
Bytecode Similarity Detection of Smart Contract across Optimization Options and Compiler Versions Based on Triplet Network


Abstract
:1. Introduction
- Bytecode diversity affected by optimization options. Ethereum uses “gas” (i.e., a form of fee) to charge the deployment and execution of smart contracts. In order to achieve the comprehensive optimization of a contract running time and resources, the compiler sets optimization options to optimize instructions and basic blocks according to the deployment and execution charges of gas. Therefore, the same source code will produce different bytecodes under the influence of optimization options.
- Bytecode diversity affected by the compiler version. The compiler version updated too quickly when Solidity was born. Since its birth, there have been nearly 100 versions and changes in several major versions. The same source code will produce different bytecode with different compiler versions.
- It is worth mentioning that each bytecode has corresponding metadata, which contains the information of whether the corresponding bytecode has been compiled and optimized, and the compiler version during compilation.
2. Related Work
- Combined with the metadata information mentioned in the introduction, the neural machine translator (NMT) is applied to the bytecode similarity measurement of smart contract. The model trained by triplet network uniformly converts the optimized compiled smart contract bytecode into non-optimized compiled bytecode, or vice versa. This overcomes the problem of byte code diversification of the same source code caused by optimization options;
- After normalizing the difference between instruction normalization and compiled version, combined with the feature extraction of traversal control flow graph (CFG), it overcomes the diversity of bytecode of the same source code caused by compiled version;
- We improved the negative sample selection method to solve the current difficulty of negative sampling;
- A smart contract data set is provided by us, including different versions of smart contract source code and more than 1 million basic block pairs.
3. Methodology or Design and Implementation
3.1. Dataset Formation
3.1.1. Opcode Formation and Logical Opcode Extraction
- Contract deployment code. This part of the role is that when EVM creates a contract, it will first create a contract account and then run the deployment code. After running, it will store the logical code with auxdata on the blockchain, and then associate the storage address with the contract account;
- Logical code. This part is the real logical operation part of the smart contract when running in EVM;
- Auxdata. This is the password verification part before smart contract deployment.
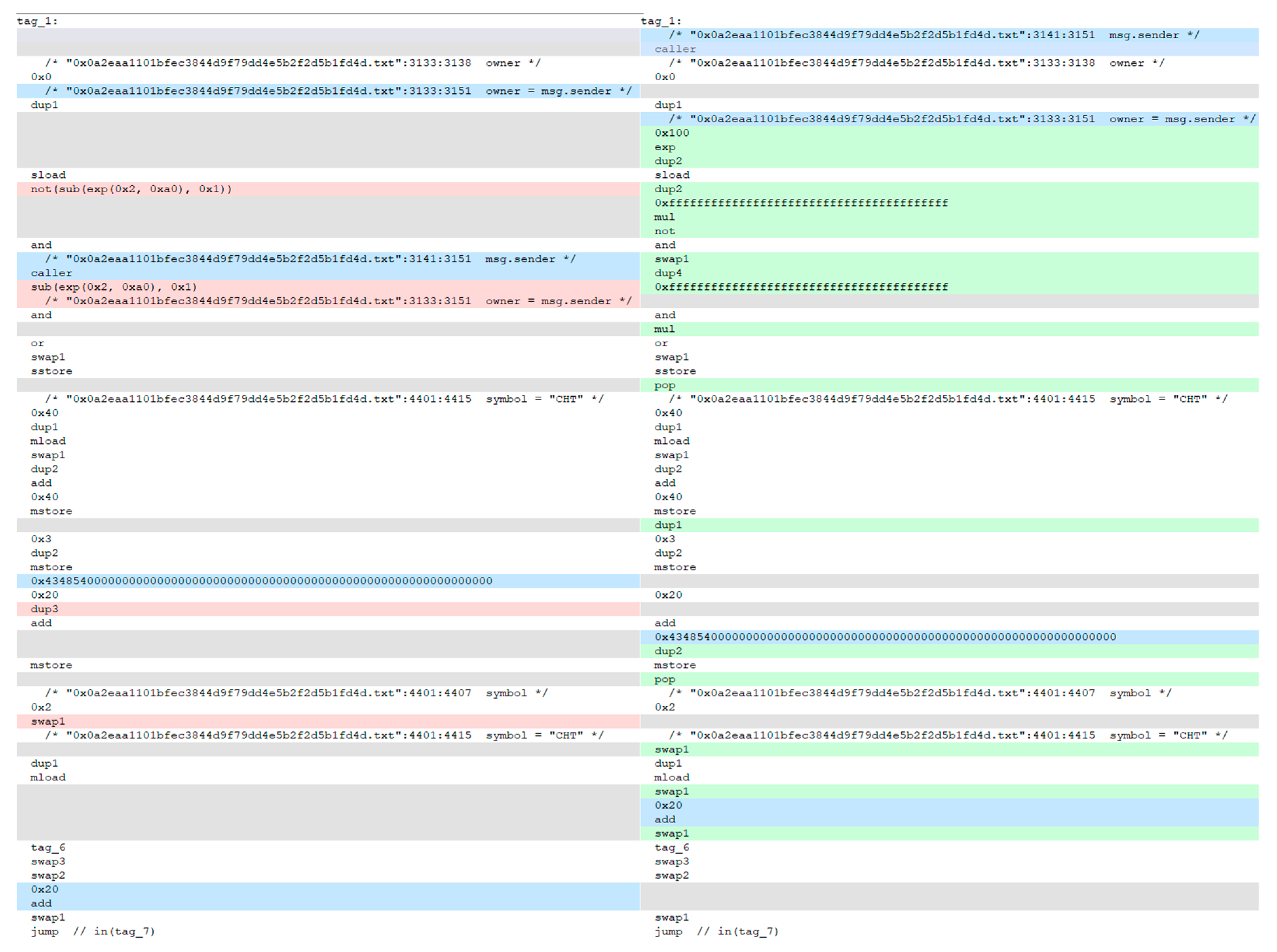
3.1.2. Instruction Normalization and Basic Block Sequence Formation
3.1.3. Positive Sample Acquisition
3.2. Neural Network Pre-Training
3.2.1. Neural Machine Translation
- The basic limitation of sequential calculation limits the computational efficiency of the recursive model. The calculation of time slice t depends on the calculation result at t − 1, which greatly limits the parallel ability of the model;
- Loss of information in the process of sequential calculation. This sequential calculation mechanism means that the semantic relationship between contexts will continue to weaken as the state passes. This is because the calculation is linear, which usually takes a certain amount of time.
3.2.2. Transformer with Self-Attention Mechanism
- It does not make any assumptions about the time and space relationship between data, which is a processing Ideal for a set of basic block pairs;
- Parallel calculation can be carried out. Moreover, the efficiency of processing a large number of data sets is high;
- It can achieve better results for longer basic block sequences.
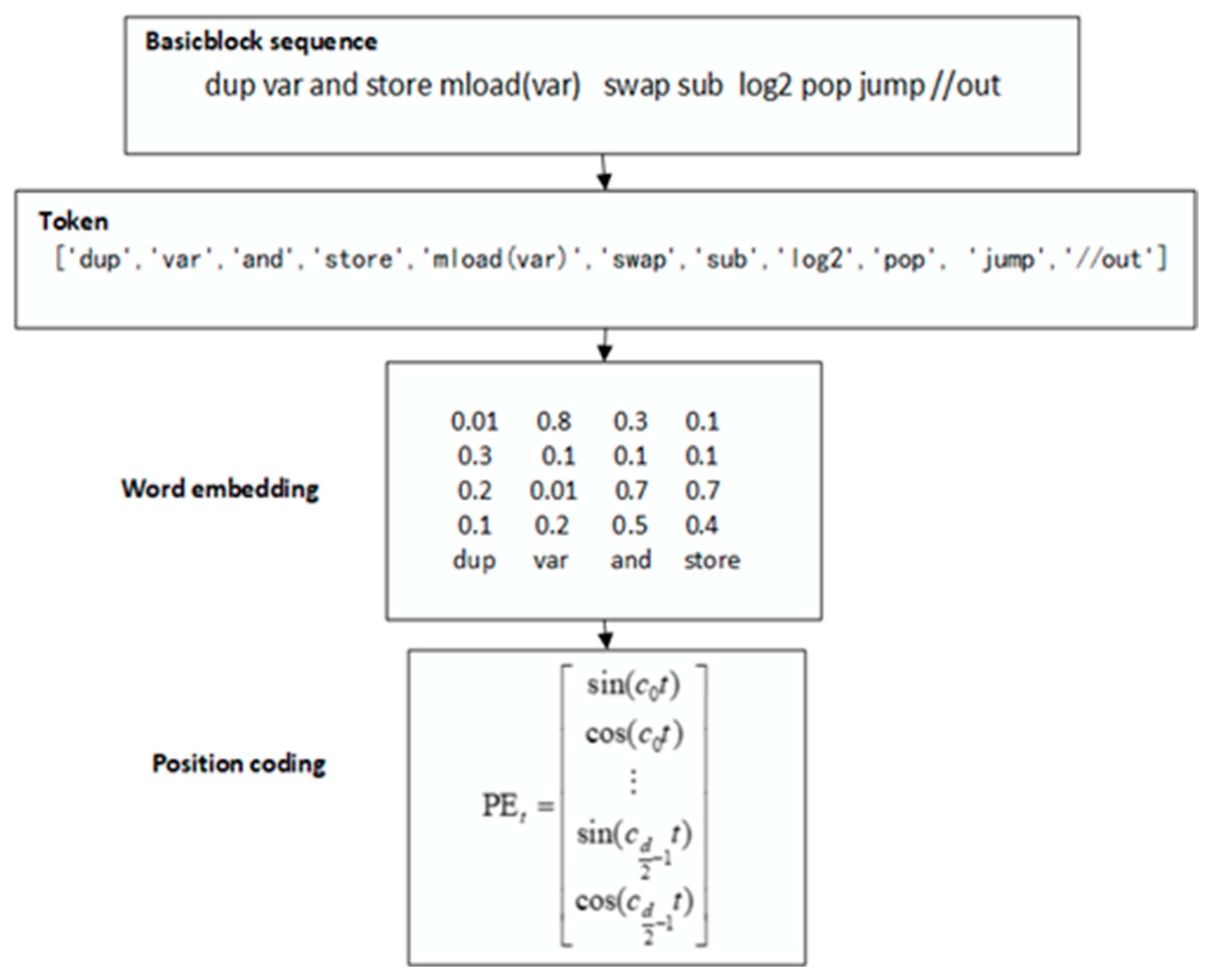
3.2.3. Basic Block Embedding and Position Coding
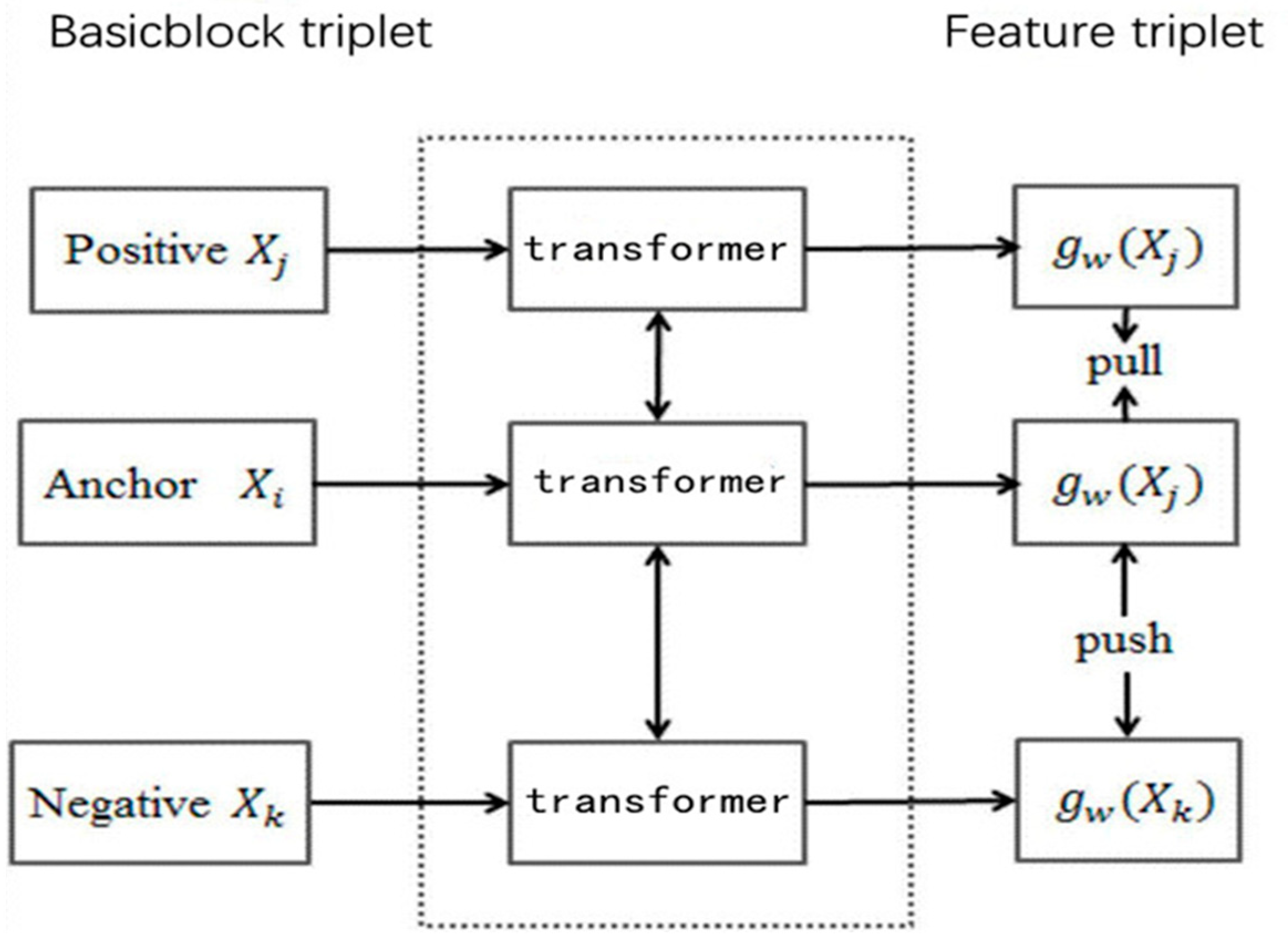
3.2.4. Negative Sample Acquisition and Hard Sample Insertion
- Random sampling of the data set, but the result of random sampling does not guarantee the difference between the sampled basic block and basic block as anchor;
- An approach [58] marks the ground truth in advance, and then a series of proposals will be generated in the algorithm. If the intersection over union (IoU) of proposals and ground truth is below a certain threshold, it is a negative sample. This can well ensure the difference between the negative sample and the smart contract itself, but it may need to label the ground truth, which requires a higher data set and consumes considerable resources. There will also be a problem that is the number of positive samples may be much smaller than the negative sample, so the effect of training is always limited.
- Make the samples with higher similarity as close as possible during training in the embedding vector space;
- Keep samples with large differences in similarity as far away as possible during training in the vector space.
3.3. Cross Compiler Version Normalization and Similarity Calculation
3.3.1. Cross Compiler Version Normalization
3.3.2. Similarity Calculation
3.4. Similarity Measure Extend to Bytecode
3.4.1. Key Instruction Combination Matching
3.4.2. Basic Block Inter Features
3.4.3. Similarity Calculation of Bytecode
4. Experiment
4.1. Training Details
- We use adam [72] as an optimizer to adapt to gradient descent;
- The hyperparameters are learning rate: 3 × 10−5, batch size: 48, epoch: 10, dropout: 0.1;
- We set 512 as the maximum length, and padding for basic block vectors is shorter than this length;
- Our training was conducted on a workstation with Intel Xeon processors, four NVIDIA 2080Ti graphics cards, 192 GB RAM, and 2 TB SSD;
- The experiments were carried out five times, and the average value was taken as the final result.
4.2. Evaluation Criteria Settings
- ASM_small: includes nearly 50,000 basic block pairs;
- ASM_base: includes nearly 300,000 basic block pairs;
- ASM_large: includes nearly 1 million basic block pairs;
- ASM_base_unnormalized: Including nearly 500,000 basic block sequence pairs of different Solidity versions, but not normalized by instructions.
- 2.
- Experiments on the effectiveness of bytecode similarity measurement in this paper across optimization options and compiler versions in Section 4.3.4, Section 4.3.5 and Section 4.3.6.
4.3. Empirical Results
4.3.1. Dataset Size and Normalization
- Constants have little effect on program semantics. In the opcode of a smart contract, unnormalized constants may include memory addresses, function signatures and transaction information, etc, which may cause OOV problems;
- In the EVM, instructions can be replaced by other instructions of the same category without changing the semantics in some cases. This feature may confuse neural net-works, especially NMT models.
4.3.2. Different Negative Sample Sampling Methods
4.3.3. Hyperparameter Margin
4.3.4. Bytecode Similarity Measurement Effect across Optimization Options
4.3.5. Bytecode Similarity Measurement across Compiler Versions
4.3.6. Comparative Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tong, Z.; Ye, F.; Yan, M.; Liu, H.; Basodi, S. A Survey on Algorithms for Intelligent Computing and Smart City Applications. Big Data Min. Anal. 2021, 4, 155–172. [Google Scholar] [CrossRef]
- Elhoseny, M.; Salama, A.; Abdelaziz, A.; Riad, A. el-din Intelligent Systems Based on Loud Computing for Healthcare Services: A Survey. Int. J. Comput. Intell. Stud. 2017, 6, 157. [Google Scholar] [CrossRef]
- Huang, H.; Yan, C.; Liu, B.; Chen, L. A Survey of Memory Deduplication Approaches for Intelligent Urban Computing. In Machine Vision and Applications; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Xu, J.; Xue, K.; Li, S.; Tian, H.; Hong, J.; Hong, P.; Yu, N. Healthchain: A Blockchain-Based Privacy Preserving Scheme for Large-Scale Health Data. IEEE Internet Things J. 2019, 6, 8770–8781. [Google Scholar] [CrossRef]
- Alshaikhli, M.; Elfouly, T.; Elharrouss, O.; Mohamed, A.; Ottakath, N. Evolution of Internet of Things from Blockchain to IOTA: A Survey. IEEE Access 2021, 10, 844–866. Available online: https://ieeexplore.ieee.org/document/9662390 (accessed on 2 February 2022). [CrossRef]
- Du, M.; Chen, Q.; Xiao, J.; Yang, H.; Ma, X. Supply Chain Finance Innovation Using Blockchain. IEEE Trans. Eng. Manag. 2020, 67, 1045–1058. [Google Scholar] [CrossRef]
- Etherscan. Available online: https://etherscan.io/ (accessed on 2 February 2022).
- Kushwaha, S.S.; Joshi, S.; Singh, D.; Kaur, M.; Lee, H.-N. Systematic Review of Security Vulnerabilities in Ethereum Blockchain Smart Contract. IEEE Access 2022, 10, 6605–6621. [Google Scholar] [CrossRef]
- Ghaleb, B.; Al-Dubai, A.; Ekonomou, E.; Qasem, M.; Romdhani, I.; Mackenzie, L. Addressing the DAO Insider Attack in RPL’s Internet of Things Networks. IEEE Commun. Lett. 2019, 23, 68–71. [Google Scholar] [CrossRef] [Green Version]
- Min, T.; Wang, H.; Guo, Y.; Cai, W. Blockchain Games: A Survey. In Proceedings of the 2019 IEEE Conference on Games (CoG), London, UK, 20–23 August 2019; pp. 1–8. [Google Scholar]
- PolyNetwork. Available online: https://www.poly.network/#/ (accessed on 2 February 2022).
- Solidity—Solidity 0.8.12 Documentation. Available online: https://docs.soliditylang.org/en/develop/ (accessed on 4 February 2022).
- Serpent. Available online: https://eth.wiki/archive/serpent (accessed on 2 February 2022).
- Expanse Tech. Available online: https://expanse.tech/ (accessed on 2 February 2022).
- Wanchain—Build the Future of Finance. Available online: https://wanchain.org/ (accessed on 2 February 2022).
- TomoChain—The Most Efficient Blockchain for the Token Economy. Available online: https://tomochain.com/ (accessed on 2 February 2022).
- SmartMesh—SmartMesh Opens up a World Parallel to the Internet. Available online: https://smartmesh.io (accessed on 2 February 2022).
- CPCHAIN—Cyber Physical Chain. Available online: https://www.cpchain.io/ (accessed on 2 February 2022).
- ThunderCore—Decentralized Future. Today. Available online: https://www.thundercore.com/ (accessed on 2 February 2022).
- Opcodes for the EVM. Available online: https://ethereum.org (accessed on 2 February 2022).
- Fröwis, M.; Böhme, R. In Code We Trust? In Proceedings of the Data Privacy Management, Cryptocurrencies and Blockchain Technology, Oslo, Norway, 14–15 September 2017; Garcia-Alfaro, J., Navarro-Arribas, G., Hartenstein, H., Herrera-Joancomartí, J., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 357–372. [Google Scholar]
- Wang, Z.; Jin, H.; Dai, W.; Choo, K.-K.R.; Zou, D. Ethereum Smart Contract Security Research: Survey and Future Research Opportunities. Front. Comput. Sci. 2020, 15, 152802. [Google Scholar] [CrossRef]
- Liu, H.; Yang, Z.; Jiang, Y.; Zhao, W.; Sun, J. Enabling Clone Detection for Ethereum Via Smart Contract Birthmarks. In Proceedings of the 2019 IEEE/ACM 27th International Conference on Program Comprehension (ICPC), Montreal, QC, Canada, 25–26 May 2019; pp. 105–115. [Google Scholar]
- Badruddoja, S.; Dantu, R.; He, Y.; Upadhyay, K.; Thompson, M. Making Smart Contracts Smarter. In Proceedings of the 2021 IEEE International Conference on Blockchain and Cryptocurrency (ICBC), Sydney, Australia, 3–6 May 2021; pp. 1–3. [Google Scholar]
- Nikolić, I.; Kolluri, A.; Sergey, I.; Saxena, P.; Hobor, A. Finding the Greedy, Prodigal, and Suicidal Contracts at Scale. In Proceedings of the 34th Annual Computer Security Applications Conference, San Juan, PR, USA, 3–7 December 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 653–663. [Google Scholar]
- Krupp, J.; Rossow, C. Teether: Gnawing at Ethereum to Automatically Exploit Smart Contracts. In Proceedings of the 27th USENIX Conference on Security Symposium, Baltimore, MD, USA, 15–17 August 2018; USENIX Association: Berkeley, CA, USA, 2018; pp. 1317–1333. [Google Scholar]
- Mossberg, M.; Manzano, F.; Hennenfent, E.; Groce, A.; Grieco, G.; Feist, J.; Brunson, T.; Dinaburg, A. Manticore: A User-Friendly Symbolic Execution Framework for Binaries and Smart Contracts. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 11–15 November 2019; pp. 1186–1189. [Google Scholar]
- Kalra, S.; Goel, S.; Dhawan, M.; Sharma, S. ZEUS: Analyzing Safety of Smart Contracts. In Proceedings of the Network and Distributed Systems Security (NDSS) Symposium 2018, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Torres, C.F.; Schütte, J.; State, R. Osiris: Hunting for Integer Bugs in Ethereum Smart Contracts. In Proceedings of the 34th Annual Computer Security Applications Conference, San Juan, PR, USA, 3–7 December 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 664–676. [Google Scholar]
- Tsankov, P. Security Analysis of Smart Contracts in Datalog. In Leveraging Applications of Formal Methods, Verification and Validation. Industrial Practice; Margaria, T., Steffen, B., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 316–322. [Google Scholar]
- Bai, X.; Cheng, Z.; Duan, Z.; Hu, K. Formal Modeling and Verification of Smart Contracts. In Proceedings of the 2018 7th International Conference on Software and Computer Applications, Kuantan, Malaysia, 8–10 February 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 322–326. [Google Scholar]
- Jiang, B.; Liu, Y.; Chan, W.K. ContractFuzzer: Fuzzing Smart Contracts for Vulnerability Detection. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 259–269, ISBN 978-1-4503-5937-5. [Google Scholar]
- Liu, C.; Liu, H.; Cao, Z.; Chen, Z.; Chen, B.; Roscoe, B. ReGuard: Finding Reentrancy Bugs in Smart Contracts. In Proceedings of the 2018 IEEE/ACM 40th International Conference on Software Engineering: Companion (ICSE-Companion), Gothenburg, Sweden, 27 May–3 June 2018; pp. 65–68. [Google Scholar]
- Rodler, M.; Li, W.; Karame, G.; Davi, L. Sereum: Protecting Existing Smart Contracts Against Re-Entrancy Attacks. arXiv 2018, arXiv:1812.05934. [Google Scholar]
- Ma, F.; Fu, Y.; Ren, M.; Wang, M.; Jiang, Y.; Zhang, K.; Li, H.; Shi, X. EVM*: From Offline Detection to Online Reinforcement for Ethereum Virtual Machine. In Proceedings of the 2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER), Hanzhou, China, 24–27 February 2019; pp. 554–558. [Google Scholar]
- Liu, H.; Liu, C.; Zhao, W.; Jiang, Y.; Sun, J. S-Gram: Towards Semantic-Aware Security Auditing for Ethereum Smart Contracts. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 814–819. [Google Scholar]
- Wang, S.; Chollak, D.; Movshovitz-Attias, D.; Tan, L. Bugram: Bug Detection with n-Gram Language Models. In Proceedings of the 2016 31st IEEE/ACM International Conference on Automated Software Engineering (ASE), Singapore, 3–7 September 2016; pp. 708–719. [Google Scholar]
- Yang, Z.; Keung, J.; Zhang, M.; Xiao, Y.; Huang, Y.; Hui, T. Smart Contracts Vulnerability Auditing with Multi-Semantics. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; IEEE: Madrid, Spain, 2020; pp. 892–901. [Google Scholar]
- Heafield, K. KenLM: Faster and Smaller Language Model Queries; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011. [Google Scholar]
- Zhuang, Y.; Liu, Z.; Qian, P.; Liu, Q.; Wang, X.; He, Q. Smart Contract Vulnerability Detection Using Graph Neural Network. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020; International Joint Conferences on Artificial Intelligence Organization: Yokohama, Japan, 2020; pp. 3283–3290. [Google Scholar]
- Ashizawa, N.; Yanai, N.; Cruz, J.P.; Okamura, S. Eth2Vec: Learning Contract-Wide Code Representations for Vulnerability Detection on Ethereum Smart Contracts. arXiv 2021, arXiv:2101.02377. [Google Scholar]
- Hildenbrandt, E.; Saxena, M.; Zhu, X.; Rodrigues, N.; Daian, P.; Guth, D.; Roşu, G. KEVM: A Complete Semantics of the Ethereum Virtual Machine. In Proceedings of the 2018 IEEE 31st Computer Security Foundations Symposium (CSF), Oxford, UK, 9–12 July 2018. [Google Scholar]
- Liu, H.; Yang, Z.; Liu, C.; Jiang, Y.; Zhao, W.; Sun, J. EClone: Detect Semantic Clones in Ethereum via Symbolic Transaction Sketch. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, 23–28 August 2021; ACM: Lake Buena Vista, FL, USA, 2018; pp. 900–903. [Google Scholar]
- Tann, W.J.-W.; Han, X.J.; Gupta, S.S.; Ong, Y.-S. Towards Safer Smart Contracts: A Sequence Learning Approach to Detecting Security Threats. arXiv 2019, arXiv:1811.06632. [Google Scholar]
- Huang, J.; Han, S.; You, W.; Shi, W.; Liang, B.; Wu, J.; Wu, Y. Hunting Vulnerable Smart Contracts via Graph Embedding Based Bytecode Matching. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2144–2456. Available online: https://ieeexplore.ieee.org/document/9316905 (accessed on 17 January 2022). [CrossRef]
- Mining Bytecode Features of Smart Contracts to Detect Ponzi Scheme on Blockchain. Available online: https://www.techscience.com/CMES/v127n3/42601 (accessed on 2 February 2022).
- Zuo, F.; Li, X.; Young, P.; Luo, L.; Zeng, Q.; Zhang, Z. Neural Machine Translation Inspired Binary Code Similarity Comparison beyond Function Pairs. In Proceedings of the 2019 Network and Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2019. [Google Scholar] [CrossRef]
- Yang, P.; Liu, W.; Yang, J. Positive Unlabeled Learning via Wrapper-Based Adaptive Sampling. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017; pp. 3273–3279. [Google Scholar]
- Slither, the Solidity Source Analyzer. Available online: https://github.com/crytic/slither (accessed on 2 February 2022).
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sukhbaatar, S.; Grave, E.; Bojanowski, P.; Joulin, A. Adaptive Attention Span in Transformers. arXiv 2019, arXiv:1905.07799. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Davis, A.S.; Arel, I. Faster Gated Recurrent Units via Conditional Computation. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 920–924. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems—Volume 2, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Rong, X. Word2vec Parameter Learning Explained. arXiv 2014, arXiv:1411.2738. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Sun, W.; Pang, J.; Liu, F.; Ma, Z. Similarity Metric Method for Binary Basic Blocks of Cross-Instruction Set Architecture. In Proceedings of the Workshop on Binary Analysis Research (BAR) 2020, San Diego, CA, USA, 23 February 2020. [Google Scholar]
- Xuan, H.; Stylianou, A.; Liu, X.; Pless, R. Hard Negative Examples Are Hard, but Useful. arXiv 2021, arXiv:2007.12749. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep Metric Learning Using Triplet Network. In Proceedings of the Similarity-Based Pattern Recognition, Copenhagen, Denmark, 12–14 October 2015; Feragen, A., Pelillo, M., Loog, M., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 84–92. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-Based Object Detectors with Online Hard Example Mining. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Robinson, J.; Chuang, C.-Y.; Sra, S.; Jegelka, S. Contrastive Learning with Hard Negative Samples. arXiv 2020, arXiv:2010.04592. [Google Scholar]
- Kim, T.; Hong, K.; Byun, H. The Feature Generator of Hard Negative Samples for Fine-Grained Image Recognition. Neurocomputing 2021, 439, 374–382. [Google Scholar] [CrossRef]
- Chen, W.; Chen, X.; Zhang, J.; Huang, K. Beyond Triplet Loss: A Deep Quadruplet Network for Person Re-Identification. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Evm-Cfg-Builder. Available online: https://github.com/crytic/evm_cfg_builder (accessed on 4 February 2022).
- Hu, X.; Chiueh, T.; Shin, K.G. Large-Scale Malware Indexing Using Function-Call Graphs. In Proceedings of the 16th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 9–13 November 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 611–620. [Google Scholar]
- Liu, B.; Huo, W.; Zhang, C.; Li, W.; Li, F.; Piao, A.; Zou, W. ADiff: Cross-Version Binary Code Similarity Detection with DNN. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 667–678, ISBN 978-1-4503-5937-5. [Google Scholar]
- Mount, J. The Equivalence of Logistic Regression and Maximum Entropymodels. 2011. Available online: http://www.mfkp.org/INRMM/article/12013393 (accessed on 10 January 2022).
- David, Y.; Partush, N.; Yahav, E. Statistical Similarity of Binaries. SIGPLAN Not. 2016, 51, 266–280. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Henderson, M.; Al-Rfou, R.; Strope, B.; Sung, Y.; Lukacs, L.; Guo, R.; Kumar, S.; Miklos, B.; Kurzweil, R. Efficient Natural Language Response Suggestion for Smart Reply. arXiv 2017, arXiv:1705.00652. [Google Scholar]
- Yang, Y.; Yuan, S.; Cer, D.; Kong, S.; Constant, N.; Pilar, P.; Ge, H.; Sung, Y.-H.; Strope, B.; Kurzweil, R. Learning Semantic Textual Similarity from Conversations. In Proceedings of the Third Workshop on Representation Learning for NLP, Melbourne, Australia, 20 July 2018; Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 164–174. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Calculation Object | Equation |
|---|---|---|
| Euclidean | Basic block vector distance, Basic block inter-features | Equation (1) |
| Generalized Jaccard | Key instruction combination mapping | Equation (6) |
| Dataset | A@3(%) | A@10(%) |
|---|---|---|
| ASM_small | 81.4 | 91.2 |
| ASM_base | 83.7 | 94.5 |
| ASM_large | 88.2 | 97.8 |
| ASM_base_unnormalized | 79.9 | 89.4 |
| Negative Sampling | A@3(%) | A@10(%) |
|---|---|---|
| Random | 83.5 | 91.4 |
| Differentiation | 87.1 | 95.2 |
| Mix | 88.2 | 97.8 |
| Margin | A@3(%) | A@10(%) |
|---|---|---|
| 80 | 82.9 | 94.0 |
| 100 | 84.3 | 95.9 |
| 120 | 88.2 | 97.8 |
| 140 | 88.4 | 97.2 |
| 160 | 83.5 | 94.4 |
| Threshold | Accuracy (%) | |
|---|---|---|
| Eclone [23] | 0.84 | 93.1 |
| Our method | 0.89 | 94.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, D.; Yue, F.; Pang, J.; Zhou, X.; Han, W.; Liu, F. Bytecode Similarity Detection of Smart Contract across Optimization Options and Compiler Versions Based on Triplet Network. Electronics 2022, 11, 597. https://doi.org/10.3390/electronics11040597
Zhu D, Yue F, Pang J, Zhou X, Han W, Liu F. Bytecode Similarity Detection of Smart Contract across Optimization Options and Compiler Versions Based on Triplet Network. Electronics. 2022; 11(4):597. https://doi.org/10.3390/electronics11040597
Chicago/Turabian StyleZhu, Di, Feng Yue, Jianmin Pang, Xin Zhou, Wenjie Han, and Fudong Liu. 2022. "Bytecode Similarity Detection of Smart Contract across Optimization Options and Compiler Versions Based on Triplet Network" Electronics 11, no. 4: 597. https://doi.org/10.3390/electronics11040597