1. Introduction
In recent years, unmanned aerial vehicle (UAV) networks have received considerable interest in both industrial and academic research owing to their potential applications in surveillance [
1], computationally intensive tasks for low-powered Internet-of-Things (IoT) devices [
2], wildfire monitoring [
3], agricultural surveying, and aerial base stations (ABSs) [
4]. UAV swarm networks can efficiently accomplish complex tasks through autonomous collaboration. This is primarily because of the significant development of enabling technologies such as sensors, batteries, formation control, localization based on the global positioning system (GPS), and range-free and range-based localization in GPS-denied environments [
5]. Low-altitude UAVs, commonly known as drones, have exhibited considerable promise in a wide variety of applications designed to mitigate disease outbreaks, such as the current COVID-19 pandemic. The UAV swarm can be deployed to perform crowd surveillance, provide public announcements to enforce social distancing, spray disinfectants in contaminated areas, and transport medical supplies to remote areas. In addition, UAVs equipped with thermal cameras can capture large-scale temperature measurements in crowded places [
6]. Owing to the flexibility in mobility adjustment, UAVs are also used as a mobile power beacon broadcaster to optimally transfer energy to the low-powered IoT devices [
7].
A UAV swarm can collaboratively sense a particular mission area to capture continuous video and three-dimensional (3D) light detection and ranging mapping (LiDAR) images using onboard sensors. The data collected by each UAV must be transmitted to a base station (BS) with a minimum delay and energy-efficient routing for further processing. This multi-UAV collaborative network, also known as flying ad hoc networks (FANETs), has several key challenges such as a dynamic time-varying topology owing to the mobility of UAVs in 3D space, node density representing the trade-off between sensing coverage and quality of service (QoS) in communication [
8], limited transmission range, and limited onboard energy. Although UAV swarms have a wide range of applications, they should generally involve cooperative coordination to achieve mission objectives. Simultaneously, they should consider all constraint resources to optimize the overall network performance to ensure the desired signal-to-interference-plus-noise ratio (SINR) in the aerial links. Therefore, proper collaboration among UAVs is necessary to achieve a balance between mission performance, such as maximizing the coverage to the mission area or ground users (GUs), and communication performance to achieve a desirable connectivity rate with minimal delay in the aerial links.
To achieve coverage efficiency, UAVs may frequently fly away from each other’s transmission ranges, which causes frequent link breakages. Frequent link breakages during data transmission may increase the number of retransmissions that consume more energy, increase the number of collisions in the medium access control (MAC) layer, and consume unnecessary bandwidth of wireless links. To maintain a better SINR, UAVs should not frequently fly away from each other’s transmission ranges. Simultaneously, UAVs should maintain a certain separation distance to avoid physical collision and maximize sensing coverage toward the ground terminal. Therefore, UAVs in the swarm should maintain a strong neighbor relationship and optimal node density to maintain a stable topology for each time interval via proper topology control by following the three principles of flocking: separation, cohesion, and alignment [
9]. The separation rule aids UAVs in maintaining a particular separation distance to avoid inter-UAV collisions and maximize coverage. The cohesion rules define the mobility of each UAV in the swarm to be attracted to the average centroid of the neighboring UAV positions. This aids the UAV swarm in staying close to each other to avoid frequent link breakages. Finally, the alignment rule requires that each UAV adopt a velocity direction according to its neighboring UAVs. Similarly, in complex environments, UAVs can sense the presence of external obstacles and generate external obstacle avoidance rules. Each flocking rule generates one motion component, and the sum of these motion components determines the optimal mobility of UAVs [
10]. The adaptive adjustment of the weight of each rule can generate a smoother and more energy-efficient trajectory for UAVs [
11].
Topology control in a FANET is a mechanism of coordinating and optimizing the mobility of UAVs (position, velocity, and acceleration) according to the transmission range of each UAV, which can produce a network with optimal transmission power and node density. Topology control reduces energy consumption, improves connectivity, and facilitates wider coverage with desirable throughput by controlling UAV mobility and transmission power [
12]. Compared with centralized control, the distributed control of the UAV swarm enhances stability and routing efficiency by maintaining neighbor intimacy utilizing one- or two-hop neighbor information. Centralized control provides less scalability and causes the possibility of a single point of failure. It also consumes a high bandwidth because each UAV must transmit its mobility information to a central node to update the topology. However, considerable theoretical disputes occur regarding UAV swarm control based on partial and relative local knowledge without the intervention of a central controller. Recently, significant developments have been achieved for the distributed control of UAV swarms, in which local optima are avoided by utilizing several metaheuristics [
13] and game-theory-based optimization [
14,
15]. The major limitation of metaheuristics and game theory is their high computational complexity with increased nodes and topology size. Therefore, to satisfy the scalability requirement and solve existing challenges such as delay, energy constraints, and mobility, an intelligent alternative approach that can perform multi-objective optimization adaptively in highly dynamic FANETs is required. Distributed algorithms such as the artificial potential field (APF) [
12,
16], virtual force [
10,
17], and boid flocking [
9] have attracted the interest of researchers in constructing topology in FANETs by producing optimal mobility of UAVs in FANETs. These algorithms are highly efficient at performing external obstacle avoidance [
11], generating a smooth trajectory for UAVs [
10], and maximizing coverage under connectivity constraints [
18,
19]. The adaptive adjustments of their attractive and repulsive force fields also support the maintenance of an optimal node density in FANETs to minimize interference in aerial links [
12,
20].
In FANETs, link quality depends on several parameters, such as inter-UAV distance, node density, SINR, delay, relative mobility, and residual energy of relaying UAVs. The optimal node density and link SINR can be achieved by jointly optimizing the UAV mobility (position, velocity, and acceleration) and transmitting power according to the inter-UAV distance by adopting a topology control technique [
12,
21]. The link delay includes MAC-layer channel access, queuing, propagation, processing, and transmission delays. The optimal resource allocation in resource-constrained FANETs, such as physical-layer UAV transmission power, MAC-layer time slots, or frequency resources, can significantly improve the SINR level in aerial links. Thus, this sequentially improves the network-layer performance (relay selection) as they are highly coupled.
Owing to the above advantages, researchers have jointly considered the MAC layer delay, link SINR, relative mobility, position progress to the destination, and residual energy of neighboring UAVs, to design a multi-objective reward function in reinforcement learning (RL)-based algorithms [
22,
23,
24]. RL is an area of machine learning concerned with how intelligent agents ought to take an action from a specific state by interacting with an environment to maximize rewards. Through the iterative state transitions, an agent learns how to choose an optimal action. Thus, RL-based action can be formulated as a Markov decision process (MDP) tuple consisting of state, action, and reward. The state represents the consequences that an agent faces in a dynamic environment by taking actions according to the learning policy. Through sequential action and utilizing previous experience, RL agents can make wiser decisions to reach a common objective. In communication theory, RL is applied in many scenarios such as channel modeling, resource allocation, and security [
25,
26]. Recently, RL has been widely used in FANETs to design the smooth collaborative trajectory planning for UAV swarms with collision avoidance [
27], and routing protocol design [
23]. Q-learning (QL) is a model-free value-based off-policy RL approach, which can obtain an instant optimal policy based on historic experiences even without prior information of the environment or even without the intervention of any central controller [
28]. Here, each agent makes an optimal decision based on its neighbor state information, which can be treated as partial MDP (PMDP).
According to our earlier discussion in this section, we can say that the topology controller (formation controller) iteratively updates the mobility of each UAV within a swarm by using the mobility information of its one-hop neighbors. Additionally, the output of the topology controller decides the topology of the UAV swarm by predicting the present and future mobility information for each UAV (acceleration, velocity, position, and flying direction) [
21]. Thus, we can say that relative trajectory knowledge given by the formation controller and link stability is highly coupled [
29]. It can ensure stable connectivity between UAVs during flocking. The formation controller updates the mobility information for each UAV in the next timeslot based on the mobility information in the current timeslot, which indicates the similarity with the Markov property. This is because the Markov property states that the next states of the process depend only on the current state of the process. As a result, QL-based PMDP formulation can be adopted to make routing decisions to find the most stable path in FANETs. Owing to this relationship, researchers have used the QL technique to select the optimal relay nodes for forwarding data in FANETs by designing a multi-objective reward function. Because the reward function reinforces the action policy of an RL agent and accelerates the algorithm convergence for optimal decision making, a good reward function considering multiple objectives (delay, relay node energy, and distance progress toward the destination node) gives better routing performance in FANETs. Consequently, this joint consideration of multiple objectives significantly improves the packet delivery ratio (PDR), throughput, end-to-end delay, and balances the energy consumption in FANETs. Considering the high mobility, constraint energy, and memory resources of UAVs, the QL method is more suitable for FANET routing decision making than deep reinforcement learning because it is computationally more expensive and requires a large memory to store training samples and a history of action–reward pairs. The relationship between QL and position-based forwarding is discussed further in
Section 3.
In FANETs, UAVs can utilize the GPS to localize them in global coordinates. In a GPS-denied environment, UAVs can use range-free and range-based cooperative localization techniques to identify self-location and the location of neighbors [
14,
19]. Consequently, position-based routing can be effectively used in dynamic FANETs. In this article, we only extensively survey existing QL-based position-aware routing protocols for FANETs. We also discuss open issues and challenges and their potential research directions related to QL-based position-aware routing in FANETs.
In the following subsections, we address related studies and summarize the contributions of this study.
1.1. Related Studies
In this subsection, we discuss recent survey papers related to FANET routing protocols and the limitations of existing FANET routing protocols. Additionally, we discuss the motivation for our research and the key contributions of this survey paper.
According to previous studies [
30,
31,
32], the routing protocols in FANETs are classified as topology- and position-based. Topology-based routing protocols can be further classified as proactive, reactive, and hybrid routing protocols. Proactive routing protocols produce a large overhead to maintain the updated routing table for a dynamic topology. Thus, they consume higher bandwidth and energy, which is not suitable for resource-constrained FANETs. Additionally, they exhibit a slow reaction to a highly dynamic topology, which causes delays, routing loops, and blind paths [
23]. A loop-free property is essential for dynamic FANETs to prevent data packets from being continually routed through similar nodes or paths. Blind path challenges occur in FANETs when the neighboring UAVs leave the transmission range of the corresponding source UAV within the intermediate time of the topology update because of several reasons such as sudden changes in relative mobility, requirements for energy replenishment, and UAV failure [
23]. Additionally, FANETs may encounter frequent link breakages if the selected relay UAV leaves the transmission range of the corresponding source UAV during data transmission. Both the blind path and link breakage phenomena produce high retransmissions, delays, and energy consumption in FANETs.
In [
33], the authors studied the optimized link-state routing protocol (OLSR), which encounters higher overheads and routing loops and has a slow reaction in highly dynamic networks. Similarly, in [
34], the authors studied the destination sequenced distance vector (DSDV), which consumes a large portion of the network bandwidth and provides a very high overhead owing to periodic updates in FANETs. Reactive routing protocols result in higher latency and delays owing to the on-demand route-discovery process. Additionally, in large-scale FANETs, the network overhead increases for reactive routing owing to an increase in the header size of the routing table [
35]. In [
32], the authors reported that dynamic source routing (DSR) provides a comparatively lower overhead at the cost of delays in route discovery. However, for large-scale FANETs, DSR routing encounters an extremely high overhead owing to an increase in the routing discovery table header [
35]. Similarly, ad hoc on-demand distance vector (AODV) routing encounters route failures, higher delays, and higher bandwidth consumption in large-scale FANETs [
34]. Hybrid routing protocols encounter higher computational complexities and overhead owing to the complex clustering, cluster-head selection, and cluster maintenance processes [
3]. Therefore, all these traditional topology-aware proactive, reactive, and hybrid routing protocols encounter several limitations in highly dynamic FANETs owing to the high control overhead and large delays in neighbor and path discovery [
36]. Additionally, they do not support adaptability to the dynamic topology to discover the efficient routing path autonomously.
In position-based routing, each UAV node utilizes the GPS for localization. In addition, UAVs can use range-free and range-based cooperative localization in a GPS-denied environment. Position-based routing protocols utilize local knowledge, often one- or two-hop information, to make routing decisions. UAVs make forwarding decisions based on their current position, the position of the destination, and the position of their neighbors. In [
37,
38], the authors studied several position-based routing protocols in FANETs by classifying them into the two categories of single-path and multipath strategies. Under the single-path strategy, they reviewed deterministic progress-based, randomized progress-based, and hybrid position-based routing protocols. Deterministic progress-based routing protocols have several relay node-selection strategies, including greedy forwarding, compass forwarding, and most forwarding [
37]. Multipath strategies include restricted direction flooding, random directional flooding, and classic flooding of data packets [
37].
According to the aforementioned study, considering the dynamism in network topology in the 3D space, inter-UAV collision, high overhead, and delay, position-based routing protocols are attracting the interest of researchers. However, position-based routing protocols encounter several challenges in FANETs, such as maintaining the link quality [
39], controlling the hello interval to predict up-to-date topology [
21], localization errors, blind paths, the presence of routing loops, and energy holes [
23]. Additionally, to prolong the lifetime of a FANET, it is necessary to achieve a proper load balance in terms of energy and delay while determining the optimal routing path [
22]. Tracing the shortest routing path may be initially beneficial, but it cannot be an optimal routing path as it depletes the energy of a few selected UAVs, and the shortest paths can be extremely congested by traffic over time [
23]. It also creates energy holes in FANETs because selecting the shortest path always drains the energy of a few selected UAVs. Greedy forwarding cannot ensure optimal performance in terms of energy consumption, delay, and link quality, as it always seeks progress in the transmission distance toward the destination. Additionally, owing to the selection of relay nodes at the edge of the transmission range of the source node, greedy forwarding encounters blind path and link-breakage problems. The compass and most forward techniques have higher possibilities of trapping in routing loops and local minimum [
37]. The term local minimum (routing holes) in position-based routing is defined as the selected relay UAV with no further neighbors to relay toward the target destination node. Flooding techniques in multipath forwarding produce excessive overhead, high MAC layer contention, high bandwidth, and energy consumption.
UAVs in a swarm exchange hello packets to update their position coordinates and residual energy. The low hello-interval provides better positioning accuracy but simultaneously increases the control overhead cost [
21]. Consequently, an adaptive strategy is required to determine the optimal hello interval in FANETs to optimize the control overhead cost and predict the updated network topology. To address the above challenges in position-based forwarding, researchers have proposed intelligent decision-making algorithms in dynamic FANETs utilizing the QL technology incorporated with position-based routing protocols. QL-based routing protocols can perform multi-objective optimization; i.e., delay and energy are minimized by leveraging the PMDP for predicting the dynamic topology with the aid of a topology controller. Recently, a significant amount of research has been conducted to enhance the performance of position-based forwarding techniques by integrating them with QL. The QL model can be trained to identify a link that is trapped in the local minimum in position-based forwarding by providing a minimum reward to the relay nodes for taking a bad action. Additionally, in [
22,
24], the designed QL-model allocates minimum reward to the relay UAVs that do not send the acknowledgment to the corresponding source UAV by considering the failure state of the selected relay nodes. In FANETs, the UAV failure state might happen owing to the hardware failure, the depletion of UAV energy, and the environmental dynamism encountered by the UAVs (external obstacles). Thus, a robust self-healing topology controller is required to reestablish the swam topology without creating any partition in topology, while performing the mission in a complex dynamic environment [
11,
17].
So far, the comprehensive review articles on position-based routing protocols in FANETs discuss the different relay UAV selection mechanisms by considering the path selection strategy, bio-inspired swarming, and topology-based routing [
37,
38]. The QL-based routing protocols incorporated with position-based forwarding techniques are new research trends for FANETs, which are not covered by the existing survey works. Motivated by this, we surveyed all the recently proposed QL-based position-aware routing protocols in FANETs, most of which are published in reputed journals. In our earlier study [
40], the relationship between QL and routing was reviewed, and seven QL-based routing protocols for FANETs were discussed and compared qualitatively, primarily focusing on key features and performance challenges. However, in this review article, we define the FANETs, their components with functionalities, and dynamic FANET topology. Then, we extensively study the realistic mobility models in FANETs according to their applications and define the QL and its relationship with dynamic FANETs. Additionally, we comprehensively review each protocol with its advantages and limitations, and then perform a comparative study considering important performance metrics for FANETs. According to our comparative study, we find key open issues and discuss their potential research directions.
According to the above discussion, related review articles on FANET routing protocols are summarized in
Table 1 to indicate our key contributions.
The limitations of topology-based proactive, reactive, and hybrid routing protocols are summarized in
Table 2.
The limitations of position-based routing protocols for FANETs are summarized in
Table 3.
According to the above discussion, the features supported by QL-based position-aware routing protocols are listed in
Table 4 compared with only position-based forwarding techniques.
1.2. Contribution of This Study
The key contributions of our study can be summarized as follows:
We discuss all the realistic mobility models for highly dynamic FANETs based on suitable applications.
We extensively review recently published QL-based position-aware routing protocols and their advantages and limitations.
Existing routing protocols are qualitatively compared in terms of their main concepts, key features, performance metrics, and implementation aspects.
We summarize all the important performance enhancement criteria (in the Lessons Learned section) to design QL-based routing protocols using the position information.
We identify open issues and research challenges in designing QL-based position-aware routing protocols and their potential research directions in highly dynamic FANETs.
1.3. Organization of This Article
The remainder of this paper is organized as follows: In the next section, we discuss FANETs, their components, their dynamic time-varying topology, and suitable mobility models for FANETs. In
Section 3, we briefly review the QL algorithm and its relationship with routing in FANETs. In
Section 4, QL-based position-aware routing protocols are extensively reviewed, and their respective advantages and limitations are outlined. In
Section 5, existing QL-based position-aware routing protocols are qualitatively compared. In
Section 6, the open issues and research challenges associated with the respective potential research directions are discussed. Finally, the paper is concluded in
Section 7.
2. Flying Ad Hoc Networks
In this subsection, we briefly discuss FANETs, their components, and the functionalities of each component. We then define the dynamic topology of FANETs. We also discuss the differences of FANETs from other ad hoc networks. Finally, we review the suitable mobility models for FANETs according to the application scenario.
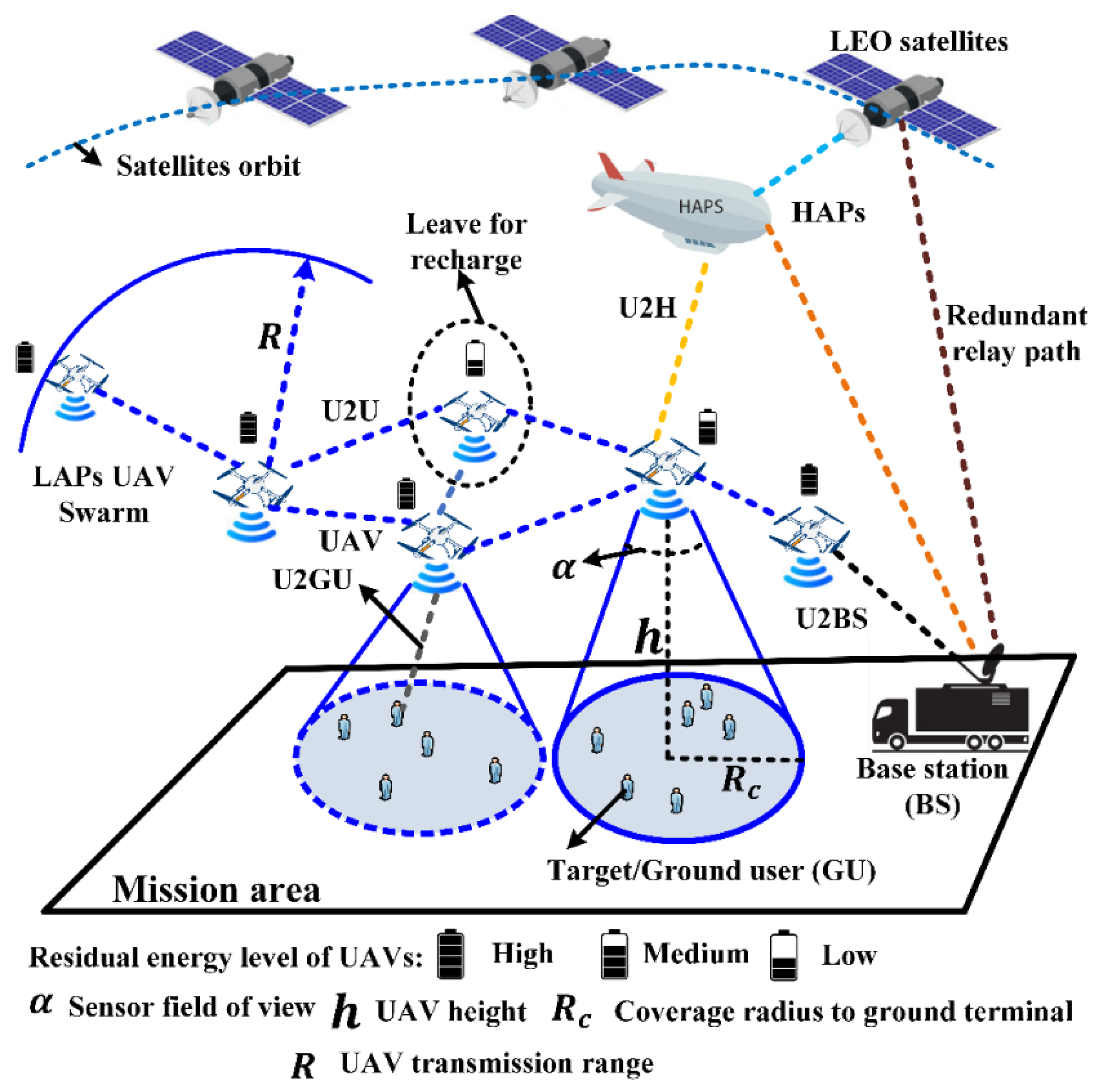
FANETs primarily consist of UAVs that mimic the behavior of swarm intelligence and collaborate with each other and the terminal BS/IoT devices/sensors/GUs or edge–fog–cloud to form an autonomous self-organized multi-UAV communication system. In FANETs, terrestrial devices are swapped with UAVs and can establish communication in any type of emergency without requiring any fixed network infrastructure. In emergency applications, when a terrestrial communication infrastructure or ground sensor network is unavailable, UAVs can be deployed to sense remote areas, utilizing their advantages, such as flexible 3D mobility, fast deployment, and large birds-eye vision. Each UAV in the swarm can sense, execute a computationally intensive task locally or by offloading to the nearest edge server, communicate, cache data, and operate as a router to forward remote UAV sensing data to the BS for further processing. Thus, a FANET has two major parts: terrestrial and non-terrestrial parts (
Figure 1).
The terrestrial section frequently consists of single or multiple fixed or mobile BSs, charging stations, edge-computing servers, GUs, and different types of sensors or IoT devices. The mobile BS can be a ground vehicle with charging stations at the top of the vehicles or edge-computing servers to perform computationally intensive tasks for UAVs. FANETs can also collaborate with existing terrestrial BSs on an on-demand basis to expand the capacity of wireless networks. When the residual energy level of an UAV reaches the minimum threshold level, UAVs can leave the aerial network through an optimal charging-scheduling algorithm to obtain energy replenishment at particular wireless charging stations located at the BS. Instead of wireless charging techniques, UAV batteries can be swapped at the BS before returning to the aerial network. The BS can also function as a gateway to connect FANETs with external wired networks, i.e., the Internet.
The non-terrestrial section consists of a set of homogenous or non-homogenous [
1] UAVs operating collaboratively at different altitudes. There are many types of UAVs, and researchers select the UAV type according to their application requirements. In [
26,
30], the authors classified UAVs according to their size, flying altitude, payload capacity, battery capacity, and endurance time. They classified UAVs into high-altitude platforms (HAPs) and low-altitude platforms (LAPs). HAPs have a high payload capacity, long endurance, and high-energy storage systems. HAPs are quasistatic and are deployed to perform a long-term mission. In this survey, we primarily focus on LAP UAV missions. LAP UAVs can be classified as fixed-wing (small aircraft), rotary-wing (single rotor or multi-rotor), and small tethered balloons. Among them, rotary-wing, particularly multi-rotor UAVs, are mostly used in surveillance and ABS applications as they support vertical take-off and landing, hovering, and provide better formation stability. In addition, multi-rotor UAVs fly in confined areas.
Typically, each UAV has four major modules: flight control, energy management, computation, and communication modules. The flight-control module is responsible for controlling the mobility of UAVs in a 3D space. The mobility information of UAVs in a 3D space can be described by six degrees of freedom (DoFs): surge, heave, sway, pitch, yaw, and roll. The formation controller obtains the optimal mobility control policy by adjusting these six DoFs according to the neighbor UAV mobility (position, velocity, and acceleration) and targets or the GU distribution/mobility within the mission area. It determines the optimal 3D positions and linear/angular velocity for each UAV to achieve both the mission and communication performance. The term surge defines the UAV’s forward and backward movement on the X-axis, the sway defines the left and right movement on the Y-axis, and the heave defines up and down movement on the Z-axis. These three terms are used to calculate the 3D Cartesian coordinates of the UAVs, and the rate of change of these 3D coordinates defines their linear velocity. Similarly, the term roll defines side-to-side tilting on the X-axis, the pitch defines forward and backward tilting on the Y-axis, and the yaw defines left and right turns on the Z-axis. These three terms (roll, pitch, and yaw) define the attitude angles and angular velocities. The energy management module produces continuous power for UAVs to generate thrust using UAV rotors and propulsion energy to continue flying in the air. It also supplies energy to perform the computation of different algorithms to execute the mission and communicate with other neighboring UAVs, remote BSs, or GUs with the aid of a communication module. Frequently, the propulsion energy of an UAV is significantly higher than the communication energy. The propulsion power consumption is proportional to the UAV trajectory [
41]. Thus, in UAV missions, the joint optimization of UAV trajectory and UAV communication provides better energy efficiency [
41]. The computation modules execute algorithms to process the collected data using onboard sensors such as cameras, LiDAR, sound navigation and ranging (SONAR), and inertial measurement units (IMUs). Communication modules consist of wireless radio antennas and wireless interfaces.
There are various communication links in FANETs depending on the mission planning and control methods. These communication links can be classified as air-to-ground (A2G) and air-to-air (A2A) links. Generally, A2G links include UAV to BS (U2BS) and UAV to GU (U2GU). Similarly, the A2A links are UAV to UAV (U2U), UAV to HAPs (U2H), and UAV to low earth orbit (LEO) satellites (U2S). UAVs can directly communicate with satellites [
42], particularly with GPS, to localize themselves in global coordinates. LAP UAVs communicate with the BS using U2BS downlinks. U2BS and U2GU links are mostly Wi-Fi links, and they have low costs in terms of delay, transmission power, latency, and path loss in line-of-sight (LoS) scenarios. However, the quality of the A2G links significantly degrades in the no-line-of-sight (NLoS) scenarios, particularly in the urban environment. However, depending on the signal quality and mission design, LAP UAVs can also utilize U2H or U2S uplinks to communicate with the BS as a redundant path [
43]. A2A links are mostly considered free-space paths and are dominated by LoS links [
1,
15]. However, owing to the high mobility and energy limitations of UAVs, these paths encounter high dynamism, Doppler effects, and link breakage.
2.1. Dynamic Topology in FANETs
The topology of a FANET can be described as a time-dependent graph, where the connectivity among UAVs is subject to change owing to the mobility of UAVs and their limited battery capacity. Frequently, the FANET mission execution time (
T) is divided into sufficiently small time slots (
) of equal length, and in each time slot, the mobility of the UAVs is considered static. Thus, in FANETs, the network topology can be expressed as a time-dependent undirected graph:
. Here, the vertex
consists of
UAVs and single or multiple BSs, and
represents the network edges. In each
, if the distance between two UAVs is
, where
R is the LoS transmission range of each UAV, a direct edge between two UAVs
is considered. In each
, UAVs can leave the aerial network to obtain energy replenishment at charging stations located in the BS and rejoin the aerial network after receiving energy replenishment. The sensor coverage radius (
) of an UAV depends on the UAV height (
) and sensor field of view (
) (see
Figure 1). With increasing
,
and the probability of obtaining an LoS to the ground terminal increase. Simultaneously, the path loss to the ground terminal increases. Thus, the height of UAVs must be optimized according to the distribution of GUs, mobility of GUs, mission environment, and the application type of FANETs.
2.2. Mobility Models in FANETs
The performance of routing protocols in FANETs is generally evaluated using testbed experiments or simulations in software environments. A testbed enables the performance of the designed routing protocol in real environments to be evaluated. However, owing to the high hardware cost, time requirements, and complexity of constructing large-scale networks with different topologies in testbed scenarios, software simulations are generally preferred for assessing performance. Software simulation-based evaluations of routing protocols in FANETs require a suitable realistic mobility model to define the optimal trajectories of each UAV in the swarm and to specify how their six DoFs (linear and angular velocity, position, attitude angles, acceleration, and direction) change with time in a 3D space.
The mobility models in FANETs should be focused on the type of UAV swarm mission and be suitable for FANET applications such as surveillance, ground target searching and tracking, and search and rescue operations. The mobility model in FANETs should satisfy the following requirements: UAVs should autonomously adjust their flying directions and plan their displacements according to the mobility information of their neighboring UAVs and the location of the target at the ground terminal. Each UAV should maintain a particular safety distance to avoid inter-UAV collisions while simultaneously staying adequately close to ensure QoS in aerial connectivity. Each UAV should be able to join or leave the FANET arbitrarily. To preserve coordination and synchronization in movements, UAVs should continuously adjust their position and velocity according to the mean velocities of neighboring UAVs. The trade-off between maximizing sensing coverage and aerial connectivity [
8] and self-healing to the failure of a neighboring UAV should be satisfied. The trajectory of each UAV in a swarm should be smooth, and the moving trajectory of each UAV should maintain fairness in terms of travel distance to maintain a balance in the energy consumption of UAVs within the swarm [
44]. Additionally, when UAVs fly over the mission area, they should cover each zone evenly, and repetitive coverage should be avoided as much as possible to improve the search efficiency [
44]. Finally, UAVs should be aware of external obstacles when adjusting their mobility. Owing to the above requirements, the mobility models in FANETs are unique and differ from the mobility models proposed for mobile ad hoc networks (MANETs) and vehicular ad hoc networks (VANETs). A realistic mobility model with a proper topology can jointly optimize the mission performance and communication performance.
Several survey papers on FANET routing protocols have comprehensively reviewed mobility models in FANETs. In [
30], the authors provided a novel taxonomy for mobility models in FANETs by classifying them into five different categories: random-based, time-based, path-based, group-based, and topology-based. In [
31], the authors briefly discussed mobility models for FANETs, including random direction, random waypoint (RWP), reference point group mobility, Gauss–Markov, semi-random circular movement, Paparazzi, and smooth-turn mobility models. However, none of these mobility models adopt the collaborative and cooperative properties of swarm intelligence and they are mostly suggested for MANETs and VANETs [
9]. Additionally, the aero dynamic constraints and UAV six DoFs are not taken into account by them [
21]. FANETs differ from MANETs and VANETs in terms of their 3D mobility, node density, rate of topological alterations, and energy limitations. Both MANET and VANET nodes have two-dimensional mobility, and VANETs have higher mobility than MANETs. However, in VANETs, nodes are not energy-constrained, and their mobility is limited by roads [
45]. Thus, the topology prediction in VANETs is much easier than that in FANETs. In FANETs, UAVs have mobility with six DoFs, the presence of external obstacles, limited energy, system stability to ensure stable links, and restricted trajectories owing to collaborative motion planning. Thus, the mobility models proposed for MANETs or VANETs are not suitable for application to FANETs. Motivated by these limitations of previous studies, we provide a brief review of realistic FANET mobility models that mimic the characteristics of a swarm according to recently published research articles.
In [
9], the authors proposed a novel mobility model for FANETs inspired by boid flocking. They defined the neighbors of UAVs into three categories by dividing the transmission range of UAVs into three zones: repulsive, stable, and attractive. They updated the accelerations, velocities, and positions of UAVs by applying seven different rules: separation, cohesion, alignment, centripetalism, consistency, and synchronization. Each of these rules defines one motion component, and the summation of these rules defines the optimal mobility for each UAV in the swarm. This behavior-based mobility model, inspired by bird flocks, supports both the coverage and connectivity requirements of FANETs with inter-UAV collision avoidance. Thus, it is suitable for performing surveillance, target searching, and rescue operations in emergency scenarios.
Similarly, in [
4,
10], the authors proposed a virtual force-based mobility model for FANETs by applying four different virtual forces to optimally deploy UAVs as an ABS. The virtual forces they considered to obtain the position and velocity for each UAV in the swarm were attractive forces toward the hot spot areas of GUs, attractive forces toward the isolated GUs, repulsive forces to neighboring UAVs to avoid inter-UAV collisions, and repulsive forces to external obstacles to avoid collision with external obstacles. The sum of these virtual forces defines the acceleration, velocity, flying direction, and position of the UAVs. This virtual force-based mobility model supports optimal coverage of the GUs and simultaneously maintains stable bi-connectivity in the aerial network. Additionally, it can generate a smooth trajectory for UAVs while maintaining fairness in the travel distance between UAVs in the swarm. The adaptive adjustment of the attractive and repulsive force weights can effectively manage swarm stability, connectivity, and obstacle avoidance [
11,
17].
In [
18,
19], the authors proposed a mobility model for FANETs inspired by Hooke’s law of springs, which is known as the virtual spring-based mobility model. According to Hooke’s law, they assumed that the force is proportional to spring deformation. In [
18], they proposed a UAV positioning method in a hexagonal pattern to maximize the coverage under QoS in connectivity by defining the attractive and repulsive virtual spring force laws. If the inter-UAV distance crosses the minimum threshold, the spring force is repulsive. In contrast, if the inter-UAV distance crosses the maximum threshold distance, the spring force is attractive. By computing the summation of all virtual spring forces with all neighboring UAVs, each UAV determines the optimal mobility. This type of mobility model is suitable for surveillance missions. Similarly, in [
19], the authors utilized a virtual spring force mobility model to maintain a strong aerial mesh network to provide communication in a disaster scenario. Although this type of mobility model can support coverage and QoS in aerial connectivity, it is not well-suited for external obstacle avoidance.
In [
12,
16,
46], the authors proposed a mobility model using an APF. APFs have attractive fields for neighboring UAVs, repulsive fields to maintain the minimum separation distance with neighboring UAVs, and repulsive fields to avoid external obstacles. The fields are computed according to the inter-UAV distance and the distance between the UAV and obstacles. The optimal mobility of UAVs can be obtained by obtaining the negative gradient of the net artificial potential field. This mobility model is suitable for maximizing coverage under connectivity constraints and avoiding external obstacles and inter-UAV collisions. Many algorithms use APFs to maintain the leader–follower topology [
47], target searching [
46], and predefined trajectory tracking. However, this type of mobility model can easily be trapped in the local minimum problem [
12], particularly in highly confined and dense obstacle mission areas. The adaptive adjustment of the attractive and repulsive force constants of APFs can control the optimal node density in FANETs and minimize interference in inter-UAV communication [
12].
In [
48,
49], the authors proposed a distributed pheromone repel mobility model to execute reconnaissance and target-searching missions. Each UAV maintains its pheromone map and scans the mission area according to its map. The UAVs exchange information among themselves to assemble a global pheromone map. The UAVs turn right or left or travel straight according to pheromone smell probabilities. UAVs prioritize regions with a low pheromone smell to explore more in the mission area and reduce repetitive coverage. The limitations of this type of mobility model are that they only consider target exploration; they do not consider the connectivity among UAVs in the aerial network. Additionally, the trajectories of UAVs are not smooth and become complex.
The realistic mobility models discussed above are summarized in
Table 5 according to their applications in FANET.
3. Q-Learning and Its Relationship with Routing in FANETs
This section provides a brief overview of the effective QL algorithm and its relationship with position-based routing decisions in FANETs.
In QL, agents iteratively adjust their action strategies through the reward that they achieve from the environmental feedback after performing a particular action (
Figure 2). The agent selects an action in a particular state according to the reinforcement or simply the previous experience, known as the Q-value. The reinforcement comprises a direct reward and future Q-value expectation. Through reinforcement, agents can evaluate the effectiveness of an action in the current state and perform a better action in the next step. The objective of the agent is to maximize the expectations of the cumulative rewards over the sequential iteration. The advantage of QL is that the reward function can be designed using multiple weighted objectives to achieve multiple goals. Additionally, a suitable strategy for exploration and exploitation can aid in attaining the global optimal solution.
In FANET routing, the data packets contained by each UAV node (source node) act as agents that function by relaying UAV selections from their neighbor to forward data packets to the desired destination (another UAV or BS). Through this sequential action, the data packets change their states from one UAV to another. This state transition continues until data packets are delivered to the desired destination node. For each action (relay node selection from the neighbor list), the UAV agent (source node) receives a reward or penalty. Gradually, each agent UAV gathers an experience represented by a Q-value that results in an optimal policy in which the cumulative reward is maximized over the iteration. The reward function is designed such that UAVs select an optimal routing path that minimizes the delay and creates a load balance in UAV energy consumption. The penalty mechanism in the reward function is triggered to avoid the local minimum problem if the next state of the data packets does not have any routing path forward toward the destination. It also aids in avoiding the routing loop and minimizes unnecessary detours of data packets during routing.
The QL-based routing decision process can be described as a partial MDP tuple
, where a set of states
represents the
active UAV node positions at each time
, a set of actions
represents the selection of the relay UAV (
) from the neighbor list of the source UAV (
) to forward the data packets to the destination,
represents the probability of successful state transition of a particular data packet from one UAV to another UAV, and
is the reward function that can be obtained by a predefined reward function to evaluate the quality of the action (to select the link
). The Q-values are iteratively updated at each UAV node using the following Bellman equation:
where the term
represent the future Q-value expectation in the next state
after implementing the best action
.
and
represent the learning rate and discount factor, respectively, the values of which are defined within the range
. The significance of
is how rapidly the QL algorithm should learn, and
defines how much the QL algorithm learns from its mistake owing to a bad action. The value of
determines the degree to which the newly obtained information overrides the old information, and this parameter controls the convergence of the learning procedure. The value of
controls the importance of future rewards. In FANETs, to obtain a better learning process and more stable Q-value, the values of
and
should be controlled adaptively with respect to the changes in the mobility of UAVs, considering the dynamic topology. The stability of the topology and the degree of change in the mobility of UAVs can be obtained with the aid of a topology control algorithm. Through proper mobility management defined by the topology controller, a UAV swarm can calculate the mobility factor and link duration [
22,
23]. The parameter link duration defines how long two neighboring UAVs exist within transmission range of each other [
21]. The link duration is a function of the UAV transmission range, relative velocity, and distance between two neighboring UAVs [
21]. If the mobility factor is high and the link duration is low, the discount factor should be low, and vice versa. Thus, by incorporating a topology controller in the routing decision-making process, UAVs can reduce the number of retransmissions. Similarly, the delay, including the MAC-layer, queueing, and transmission delays, can be obtained from the designed MAC protocol and queuing model [
22].
can be adjusted adaptively according to the delay.
In the QL algorithm, an appropriate balance between exploration and exploitation is necessary to avoid local optima. Exploration refers to the seeking of new actions by the agent (source UAV) to gather new experiences. Exploration can provide good or bad rewards, but it can aid in determining the global optima. In contrast, exploitation involves taking action according to previous knowledge (Q-value). Owing to the limited energy of UAVs, excessive exploration can delay convergence and may include many bad actions that may increase the number of retransmissions. Therefore, proper guidelines are required to explore a better state (relay UAV) from the neighbor list.
4. Q-Learning-Based Position-Aware Routing Protocols in FANETs
According to our discussion in
Section 1.1, the routing protocols in FANETs are categorized as topology-based and position-based protocols. In this section, we extensively review the QL-based position-aware routing protocols in FANETs, which is a new research trend. The QL-based routing protocols incorporated with position-based forwarding can be considered as a special subcategory of position-based forwarding, where RL is exploited to make the routing decision. As a result, we do not give any further classification for QL-based position-aware routing protocols as they fall into a similar category. The QL-based position-aware routing protocols along with their optimization objective, advantages, and limitations are comprehensively reviewed according to the order of the published year.
4.1. Q-Learning-Based Geographic Routing Protocol (QGEO)
Jung et al. [
39] proposed the Q-learning-based geographic routing protocol (QGEO) that outperforms position-based routing protocols in terms of PDR and network overhead in high-mobility scenarios of UAVs. Here, each UAV makes a routing decision in a distributed manner by utilizing the one-hop neighbor node position with the aid of GPS and RL. Each node broadcasts hello packets at a fixed hello-interval that includes mobility information (position, velocity, and direction), current Q-value, link condition (link capacity, interference, and delay), and location error. Unlike the position-based routing protocol, instead of only seeking progress in transmission distance toward the destination, it provides a concept for packet travel speed (PTS) to select the next relay node. The PTS jointly considers the distance progress toward the destination and the channel conditions. The channel condition is computed as the packet travel time (PTT), which consists of the MAC delay, transmission delay, link error, and localization error. The relay node that provides a higher PTS receives more rewards and is selected as the next forwarding node.
PTT (
) and PTS (
) between source UAV (
) and relay UAV (
) are computed as follows:
and
where
,
, and
represent the MAC, queuing, transmission, and propagation delays, respectively, for link
.
and
represent the link and localization errors, respectively, for link
.
and
represent the distance between the source UAV and destination BS and the distance between the selected relay UAV and destination BS, respectively. The parameter
means that
indicates the progress of distance toward the destination BS, and a higher value of
means that the link condition of
is good and offers a very small delay.
If a local minimum incident occurs, the corresponding relay node receives a minimum reward as a penalty.
Advantages: QGEO overcomes the limitations of position-based routing protocols by considering link conditions and location errors during the next-hop selection process via QL. QGEO can avoid the local minimum by assigning a minimum reward.
Limitations: QGEO does not consider the mobility control of the UAV swarm and considers a fixed hello interval (4 Hz) during the simulation. The learning rate and discount factor are not adjusted adaptively with the mobility of the UAV swarm. Additionally, the RE of the UAV node is not considered while making the routing decision. QGEO does not consider the balance between exploration and exploitation strategies to explore better relay UAVs.
4.2. Reward Function Learning for QL-Based Geographic Routing Protocol (RFLQGEO)
Jin et al. [
50] proposed the reward function learning for a QL-based geographic routing protocol (RFLQGEO) that provides less retransmission, lower average end-to-end delay, and higher PDR compared with QGEO. RFLQGEO utilizes the inverse RL concept to design the routing decision by exchanging the hello packet, which accelerates the learning process with less communication overhead. RFLQGEO has three components: the location information module, QL routing module, and reward function learning module. The location information module uses hello packets to share the position obtained by the GPS, link condition, residual energy level, link error, location errors, and Q-value with neighboring UAVs. The QL module updates the Q-value using a reward function that jointly considers the distance between two UAVs directed to the destination sink node, PTT including the MAC and transmission delay, link and position error, and void area avoidance feature.
Advantages: RFLQGEO outperforms QGEO in terms of designing the reward function for better learning by including the distance progress in the direction of the sink and void area avoidance component in the reward function.
Limitations: The limitations of RLQGEO are that it does not consider the adaptive control of the hello interval, mobility control mechanism, and exploration and exploitation method to avoid local optima during the learning process. Additionally, the residual energy of the UAV node is not considered in the reward function.
4.3. QL-Based Cross-Layer Routing Protocol (QLCLRP)
He et al. [
51] proposed the QL-based cross-layer routing protocol (QLCLRP), which utilizes the upper confidence bound (UCB) to determine the balance between exploration and exploitation. They proposed carrier-sense multiple access with multi-channel automatic synchronization (CSMA/MAS) to reduce collisions in the MAC layer by maintaining transmission in a round-robin fashion with synchronization. The MAC delay statics are sent to the QL module for better routing decision-making. The Q-value is adaptively updated for better decision-making by updating the learning rate and discount factor according to the mobility of the node and variance of the MAC delay. The reward function includes the difference between the distances between two UAVs projected to the destination and the MAC delay.
Advantages: QLCLRP uses the cross-layer concept with an exploration strategy using UCB that enhances the performance of both the MAC and routing layers.
Limitations: In QLCLRP, the hello interval frequency is not adaptive. It does not consider mobility control and energy-efficient routing, although the exploration rate was defined by calculating the UCB for each source node considering the number of times a node is selected as a forwarding node and the number of times a source node makes the routing decision.
4.4. Multi-Objective QL-Based Routing Protocol (QMR)
Liu et al. [
22] proposed a multi-objective QL-based routing (QMR) protocol for FANETs that jointly optimizes the delay and energy consumption in FANETs while making routing decisions. They proposed a new exploration and exploitation mechanism considering the network condition that includes the PTS, link quality, and relative mobility factor, which aids in avoiding local optima. To make the learning process more efficient and stable, they updated the Q-value by adaptively updating the learning rate and discount factor, utilizing the exponential of the normalized one-hop delay and variation in the neighbor set at two different times, respectively. During exploitation, a better decision is made by the QL module as Q-values are weighted by the link-quality metric. QMR estimates link quality using the expected transmission count (ETX) method [
52].
Advantages: QMR considers a minimum reward policy when the routing loop, local minimum, and node failure-state occur during relay node selection. It jointly considers delay and energy optimization in the reward function.
Limitations: QMR does not consider mobility control and the control of the hello interval. The Q-value is updated without considering the SINR level of the links. Proper mobility control is necessary for QMR, as they provide actual velocity constraints for neighboring UAVs by calculating the PTS to satisfy the deadline PTT during data transmission. A mobility control method can control the relative velocity with neighboring UAVs and maximize the link duration between neighboring UAVs for successful data transmission within PTT.
4.5. QL-Based Multi-Objective Fuzzy Routing Protocol (QLMF)
Yang et al. [
53] proposed the QL-based multi-objective fuzzy routing (QLMF) for FANETs, in which the next hop is selected by sending the link and path-related parameters to a fuzzy controller. The link-related parameters are the transmission rate, energy state, and flight status, such as similarity in the flying direction. The path-related parameters are dynamically updated by the RL, which maintains two different Q-values: hop count and successful packet delivery time. Therefore, the fuzzy controller uses three link-related parameters and two path-related parameters as the input membership functions. Subsequently, the parameter is divided into two-level fuzzy linguistic variables that are inferred with the predefined rule base to select a better forwarding node based on the output crisp value after defuzzification.
Advantages: QLMF outperforms Q-value-based ad hoc on-demand distance vector routing in terms of hop count and energy consumption.
Limitations: Maintaining two different Q-values for each UAV is challenging, and the learning rates are fixed. The delay is calculated considering the number of hops required to reach the destination, which is not appropriate for MAC, queuing, and transmission delays, and must be calculated for precise estimation.
4.6. QL-Based Routing Protocol for FANET (Q-FANET)
Luis et al. [
24] proposed an improved QL-based routing protocol for FANETs (Q-FANET), which consists of two sub-modules: QMR [
22] and Q-noise+ [
53]. In typical QL, the Q-values are updated based on the reward of the most recent episodes. In contrast, considering the mobility in FANETs and dynamic channel conditions, Q-FANET updates the Q-value more precisely by considering the weighted reward for the finite number of last episodes and the SINR level of the selected link. While updating the Q-value, a higher weight is assigned to the recent episodes to obtain a more accurate Q-value. Q-FANET uses the QMR module to select the relay node according to the maximum PTS and to solve the routing hole problem (local minimum). When the routing hole problem occurs, Q-FANET uses the QMR penalty mechanism and allocates the minimum reward to that relay node. Otherwise, a QL module that performs random action (random relay selection) or exploration according to the maximum Q-value is used by adopting the
-greedy policy.
Advantages: Q-FANET provides low delay and jitter for a better quality of service in highly dynamic FANETs. It also allocates minimum reward for bad action to overcome the local minimum, routing loop, and node failure-state in FANETs.
Limitations: Q-FANET uses the -greedy policy with random action (relay UAV selection) to balance between exploration and exploitation. However, random actions without proper guidance may provide less reward and produce higher retransmission in FANETs. Additionally, storing the Q-value for the last finite number of episodes requires extra memory consumption for each UAV.
4.7. QL-Based Topology-Aware Routing Protocol (QTAR)
Arafat et al. [
23] proposed QL-based topology-aware routing (QTAR) for FANETs, which can make better routing decisions by extending the local view of each UAV using two-hop neighbor information. They updated the Q-values by adaptively adjusting the learning rate based on the exponential normalized two-hop delay and discount factor based on the one-hop current and previous neighbor similarity set of each UAV neighbor. Through this process, QTAR produces a more stable Q-value for better exploration, considering the dynamism in the FANET topology. The reward function includes the delay in terms of the MAC and queuing delay, UAV residual energy level, and PTS for two-hop links. They adaptively adjusted the hello interval based on the minimum link duration among one-hop neighbor UAVs.
Advantages: The multi-objective reward function using two-hop neighbor information optimizes the delay and creates a proper load balance in the UAV energy consumption during multi-hop routing. The penalty mechanism in the reward function ensures avoidance of routing loops, routing holes, and local optima.
Limitations: QTAR considers velocity constraints that jointly consider distance progress and channel conditions in terms of MAC and queuing delay for two-hop neighbor UAVs to ensure data packet delivery within the deadline PTT. Proper mobility control is necessary to satisfy this PTS constraint; otherwise, the selected relay UAV may leave the transmission range of the corresponding source UAV owing to the change in relative velocity. Maintaining two-hop neighbor information produces a high overhead for each UAV.
4.8. Predictive Ad Hoc Routing Protocol Fueled by Reinforcement Learning and Trajectory Knowledge (PARRoT)
Benjamin et al. [
29] proposed predictive ad hoc routing fueled by reinforcement learning and trajectory knowledge (PARRoT) for FANETs to perform the collaborative mission of a UAV swarm. In PARRoT, each UAV exchanges hello packets with a one-hop neighbor, which includes a unique UAV address, hello packet sequence number, current position, predicted future position, reward, and cohesion value. Based on the hello packet transmission and reception in reverse order (from the destination to the source node), each node updates the link-quality status represented as a Q-value. To address the dynamic topology in FANETs, the discount factor is calculated by considering two dynamic parameters: link duration and cohesion value. The link duration is calculated using a mobility controller that utilizes the trajectory knowledge (relative velocity, relative position, and transmission range) of two neighboring UAVs. The cohesion value is calculated based on the variation in the neighbor set at two different times. The neighbor link that provides a high link duration and cohesion value receives more rewards. To make the routing decision, each source node selects a neighbor link based on the maximum Q-value.
To simulate the routing behavior, they considered both generic and realistic mobility models. For instance, they utilized the distributed dispersion detection (DDD) mobility model [
54], which is suitable for exploring plume sources in disaster scenarios. In addition, they considered the dynamic cluster hovering (DCH) method [
55], in which a UAV swarm dynamically adjusts its locations to provide network coverage of ground-based vehicles.
Advantages: PARRoT introduces relative trajectory knowledge between two neighboring UAVs to make routing decisions in FANETs. Owing to the knowledge of relative mobility information, it selects a more stable neighbor link in FANETs and provides the highest survival time of the link to complete data transmission.
Limitations: The residual energy of the neighbor node and routing loop are not considered in routing decision making. When making the routing decision, PARRoT always exploits the link with the maximum Q-value; thus, no exploration criteria are considered.
4.9. Simulated Annealing Inspired Q-Learning (SAIQL)
Sugranes et al. [
56] proposed simulated annealing-inspired Q-learning (SAIQL) for FANETs that utilizes an adaptive learning rate operated through heuristic simulated annealing optimization (SAO), where the temperature parameter (
) captures the influence of the UAV’s mobility to update the Q-value. SAIQL considers a piecewise linear mobility model, where UAVs maintain piecewise linear motion over a time slot whose duration is exponentially distributed. In each time slot, the UAVs maintain constant velocity and direction, which may vary in the next time slot. The learning rate is obtained using
of the SAO, which promptly adapts to the UAV’s average velocities during each time slot. SAIQL reduces the energy consumption of UAVs and increases the PDR of FANETs.
Advantages: SAO at high temperatures has more aggressive exploration rates, and the algorithm learns gradually toward the optimal decisions over time by cooling the temperature that minimizes the end-to-end transmission energy of UAVs. SAIQL avoids routing loops as intermediate UAVs cannot be included in the end-to-end routing path more than once, and each UAV maintains an updated Q-table with information regarding the visited UAV nodes.
Limitations: During exploration, a new action is selected randomly, which may produce unnecessary detours and delay the convergence of the algorithm. A specific guide is necessary to select a new action during exploration, such as a set of UAV nodes with sufficient residual energy, which indicates the distance progress toward the destination and satisfies the PTT to deliver the data successfully within the deadline.
5. Comparison of QL-Based Position-Aware Routing Protocols
In this section, the QL-based position-aware routing protocols discussed in
Section 4 are discussed in terms of their objectives and innovative features. Additionally, they are qualitatively compared.
The objective and innovative features of the QL-based position-aware routing protocols are summarized in
Table 6.
The mobility model, localization technique, neighbor information, MAC protocol type, exploration strategy, and simulation tool are presented in
Table 7. Most of the routing protocols consider generic mobility models such as Gaussian Markov and RWP mobility models for simulating the designed routing protocols. Only PARRoT considers realistic mobility models for UAV swarm missions by adjusting UAV locations according to the mobility of the ground vehicle to provide better network coverage. All of them utilize GPS to detect locations in the global frame. All routing protocols except QTAR utilize one-hop neighbor information to select relay nodes. By utilizing two-hop neighbor information, QTAR extends the local view of each agent and avoids link breakage and blind-path challenges in FANETs. Most routing protocols consider the IEEE 802.11g/n default MAC standard to define the physical layer standard. To achieve a balance between exploration and exploitation in the QL model, some algorithms consider the exploration strategy based on UCB, ∈-greedy strategy, one-hop PTS, and two-hop PTS and integrate the metaheuristic algorithm (SAO) with the QL model. Network Simulator 3 (NS-3), MATLAB, and WSNet are popular tools used to simulate QL-based position-aware routing protocols.
The path selection strategy, local minimum avoidance, adaptability in the hello interval, link stability, localization error consideration, and scalability features are summarized in
Table 7 (in the continued table). All routing protocols utilize a single-path strategy to discover the multihop routing path to reduce the number of broadcasts in energy- and bandwidth-constrained FANETs. They avoid the local minimum problem in the position-based forwarding technique by assigning the minimum reward to the corresponding relay nodes that have no further nodes to forward the data packets toward the destination. The SAIQL avoids the routing loop problem by saving the visited UAVs in the end-to-end path, and none of the forwarding UAVs select the relay UAV that has been selected previously in the end-to-end path. QTAR optimizes the hello interval in FANETs by adaptively selecting its value according to the minimum link duration found within a one-hop neighbor. This technique adaptively sets the hello interval and controls the control overhead. We consider the stability of the selected links to be higher in QMR, QTAR, and PARRoT. This is because both QMR and QTAR consider the PTS and residual energy levels in the reward function when selecting the relay node. PARRoT introduces a mobility prediction mechanism by calculating the link duration and cohesion metric according to the relative trajectory knowledge of neighboring UAVs. Thus, it selects a more stable path by considering high-mobility FANETs. Only QGEO, RFLQGEO, and QLCLRP consider the node localization error when selecting the relay UAV. We consider a low scalability for QLMF because it updates two different Q-values in the learning process and send them to the fuzzy logic controller for decision making. We consider high scalability for QGEO, RFLQGEO, QMR, and PARRoT because they maintain only single Q-value to update the quality of neighbor links. We consider medium scalability for QTAR because it utilizes two-hop neighbor information to make a better optimal decision; however, keeping two-hop information at each UAV produces higher overhead. Similarly, we consider medium scalability for SAIQL because it utilizes the SAO-based metaheuristic algorithm to update the Q-values for each neighbor link, which is an iterative process.
The end-to-end delay optimization, UAV energy efficiency, control overhead, PDR, and adaptive learning features are summarized in
Table 7 (in the continued table). We observed that QGEO, RFLQGEO, and QLCLRP consider only the MAC delay to select relay node links. Additionally, they consider the progress of the transmission distance toward the destination node to select the relay link. Among them, QMR, Q-FANET, and QTAR jointly considers the MAC, queuing, and transmission delays to select the relay node. QMR, QTAR, SAIQL, and QLMF consider the UAV residual energy level to select the relay node as part of their objective in the reward function. Thus, QMR, QTAR, SAIQL, and QLMF produce balance in energy consumption, which prolongs the lifetime of FANETs. QTAR provides a higher control overhead than others because it uses two-hop neighbor information. We can consider medium control overhead size for QLMF because it requires storing two different Q-values. Similarly, we consider medium control overhead for PARRoT and SAIQL because they learn the optimal policy by sharing data packets with their neighbors. QMR and QTAR give higher PDR compared to others because they choose more stable links by considering PTS and link residual energy. Similarly, PARRoT also gives higher PDR in highly dynamic FANETs because it updates the discount factor and Q-values of the neighbor link according to the relative trajectory knowledge (by calculating the predictive link duration). To adaptively train the QL model according to the mobility dynamism in FANETs, as discussed in
Section 4, several algorithms adaptively set the learning rate and discount factor. QGEO considers only two different discount factor values according to inter-UAV distances. In contrast, QMR controls both the learning rate and discount factor according to the normalized one-hop delay and changes in the neighbor sets. The QTAR algorithm adopts the same technique but considers two-hop delay to control the learning rate. As a result, it can produce a more precise Q-value and adopts the dynamical topology behavior more adaptively compared to others.







{kind=link}
{kind=link}