1. Introduction
Embedded devices are being used by many people around the world. As denoted in the term “Internet of Things,” these embedded processors are connected to the Internet, which provides convenience, and the number of devices has increased significantly. In this situation, the importance of safety and security issues for embedded systems is increasing, and there is still a need for continued research [
1,
2,
3]. Embedded devices have some limitations such as power consumption, memory usage and computation performance. These limitations make it difficult to apply the security techniques used in general-purpose computers to embedded devices [
1]. Currently, many small-scale embedded devices operate without an operating system (OS) due to performance overhead. Therefore, these limitations should be considered more in embedded systems than in general-purpose systems. For similar reasons, embedded systems are primarily written in the C programming language, which can efficiently manage resources and provide programmers with the ability to directly manage memory and optimize performance. However, C is an unsafe language and has vulnerabilities. Typically, due to the lack of boundary checks, it can often cause buffer overflow, which makes the program vulnerable to runtime attacks [
4].
Stack smashing [
5] and code reuse attacks (CRAs) are well-known runtime attacks; CRAs include return-oriented programming (ROP) [
6,
7] and jump-oriented Programming (JOP) [
8]. These attacks are generally performed by overwriting the return address (RA) stored in the stack. Stack smashing is an attack in which the attacker can execute their malicious code on the stack by overwriting the RA using starting address of the injected code. These attacks were easily prevented by Data Execution Prevention (DEP) [
9] or No-Execute (NX) protection [
10], which block the code execution in memory areas such as the stack or heap. Such security technique prevent memory from being simultaneously writable and executable.
The CRA is a new attack that bypasses these security techniques. It utilizes small instruction sequences included in existing programs such as libraries. This instruction sequence is called a gadget, and the end of the gadget primarily contains branch statements such as ret or jump. By connecting these gadgets, an attacker can perform arbitrary operations.
A representative technique for preventing CRAs is control-flow integrity (CFI) [
11,
12,
13]. CFI is a technique that ensures that a program follows a predefined control-flow graph (CFG) at compile time. In addition to runtime attacks, soft errors can cause a program to deviate from a pre-determined CFG. A soft error is a temporary error that occurs inside a semiconductor due to neutrons or alpha particles [
14]. This error can cause bit flips in the register or memory. As a result, it can affect the control flow and violate the CFG [
15]. Since it is not a physical error, it disappears when the device is restarted. However, most embedded systems require continuous operation, so detection of such soft errors is important to instantly correct improper execution of a program. In this paper, control flow errors (CFEs) include all cases that violate the predefined CFG, and we define that a control flow that deviates from the CFG is reffered to as a CFE. We propose a new method based on the memory protection unit (MPU) for detection of CFEs. Our technique guarantees CFI by inserting MPU configuration codes at compile time based on the low level virtual machine (LLVM) compiler [
16]. An MPU is included in most embedded devices, and it can assign read-write-execute authority to some or all of the memory space. The idea for our technique involves setting the execute authority only in the area to be executed, and the area not to be executed is assigned to non-execute. Since our technique sets the area to be executed as the execute region in the MPU, runtime attacks can be detected through the MPU. The rest of the paper is organized as follows: In
Section 2, we describe the necessary background.
Section 3 provides the assumptions for our target and threat model that we want to protect using the proposed CFI technique.
Section 4 explains our architecture and the principle for detecting CFEs.
Section 5 introduces the code generation workflow.
Section 6 analyzes the generated overhead when the technique is applied. Finally, we conclude in
Section 7.
4. Proposed Architecture
4.1. Principle of CFE Detection
This section describes the approach and structure of ACE-M, the security technique we propose. ACE-M uses the MPU that most embedded devices have. The principle idea of ACE-M is to set entire code areas as non-execute areas, and to allow only the code area (function area) to be set as execute areas. Since the ACE-M technique can be implemented using three MPU regions, R0, R1, and R2, the remaining regions can be used elsewhere if necessary. In general, we use R1 for configuring the current executed region, and R2 for the next area, which is performed by the branch instruction. From this point of view, a function that sets R1 is performed at the beginning of all functions and after the call instruction, and an operation that sets R2 must be performed before the call or return instruction. R0 is set to non-execute at the beginning of the main. At this time, it should be noted that the MPU region for the main function must be set in R1 before setting R0 because if R0 is performed first, the entire code area cannot run. Our technique guarantees CFI, but which is maintained while the function is being executed. Therefore, it is possible to detect CFEs even in special situations in which the PC is changed due to a soft error.
Figure 4 shows that the F1 function calls the F2 function using the MPU region and memory space.
Figure 4a shows that the F1 function is currently being performed. In this case, F1 is also called by another function. That is, the F1 region is set in R2 before calling, and then the F1 region is set in the R1 region in F1. While F1 is being executed, it can be confirmed that both regions R1 and R2 include only F1.
Figure 4b is the state before calling F2 from F1. Before calling F2, the setting for the F2 region was performed on R2.
Figure 4c is the state in which F2 is being performed. Every function has inserted code in the first basic block (BB) that sets its area in R1. Therefore,
Figure 4a,c show that when the function begins, R1 and R2 have the same area.
The return is performed in the same way as the call.
Figure 5 likewise shows a situation in which F2 returns to F1.
Figure 5a shows the state in which F2 is being executed.
Figure 5b is the situation before the return. Before the return occurs, the setting for F1 is executed on R2.
Figure 5c shows that when returning to F1, an operation in R1 that sets its own area is performed again in F1. In this way, only the function area currently being executed can be executed in the MPU area. We can verify abnormal control flow, when the PC points to an abnormal address that is not included in the MPU regions.
4.2. Automated Code Insertion for MPU Configuration
We insert MPU-related functions in two major steps. Both steps are important for ACE-M to perform normally. Through this process, we satisfy several conditions. First, the function region currently being executed is set in R1. Second, before CFINs such as calls and returns, the region in which the function will next be executed is set in R2. These two conditions are fundamental requirements that must be satisfied when using our technique. Setting R2 is similar to verifying the TA in general CFI. In Algorithm 1, is an MPU configuration function that allows the program to execute a specific area; it requires three arguments. These arguments include the starting address, size and region number. includes temporary arguments. Since the starting address and size can be determined after inserting all of the MPU configuration code, only the region number can be fixed. is a new instruction that calls the MPU configuration function . Region number 1 is fixed in terms of the arguments of this function, which are inserted before the first instruction of the entry basic block and after the call instruction in any basic block. In addition, region number 2 is fixed in terms of the function’s arguments, which are inserted before the call instruction in any basic block. Setting a fixed region number in the temporary arguments can be utilized when re-setting the arguments to an accurate value.
However, there is still no guarantee of backward-edge CFI. Our technique is based on inserting an MPU configuration function to ensure CFI at compile time through LLVM transform pass. In general, it is impossible to specify where the function was called at compile time. These problems can be solved using the conditions we set earlier. All functions must be called by other functions. Therefore, we can predict that the region for the caller is set in R1 when the callee begins, and we can obtain the starting address and size by reading the MPU registers in R1 that are related.
In Algorithm 2,
is a function that reads the MPU registers in R1 that are related.
is inserted before the first instruction in the entry basic block and it returns
.
includes the starting address and size reading from the MPU register.
is inserted before the return instruction in addition to
. ACE-M can guarantee backward-edge CFI without allocating a separate memory area to the SRAM. A shadow stack is the typical CFI for such a method, and it must protect the shadow stack, which means that a separate security system is required. However, our technique enforces CFI only in terms of code memory area by using MPUs.
| Algorithm 1 Insert Function |
MPU configuration function new instruction to be inserted first instruction in the basic block function call instruction temporary arguments used to create MPU configuration function current basic block in the function current instruction in the basic block Create_CallInst (F, ): create a call instruction Insert_before (, ): insert a new instruction before the old instruction getNextNode(): get next instruction’s pointer Create_CallInst(, ) if then if then Insert_before(, ) end if end if if then Insert_before(, ) Insert_before(getNextNode(), ) end if
|
| Algorithm 2 Read Caller Information in Callee |
- 1:
MPU configuration function - 2:
read MPU register to obtain starting address and size of a caller - 3:
new instruction to be inserted - 4:
caller function’s starting address and size - 5:
current instruction in BB -
- 6:
Create_CallInst (F, ): create call instruction - 7:
Insert_before (, ): insert new instruction before the old instruction -
- 8:
Create_CallInst() - 9:
if then - 10:
if then - 11:
Insert_before(, ) - 12:
end if - 13:
end if - 14:
Create_CallInst(, ) - 15:
if then - 16:
if then - 17:
Insert_before(, ) - 18:
end if - 19:
end if
|
4.3. Profiling & Function Layout
In
Section 4.2, we inserted all the necessary MPU configuration function call instructions. However, in this step, the arrangement of the function has not yet been determined, and therefore, the MPU configuration function with its temporary arguments is inserted. At this point, the size of the final function can be determined. and we can extract the function size. ACE-M guarantees CFI by using MPU regions at the function level. In general, each function should be able to be assigned to a single MPU region. To set an MPU region, there are requirements that must be met. First, the size must be a power of 2 and range from at least 32 bytes to 4 GB. In addition, the starting address of the MPU area should be a multiple of the region size. To satisfy these conditions, the function must be located at a specific address. Therefore, it is necessary to amend the linker script.
Figure 6 shows the memory layout of the function in the code area. To construct such a memory layout, the first piece of information that must be determined is the size of the function. Since the MPU region can be specified only once the size of the function is determined.
In ACE-M, the functions are placed in descending order. The sizes of F1 and F2 are larger than 128 bytes and smaller than 256 bytes. Therefore, each MPU region that covers F1 and F2 has a size of 256 bytes. Additionally, the function must be located at a multiple of 0 × 100 in the form of a Hex of 256 bytes. Likewise, F3 may be located at a multiple of 0 × 80 because it may be set as an MPU area of 128 bytes. In this paper, we focused on security performance rather than code size. Code area layout can be optimized if necessary.
4.4. Set Accurate Arguments
We wrote a linker script, placed each function at a specific address in the physical memory, and extracted the starting address and size for each function in the previous step. In this step, the temporary arguments can be modified correctly. In Algorithm 3, we first find the call instruction and check whether the called function is
. We also read the arguments of the called
. If the value of
in the arguments is 1, we modify the arguments to fit the current function region. If the value of
in the arguments is 2, it means the next instruction is the call instruction. We can check the next instruction’s called function and modify the arguments of
.
| Algorithm 3 Set Arguments |
- 1:
MPU configuration function - 2:
called function from function call instruction - 3:
arguments of the current function - 4:
arguments of the next function - 5:
region number included in arguments - 6:
current instruction in BB -
- 7:
setOperand(): set argument of function -
- 8:
if then - 9:
if then - 10:
if then - 11:
setOperand() - 12:
end if - 13:
if then - 14:
setOperand() - 15:
end if - 16:
end if - 17:
end if
|
4.5. Transformed Function for the ACE-M Technique
The code for an MPU region configuration is required for each function to apply ACE-M. A function that does not contain a call instruction within the function only transforms the first BB and the last BB, as shown in
Figure 7. Basically, in the first BB, the current function area is set at R1. In the last BB, int R2, the area for the caller is set to return to the caller. In ACE-M, the function region currently being EXECUTED is set in R1. That is, when moving to the callee using a call instruction, the area of the caller is set in R1. Based on this configuration, the callee is the first to back up the information on the caller, and the MPU settings can be executed using this information before the return instruction. The function including the call can be confirmed using
Figure 8. This process is the same as setting the target function area to be called at R2 before calling and setting the function area currently being performed at R1 when returning. By inserting the MPU configuration code into the function, an attack occurring at runtime may be detected.
4.6. Detection Scenario Using ACE-M
Figure 9 shows an execution scenario in which a CFE is detected. During this process, Function B is called from Function A and returned from Function B to Function A. It is assumed that the address of Function C overwrites the RA while returning from Function B. In this case, the last MPU configuration performed corresponds to ➃. Function C is not included in the R1 and R2 regions at that time and thus cannot be executed by R0. This situation is considered a CFE, and the MPU raises a memory management fault.
4.7. Transformed Function for ACE-M Technique
Our technique can prevent stack smashing as well as CRAs. In this paper, we assume that the program is executed only in the code memory region. That is, the region excluding the code memory region becomes an NX area. This assumption may be simply satisfied because it is possible to set the program so that it will not be executed in the SRAM through the MPU. In addition, this method becomes a technique that blocks a stack smashing attack. CRAs such as ROP and JOP can also be detected using the proposed method. ROP and JOP eventually perform any operations the attacker intends by chaining a gadget in the code domain. To execute gadgets, the PC must point to the starting address. This area is not included in the MPU region that we have set to satisfy the CFI. This limitation can be enforced because our technique pre-sets the function area to be branched rather than comparing the TA, and the MPU detects CFEs. However, there are some limitations to our work. The technique we propose increases the performance overhead and code size, which are limitations of existing software-based CFI. In addition, fragmentation occurs between functions in the memory layout process that maps the function to the MPU area. In addition, we specify the environment for the executing program to ensure security, our system is bare-metal, and the program must be performed using a single thread, which is necessary because the MPU mapped to each thread must be separately managed, and requires its own function modifications. ACE-M cannot be applied when using library functions other than those that are already compatible. Since most of the overhead that occurs due to our technique is caused by the insertion of the MPU setting function, optimization of these functions can lead to a reduction in overhead. We will leave this optimization step as a future task.
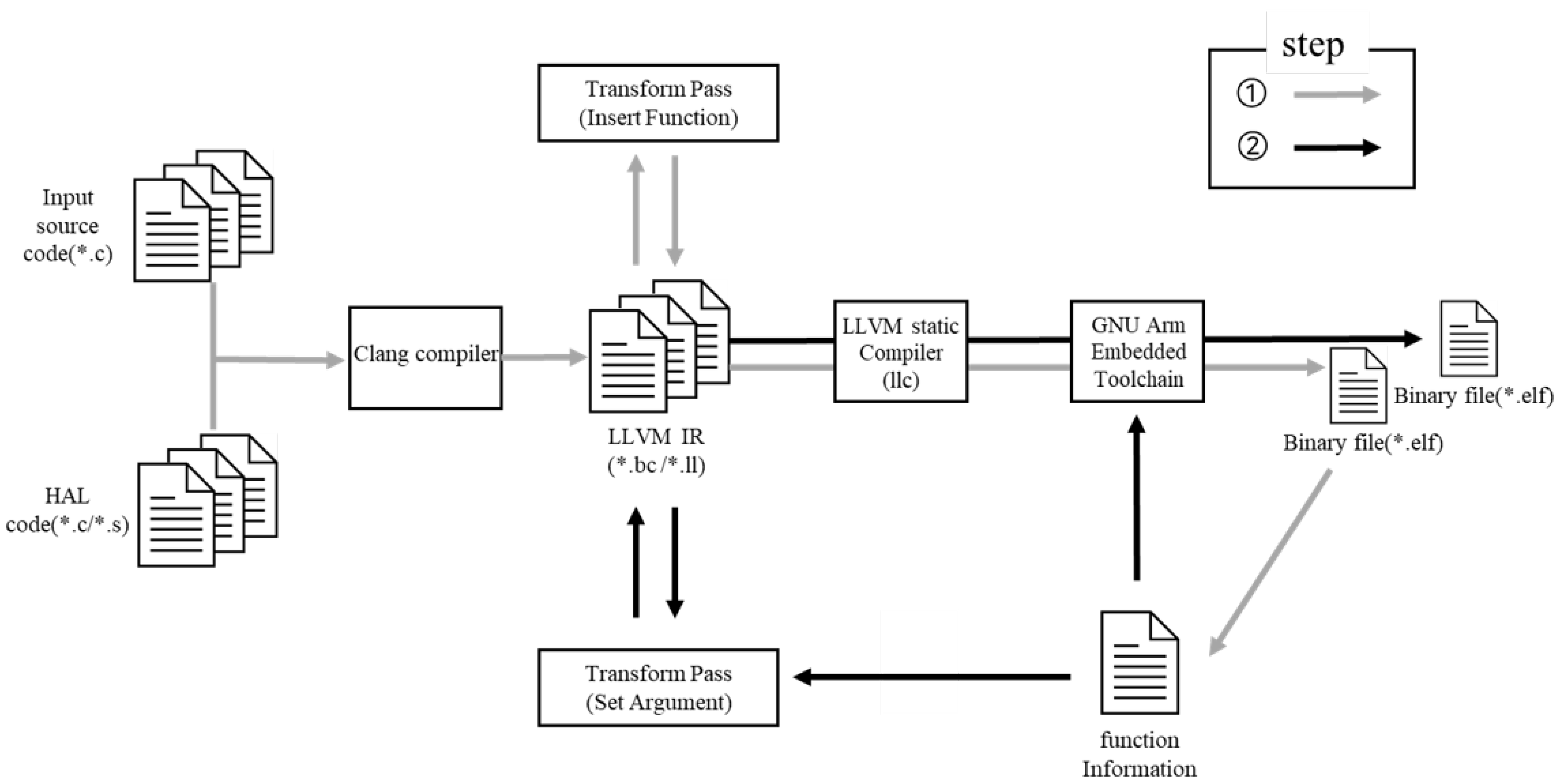
5. Code-Generation
In this section, we explain our workflow for generating the binary code to which our technique is applied as shown in
Figure 10. In general, a compiler consists of front-end, middle-end, and back-end stages. In this case, a compiler is required as much as the product of the programming language and the execution architecture type. LLVM has been developed to cope with this problem.
5.1. Clang
The Clang compiler compiles languages such as C, C++, and Objective-C, and it works with LLVM. Clang is primarily used as the LLVM front-end. The source code, which is written in C, is compiled into LLVM intermediate representation (LLVM IR), which is provided by LLVM.
5.2. Optimization in Middle-End
In the middle-end, LLVM IR can be analyzed and transformed using LLVM Pass. An existing pass or custom pass can be used during optimization. We implemented our custom pass, which inserts a function and a pass that sets the Arguments.
5.3. Binary Code Generation
The LLVM static compiler compiles the LLVM IR code into a target file suitable for the system’s architecture. Finally, we generate an executable object file using a linking process through a linker provided by the GNU Arm Embedded Toolchain.
6. Performance Evaluation
In this section, we evaluate the ACE-M technique and analyze its overhead. The evaluation metrics include the detection rate, cycle count overhead and code size.
6.1. Evaluation Environments and Benchmarks
To verify the validity of the proposed ACE-M technique, we evaluate each metrics in the STM32CubeIDE debug environment, and the STM32F407VG development board was used. We use Embench-iot, which is included in open source Benchmarks for Embedded Platform. However, ACE-M requires modification of all running functions, so benchmarks with library functions were excluded.
6.2. Detection Rate
In computer security, the ability to execute arbitrary commands or code is called arbitrary code execution (ACE). We evaluated our detection performance by imitating it in a debugging environment. ACE is generally conducted through control of the running process’s instruction pointer. Instruction pointers generally refer to the PC, and the PC refers to the address of the instruction to be executed next. Therefore, it is possible to check whether a CFE has occurred by arbitrarily changing the PC value, and if a CFE is generated, the MPU raise a memory management fault. When modifying the PC value in the memory address, excluding the function included in the MPU region, it correctly made detections as 100% of the time. In addition, since our technique alternates between using MPU regions R1 and R2, it can also make detections when moving to other functions not in the CFINs. For example, a program may not return to the next instruction of the call. In that case, it can detect a CFE when the next MPU code is executed.
6.3. Execution Cycle Counter Overhead Analysis
We measured the execution time using a data watch and trace unit (DWT) containing a clock cycle register (CYCCNT) in a Cortex-M3/M4.
Figure 11 compares the basic benchmarks and benchmarks with ACE-M using the CYCCNT. The benchmarks had performance overheads of 56.28%, 8.56%, 6.98%, 20.63%, 30.76%, 4.07% and 3.88%.
In our technique, MPU configuration codes are inserted to ensure CFI. Since these are the same size in every existing function, a relatively small function can incur a considerable overhead. Therefore, it was confirmed that an average of 5.87% overhead occurred in the benchmarks, where the CYCCNT is approximately 6000 or more due to the relatively large size of the program. Although not expressed in the graph, in the case of the crc_32 benchmark, the performance overhead increased by approximately 80%, which confirms that small functions were continuously called in a loop. After that, we made this small function an inline function and evaluated it again; it recorded an overhead of only 0.76%.
6.4. Code Size Overhead
Figure 12 shows the increase in code size that occurs for a major single function in the benchmark. The code used for MPU setting is inserted in the basic function. The actual function size is the size of the existing function plus the configuration function, but occupied size becomes larger because the rest of the region cannot be used for other purposes. The best case is a case in which the configuration code inserted is a multiplier of 2 or a bit smaller. Conversely, the worst case is a case in which the configuration function is added and slightly exceeds a multiplier of 2. This scenario may cause a problem in which more memory is used, up to the corresponding function size.
7. Conclusions
In this paper, we propose ACE-M, which is based on the MPU. For our technique, we insert MPU configuration codes into functions. This strategy is similar to those used in previous studies. However, ACE-M does not compare TA values to enforce CFI. The MPU can provide execute authority to the function region. Unlike other techniques, these settings are valid not only for CFINs but also while the corresponding function is being executed. For this reason, we could detect CFEs caused by soft errors. However, since the configuration code must be inserted, the size of the code increases and the time overhead is inevitably incurred. We measured the execution time overhead using the CYCCNT register included in a Cortex-M3/M4, and the results showed an overhead of approximately 5.87% when executing a program with an overall CYCCNT exceeding 6000. It is possible to improve the security of existing small low-end embedded systems using an MPU. Our technique’s coverage is only for the bare-metal systems, but this approach can be applied to specific processes in other systems. In future work, we will work on optimizing the inserted code and memory layout so that it has a lower overhead. In addition, it seems that such overhead can be lowered through hardware-based design adopting the method of ACE-M while maintaining the detection rate.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}