
Location Based Indoor and Outdoor Lightweight Activity Recognition System

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
2. Related Work
3. Outdoor Activity Recognition System
3.1. POI Identification Mechanism
3.1.1. First Iteration
- The angle formed by connecting the three points is less than 40 degrees.
- The ratio between the two sides of the angle (longest side/shortest side) is less than 2.
- The angles formed by the first point and its previous point, or the angle formed by the third point and its next point, are greater than 145 degrees and less than 215 degrees.
- 1.
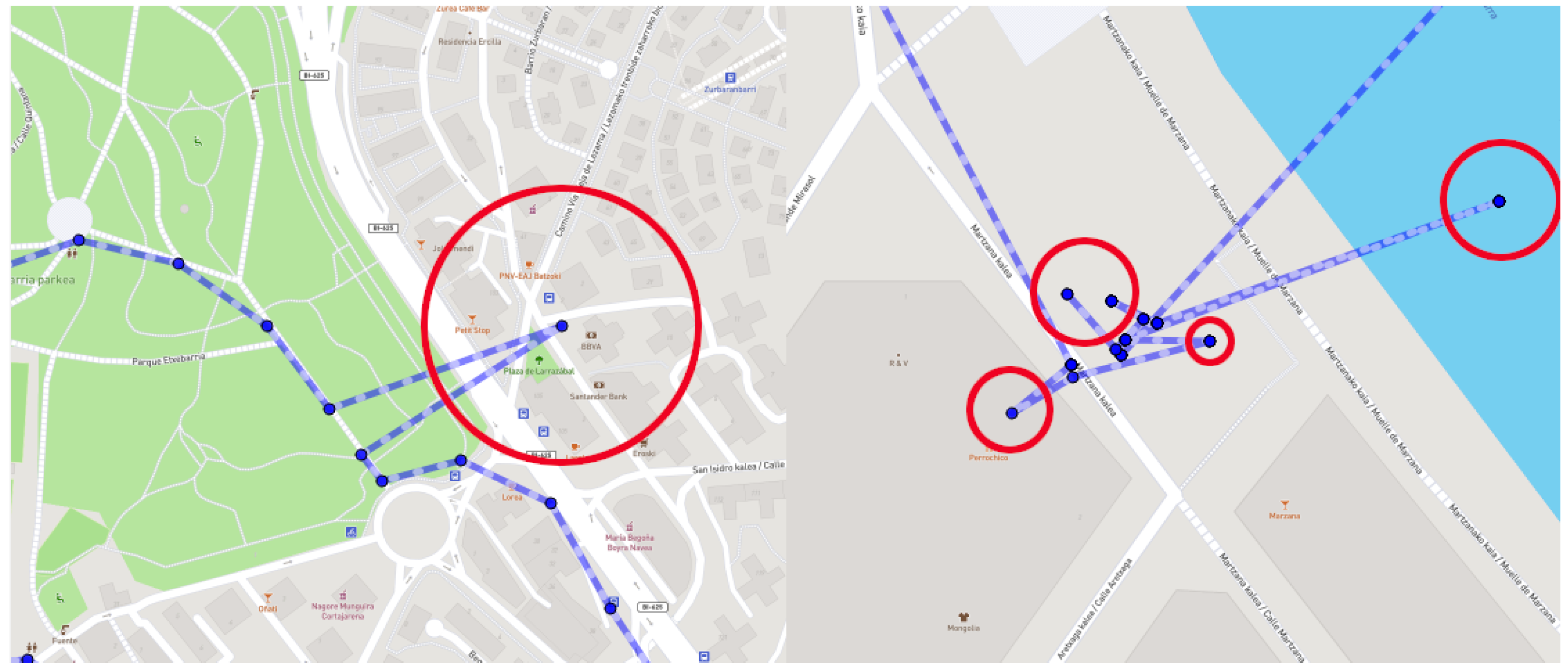
- Static jumps: already identified during the data cleaning phase of the first iteration. They are points that have exactly the same coordinates. It is not common for the points to have the same coordinates; therefore, they may indicate that there are errors in the GPS data (See Figure 2).
- 2.
- GPS drifts: also addressed during the first iteration. However, the data cleaning algorithm was mainly oriented to motion-related GPS drifts. After analysis of results, another more problematic type of GPS drift associated with static points was detected (See Figure 3).
- 3.
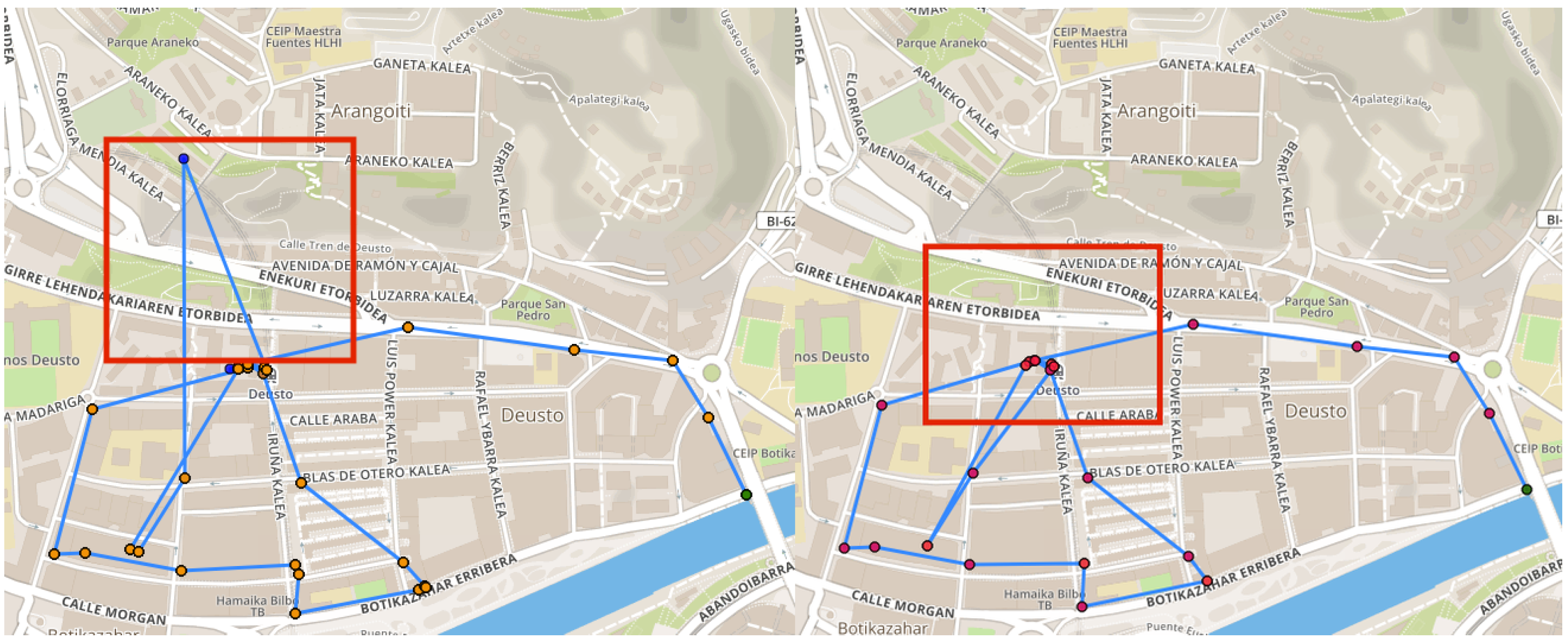
- Multi-clustering: even though it is directly related to the two previous errors, multi-clustering is so relevant that it has to be addressed in a different way. Sometimes, due to GPS errors, although the user remains in the same place, spatial jumps (in the form of drifts or static-jumps) occur, resulting in false clusters, when in fact all the points belong to the same unique cluster (see Figure 4 where all the points belong to a single cluster).
3.1.2. Second Iteration
- The standard deviation of the distances from the cluster points to the cluster centroid. In general, a good cluster should not have values that are too high (something that is already taken care of by DBSCAN itself), but not too small either as it would imply a “static jump”.
- The variability representing the average number of different coordinates with respect to the total number of points in the cluster. In a good cluster it is not normal that coordinates are repeated, therefore, it is normal to have values close to 1. If they are closer to 0, it implies a “static jump”.
- Number of inputs and outputs. The number of inputs and outputs occurring in that cluster is checked. A good cluster should have 2, if it is in the middle of the route, or 1 if it is the start or the end of the route (home, for example). A larger number may imply that the same cluster is crossed by the user several times throughout the day, although it could also be the result of a GPS drift that goes outside the cluster boundaries.
- Time jumps inside the cluster. The time difference between consecutive points in the cluster is calculated and those exceeding 125 s are considered as “time jumps” (GPS samples are usually obtained every 60 s, so we give a margin of slightly more than two samples).
- First, those clusters that have two or less inputs and outputs are checked. When these clusters have a variability of less than 0.5 and the standard deviation of the distances is greater than 1.8, these clusters are considered as ‘good’. On the contrary, they are considered ‘bad’ when the standard deviation of the distances is less than 0.1 (regardless of the variability). For all other cases, the cluster is considered as ‘good’.
- For those clusters that have more than two inputs and outputs, only the clusters that have no time jumps are considered ‘good’.
- The clusters are considered as ‘bad’ for all other cases.
- Level 1: The cluster analysis starts from level 1, so the label of the first point to check is considered the initial label of this level. Then, we get the next point and check if it belongs to the first level (it has a label that belongs to level 1). If not, it would go to level 2 (the label of this new point will be the initial label of level 2).
- Level 2: The next point of the route is taken and its label is checked. If it is a label belonging to level 1, it is returned to level 1. As we consider that all the points until now are part of the same cluster, we add the labels of level 2 as valid levels for level 1. If the label is not part of level 1, we check if it belongs to the labels of level 2, in that case, we consider that the point still belongs to level 2. Otherwise, we check if the label is part of ‘good’ labeled cluster, since a good cluster cannot belong to a multi-cluster, the process is considered completed and the actual cluster is considered with only those points belonging to level 1. If the cluster is not labeled as ‘good’, it would go to level 3 (the label of the new point being the initial label of level 3).
- Level 3: Again, we get the next point of the route and its label is checked. If it is a label belonging to level 1, it is returned to this level and the labels of levels 2 and 3 are added to level 1. On the contrary, if it is a label of level 2, it is returned to this level and the labels of level 3 are added to level 2. Otherwise, a preliminary check is made before moving to level 4. The centroids of the three levels are calculated and it is checked if any of them form an angle less than 45º, or level 3 has been labeled as a bad cluster, or it is a static point, in which case it is moved to level 4 (the label of the new point being the initial label of level 4). If the condition is not fulfilled, the process is finished and only the points belonging to level 1 would be part of the actual cluster.
- Level 4: As in the other levels, the label of the next point on the route is checked. If it is a level 1 label, it is returned to this level and the labels of levels 2, 3, and 4 are added to level 1. If it is a level 2 label, it is returned to this level and the labels of levels 3 and 4 are added to it. Otherwise, and as long as the point label is not part of a cluster labeled as ’good’ (in which case the process ends directly), a previous check is made again before passing to level 5, if the current point label belongs to a cluster related to any of the clusters (labels) belonging to level 4, or if the current point is static, it is passed to level 5 (as always, using the label of this point as the initial label of level 5). If the condition is not fulfilled, the process ends, the rest of the levels do not belong to the cluster, and only the points belonging to level 1 are part of the real cluster.
- Level 5: As in the previous case, the different levels are checked and the corresponding level is passed by updating the labels. If the tag belongs to level 5, it remains at the same level. Otherwise, the analysis is finished and only the level 1 points are part of the cluster.
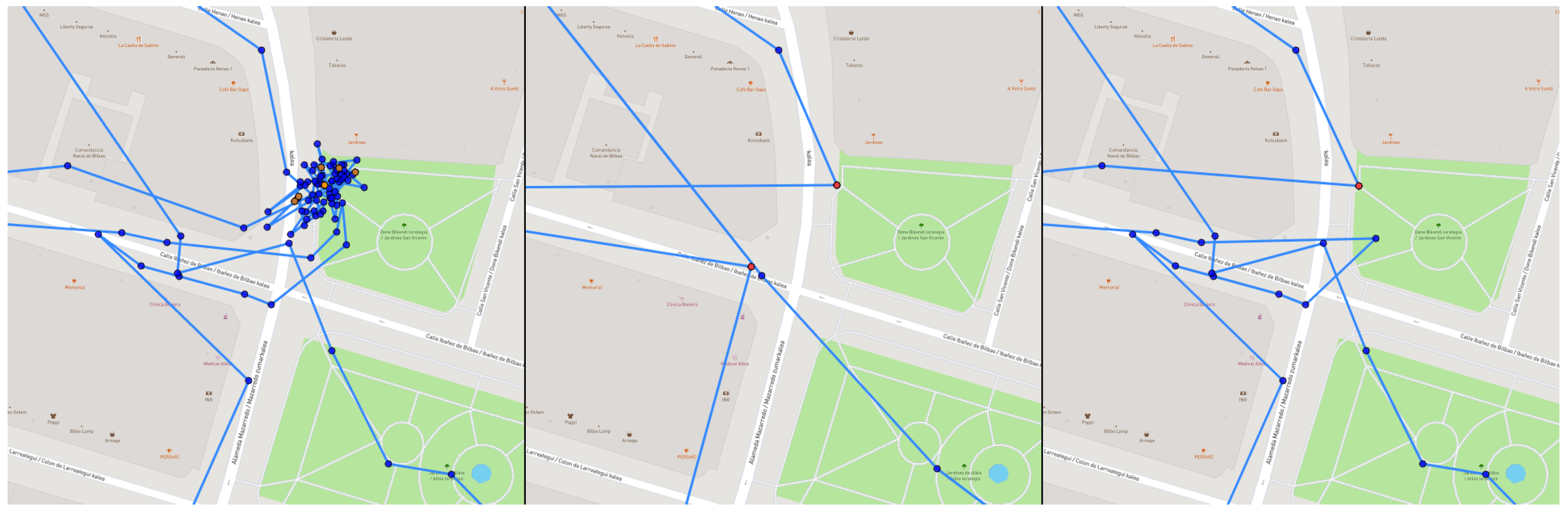
3.2. Semantic Location Extraction
- A high granularity place categorization taxonomy.
- It does not only provide a large database of coordinates related to places with semantic meaning, but also provides other kinds of information such as the area of the buildings, if a facility is adapted for disabled people, if a restaurant provides the takeaway option and so on.
- Anyone can contribute to OSM adding new places or updating old ones.
- Allows the retrieval of the nearest places to the coordinates providing the radius of the circumference.
- Accurate transformation from coordinates to a street address.
- Nominatim (https://nominatim.org/ (accessed on 19 January 2022)): is the geocoding and reverse geocoding endpoint of OSM. Providing the coordinates of a location, it returns the characteristics (name, address, category, etc.) of a place if there is one in those exact coordinates (with a very small search radius); otherwise, it returns the street address associated with those coordinates.
- Overpass (https://wiki.openstreetmap.org/wiki/Overpass_API (accessed on 19 January 2022)): allows the retrieval of all the information that OSM has in a specific location delimited by a bounding box. Unlike Nominatim where the logic is on the server side, with Overpass we retrieve all the data that we consider that is necessary for the semantic location extraction (nodes, buildings’ polygons, roads, etc.) and we process it locally.
3.2.1. Semantic Location Extraction Process
3.2.2. Building Partitioning Method
- Nodes that only have informative tags.
- Nodes that represent elements with no surface (such as telephone booths or cash machines).
- Hotels (if a hotel is marked as a node it implies that there are floors in that building functioning as a hotel, but there could be some ground floor stores).
- 1.
- When both points are on the same edge. In this particular case (see the green edge in Figure 20), the projections on the edge of both nodes are used. Then, the perpendicular bisector of the projections of both points on the edge is calculated.
- 2.
- Neighbours on consecutive edges. It is checked which of the two points is closest to another edge (see Figure 21). That edge is used as a basis for the same procedure shown in 1.
- 3.
- Points in non-consecutive edges. In this case, the dots are used instead of the projections. We use the nearest neighbor in the red edge (see Figure 22).
3.2.3. Activity Recognition through Semantic Location Mapping
- 1.
- Related to the instrumental activities of daily living: Go to the shop, Go to clothing store, Go to the department store, Go to the shopping mall, Go to shoe store, Go to the home goods store, Go to jewelry store, Go to the hardware store, Go to flower store, Go to laundry shop, Go to Sports shop, Cooking, Go to the pharmacy, Go to the drugstore, Doing housework, Doing laundry at home, Driving or using public, transportation, Take plane, Take train, International travel, Use taxi, Going to work, Go to the accountant, Go to the ATM, Go to the Bank.
- 2.
- Related to eating habits: Going to the restaurant, Going to the food shop, Going to the bar, Going to the cafe, Going to the liquor store, Order food in person, Go to the bakery, Buy food, Buy fish, Buy frozen food, Buy ice cream, Go to the butcher, Go to the deli.
- 3.
- Related to physical activity: Go to the gym, Walking more than a mile, Walking several blocks, Walking one block, Still time, Swimming, Dancing, Golf.
- 4.
- Related to socialization: Going to the restaurant, Visiting Family, Visiting Friends, Go to the bar, Go out in public.
- 5.
- Related to hobbies: Rent a movie, Go to the cinema, Go to the aquarium, Go to the amusement park, Go to the bowling alley, Go to the gambling shop, Go camping, Go to the zoo, Go to the stadium, Go to the nightclub, Go to tourist attraction, Go to the beach, Nature, Go to the Spa/Sauna, Go to the beauty salon, Go to the hairdresser, Go to cosmetics store.
- 6.
- Doctor related activities: Go to the doctor, Go to the dentist, Go to the physiotherapist, Got to the hospital, Go to the gym.
- 7.
- Related to cognition: Spirituality, Education, Go to cinema, Go to museum, Go to the art gallery, Go to bookshop, Go to library.
- 8.
- Other: Lodging, Take children to school, Take children to the playground, Go to the kindergarten, Buy baby products.
4. Indoor Activity Recognition System
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Irizar-Arrieta, A.; Gómez-Carmona, O.; Bilbao-Jayo, A.; Casado-Mansilla, D.; Lopez-De-Ipina, D.; Almeida, A. Addressing behavioural technologies through the human factor: A review. IEEE Access 2020, 8, 52306–52322. [Google Scholar] [CrossRef]
- Onile, E.; Machlev, R.; Petlenkov, E.; Levron, Y.; Belikov, J. Uses of the digital twins concept for energy services, intelligent recommendation systems, and demand side management: A review. IEEE Energy Rep. 2021, 7, 997–1015. [Google Scholar] [CrossRef]
- Guo, K.; Lu, Y.; Gao, H.; Cao, R. Artificial intelligence-based semantic internet of things in a user-centric smart city. Sensors 2018, 18, 1341. [Google Scholar] [CrossRef] [Green Version]
- Mulero, R.; Urosevic, V.; Almeida, A.; Tatsiopoulos, C. Towards ambient assisted cities using linked data and data analysis. J. Ambient. Intell. Hum. Comp. 2018, 9, 1573–1591. [Google Scholar] [CrossRef] [Green Version]
- Almeida, A.; Mulero, R.; Rametta, P.; Urošević, V.; Andrić, M.; Patrono, L. A critical analysis of an IoT—Aware AAL system for elderly monitoring. Future Gener. Comput. Syst. 2019, 97, 598–619. [Google Scholar] [CrossRef]
- Mulero, R.; Aitor, A.; Azkune, G.; Abril-Jiménez, P.; Waldmeyer, M.T.A.; Castrillo, M.P.; Patrono, L.; Rametta, P.; Sergi, I. An IoT-aware approach for elderly-friendly cities. IEEE Access 2018, 6, 7941–7957. [Google Scholar] [CrossRef]
- Bilbao Jayo, A.; Cantero, X.; Almeida, A.; Fasano, L.; Montanaro, T.; Sergi, I.; Patrono, L. A lightweight semantic-location system for indoor and outdoor behavior modelling. In Proceedings of the 6th International Conference on Smart and Sustainable Technologies (SpliTech), Bol and Split, Croatia, 8–11 September 2021. [Google Scholar] [CrossRef]
- Bilbao-Jayo, A.; Almeida, A.; Sergi, I.; Montanaro, T.; Fasano, L.; Emaldi, M.; Patrono, L. Behavior Modeling for a Beacon-Based Indoor Location System. Sensors 2021, 21, 4839. [Google Scholar] [CrossRef]
- Almeida, A.; Azkune, G.; Bilbao, A. Embedding-Level Attention and Multi-Scale Convolutional Neural Networks for Behaviour Modelling. In Proceedings of the IEEE SmartWorld, Ubiquitous Intelligence and Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018. [Google Scholar] [CrossRef]
- Hao, C.; Zhou, Y. Design and Implementation of User Behavior Acquisition and Simulation Prediction Framework for Mobile Intelligent Terminal Based on User Perception. In Proceedings of the IEEE Conference on Telecommunications, Optics and Computer Science (TOCS), Shenyang, China, 11–13 December 2020. [Google Scholar] [CrossRef]
- Buffelli, D.; Vandin, F. Attention-Based Deep Learning Framework for Human Activity Recognition With User Adaptation. IEEE Sens. J 2021, 21, 13474–13483. [Google Scholar] [CrossRef]
- Hasegawa, T. Smartphone Sensor-Based Human Activity Recognition Robust to Different Sampling Rates. IEEE Sens. J. 2021, 21, 6930–6941. [Google Scholar] [CrossRef]
- Verdouw, C.N.; Sundmaeker, H.; Meyer, F.; Wolfert, J.; Verhoosel, J.; Kreowski, H.-J.; Scholz-Reiter, B.; Thoben, K.-D. (Eds.) Smart Agri-Food Logistics: Requirements for the Future Internet, Dynamics in Logistics; Springer: Berlin/Heidelberg, Germany, 2013; pp. 247–257. [Google Scholar] [CrossRef] [Green Version]
- Tian, J.; Wang, G.; Gao, X.; Shi, K. User behavior based automatical navigation system on Android platform. In Proceedings of the 23rd Wireless and Optical Communication Conference (WOCC), Newark, NJ, USA, 9–10 May 2014. [Google Scholar] [CrossRef]
- Krejcar, O. Using of mobile device localization for several types of applications in intelligent crisis management. In Proceedings of the 5th IEEE GCC Conference and Exhibition, Kuwait City, Kuwait, 17–19 March 2009. [Google Scholar] [CrossRef]
- Ghajargar, M. Toward intelligent environments: Supporting reflection with smart objects in the home. Interactions 2017, 24, 60–62. [Google Scholar] [CrossRef]
- Sung, K.; Choi, J.; Oh, H. Management system for Customized Individual Service using User Behavior Pattern Analysis Algorithm on HomeNetwork. In Proceedings of the International Conference on Multimedia and Ubiquitous Engineering (MUE’07), Seoul, Korea, 26–28 April 2007. [Google Scholar] [CrossRef]
- Nasralla, M.M. Sustainable Virtual Reality Patient Rehabilitation Systems with IoT Sensors Using Virtual Smart Cities. Sustainability 2021, 13, 4716. [Google Scholar] [CrossRef]
- Jiahong, Z.; Bin, S. A new multi-objective model of location-allocation in emergency response network design for hazardous materials transportation. In Proceedings of the IEEE International Conference on Emergency Management and Management Sciences, Beijing, China, 8–10 August 2010. [Google Scholar] [CrossRef]
- Cavalera, G.; Conte Rosito, R.; Lacasa, V.; Mongiello, M.; Nocera, F.; Patrono, L.; Sergi, I. An Innovative Smart System based on IoT Technologies for Fire and Danger Situations. In Proceedings of the 4th International Conference on Smart and Sustainable Technologies (SpliTech), Split, Croatia, 18–21 June 2019. [Google Scholar] [CrossRef]
- Mongiello, M.; Nocera, F.; Parchitelli, A.; Riccardi, L.; Avena, L.; Patrono, L.; Sergi, I.; Rametta, P. A Microservices-based IoT Monitoring System to Improve the Safety in Public Building. In Proceedings of the 3rd International Conference on Smart and Sustainable Technologies (SpliTech), Split, Croatia, 26–29 June 2018. [Google Scholar]
- Mongiello, M.; Nocera, F.; Parchitelli, A.; Patrono, L.; Rametta, P.; Riccardi, L.; Sergi, I. A Smart IoT-Aware System For Crisis Scenario Management. J. Commun. Softw. Syst. 2018, 14, 91–98. [Google Scholar] [CrossRef] [Green Version]
- Tan, C.N.L.; Klein, C.; Elmroth, E. Location-aware load prediction in edge data centers. In Proceedings of the Second International Conference on Fog and Mobile Edge Computing (FMEC), Valencia, Spain, 8–11 May 2017. [Google Scholar] [CrossRef]
- Corno, F.; De Russis, L.; Marcelli, A.; Montanaro, T. An Unsupervised and Noninvasive Model for Predicting Network Resource Demands. IEEE Internet Things J. 2018, 5, 4342–4350. [Google Scholar] [CrossRef]
- Pant, N.; Elmasri, R. Detecting meaningful places and predicting locations using varied k-means and hidden Markov model. In Proceedings of the 17th SIAM International Conference on Data Mining (SDM 2017), Houston, TX, USA, 27–29 April 2017. [Google Scholar]
- Ashbrook, D.; Starner, T. Learning significant locations and predicting user movement with GPS. In Proceedings of the Sixth International Symposium on Wearable Computers, Seattle, WA, USA, 10 October 2002. [Google Scholar] [CrossRef] [Green Version]
- Ashbrook, D.; Starner, T. Using GPS to learn significant locations and predict movement across multiple users. Pers. Ubiquitous Comput. 2003, 7, 275–286. [Google Scholar] [CrossRef]
- Yang, J.; Xu, J.; Xu, M.; Zheng, N.; Chen, Y. Predicting next location using a variable order Markov model. In Proceedings of the 5th ACM SIGSPATIAL International Workshop on GeoStreaming, Dallas, TX, USA, 4 November 2014. [Google Scholar] [CrossRef]
- Wang, S.; Wang, X.; Yang, Y.; Cai, H. Based Point of Interest and Experience to Task Assignment on Location-Based Social Networks. In Proceedings of the 12th International Conference on Mobile Ad-Hoc and Sensor Networks (MSN), Hefei, China, 16–18 December 2016. [Google Scholar] [CrossRef]
- Tiwari, S.; Kaushik, S. Extracting Region of Interest (ROI) Details Using LBS Infrastructure and Web-Databases. In Proceedings of the IEEE 13th International Conference on Mobile Data Management, Bengaluru, India, 23–26 July 2012. [Google Scholar] [CrossRef]
- Su, C.; Jia, X.; Xie, X.; Li, N. Community Detection and Location Recommendation Based on LBSN. In Proceedings of the International Conference on Network and Information Systems for Computers (ICNISC), Shanghai, China, 14–16 April 2017. [Google Scholar] [CrossRef]
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship and mobility: User movement in location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’11), San Diego, CA, USA, 21–24 August 2011. [Google Scholar] [CrossRef]
- Pipanmekaporn, L.; Kamolsantiroj, S. Mining Semantic Location History for Collaborative POI Recommendation in Online Social Networks. In Proceedings of the 2nd International Conference on Open and Big Data (OBD), Vienna, Austria, 22–24 August 2016. [Google Scholar] [CrossRef]
- Krueger, R.; Thom, D.; Ertl, T. Visual Analysis of Movement Behavior Using Web Data for Context Enrichment. In Proceedings of the IEEE Pacific Visualization Symposium, Yokohama, Japan, 4–7 March 2014. [Google Scholar] [CrossRef]
- Krueger, R.; Thom, D.; Ertl, T. Semantic Enrichment of Movement Behavior with Foursquare—A Visual Analytics Approach. IEEE Trans. Vis. Comput. Graph. 2015, 21, 903–915. [Google Scholar] [CrossRef]
- Wang, D.; Shang, J.; Cheng, W.; Li, X. iMiner: Sub-room-level POI interaction detection for semantic location history construction. In Proceedings of the Fourth International Conference on Ubiquitous Positioning, Indoor Navigation and Location Based Services (UPINLBS), Shanghai, China, 2–4 November 2016. [Google Scholar] [CrossRef]
- Li, Y.; Pu, F.; Cao, Q. Semantic Location-Aware Model for Ubiquitous Computing. In Proceedings of the International Symposium on Information Science and Engineering, Shanghai, China, 20–22 November 2008. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, J.; Gu, J.; Xu, Y. Event Based Semantic Location Model in Cooperative Mobile Computing. In Proceedings of the Ninth International Conference on Hybrid Intelligent Systems, Shenyang, China, 12–14 August 2009. [Google Scholar] [CrossRef]
- Jiang, L.; Yue, P.; Guo, X. Semantic location-based services. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016. [Google Scholar] [CrossRef]
- Li, L.; Guo, X.; Xu, F.; Hu, F. An Accurate and Calibration-free Approach for RSS-based WiFi Localization. In Proceedings of the IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018. [Google Scholar] [CrossRef]
- Li, L.; Guo, X.; Ansari, N.; Li, H. A Hybrid Fingerprint Quality Evaluation Model for WiFi Localization. IEEE Internet Things J. 2019, 6, 9829–9840. [Google Scholar] [CrossRef]
- Zhao, F.; Huang, T.; Wang, D. A Probabilistic Approach for WiFi Fingerprint Localization in Severely Dynamic Indoor Environments. IEEE Access 2019, 7, 116348–116357. [Google Scholar] [CrossRef]
- Solic, P.; Blazevic, Z.; Skiljo, M.; Patrono, L.; Colella, R.; Rodrigues, J.J.P.C. Gen2 RFID as IoT enabler: Characterization and performance improvement. IEEE Wirel. Commun. 2017, 24, 33–39. [Google Scholar] [CrossRef]
- Mainetti, L.; Mele, F.; Patrono, L.; Simone, F.; Stefanizzi, M.L.; Vergallo, R. An RFID-based tracing and tracking system for the fresh vegetables supply chain. Int. J. Antennas Propag. 2013, 2013, 531364. [Google Scholar] [CrossRef] [Green Version]
- Calcagnini, G.; Censi, F.; Maffia, M.; Mainetti, L.; Mattei, E.; Patrono, L.; Urso, E. Evaluation of thermal and nonthermal effects of UHF RFID exposure on biological drugs. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 1051–1057. [Google Scholar] [CrossRef]
- Catarinucci, L.; Colella, R.; De Blasi, M.; Patrono, L.; Tarricone, L. Experimental performance evaluation of passive UHF RFID tags in electromagnetically critical supply chains. J. Commun. Softw. Syst. 2011, 7, 59–70. [Google Scholar] [CrossRef]
- Catarinucci, L.; Colella, R.; De Blasi, M.; Mighali, V.; Patrono, L.; Tarricone, L. High performance RFID tags for item-level tracing systems. In Proceedings of the SoftCOM 2010, 18th International Conference on Software, Telecommunications and Computer Networks, Split, Croatia, 23–25 September 2010; pp. 21–26. [Google Scholar]
- Paolini, G.; Masotti, D.; Antoniazzi, F.; Cinotti, T.S.; Costanzo, A. Fall Detection and 3-D Indoor Localization by a Custom RFID Reader Embedded in a Smart e-Health Platform. IEEE Trans. Microw. Theory 2019, 67, 5329–5339. [Google Scholar] [CrossRef]
- Khattak, S.B.A.; Jia, M.; Marey, M.; Guo, Q.; Gu, X. A Novel Single Anchor Localization Method for Wireless Sensors in 5G Satellite-Terrestrial Network. Alex. Eng. J. 2021, 61, 5595–5606. [Google Scholar] [CrossRef]
- Khan, M.A.; Nasralla, M.M.; Umar, M.M.; Iqbal, Z.; Rehman, G.U.; Sarfraz, M.S.; Choudhury, N. A Survey on the Noncooperative Environment in Smart Nodes-Based Ad Hoc Networks: Motivations and Solutions. Secur. Commun. Netw. 2021, 2021, 9921826. [Google Scholar] [CrossRef]
- Alletto, S.; Cucchiara, R.; Del Fiore, G.; Mainetti, L.; Mighali, V.; Patrono, L.; Serra, G. An Indoor Location-Aware System for an IoT-Based Smart Museum. IEEE Internet Things J. 2016, 3, 244–253. [Google Scholar] [CrossRef]
- Mighali, V.; Del Fiore, G.; Patrono, L.; Mainetti, L.; Alletto, S.; Serra, G.; Cucchiara, R. Innovative IoT-aware services for a smart museum. In Proceedings of the 24th International Conference on World Wide Web (WWW’15 Companion), Florence, Italy, 18–22 May 2015. [Google Scholar] [CrossRef]
- Toasa, F.A.; Tello-Oquendo, L.; Peñaafiel-Ojeda, C.R.; Cuzco, G. Experimental Demonstration for Indoor Localization Based on AoA of Bluetooth 5.1 Using Software Defined Radio. In Proceedings of the IEEE 18th Annual Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD’96), Portland, OR, USA, 2–4 August 1996. [Google Scholar] [CrossRef]
- Gillies, S. The Shapely User Manual. Available online: https://shapely.readthedocs.io/en/latest/ (accessed on 19 January 2022).
- Wettstein, M.; Wahl, H.W.; Shoval, N.; Auslander, G.; Oswald, F.; Heinik, J. Cognitive status moderates the relationship between out-of-home behavior (OOHB), environmental mastery and affect. Arch. Gerontol. Geriatr. 2014, 59, 113–121. [Google Scholar] [CrossRef]
- Wahl, H.W.; Wettstein, M.; Shoval, N.; Oswald, F.; Kaspar, R.; Issacson, M.; Viss, E.; Auslander, G.; Heinik, J. Interplay of cognitive and motivational resources for out-of-home behavior in a sample of cognitively heterogeneous older adults: Findings of the SenTra project. J. Gerontol. B Psychol. Sci. Soc. Sci. 2013, 68, 691–702. [Google Scholar] [CrossRef] [Green Version]
- Asensio-Cuesta, S.; Sánchez-García, A.; Conejero, J.A.; Saez, C.; Rivero-Rodriguez, A.; García-Gómez, J.M. Smartphone sensors for monitoring cancer-related quality of life: App design, EORTC QLQ-C30 mapping and feasibility study in healthy subjects. Int. J. Environ. Res. Public Health 2019, 16, 461. [Google Scholar] [CrossRef] [Green Version]
- Clark, L.A.; Watson, D. Mood and the mundane: Relations between daily life events and self-reported mood. J. Pers. Soc. Psychol. 2008, 54, 296–308. [Google Scholar] [CrossRef]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | POI/Clusters Detection | Semantic Location (SL) or Meaningful Location | POI + SL in Chain | Indoor Location Prediction | Indoor Location Estimation | User Activity Prediction |
|---|---|---|---|---|---|---|
| Pant et al. [25] | Yes | Yes but within personal clusters | Yes | No | No | No |
| Ashbrook et al. (2002) [26] | No | Yes but within personal clusters | Yes | No | No | No |
| Ashbrook et al. (2003) [27] | No | Yes but within personal clusters | Yes | No | No | No |
| Yang et al. [28] | No | They predict trajectories instead of locations | No | Yes, but the activity is only related to the trajectory | No | No |
| Bilbao-Jayo et al. [7] | Yes | Yes, but with a less efficient algorithm that obtains less significant locations | Yes, but with a less efficient algorithm that obtains less significant locations | Yes | Yes | Yes |
| Wang et al. [29] | Yes | No | No | Yes, but they mainly predict similarity among users also based on social links | No | No |
| Tiwari et al. [30] | No | Yes, but they considered only old databases | No | No | No | No |
| Su et al. [31] | Yes, but based on friendships | No | No | No | No | No |
| Cho et al. [32] | Yes | Yes, a meaningful place is a place in which a friend has already been | No | Yes, but they predict a model of human mobility | No | No |
| Pipanmekaporn et al. [33] | Yes | No | No | Yes, but they mainly predict similarity among users also | No | No |
| Krueger et al. (2014) [34] | Yes | Yes, but they do not use public databases | Yes | Yes, but only to determine which place was visited (not the activity itself) | No | No |
| Krueger et al. (2015) [35] | Yes | Yes, but they do not use public databases | Yes | Yes, but only to determine which place was visited (not the activity itself) | No | No |
| Wang et al. [36] | No | No | No | No | Yes, but with accelerometers, compasses, and gyroscopes | No |
| Li et al. [37] | No | No | No | No | Yes, they associate meaningful places to coordinates through ontologies | No |
| Zhang et al. [38] | No | No | No | No | Yes | No |
| Jiang et al. [39] | No | Yes | No | No | No | No |
| Li et al. (2018) [40] | No | No | No | No | Yes | No |
| Li et al. (2019) [41] | No | No | No | No | Yes | No |
| Zhao et al. [42] | No | No | No | No | Yes | No |
| Solic et al. [43] | No | No | No | No | Yes | No |
| Mainetti et al. [44] | No | No | No | No | Yes | No |
| Calcagnini et al. [45] | No | No | No | No | Yes | No |
| Catarinucci et al. (2010) [47] | No | No | No | No | Yes | No |
| Catarinucci et al. (2011) [46] | No | No | No | No | Yes | No |
| Paolini et al. (2011) [48] | No | No | No | No | Yes, through RFID technology. | Yes, but only to detect falls |
| Aletto et al. [51] | No | No | No | No | Yes | No |
| Mighali et al. [52] | No | No | No | No | Yes | No |
| Mighali et al. [53] | No | No | No | No | Yes, with BLE 5.1 | No |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bilbao-Jayo, A.; Cantero, X.; Almeida, A.; Fasano, L.; Montanaro, T.; Sergi, I.; Patrono, L. Location Based Indoor and Outdoor Lightweight Activity Recognition System. Electronics 2022, 11, 360. https://doi.org/10.3390/electronics11030360
Bilbao-Jayo A, Cantero X, Almeida A, Fasano L, Montanaro T, Sergi I, Patrono L. Location Based Indoor and Outdoor Lightweight Activity Recognition System. Electronics. 2022; 11(3):360. https://doi.org/10.3390/electronics11030360
Chicago/Turabian StyleBilbao-Jayo, Aritz, Xabier Cantero, Aitor Almeida, Luca Fasano, Teodoro Montanaro, Ilaria Sergi, and Luigi Patrono. 2022. "Location Based Indoor and Outdoor Lightweight Activity Recognition System" Electronics 11, no. 3: 360. https://doi.org/10.3390/electronics11030360