
A Semi-Supervised Object Detection Algorithm Based on Teacher-Student Models with Strong-Weak Heads

Abstract
:1. Introduction
- We propose a novel semi-supervised object detection algorithm with competitive performance in sufficient experiments on PASCAL VOC and MS-COCO datasets.
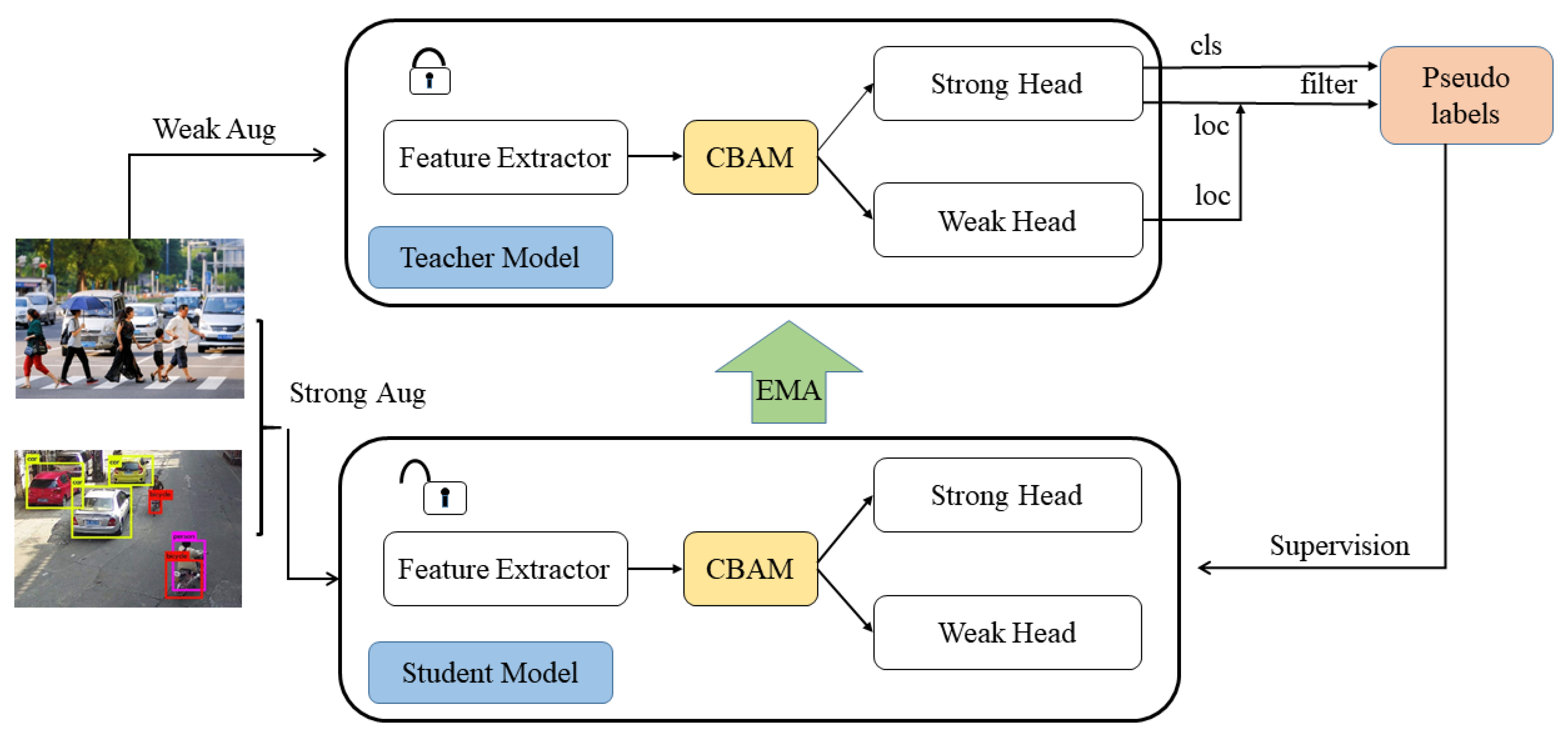
- In the teacher model, the strong head inference results could generate pseudo labels, with which the weak head inference results can be used to compute the IOUs to determine the quality of pseudo label location to filter pseudo annotations.
- In the student model, the strong head focuses on clean data (ground truth labels and high-quality pseudo labels), while the weak head can extract features from clean data and dirty data (low-quality pseudo labels) without polluting the strong head weights by noise in dirty ones.
2. Related Work
2.1. Object Detection
2.2. Semi-Supervised Image Classification
2.3. Semi-Supervised Object Detection
3. Methodology
3.1. Method Overview
3.2. Pre-Training Stage
3.3. Semi-Supervised Training Stage
3.4. Strong-Weak Heads
3.5. CBAM
3.6. Data Augmentation
4. Experiments and Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Experimental Details
4.4. Experimental Results on COCO
4.5. Experimental Results on VOC
4.6. Ablation Experiments
4.6.1. Multi-Head Ablation Experiment
- A strong head of the teacher model.
- A weak head of the teacher model.
- A strong head of the student model.
- A weak head of the student model.
4.6.2. Data Augmentation Ablation Experiment
4.7. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; Volume 28. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Sohn, K.; Zhang, Z.; Li, C.-L.; Zhang, H.; Lee, C.-Y.; Pfister, T. A simple semi-supervised learning framework for object detection. arXiv 2020, arXiv:2005.04757. [Google Scholar]
- Liu, Y.-C.; Ma, C.-Y.; He, Z.; Kuo, C.-W.; Chen, K.; Zhang, P.; Wu, B.; Kira, Z.; Vajda, P. Unbiased teacher for semi-supervised object detection. arXiv 2021, arXiv:2102.09480. [Google Scholar]
- Zhou, Q.; Yu, C.; Wang, Z.; Qian, Q.; Li, H. Instant-teaching: An end-to-end semi-supervised object detection framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4081–4090. [Google Scholar]
- Yang, Q.; Wei, X.; Wang, B.; Hua, X.-S.; Zhang, L. Interactive self-training with mean teachers for semi-supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5941–5950. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; Volume 29. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Hashimaa, S.M.; Mahmoud, I.I.; Elazm, A.A. Experimental comparison among Fast Block Matching Algorithms (FBMAs) for motion estimation and object tracking. In Proceedings of the 2011 28th National Radio Science Conference (NRSC), Cairo, Egypt, 26–28 April 2011; pp. 1–8. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lv, H.; Yan, H.; Liu, K.; Zhou, Z.; Jing, J. Yolov5-ac: Attention mechanism-based lightweight yolov5 for track pedestrian detection. Sensors 2022, 22, 5903. [Google Scholar] [CrossRef] [PubMed]
- Yin, G.; Yu, M.; Wang, M.; Hu, Y.; Zhang, Y. Research on highway vehicle detection based on faster R-CNN and domain adaptation. Appl. Intell. 2022, 52, 3483–3498. [Google Scholar] [CrossRef]
- Sumit, S.S.; Awang Rambli, D.R.; Mirjalili, S.; Ejaz, M.M.; Miah, M.S.U. Restinet: On improving the performance of tiny-yolo-based cnn architecture for applications in human detection. Appl. Sci. 2022, 12, 9331. [Google Scholar] [CrossRef]
- Vecvanags, A.; Aktas, K.; Pavlovs, I.; Avots, E.; Filipovs, J.; Brauns, A.; Done, G.; Jakovels, D.; Anbarjafari, G. Ungulate Detection and Species Classification from Camera Trap Images Using RetinaNet and Faster R-CNN. Entropy 2022, 24, 353. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Ren, G.; Yu, R.; Guo, S.; Zhu, J.; Zhang, L. Image-adaptive YOLO for object detection in adverse weather conditions. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; pp. 1792–1800. [Google Scholar]
- Wu, H.; Hu, Y.; Wang, W.; Mei, X.; Xian, J. Ship fire detection based on an improved YOLO algorithm with a lightweight convolutional neural network model. Sensors 2022, 22, 7420. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Xiao, D.; Liu, Y.; Wu, H. An algorithm for automatic identification of multiple developmental stages of rice spikes based on improved Faster R-CNN. Crop J. 2022, 10, 1323–1333. [Google Scholar] [CrossRef]
- Bachman, P.; Alsharif, O.; Precup, D. Learning with pseudo-ensembles. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; Volume 27. [Google Scholar]
- Lee, D.-H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Atlanta, GA, USA, 16–21 June 2013; p. 896. [Google Scholar]
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring. arXiv 2019, arXiv:1911.09785. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. Mixmatch: A holistic approach to semi-supervised learning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2019; Volume 32. [Google Scholar]
- Miyato, T.; Maeda, S.-i.; Koyama, M.; Ishii, S. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1979–1993. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuo, C.-W.; Ma, C.-Y.; Huang, J.-B.; Kira, Z. Featmatch: Feature-based augmentation for semi-supervised learning. In European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 479–495. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 113–123. [Google Scholar]
- Zoph, B.; Cubuk, E.D.; Ghiasi, G.; Lin, T.-Y.; Shlens, J.; Le, Q.V. Learning data augmentation strategies for object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 566–583. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Xu, M.; Zhang, Z.; Hu, H.; Wang, J.; Wang, L.; Wei, F.; Bai, X.; Liu, Z. End-to-end semi-supervised object detection with soft teacher. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 3060–3069. [Google Scholar]
- Kim, J.-H.; Shim, H.-J.; Jung, J.-W.; Yu, H.-J. A Supervised Learning Method for Improving the Generalization of Speaker Verification Systems by Learning Metrics from a Mean Teacher. Appl. Sci. 2021, 12, 76. [Google Scholar] [CrossRef]
- Xiong, F.; Tian, J.; Hao, Z.; He, Y.; Ren, X. SCMT: Self-Correction Mean Teacher for Semi-supervised Object Detection. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI-22), Vienna, Austria, 23–29 July 2022; pp. 1488–1494. [Google Scholar]
- Gao, J.; Wang, J.; Dai, S.; Li, L.-J.; Nevatia, R. Note-rcnn: Noise tolerant ensemble rcnn for semi-supervised object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–October–2 November 2019; pp. 9508–9517. [Google Scholar]
- Jeong, J.; Lee, S.; Kim, J.; Kwak, N. Consistency-based semi-supervised learning for object detection. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2019; Volume 32. [Google Scholar]
- Jeong, J.; Verma, V.; Hyun, M.; Kannala, J.; Kwak, N. Interpolation-based semi-supervised learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11602–11611. [Google Scholar]
- Li, Y.; Huang, D.; Qin, D.; Wang, L.; Gong, B. Improving object detection with selective self-supervised self-training. In European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 589–607. [Google Scholar]
- Misra, I.; Shrivastava, A.; Hebert, M. Watch and learn: Semi-supervised learning for object detectors from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3593–3602. [Google Scholar]
- Tang, P.; Ramaiah, C.; Wang, Y.; Xu, R.; Xiong, C. Proposal learning for semi-supervised object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 2291–2301. [Google Scholar]
- Tang, Y.; Wang, J.; Gao, B.; Dellandréa, E.; Gaizauskas, R.; Chen, L. Large scale semi-supervised object detection using visual and semantic knowledge transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2119–2128. [Google Scholar]
- Zheng, S.; Chen, C.; Cai, X.; Ye, T.; Tan, W. Dual Decoupling Training for Semi-Supervised Object Detection with Noise-Bypass Head. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI-22), Virtual, 22 February–1 March 2022. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 1% COCO | 2% COCO | 5% COCO | 10% COCO | COCO-Full |
|---|---|---|---|---|---|
| Baseline | 9.05 ± 0.16 | 12.70 ± 0.15 | 18.47 ± 0.22 | 23.86 ± 0.81 | 37.63 |
| CSD [38] | 11.12 ± 0.15 | 14.15 ± 0.13 | 18.79 ± 0.13 | 22.76 ± 0.09 | 38.52 |
| STAC [1] | 13.97 ± 0.35 | 18.25 ± 0.25 | 24.38 ± 0.12 | 28.64 ± 0.21 | 39.21 |
| ISMT [4] | 18.88 ± 0.74 | 22.43 ± 0.56 | 26.37 ± 0.24 | 30.53 ± 0.52 | 39.64 |
| Instant-teaching [3] | 18.05 ± 0.20 | 22.45 ± 0.15 | 26.75 ± 0.05 | 30.40 ± 0.05 | 40.20 |
| Unbiased Teacher [2] | 20.75 ± 0.12 | 24.30 ± 0.07 | 28.27 ± 0.15 | 31.50 ± 0.10 | 41.30 |
| Ours | 18.70 ± 0.32 | 24.55 ± 0.22 | 28.10 ± 0.20 | 32.50 ± 0.35 | 42.01 |
| Method | Labeled | Unlabeled | AP | AP50 |
|---|---|---|---|---|
| Baseline | VOC07 | - | 42.6 | 72.6 |
| CSD [38] | VOC07 | VOC12 | 42.7 | 76.7 |
| STAC [1] | 44.6 | 77.5 | ||
| ISMT [4] | 46.2 | 77.2 | ||
| Instant-teaching [3] | 48.7 | 78.3 | ||
| Unbiased Teacher [2] | 49.7 | 77.4 | ||
| Ours | 52.5 | 81.0 | ||
| CSD [38] | VOC07 | VOC12+MSCOCO20cls | 43.6 | 77.1 |
| STAC [1] | 46.0 | 79.1 | ||
| ISMT [4] | 49.6 | 77.8 | ||
| Instant-teaching [3] | 50.8 | 78.8 | ||
| Unbiased Teacher [2] | 50.3 | 78.8 | ||
| Ours | 53.5 | 82.1 |
| Head | mAP | CBAM/mAP |
|---|---|---|
| Teacher-Weak | 31.9 | 32.1 |
| Teacher-Strong | 32.2 | 32.5 |
| Student-Weak | 29.9 | 30.1 |
| Student-Strong | 30.3 | 30.5 |
| Method | AP | ||||
|---|---|---|---|---|---|
| Others | √ | - | - | - | 31.1 |
| CutOut | √ | √ | - | - | 31.3 |
| Mixup | √ | √ | √ | - | 32.3 |
| Mosaic | √ | √ | √ | √ | 32.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, X.; Luo, F.; Qi, W.; Liu, H. A Semi-Supervised Object Detection Algorithm Based on Teacher-Student Models with Strong-Weak Heads. Electronics 2022, 11, 3849. https://doi.org/10.3390/electronics11233849
Cai X, Luo F, Qi W, Liu H. A Semi-Supervised Object Detection Algorithm Based on Teacher-Student Models with Strong-Weak Heads. Electronics. 2022; 11(23):3849. https://doi.org/10.3390/electronics11233849
Chicago/Turabian StyleCai, Xiaowei, Fuyi Luo, Wei Qi, and Hong Liu. 2022. "A Semi-Supervised Object Detection Algorithm Based on Teacher-Student Models with Strong-Weak Heads" Electronics 11, no. 23: 3849. https://doi.org/10.3390/electronics11233849
APA StyleCai, X., Luo, F., Qi, W., & Liu, H. (2022). A Semi-Supervised Object Detection Algorithm Based on Teacher-Student Models with Strong-Weak Heads. Electronics, 11(23), 3849. https://doi.org/10.3390/electronics11233849