2.2. Methods
In the video, the 2D skeleton information is first extracted, then the 2D skeleton information is converted into 3D skeleton information, and then the 3D information is used as the input of the algorithm model for action recognition. The 2D attitude estimation algorithm uses the RMPE algorithm, which belongs to the top-down attitude estimation method and is an improvement of the SPPE algorithm to solve the problem of inaccurate and redundant detection frame positions [
21]. It is divided into three steps: human frame detection, human pose estimation, and non-maximum suppression (
Figure 3). The first step is to normalize the input image using the YOLO.v3 algorithm, then divide the dimensions into several grids, and then use multiple priority boxes for each grid and find multidimensional attributes for each box. During this process, the detected human frame may be incorrect [
22]. The second step mainly solves the problem of inaccurate detection frames. The results of the previous step are input into two parallel attitude estimation branches. The upper branch modifies the original detection framework through STN to maximize the effect of SPPE evaluation. However, there are errors in this step. The inverse transform parameters are calculated, and the predicted human pose is mapped into the original detection frame. During training, the lower branch ParallelSPPE acts as a regular corrector to avoid local optimization. The pose evaluation results are compared with the indicated actual pose, and the center position error is sent back to the STN module to improve the accuracy of the SDN module selection. The third step is to solve the detection frame redundancy problem. The pose estimation results are input into the PoseNMS module, which outputs 2D coordinates of human key points by comparing the similarity of human poses. The fourth step is to convert 2D coordinates into 3D coordinates. For the output 2D coordinates, this paper uses the VideoPoSe3D algorithm mentioned in
Section 2.1 to convert them into 3D coordinates [
23]. The algorithm uses a fully convolutional network to perform time-domain convolution on the input 2D keypoint sequence to obtain a 3D keypoint sequence. With multiple residual modules and rapidly increasing dilated convolution factors, the field of view can be extended to the entire input array and ultimately to the 3D integrated frame array output.
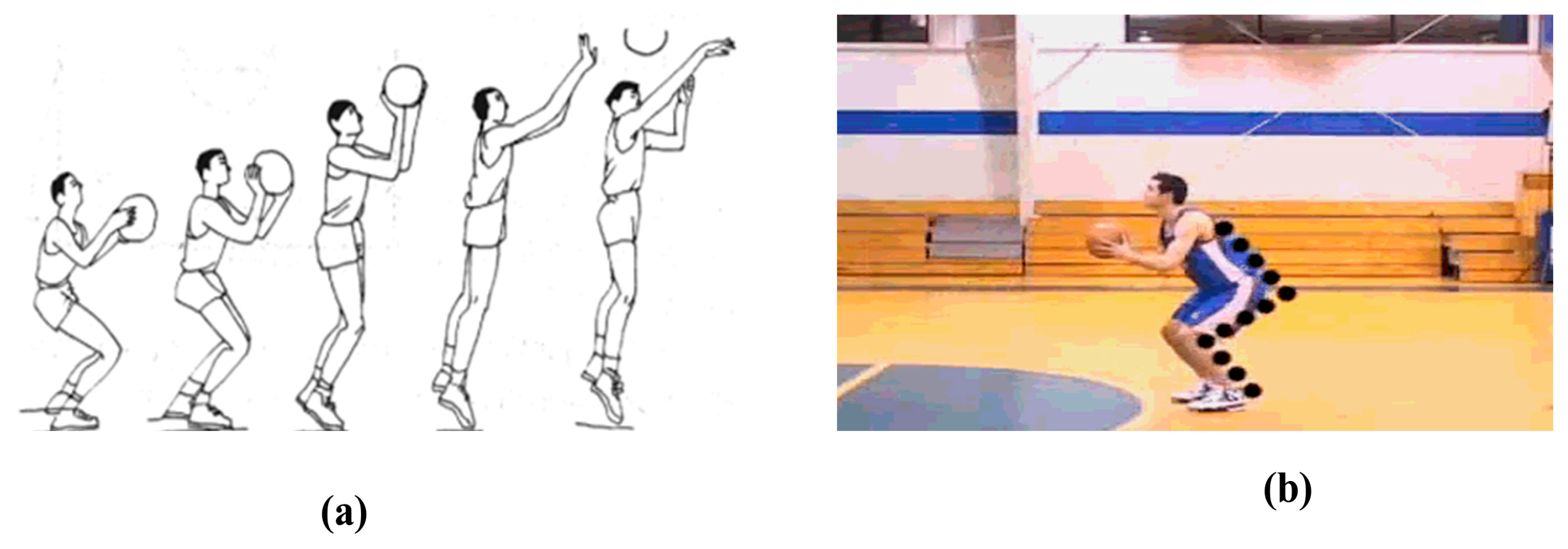
The biggest problem encountered by 3D motion recognition is that the recognition efficiency is not high due to the interference of the environment. For the recognition of 2D images, the method processes hundreds of pixels of each image in real time to extract features, which is expensive to calculate, and the scene noise will affect the recognition accuracy. The input source of 3D motion recognition is RGBD video, in which the depth data have no color information, so the color of the subjects’ clothes and the chaotic scene have no impact on the segmentation process. This allows researchers to focus more on obtaining robust feature descriptors to describe actions, rather than on low-level segmentation. Therefore, this paper introduces the deep learning method in basketball training, which can assist in training and improve the scoring rate.
The key points of the human body are acquired in the video or collected by the camera. Due to different shooting angles, background environments, etc., the data are very different. Therefore, it is necessary to preprocess the keypoint sequence data, including coordinate transformation and normalization operations. In order to conform to the human body movement logic, this paper establishes the coordinate system of the human body movement direction, standing direction, and ground direction and maps all coordinates to this coordinate system [
24]. According to computer graphics, the modification of the integrated system includes printing the rotation and translation functions, and the transformation of the coordinate system includes the rotation and translation operations around the axis. For point
, point
is post-revised. There is a mapping relationship shown in Equation (1).
where
is a rotation variable and
is a translation variable. First, the neck node of the human body is taken as the origin, the two shoulder lines are taken as the
x-axis direction, and the
y-axis is established according to the right-hand coordination method. At this time, the
y-axis is the vertical direction of the human body (
Figure 4). By translating the appearance of the
y-axis, the body coordinates fall on the positive semi-axis of this axis, and the
z-axis is the frame, which is the movement direction of the body’s center point on the first frame, and the coordinates after the last frame are mapped. Normalization is measuring data graphically equally within a given interval. When normalizing keypoint data, this worksheet selects the positive maximum value of the
y-axis as the person’s height and normalizes it to 1, and then measures other data in equal proportions, with all coordinates in the range of [0, 1].
This paper studies the spatiotemporal graph convolutional neural network model (ST-GCN), which designs a general representation of skeleton sequences for action recognition. The model is based on a series of skeletal graphs, where each node corresponds to a joint of the human body. There are two types of edges: temporary edges that connect the same joint to a natural joint of the joint and edges that extend the space between successive joints. Based on this, a multilayer transformation for temporal graphs is constructed to capture the information integration in the spatiotemporal dimension.
The spatiotemporal graph convolution can be obtained by corresponding connections of the same important points in normal frames on temporal edges. As such, it has a permanent structure that can be changed through steps such as spatiotemporal transformations. For frame V, each frame has keypoint D and channel C, and each row shows the location of the main point at different times. If the length of each transition is 1, once the node is changed once, the switching center point of the main frame will contain a total of K frames before and after it, and the size of the agreed kernel is K*1. The structure of the algorithm is shown in
Figure 5, and the network is divided into three parts. The first part adjusts the input matrix, i.e., the coordinates of the joints in different frames. The second part strengthens the ST-GCN structure. In ST-GCN, it is used to measure the edge weight of different parts of the human body. The changes in the figure show the local spatial functions in the edge of the layer frame and the temporal function in the edge of the transition layer. The third part uses the average pooling layer and the whole link layer to classify the elements and print the classification results [
25].
Traditional skeleton recognition uses convolutions to identify bone motion to concatenate the coordinate vectors of all joints to create an aspect ratio vector for each frame. We use spatiotemporal graphs to represent skeleton sequences. In particular, the undirected spatiotemporal graph
G = (
V,
E) is constructed in skeletal order, with
N joints and
T frames. Node set
contains all joints in the skeleton sequence. In the input of ST-GCN, the coordinate system of the length and width vector on the node
is composed of the
ith joint coordinate vector and the rated confidence of
t. This paper uses two steps to create a spatiotemporal map of the skeleton sequence. First, according to the connection of the human body structure, the joints are attached to the frame with the edges. In a continuous integration system, each joint is connected to a single joint. Thus, the connections in this system are naturally defined without excluding the individual parts [
26]. This enables network configurations to handle datasets with varying numbers of nodes or connections.
The definition of the transformation process in a 2D image or feature map is considered as a 2D grid. The output feature map of the transformation process is also a 2D grid. Given a convolution operator with kernel size KXK, the output value of a channel in spatial location
x can be written as follows:
where
p is a sampling function centered on the center, which represents the neighborhood of position
x;
: Z2 →
Rc is a weight function. The inner product is calculated by the weight vector of the C-dimensional space. In graph convolution, the sampling function and weighting function need to be redefined. The sampling function
P(
x,
h,
w) is defined on adjacent pixels relative to the center position
x:
, and
is the minimum length of any path from
to
. The mapping
ltj maps nodes in the neighborhood set to labels, and the weight function can be expressed as follows:
Using the improved sampling function and weight function, Formula (2) is now rewritten in the form of graph convolution as follows:
The result of normalization is
, and this term is used to balance a subset of outputs with different contributions. Finally, we can obtain the following:
After the spatial graph CNN is established, the task of modeling the spatial and temporal dynamics within the skeleton sequence begins. Starting in the modeling space, temporal dynamics are worked on in skeleton order. Note that in the construction of the map, the timing aspects of the map are constructed by connecting the same joints between consecutive frames. Spatial graphs can define a much simpler strategy for extending CNNs to the spatiotemporal domain. In other words, the concept of the neighborhood is extended to include temporarily connected joints:
where parameter
controls the time limit included in the neighbor map, so it can be called the time kernel size. In order to complete the transformation process on the spatiotemporal graph, the model function (equivalent to the spatial condition) and the weight function are required:
This method is a simple and straightforward sharing strategy. In this strategy, (1) the aspect vector on each adjacent node has an inner product with the same weight vector; (2) distance division, the distance part is the distance of the adjacent part set at the distance from the tip to the root node; (3) spatial division, since the human skeleton is spatial, the subset is specifically divided into the root node itself, the centripetal group, and the centrifugal subset. The single-label partitioning performs simple feature averaging before the convolution operation, so the performance is poor, and the multi-subset partitioning strategy solves this problem; meanwhile, in the multi-subset partitioning strategy, the spatial configuration partition has better performance. Therefore, this paper uses spatially configured partitions and considers concentric and eccentric motion patterns.
In action recognition, the evaluation metrics used by 2D-based pose methods are the percentage of correctly estimated body parts (PCP) and
mAP. PCP selects limb length as a benchmark to evaluate the detection accuracy of the head, torso, upper arm, lower arm, thigh, and calf. PCK chooses the normalized distance as the benchmark to evaluate the detection accuracy of seven joints, namely head, shoulder, elbow, wrist, hip, knee, and ankle. The
mAP index reflects the average PCKh detection rate across all joints. The human pose estimation experiment in this paper uses the
mAP:
, where
AP is average accuracy,
s is a threshold,
mAP is the mean
AP in different s,
p is the number of human in the video,
OKSp mainly evaluates and predicts the similarity between the joint position of the
P-th person and the label position, and
σ(∙) is a crone function.
where
i is the node type variable and
represents the importance of joint point
i; when
, the node is visible. The 3D-based recognition methods use Top
i and Top5 benchmarks. Top
i is the largest label prediction value in the final probability vector of the predicted label. Top5 is the final probability vector of the top 5. In addition, the recognition accuracy is evaluated using cross-view (CV) and cross-subject (CS) benchmarks.
2.3. Guideline for Basketball Teaching
Through the collection and comparative analysis of team and player schedule information, basic data, and data in personal training, the user uploads a single person’s sports video, and through the comparative analysis of the extracted three-dimensional skeleton information and the skeleton information of standard actions, assists players in training for standard actions. For the team game, the user uploads the complete game video, analyzes it through the introduced recognition algorithm, feeds back the movement and position of each player, and provides tactical guidance to the coach. Before the development of the system, it is necessary to conduct a feasibility analysis of the system to be developed, including economic feasibility, technical feasibility, and operational feasibility. The following is the specific analysis content [
27]:
In terms of economic feasibility, compared with commercial sports video analysis systems at home and abroad, at present, in basketball games, mainstream commercial systems mainly use foreign analysis systems, such as SynergySports, ShortTrackerTeam, and Coach’s Eye. The cost is high. For the training and use of ordinary college basketball teams, the economic pressure is too great, However, the development of this system is all completed on a personal computer, and the software used is free software. The data in development come from daily collection, and the development cost is low. The charge for the basketball auxiliary training system after commercial use is low, which solves the problem of high investment costs in colleges and universities [
28].
In terms of technical feasibility, domestic game analysis systems, namely Tongdao intelligent cloud platform, intelligent teaching assistant event systems, SportsDT of peer technology, and other systems are mainly focused on football, golf, and other matches and require a lot of manual assistance, with slightly lower intelligence and agility. Through the research of the 3D-based motion recognition algorithm presented in
Section 3, this system can improve the recognition rate of athletes, extract the corresponding 3D skeleton of the motion, and compare the skeleton longitudinally to effectively assist coaches in training [
29].
In terms of operational feasibility, the system is designed with a simple interface. Users do not need to understand the background processing process. For users, the background data processing process and computing difficulty can be ignored. At the same time, the system is deployed on Alibaba Cloud without excessive computer configuration, so it is operationally feasible.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}