


Developing Cross-Domain Host-Based Intrusion Detection


Abstract
:1. Introduction
- Design and development of a method for HIDS domain similarity score measurement
- Design and development of an approach for selection of candidate source domain to work with a given HIDS target domain
- Implementation of new cross-domain approaches for Host-Based Intrusion Detection.
- Alleviating the pains of zero-day attacks against host infrastructures.
2. Background
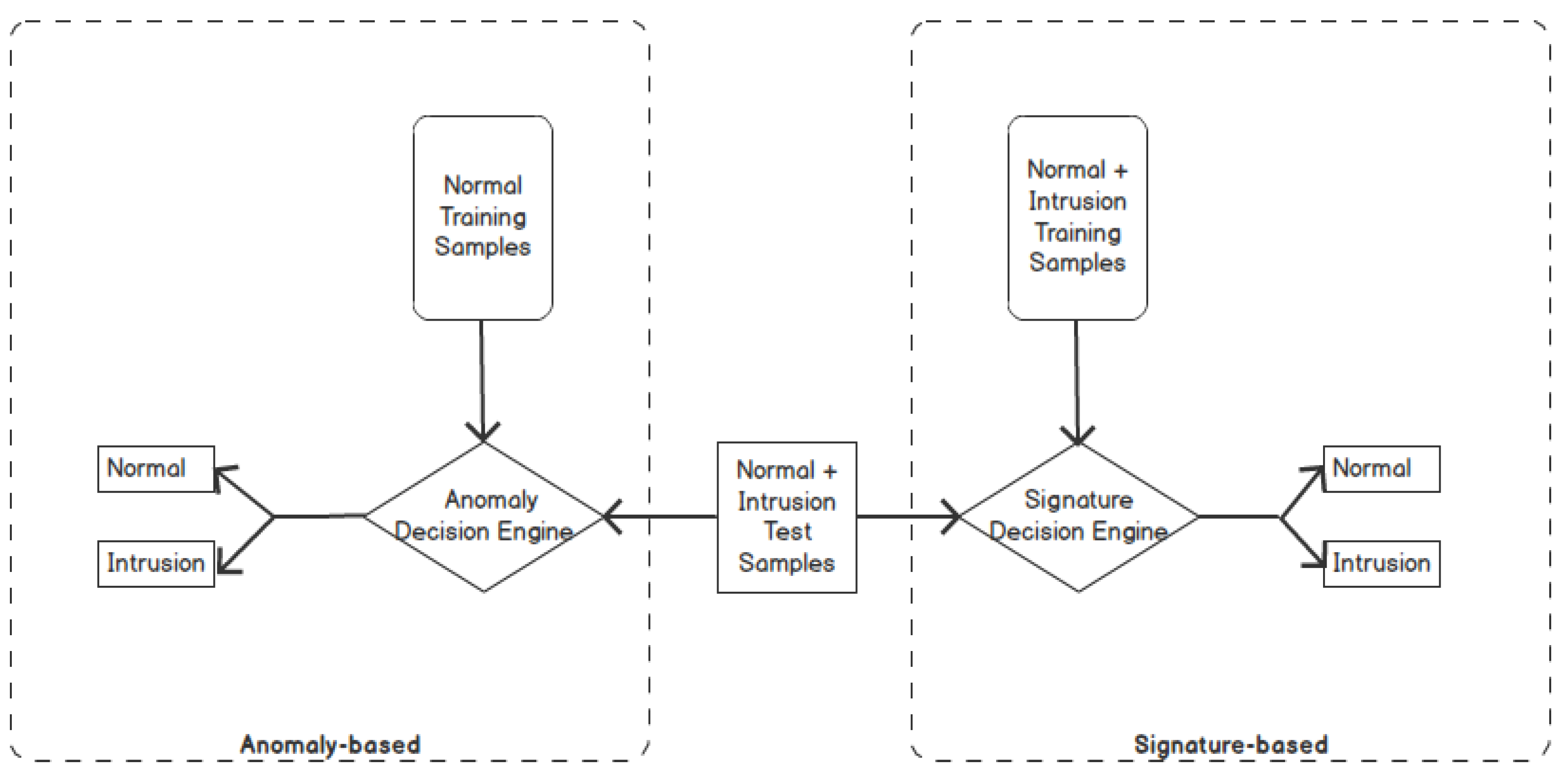
2.1. Intrusion Detection Approaches
2.1.1. Signature-Based Detection
2.1.2. Anomaly-Based Detection
2.1.3. Hybrid Detection
2.2. Intrusion Detection Data Sources
2.2.1. Network Intrusion Detection Systems
2.2.2. Host-Based Intrusion Detection Systems
2.3. IDS Datasets
3. Related Work
3.1. In-Domain Approaches for Intrusion Detection
3.2. Transfer Learning Approaches for Intrusion Detection
4. Proposed Method
4.1. Problem Setting
- Source domain selection.
- Improving the performance of the target domain by leveraging the selected source domain.
4.2. Source Domain Selection
4.2.1. In-Domain Models
4.2.2. Domain Similarity Score Computation
| Algorithm 1 Domain Similarity Score Process |
input: } output: S (a new matrix)
|
4.3. Target Domain Improvement
| Algorithm 2 Unique Token List |
input: } output:
|
- Model Embedding Layer (Src_Emb): Here, the embedding layer of model is simply replaced with the embedding layer of model and frozen (Algorithm 3) so the weights of the embedding layer are not adjusted during fine-tuning. The model then is fine-tuned using the train portion of data.
| Algorithm 3 Model Embedding Layer (Src_Emb) |
input: output:
|
- Domain Independent Tokens of Embedding Layer (DIT_Src_Emb): In the previous technique, our assumption was that the representation of domain independent (DI) tokens in the model embedding layer is so strong that the unoptimized domain specific (DS) tokens will not matter. This assumption can be true for situations where has a much greater number of DI tokens than DS tokens. In situations where this is not the case, it may be better to retain the representation of the DS tokens in model. This technique addresses such situation by only replacing the DI tokens representation in model embedding with DI tokens representation in model embedding (Algorithm 4). As with the previous technique, the derived embedding layer is frozen and model is fine-tuned using the train portion of data.
| Algorithm 4 Domain Independent Tokens of Embedding Layer (DIT_Src_Emb) |
input: output:
|
- Combination of Embedding Layers using PCA (Comb_PCA): One of their methods for fusing word embeddings in [55] involved concatenating embedding layers and using principal component analysis (PCA) to reduce the dimension of the derived embedding layer. We adopt the same approach here but only apply this to the DI tokens. DS tokens in model are retained (Algorithm 5). Again the derived embedding layer is frozen and model is fine-tuned using the train portion of data.
| Algorithm 5 Combination of Embedding Layers using PCA (Comb_PCA) |
input: output:
|
5. Experimental Results and Analysis
5.1. Datasets
5.2. Performance Metric
5.3. In-Domain Models
- Embedding dimension: 32
- Sequence Maximum Length: third quartile of the domain sequence length
- number of 1D-CNN layers: 2
- number of dense layers: 2
- MaxPooling1D: 5
- Kernel Size: 3
- batch size: 50
- Number of Epochs: 50
5.4. Similarity Score
5.5. Target Domain Improvement
6. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Snabe Hagemann, J.; Weinelt, B. Digital Transformation of Industries: Demystifying Digital and Securing $100 Trillion for Society and Industry by 2025. Available online: https://issuu.com/laszlopacso/docs/wef-digital-transformation-of-indus (accessed on 26 September 2022).
- Zhu, J.; McClave, E.; Pham, Q.; Polineni, S.; Reinhart, S.; Sheatsley, R.; Toth, A. A Vision Toward an Internet of Battlefield Things (IoBT): Autonomous Classifying Sensor Network; Technical Report; US Army Research Laboratory: Adelphi, MD, USA, 2018.
- Narayanan, P.; Vindiola, M.; Park, S.; Logie, A.; Waytowich, N.; Mittrick, M.; Richardson, J.; Asher, D.; Kott, A. First-Year Report of ARL Directors Strategic Initiative (FY20-23): Artificial Intelligence (AI) for Command and Control (C2) of Multi-Domain Operations (MDO); Technical Report; US Army Combat Capabilities Development Command, Army Research Laboratory: Adelphi, MD, USA, 2021.
- Parkavi, R.; Nithya, R.; Priyadharshini, G. Digital Terrorism Attack: Types, Effects, and Prevention. In Critical Concepts, Standards, and Techniques in Cyber Forensics; IGI Global: Hershey, PA, USA, 2020; pp. 61–87. [Google Scholar]
- Morgan, S. 2019 Official Annual Cybercrime Report. Available online: https://cybernetsecurity.com/industry-papers/CV-HG-2019-Official-Annual-Cybercrime-Report.pdf (accessed on 26 September 2022).
- Marelli, M. The SolarWinds hack: Lessons for international humanitarian organizations. Int. Rev. Red Cross 2022, 104, 1–18. [Google Scholar] [CrossRef]
- Crane, C. Cyber Attack Statistics by Year: A Look at the Last Decade, 42. Available online: https://sectigostore.com/blog/42-cyber-attack-statistics-by-year-a-look-at-the-last-decade/ (accessed on 26 September 2022).
- Ponemon, I. Cost of Data Breach Report 2021. Available online: https://www.dataendure.com/wp-content/uploads/2021_Cost_of_a_Data_Breach_-2.pdf (accessed on 26 September 2022).
- Morgan, S. Cybercrime to Cost the World $10.5 Trillion Annually by 2025. Available online: https://cybersecurityventures.com/cybercrime-damage-costs-10-trillion-by-2025/ (accessed on 26 September 2022).
- Hindy, H.; Atkinson, R.; Tachtatzis, C.; Colin, J.N.; Bayne, E.; Bellekens, X. Utilising deep learning techniques for effective zero-day attack detection. Electronics 2020, 9, 1684. [Google Scholar] [CrossRef]
- Modi, C.; Patel, D.; Borisaniya, B.; Patel, H.; Patel, A.; Rajarajan, M. A survey of intrusion detection techniques in cloud. J. Netw. Comput. Appl. 2013, 36, 42–57. [Google Scholar] [CrossRef]
- Mishra, P.; Varadharajan, V.; Tupakula, U.; Pilli, E.S. A detailed investigation and analysis of using machine learning techniques for intrusion detection. IEEE Commun. Surv. Tutorials 2018, 21, 686–728. [Google Scholar] [CrossRef]
- Tidjon, L.N.; Frappier, M.; Mammar, A. Intrusion detection systems: A cross-domain overview. IEEE Commun. Surv. Tutorials 2019, 21, 3639–3681. [Google Scholar] [CrossRef]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 1–22. [Google Scholar] [CrossRef] [Green Version]
- De Boer, P.; Pels, M. Host-Based Intrusion Detection Systems. Available online: https://www.os3.nl/media/2004-2005/rp1/report19.pdf (accessed on 26 September 2022).
- Vigna, G.; Kruegel, C. Host-Based Intrusion Detection System. Available online: https://susy.mdpi.com/user/manuscripts/resubmit/c279999d25191388cc075c6d0cb5ce2a (accessed on 26 September 2022).
- Li, Y.; Xia, J.; Zhang, S.; Yan, J.; Ai, X.; Dai, K. An efficient intrusion detection system based on support vector machines and gradually feature removal method. Expert Syst. Appl. 2012, 39, 424–430. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. Comput. Sci. 2021, 2, 1–21. [Google Scholar] [CrossRef]
- Kim, K.; Aminanto, M.E. Deep learning in intrusion detection perspective: Overview and further challenges. In Proceedings of the 2017 International Workshop on Big Data and Information Security (IWBIS), Jakarta, Indonesia, 23–24 September 2017; pp. 5–10. [Google Scholar]
- Aminanto, E.; Kim, K. Deep learning in intrusion detection system: An overview. In Proceedings of the 2016 International Research Conference on Engineering and Technology (2016 IRCET), Higher Education Forum, Bali, Indonesia, 28–30 June 2016. [Google Scholar]
- Gangopadhyay, A.; Odebode, I.; Yesha, Y. A Domain Adaptation Technique for Deep Learning in Cybersecurity. In Proceedings of the OTM Confederated International Conferences “on the Move to Meaningful Internet Systems”, Rhodes, Greece, 21–25 October 2019. [Google Scholar]
- Bleiweiss, A. LSTM Neural Networks for Transfer Learning in Online Moderation of Abuse Context. In Proceedings of the 11th International Conference on Agents and Artificial Intelligence, Prague, Czech Republic, 19–21 February 2019. [Google Scholar]
- Mou, L.; Meng, Z.; Yan, R.; Li, G.; Xu, Y.; Zhang, L.; Jin, Z. How transferable are neural networks in nlp applications? arXiv 2016, arXiv:1603.06111. [Google Scholar]
- Braud, C.; Lacroix, O.; Søgaard, A. Cross-lingual and cross-domain discourse segmentation of entire documents. arXiv 2017, arXiv:1704.04100. [Google Scholar]
- Pan, S.J.; Ni, X.; Sun, J.T.; Yang, Q.; Chen, Z. Cross-domain sentiment classification via spectral feature alignment. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Buczak, A.L.; Guven, E. A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Commun. Surv. Tutorials 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- Kreibich, C.; Crowcroft, J. Honeycomb: Creating intrusion detection signatures using honeypots. Acm Sigcomm Comput. Commun. Rev. 2004, 34, 51–56. [Google Scholar] [CrossRef]
- Cannady, J. Artificial Neural Networks for Misuse Detection. Available online: http://pld.cs.luc.edu/courses/intrusion/fall05/cannady.artificial_neural_networks_for_misuse_detection.pdf (accessed on 26 September 2022).
- Livadas, C.; Walsh, R.; Lapsley, D.; Strayer, W.T. Usilng machine learning technliques to identify botnet traffic. In Proceedings of the 2006 31st IEEE Conference on Local Computer Networks, Tampa, FL, USA, 14–16 November 2006; pp. 967–974. [Google Scholar]
- Kruegel, C.; Toth, T. Using decision trees to improve signature-based intrusion detection. In Proceedings of the International Workshop on Recent Advances in Intrusion Detection, Pittsburgh, PA, USA, 8–10 September 2003; pp. 173–191. [Google Scholar]
- Norton, M.; Roelker, D. Snort 2.0 Rule Optimizer. Sourcefire Netw. Secur. White Pap. Available online: https://www.cs.ucdavis.edu/~wu/ecs236/sf_snort20_detection_rvstd.pdf (accessed on 26 September 2022).
- Gharibian, F.; Ghorbani, A.A. Comparative study of supervised machine learning techniques for intrusion detection. In Proceedings of the Fifth Annual Conference on Communication Networks and Services Research (CNSR’07), Fredericton, NB, Canada, 14–17 May 2007; pp. 350–358. [Google Scholar]
- The Third International Knowledge Discovery and Data Mining Tools Competition Dataset KDD Cup 1999 Data. 1999. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 20 September 2021).
- Kruegel, C.; Mutz, D.; Robertson, W.; Valeur, F. Bayesian event classification for intrusion detection. In Proceedings of the 19th Annual Computer Security Applications Conference, Las Vegas, NV, USA, 8–12 December 2003; pp. 14–23. [Google Scholar]
- Wagner, C.; François, J.; Engel, T.; State, R. Machine learning approach for ip-flow record anomaly detection. In Proceedings of the International Conference on Research in Networking, Valencia, Spain, 9–13 May 2011. [Google Scholar]
- Brauckhoff, D.; Wagner, A.; May, M. FLAME: A Flow-Level Anomaly Modeling Engine. Available online: https://www.usenix.org/legacy/event/cset08/tech/full_papers/brauckhoff/brauckhoff_html/ (accessed on 26 September 2022).
- Zhang, J.; Zulkernine, M.; Haque, A. Random-forests-based network intrusion detection systems. IEEE Trans. Syst. Man Cybern. Part (Appl. Rev.) 2008, 38, 649–659. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, K.; Jing, X.; Jin, H.L. Problems of kdd cup 99 dataset existed and data preprocessing. Appl. Mech. Mater. 2014, 667, 218–225. [Google Scholar] [CrossRef]
- Simon, C.K.; Sochenkov, I.V. Evaluating Host-Based Intrusion Detection on the adfa-wd and ADFA-WD: SAA Datasets. 2021. Available online: Semanticscholar.org (accessed on 20 September 2021).
- Vinayakumar, R.; Alazab, M.; Soman, K.; Poornachandran, P.; Al-Nemrat, A.; Venkatraman, S. Deep learning approach for intelligent intrusion detection system. IEEE Access 2019, 7, 41525–41550. [Google Scholar] [CrossRef]
- Park, D.; Ryu, K.; Shin, D.; Shin, D.; Park, J.; Kim, J. A Comparative Study of Machine Learning Algorithms Using LID-DS DataSet. Kips Trans. Softw. Data Eng. 2021, 10, 91–98. [Google Scholar]
- Xu, Y.; Liu, Z.; Li, Y.; Zheng, Y.; Hou, H.; Gao, M.; Song, Y.; Xin, Y. Intrusion Detection Based on Fusing Deep Neural Networks and Transfer Learning. In Proceedings of the International Forum on Digital TV and Wireless Multimedia Communications, Shanghai, China, 19–20 September 2019. [Google Scholar]
- Divekar, A.; Parekh, M.; Savla, V.; Mishra, R.; Shirole, M. Benchmarking datasets for anomaly-based network intrusion detection: KDD CUP 99 alternatives. In Proceedings of the 2018 IEEE 3rd International Conference on Computing, Communication and Security (ICCCS), Kathmandu, Nepal, 25–27 October 2018; pp. 1–8. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Wu, P.; Guo, H.; Buckland, R. A transfer learning approach for network intrusion detection. In Proceedings of the 2019 IEEE 4th International Conference on Big Data Analytics (ICBDA), Suzhou, China, 15–18 March 2019; pp. 281–285. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Ajayi, O.; Gangopadhyay, A. DAHID: Domain Adaptive Host-based Intrusion Detection. In Proceedings of the 2021 IEEE International Conference on Cyber Security and Resilience (CSR), Rhodes, Greece, 26–28 July 2021; pp. 467–472. [Google Scholar]
- Shilov, A. Microsoft’s Windows XP Finally Dead: Last Embedded Version Reaches EOL. Available online: https://www.anandtech.com/show/14200/microsofts-windows-xp-finally-dead-last-embedded-version-reaches-eol#:~:text=Microsoft’s%20Windows%20XP%20Home%20and,EOL%20on%20January%208%2C%202019 (accessed on 20 September 2021).
- Lobo, J.M.; Jiménez-Valverde, A.; Real, R. AUC: A misleading measure of the performance of predictive distribution models. Glob. Ecol. Biogeogr. 2008, 17, 145–151. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]
- Christian, H.; Agus, M.P.; Suhartono, D. Single document automatic text summarization using term frequency-inverse document frequency (TF-IDF). ComTech Comput. Math. Eng. Appl. 2016, 7, 285–294. [Google Scholar] [CrossRef]
- Xia, P.; Zhang, L.; Li, F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015, 307, 39–52. [Google Scholar] [CrossRef]
- Rettig, L.; Audiffren, J.; Cudré-Mauroux, P. Fusing vector space models for domain-specific applications. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; IEEE; pp. 1110–1117. [Google Scholar]
- Grimmer, M.; Röhling, M.M.; Kreusel, D.; Ganz, S. A modern and sophisticated host based intrusion detection data set. IT-Sicherh. Voraussetzung Eine Erfolgreiche Digit. 2019, pp. 135–145. Available online: https://www.researchgate.net/profile/Martin-Grimmer/publication/357056160_A_Modern_and_Sophisticated_Host_Based_Intrusion_Detection_Data_Set/links/61b9faaf1d88475981f04cb9/A-Modern-and-Sophisticated-Host-Based-Intrusion-Detection-Data-Set.pdf (accessed on 26 September 2022).
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef] [Green Version]
- Park, D.; Kim, S.; Kwon, H.; Shin, D.; Shin, D. Host-Based Intrusion Detection Model Using Siamese Network. IEEE Access 2021, 9, 76614–76623. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year Created | Dataset | Operating System | Provider |
|---|---|---|---|
| 1999 | KDD | Solaris BSM | Massachusetts Institute of Technology |
| 2006 | UNM | SunOS | University of New Mexico |
| 2013 | ADFA-LD | Linux | University of New South Wales |
| 2014 | ADFA-WD | Windows | University of New South Wales |
| 2017 | NGIDS-DS | Linux | University of New South Wales |
| 2019 | LID-DS | Linux | Leipzig University |
| Attack Scenario | CVE/CWE | Benign | Attack |
|---|---|---|---|
| Heartbleed | CVE-2014-0160 | 1000 | 100 |
| PHP file upload: unrestricted upload of file with dangerous type | CWE-434 | 1009 | 103 |
| Bruteforce login: improper restriction of excessive authentication attempts | CWE-307 | 994 | 98 |
| SQL injection with sqlmap | CWE-89 | 978 | 100 |
| ZipSlip | various | 1000 | 100 |
| EPS file upload: unrestricted upload of file with dangerous type | CWE-434 | 972 | 99 |
| MySQL authentification bypass | CVE-2012-2122 | 1240 | 155 |
| Nginx integer overflow vulnerability | CVE-2017-7952 | 983 | 174 |
| Sprockets information leak vulnerability | CVE-2018-3760 | 1084 | 137 |
| Rails file content disclosure vulnerability | CVE-2019-5418 | 981 | 98 |
| Test Set | Precision | Recall | F2-Score |
|---|---|---|---|
| CWE_307 | 0.48 | 0.96 | 0.8 |
| CVE_2012 | 1.00 | 1.00 | 1.00 |
| CVE_2014 | 0.21 | 0.12 | 0.13 |
| CVE_2017 | 1.00 | 1.00 | 1.00 |
| CVE_2018 | 1.00 | 1.00 | 1.00 |
| CVE_2019 | 1.00 | 1.00 | 1.00 |
| PHP_CWE | 1.00 | 0.96 | 0.97 |
| CWE_89 | 1.00 | 1.00 | 1.00 |
| EPS_CWE | 1.00 | 1.00 | 1.00 |
| LID | 0.96 | 0.91 | 0.92 |
| Scenarios | CWE_307 | CVE_2012 | CVE_2014 | CVE_2017 | CVE_2018 | CVE_2019 | EPS_CWE | PHP_CWE | CWE_89 |
|---|---|---|---|---|---|---|---|---|---|
| CWE_307 | 1 | 0.431 | 0.935 | 0.328 | 0.056 | 0.058 | 0.564 | 0.379 | 0.373 |
| CVE_2012 | 1 | 0.311 | 0.050 | 0.093 | 0.100 | 0.346 | 0.366 | 0.369 | |
| CVE_2014 | 1 | 0.323 | 0.052 | 0.054 | 0.479 | 0.439 | 0.426 | ||
| CVE_2017 | 1 | 0.038 | 0.037 | 0.187 | 0.169 | 0.173 | |||
| CVE_2018 | 1 | 1.000 | 0.052 | 0.042 | 0.041 | ||||
| CVE_2019 | 1 | 0.054 | 0.046 | 0.045 | |||||
| EPS_CWE | 1 | 0.138 | 0.133 | ||||||
| PHP_CWE | 1 | 0.998 | |||||||
| CWE_89 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ajayi, O.; Gangopadhyay, A.; Erbacher, R.F.; Bursat, C. Developing Cross-Domain Host-Based Intrusion Detection. Electronics 2022, 11, 3631. https://doi.org/10.3390/electronics11213631
Ajayi O, Gangopadhyay A, Erbacher RF, Bursat C. Developing Cross-Domain Host-Based Intrusion Detection. Electronics. 2022; 11(21):3631. https://doi.org/10.3390/electronics11213631
Chicago/Turabian StyleAjayi, Oluwagbemiga, Aryya Gangopadhyay, Robert F. Erbacher, and Carl Bursat. 2022. "Developing Cross-Domain Host-Based Intrusion Detection" Electronics 11, no. 21: 3631. https://doi.org/10.3390/electronics11213631
APA StyleAjayi, O., Gangopadhyay, A., Erbacher, R. F., & Bursat, C. (2022). Developing Cross-Domain Host-Based Intrusion Detection. Electronics, 11(21), 3631. https://doi.org/10.3390/electronics11213631