


Sightless but Not Blind: A Non-Ideal Spectrum Sensing Algorithm Countering Intelligent Jamming for Wireless Communication


Abstract
:1. Introduction
1.1. Related Works
1.2. Contribution and Structure
- This paper proposes a NISS algorithm, which combines the advantages of Q-learning and the WBSS algorithm. The proposed algorithm has a fast convergence rate and high decision accuracy.
- This paper takes the probability of false alarm and missed detection into account in anti-jamming communication for the first time, which is closer to the actual electromagnetic environment and fills the blank of intelligent anti-jamming wireless communication in the case of non-ideal sensing.
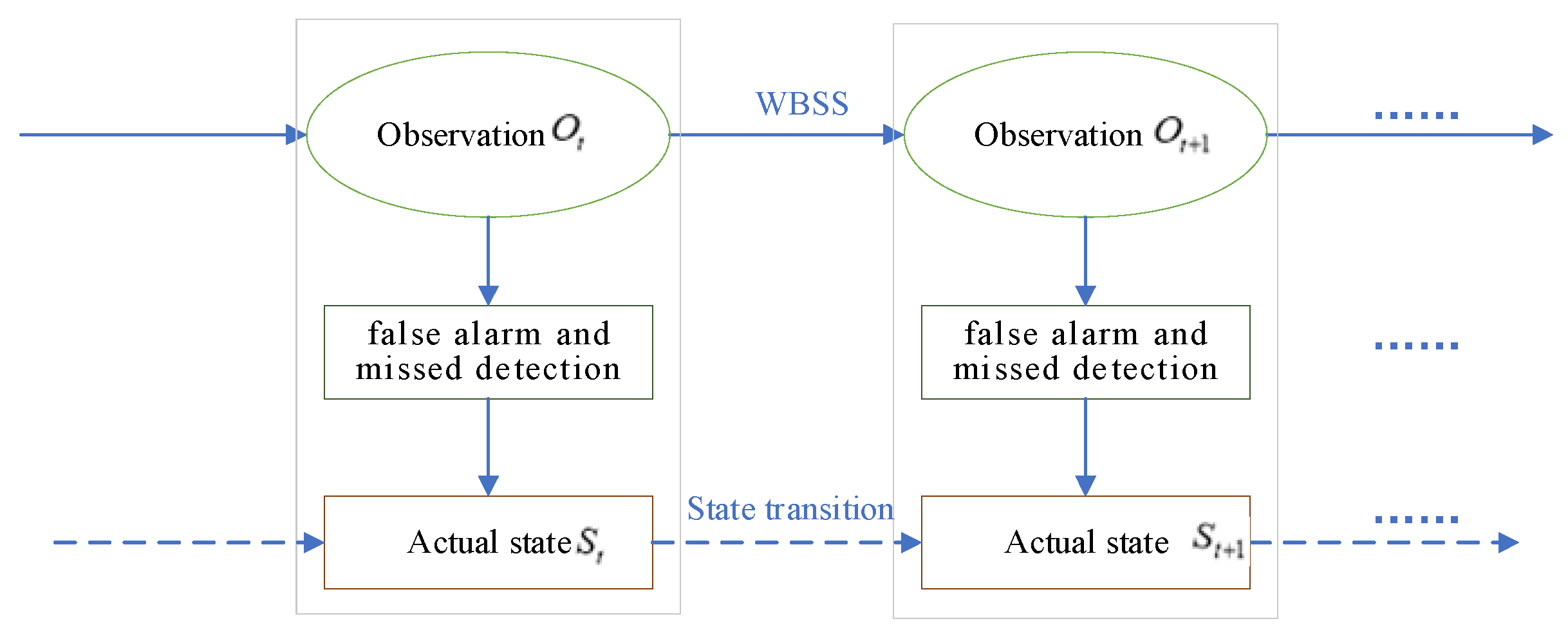
2. System Model and Problem Formulation
2.1. System Model
2.2. Problem Formulation
- The communication frequency band is divided into channels with the same bandwidth, and there is no frequency overlap between the channels, and the fading characteristics of each channel are the same and flat fading.
- The sensing result is only affected by false alarm and missed detection, which leads to inaccuracy, and there is no inaccuracy caused by other factors.
- In the same time slot, the channel of jamming does not change.
3. Detailed Derivation of Algorithm
| Algorithm 1: Intelligent anti-jamming communication decision algorithm based on NISS. |
| 1. Initialization: Learning factor , Discount factor and other parameters in Table 1. The Q table is initialized as a zero matrix with rows and columns, that is, for any and , let . |
| 2. for do |
| 3. In the current transmitter state , the transmitter performs the optimal policy selection action obtained in the last timeslot or the initial action . |
| 4. The transmitter detects the energy of each channel. |
| 5. Calculate the probability of false alarm and missed detection according to the detection results. |
| 6. According to the detection results, false alarm, and missed detection, the real-time reward is calculated and the next state is predicted to obtain the optimal communication channel . |
| 7. The agent updates the Q value according to (18) and (19). |
| 8. The agent obtains the optimal strategy according to (20) and instructs the transmitter to transmit in the next time slot. |
| 9. |
| 10: end for |
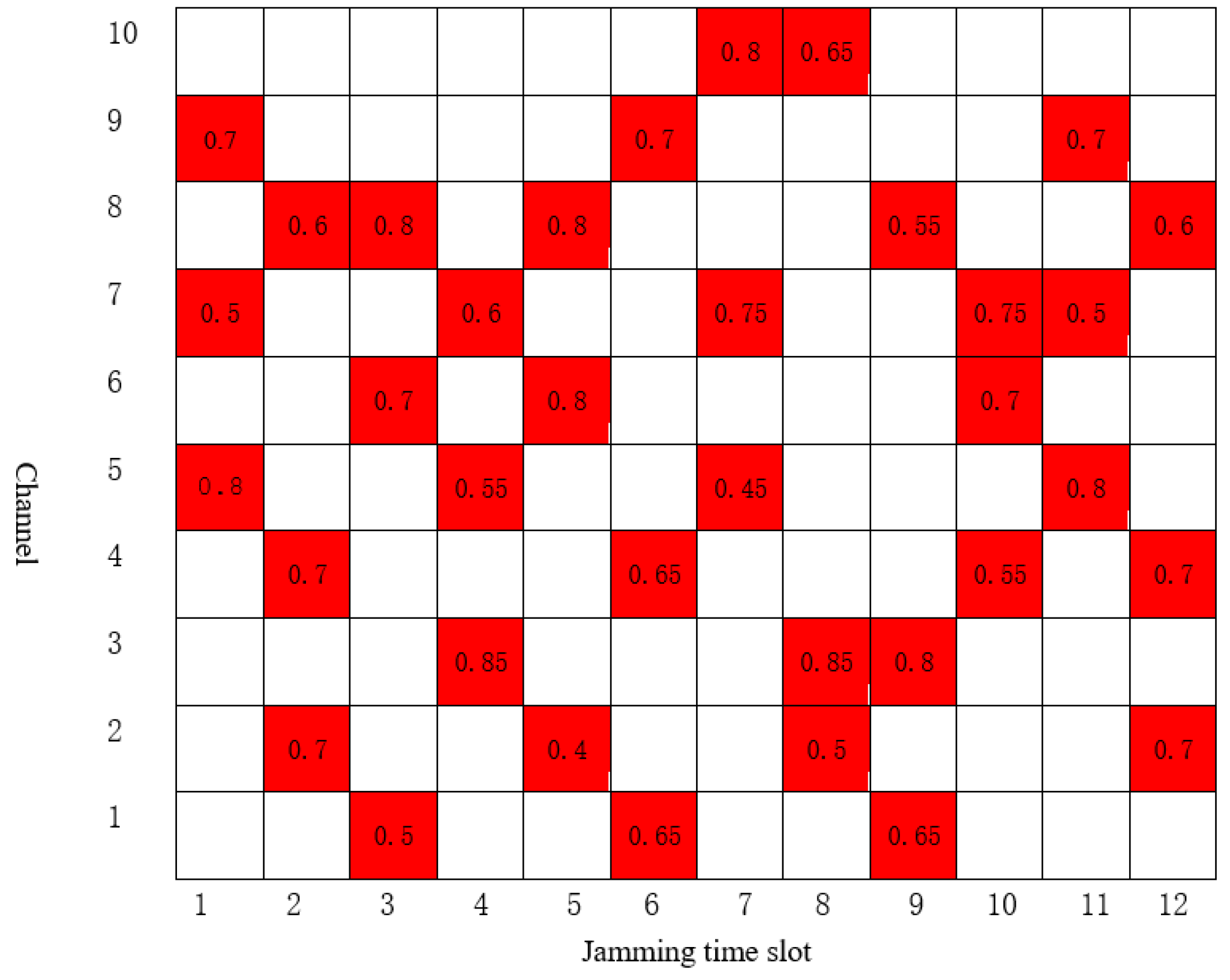
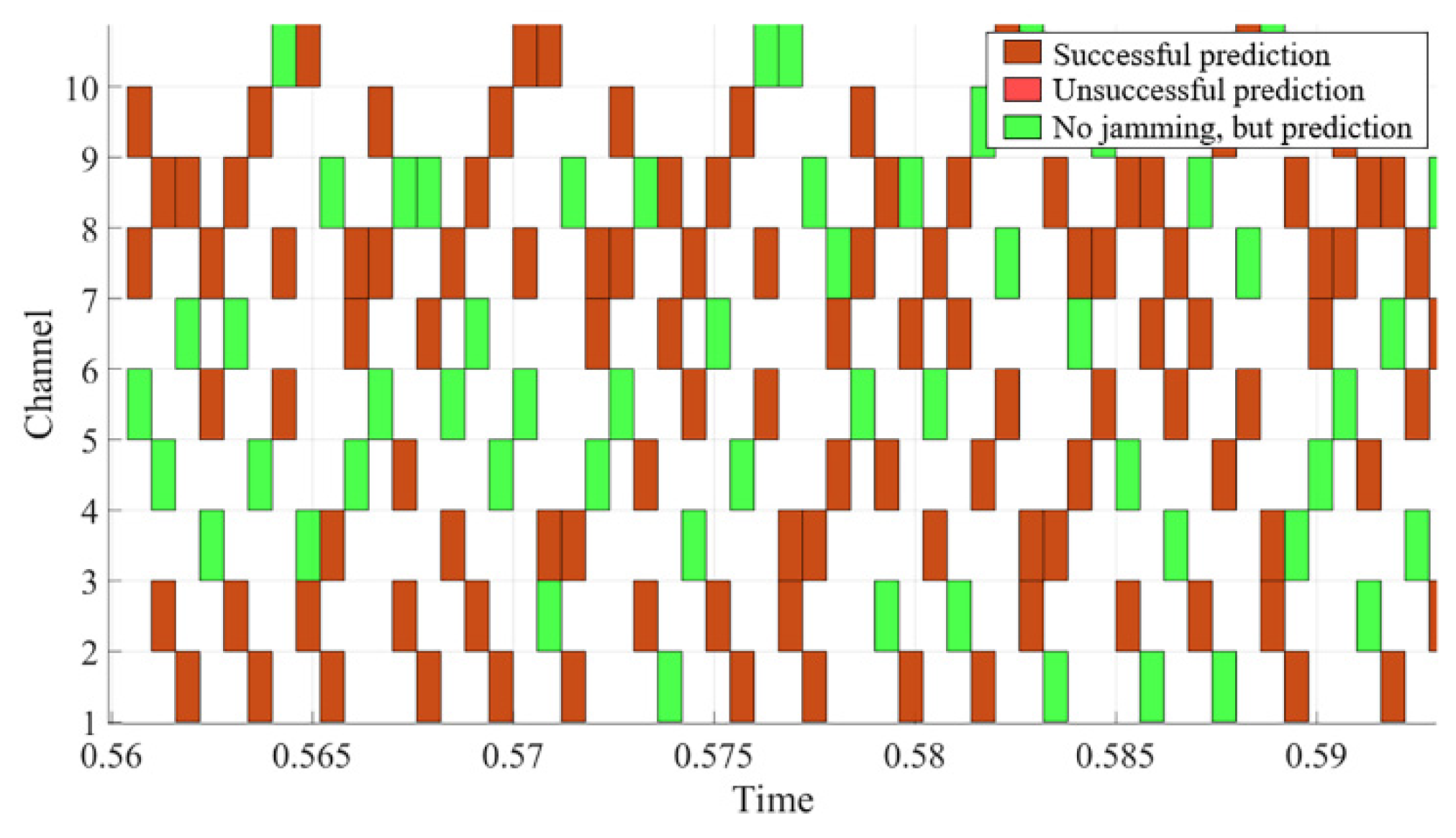
4. Simulation Result and Analysis
4.1. Parameter Settings

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Communication timeslot length | 0.6 ms |
| Transmission timeslot length | 0.5 ms |
| Perception timeslot length | 0.04 ms |
| Learning timeslot length | 0.06 ms |
| Total transmission timeslots | 10,000 |
| Number of available channels | 10 |
| Transmission power of transmitter | 30 dBm |
| Fading of communication signal | −130 dB |
| Transmission power of jamming | 30 dBm |
| Fading of jamming | −134 dB |
| Power spectral density of ambient noise | −174 dBm/Hz |
| Channel bandwidth | 1 MHz |
| Learning rate factor | 0.1 |
| The discount factor | 0.5 |
| Transmission success reward | 1 |
| Transmission failure loss | −3 |
4.2. Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yao, F. Communication Anti-Jamming Engineering and Practice; Electronic Industry Press: Beijing, China, 2008. [Google Scholar]
- Wu, Y.; Wang, B.; Liu, K.R. Optimal defense against jamming attacks in cognitive radio networks using the Markov decision process approach. In Proceedings of the 2010 IEEE Global Telecommunications Conference GLOBECOM, Miami, FL, USA, 6–10 December 2010; pp. 1–5. [Google Scholar]
- Wu, Y.; Wang, B.; Liu, K.J.R.; Clancy, T.C. Anti-Jamming Games in Multi-Channel Cognitive Radio Networks. IEEE J. Sel. Areas Commun. 2012, 30, 4–15. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Song, M.; Xin, C.; Backens, J. A game-theoretical anti-jamming scheme for cognitive radio networks. IEEE Netw. 2013, 27, 22–27. [Google Scholar] [CrossRef]
- Jia, L.; Yao, F.; Sun, Y.; Niu, Y.; Zhu, Y. Bayesian Stackelberg Game for Anti jamming Transmission With Incomplete Information. IEEE Commun. Lett. 2016, 20, 1991–1994. [Google Scholar] [CrossRef]
- Yao, F.; Jia, L.; Sun, Y.; Xu, Y.; Feng, S.; Zhu, Y. A hierarchical learning approach to anti-jamming channel selection strategies. Wirel. Netw. 2019, 25, 201–213. [Google Scholar] [CrossRef]
- Salameh, H.A.B.; Almajali, S.; Ayyash, M.; Elgala, H. Spectrum assignment in cognitive radio networks for internet-of-things delay-sensitive applications under jamming attacks. IEEE Internet Things J. 2018, 5, 1904–1913. [Google Scholar] [CrossRef]
- Wang, X.; Wang, J.; Xu, Y.; Chen, J.; Jia, L.; Liu, X.; Yang, Y. Dynamic Spectrum Anti-Jamming Communications: Challenges and Opportunities. IEEE Commun. Mag. 2020, 58, 79–85. [Google Scholar] [CrossRef]
- Li, Y.; Xu, Y.; Liu, X. Dynamic Spectrum Anti-jamming in Broadband Communications: A Hierarchical Deep Reinforcement Learning Approach. IEEE Wirel. Commun. Lett. 2020, 9, 1616–1619. [Google Scholar] [CrossRef]
- Xiao, L.; Li, Y.; Dai, C.; Dai, H.; Poor, H.V. Reinforcement learning-based NOMA power allocation in the presence of smart jamming. IEEE Trans. Veh. Technol. 2017, 67, 3377–3389. [Google Scholar] [CrossRef]
- Pu, Z.; Niu, Y.; Zhang, G. A Multi-Parameter Intelligent Communication Anti-Jamming Method Based on Three-Dimensional Q-Learning. In Proceedings of the 2022 IEEE 2nd International Conference on Computer Communication and Artificial Intelligence (CCAI), Beijing, China, 6–8 May 2022; pp. 205–210. [Google Scholar]
- Zhang, G.; Li, Y.; Jia, L.; Niu, Y.; Zhou, Q.; Pu, Z. Collaborative Anti-jamming Algorithm Based on Q-learning in Wireless Communication Network. In Proceedings of the 2022 IEEE 2nd International Conference on Computer Communication and Artificial Intelligence (CCAI), Beijing, China, 6–8 May 2022; pp. 222–226. [Google Scholar]
- Geng, S.; Li, P.; Yin, X.; Lu, H.; Zhu, R.; Cao, W.; Nie, J. The Study on Anti-Jamming Power Control Strategy Based on Q-learning. In Proceedings of the 2022 7th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 15–17 April 2022; pp. 182–185. [Google Scholar]
- Zhou, Q.; Li, Y.; Niu, Y.; Qin, Z.; Zhao, L.; Wang, J. One Plus One is Greater Than Two”: Defeating Intelligent Dynamic Jamming with Collaborative Multi-agent Reinforcement Learning. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications(ICCC), Chengdu, China, 11–14 December 2020; pp. 1522–1526. [Google Scholar]
- Zhang, F.; Gong, A.; Deng, L.; Liu, F.; Lin, Y.; Zhang, Y. Wireless Downlink Scheduling with Deadline Constraint for Realistic Channel Observation Environment. Comput. Sci. 2021, 48, 7. [Google Scholar]
- Zhou, Q.; Li, Y.; Niu, Y. A Countermeasure Against Random Pulse Jamming in Time Domain Based on Reinforcement Learning. IEEE Access 2020, 8, 97164–97174. [Google Scholar] [CrossRef]
- Kay, S.M. Fundamentals of Statistical Signal Processing; Volume II: Detection Theory; PTR Prentice-Hall: Hoboken, NJ, USA, 1998. [Google Scholar]
- Yih-Shen, C.; Chung-Ju, C.; Fang-Chin, R. Q-learning-based multi-rate transmission control scheme for RRM in multimedia WCDMA systems. IEEE Trans. Veh. Technol. 2004, 53, 38–48. [Google Scholar]
- Wang, W.; Kwasinski, A.; Niyato, D.; Han, Z. A Survey on Applications of Model-Free Strategy Learning in Cognitive Wireless Networks. IEEE Commun. Surv. Tutor. 2016, 18, 1717–1757. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, Z.; Niu, Y.; Xiang, P.; Zhang, G. Sightless but Not Blind: A Non-Ideal Spectrum Sensing Algorithm Countering Intelligent Jamming for Wireless Communication. Electronics 2022, 11, 3402. https://doi.org/10.3390/electronics11203402
Pu Z, Niu Y, Xiang P, Zhang G. Sightless but Not Blind: A Non-Ideal Spectrum Sensing Algorithm Countering Intelligent Jamming for Wireless Communication. Electronics. 2022; 11(20):3402. https://doi.org/10.3390/electronics11203402
Chicago/Turabian StylePu, Ziming, Yingtao Niu, Peng Xiang, and Guoliang Zhang. 2022. "Sightless but Not Blind: A Non-Ideal Spectrum Sensing Algorithm Countering Intelligent Jamming for Wireless Communication" Electronics 11, no. 20: 3402. https://doi.org/10.3390/electronics11203402
APA StylePu, Z., Niu, Y., Xiang, P., & Zhang, G. (2022). Sightless but Not Blind: A Non-Ideal Spectrum Sensing Algorithm Countering Intelligent Jamming for Wireless Communication. Electronics, 11(20), 3402. https://doi.org/10.3390/electronics11203402