
Enhancing Knowledge of Propagation-Perception-Based Attention Recommender Systems

 ,
,  ,
,
Abstract
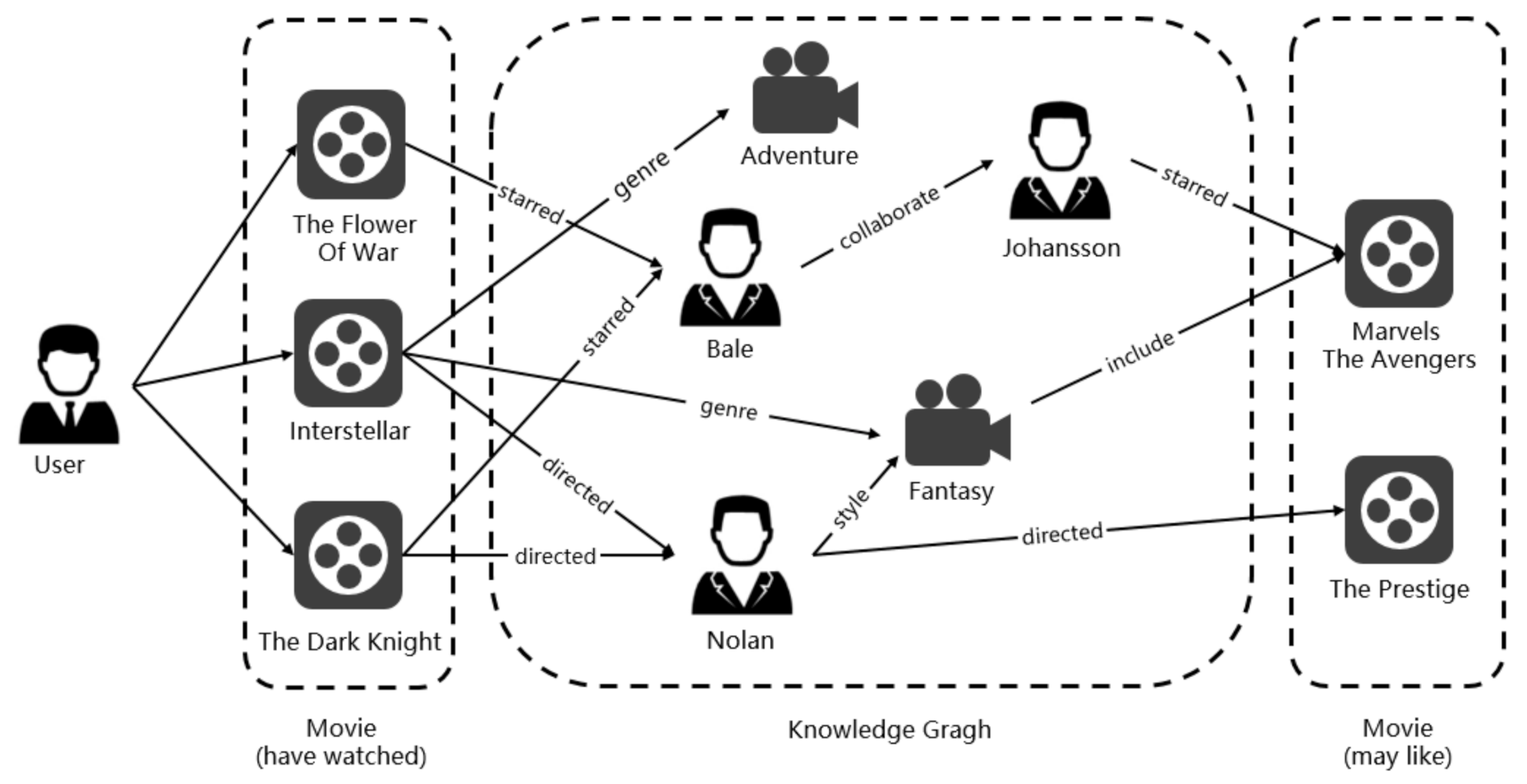
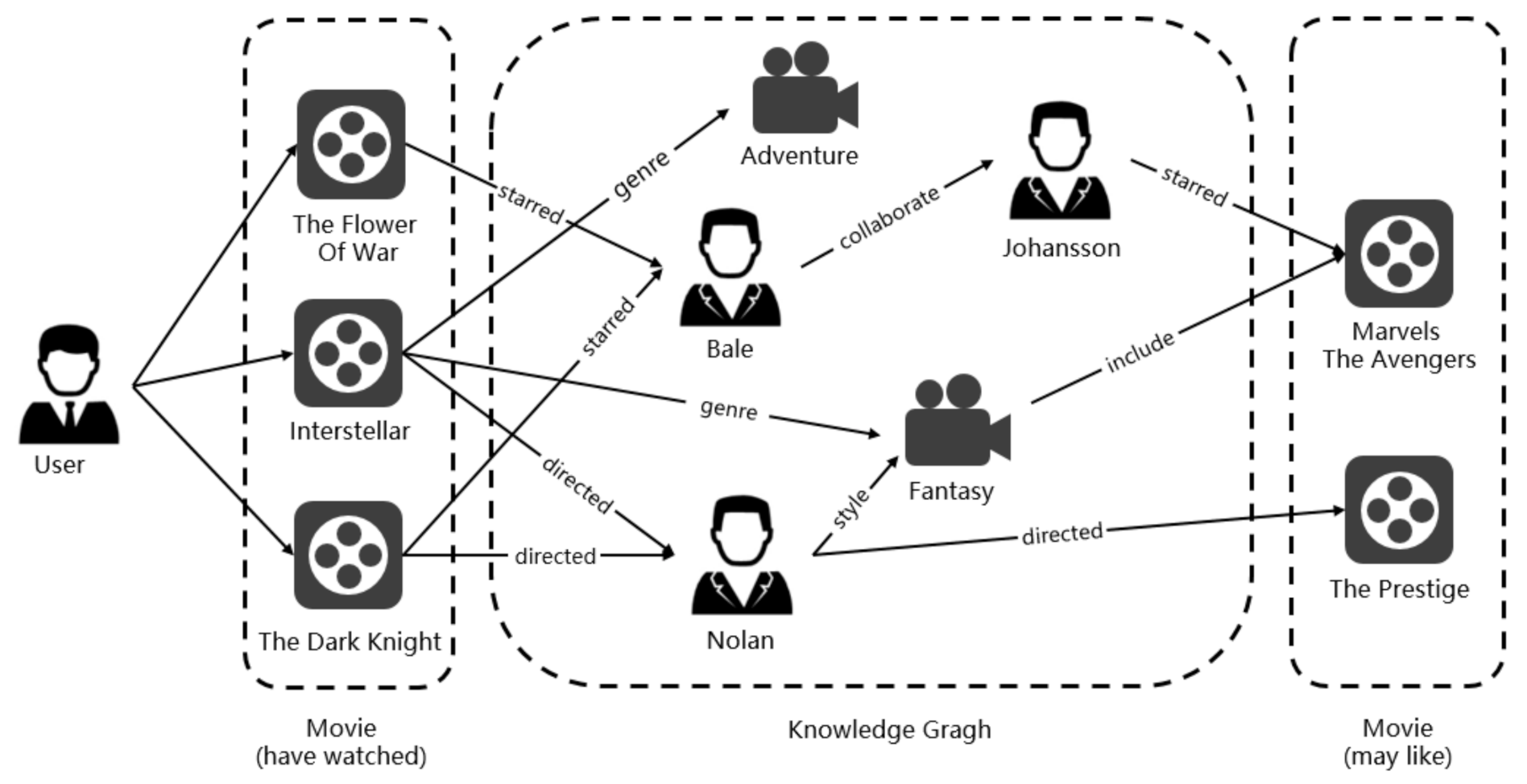
:1. Introduction
- We design an attention mechanism with asymmetric semantics in EKPNet for the KG propagation. It enhances the mining of user preferences by mapping the semantics of head and tail entities into different preference spaces.
- A new communication exploration framework has been proposed. The deep learning network is used to explore the entity characteristics of different depth propagation aggregates in the KG. It balances both the memorization and generalization of features, and adaptively adjusts the weights to different depths.
- We test our model through a large number of experiments on two real-world public datasets. Compared with several state-of-the-art baselines in multiple indicators, EKPNet has a substantial improvement.
2. Related Work
2.1. Knowledge Graph-Based Recommender
2.2. Attention Mechanism
3. Preliminaries
3.1. Implicit Feedback
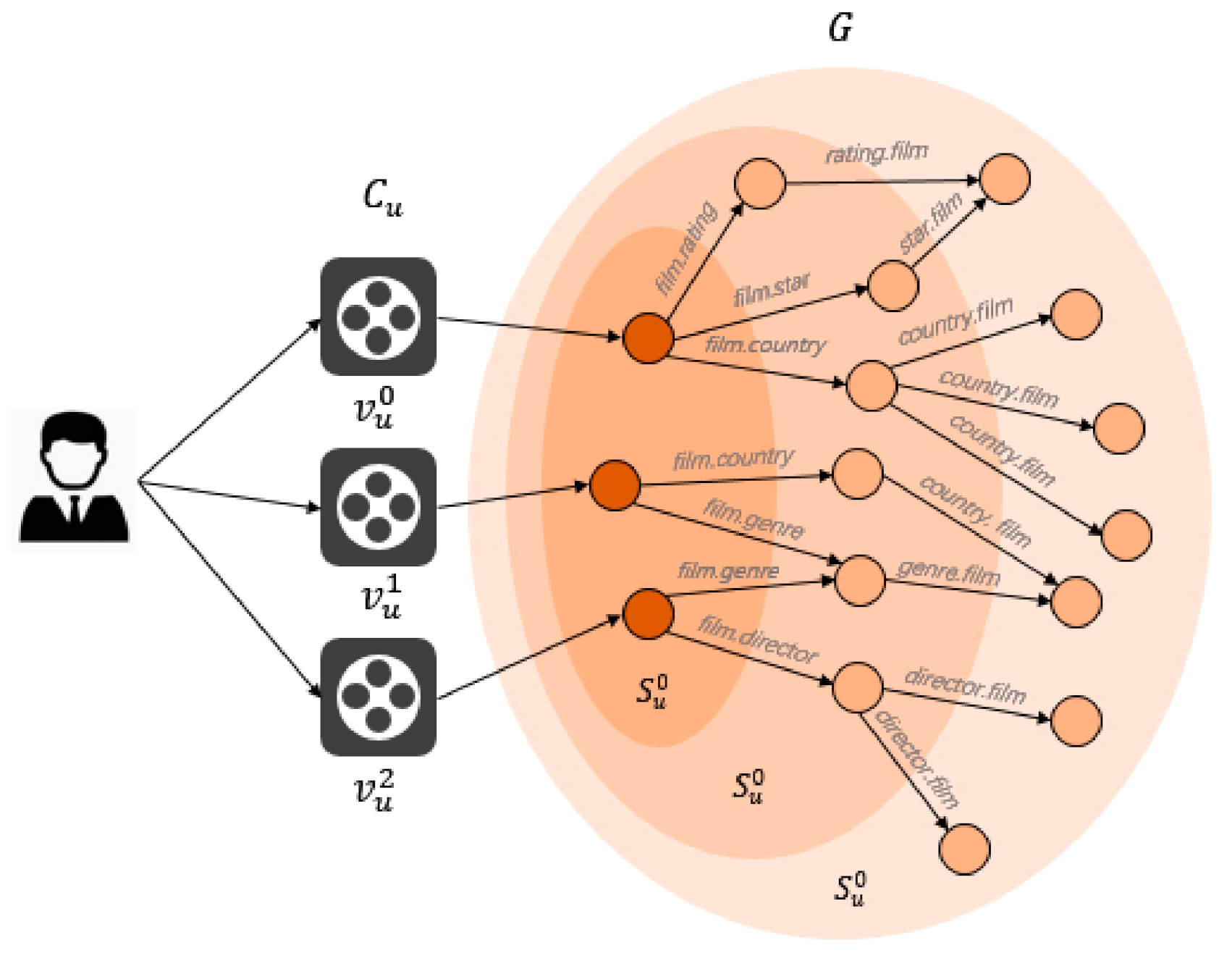
3.2. Knowledge Graph
3.3. Problem Formulation
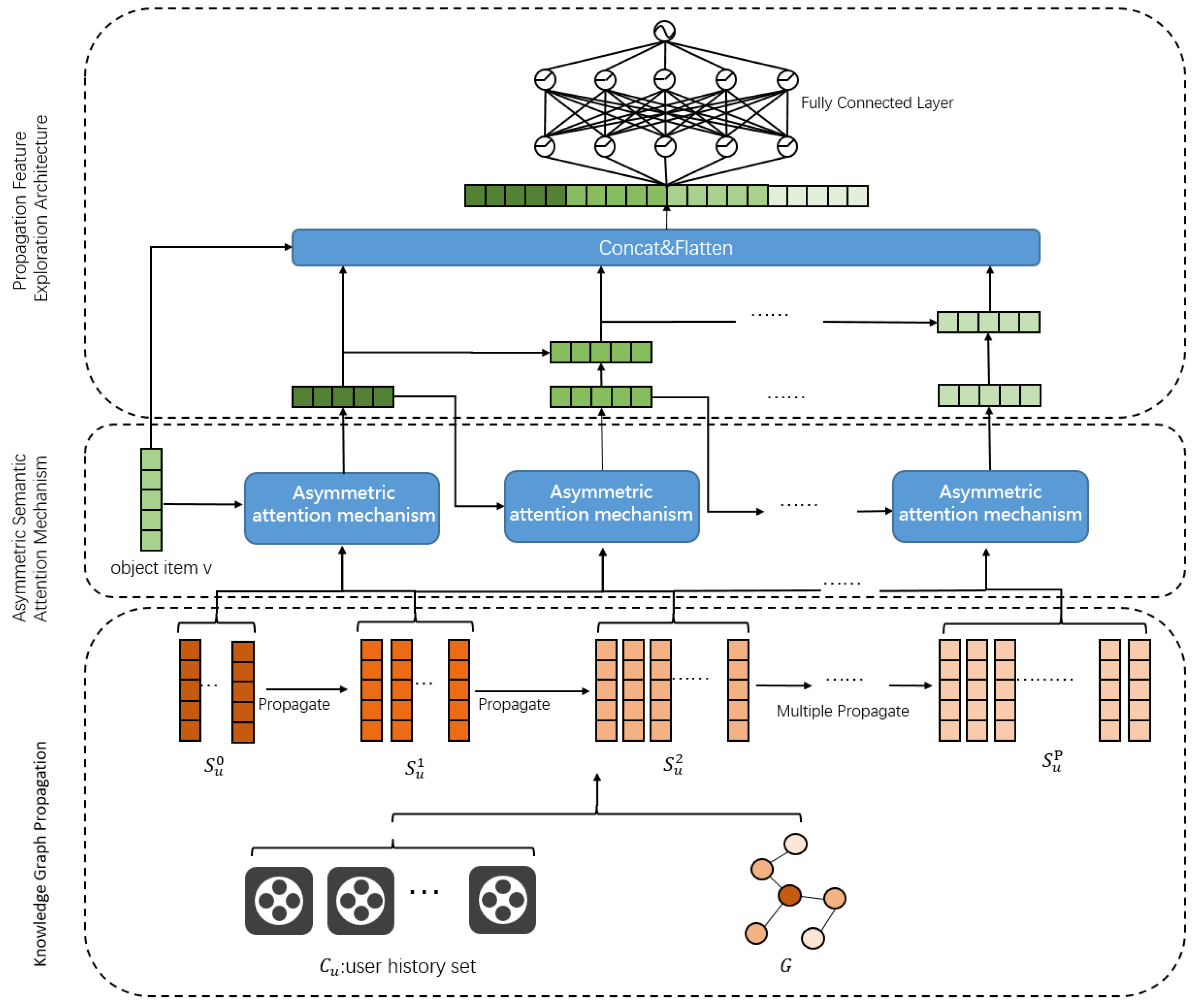
4. The Proposed Method
4.1. Knowledge Graph Propagation
4.2. Asymmetric Semantic Attention Mechanism
4.3. Propagation Feature Exploration Architecture
4.4. Learning Algorithm
| Algorithm 1 Learning in the pre-training for EKPNet |
| Input: implicit feedback matrix Y, knowledge graph G Set: batch size b, learning rate α, dimensionality k
|
| Output: Parameters of the model |
| Algorithm 2 EKPNet Learning Algorithm |
| Input: implicit feedback matrix Y, knowledge graph G, The parameters of Algorithm 1. Set: batch size b, learning rate α, dimensionality k |
|
| Output: results predictions |
5. Experimental Results and Discussion
5.1. Experiment Preparation
5.1.1. Dataset
5.1.2. Baseline
5.1.3. Experimental Settings
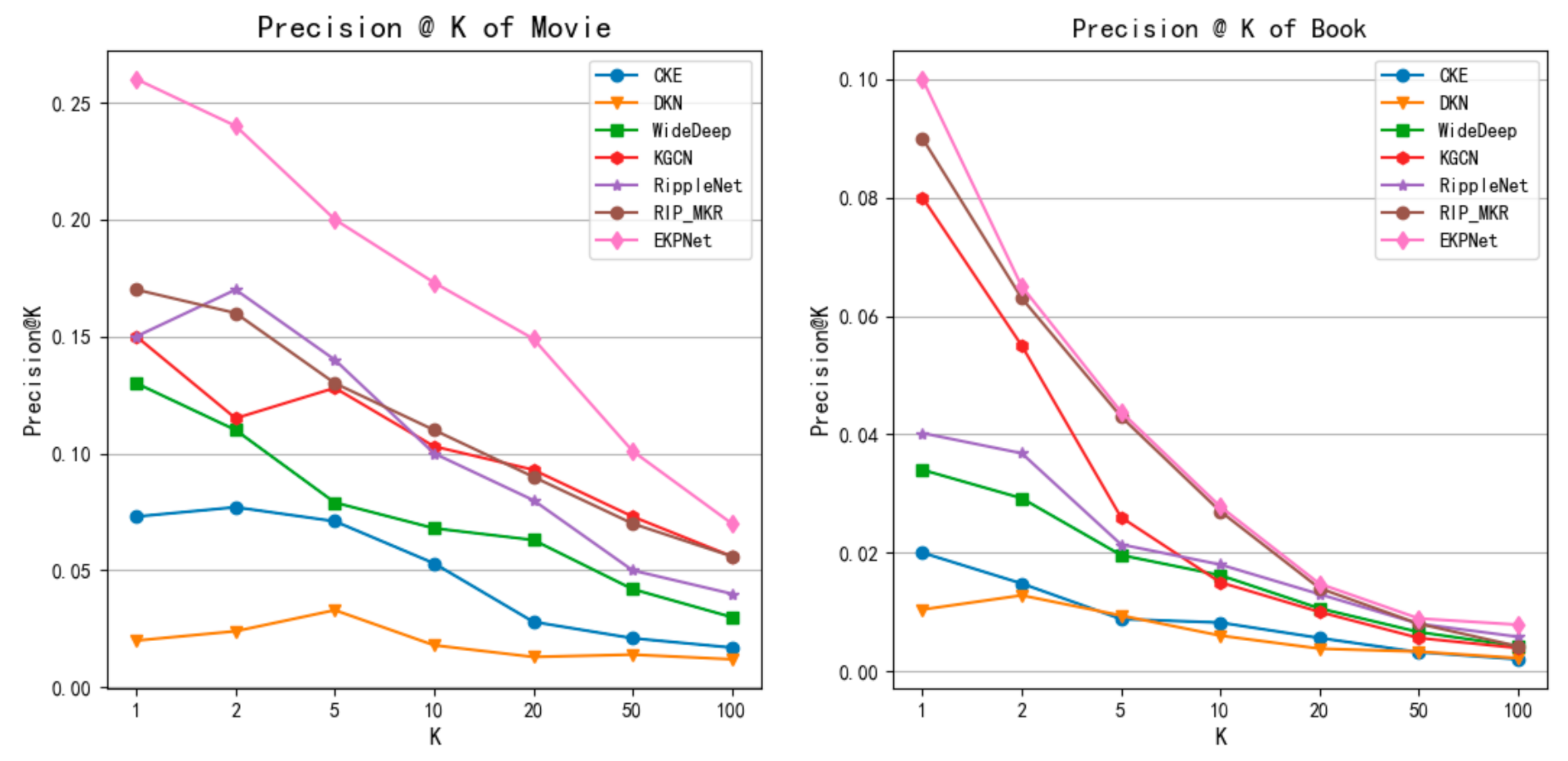
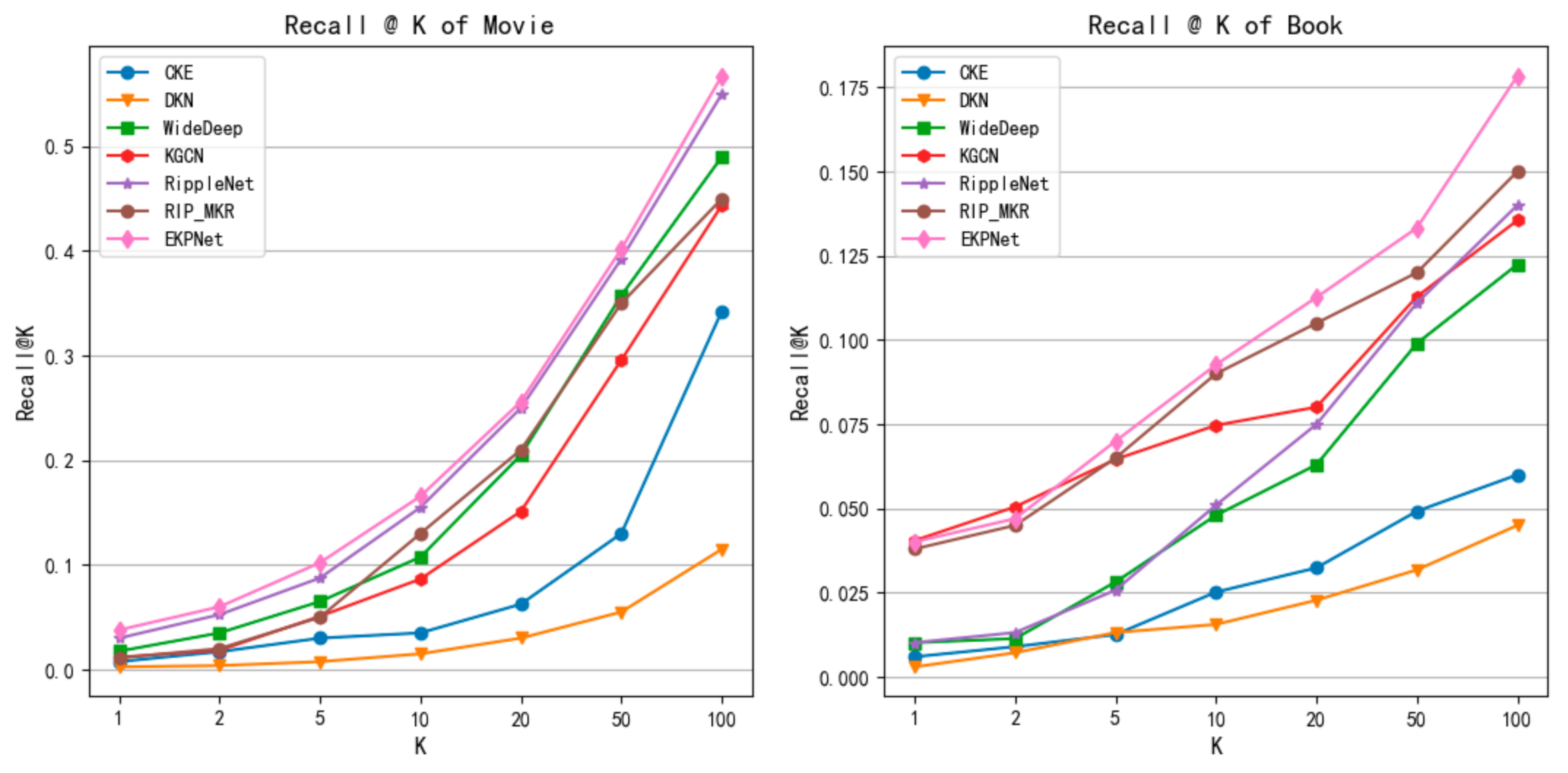
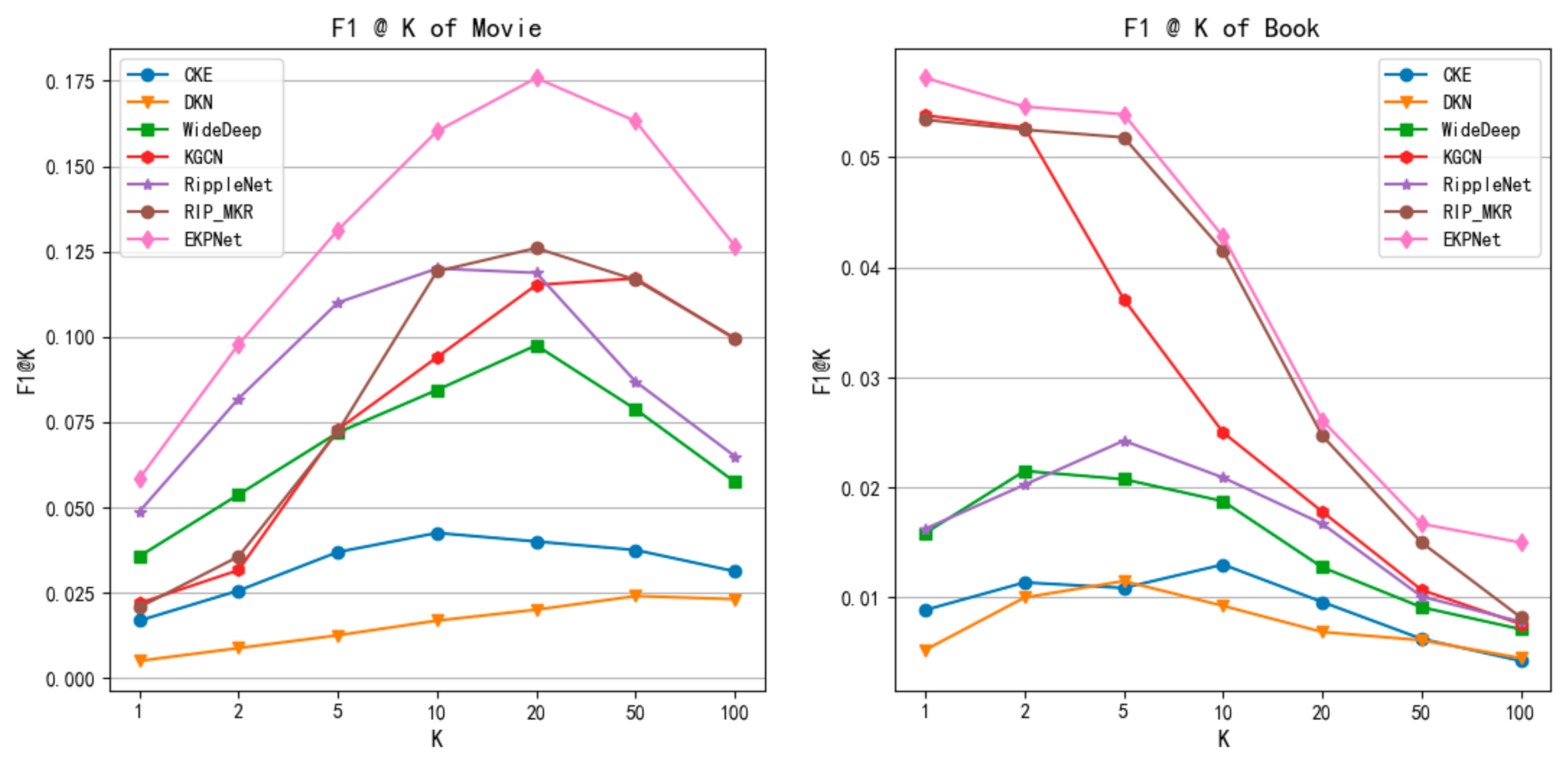
5.2. Experimental Results
- Compared with these state-of-the-art baselines, EKPNet has a better effect on datasets in two different fields. More specifically, the asymmetric semantic attention mechanism and the multi-level propagation feature exploration architecture play an active role in mining user preferences and providing recommended items. Compared with the effect of baseline on the MovieLens-1M and Book-Crossing datasets, EKPNet has average increased AUC values by 10.8% and 8.5%, and ACC by 11.2% and 7.1%.
- For the top-K task our model has a greater advantage on the MovieLens-1M dataset. Its relatively low sparsity in KG may lead to better training of the semantic vectors we introduced. Another reason why the EKPNet model improves less in the Book-Crossing dataset compared to Ripp-MKR is that Ripp-MKR introduces neural collaborative filtering, while the Book-Crossing dataset has more interaction information to assist joint learning. In addition, our model targets the CTR task and the cross-entropy loss used in the loss function, rather than the selection ranking loss, so there are some limitations for the ranking task.
- By observing the results between the two data, it is found that the results of the Book-Crossing dataset in all models are lower than the MovieLens-1M dataset. The main reason is shown in Table 3 in Section 5.1. On the one hand, in the user project interaction matrix, the Book-Crossing dataset has an average number of 117 fewer interactions per user than the MovieLens-1M dataset, with a difference of 5.05% in sparsity. On the other hand, in the knowledge graph dataset of the two data, the Book-Crossing dataset has an average of four fewer links per entity than the MovieLens-1M dataset. The sparse data make each model have insufficient information to explore the characteristics of user items and its performance is not satisfactory.
- Compared with other baselines, DKN’s method is overwhelmed by most models, because compared with news titles, the names of movies and books are shorter, the information contained is very limited, and it is difficult to reflect the characteristics of movies or books.
- The poor performance of the CKE model for us may be due to the lack of image and text information in the data, which limits the expression of the model. Then, unlike RippleNet and EKPNet, the model only directly uses related entities to represent features, and does not use related entities to enrich feature representations.
- Compared with the above two baselines, Deep&Wide achieved relatively good results, indicating that deep learning obtains better results in exploring the intersection of entity features. However, compared with the other three unification-based methods the results are poor, and it can be seen that exploring the knowledge graph is crucial for the prediction results.
- RippleNet, KGCN and Ripp-MKR exhibit the best performances among all the baselines. Therefore, it is proved that exploring structural information in the knowledge graph can effectively improve the model effect.
- EKPNet has a clear advantage over RippleNet and Ripp-MKR in both tasks. It demonstrates that in outward propagation, considering the impact of distinguishing the semantics of different classes of head and tail entities in the attention mechanism and exploring the aggregation features at different levels of propagation have a positive impact on the final results. The EKPNet also exhibits a better performance compared to KGCN, proving that our model also has some advantages compared to graph convolutional networks.
- For the inward aggregated attention mechanism model KCAN, we obtained an AUC of 0.907 in the MovieLens-1M dataset and 0.928 in the EKPNet model. Our model improved by 2.31% compared to KCAN. However, KCAN treats users as entity vectors in the knowledge graph, and every time a new user interaction occurs, the graph needs to be reconstructed and the entire model retrained. Additionally, our work uses the user’s interaction history items in the knowledge graph outward propagation to indicate that the user can solve the problem of new users appearing. Therefore, EKPNet exhibits a better performance.
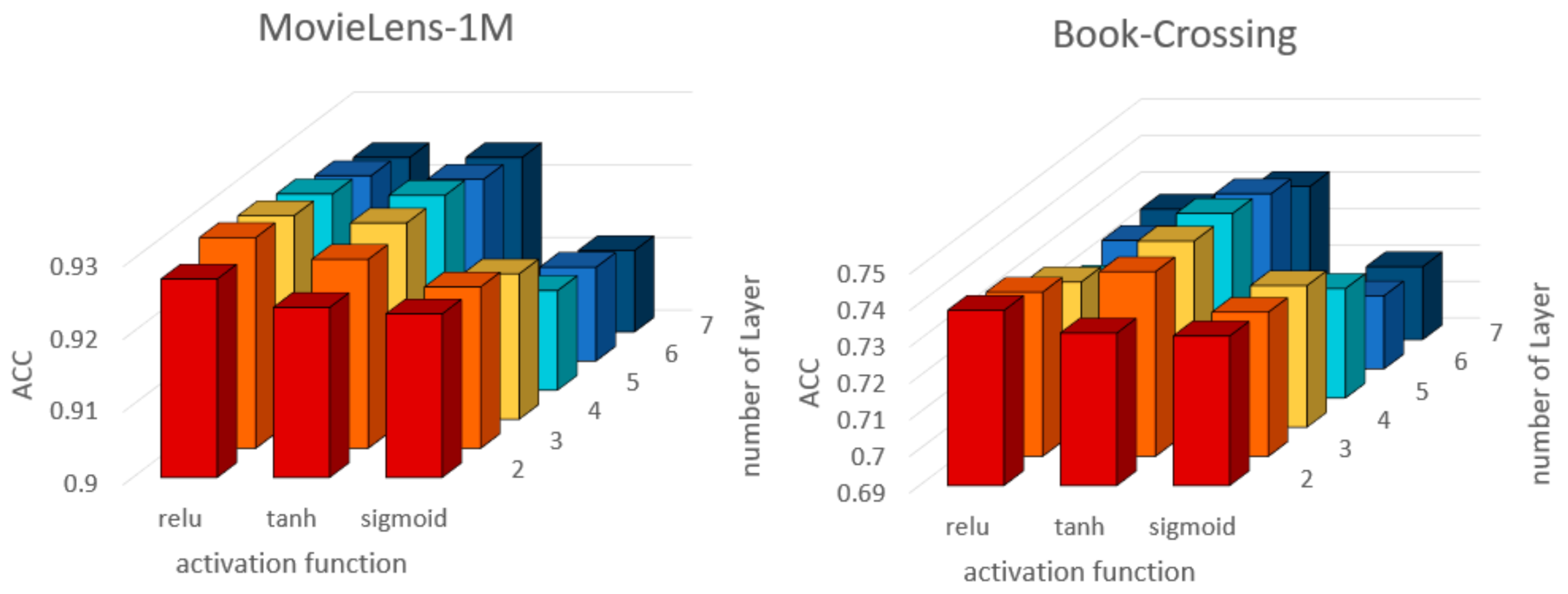
5.3. The Influence of Activation Function and MLP Structure
5.4. Module Ablation Experiment
5.5. Cost of the Model
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Resnick, P.; Varian, H.R. Recommender systems. Commun. ACM 1997, 40, 56–58. [Google Scholar] [CrossRef]
- Zhang, Y.; Abbas, H.; Sun, Y. Smart e-commerce integration with recommender systems. Electron. Mark. 2019, 29, 219–220. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Ji, Y.; Li, J.; Ye, Y. A triple wing harmonium model for movie recommendation. IEEE Trans. Ind. Inform. 2015, 12, 231–239. [Google Scholar] [CrossRef]
- Hu, Y.; Xiong, F.; Lu, D.; Wang, X.; Xiong, X.; Chen, H. Movie collaborative filtering with multiplex implicit feedbacks. Neurocomputing 2020, 398, 485–494. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Deng, S.; Huang, L.; Xu, G.; Wu, X.; Wu, Z. On deep learning for trust-aware recommendations in social networks. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 1164–1177. [Google Scholar] [CrossRef] [PubMed]
- Aslanian, E.; Radmanesh, M.; Jalili, M. Hybrid recommender systems based on content feature relationship. IEEE Trans. Ind. Inform. 2016, 99, 1. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, Y.; Han, J.; Wang, E.; Zhuang, F.; Xiong, H. Exploiting the sentimental bias between ratings and reviews for enhancing recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018. [Google Scholar]
- Guo, Q.; Zhuang, F.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A survey on knowledge graph-based recommender systems. IEEE Trans. Knowl. Data Eng. 2020, 50, 937. [Google Scholar] [CrossRef]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. Dbpedia–a large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef] [Green Version]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Xu, W.; Gao, X.; Sheng, Y.; Chen, G. Recommendation System with Reasoning Path Based on DQN and Knowledge Graph. In Proceedings of the 2021 15th International Conference on Ubiquitous Information Management and Communication (IMCOM), Seoul, Korea, 4–6 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep knowledge-aware network for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Tang, X.; Wang, T.; Yang, H.; Song, H. AKUPM: Attention-enhanced knowledge-aware user preference model for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1891–1899. [Google Scholar]
- Wang, Y.; Dong, L.; Li, Y.; Zhang, H. Multitask feature learning approach for knowledge graph enhanced recommendations with RippleNet. PLoS ONE 2021, 16, e0251162. [Google Scholar] [CrossRef] [PubMed]
- Mahdy, A.M. Numerical solutions for solving model time-fractional Fokker–Planck equation. Numer. Methods Partial. Differ. Equ. 2021, 37, 1120–1135. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. Proc. VLDB Endow. 2011, 4, 992–1003. [Google Scholar] [CrossRef]
- Yu, X.; Ren, X.; Gu, Q.; Sun, Y.; Han, J. Collaborative filtering with entity similarity regularization in heterogeneous information networks. IJCAI HINA 2013, 27. Available online: http://hanj.cs.illinois.edu/pdf/hina13_xyu.pdf (accessed on 5 January 2022).
- Zhao, H.; Yao, Q.; Li, J.; Song, Y.; Lee, D.L. Meta-graph based recommendation fusion over heterogeneous information networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 635–644. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Ye, Y.; Wang, X.; Yao, J.; Jia, K.; Zhou, J.; Xiao, Y.; Yang, H. Bayes EMbedding (BEM) Refining Representation by Integrating Knowledge Graphs and Behavior-specific Networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 679–688. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; p. 26. [Google Scholar]
- Cheng, Z.; Ding, Y.; He, X.; Zhu, L.; Song, X.; Kankanhalli, M.S. A3NCF: An Adaptive Aspect Attention Model for Rating Prediction. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 3748–3754. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Han, K.J.; Prieto, R.; Ma, T. State-of-the-art speech recognition using multi-stream self-attention with dilated 1d convolutions. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 54–61. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Xiao, J.; Ye, H.; He, X.; Zhang, H.; Wu, F.; Chua, T.S. Attentional factorization machines: Learning the weight of feature interactions via attention networks. arXiv 2017, arXiv:1708.04617. [Google Scholar]
- Zhou, G.; Zhu, X.; Song, C.; Fan, Y.; Zhu, H.; Ma, X.; Yan, Y.; Jin, J.; Li, H.; Gai, K. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1059–1068. [Google Scholar]
- Yun, S.; Kim, R.; Ko, M.; Kang, J. Sain: Self-attentive integration network for recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 1205–1208. [Google Scholar]
- Tu, K.; Cui, P.; Wang, D.; Zhang, Z.; Zhou, J.; Qi, Y.; Zhu, W. Conditional Graph Attention Networks for Distilling and Refining Knowledge Graphs in Recommendation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Queensland, Australia, 1–5 November 2021; pp. 1834–1843. [Google Scholar]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1, pp. 687–696. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The movielens datasets: History and context. Acm Trans. Interact. Intell. Syst. 2015, 5, 1–19. [Google Scholar] [CrossRef]
- Ziegler, C.N.; McNee, S.M.; Konstan, J.A.; Lausen, G. Improving recommendation lists through topic diversification. In Proceedings of the 14th international conference on World Wide Web, Chiba, Japan, 10–14 May 2005; pp. 22–32. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MovieLens-1M | Book-Crossing | ||
|---|---|---|---|
| User–Item Interaction | #users | 6036 | 17,860 |
| #items | 2445 | 14,967 | |
| #interaction | 753,772 | 139,746 | |
| #inter-avg | 125 | 8 | |
| # sparsity | 94.89% | 99.94% | |
| Knowledge Graph | #entities | 182,011 | 77,903 |
| #relations | 12 | 25 | |
| #KG triples | 1,241,995 | 198,771 | |
| #link-avg | 7 | 3 |
| d | P | N | lr | L | ||||
|---|---|---|---|---|---|---|---|---|
| Movielens-pre | 16 | 2 | 32 | 0.01 | 5 × 10−3 | - | 1 × 10−2 | - |
| Movielens | 16 | 2 | 32 | 0.001 | 1 × 10−7 | 1 × 10−7 | 5 × 10−3 | 3 |
| BookCrossing-pre | 4 | 3 | 32 | 0.01 | 1 × 10−7 | - | 1 × 10−2 | - |
| BookCrossing | 4 | 3 | 32 | 0.001 | 1 × 10−4 | 1 × 10−4 | 5 × 10−3 | 4 |
| Model | MovieLens-1M | Book-Crossing | ||||||
|---|---|---|---|---|---|---|---|---|
| AUC | imp | ACC | imp | AUC | imp | ACC | imp | |
| CKE | 0.765 | 21.31% | 0.719 | 19.05% | 0.654 | 13.30% | 0.625 | 8.32% |
| DKN | 0.683 | 35.87% | 0.612 | 39.87% | 0.631 | 17.43% | 0.604 | 12.09% |
| Wide&Deep | 0.896 | 3.57% | 0.823 | 4.01% | 0.693 | 6.93% | 0.621 | 9.02% |
| RippleNet | 0.917 | 1.20% | 0.844 | 1.42% | 0.698 | 6.16% | 0.640 | 5.78% |
| KGCN | 0.907 | 2.1% | 0.838 | 1.8% | 0.687 | 5.4% | 0.631 | 4.6% |
| Ripp-MKR | 0.920 | 0.8% | 0.845 | 1.1% | 0.720 | 2.1% | 0.650 | 2.7% |
| EKPNet | 0.928 | - | 0.856 | - | 0.741 | - | 0.677 | - |
| ACC | EKP_no | EKP_att | EKP_frame | EKPNet |
|---|---|---|---|---|
| MovieLens-1M | 0.9172 | 0.9213 | 0.9219 | 0.9284 |
| Book-Crossing | 0.7006 | 0.7105 | 0.7251 | 0.7408 |
| Time | RippleNet | EKPNet | Ripp-MKR | KGCN |
|---|---|---|---|---|
| MovieLens-1M | 352.8 s | 386.3 s + 252.1 s | 924.1 s | 1016.2 s |
| Book-Crossing | 136.3 s | 152.2 s + 122.4 s | 524.2 s | 734.1 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Wang, Y.; Chen, C.; Liu, R.; Zhou, S.; Gao, T. Enhancing Knowledge of Propagation-Perception-Based Attention Recommender Systems. Electronics 2022, 11, 547. https://doi.org/10.3390/electronics11040547
Zhang H, Wang Y, Chen C, Liu R, Zhou S, Gao T. Enhancing Knowledge of Propagation-Perception-Based Attention Recommender Systems. Electronics. 2022; 11(4):547. https://doi.org/10.3390/electronics11040547
Chicago/Turabian StyleZhang, Hanzhong, Yinglong Wang, Chao Chen, Ruixia Liu, Shuwang Zhou, and Tianlei Gao. 2022. "Enhancing Knowledge of Propagation-Perception-Based Attention Recommender Systems" Electronics 11, no. 4: 547. https://doi.org/10.3390/electronics11040547
APA StyleZhang, H., Wang, Y., Chen, C., Liu, R., Zhou, S., & Gao, T. (2022). Enhancing Knowledge of Propagation-Perception-Based Attention Recommender Systems. Electronics, 11(4), 547. https://doi.org/10.3390/electronics11040547