
Convincing 3D Face Reconstruction from a Single Color Image under Occluded Scenes

Abstract
:1. Introduction
- We propose a novel approach that combines the face parsing approach and face contour map to generate a face with complete facial features.
- Face occlusion is a common problem. In response to the problem of an invisible face area under occluded scenes, we propose synthesizing the input face image based on GANS rather than reconstructing the 3D face directly.
- We improved the loss function of our 3D face reconstruction framework for occluded scenes. Our results (especially the face texture) are more accurate than other recent methods.
2. Related Work
2.1. Single-View 3D Face Shape Prediction
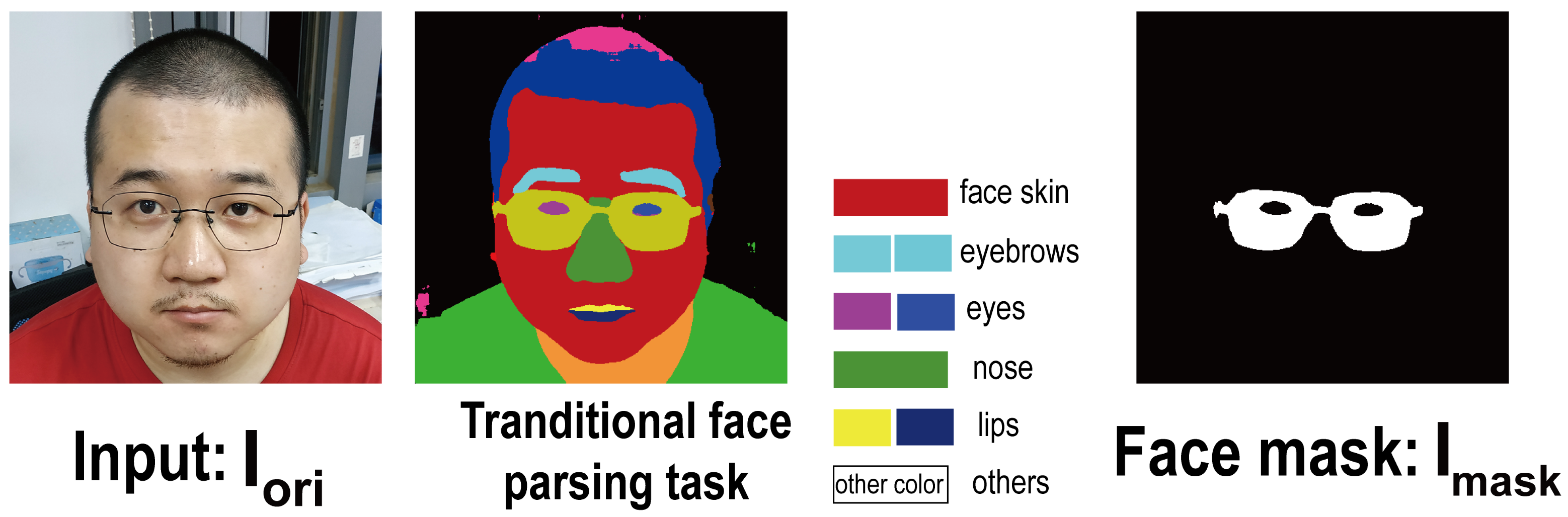
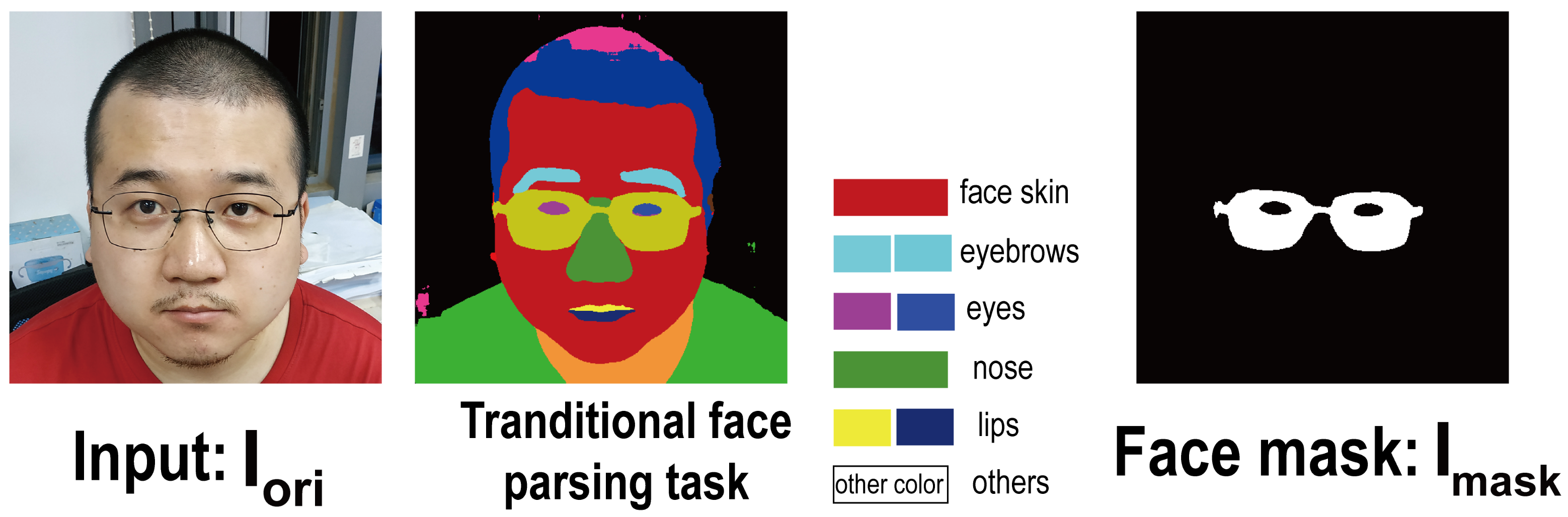
2.2. Face Parsing
2.3. Generative Adversarial Networks
2.4. Face Image Synthesis
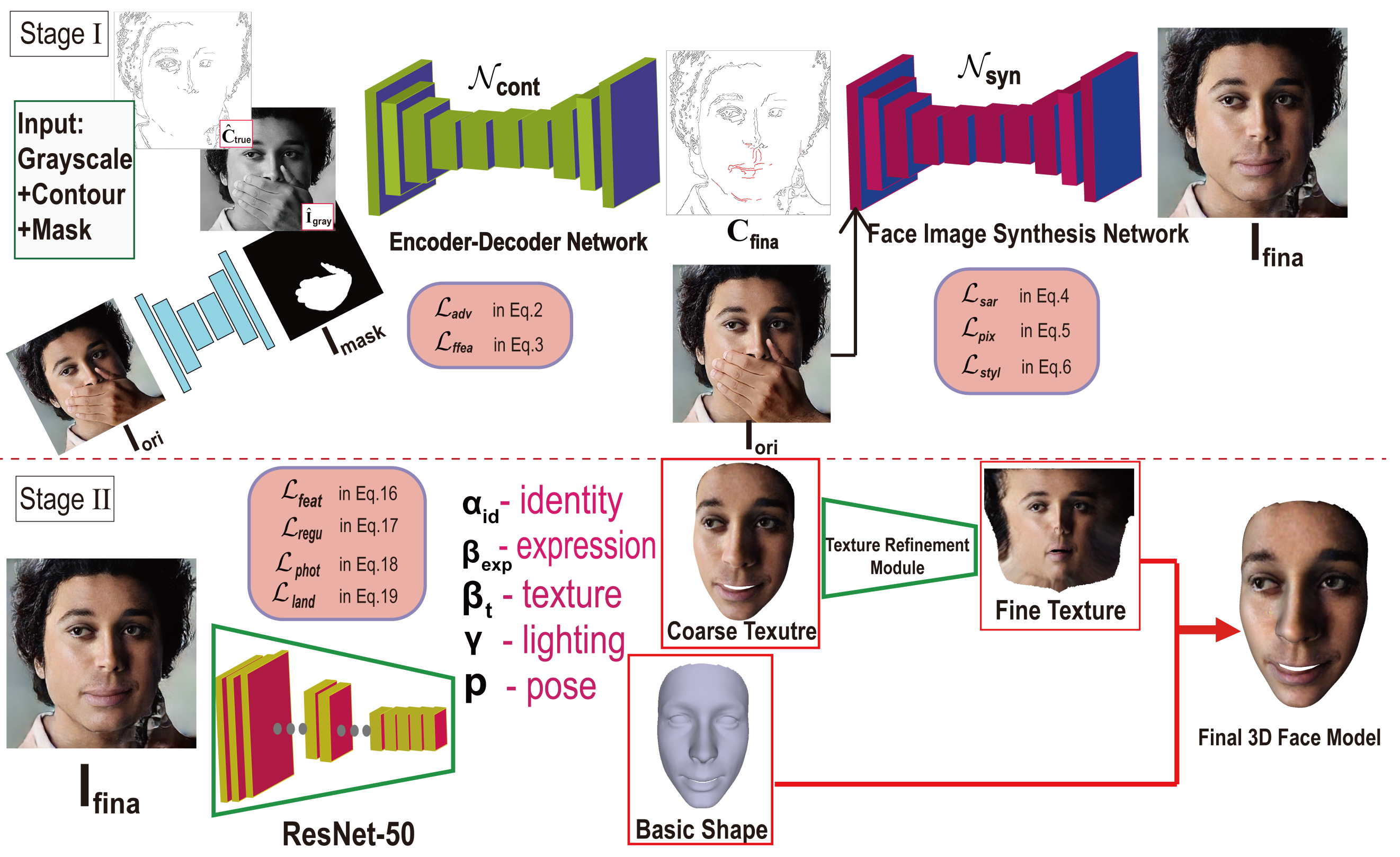
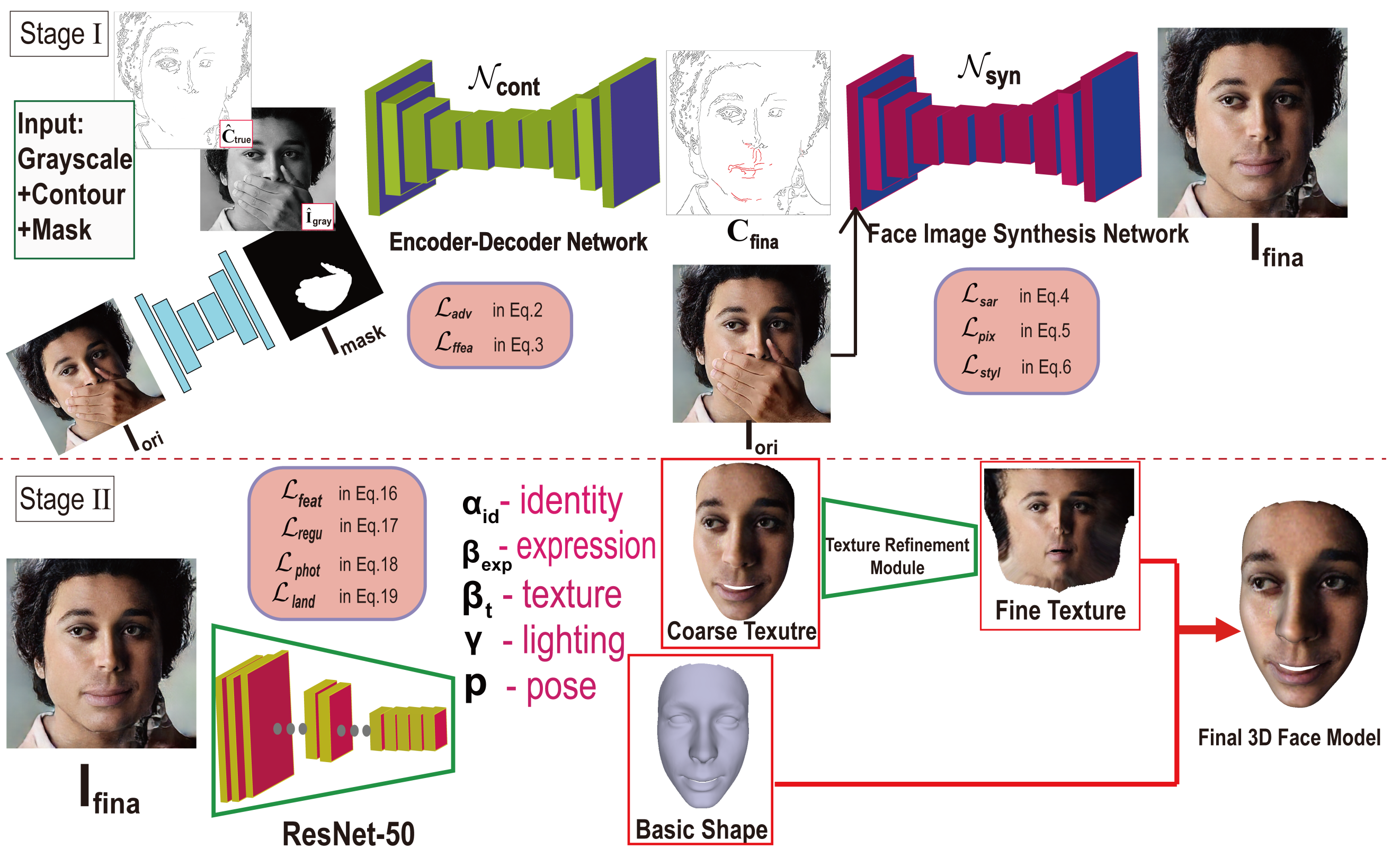
3. Our Method
- In response to the occlusion area, synthesizing the 2D face with complete facial features.
- Detailed 3D shape reconstruction module based on unobstructed frontal images.
3.1. Face Mask Generation
3.2. Face Image Synthesis with GANs
3.3. 3D Shape Model
3.4. Camera and Illumination Model
3.5. Loss Function of Shape Reconstruction
4. Implementation Details
5. Experimental Results
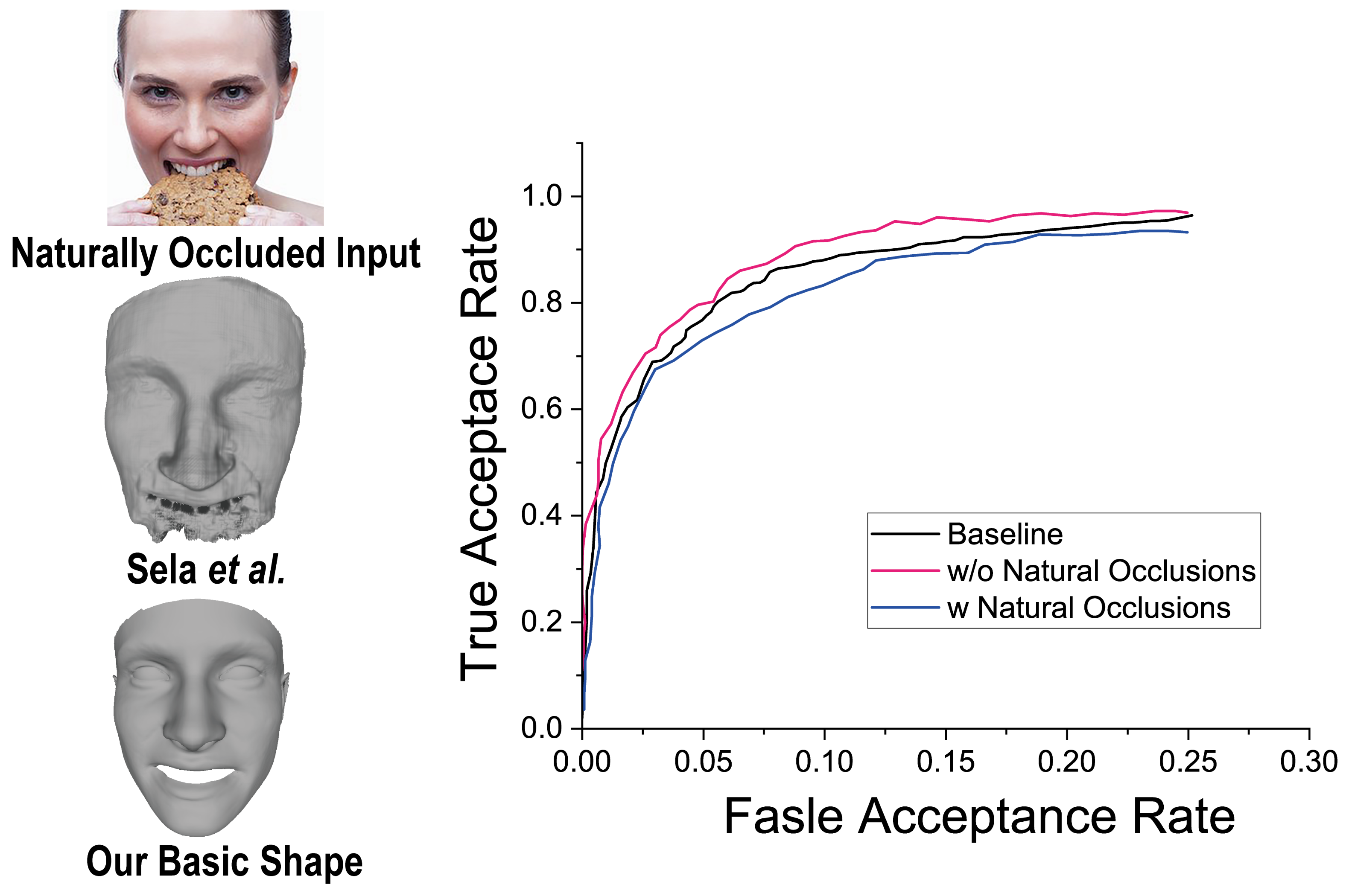
5.1. Qualitative Comparisons with Recent Arts
5.2. Ablation Study
5.3. Quantitative Comparison
5.3.1. Comparison Result on the MICC Florence Datasets
5.3.2. Quantitative Comparison
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Blanz, V.; Vetter, T. Face recognition based on fitting a 3d morphable model. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1063–1074. [Google Scholar] [CrossRef] [Green Version]
- Tuan Tran, A.; Hassner, T.; Masi, I.; Medioni, G. Regressing robust and discriminative 3D morphable models with a very deep neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5163–5172. [Google Scholar]
- Gilani, S.Z.; Mian, A. Learning from millions of 3D scans for large-scale 3D face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1896–1905. [Google Scholar]
- Hu, Y.; Jiang, D.; Yan, S.; Zhang, L. Automatic 3D reconstruction for face recognition. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 19 May 2004; pp. 843–848. [Google Scholar]
- Liu, X.; Chen, T. Pose-robust face recognition using geometry assisted probabilistic modeling. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 502–509. [Google Scholar]
- Wang, S.; Cheng, Z.; Deng, X.; Chang, L.; Duan, F.; Lu, K. Leveraging 3D blendshape for facial expression recognition using CNN. Sci. China Inf. Sci 2020, 63, 120114. [Google Scholar] [CrossRef] [Green Version]
- Cao, C.; Hou, Q.; Zhou, K. Displaced dynamic expression regression for real-time facial tracking and animation. ACM Trans. Graph. (TOG) 2014, 33, 1–10. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, J.; Liu, Z.; Liu, Y.; Wang, X. Rotate-and-Render: Unsupervised Photorealistic Face Rotation from Single-View Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5911–5920. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. 2015. Available online: https://www.robots.ox.ac.uk/~vgg/publications/2015/Parkhi15/parkhi15.pdf (accessed on 30 December 2021).
- Tuan Tran, A.; Hassner, T.; Masi, I.; Paz, E.; Nirkin, Y.; Medioni, G. Extreme 3d face reconstruction: Seeing through occlusions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3935–3944. [Google Scholar]
- Blanz, V.; Vetter, T. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 8–13 August 1999; Volume 99, pp. 187–194. [Google Scholar]
- Paysan, P.; Knothe, R.; Amberg, B.; Romdhani, S.; Vetter, T. A 3D face model for pose and illumination invariant face recognition. In Proceedings of the 2009 Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, Genova, Italy, 2–4 September 2009; pp. 296–301. [Google Scholar]
- Liang, S. Data-Driven Approaches for Personalized Head Reconstruction. Ph.D. Thesis, University of Washington, Seattle, WA, USA, 2018. [Google Scholar]
- Cootes, T.F.; Edwards, G.J.; Taylor, C.J. Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 681–685. [Google Scholar] [CrossRef] [Green Version]
- Saragih, J.; Goecke, R. A nonlinear discriminative approach to AAM fitting. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Tzimiropoulos, G.; Pantic, M. Optimization problems for fast aam fitting in-the-wild. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 593–600. [Google Scholar]
- Cristinacce, D.; Cootes, T.F. Feature detection and tracking with constrained local models. Bmvc 2006, 1, 3. [Google Scholar]
- Asthana, A.; Zafeiriou, S.; Cheng, S.; Pantic, M. Robust discriminative response map fitting with constrained local models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3444–3451. [Google Scholar]
- Saragih, J.M.; Lucey, S.; Cohn, J.F. Deformable model fitting by regularized landmark mean-shift. Int. J. Comput. Vis. 2011, 91, 200–215. [Google Scholar] [CrossRef]
- Kowalski, M.; Naruniec, J.; Trzcinski, T. Deep alignment network: A convolutional neural network for robust face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 June 2017; pp. 88–97. [Google Scholar]
- Liang, Z.; Ding, S.; Lin, L. Unconstrained facial landmark localization with backbone-branches fully-convolutional networks. arXiv 2015, arXiv:1507.03409. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Facial landmark detection by deep multi-task learning. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 94–108. [Google Scholar]
- Alp Guler, R.; Trigeorgis, G.; Antonakos, E.; Snape, P.; Zafeiriou, S.; Kokkinos, I. Densereg: Fully convolutional dense shape regression in-the-wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 6799–6808. [Google Scholar]
- Yu, R.; Saito, S.; Li, H.; Ceylan, D.; Li, H. Learning dense facial correspondences in unconstrained images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4723–4732. [Google Scholar]
- Jourabloo, A.; Liu, X. Large-pose face alignment via CNN-based dense 3D model fitting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4188–4196. [Google Scholar]
- Richardson, E.; Sela, M.; Kimmel, R. 3D face reconstruction by learning from synthetic data. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 460–469. [Google Scholar]
- Zhu, X.; Lei, Z.; Liu, X.; Shi, H.; Li, S.Z. Face alignment across large poses: A 3d solution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 146–155. [Google Scholar]
- Richardson, E.; Sela, M.; Or-El, R.; Kimmel, R. Learning detailed face reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 1259–1268. [Google Scholar]
- Liu, F.; Zeng, D.; Zhao, Q.; Liu, X. Joint face alignment and 3D face reconstruction. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 545–560. [Google Scholar]
- Feng, Y.; Wu, F.; Shao, X.; Wang, Y.; Zhou, X. Joint 3d face reconstruction and dense alignment with position map regression network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 534–551. [Google Scholar]
- Johnson, J.; Gupta, A.; Li, F.-F. Image generation from scene graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1219–1228. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 1125–1134. [Google Scholar]
- Pan, J.; Wang, C.; Jia, X.; Shao, J.; Sheng, L.; Yan, J.; Wang, X. Video generation from single semantic label map. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3733–3742. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2337–2346. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Salt Lake City, UT, USA, 18–23 June 2018; pp. 801–818. [Google Scholar]
- Wei, Z.; Sun, Y.; Wang, J.; Lai, H.; Liu, S. Learning adaptive receptive fields for deep image parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Venice, Italy, 22–29 October 2017; pp. 2434–2442. [Google Scholar]
- Lee, C.H.; Liu, Z.; Wu, L.; Luo, P. Maskgan: Towards diverse and interactive facial image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5549–5558. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 3730–3738. [Google Scholar]
- Zhou, L.; Liu, Z.; He, X. Face parsing via a fully-convolutional continuous CRF neural network. arXiv 2017, arXiv:1708.03736. [Google Scholar]
- Yin, Z.; Yiu, V.; Hu, X.; Tang, L. End-to-end face parsing via interlinked convolutional neural networks. Cogn. Neurodyn. 2021, 15, 169–179. [Google Scholar] [CrossRef] [PubMed]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Shen, W.; Liu, R. Learning residual images for face attribute manipulation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 4030–4038. [Google Scholar]
- Li, M.; Zuo, W.; Zhang, D. Deep identity-aware transfer of facial attributes. arXiv 2016, arXiv:1610.05586. [Google Scholar]
- Xiao, T.; Hong, J.; Ma, J. Elegant: Exchanging latent encodings with gan for transferring multiple face attributes. In Proceedings of the European Conference on Computer Vision (ECCV), Salt Lake City, UT, USA, 18–23 June 2018; pp. 168–184. [Google Scholar]
- He, Z.; Zuo, W.; Kan, M.; Shan, S.; Chen, X. Attgan: Facial attribute editing by only changing what you want. arXiv 2017, arXiv:1711.10678. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, J.; Yang, H.; Chen, D.; Zeng, M.; Wen, F.; Yuan, L. Face Parsing with RoI Tanh-Warping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5654–5663. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Krähenbühl, P.; Shechtman, E.; Efros, A.A. Generative visual manipulation on the natural image manifold. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 597–613. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. arXiv 2017, arXiv:1703.00848. [Google Scholar]
- Demir, U.; Unal, G. Patch-based image inpainting with generative adversarial networks. arXiv 2018, arXiv:1803.07422. [Google Scholar]
- Frühstück, A.; Alhashim, I.; Wonka, P. TileGAN: Synthesis of large-scale non-homogeneous textures. ACM Trans. Graph. (TOG) 2019, 38, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 702–716. [Google Scholar]
- Slossberg, R.; Shamai, G.; Kimmel, R. High quality facial surface and texture synthesis via generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Pizzati, F.; Cerri, P.; de Charette, R. CoMoGAN: Continuous model-guided image-to-image translation. arXiv 2021, arXiv:2103.06879. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Dapeng, Z.; Yue, Q. Generative Contour Guided Occlusions Removal 3D Face Reconstruction. In Proceedings of the 2021 International Conference on Virtual Reality and Visualization (ICVRV), Nanchang, China, 17–20 October 2021; pp. 74–79. [Google Scholar]
- Dapeng, Z.; Yue, Q. Learning Detailed Face Reconstruction Under Occluded Scenes. In Proceedings of the 2021 International Conference on Virtual Reality and Visualization (ICVRV), Nanchang, China, 17–20 October 2021; pp. 80–84. [Google Scholar]
- Dapeng, Z.; Yue, Q. Generative Landmarks Guided Eyeglasses Removal 3D Face Reconstruction. In International Conference on Multimedia Modeling; Springer: Berlin/Heidelberg, Germany, 2022; pp. 111–122. [Google Scholar]
- Zhao, D.; Qi, Y. Generative Face Parsing Map Guided 3D Face Reconstruction Under Occluded Scenes. In Advances in Computer Graphics; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 252–263. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Dolhansky, B.; Ferrer, C.C. Eye in-painting with exemplar generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7902–7911. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. Edgeconnect: Generative image inpainting with adversarial edge learning. arXiv 2019, arXiv:1901.00212. [Google Scholar]
- Song, Y.; Yang, C.; Lin, Z.; Liu, X.; Huang, Q.; Li, H.; Kuo, C.C.J. Contextual-based image inpainting: Infer, match, and translate. In Proceedings of the European Conference on Computer Vision (ECCV), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3–19. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Yang, Y.; Guo, X.; Ma, J.; Ma, L.; Ling, H. LaFIn: Generative Landmark Guided Face Inpainting. arXiv 2019, arXiv:1911.11394. [Google Scholar]
- Sajjadi, M.S.; Scholkopf, B.; Hirsch, M. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017; pp. 4491–4500. [Google Scholar]
- Ramamoorthi, R.; Hanrahan, P. An efficient representation for irradiance environment maps. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 8–13 August 2001; pp. 497–500. [Google Scholar]
- Ramamoorthi, R.; Hanrahan, P. A signal-processing framework for inverse rendering. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 8–13 August 2001; pp. 117–128. [Google Scholar]
- Müller, C. Spherical Harmonics; Springer: Berlin/Heidelberg, Germany, 2006; Volume 17. [Google Scholar]
- Deng, Y.; Yang, J.; Xu, S.; Chen, D.; Jia, Y.; Tong, X. Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, J.; Yuan, Y.; Shao, T.; Zhou, K. Towards High-Fidelity 3D Face Reconstruction from In-the-Wild Images Using Graph Convolutional Networks. arXiv 2020, arXiv:2003.05653. [Google Scholar]
- Genova, K.; Cole, F.; Maschinot, A.; Sarna, A.; Vlasic, D.; Freeman, W.T. Unsupervised training for 3d morphable model regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8377–8386. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Tewari, A.; Zollhöfer, M.; Garrido, P.; Bernard, F.; Kim, H.; Pérez, P.; Theobalt, C. Self-supervised multi-level face model learning for monocular reconstruction at over 250 hz. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2549–2559. [Google Scholar]
- Tewari, A.; Zollhofer, M.; Kim, H.; Garrido, P.; Bernard, F.; Perez, P.; Theobalt, C. Mofa: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1274–1283. [Google Scholar]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Nirkin, Y.; Masi, I.; Tuan, A.T.; Hassner, T.; Medioni, G. On face segmentation, face swapping, and face perception. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 98–105. [Google Scholar]
- Wang, X.; Guo, Y.; Deng, B.; Zhang, J. Lightweight Photometric Stereo for Facial Details Recovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 740–749. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017; pp. 1021–1030. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- Guo, J.; Zhu, X.; Yang, Y.; Yang, F.; Lei, Z.; Li, S.Z. Towards Fast, Accurate and Stable 3D Dense Face Alignment. arXiv 2020, arXiv:2009.09960. [Google Scholar]
- Zeng, X.; Peng, X.; Qiao, Y. DF2Net: A Dense-Fine-Finer Network for Detailed 3D Face Reconstruction. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 2315–2324. [Google Scholar]
- Chen, A.; Chen, Z.; Zhang, G.; Mitchell, K.; Yu, J. Photo-realistic facial details synthesis from single image. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9429–9439. [Google Scholar]
- Bagdanov, A.D.; Del Bimbo, A.; Masi, I. The florence 2d/3d hybrid face dataset. In Proceedings of the 2011 Joint ACM Workshop on Human Gesture and Behavior Understanding, New York, NY, USA, 1 December 2011; pp. 79–80. [Google Scholar]
- Cao, C.; Weng, Y.; Zhou, S.; Tong, Y.; Zhou, K. Facewarehouse: A 3d facial expression database for visual computing. IEEE Trans. Vis. Comput. Graph. 2013, 20, 413–425. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the Workshop on Faces in’Real-Life’Images: Detection, Alignment, and Recognition, Marseille, France, 17 October 2008. [Google Scholar]
- Sela, M.; Richardson, E.; Kimmel, R. Unrestricted facial geometry reconstruction using image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017; pp. 1576–1585. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Loss Function | MICC | Face Warehous | |||
|---|---|---|---|---|---|
| ✓ | − | − | ✓ | ||
| − | ✓ | ✓ | − | ||
| ✓ | − | ✓ | ✓ | ||
| − | ✓ | ✓ | − | ||
| ✓ | ✓ | ✓ | ✓ | ||
| Method | 100%-EER | Accuracy | nAUC |
|---|---|---|---|
| Tran et al. | |||
| Our Shape and occlusions | |||
| Ours(w/Occ) | |||
| Ours(w/o Occ) | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, D.; Cai, J.; Qi, Y. Convincing 3D Face Reconstruction from a Single Color Image under Occluded Scenes. Electronics 2022, 11, 543. https://doi.org/10.3390/electronics11040543
Zhao D, Cai J, Qi Y. Convincing 3D Face Reconstruction from a Single Color Image under Occluded Scenes. Electronics. 2022; 11(4):543. https://doi.org/10.3390/electronics11040543
Chicago/Turabian StyleZhao, Dapeng, Jinkang Cai, and Yue Qi. 2022. "Convincing 3D Face Reconstruction from a Single Color Image under Occluded Scenes" Electronics 11, no. 4: 543. https://doi.org/10.3390/electronics11040543
APA StyleZhao, D., Cai, J., & Qi, Y. (2022). Convincing 3D Face Reconstruction from a Single Color Image under Occluded Scenes. Electronics, 11(4), 543. https://doi.org/10.3390/electronics11040543