1. Introduction
Data fragmentation arises as a strategy to provide a new and adequate distribution unit in terms of performance. Chunks in a Distributed Database Management System (DDBMS) allow data to be stored close to the points of use, and thus each site manages only a portion of the database, reducing I/O requests. In addition, in a DDBMS scheme the location of the data reduces delays in remote access [
1].
Relational tables can be partitioned either horizontally or vertically. The basis of horizontal fragmentation is the select operator where the selection predicates determine the fragmentation, while vertical fragmentation is performed utilizing the project operator [
1].
This research uses horizontal fragmentation to divide a relation along its tuples, considering a cost model that uses predicates to obtain each fragment and assign it to the site where it produces the lowest cost under the current workload.
Database fragmentation can be performed statically or dynamically [
2]. When a workload changes, databases in a distributed environment require redesigning their schema. When these changes in the workload occur, dynamic fragmentation can be carried out from the starting point; however, for highly dynamic systems this causes an overhead when redesigning. The best approach is to redesign the schema incrementally each time changes are detected or periodically at regular intervals of time [
1]. Rodríguez et al. [
2] show different disadvantages of the static approach and mention the dynamic approach as a solution to all of them.
This work applies horizontal fragmentation dynamically to determine when to perform new fragmentations over time in a distributed database, thus avoiding the significant amount of time spent by the database administrator observing the system to collect the frequencies of the operations performed, guaranteeing the use of real trends to reduce query execution time, adapting the scheme to changes in access patterns and making refragmentation a trivial, autonomous, and executed on-the-fly task.
Large amounts of complex data (e.g., image, sound, and video) are collected and organized in databases every day. These complex data come in different formats and cannot be sorted by content in the same way as conventional data (those represented as strings or numbers). This scenario, combined with the huge size and considerable growth of some complex data collections, poses new challenges for information retrieval [
3]. The consideration of multimedia databases and CBIR (Content-Based Image Retrieval) makes this work a valuable study to face challenges and use fragmentation as an approach to improve the performance of this type of database. This article stands out for contemplating all the characteristics mentioned above in the new and complete fragmentation method applied to the database management systems that are most used in the literature [
4].
This article is organized as follows:
Section 2 shows the works related to dynamic horizontal fragmentation. The method proposed by this work is described in detail in
Section 3. The evaluations and results are shown in
Section 4.
Section 5 mentions different aspects to consider in the application of the proposed method. Finally,
Section 6 provides the conclusions and future research plans.
2. Related Work
To introduce this section, the work that laid the foundations for the development of the objectives of this work is presented. Our previous work in [
4] showed an in-depth analysis of the approaches related to dynamic fragmentation methods in multimedia databases. The most current works related to the topics of interest were selected through a research methodology. The conclusion in [
4] produced the objective of this new research since the platform where the horizontal fragmentation method was implemented was developed. In [
4], three works [
5,
6,
7] stood out for presenting a simple cost model for their implementation. Researchers in [
5,
6] carried out a vertical and horizontal fragmentation, respectively. Rodriguez-Mazahua et al. [
7] presented a hybrid fragmentation method for multimedia databases. The analysis in [
4] mentions that these works are excellent ways to perform fragmentation and it is concluded that the research performed helps researchers and practitioners with an overview of the state of the art of this type of work.
Pinto and Torres [
8] provided a solution to the problem of dynamic data reassignment in a partitionable distributed database with changing access patterns. They used a public company subsidized by the Mexican government, CFE (Comision Federal de Electricidad, Federal Electricity Commission), as a case study. CFE has a distributed database in continuous operation, which causes data fragmentation that cannot be determined with the server turned off. Therefore, the authors performed a horizontal fragmentation with partial replication to achieve improved performance through access patterns. It was mentioned as a conclusion that the tests showed a good behavior of the method under a distributed structure of 16 computers.
Saad et al. [
9] proposed a multimedia primary horizontal fragmentation approach and achieved this by analyzing the implications between predicates creating minterms to use in k-NN (K-Nearest Neighbor) and range query methods. A prototype was produced, implemented in C#, and named Multimedia Implication Identifier. The experiments satisfactorily obtained the expected result in a computational time that grows in a quadratic way for the analysis of the implications of similarity.
Hauglid et al. [
10] showed how DYFRAM performs dynamic table fragmentation and replication based on recent historical access to maximize the number of local accesses and minimize remote ones. DYFRAM is a decentralized approach that takes place in a distributed database environment. This work achieves its objective by observing the access patterns of the sites to the tables. The evaluation presented began by obtaining the results through a workload simulator under two sites; later, a new scenario was presented simulating two highly dynamic workloads involving more sites. Finally, DYFRAM was implemented in a distributed database system (DASCOSA-DB).
Abdalla and Amer [
11] presented a fragmentation strategy that sometimes uses partial replication to allocate fragments. The approach presented by the authors applies horizontal fragmentation in a relational database environment. To achieve this objective, a heuristic technique is used, since it evaluates the allocation of fragments to sites through a cost model. Finally, the heuristic model assigns the fragment to where it represents the highest cost. It is concluded that the proposed technique significantly improves the performance of distributed databases by eliminating frequent remote accesses and high data transfer costs between sites.
Bellatreche et al. [
12] oriented their work to the inclusion of optimal fragmentation schemes of large relational data warehouses. Different schemes are statically selected using a genetic algorithm. It presents the primary choice for horizontal incremental data fragmentation and adapts to the operations and evolution of data warehouse workloads. The conclusion mentioned that the adaptation produced an incremental approach, which was compared with two other strategies and was shown to give a better optimization with the queries, reducing the maintenance cost.
Derrar and Ahmed-Nacer [
13] carried out an investigation on horizontal fragmentation applied to data warehouses using the recent history of data access to minimize response time in OLAP query systems. In the first stage, the authors use histograms to analyze access to the fragments and apply refragmentation according to the new statistics collected. To evaluate this strategy, the APB-1 benchmark was used, which has a star scheme. It was implemented under Oracle 10G with 9000 tuples and 4-dimensional tables. The conclusions indicated that the results obtained are encouraging since the approach reduces the space occupied in memory and the query response time was shorter.
Herrmann et al. [
14] presented Cinderella, an autonomous algorithm to carry out horizontal fragmentation in irregularly structured entities. Cinderella maintains the fragments while entities are added, modified, or deleted to increase local queries and reduce execution costs. The approach has the quality of being incremental and abandons the idea of a single fragmentation. The presented work produces entity-based or workload-based fragmentation schemes. The evaluation was carried out with the TPC-H benchmark in PostgreSQL 9.3 and showed favorable results when achieving the planned objectives.
Fetai et al. [
6] presented Cumulus, a workload-based adaptive fragmentation protocol for applications with a high need for data consistency assurance. Cumulus is capable of fragmenting shared-nothing architectures, minimizing distributed queries, or even avoiding them. The work presented is adaptive and dynamic as it performs refragmentation at runtime. The evaluation was carried out with the TPC-C benchmark and a database of more than 10,000 tuples, showing the overall performance gain compared to systems where distributed transactions occur. Cumulus processes the workload and refragments before starting data redistribution, intending to eliminate costly and unnecessary reconfiguration.
Abdel et al. [
15] presented a distributed database system on a cloud environment to perform dynamic fragmentation, allocation, and replication decisions based on access patterns to sites and the load involved in allocating or migrating fragments or replicas to these. To carry out the objective of this work, an MCRUD (Modified Create, Read, Update and Delete) matrix is built to determine the operations performed with each predicate on each site and each application. The results evaluate the costs of each attribute and are placed in the ALP (Attribute Locality Precedence) matrix. The predicates of the attributes with a higher value in the ALP matrix define the horizontal fragmentation scheme. The MCRUD matrix determines the sites where the fragments will be assigned and where they will be replicated. The evaluation shows cost reduction through the application of the scheme produced by the approach presented.
Serafini et al. [
16] proposed Clay, an elastic algorithm capable of load balancing and distributing transactions through dynamic blocks called clumps. Clumps are created at runtime and based on the monitored workload. The authors compared Clay with graph fragmentation techniques and presented differences and key advantages that showed the proposed approach as a better option. Clay runs in an OLTP database environment and a reconfiguration engine that dynamically changes the data layer. The evaluation was carried out through three workloads: TPC-C benchmark, Product-Parts-Suppliers, and Twitter benchmark.
Lwin and Naing [
17] described an algorithm for assigning non-replicated dynamic fragments in a distributed database system. This approach was presented in two parts: the pre-processing phase and the action phase. The pre-processing phase uses the log information table stored by each site and obtains information for the method. The action phase fragments, allocates, and migrates data under a horizontal technique. The evaluation included four sites with fully connected distributed database systems and 10,000 tuples in each. A total of 75 percent of response inquiries and 25 percent of update operations were executed.
Olma et al. [
18] presented a logical raw files fragmentation scheme. This scheme allows for lightweight indexing on each fragment, highlighting benefits that are refined on the fly using an online random algorithm. The authors integrated this approach into a prototype in situ query engine called Slalom. The evaluation was carried out using synthetic and real workloads comparing Slalom response times against a traditional DBMS (Database Management System), a state-of-the-art in situ query processing engine, and adaptive indexing.
Castro-Medina et al. [
19] introduced FRAGMENT, a web application to carry out static horizontal fragmentation and replication over a cloud environment. FRAGMENT proposes a scheme for assigning fragments to the sites where the current cost of each fragment is reduced the most. The authors validated their work within the Amazon Web Services (AWS) platform with a simulated data set and the TPC-E benchmark.
Rodríguez-Arauz et al. [
20] collected historical data from the Orizaba Technological Institute and created a multimedia database with these. They used horizontal fragmentation to optimize data management and measured their performance using a cost model, which proved to be better than when horizontal fragmentation was not used.
Abebe et al. [
21] developed MorphoSys, a distributed database system that makes decisions automatically on how to partition data, what to replicate, and where to place these partitioned and replicated data. The authors used two benchmarks to evaluate their approach: YCSB and TPC-C. The results show that MorphoSys improves the performance of the evaluated databases 900 times.
Ge et al. [
22] introduced a set-based adaptive distributed differential evolution (S-ADDE) algorithm. S-ADDE adopts an island model to maintain population diversity. With the help of the S-ADDE database fragmentation result, the anonymity degree of the original dataset in each fragment increases. According to the analysis of the experimental results, the proposed S-ADDE algorithm is significantly better than the compared algorithms.
Different works were shown that apply horizontal fragmentation in different ways.
Table 1 shows the comparison of the different approaches under five headings. It is analyzed: if the works present completeness, that is, everything necessary to be implemented; if they have characteristics to implement them easily; if they are based on a cost model to carry out fragmentation; if the fragmentation they perform is dynamic; and finally, if they contemplate the use of content-based queries. The works that do not present completeness, do not include diagrams, equations, or algorithms that fully describe the approach they present, thus making it difficult to replicate the research. The approaches that are not easy to implement contain elements, data sets, tools, or preconditions difficult to obtain under the context of development, budget, or delimitation of the goals of this research.
Table 1 shows that we aim to provide a horizontal fragmentation method that fulfills the five criteria.
3. Dynamic Horizontal Fragmentation Contemplating CBIR
To introduce the description of the developed method, it will be briefly presented where it was implemented, and the tools involved. The strategy is divided into two sections. The first section involves the static fragmentation which takes place within the XAMANA web application. The second section performs the dynamic fragmentation as part of a library ready to be implemented within the projects related to the table that will be fragmented.
XAMANA is a web application developed under the Java programming language with the JavaServer Faces framework. The objective of XAMANA is to host the three types of fragmentation (horizontal, vertical, and hybrid) and execute them in four database management systems widely used in industry and academia [
4]: MySQL, PostgreSQL, Postgres-XL, and MongoDB.
Figure 1 shows the workflow of the static fragmentation method proposed in this work. As can be seen, content-based queries are part of the first steps of the diagram, as a new investigation will be developed when they are not present in the table to be fragmented.
The first step in the diagram is to obtain the name of the DBMS that the user utilizes (MySQL, PostgreSQL, Postgres-XL, or MongoDB) and the data to establish a remote connection with reading and writing privileges.
After verifying if content-based queries were executed on the table to be fragmented, descriptors hosted in the column that the user chooses are grouped. At this stage, other data are requested, which are detailed below, since they are part of the dynamic horizontal fragmentation workflow. The penultimate stage presents the scheme proposed by this approach. If the user agrees with the scheme shown, it will proceed to the last stage. The application of the fragmentation scheme is carried out under the connection data obtained in the first step of the workflow.
Figure 2 shows the workflow of the dynamic fragmentation method considering CBIR.
The first three activities of the dynamic fragmentation workflow take place inside XAMANA while the permanent analysis of the operations occurs inside a library named observer-fragmenter. The observer-fragmenter is responsible for dynamically adapting the distributed database schema to new trends in the workload at each site over time.
Figure 2 shows the first stage, which consists of obtaining and analyzing the log files. These files contain valuable information about the addresses of the sites and the approximate number of operations carried out in each of them. The analysis of the files consists of obtaining the initial operation and performance thresholds, calculated by the frequency of operations, the type (create, read, update, and delete), and where they come from (local or remote). The user assigns a percentage for the performance and operation threshold, which when reached in each fragment will cause a refragmentation. The frequency of the fragmentation is inversely proportional to these percentages; a low value for these thresholds will trigger a new fragmentation more often, while a high value for these thresholds will cause fewer fragmentations. We decided that the DBA must fix these parameters for two reasons: (1) the DBA knows how often the database access patterns change, and (2) to provide him/her the ability to configure the frequency of the fragmentation. For instance, if 10 operations accessed the data located in fragment
i in the last fragmentation
, an operation threshold of 50% would indicate that six new operations must be executed in fragment
i to exceed the current operation threshold, while a performance threshold of 100% would imply that the current value must be doubled to trigger a new fragmentation. In the third activity, it is observed that the user must implement the observer-fragmenter in each of his/her applications. The permanent analysis of the operations is carried out after implementing the proposed library in each site where queries are executed on the table of interest. The observer-fragmenter records the operations performed after fragmentation using the primary key and the type of operation and analyzes whether the operation and performance thresholds were reached. The last stage of the diagram shows the result of this approach which are sites with fragments of the original table. The user performs the operations on the fragments and in this way the execution cost and response time of the queries are reduced.
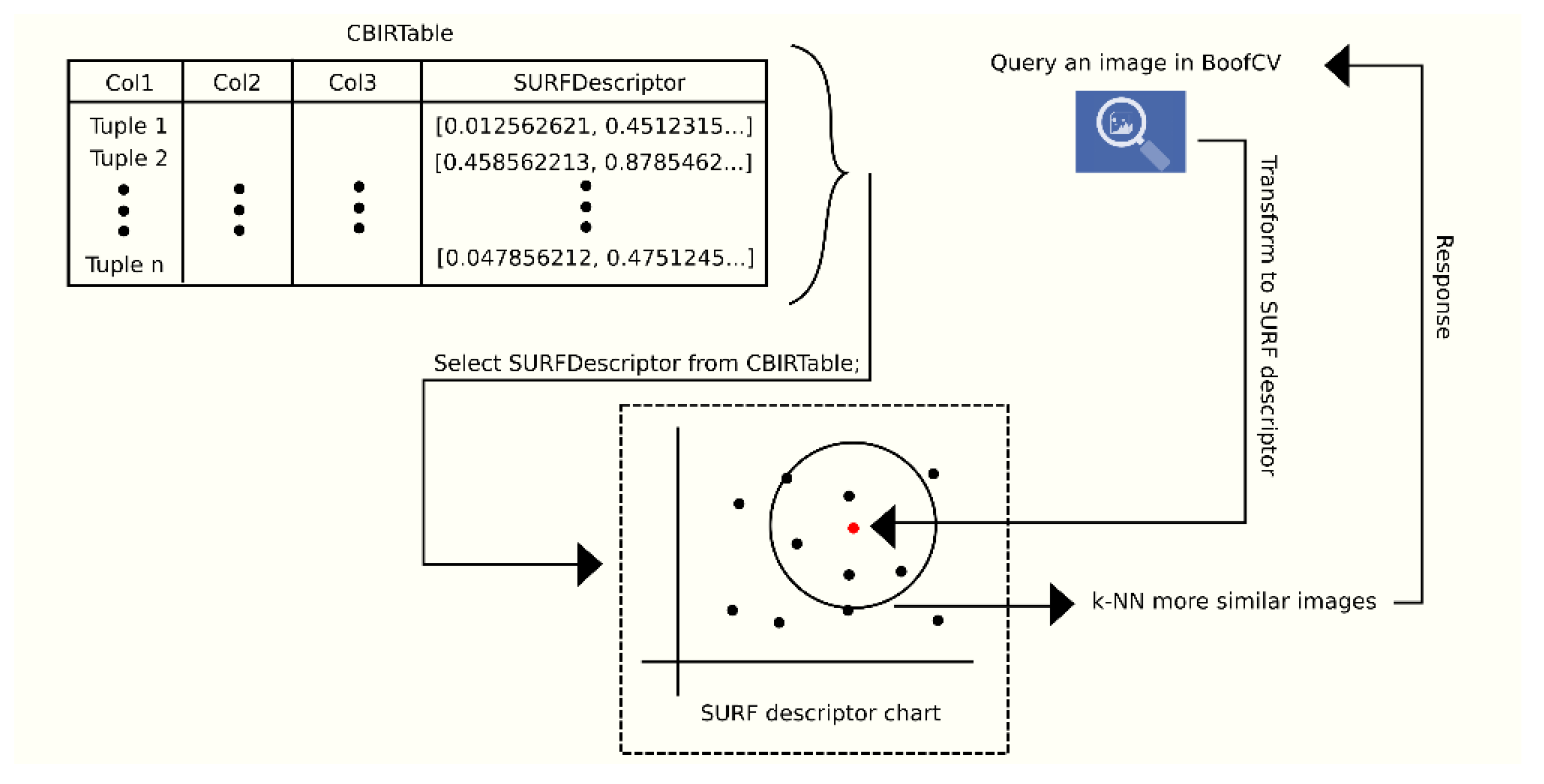
This work contemplates content-based queries under the suggested implementation of SURF (Speeded Up Robust Feature) descriptors under BoofCV [
23] and k-NN queries. Under this approach, BoofCV uses all the descriptors to carry out the classification of the multimedia elements and identify the most similar. Under a database approach, all the descriptors of a set of images are retrieved to obtain an answer for each query, which is filtered by the BoofCV libraries. This results in the log files not containing the number of operations used. For this reason, the record of operations within the observer-fragmenter was considered, so that only the real operations are recorded after filtering BoofCV.
Figure 3 represents the process of content-based queries under the BoofCV approach. In this research, we validate the proposed method using a multimedia database that contains SURF descriptors of images obtained by BoofCV.
By reducing the set of descriptors through this fragmentation approach, CBIRs are executed on smaller groups of SURF descriptors, thus improving the performance of these types of queries.
The operation threshold is calculated by adding the number of operations performed since the last fragmentation or refragmentation. Values representing the cost of each type of operation were determined to calculate the performance threshold.
Table 2 shows the values assigned to each type of operation.
Executing operations from remote sites is more expensive than running operations locally. This work considers in its cost model if the sites where the operations are carried out are local or remote. The performance threshold is obtained by the following equations:
where
PT is the performance threshold of fragment
i,
VTO is the value of the operation type according to
Table 2, and
RV is the remote value.
RV takes the value of 1 when the operation
j is local and 2 when it is remote,
S is the size of the data involved in the queries,
Sel is the selectivity of the predicates,
F is the frequency of operations executed from the same site and
N is the number of operations in the log file considering the fragmentation predicate.
When the operation and performance thresholds are exceeded by the operations performed, a new fragmentation is executed. The dynamic fragmentation that is carried out in the observer-fragmenter uses the graph of the Gaussian curve to normalize the use of the tuples throughout the fragment by the different sites. The diagram is divided into two and the site that represents a greater cost is determined on the tuples of the first and second part of the Gaussian diagram. Finally, the tuples of each half are assigned to their respective fragments and the fragments assigned to their sites.
As part of fragmentation techniques, it must be ensured that the semantics of the database do not undergo changes during fragmentation. Therefore, fragmentation techniques must meet three properties:
Completeness. If a relation instance R is decomposed into fragments FR = {R1, R2, …, Rn}, each data item that is in R can also be found in one or more of Ri’s;
Reconstruction. If a relation R is decomposed into fragments FR = {R1, R2, …, Rn}, it should be possible to define a relational operator ∇ such that:
The reconstructability of the relation from its fragments ensures that constraints defined on the data in the form of dependencies are preserved;
Disjointness. If a relation R is horizontally decomposed into fragments FR = {R1, R2, …, Rn} and data item di is in Rj, it is not in any other fragment Rk (k ≠ j). This criterion ensures that the horizontal fragments are disjoint. If relation R is vertically decomposed, its primary key attributes are typically repeated in all its fragments (for reconstruction). Therefore, in the case of vertical partitioning, disjointness is defined only on the nonprimary key attributes of a relation.
The method proposed in this work ensures the three previous properties. Completeness is guaranteed in the dynamic and static part of the approach, creating schemas that contain all the tuples of the original relation, allowing each tuple to be found in the created fragments. This is achieved by adding a fragment to the horizontal fragmentation scheme defined by the negation of the fragmentation predicates. Reconstruction is ensured by creating schemas under predicates that include, together, all the tuples of the original relation, as well as the dependencies of the same defined in the beginning. This method ensures disjointness, as it produces schemes with completely different fragments from each other.
Algorithm 1, Observer, represents the pseudo-code to analyze the changes in each operation performed and trigger a new fragmentation. The Token that Algorithm 1 uses as a parameter is provided by the web application, which is an identifier for obtaining the entire set of fragments, tuples, statistics, sites, and connection data from the XAMANA database. As observed in lines 4 and 8, the operation and performance thresholds are obtained as a percentage and must be interpreted under their respective values to determine when they are reached. Dynamic fragmentation occurs when both thresholds are reached or exceeded, i.e., the frequency of execution of the refragmentations is directly related to the cost model.
Algorithm 1 uses Algorithm 2, Fragmenter, which is responsible for applying fragmentation. As parameters, Algorithm 2 receives the data of the fragment (or the table) to be fragmented and the Token. In both algorithms, different details are omitted to summarize them and make them easier to understand. One of them is the recording of the new statistics in the XAMANA database after the fragmentation has been performed. In Algorithm 2, the implementation of fragmentation in MongoDB is highly related to the language in which the algorithm is implemented; however, this part is described in a general way using instructions from the NoSQL (Not Only SQL) DBMS.
| Algorithm 1 Observer |
| 1 | input: Token |
| 2 | fragments[]←Token.get fragments |
| 3 | fori from 0 to size of fragments[] do |
| 4 | nOperations←(fragments[i].Performance threshold percentage× |
| 5 | fragments[i].Number of initial operations)/100 |
| 6 | nOperations←nOperations+fragments[i].Number of initial operations |
| 7 | if fragments[i].Current operations number >= nOperations then |
| 8 | nPerformance← (fragments[i].Performance threshold percentage× |
| 9 | fragments[i].Number of initial performance)/100 |
| 10 | nPerformance←nPerformance+fragments[i].Number of initial performance |
| 11 | if fragments[i].Current performance number >= nPerformance then |
| 12 | x←fragmenter(fragments[i], Token) |
| 13 | write to activity file x |
In the application of Algorithm 2 in the observer-fragmenter, implemented in Java, lines 3–11 were carried out as queries to the XAMANA database.
The variable oddEven, on line 13, allows fragmentation for odd tuples and then for even tuples by changing the vector in turn and the IP address to which the tuples will be assigned. The arrangement of the tuples from lowest to highest frequency and the separation of even and odd causes a representation of the graph of a Gaussian curve to normalize the data. Separating even and odd tuples is similar to dividing the Gaussian graph into two.
Line 20 takes into account MongoDB, since being a NoSQL DBMS, the operations are different. Lines 21 and 27 separate the formation of the CREATE statement for MySQL and PostgreSQL DBMSs, since the syntax is similar, but not the same. Another reason why the algorithm separates relational DBMSs is due to data types, as some are not included in both.
The fragmentation process handles four IP addresses. The algorithm in lines 7, 8, and 9 shows the purpose of three of them. The fourth address is the connection to the XAMANA server, which must be considered in the workflow of the fragmentation performed by the web application, since users must allow the remote connection from this IP to their servers.
Lines 38–54 represent obtaining the tuples from the source server to the destination server. Lines 57–62 show a more compact process for MongoDB, since it allows the copying of documents without defining a structure in the destination and source collection, even in new versions of MongoDB, when making a connection to a non-existent collection, the DBMS creates it automatically.
| Algorithm 2 Fragmenter |
| 1 | input: fragment, Token |
| 2 | output: status |
| 3 | tupleIdFrequency[][]←get tuple identifiers and access frequency from fragment.Identifier |
| 4 | oddId[]←sort tupleIdFrequency[][] by frequency from lowest to highest, number them and get |
| 5 | odd |
| 6 | evenId[]←sort tupleIdFrequency[][] by frequency from lowest to highest, number them and |
| 7 | get even |
| 8 | connection←get connection data using Token |
| 9 | oddIP←get site that occupies the most odd tuples |
| 10 | evenIP←get site that occupies the most even tuples |
| 11 | inicialIP←get site where the fragment comes from |
| 12 | attributes[]←get fragment attributes |
| 13 | keyAttribute←get table identifier |
| 14 | for oddEven from 0 to 2 do |
| 15 | if oddEven is 0 then |
| 16 | vectorInTurn[]←oddId[] |
| 17 | ipInTurn←oddIP |
| 18 | else |
| 19 | vectorInTurn[]←evenId[] |
| 20 | ipInTurn←evenIP |
| 21 | sentence←”“ |
| 22 | if Token.get database type is not “MongoDB” then |
| 23 | if Token.get database type is “MySQL” then |
| 24 | foreach r←attribute in atributtes[] do |
| 25 | sentence←sentence + r.get name + “ “ + r.get datatype + “(“ + r.get size + “), “; |
| 26 | sentence←sentence − last two characters |
| 27 | createSentence←”create table “+fragment.get name+”_”+(oddEven)+ “ (“+ |
| 28 | sentence+”, PRIMARY KEY(“+keyAttribute.get name+”))” |
| 29 | if Token.get database type is “PostgreSQL” or “Postgres-XL” then |
| 30 | foreach r←attribute in attributes[] do |
| 31 | sentence←sentence + r.get name + “ “ + r.get datatype + “(“ + r.get size + “)”; |
| 32 | if r.get name is keyAttribute.get name then |
| 33 | sentence←sentence + “ PRIMARY KEY, “ |
| 34 | else |
| 35 | sentence←sentence + “, “ |
| 36 | sentence←sentence-last two characters |
| 37 | createSentence←”create table “+fragment.get name+”_”+(oddEven)+ “ (“+ |
| 38 | sentence+”);” |
| 39 | execute createSentence on ipInTurn using connection |
| 40 | u←”“ |
| 41 | foreach r←attribute in attributes[] do |
| 42 | u←u + r.get name + “, “ |
| 43 | u←u-last two characters |
| 44 | foreach y←item in vectorInTurn[] do |
| 45 | query←”select “ + u + “ from “ + fragment.get name + “ where “ |
| 46 | + keyAttribute.get name + “=“ + y + “;” |
| 47 | t[]←execute query in inicialIP using connection |
| 48 | values←”“ |
| 49 | for w from 0 to size of t[] do |
| 50 | values←values + t[w] + “, “ |
| 51 | values←values − last two characters |
| 52 | query←”INSERT INTO “ + fragment.get name + “_” + (oddEven) |
| 53 | + “ VALUES (“ + values + “);” |
| 54 | deleteQuery←”DELETE FROM “ +fragment.get name + “_” + (oddEven) + |
| 55 | “ WHERE “+ keyAttribute.get name + “=“ + y + “;” |
| 56 | execute query in ipInTurn using connection |
| 57 | execute deleteQuery in inicialIP using connection |
| 58 | status←”Fragmentation carried out successfully” |
| 59 | else |
| 60 | execute createCollection(fragment.get name + “_” + (oddEven)) in ipInTurn using |
| 61 | connection |
| 62 | foreach y←item in vectorInTurn[] do |
| 63 | where←create a new document with _id:y |
| 64 | resultSet←find using where in inicialIP using connection |
| 65 | insertOne with resultSet in new collection called fragment.get name + “_” + |
| 66 | (oddEven) |
| 67 | deleteOne using where in inicialIP |
| 68 | status←”Fragmentation carried out successfully” |
| 69 | return status |
4. Results
To obtain the results of this approach we use a multimedia database called HITO (Historia del Instituto Tecnológico de Orizaba, History of the Technological Institute of Mexico) [
20], implemented in MongoDB with more than 1.5 GB of storage. To carry out both workflows that perform static and dynamic fragmentation, the operations shown in
Table 3 were executed on the collection “
multimedia_records”, shown in
Table 4. The attribute
descriptor contains the SURF descriptor of the images obtained by BoofCV. In this way, a log file is obtained that will be used to obtain statistics of the operations before the first fragmentation using XAMANA.
The evaluation was carried out at three sites. The first site uses Ubuntu 20.04.3 LTS as the operating system, 4 GB RAM, and an AMD A6 processor with a clock frequency of 2.1 GHz. The second site uses Windows 10 as the operating system, 6 GB of RAM, and an Intel processor I7 with a 3 GHz clock frequency. The third site also uses Windows 10 as an operating system, 6 GB of RAM, and an AMD A8 processor with 2 GHz as a clock frequency. The centralized database is on the first site.
The data types shown in
Table 4 were interpreted using Java. As seen in
Table 3, read operations are performed from three different sites. Site 1 represents IP 192.168.200.5, site 2 represents IP 192.168.200.30, and site 3 represents IP 192.168.200.39.
Figure 4 shows the initial XAMANA view requesting the type of database to be fragmented. As a complement to JavaServer Faces in the web application, the PrimeFaces library was used to add a rich open-source user interface.
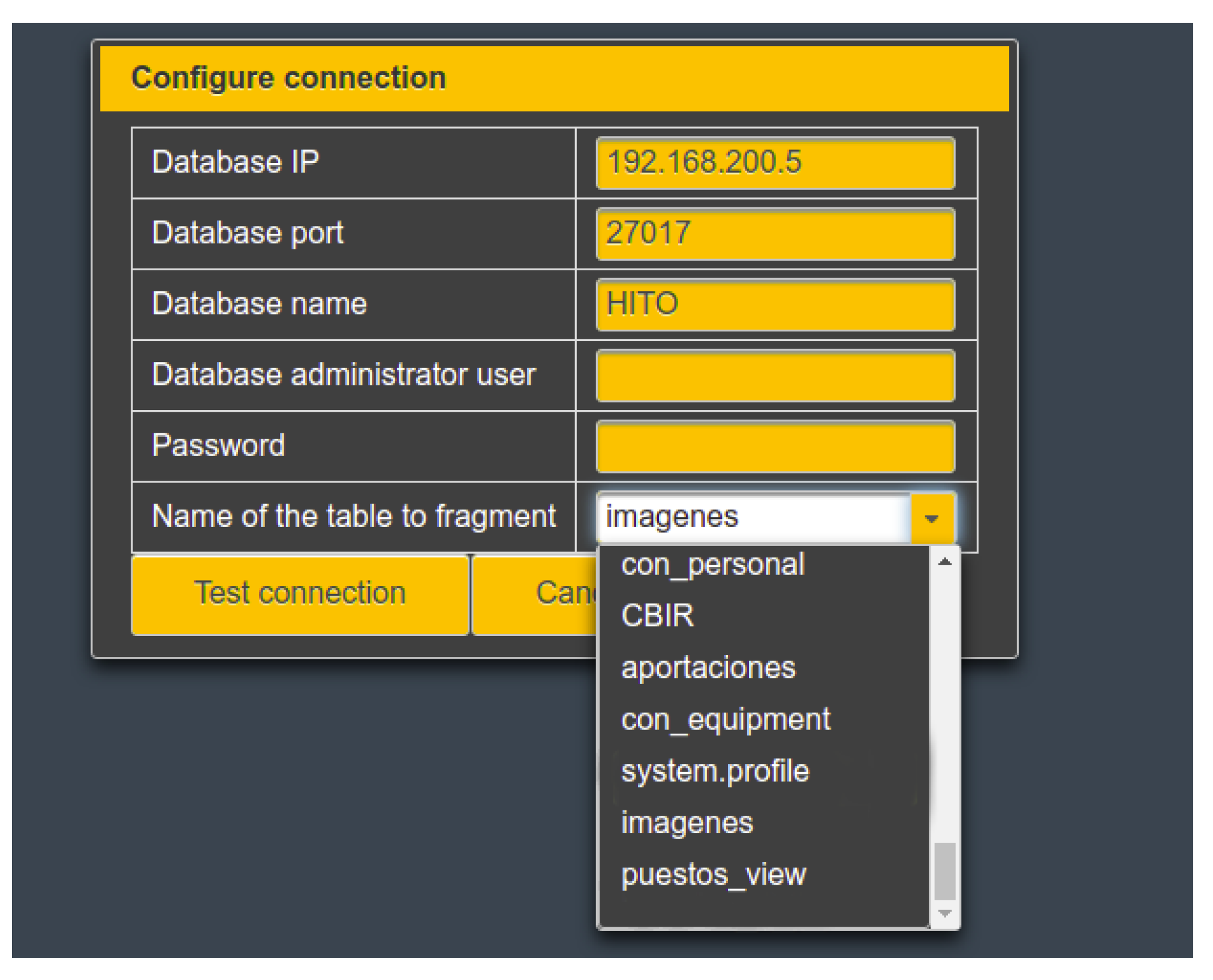
The connection configuration view is shown in
Figure 5. The data of the connection to the database are those mentioned in the preconditions that must be the same for all the sites of the same user (except the IP). The database address must allow remote connection from the XAMANA server IP. The username and password fields are not mandatory in databases where authentication is disabled. When placing the connection data, the list of tables found is automatically displayed.
The status of the connection is shown in the dialog in
Figure 6. If the connection data do not allow communication between XAMANA and the user’s database, a message informs that the data must be entered properly. If the connection data are correct, the fragmentation must be configured in the following view.
The fragmentation configuration screen is shown in
Figure 7. In
Figure 7, horizontal fragmentation was selected, being one of the three types of fragmentation that the web application allows. The CBIR option, when selected, displays the dialog shown in
Figure 8. The next field requested by the form presents the option to add the log files where the records of the operations previously executed are stored. For this evaluation, the thresholds were set with the percentages shown.
Figure 8 shows the selection of the descriptor attribute, by which the grouping of tuples and production of fragments will be carried out in the first stage of horizontal fragmentation. The descriptor attribute can be of any type of data, considering that it must form groups of tuples that share the same values. It is of interest to mention that the descriptor attribute contemplated in this stage does not share a similarity with the descriptors obtained by SURF. The use and implementation of BoofCV can help to obtain the values of the descriptor attribute, since using the k-NN algorithm with SURF descriptors allows for grouping multimedia content with similar characteristics.
Figure 9 shows the final structure of the fragments. The first column mentions the name of the fragment, the second column contains the set that defines the fragment, the third column represents the number of tuples that each fragment will contain, the fourth column shows the percentage that each fragment represents with respect to the entire table, the fifth column contains the operation value and the sixth column the performance value.
The values of the last two columns are obtained from the log file. The calculation of the initial values of operations and performance are obtained by searching the log for all operations that contain the set of each fragment in their predicates. The operations value is the number of operations found from that set. As an example, the
multimedia_records_f3 fragment, defined by the
event set, had five operations on the log file (one from site 1, three from site 2, and one from site 3 according to
Table 3). Therefore,
multimedia_records_f3 obtained a performance value of 5793, which is determined through the performance threshold cost model shown in Equation (1), adding the result of multiplying the value of the operation by the remote value by the variable
S by the frequency of each operation for each set.
Table 5 describes the performance value for each proposed fragment of
Figure 9.
The observer-fragmenter contains a mechanism to save the operations performed and bypass the log file in future fragmentations. The initial values are broadly related to determining the execution of the next fragmentation.
The final fragment structure view provides two final buttons. The button to apply the schema physically on the table and the button to download files to start the dynamic fragmentation. For the PostgreSQL DBMS, in addition to the observer-fragmenter, functions and triggers are offered to maintain a suitable design between the fragments. Functions and triggers analyze changes to the original table structure; that is, adding, removing, and modifying attributes. If any of these operations are executed on the original table, they must also be carried out on the fragments related to this table. In this way, the design of the fragments is synchronized with the original design, properly maintaining the structure of the attributes.
After performing the first fragmentation and starting the dynamic fragmentation, new operations are performed from sites 1, 2, and 3 on the observed fragments that trigger a new fragmentation.
Table 6 shows the operations performed by the three sites. For example, two operations (creation and read) are performed from site 1 on document IMG1662 located in the fragment
multimedia_records_f1.
After performing the 24 operations shown in
Table 6, the threshold analysis was carried out. The above operation and performance values shown in
Figure 9 represent 100% of the thresholds. However, in this evaluation, the thresholds were set at 5% and this means that both values should be lower than the previous ones.
Table 7 shows the thresholds reached by each fragment through the operations performed in
Table 6. For example, for
multimedia_records_f3, the previous operation and performance values according to
Figure 9 are 5 and 5793, respectively; therefore, the operation and performance thresholds are 0.25 and 289.65 (5 × 0.05 and 5793 × 0.05), the current operation value is 6 (read and update from site 1, create and delete from site 2, and read and update from site 3 according to
Table 6), and current performance value is 20 since the operations executed by site 1 are local and those by site 2 and 3 are remote.
Table 7 describes that no fragment exceeds both thresholds of 5% except for the
multimedia_records_f4 fragment. To represent the operation of refragmentation,
Figure 10 of the
multimedia_records_f4 fragment is shown.
The tuples are placed on a diagram representing the Gaussian curve to normalize the costs.
Figure 10 shows that the Gaussian curve will divide them to generate two new fragments:
multimedia_records_f4_1 and
multimedia_records_f4_2. The observer-fragmenter looks for the place where the tuples of each fragment represent the highest cost to perform the assignment. Therefore,
multimedia_records_f4_1 is assigned to site 3 and
multimedia_records_f4_2 to site 2. The current values of operations and performance are considered as previous values in the next refragmentation operation. Under the new refragmentation scheme, the same operations presented in
Table 3 are executed.
Table 8 shows the comparison of the execution times.
Table 8 shows a reduction in response times by 84.85% since remote communication was reduced and local communication increased. The initial operations found in the log were reads only and did not include content-based queries. A new experiment is carried out contemplating the retrieval of all descriptors to carry out content-based queries using the same attribute as multimedia description in the previous experiment. New operations are presented in the log simulating a new workload described in
Table 9. The initial fragments produced by the web application are the same as in
Figure 9, but the initial values of operations and performance are not.
Figure 11 shows the new initial values.
Table 10 presents the new operations performed in this experiment under the execution of the observer-fragmenter.
This evaluation uses 0.4% in both thresholds and is applied under two sites.
Table 11 represents the calculation of the thresholds for each fragment.
Table 11 shows that the only fragment to exceed both thresholds was
multimedia_records_f4. Refragmentation is carried out in the same way as in
Figure 9, placing the most used tuples in the center of the diagram and producing two new fragments. The execution times of the operations performed in
Table 9 are again compared in
Table 12 to observe the different execution times in this new evaluation.
Table 12 presents an improvement in response times of 98.84%. Additionally, the work presented in [
19] shows an operation simulator for MySQL. The functionalities of the query simulator were enriched to obtain log files simulating workloads and sites on the DBMS of this work. Execution times were obtained using a program written in Java before fragmentation and after fragmentation. A total of 200 queries on each site were simulated on the same MongoDB media collection to gain a more accurate percentage of improvement. Average response times resulted in an 86% reduction.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}