in manufacturing costs as well as more reliable manufacturing processes and design techniques [
2,
3]. This technological improvement has allowed the use of reflectarrays in a myriad of applications in the far field, such as space communications [
4], including direct broadcast satellites [
5], cubesats [
6,
7], synthetic radar apertures [
8], global Earth coverage [
9] and multibeam coverage [
10,
11], as well as in terrestrial millimeter communications such as point-to-multipoint [
12], point-to-point [
13], beam scanning [
14] and the new intelligent reflective surfaces paradigm for beyond-fifth-generation wireless networks [
15]. Reflectarrays have also found applicability in the near field in wireless power transmission [
16], the internet of things [
17] and measurement systems for new 5G radio devices [
18].
With this increased applicability of reflectarrays, it is important to develop increasingly efficient tools to improve the efficacy of the analysis process, so that antennas may be readily designed with a fraction of the effort compared to the use of commercial multi-purpose tools. In this regard, an accurate analysis of a reflectarray antenna requires the use of a full-wave analysis tool based on local periodicity (FW-LP) [
2], usually a method of moments (MoM-LP) [
19,
20,
21,
22], to obtain the four complex reflection coefficients that characterize the electromagnetic response of the unit cell. This tool provides a reasonable computational speed for reflectarray analysis and design compared with a full-wave analysis of the whole antenna [
23,
24], but it is relatively slow for a direct optimization of the layout [
25]. In the context of this work, the analysis of a reflectarray antenna consists in extracting the electromagnetic response (i.e., the reflection coefficients) of all the elements of which it is composed; the layout design consists in finding, at a single frequency, the sizes of the relevant geometric features of all unit cells (patch dimensions, dipole lengths, etc.) and it is performed at the unit cell level to adjust the phase response to a given desired value [
26], one unit cell at a time. The direct layout optimization process consists in optimizing all reflectarray elements at the same time, imposing constraints at the radiation pattern level in the copolar and/or crosspolar components at one or several frequencies. Direct layout optimization may be performed using any of the multiple optimization algorithms available in the literature. Some algorithms that have been recently applied with success for the optimization of reflectarray antennas include the generalized Intersection approach [
18,
25], gradient minimax [
27] and social network optimization [
28,
29], among others. These algorithms typically require the evaluation of the cost function that invokes the analysis tools thousands or even hundreds of thousands of times. It is thus interesting to find alternatives to the analysis process with the FW-LP for design and optimization procedures. In this way, not only would the tasks of design and optimization be considerably accelerated, but since an intensive computational task is substituted by another which is much faster, energy savings would be achieved via the reduction in the overall time that it takes for the antenna to be designed.
The most common techniques for the acceleration of the reflectarray analysis include the use of databases (in the form of look-up tables or LUTs) [
30,
31,
32] or machine learning techniques (MLTs) such as artificial neural networks (ANNs) [
33,
34,
35], ordinary kriging [
36] or support vector machines applied to regression (SVR) [
37,
38]. Both approaches—the use of MLTs and databases—present potential advantages and disadvantages. On the one hand, the MLTs can be viewed as a “smart” interpolation in the sense that the training process that is required to build the surrogate model finds the optimal weighting factors to be applied to the input variables. In this way, prediction of new outputs based on unknown inputs is potentially more accurate. Conversely, databases do not require any prior knowledge to generate the output values beyond the precomputed samples that are stored in the database. Both approaches require the use of a FW-LP tool to generate samples of the electromagnetic response of the unit cell. For the MLTs, these samples are used in a cross-validation procedure consisting of three phases—training, validation and testing—that guarantee the generalization properties of the surrogate model [
39,
40]. Although this process may be costly [
41], it only needs to be performed once. Then, the surrogate model performs a linear combination of kernel functions that depend on all the weighting values obtained in the cross-validation procedure and the new input variables.
On the other hand, databases only require sample generation, skipping the cross-validation procedure. In this regard, databases are potentially faster to generate than surrogate models. Then, for the application of a local interpolation, the database has to identify samples of which the coordinates are close to those of the input variables. This local interpolation is also faster than the linear combination of kernel functions performed by MLTs. Thus, a database can also be potentially faster than an MLT applied to antenna design and optimization. However, the database achieves this at the expense of having potentially less accuracy than the surrogate models. Finally, even though both approaches have been shown to greatly accelerate reflectarray layout design and direct layout optimization with regard to the FW-LP [
30,
37], they have yet to be compared against each other. In addition, other works in the literature employing databases for reflectarray design and optimization [
30,
31,
32,
42] do not provide details on implementation, which may significantly impact performance if not performed carefully.
In this work, we propose a simple database in the form of a lookup table of reflection coefficients with efficient memory access and a fast but effective N-linear interpolation approach (i.e., a linear interpolation in
N dimensions) for the analysis, layout design and crosspolar optimization of reflectarray antennas. Its performance is benchmarked against the baseline provided by the FW-LP tool from which the database is generated in terms of speed-up and accuracy at the radiation pattern level. In addition, the database is also compared with another tool based on SVR, which the authors of the present work have previously shown to provide substantial acceleration, while preserving the accuracy in the analysis of the unit cell [
40], as well as in the design and direct layout optimization of reflectarray antennas [
26,
37,
43]. The results show that, as long as the database is conveniently populated, the accuracy is this approach is similar to that obtained with the SVR, while achieving faster layout designs and avoiding the machine learning training phase, which can be computationally expensive. In addition, the results show that the number of samples of the database may be reduced, compared with other works in the literature [
30], while still providing accurate results. This fact can be exploited in high-dimensional databases to greatly reduce the total number of samples by reducing the size of the grid, while still obtaining acceptable accuracy in the radiation pattern.
2. Statement of the Problem
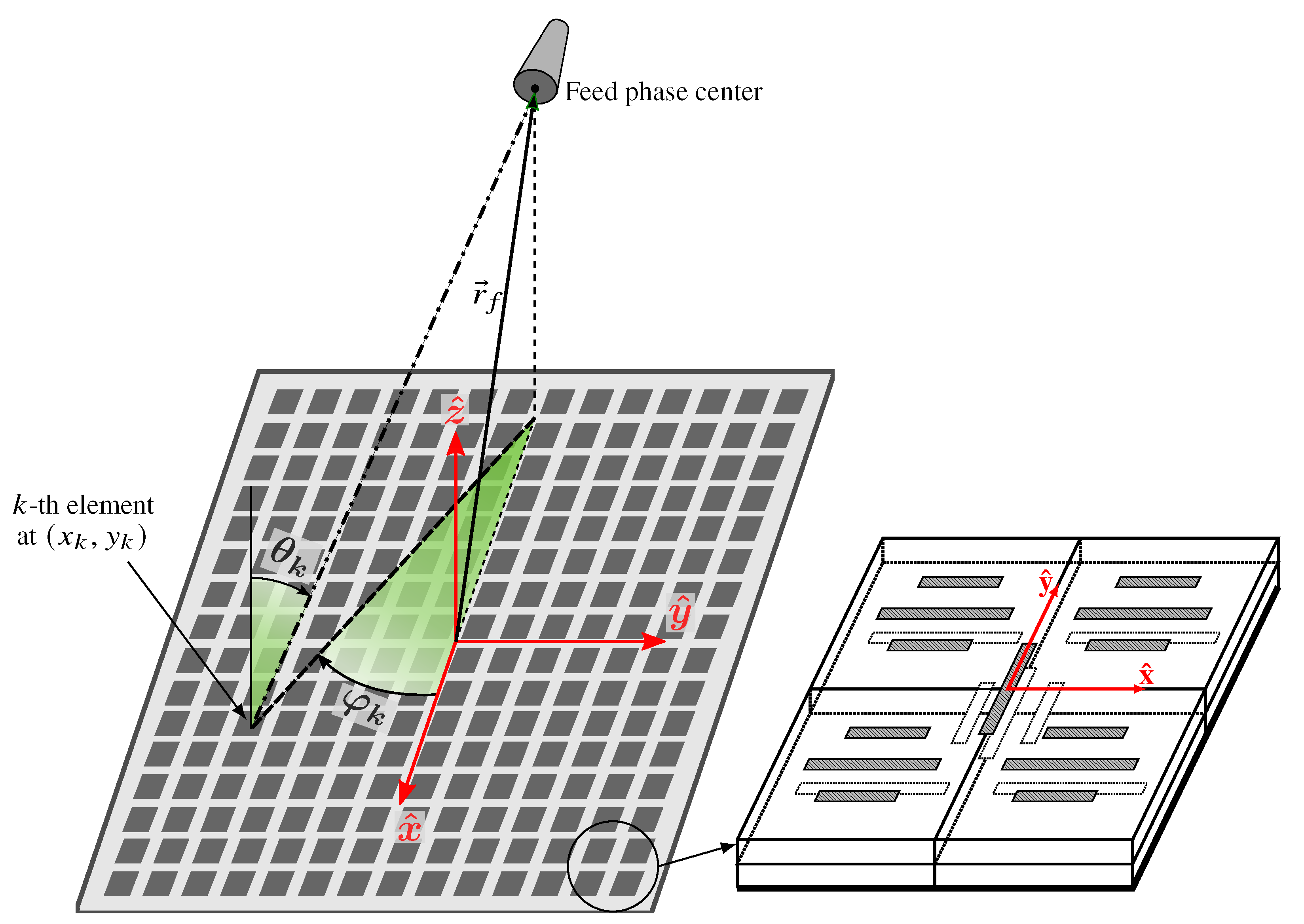
The main goal of employing a database for reflectarray analysis, layout design and direct layout optimization is to considerably accelerate those tasks with regard to the use of an FW-LP tool, while having a reasonable accuracy in the prediction of radiation patterns. Before detailing the particularities of the database, let us consider the reflectarray diagram shown in
Figure 1. The considered reflectarray is planar and composed of a number of elements or unit cells (depicted in
Figure 1 as patches, but other geometries are possible, such as dipoles, rings, etc.) and a feed of which the phase centre is placed at
with regard to the center of the reflectarray. With this antenna’s optics, the
k-th element will experience an angle of incidence from the feed phase center
, and it will be different for each reflectarray element.
The electromagnetic response of the
k-th unit cell is given by the matrix of reflection coefficients, comprising four complex numbers:
where
and
are known as the direct coefficients and
and
are known as the cross-coefficients. Their value depends on several parameters: frequency, periodicity of the unit cell, substrate characteristics, angle of incidence and the geometrical features of the unit cell (patch dimensions, dipole width and length, etc.). From the point of view of the antenna design, the frequency is fixed beforehand depending on the application, and it may be a certain bandwidth, in which case a small set of discrete frequencies are employed in the design. The substrate is also fixed and it is selected among a set of commercially available substrates. The periodicity may be chosen after a parametric study or to meet certain conditions, such as avoiding grating lobes [
2]. The angles of incidence at each element are fixed once the antenna optics has been selected to meet certain requirements, such as gain and a lack of blockage by the feed (see
Figure 1). Finally, the geometrical features of the unit cell provide the degrees of freedom (DoF) for the reflectarray layout design and/or optimization.
Given the above-mentioned considerations, a database for the rapid calculation of the reflection coefficients in (
1) should consider the frequencies of operation, the angle of incidence and the geometrical features of the unit cell. This means that the periodicity and substrate characteristics will be fixed before generating samples of
R to populate the database. Thus, if either the periodicity or the substrate changes, the database needs to be generated again. However, once a database has been generated for a suitable unit cell, it can be reused in as many designs as necessary (the same would apply to MLT surrogate models).
After the database is generated and integrated into an analysis tool to obtain the reflection coefficients in (
1), the radiation pattern can be computed by following the formulation detailed in [
45].
5. Reducing the Number of Samples in the Database
The results shown in the previous section demonstrate the discrepancies in the radiation patterns for different tasks: layout design, antenna analysis and direct layout optimization. As long as the analysis is accurate enough, the layout design and optimization will provide accurate results as well. However, the accuracy of the database not only depends on the interpolation approach used (N-linear in the present work), but also on the number of samples employed to populate the database. For instance, here
yielded very accurate results. Other works employ more samples in each dimension, such as
in [
30]. In the case of surrogate models based on SVR, one can considerably reduce the number of training samples without affecting the accuracy of the radiation pattern [
41]. This also implies the opposite: there is a point from which it does not matter how many more training samples are employed; the accuracy will not improve. Thus, it is also interesting to analyze how modifying the sample density in the database impacts the accuracy at the radiation pattern level.
For a fair comparison with the surrogate models, we employed the same number of samples in our database as that used by the SVR in the training process. That means that the samples used in the test phase of the cross-validation procedure were not counted towards the total number of samples used to populate the database. It is worth noting that only the number of samples in the database and the SVR training process was the same—not the samples themselves, since the database requires a regular grid, whereas the SVR employs randomly generated samples [
40].
For this comparison, the following relative error in the radiation pattern was used:
where
G is either the copolar or the crosspolar gain pattern. Note that, using the
-norm in (
15), all the points at which the far field is computed are taken into account for the calculation of the relative error. This means that the side-lobe area will contribute to the error as much as points in the coverage zone where the figures of merit are computed (i.e., CP
min, XPD
min and XPI).
Figure 9 shows the evolution of the relative error of the radiation pattern when the number of samples varies. For the database it includes two lines. The solid line represents the evolution of the relative error when the magnitude of the direct coefficients
and
is directly interpolated, whereas the dashed line represents the relative error when the magnitudes of
and
are obtained from the interpolated real and imaginary parts. As can be seen, directly interpolating the magnitude of the direct coefficients significantly increases the overall accuracy of the database, making it more robust and accurate when the number of samples per
pair decreases. Indeed, in that case, the relative error of the database and the surrogate models based on SVR is very similar for both the copolar and crosspolar components of the radiation pattern.
In addition, the relevant figures of merit did not change very significantly.
Table 6 shows the values of the figures of merit for two different databases employed to generate
Figure 9, specifically, the rightmost point (
) and the third point from the left (
). As reference, the figures of merit obtained in a simulation with MoM-LP are also provided. As can be seen, even when significantly reducing the number of samples in the database, from a grid of
points to
, the value of the figures of merit barely change. This result is in agreement with that shown in
Figure 9, and it can be exploited for high-dimensional databases to greatly reduce the total number of samples by reducing the size of the grid, while still obtaining acceptable accuracy in the radiation pattern.
6. Conclusions
In this work, we have presented a simple and efficient database for reflectarray analysis, layout design and direct layout optimization for cross-polarization improvement. The database employs multidimensional N-linear interpolation and efficient access to the reflection coefficients stored in the memory for a very fast analysis of the unit cell.
In order to assess the performance of this database both in terms of computational efficiency and accuracy at the radiation pattern level, it was compared with the MoM-LP tool employed to populate the database and with a machine learning technique based on SVR. In all cases shown in this work, the database presents a high degree of accuracy compared with the simulations carried out with MoM-LP, while significantly decreasing computing times. In particular, the database is four orders of magnitude faster than MoM-LP in carrying out analysis and layout design, whereas it is an order of magnitude faster than the SVR for the same tasks. In addition to this improved computational performance in reflectarray analysis and design, the accuracy remains high, with a relative difference in the obtained layout of less than 1.1%, which translates to relative errors in the radiation pattern of less 0.2% in the copolar pattern and less than 0.7% in the radiation pattern. Regarding the accuracy in the figures of merit, differences in minimum copolar gain in the area of interest are negligible, whereas in the cross-polarization performance the maximum difference was less than 0.3 dB in the XPI parameter. For direct layout optimization, both the database and the SVR offered similar computing times with similar accuracy, both being one order of magnitude faster than the MoM-LP approach.
In addition, the database accuracy as a function of the number of samples per pair of angles of incidence was tested. As is the case with SVR models, the number of samples can be reliably reduced while maintaining a high degree of accuracy in the radiation pattern. This behavior is very interesting for high-dimensional databases, since the number of samples quickly increases with the dimensionality. Thus, by maintaining a low sample density in each dimension, the total number of samples can be kept to a moderate number without excessively penalizing the accuracy in the prediction of the radiation patterns.
The use of the database, despite using a simple N-linear interpolation, offers good accuracy and fast computing times compared to the use of MoM-LP. Compared to machine learning techniques such as SVR, it avoids the training phase, which can be time consuming. Thus, a database based on N-linear interpolation is a suitable tool for reflectarray design and direct layout optimization for any application that requires the use of this kind of antenna.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}