1. Introduction
This paper is an extension of the work originally presented in the 2020 11th conference of the European Study Group on Cardiovascular Oscillations [
1].
Developments in the measurement and available devices have led to even more accurate observations on the heart rate and its variations; this led to defining heart rate variability (HRV) as a diagnostic tool for heart disease evaluations.
Traditionally, HRV analysis from short-term laboratory recordings is based on time and frequency domains measurements [
2,
3]. Other methodological approaches, mainly based on nonlinear dynamics properties of the heart rate variability signal, are applied to long-term time series, owing to the need for large amount of data to derive the desired indexes [
4,
5]. The Poincaré plot is a simple and robust graphical technique which can be applied both to long- and short-term HRV recordings, in order to extract relevant information on beat-to-beat signal dynamics [
6].
Machine learning (ML) is a branch of artificial intelligence whose aim is to recognize hidden patterns automatically from data. Recently, it has been frequently used to deal with biomedical issues in several contexts: cardiology [
7,
8], fetal monitoring [
9,
10,
11], medical imaging analysis [
12,
13], oncology [
14,
15,
16] and in several other medical specialties [
17,
18,
19]. Problems regarding regression or classification have been solved by applying state-of-art algorithms which proved to help clinicians in handling difficult tasks.
Previous studies have shown that abnormal Poincaré maps, classified by visual examination, are better predictors of cardiac mortality in heart failure patients than conventional indexes [
20,
21]. To overcome the limitation of subjective evaluation of the plots, our group introduced new signal-processing procedures to automatically quantify major morphological characteristics of these plots [
22,
23].
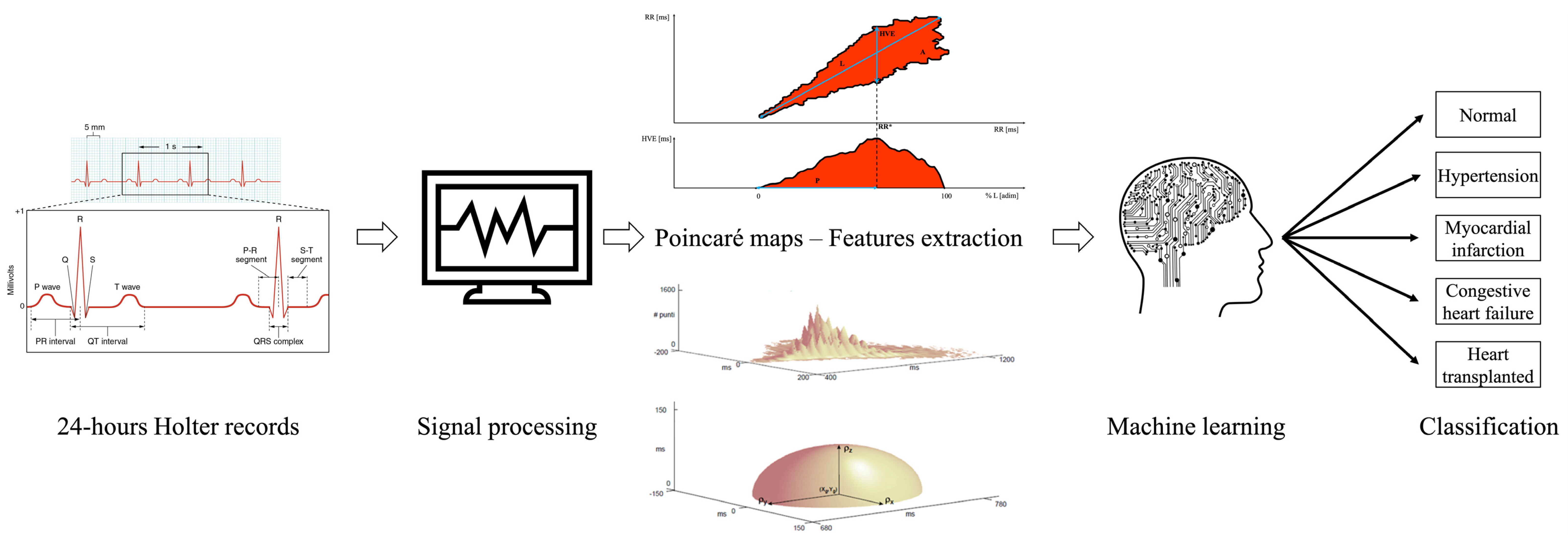
The question remains whether it is possible to use Poincaré maps—2D and 3D—and new unconventional quantitative features extracted from Poincaré maps to discriminate different cardiac issues since, to the best of our knowledge, there are no existing similar systems which have used these parameters to perform a 5-group classification in cardiology. Indeed, our aim was to prove the feasibility of the proposed parameters in distinguishing five types of cardiac issues. To reach this scope, we fed ML algorithms using the above-mentioned features through a dedicated software developed by the authors [
23].
Our preliminary findings indicate that the proposed combination of features and algorithms represents a valuable approach to automatically discriminate several cardiac conditions. This finding confirms the potential application of this methodology as a valid tool to support the clinical decision making of patients affected by different cardiac pathologies.
Several publications have appeared in recent years showing how ML algorithms contributed to classifying cardiac pathologies. For example, Isler and co-workers [
24] investigated the best features subset for a binary classification problem (namely, congestive heart failure (CHF) versus healthy controls) but setting up a multi-stage classification strategy to accomplish the highest diagnosis accuracy. The authors considered different typologies of features (even some extracted from Poincaré maps), preliminary outcomes following a one-step classification process by means of several ML algorithms and results comparisons related to these algorithms evaluating the differences of different cross-validation methods [
25]. Gong and co-workers [
26] presented a similar work whose last scope was to find out eventual enhancements in the testing stage runtime of the proposed ML classification strategy. The authors assessed whether a precise feature subset (in which they included 3 Poincaré maps features out of 10)–Adopted following a histogram-manual feature selection, where they were extracted from segmented 5 min ECG acquisitions–Fed neural network to provide evidence to distinguish arrhythmia and normal state ECG in few (about 200) milliseconds. Finally, Zhao and co-workers [
27] analyzed, instead, the concomitant extraction of features from HRV and pulse transit time variability to assess potential improvements in CHF investigation using a ML strategy. The authors observed the features extracted from pulse transit time variability helped to increase the classification scores.
Although ML strategies proved effective in many binary classification problems, most of the previous studies do not focus on multi-group classifications and, moreover, do not investigate as potential features non–Standard ones extracted from Poincaré maps. With this goal, this work integrates the preliminary findings observed in [
1] exploring improvements in the classification performance of 5 classes of patients using the quantitative features extracted from Poincaré maps (
Figure 1).
The implementation of ML-based tools in physiology, e.g., in the cardiovascular field, has attracted attention and is influencing the biomedical community. The introduction of parameters (i.e., those extracted from Poincaré maps) could represent a potential support for physiologists called to make specific decisions which can save patients’ lives.
3. Results
3.1. Statistical Analysis
Table 1 reports the results obtained by applying the Kruskal Wallis test on each parameter (Par) among the 5 classes extracted through the Poincaré plot analysis, while
Table 2 shows the results of the post hoc test for the variables resulting significant in
Table 1.
None of the variables were able to distinguish each group from all the others although several differences were detected through the post-hoc analysis. The class with the greatest number of significances was the T (17 significances), followed by the normal one (14 significances), C and H (both 10 significances). Therefore, according to the statistical analysis, subjects who underwent a heart transplantation and healthy subjects were the most recognizable by the Poincaré maps.
Then, the multinomial logistic regression was performed; L, P, N
p, D
p and V were kept after the correlation analysis.
Table 3 shows the confusion matrix of such model.
The overall accuracy of the model was 76.0%, while the goodness of fit test showed a p-value = 1.000 indicating a good match between the model and the real data. T patients were the most recognizable while M patients were the least recognizable.
3.2. Machine Learning Analysis
First, the ML analysis was performed on the as-is dataset by employing a LOOCV: 10 patients for 5 groups for a total of 50 subjects. The small sample size and the low number of subjects per class did not allow us to obtain–ss expected–reliable results (data not shown). Therefore, the analysis was repeated on the dataset augmented through SMOTE to obtain more insights. In any case, it should be reminded the multinomial logistic regression already proved in advance the feasibility of our features in distinguishing the 5 classes.
SMOTE was implemented to augment the dataset with artificial data, thus increasing the number of records from 50 to 100 (each group was doubled). Then, a LOOCV step was implemented to compute the evaluation metrics for the proposed ML algorithms.
Table 4 reports these using the normal class as reference for each algorithm, while
Table 5 shows the confusion matrix of the best algorithm.
Excluding NB, which achieved lower performances (accuracy of 76% yet a good specificity of 93.8%) mainly due to the strong correlation between several of the considered features (correlation study data not shown), the other algorithms showed successful results. ADA-B and KNN obtained metrics greater than 90%; indeed, the former showed an accuracy of 91% with a specificity of 97.5%, while the latter an accuracy of 92% and a perfect specificity (100%). Furthermore, it was even remarkable GB sensitivity (100%).
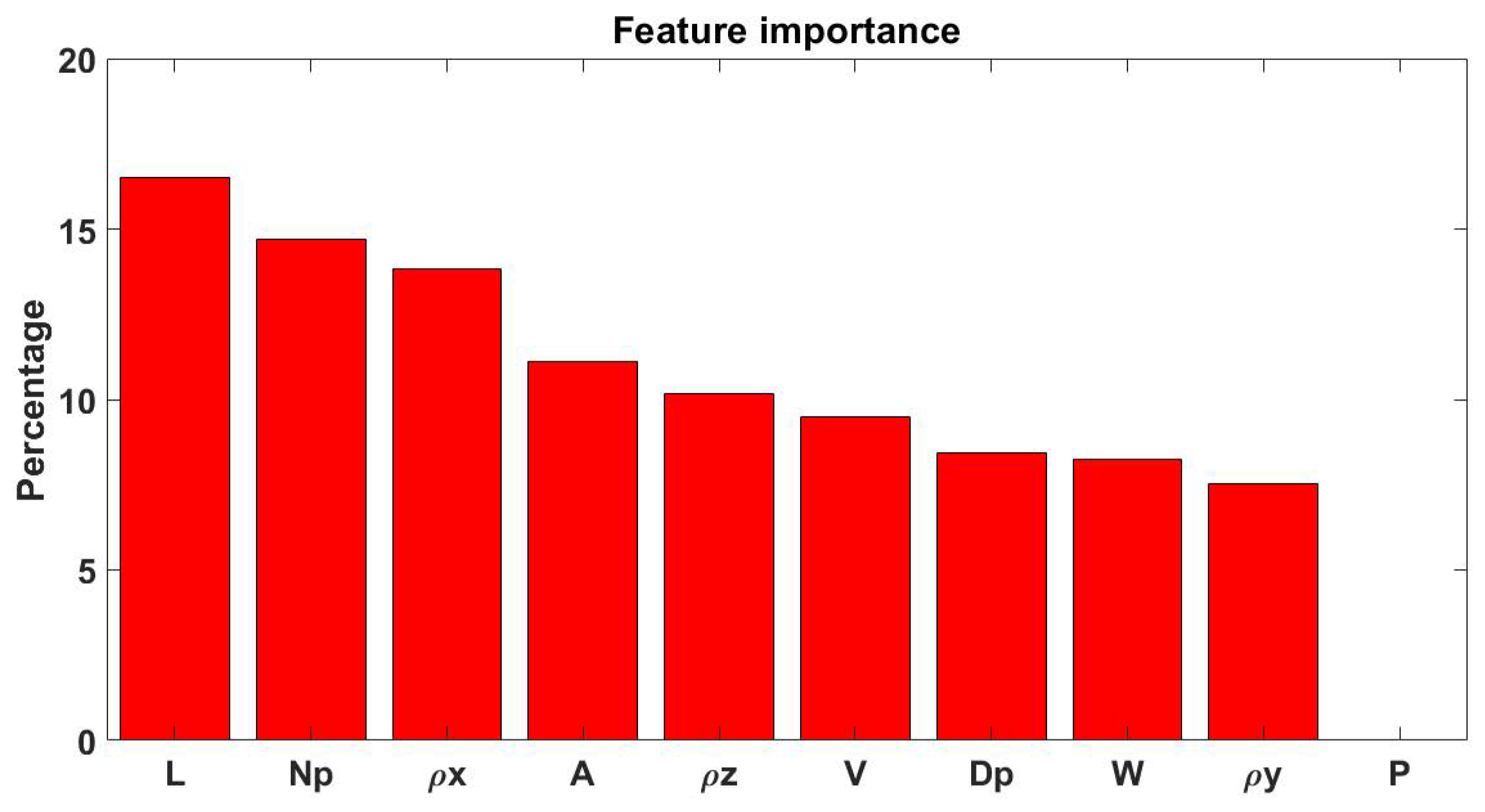
Finally, the features importance, according to the information gain, was computed and illustrated in
Figure 2 after a transformation into percentage values. The top-3 features to perform the classification resulted L, N
p and ρ
x.
Table 6 shows the evaluation metrics of the algorithms after applying the wrapper method. The ranking of the algorithms was the same obtained with the other workflow: KNN obtained the highest accuracy (96.7%) followed by ADA-B (93.3%) and GB (90.0%). The sensitivity and the specificity were computed using the normal class as reference.
4. Discussion
In this paper, the aim was to distinguish healthy subjects from patients affected by four different cardiac pathologies by using first a univariate statistical analysis and then ML algorithms applied on features extracted from Poincaré maps.
The initial part (namely, the Kruskal Wallis test) of the statistical analysis showed promising results by highlighting the statistically significance of 8 out of 10 parameters, while the second part (post-hoc tests) enhanced which type of pathology was the most discernible according to the analyzed parameters: T was the most different class according to our features. These results were particularly surprising because, despite having only 10 subjects per group, almost all the features resulted highly statistically significant and therefore strongly showed to distinguish the presented subject classes. The performed statistical analyses are an extension of these presented in our previous work [
1] and corroborate the feature importance evidence reported in
Figure 2; indeed, P and V proved non-significant and of less importance.
The ML analysis aimed at creating reliable models to classify the 50 patients; the KNN algorithm achieved the highest evaluation metrics followed by ADA-B. Both overcame a 90% overall accuracy, demonstrating the average reliability of the tested algorithms was overall high. There were two reasons for preferring a ML analysis rather than a logistic regression: first, the logistic regression requires 3 assumptions–Multicollinearity, absence of outliers and a ratio 1:10 between variables and patients [
52]. While there are no assumptions for a ML analysis; furthermore, it has been demonstrated empirically that a ML analysis can outperform a multinomial logistic regression [
17].
In the “Introduction” and “Poincaré plot analysis” sections we described the motivations which have pushed investigations to perform objective evaluations of Poincaré maps to derive new quantitative parameters; these could support to reveal hidden patterns in various disease conditions. Moridani and co-workers also presented novel 2D features extracted from Poincaré maps (and related graphs which the authors labeled “return maps”) of 80 cardiovascular patients. The three presented features demonstrated the most appropriate (compared to traditional and conventional Poincaré ones) to predict differences in HRV signals of patients in different time windows before death, representing a potential tool to save intensive care units patients in the future [
53].
Considering similar intentions, the combination of goals, analyses and the chosen Poincaré-related features offers a novel solution for the application of ML strategies in the cardiovascular field. Indeed, to our best knowledge, this is the first research study which proposes the opportunity to classify healthy subjects and patients affected by 4 different cardiac pathologies considering only a set of geometrical 2D and 3D parameters extracted from Poincaré maps. The following paragraphs will validate the previous claims presenting similar studies which investigated ML multi-group classifications but investigating also features belonging to the temporal and spatial domain of HRV.
Rezaei and co-workers assessed in a recent conference paper the potential use of kNN to distinguish 4 classes of subjects, one of normal sinus rhythm patients and others collecting subjects affected by three pathologies, namely atrial fibrillation, acute myocardial infarction and CHF, respectively. The authors extracted from Poincaré maps 16 features which were subsequently statistically evaluated and fed to a kNN algorithm. A combination of 2 conventional and 2 unconventional Poincaré based parameters proved to correctly separate (with scores higher than 90%) the cardiac signals belonging to different patients’ classes [
54].
Agliari and co-workers investigated a similar multi-group classification using a multi-layer feed-forward neural network [
50]. The study considered more than 2200 patients with 4 possible outcomes: healthy, atrial fibrillation, congestive decompensation and other pathologies (among which it can be highlighted the I class). The authors considered only one of the 2 Poincaré parameters (described also by Rezaei and co-workers [
54]) after a correlation analysis between the 49 initial collected features [
55].
Another remarkable example has been proposed by Devi and co-workers. They considered the same 2 “classical” Poincaré parameters yet mentioned (and their ratio too) as potential indicators for the prediction of sudden cardiac death. The authors analyzed several archived ECG of normal subjects and patients (which suffered/non suffered of sudden death) affected by cardiovascular diseases. Although the authors initially included the Poincaré parameters in the feature set, a subsequent feature selection step (using a hybrid approach of unsupervised and sampling-boosting ensemble learning techniques) excluded such features from the optimal subset. However, the overall approach demonstrated effective to distinguish sudden death patients from merely heart failure ones and healthy controls with a satisfactory accuracy of 83.33% using fine and weighted kNN algorithms [
56].
Recently, Leite and co-workers investigated the NOLTISALIS database designing a multi-group study to classify H, C and T patients. The authors used an improved recurrent neural network fed by six “time sequences of features”. The methodology achieved promising results for both the training set (96.7%) and the test set (86.7%) [
57]. When comparing these results with those in this paper, on the test set the authors accuracies result lower than ours, while we both have achieved 100% of sensitivity; nevertheless, a direct comparison is not completely fair since we considered five groups and we applied SMOTE for data augmentation.
The most recent, similar contribution was presented by D’Addio and co-workers [
58] where the authors showed NB, ADA-B and KNN (listed considering increasing sensitivities) effectively classified C patients’ severity based on New York Heart Association functional classification, using the same unconventional features extracted from bi-dimensional and three-dimensional Poincaré Plots. Their accuracies and, generally, the overall evaluation metrics are lower than ours in this study but, again, a direct comparison is not completely fair since we considered a different target and we applied SMOTE for data augmentation.
However, these studies should be considered as pilot ones, because the respective authors always highlighted new investigations with larger dataset should be carried out as verifications.
5. Conclusions
In conclusion, this paper demonstrates–Again, corroborating the promising results obtained in our previous conference papers for the same [
1] or a similar goal [
58,
59]–ML strategies could be effectively implemented to support specialists in discriminating healthy subjects from patients which are potentially affected by either H, M or C, or underwent a T previously. kNN, ADA-B and GB proved fully valid for the scope presenting high performances with score peaks in different indicators which could potentially suggest the adoption of a precise algorithm between those proposed. Additionally, we also found the multinomial logistic regression demonstrated useful to prove–without using any ML algorithm–the goodness of the Poincaré related features.
We remark the main novelty is represented by the implementation of a 5-class investigation using only unconventional geometrical Poincaré parameters; to best of the authors’ knowledge, the paper presented by Pinho and co-workers is the only example in the field of a multi-group classification considering more than 5 categories of heart diseases [
60]. Nevertheless, the authors do not consider features extracted from Poincaré maps for their scope; therefore, a direct comparison is not possible.
Despite not pursuing the same aims of our research, we compared other works found in literature with ours. Rezaei and co-workers obtained evaluation metrics compatible with the result presented in this manuscript [
54]. Differently, Devi and co-workers achieved an 83.3% of accuracy in detecting patients suffering from sudden death, while Agliari and co-workers exhibited an accuracy up to 85% with a multi-group classification by means of neural networks [
55,
56]. Finally, Leite and co-workers achieved with a similar methodology comparable result on the NOLTISALIS database (similar objective, but different features), nevertheless excluding the H and M groups [
57].
Of course, even our study exhibited limitations. First, the dataset was clearly small, and this could represent a limitation for both the statistical analysis and ML analyses. For this reason, SMOTE was applied allowing us to conduct the modeling analysis through ML, although SMOTE itself could be considered a limitation, too. Nevertheless, both these could be addressed in the future by increasing the number of patients. Another part of the strategy, which could provide our methodology with more value, could be even the use of shorter ECG acquisitions (e.g., up to a minimum of 30 min) as to strengthen the predictive power of our features.


 ,
, 





{kind=link}
{kind=link}