



Adaptive Kernel Density Estimation for Traffic Accidents Based on Improved Bandwidth Research on Black Spot Identification Model

Abstract
1. Introduction
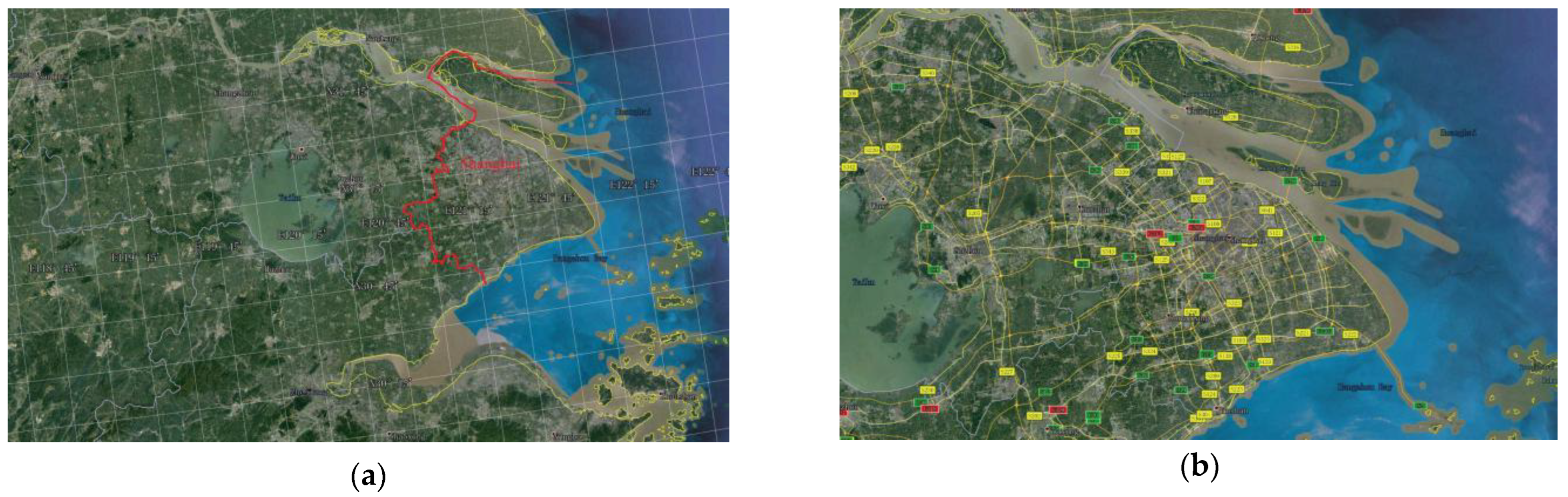
2. Study Area and Data Collection
3. Recognition Methods
3.1. Adaptive Kernel Density Estimation
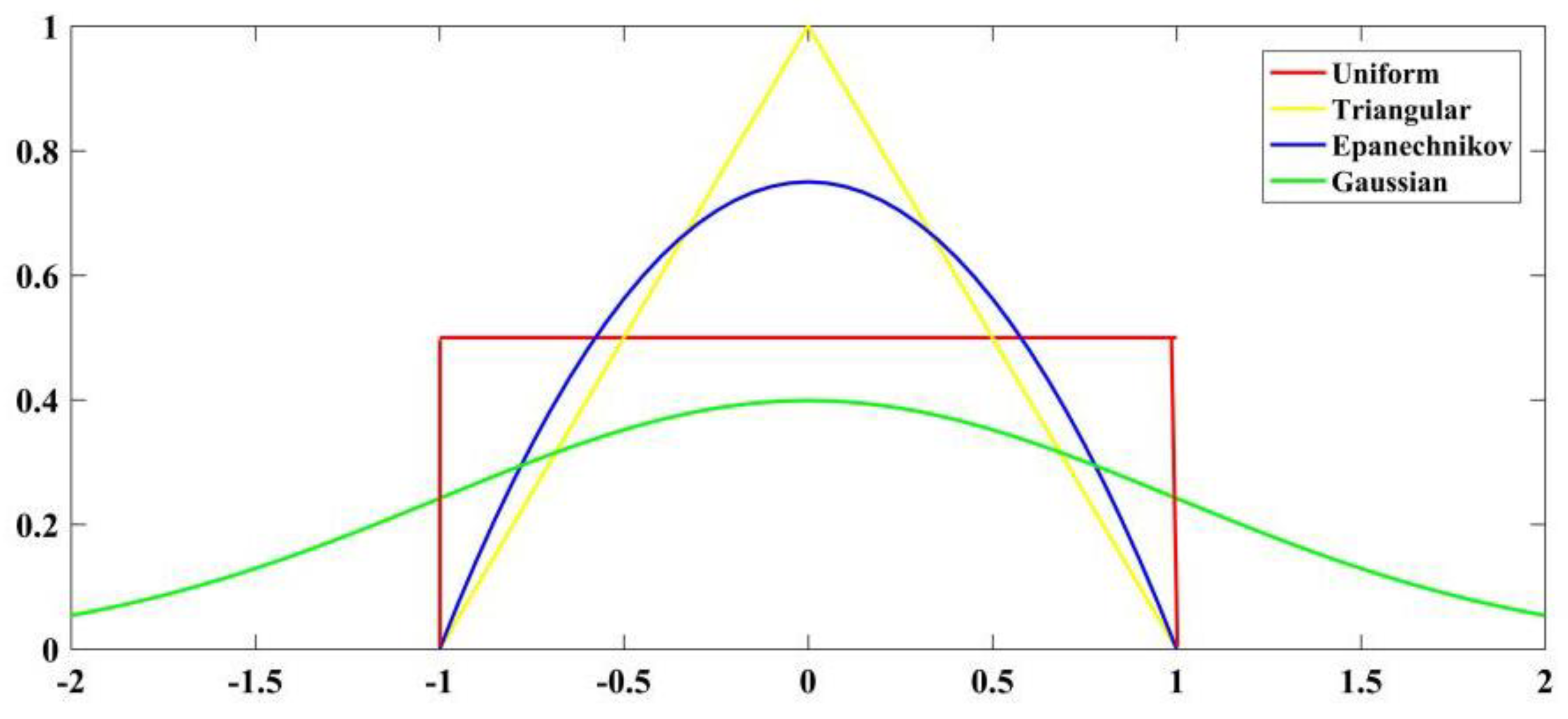
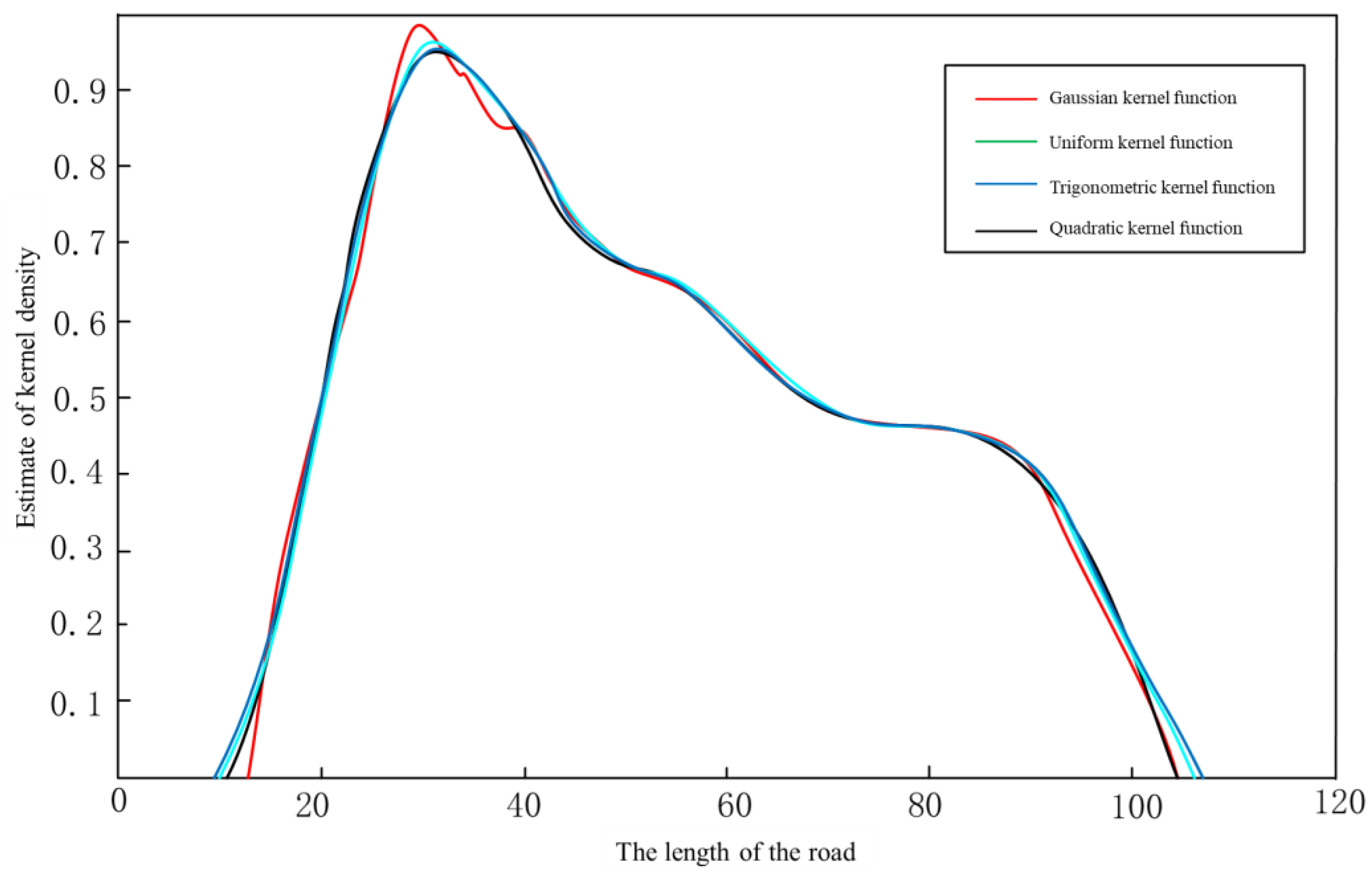
3.2. Kernel Function Selection
3.3. Calculation of Adaptive Bandwidth
3.4. Road Hazard Index
4. Result Analysis
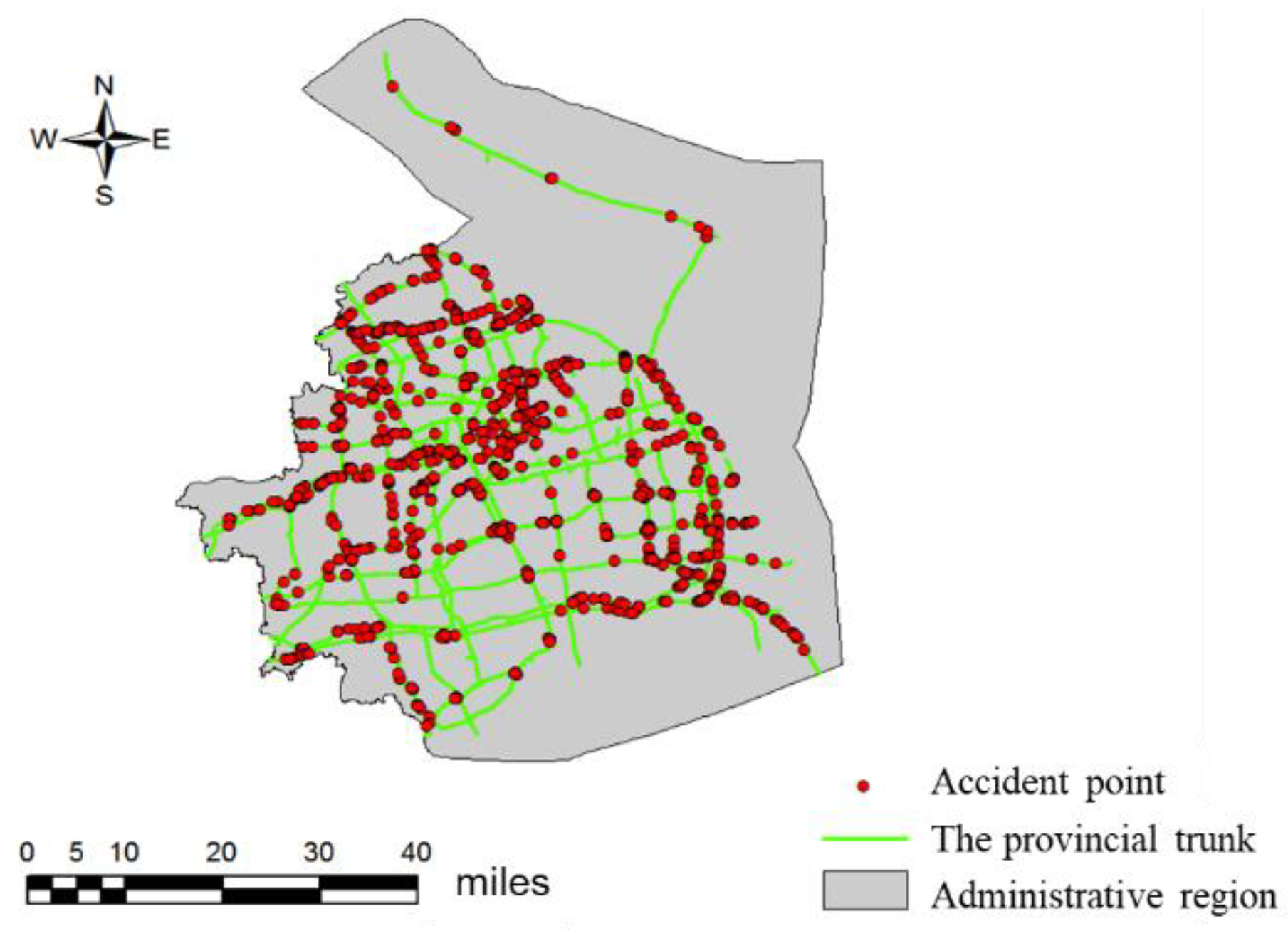
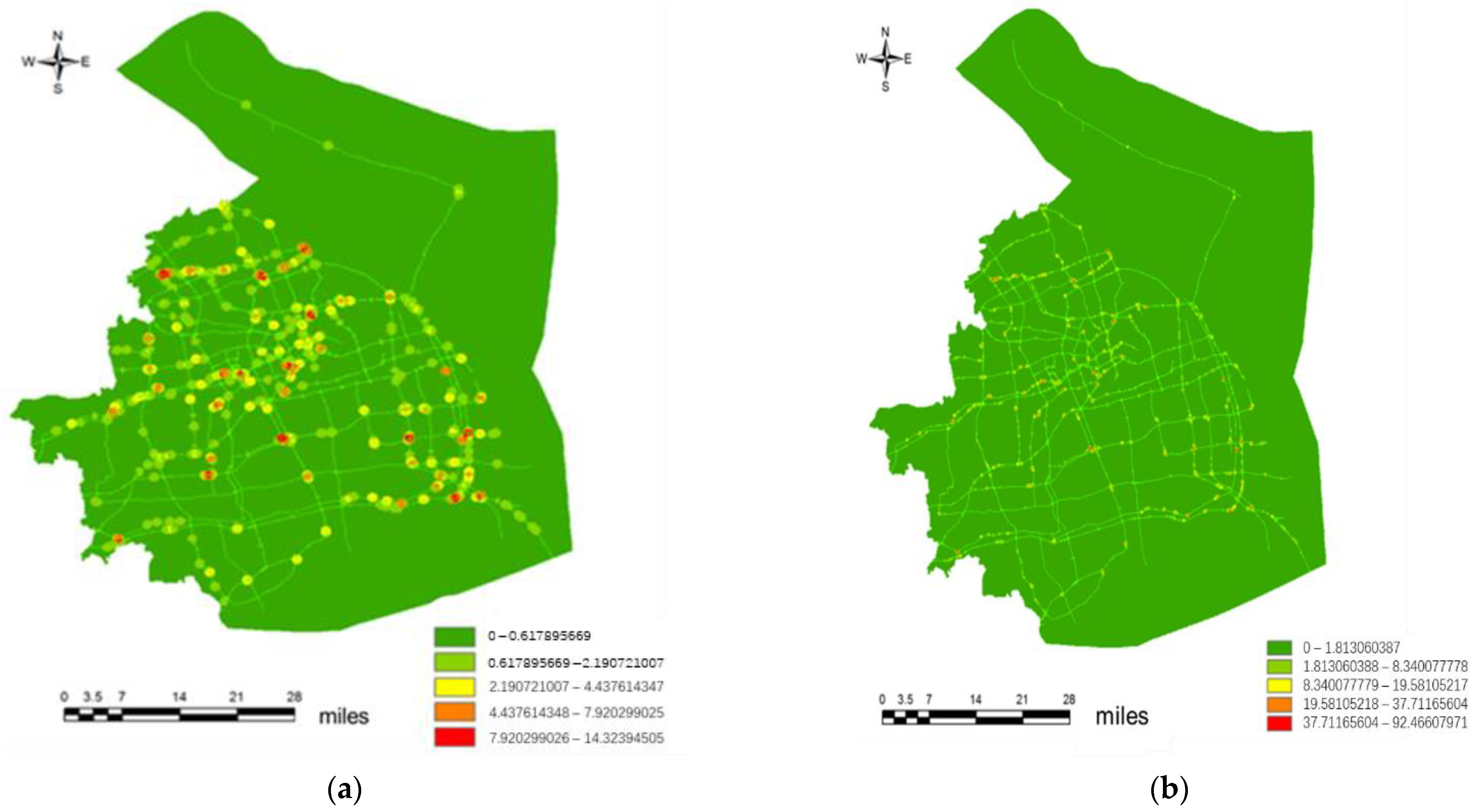
4.1. Black Spot Recognition in Traffic Accidents
4.2. Method Comparison
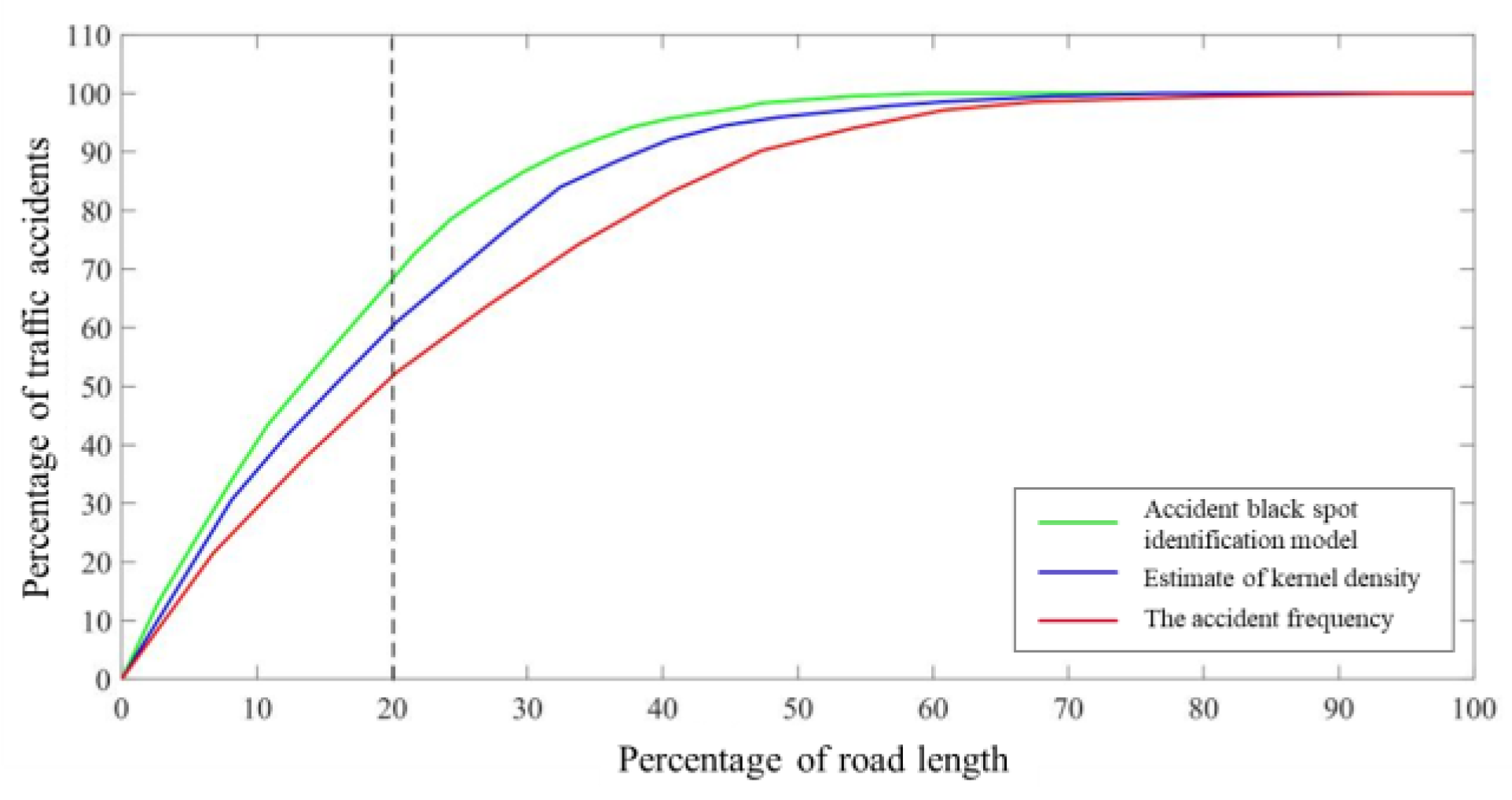
4.3. Method Testing and Evaluation
4.3.1. Accuracy Test
4.3.2. Evaluation of Identification Methods
5. Conclusions
- (1)
- General
- Through the collection and analysis of traffic accident data on Shanghai’s national and provincial trunk lines, a method for identifying black spots in traffic accidents based on improved bandwidth adaptive kernel density estimation was proposed and road hazard indexes were added as identification parameters to construct traffic accident black spot recognition model. On this basis, using ArcGIS software, the black spot recognition results were compared with the accident frequency method and the nuclear density estimation method, and it is concluded that the adaptive nuclear density estimation method had the highest degree of clustering.
- Using CPAI and RRMCLI to verify and evaluate the effectiveness of the three identification methods, it is concluded that the CPAI of the adaptive nuclear density estimation method was 18.25, which was higher than the accident frequency method and the nuclear density estimation. At the same time, considering the safety improvement budget of 20% of road length, the adaptive kernel density estimation method could identify about 69% of the number of traffic accidents, which was 1.13 times and 1.27 times of the kernel density estimation method and the accident frequency method, respectively.
- (2)
- Innovation
- (3)
- Deficiencies and Prospects
- The analysis results have reference value for road safety management and control in Shanghai, and can be further applied to the design of road safety improvement schemes. Meanwhile, the proposal and application of the adaptive kernel density estimation method in traffic accident black spots is conducive to the further expansion of black spot identification methods.
- This study only used bandwidth and road hazard index as the main parameters when identifying traffic accident black spots and did not consider that the impact of highway spatial density may be highly related to road network structure and road parameters on accident black spots, such as lane width, road linearity, etc. In addition, the impact of different traffic flows at different sections of the road on the identification of black spots in traffic accidents needs to be further studied.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sadeghi, A.; Farhad, H.; Moghaddam, A.M.; Qazizadeh, M.J. Identification of accident-prone sections in roadways with incomplete and uncertain inspection-based information: A distributed hazard index based on evidential reasoning approach. Reliab. Eng. Syst. Saf. 2018, 178, 278–289. [Google Scholar] [CrossRef]
- Chen, W. Analysis of road sections with frequent traffic accidents. J. Chin. People’s Public Secur. Univ. 2004, 2, 83–88. [Google Scholar]
- Ali, Y.; Zheng, Z.; Haque, M.M. Modelling lane-changing execution behaviour in a connected environment: A grouped random parameters with heterogeneity-in-means approach. Commun. Transp. Res. 2021, 1, 100009. [Google Scholar] [CrossRef]
- Nadimi, N.; Sheikh Hosseini Lori, E. Applying different analytic methods to determine black spots in two-lane highways. J. Transp. Saf. Secur. 2022, 14, 1395–1418. [Google Scholar] [CrossRef]
- Montella, A. A comparative analysis of hotspot identification methods. Accid. Anal. Prev. 2010, 42, 571–581. [Google Scholar] [CrossRef]
- Plug, C.; Xia, J.C.; Caulfield, C. Spatial and temporal visualisation techniques for crash analysis. Accid. Anal. Prev. 2011, 43, 1937–1946. [Google Scholar] [CrossRef]
- Gregoriades, A.; Mouskos, K.C. Black spots identification through a Bayesian Networks quantification of accident risk index. Transp. Res. Part C Emerg. Technol. 2013, 28, 28–43. [Google Scholar] [CrossRef]
- Ambros, J.; Havránek, P.; Valentová, V.; Křivánková, Z.; Striegler, R. Identification of Hazardous Locations in Regional Road Network—Comparison of Reactive and Proactive Approaches. Transp. Res. Procedia 2016, 14, 4209–4217. [Google Scholar] [CrossRef]
- Prieto, F.; Gomez-Deniz, E.; Sarabia, J.M. Modelling road accident blackspots data with the discrete generalized Pareto distribution. Accid. Anal. Prev. 2014, 71, 38–49. [Google Scholar] [CrossRef][Green Version]
- Thomas, I. Spatial data aggregation: Exploratory analysis of road accidents. Accid. Anal. Prev. 1996, 28, 251–264. [Google Scholar] [CrossRef]
- Meng, X.; Zhang, D.; Wu, P. The influence of sliding window length and sliding step length on the identification of accident-prone sections. Transp. Syst. Eng. Inf. 2018, 18, 148–155. [Google Scholar]
- Ghadi, M.; Török, Á. Comparison Different Black Spot Identification Methods. Transp. Res. Procedia 2017, 27, 1105–1112. [Google Scholar] [CrossRef]
- Elyasi, M.R.; Saffarzade, M.; Boroujerdian, A.M. A novel dynamic segmentation model for identification and prioritization of black spots based on the pattern of potential for safety improvement. Transp. Res. Part A Policy Pract. 2016, 91, 346–357. [Google Scholar] [CrossRef]
- Koorey, G. Road Data Aggregation and Sectioning Considerations for Crash Analysis. Transp. Res. Rec. J. Transp. Res. Board 2009, 2103, 61–68. [Google Scholar] [CrossRef]
- Ghadi, M.; Torok, A. A comparative analysis of black spot identification methods and road accident segmentation methods. Accid. Anal. Prev. 2019, 128, 1–7. [Google Scholar] [CrossRef]
- Yao, S.; Loo, B.P.; Yang, B.Z. Traffic collisions in space: Four decades of advancement in applied GIS. Ann. GIS 2016, 22, 1–14. [Google Scholar] [CrossRef]
- Nie, K.; Wang, Z.; Du, Q.; Ren, F.; Tian, Q. A Network-Constrained Integrated Method for Detecting Spatial Cluster and Risk Location of Traffic Crash: A Case Study from Wuhan, China. Sustainability 2015, 7, 2662–2677. [Google Scholar] [CrossRef]
- Harirforoush, H.; Bellalite, L. A new integrated GIS-based analysis to detect hotspots: A case study of the city of Sherbrooke. Accid. Anal. Prev. 2019, 130, 62–74. [Google Scholar] [CrossRef]
- Bíl, M.; Andrášik, R.; Sedoník, J. A detailed spatiotemporal analysis of traffic crash hotspots. Appl. Geogr. 2019, 107, 82–90. [Google Scholar] [CrossRef]
- Flahaut, B.; Mouchart, M.; San Martin, E.; Thomas, I. The local spatial autocorrelation and the kernel method for identifying black zones. A comparative approach. Accid. Anal. Prev. 2003, 35, 991–1004. [Google Scholar] [CrossRef]
- Shafabakhsh, G.A.; Famili, A.; Bahadori, M.S. GIS-based spatial analysis of urban traffic accidents: Case study in Mashhad, Iran. J. Traffic Transp. Eng. 2017, 4, 290–299. [Google Scholar] [CrossRef]
- Kemp, C.D.; Silverman, B.W. Density Estimation for Statistics and Data Analysis. J. R. Stat. Soc. Ser. D 1987, 36, 495. [Google Scholar] [CrossRef]
- Tang, X.; Luo, M. The optimal choice of non-parametric kernel density estimation kernel function. J. Qiannan Teach. Coll. Natl. 2019, 39, 16–19. [Google Scholar]
- Bil, M.; Andrasik, R.; Janoska, Z. Identification of hazardous road locations of traffic accidents by means of kernel density estimation and cluster significance evaluation. Accid. Anal. Prev. 2013, 55, 265–273. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y. Identification and Cause Analysis of Black Spots in Mountain Expressway Accidents; Chang’an University: Xi’an, China, 2017. [Google Scholar]
- Thakali, L.; Kwon, T.J.; Fu, L. Identification of crash hotspots using kernel density estimation and kriging methods: A comparison. J. Mod. Transp. 2015, 23, 93–106. [Google Scholar] [CrossRef]
- Ulak, M.B.; Ozguven, E.E.; Vanli, O.A.; Horner, M.W. Exploring alternative spatial weights to detect crash hotspots—ScienceDirect. Comput. Environ. Urban Syst. 2019, 78, 101398. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Total Number of Accidents | Number of Injured | Death Toll | Direct Economic Loss [Yuan] | Injury Rate | Mortality Rate |
|---|---|---|---|---|---|---|
| 2017 | 864 | 290 | 59 | 1,867,883 | 0.336 | 0.068 |
| 2018 | 618 | 101 | 29 | 492,473 | 0.163 | 0.047 |
| 2019 | 550 | 86 | 20 | 432,560 | 0.156 | 0.036 |
| Total | 2031 | 477 | 108 | 2,792,916 | 0.235 | 0.053 |
| Administrative District | Total Number of Accidents | Number of Injured | Death Toll | Direct Economic Loss [Yuan] | Injury Rate | Mortality Rate |
|---|---|---|---|---|---|---|
| Baoshan District | 177 | 47 | 12 | 54,600 | 0.266 | 0.068 |
| Chongming District | 41 | 4 | 0 | 23,500 | 0.096 | 0 |
| Fengxian District | 183 | 41 | 4 | 315,800 | 0.224 | 0.022 |
| Hongkou Distric | 25 | 5 | 0 | 4600 | 0.200 | 0 |
| Huangpu District | 44 | 18 | 9 | 110,000 | 0.409 | 0.205 |
| Jiading District | 170 | 38 | 10 | 192,700 | 0.224 | 0.059 |
| Jingshan District | 124 | 17 | 1 | 33,000 | 0.137 | 0.008 |
| Jingan District | 53 | 7 | 4 | 7000 | 0.132 | 0.075 |
| Minhang District | 189 | 54 | 6 | 347,900 | 0.286 | 0.032 |
| Pudong New Area | 420 | 113 | 28 | 1,218,535 | 0.269 | 0.067 |
| Putuo District | 36 | 13 | 4 | 8381 | 0.361 | 0.111 |
| Qingpu District | 248 | 35 | 8 | 164,700 | 0.141 | 0.0322 |
| Songjiang District | 154 | 53 | 19 | 238,700 | 0.344 | 0.123 |
| Xuhui District | 100 | 16 | 0 | 13,500 | 0.16 | 0 |
| Yangpu District | 43 | 9 | 0 | 4400 | 0.209 | 0 |
| Changning District | 24 | 7 | 3 | 16,000 | 0.292 | 0.125 |
| Kernel Functions | Expressions |
|---|---|
| Uniform | |
| Gaussian | |
| Triangular | |
| Epanechnikov |
| Serial Number | Adaptive Kernel Density Estimation | Kernel Density Estimation | Accident Frequency Method | |
|---|---|---|---|---|
| Section Length [m] | Kernel Density Estimate | Kernel Density Estimate | Density Value | |
| 1 | 226 | 189.36 | 176.96 | 173.62 |
| 2 | 214 | 176.91 | 172.34 | 161.45 |
| 3 | 249 | 162.43 | 160.59 | 143.78 |
| 4 | 152 | 134.61 | 113.21 | 101.48 |
| 5 | 106 | 109.28 | 90.36 | 86.43 |
| 6 | 83 | 102.83 | 83.47 | 64.81 |
| Method | Traffic Accident on the Black Spot | Total Traffic Accident | Length of Black Spots | Total Road Length | CPAI |
|---|---|---|---|---|---|
| Accident frequency method | 408 | 1947 | 184.68 | 2657 | 14.39 |
| Kernel density estimation | 471 | 1947 | 162.45 | 2657 | 16.36 |
| Black spot recognition model | 514 | 1947 | 145.57 | 2657 | 18.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, H.; Dong, L.; Huang, M.; Zang, W.; Zhou, L. Adaptive Kernel Density Estimation for Traffic Accidents Based on Improved Bandwidth Research on Black Spot Identification Model. Electronics 2022, 11, 3604. https://doi.org/10.3390/electronics11213604
Ge H, Dong L, Huang M, Zang W, Zhou L. Adaptive Kernel Density Estimation for Traffic Accidents Based on Improved Bandwidth Research on Black Spot Identification Model. Electronics. 2022; 11(21):3604. https://doi.org/10.3390/electronics11213604
Chicago/Turabian StyleGe, Huimin, Lei Dong, Mingyue Huang, Wenkai Zang, and Lijun Zhou. 2022. "Adaptive Kernel Density Estimation for Traffic Accidents Based on Improved Bandwidth Research on Black Spot Identification Model" Electronics 11, no. 21: 3604. https://doi.org/10.3390/electronics11213604
APA StyleGe, H., Dong, L., Huang, M., Zang, W., & Zhou, L. (2022). Adaptive Kernel Density Estimation for Traffic Accidents Based on Improved Bandwidth Research on Black Spot Identification Model. Electronics, 11(21), 3604. https://doi.org/10.3390/electronics11213604