
Immune System Programming: A Machine Learning Approach Based on Artificial Immune Systems Enhanced by Local Search




Abstract
:1. Introduction
2. Meta-Heuristic Programming (MHP)
- TrialProgram: attempts to generate trial programs from the current program(s).
- Enhancement: enhances the search process by exploiting the best region (good regions are explored more thoroughly to find better solutions) or escaping from the local region if an improvement step is not achieved.
- UpdateProgram: selects one or more programs to use for the next generation or the next iterate.
- Diversification: directs the search to new unexplored regions in the search space or to escape from the local area.
- 1.
- Initialization: Generate an initial population (or an initial program ) and initialize the iteration counter .
- 2.
- Main Loop: Repeat the main search steps (2.1)–(2.4) for M times.
- 2.1
- Trial Solutions: Use TrialProgram Procedure in order to create trial programs from the current ones (or ).
- 2.2
- Enhancement: Apply Enhancement Procedure to improve the programs in .
- 2.3
- Solution Updating: Apply UpdateProgram Procedure to choose the next population (or next iterate program ).
- 2.4
- Update Parameter: Update the current parameters.
- 3.
- Termination: Proceed to Step 5 if the termination criteria are met.
- 4.
- Diversification: If it is necessary to diversify, apply DiverseProgram Procedure to update the population (or solution ) with new diverse solutions. Set and go to Step 2.
- 5.
- Intensification: Apply Enhancement Procedure to improve the best programs obtained so far.
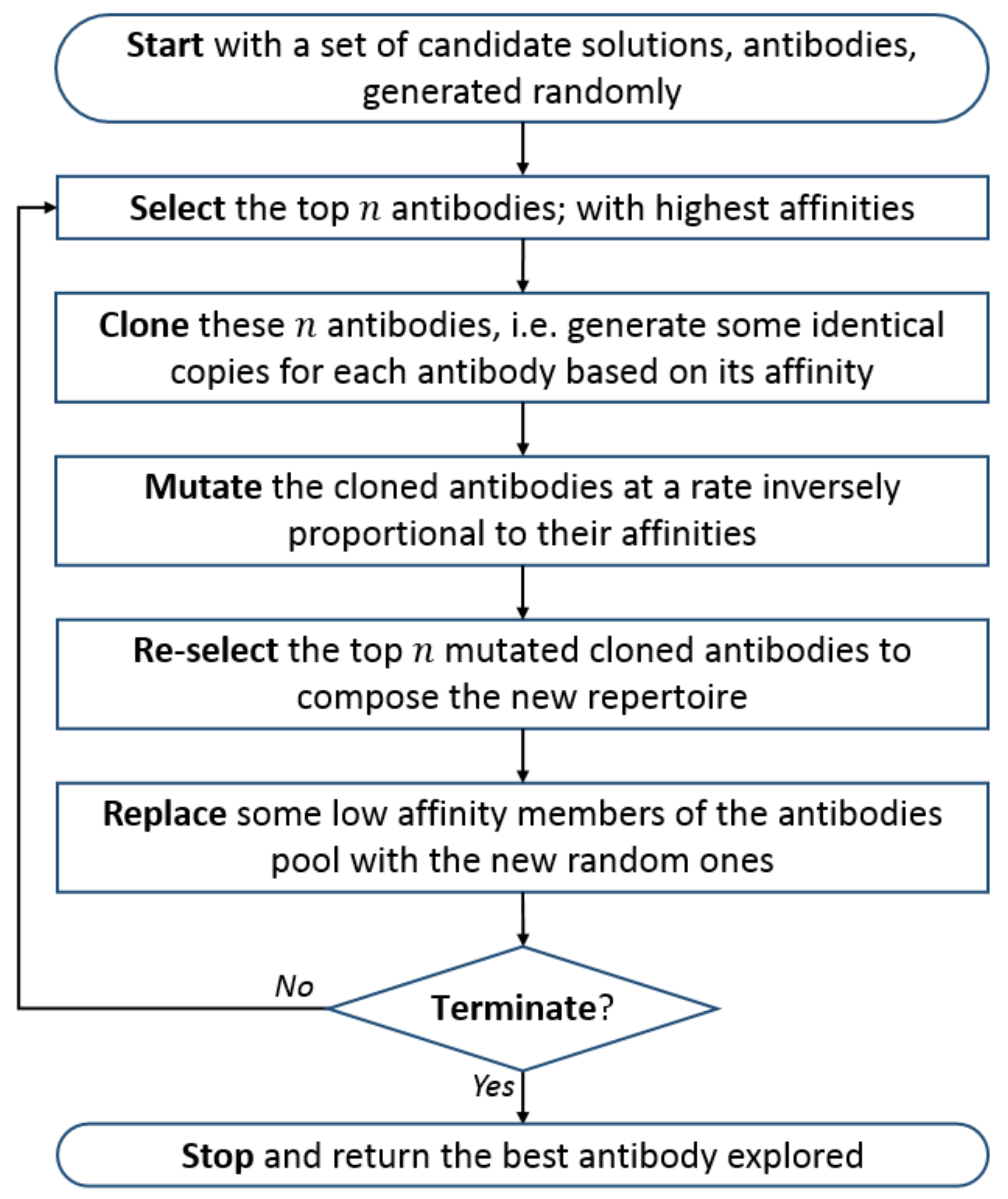
3. Artificial Immune System
| Algorithm 1 CLONALG algorithm. |
|
4. Immune System Programming with Local Search
- Initial Stage: The set of initial programs is randomly generated.
- Evaluation Stage: For each program in , evaluate its efficiency through its ability to solve the considered problem.
- Clonal Stage: Create some clones of the most promising programs in and save them as the set.
- Mutation Stage: Apply a mutation mechanism on programs in the set to create a new set of children programs called the set.
- Divers Stage: Construct a new set, named the set, that contains diverse programs to assist the search process variety.
- Replace Stage: Replace the set with selected programs from .
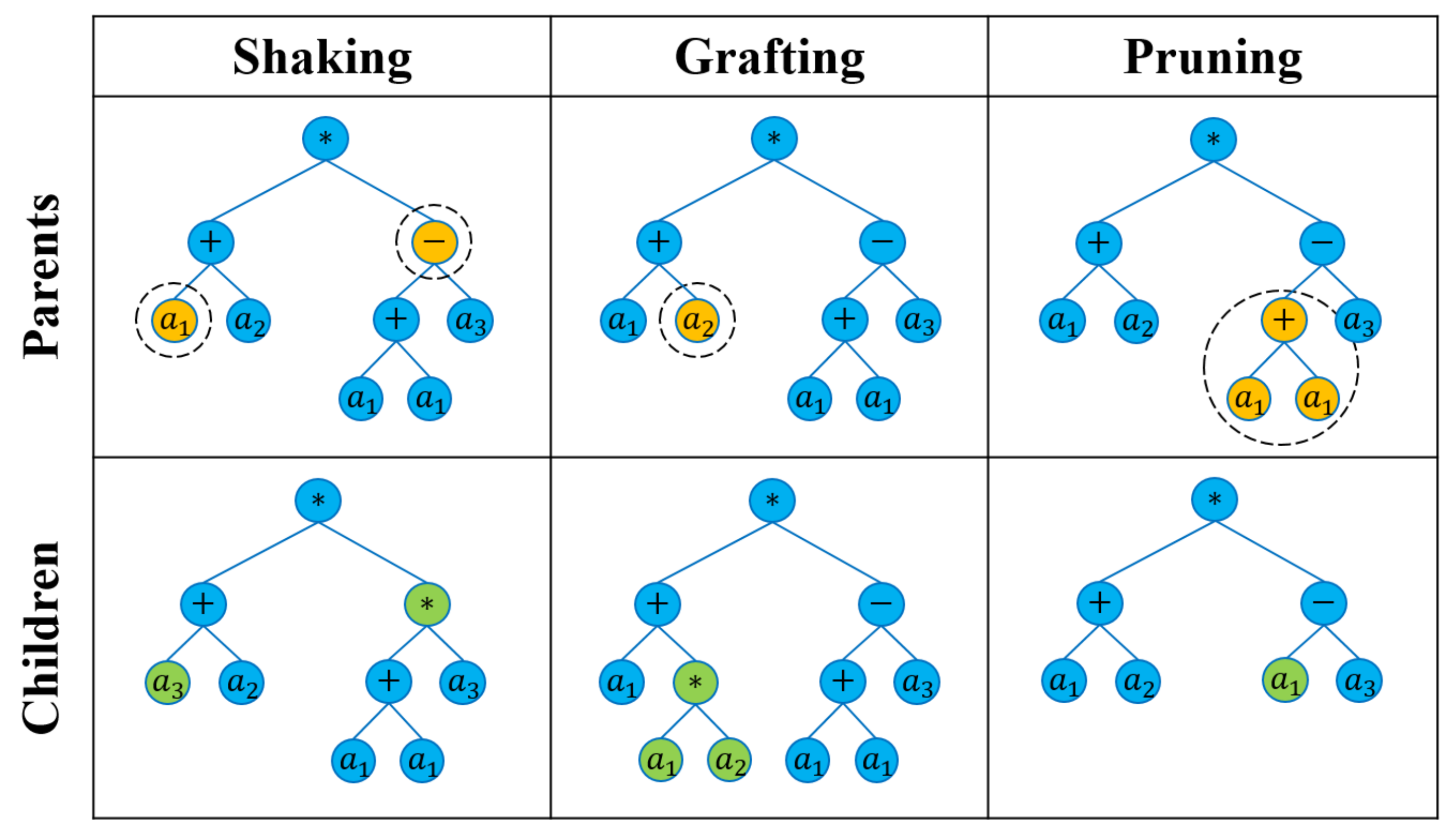
4.1. Breeding Operations
- , the program depth, is the number of links in the path from the root of the program P to its farthest terminal node.
- is the number of links in the path from node l to the root of the program that contains l.
- is the maximum depth for a program that is allowed during the search process.
- is the number of all nodes in the program P.
4.1.1. Shaking Procedure
- 1.
- Initialization: Set Γ to hold the numbers of all changeable nodes in P and set the program pool to be empty.
- 2.
- If Γ is empty, then terminate. Otherwise, let equal to .
- 3.
- Main Loop: For , do the following Steps 3.1–3.4.
- 3.1
- Set .
- 3.2
- Let v be a random permutation of numbers in Γ.
- 3.3
- For , do the following Step 3.3.1.
- 3.3.1
- If a similar alternative value from the collection of terminals or functions exists, replace with it.
- 3.4
- Add to .
- 4.
- Return with .
4.1.2. Grafting Procedure
- 1.
- Initialization: Initialize to be an empty program pool set.
- 2.
- Main Loop: For , do the following Steps 2.1–2.3.
- 2.1
- Set .
- 2.2
- For , do the following Steps 2.2.1–2.2.3.
- 2.2.1
- Set T to contain all terminal nodes in whose depth is less than or equal to .
- 2.2.2
- If T is empty, then terminate. If not, choose a terminal node at random.
- 2.2.3
- The node t is replaced with a new randomly generated subtree with depth i.
- 2.3
- Update and add it to .
- 3.
- Return with .
4.1.3. Pruning Procedure
- 1.
- Initialization: Initialize to be an empty program pool set and update N to be equal to .
- 2.
- Main Loop: For , do the following Steps 2.1–2.3.
- 2.1
- Set .
- 2.2
- For , do the following Steps 2.2.1–2.2.3.
- 2.2.1
- Set S to contain all subtrees in whose depth is equal to i.
- 2.2.2
- From S, choose a subtree θ at random.
- 2.2.3
- Replace θ with a terminal node chosen from the set of terminals at random.
- 2.3
- Update and add it to .
- 3.
- Return with .
4.2. LS Procedure
- 1.
- Initialization: Set , and .
- 2.
- Main Loop: do the following Steps 2.1–2.5 while .
- 2.1
- Apply the shaking procedure and set X = Shaking().
- 2.2
- Set be the best program in X.
- 2.3
- If is better than P, then set and go to Step 2.1. Otherwise, set .
- 2.4
- If P is better than , then set = P.
- 2.5
- If , apply only one option randomly selected from the following choices (i) or (ii).
- (i)
- Apply the grafting procedure and set Y = Grafting().
- (ii)
- Apply the pruning procedure and set Y = Pruning().
Let , where is the best program in the Y.
- 3.
- Termination: Return .
4.3. ISPLS Algorithm
| Algorithm 2 ISPLS algorithm. |
|
- Step 2.1 is , to sorting all programs in .
- Step 2.2 is , to fill .
- Step 2.4 is , to update , where .
- Step 2.5 is , to generate a set of d programs for .
- Step 2.7 is , to update .
5. Experimental Results
5.1. Test Problems
5.1.1. Symbolic Regression Problems
The Fourth Degree Polynomial
The Quintic Degree Polynomial
The Sixtic Degree Polynomial
The Multivariate Polynomial
5.1.2. 6-Bit Multiplexer Problem
5.1.3. 3-Bit Even-Parity Problem
5.2. Parameter Tuning
5.3. Comparative Results
5.3.1. ISPLS Algorithm vs. GPLab Toolbox and TP Algorithm
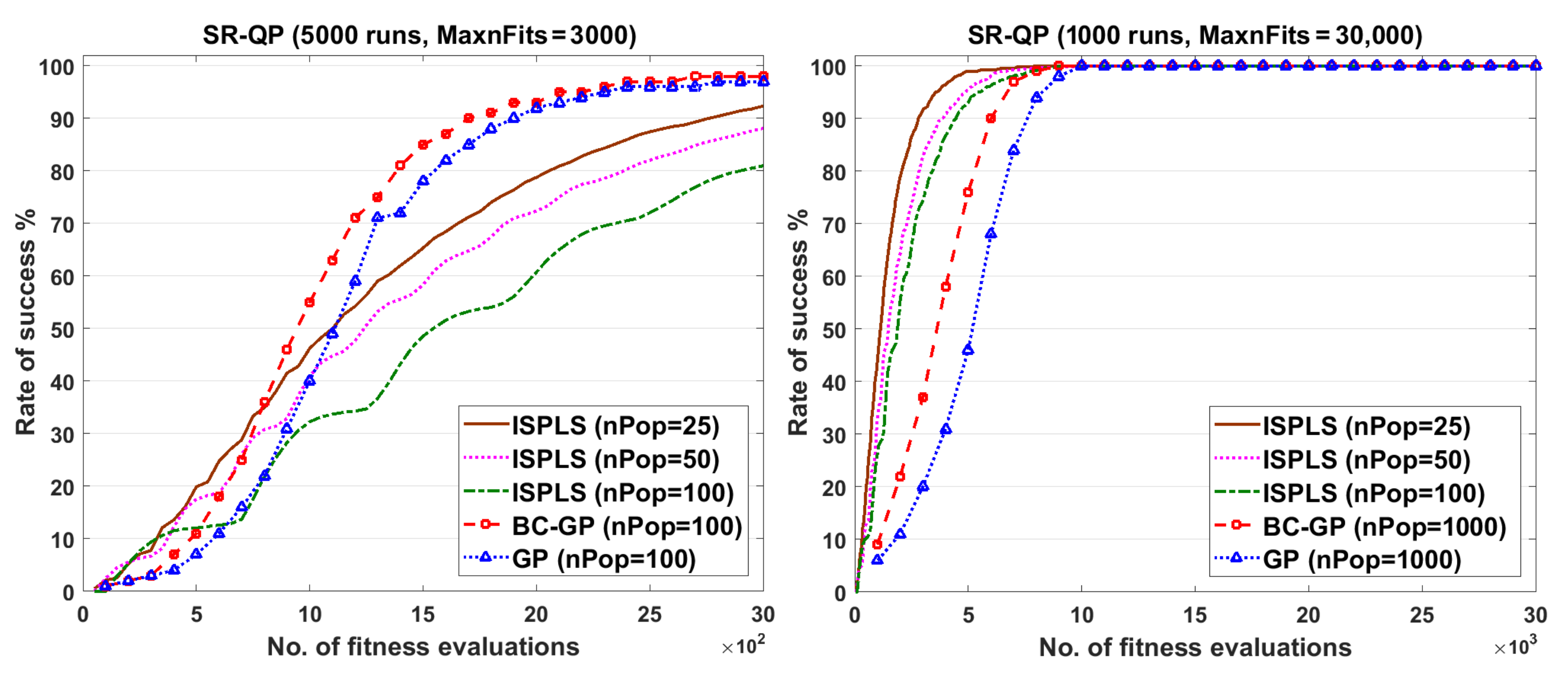
5.3.2. ISPLS Algorithm vs. GP and BC-GP Algorithms
5.3.3. ISPLS Algorithm vs. CGP, ECGP, EGGP, TAPMCGP and FMCGP Algorithms
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gendreau, M.; Potvin, J.Y. Handbook of Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2010; Volume 2. [Google Scholar]
- Koza, J.R. Genetic Programming: A Paradigm for Genetically Breeding Populations of Computer Programs to Solve Problems; Stanford University: Stanford, CA, USA, 1990. [Google Scholar]
- Koza, J.R. Genetic Programming: On the Programming of Computers by Means of Natural Selection; MIT Press: Cambridge, MA, USA, 1992; Volume 1. [Google Scholar]
- Cramer, N.L. A representation for the adaptive generation of simple sequential programs. In Proceedings of the First International Conference on Genetic Algorithms, Pittsburgh, PA, USA, 24–26 July 1985; pp. 183–187. [Google Scholar]
- Koza, J.R. Genetic programming as a means for programming computers by natural selection. Stat. Comput. 1994, 4, 87–112. [Google Scholar] [CrossRef]
- Koza, J.R. Genetic Programming III: Darwinian Invention and Problem Solving; Morgan Kaufmann: Burlington, MA, USA, 1999; Volume 3. [Google Scholar]
- Santoso, L.; Singh, B.; Rajest, S.; Regin, R.; Kadhim, K. A genetic programming approach to binary classification problem. EAI Endorsed Trans. Energy Web 2020, 8, e11. [Google Scholar] [CrossRef]
- Devarriya, D.; Gulati, C.; Mansharamani, V.; Sakalle, A.; Bhardwaj, A. Unbalanced breast cancer data classification using novel fitness functions in genetic programming. Expert Syst. Appl. 2020, 140, 112866. [Google Scholar] [CrossRef]
- Hu, N.; Zhong, J.; Zhou, J.T.; Zhou, S.; Cai, W.; Monterola, C. Guide them through: An automatic crowd control framework using multi-objective genetic programming. Appl. Soft Comput. 2018, 66, 90–103. [Google Scholar] [CrossRef] [Green Version]
- De Vega, F.F.; Olague, G.; Lanza, D.; Banzhaf, W.; Goodman, E.; Menendez-Clavijo, J.; Martinez, A. Time and individual duration in genetic programming. IEEE Access 2020, 8, 38692–38713. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Quarta, M. Hybrid multigene genetic programming-artificial neural networks approach for dynamic performance prediction of an aeroengine. Aerosp. Sci. Technol. 2020, 103, 105902. [Google Scholar] [CrossRef]
- Zhang, F.; Mei, Y.; Nguyen, S.; Zhang, M. Collaborative multifidelity-based surrogate models for genetic programming in dynamic flexible job shop scheduling. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef]
- Hodan, D.; Mrazek, V.; Vasicek, Z. Semantically-oriented mutation operator in cartesian genetic programming for evolutionary circuit design. Genet. Program. Evolvable Mach. 2021, 22, 539–572. [Google Scholar] [CrossRef]
- Dray, K.E.; Edelstein, H.I.; Dreyer, K.S.; Leonard, J.N. Control of mammalian cell-based devices with genetic programming. Curr. Opin. Syst. Biol. 2021, 28, 100372. [Google Scholar] [CrossRef]
- Alviso, D.; Artana, G.; Duriez, T. Prediction of biodiesel physico-chemical properties from its fatty acid composition using genetic programming. Fuel 2020, 264, 116844. [Google Scholar] [CrossRef]
- Huang, J.; Liew, J.; Ademiloye, A.; Liew, K.M. Artificial intelligence in materials modeling and design. Arch. Comput. Methods Eng. 2021, 28, 3399–3413. [Google Scholar] [CrossRef]
- Zhong, J.; Feng, L.; Cai, W.; Ong, Y.S. Multifactorial genetic programming for symbolic regression problems. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 4492–4505. [Google Scholar] [CrossRef]
- Chaabene, W.B.; Nehdi, M.L. Genetic programming based symbolic regression for shear capacity prediction of SFRC beams. Constr. Build. Mater. 2021, 280, 122523. [Google Scholar] [CrossRef]
- Gayanov, R.; Mironov, K.; Kurennov, D. Estimating the trajectory of a thrown object from video signal with use of genetic programming. In Proceedings of the 2017 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Bilbao, Spain, 18–20 December 2017; pp. 134–138. [Google Scholar]
- Pigozzi, F.; Medvet, E.; Nenzi, L. Mining Road Traffic Rules with Signal Temporal Logic and Grammar-Based Genetic Programming. Appl. Sci. 2021, 11, 10573. [Google Scholar] [CrossRef]
- Mabrouk, E.; Ayman, A.; Raslan, Y.; Hedar, A.R. Immune system programming for medical image segmentation. J. Comput. Sci. 2019, 31, 111–125. [Google Scholar] [CrossRef]
- Meier, A.; Gonter, M.; Kruse, R. Accelerating convergence in cartesian genetic programming by using a new genetic operator. In Proceedings of the 15th Annual Conference on Genetic and Evolutionary Computation, Amsterdam, The Netherlands, 6–10 July 2013; pp. 981–988. [Google Scholar]
- Montoya, F.G.; Navarro, R.B. Optimization Methods Applied to Power Systems: Volume 1; MDPI: Basel, Switzerland, 2019. [Google Scholar]
- Adam, S.P.; Alexandropoulos, S.A.N.; Pardalos, P.M.; Vrahatis, M.N. No free lunch theorem: A review. In Approximation and Optimization; Springer: Cham, Switzerland, 2019; pp. 57–82. [Google Scholar]
- Mabrouk, E.; Hedar, A.R.; Fukushima, M. Memetic programming with adaptive local search using tree data structures. In Proceedings of the 5th International Conference on Soft Computing as Transdisciplinary Science and Technology, Cergy-Pontoise, France, 28–31 October 2008; pp. 258–264. [Google Scholar]
- Hedar, A.R.; Mabrouk, E.; Fukushima, M. Tabu programming: A new problem solver through adaptive memory programming over tree data structures. Int. J. Inf. Technol. Decis. Mak. 2011, 10, 373–406. [Google Scholar] [CrossRef]
- Osman, M.K. Designing Machine Learning Tools Based on Meta-Heuristic Programming. Ph.D. Thesis, University of Cairo, Cairo, Egypt, 2011. [Google Scholar]
- Saleh, A.J.; Karim, A.; Shanmugam, B.; Azam, S.; Kannoorpatti, K.; Jonkman, M.; Boer, F.D. An intelligent spam detection model based on artificial immune system. Information 2019, 10, 209. [Google Scholar] [CrossRef] [Green Version]
- Park, H.; Choi, J.E.; Kim, D.; Hong, S.J. Artificial immune system for fault detection and classification of semiconductor equipment. Electronics 2021, 10, 944. [Google Scholar] [CrossRef]
- Mabrouk, E. Meta-Heuristics Programming and Its Applications. Ph.D. Thesis, University of Kyoto, Kyoto, Japan, 2011. [Google Scholar]
- Talbi, E. Metaheuristics: From Design to Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- De Castro, L.N.; Timmis, J. Artificial immune systems as a novel soft computing paradigm. Soft Comput. 2003, 7, 526–544. [Google Scholar] [CrossRef]
- Bondal, A.A. Artificial Immune Systems Applied to Job Shop Scheduling. Ph.D. Thesis, Ohio University, Athens, OH, USA, 2008. [Google Scholar]
- Gonzalez, F.; Dasgupta, D. A Study of Artificial Immune Systems Applied to Anomaly Detection. Ph.D. Thesis, University of Memphis, Memphis, TN, USA, 2003. [Google Scholar]
- Farmer, J.D.; Packard, N.H.; Perelson, A.S. The immune system, adaptation, and machine learning. Phys. D Nonlinear Phenom. 1986, 22, 187–204. [Google Scholar] [CrossRef]
- Aickelin, U.; Greensmith, J.; Twycross, J. Immune system approaches to intrusion detection—A review. In Artificial Immune Systems; Springer: Berlin/Heidelberg, Germany, 2004; pp. 316–329. [Google Scholar]
- Brownlee, J. Clonal Selection Theory & CLONALG—The Clonal Selection Classification Algorithm (CSCA); Technical Report; Swinburne University of Technology: Melbourne, VIC, Australia, 2005. [Google Scholar]
- Al-Enezi, J.; Abbod, M.; Alsharhan, S. Artificial immune systems-models, algorithms and applications. IJRRAS 2010, 3, 118–131. [Google Scholar]
- Walker, J.A.; Miller, J.F. The automatic acquisition, evolution and reuse of modules in cartesian genetic programming. Evol. Comput. IEEE Trans. 2008, 12, 397–417. [Google Scholar] [CrossRef]
- Gangopadhyay, D.; Reyhani-Masoleh, A. Multiple-bit parity-based concurrent fault detection architecture for parallel CRC computation. IEEE Trans. Comput. 2015, 65, 2143–2157. [Google Scholar] [CrossRef]
- Walker, J.A.; Miller, J.F. Evolution and acquisition of modules in cartesian genetic programming. In Genetic Programming; Springer: Berlin/Heidelberg, Germany, 2004; pp. 187–197. [Google Scholar]
- Steel, R.G.D.; Torrie, J.H.; Dicky, D.A. Principles and Procedures of Statistics: A Biometrical Approach; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Silva, S.; Almeida, J. GPLAB–A Genetic Programming Toolbox for MATLAB. 2003. Available online: http://gplab.sourceforge.net/ (accessed on 10 March 2022).
- William, E.; Northern, J., III. Genetic programming lab (GPLab) tool set version 3.0. In Proceedings of the Region 5 Conference, 2008 IEEE, Kansas City, MO, USA, 17–20 April 2008; pp. 1–6. [Google Scholar]
- Poli, R. Tournament selection, iterated coupon-collection problem, and backward-chaining evolutionary algorithms. In Foundations of Genetic Algorithms; Springer: Berlin/Heidelberg, Germany, 2005; pp. 132–155. [Google Scholar]
- Poli, R.; Langdon, W.B. Backward-chaining evolutionary algorithms. Artif. Intell. 2006, 170, 953–982. [Google Scholar] [CrossRef] [Green Version]
- Atkinson, T. Evolving Graphs by Graph Programming. Ph.D. Thesis, University of York, York, UK, 2019. [Google Scholar]
- Fang, W.; Gu, M. FMCGP: Frameshift mutation cartesian genetic programming. Complex Intell. Syst. 2021, 7, 1195–1206. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | |||||||
|---|---|---|---|---|---|---|---|
| SR-QP | 3 | 25 | 0.2 | 1 | 0.5 | 0.25 | 0.04 |
| SR-QUP | 4 | 50 | 0.2 | 1 | 0.6 | 0.25 | 0.04 |
| SR-SP | 4 | 75 | 0.2 | 1 | 0.5 | 0.25 | 0.06 |
| POLY-4 | 3 | 50 | 0.2 | 2 | 0.5 | 0.25 | 0.06 |
| 6-BM | 4 | 50 | 0.2 | 2 | 0.5 | 0.25 | 0.04 |
| 3-BEP | 5 | 50 | 0.2 | 2 | 0.5 | 0.25 | 0.04 |
| Parameter | SR-QP | SR-QUP | SR-SP | POLY-4 | 6-BM | 3-BEP | |
|---|---|---|---|---|---|---|---|
| Name | Value | Mean | Mean | Mean | Mean | Mean | Mean |
| 2 | 2252 | 46,013 | 16,699 | 4560 | 15,880 | 70,359 | |
| 3 | 1166 | 15,794 | 13,242 | 5326 | 9689 | 74,225 | |
| 4 | 1360 | 8485 | 7867 | 6855 | 9300 | 10,480 | |
| 5 | 2920 | 6334 | 7415 | 24,225 | 8928 | 3036 | |
| 6 | 9060 | 15,662 | 19,366 | - | 9404 | 2539 | |
| 25 | 1170 | 9141 | 14,731 | 4708 | 9604 | 2822 | |
| 50 | 1422 | 8927 | 10,606 | 4694 | 7679 | 3512 | |
| 75 | 1641 | 9122 | 10,177 | 5599 | 9660 | 3400 | |
| 100 | 2118 | 8652 | 11,475 | 5941 | 11,644 | 3035 | |
| 125 | 1764 | 8536 | 13,330 | 6729 | 9534 | 3254 | |
| 0.05 | 1835 | 8361 | 12,815 | 9184 | 21,363 | 3948 | |
| 0.1 | 1541 | 8839 | 10,346 | 7066 | 11,886 | 3032 | |
| 0.15 | 1099 | 7498 | 10,322 | 5796 | 10,730 | 2911 | |
| 0.2 | 1213 | 8503 | 9147 | 4956 | 10,747 | 2841 | |
| 0.25 | 1202 | 8311 | 7824 | 5276 | 8875 | 3290 | |
| Parameter | SR-QP | SR-QUP | SR-SP | POLY-4 | 6-BM | 3-BEP | |
|---|---|---|---|---|---|---|---|
| Name | Value | Mean | Mean | Mean | Mean | Mean | Mean |
| 1 | 1447 | 8431 | 8310 | 4441 | 9747 | 3459 | |
| 2 | 1362 | 8671 | 9099 | 4959 | 9298 | 2921 | |
| 3 | 1354 | 7874 | 9030 | 6042 | 8188 | 2656 | |
| 4 | 1644 | 8715 | 8032 | 6504 | 9050 | 3023 | |
| 5 | 1425 | 12,526 | 9817 | 6976 | 9770 | 2884 | |
| 0.3 | 1213 | 13,169 | 8706 | 4512 | 8370 | 2363 | |
| 0.4 | 1132 | 10,357 | 7299 | 5030 | 7977 | 2344 | |
| 0.5 | 1216 | 8688 | 9047 | 5406 | 8940 | 3022 | |
| 0.6 | 1242 | 7717 | 10,398 | 5628 | 10,673 | 3024 | |
| 0.7 | 1385 | 8422 | 9518 | 5598 | 10,905 | 2848 | |
| 0.2 | 1311 | 11,170 | 9871 | 5083 | 9464 | 2842 | |
| 0.25 | 1348 | 8097 | 9267 | 5190 | 8755 | 3285 | |
| 0.3 | 1207 | 9813 | 9936 | 4943 | 8689 | 2778 | |
| 0.35 | 1345 | 7413 | 8887 | 5287 | 9638 | 2979 | |
| 0.4 | 1343 | 8863 | 7221 | 4694 | 8426 | 2847 | |
| 0.02 | 1180 | 8105 | 10,449 | 4407 | 9984 | 3591 | |
| 0.03 | 1387 | 10,238 | 7885 | 4081 | 9668 | 3369 | |
| 0.04 | 1310 | 8879 | 7675 | 4176 | 9585 | 3220 | |
| 0.05 | 1238 | 8593 | 8596 | 5293 | 8177 | 2660 | |
| 0.06 | 1203 | 11,130 | 9115 | 4680 | 8401 | 3038 | |
| GPLab | TP | ISPLS | ||||||
|---|---|---|---|---|---|---|---|---|
| Problem | Mean | Rate | Value | Mean | Rate | Value | Mean | Rate |
| SR-QP | 1303 | 81% | 0.011 | 801 | 99% | <0.01 | 1129 | 97% |
| 6-BM | 8445 | 100% | 0.0879 | 7829 | 98% | 0.6410 | 7599 | 98% |
| 3-BEP | 11,175 | 77% | <0.01 | 5612 | 100% | <0.01 | 2363 | 100% |
| Problem | CGP | ECGP | CGP | EGGP | ISPLS | |
|---|---|---|---|---|---|---|
| [39] | [39] | [47] | [47] | |||
| ME | 32.2 | 25.9 | – | – | 3.5 | |
| SR-QUP | MAD | 31.0 | 24.4 | – | – | 6.9 |
| IQR | 525.6 | 296.8 | – | – | 5.9 | |
| ME | 12.7 | 29.7 | – | – | 4.6 | |
| SR-SP | MAD | 10.9 | 25.1 | – | – | 5.4 |
| IQR | 64.1 | 279.4 | – | – | 6.2 | |
| ME | 6.0 | 5.9 | 4.4 | 2.8 | 1.5 | |
| 3-BEP | MAD | 2.9 | 3.8 | 2.5 | 1.6 | 1.6 |
| IQR | 6.6 | 10.4 | 5.3 | 4.8 | 2.4 |
| Problem | Baseline CGP | TAPMCGP | FMCGP | ISPLS | |
|---|---|---|---|---|---|
| [48] | [48] | [48] | |||
| Mean | 28,633.66 | 7150.55 | 10,537.45 | 6333.97 | |
| SR-QUP | Std | 51,655.34 | 15,221.36 | 16,538.50 | 6276.15 |
| p value | <0.01 | 0.1962 | <0.01 | ||
| Mean | 15,843.74 | 6832.54 | 5676.55 | 7221.01 | |
| SR-SP | Std | 25,609.54 | 12,326.49 | 5865.20 | 7591.74 |
| p value | <0.01 | 0.6100 | 0.044 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mabrouk, E.; Raslan, Y.; Hedar, A.-R. Immune System Programming: A Machine Learning Approach Based on Artificial Immune Systems Enhanced by Local Search. Electronics 2022, 11, 982. https://doi.org/10.3390/electronics11070982
Mabrouk E, Raslan Y, Hedar A-R. Immune System Programming: A Machine Learning Approach Based on Artificial Immune Systems Enhanced by Local Search. Electronics. 2022; 11(7):982. https://doi.org/10.3390/electronics11070982
Chicago/Turabian StyleMabrouk, Emad, Yara Raslan, and Abdel-Rahman Hedar. 2022. "Immune System Programming: A Machine Learning Approach Based on Artificial Immune Systems Enhanced by Local Search" Electronics 11, no. 7: 982. https://doi.org/10.3390/electronics11070982
APA StyleMabrouk, E., Raslan, Y., & Hedar, A.-R. (2022). Immune System Programming: A Machine Learning Approach Based on Artificial Immune Systems Enhanced by Local Search. Electronics, 11(7), 982. https://doi.org/10.3390/electronics11070982