
A Saliency Prediction Model Based on Re-Parameterization and Channel Attention Mechanism


Abstract
:1. Introduction
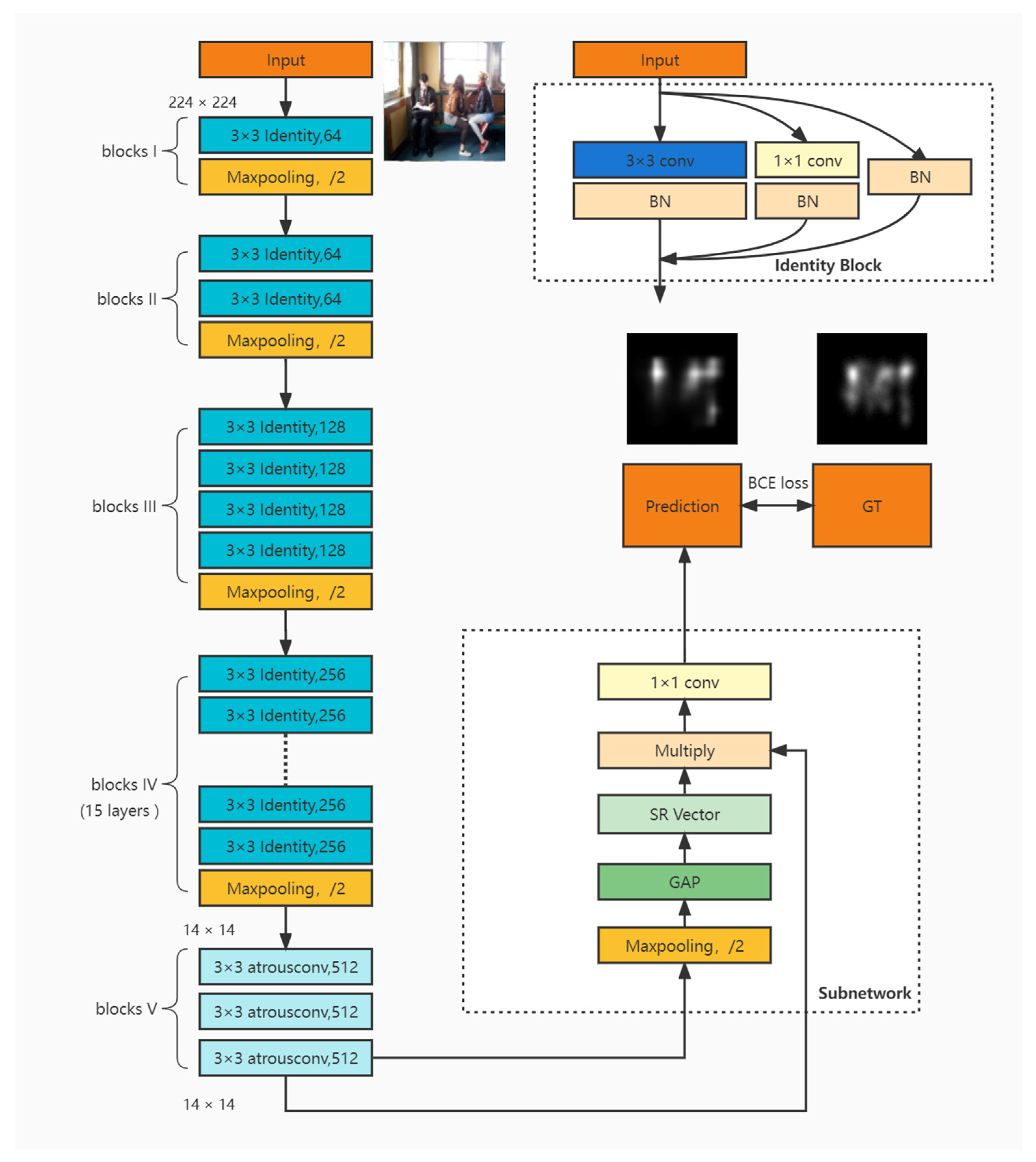
- We propose a new, multilevel, deep neural network (DNN) model that adds an identity block to the network through re-parameterization. By integrating the identity block and improving the receptive field, we obtain more robust and accurate features. Simultaneously, the proposed model effectively reduces computational cost compared with the commonly used multiscale networks.
- We design a semantic perception subnetwork by adjusting channel features and exploring the correlation between high-level semantic information. The priority and importance of high-level information in visual saliency prediction are verified by testing and comparing datasets with rich semantic targets.
2. Related Work
2.1. Visual Saliency and Attention Mechanism
2.2. Visual Saliency Models
2.3. Understanding Advanced Semantic Information
3. Proposed Approach
3.1. Multilevel Feature Re-Parameterization Network
3.2. Semantic Feature-Aware Network
4. Experiments and Analysis
4.1. Evaluation Measures
- NSS can represent consistency between mappings, taking the average value of at point of human eye attention, where n represents the total number of human eye fixation, represents the unit normalized saliency map , represents the ith pixel, and is the total number of pixels at the fixation point. NSS value is negatively correlated with model performance.
- Linear CC is a statistical metric for measuring the linear correlation between two random variables. For the prediction and evaluation of saliency, a prediction saliency map () and a ground truth density map () are regarded as two random variables. Then, the calculation formula of is:where is the covariance and is the standard deviation. can equally punish false positive and false negative, with a value range of (−1, 1). When the value is close to both ends, the model performs better.
- EMD represents the distance between the two 2D maps, G and S. It is the minimum cost of transforming the probability distribution of the estimated saliency map S into the probability distribution of the GT. Therefore, a lower EMD corresponds to a high-quality saliency map. In the field of saliency prediction, EMD represents the minimum cost of converting the probability distribution of a saliency map into one of a human eye attention map.
4.2. Experimental Results and Analysis
5. Model Visualization and Ablation Analysis
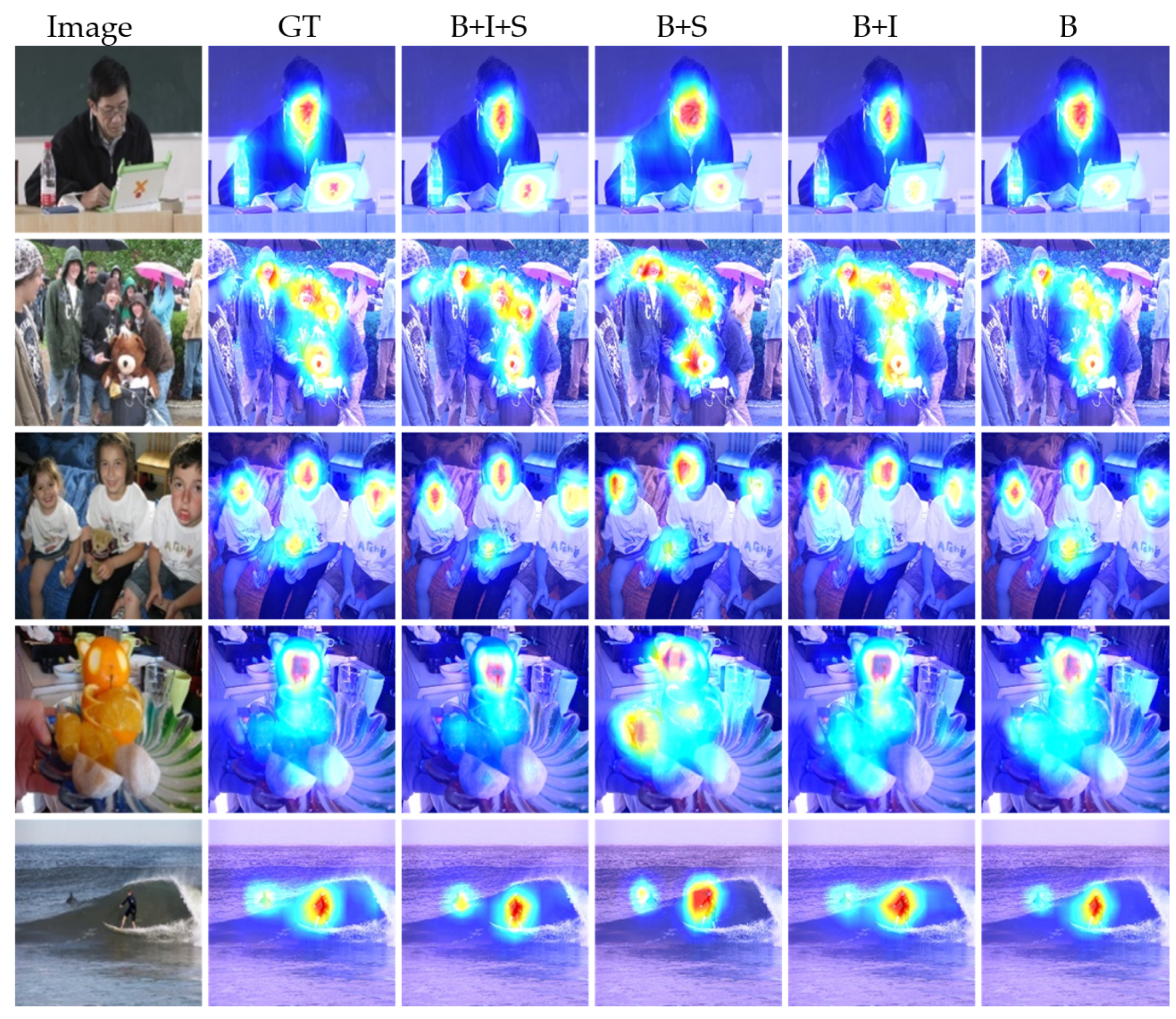
- Influence of identity block: Our backbone network uses a non-cross layer to capture spatial features that are equal to multiscale networks. Multiscale models have been widely used in recent years. Multiscale features and residual blocks are considered the key elements of the saliency prediction task that can further improve the performance of a saliency model. To verify the similar effect of the backbone network in our model, we compared the whole network (B + I + S) with the basic network (B) and basic network with subnetwork (B + S). For each image, we calculated the score of the metrics. As shown in Table 3, the non-cross layer can significantly improve the performance of the model. Also, it can greatly reduce the over-fitting phenomenon that may occur, and the network is too sensitive to detect error saliency areas (e.g., fourth line). Our model also exhibits some advantages in parameters and reasoning time because we used the re-parameterization network instead of directly using the multiscale network. Compared with other models (EML-Net: 23.5 M and SAM-ResNet50: 70.1 M), the parameters of our model (14.8 M) decreased significantly.
- Influence of subnetwork: Similar architectures that use emotion or semantic features can act well on emotion or semantic priority and predict the relative importance of an image area by enhancing the ability of channel weighted subnetworks. To illustrate this phenomenon, we calculated the same difference score between our model (B + I + S) and the basic network without subnetwork (B + I) predictions. By correlating the difference of each model with the authenticity of background in the image, the degree of relative saliency of the human-related object predicted by the model was evaluated (e.g., the computer in the first line). As indicated in Table 3, a large correlation shows that the model performed better in predicting relative saliency. The best scores are marked in bold.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sziklai, G.C. Some studies in the speed of visual perception. Inf. Theory IRE Trans. 1956, 76, 125–128. [Google Scholar] [CrossRef]
- Koch, K.; Mclean, J.; Segev, R.; Freed, M.A.; Michael, I.I.; Balasubramanian, V.; Sterling, P. How Much the Eye Tells the Brain. Curr. Biol. 2006, 16, 1428–1434. [Google Scholar] [CrossRef] [Green Version]
- Yan, F.; Chen, C.; Xiao, P.; Qi, S.; Wang, Z.; Xiao, R. Review of Visual Saliency Prediction: Development Process from Neurobiological Basis to Deep Models. Appl. Sci. 2021, 12, 309. [Google Scholar] [CrossRef]
- Wang, W.; Shen, J.; Cheng, M.M.; Shao, L. An Iterative and Cooperative Top-Down and Bottom-Up Inference Network for Salient Object Detection. In Proceedings of the CVPR19, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wang, W.; Lai, Q.; Fu, H.; Shen, J.; Yang, R. Salient Object Detection in the Deep Learning Era: An In-depth Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1448–1457. [Google Scholar] [CrossRef]
- Zhang, P.; Liu, W.; Zeng, Y.; Lei, Y.; Lu, H. Looking for the Detail and Context Devils: High-Resolution Salient Object Detection. IEEE Trans. Image Processing 2021, 30, 3204–3216. [Google Scholar] [CrossRef]
- Fan, L.; Wang, W.; Huang, S.; Tang, X.; Zhu, S.C. Understanding Human Gaze Communication by Spatio-Temporal Graph Reasoning. arXiv 2019, arXiv:1909.02144. [Google Scholar]
- Aksoy, E.; Yazc, A.; Kasap, M. See, Attend and Brake: An Attention-based Saliency Map Prediction Model for End-to-End Driving. arXiv 2020, arXiv:2002.11020. [Google Scholar]
- Chen, C.; Zhou, K.; Zha, M.; Qu, X.; Guo, X.; Chen, H.; Wang, Z.; Xiao, R. An effective deep neural network for lung lesions segmentation from COVID-19 CT images. IEEE Trans. Ind. Inform. 2021, 17, 6528–6538. [Google Scholar] [CrossRef]
- Chen, C.; Xiao, R.; Zhang, T.; Lu, Y.; Guo, X.; Wang, J.; Chen, H.; Wang, Z. Pathological lung segmentation in chest CT images based on improved random walker. Comput. Methods Programs Biomed. 2021, 200, 105864. [Google Scholar] [CrossRef]
- Jia, Z.; Lin, Y.; Wang, J.; Wang, X.; Xie, P.; Zhang, Y. SalientSleepNet: Multimodal Salient Wave Detection Network for Sleep Staging. arXiv 2021, arXiv:2105.13864. [Google Scholar]
- O’Shea, A.; Lightbody, G.; Boylan, G.; Temko, A. Neonatal seizure detection from raw multi-channel EEG using a fully convolutional architecture. arXiv 2021, arXiv:2105.13854. [Google Scholar] [CrossRef]
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Koch, C.; Ullman, S. Shifts in Selective Visual Attention: Towards the Underlying Neural Circuitry. Hum Neurobiol. 1987, 4, 219–227. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.-F.; Zhang, H.-J. Contrast-based image attention analysis by using fuzzy growing. In Proceedings of the Eleventh ACM International Conference on Multimedia, Berkeley, CA, USA, 2–8 November 2003; pp. 374–381. [Google Scholar]
- Feng, J.; Wei, Y.; Tao, L.; Zhang, C.; Sun, J. Salient object detection by composition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1028–1035. [Google Scholar]
- Liu, T.; Yuan, Z.; Sun, J.; Wang, J.; Zheng, N.; Tang, X.; Shum, H.-Y. Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 353–367. [Google Scholar]
- Borji, A.; Itti, L. Exploiting local and global patch rarities for saliency detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 July 2012; pp. 478–485. [Google Scholar]
- Zhi, L.; Zhang, X.; Luo, S.; Meur, O.L. Superpixel-Based Spatiotemporal Saliency Detection. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1522–1540. [Google Scholar]
- Huang, G.; Pun, C.M.; Lin, C. Unsupervised video co-segmentation based on superpixel co-saliency and region merging. Multimed. Tools Appl. 2016, 76, 12941–12964. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A.; Castelhano, M.S.; Henderson, J.M. Top-down control of visual attention in object detection. In Proceedings of the International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; pp. I-253–I-256. [Google Scholar]
- Xie, Y.; Lu, H.; Yang, M.H. Bayesian Saliency via Low and Mid Level Cues. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2013, 22, 1689–1698. [Google Scholar]
- Gao, D.; Vasconcelos, N. Discriminant saliency for visual recognition from cluttered scenes. Adv. Neural Inf. Process. Syst. 2004, 17, 481–488. [Google Scholar]
- Gao, D.; Han, S.; Vasconcelos, N. Discriminant Saliency, the Detection of Suspicious Coincidences, and Applications to Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 989–1005. [Google Scholar]
- Vig, E.; Dorr, M.; Cox, D. Large-scale optimization of hierarchical features for saliency prediction in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2798–2805. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Kümmerer, M.; Theis, L.; Bethge, M. Deep gaze i: Boosting saliency prediction with feature maps trained on imagenet. arXiv 2014, arXiv:1411.1045. [Google Scholar]
- Kruthiventi, S.; Ayush, K.; Babu, R.V. DeepFix: A Fully Convolutional Neural Network for Predicting Human Eye Fixations. IEEE Trans. Image Process. 2017, 26, 4446–4456. [Google Scholar] [CrossRef] [Green Version]
- Kümmerer, M.; Wallis, T.S.; Bethge, M. DeepGaze II: Reading fixations from deep features trained on object recognition. arXiv 2016, arXiv:1610.01563. [Google Scholar]
- Jiang, M.; Huang, S.; Duan, J.; Zhao, Q. Salicon: Saliency in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1072–1080. [Google Scholar]
- Pan, J.; Sayrol, E.; Giro-i-Nieto, X.; McGuinness, K.; O’Connor, N.E. Shallow and deep convolutional networks for saliency prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 598–606. [Google Scholar]
- Jetley, S.; Murray, N.; Vig, E. End-to-end saliency mapping via probability distribution prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5753–5761. [Google Scholar]
- Liu, N.; Han, J. A deep spatial contextual long-term recurrent convolutional network for saliency detection. IEEE Trans. Image Process. 2018, 27, 3264–3274. [Google Scholar] [CrossRef] [Green Version]
- Cornia, M.; Baraldi, L.; Serra, G.; Cucchiara, R. A deep multi-level network for saliency prediction. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3488–3493. [Google Scholar]
- Marcella, C.; Lorenzo, B.; Giuseppe, S.; Rita, C. Predicting Human Eye Fixations via an LSTM-based Saliency Attentive Model. IEEE Trans. Image Process. 2016, 27, 5142–5154. [Google Scholar]
- Pan, J.; Ferrer, C.C.; McGuinness, K.; O’Connor, N.E.; Torres, J.; Sayrol, E.; Giro-i-Nieto, X. Salgan: Visual saliency prediction with generative adversarial networks. arXiv 2017, arXiv:1701.01081. [Google Scholar]
- Jia, S.; Bruce, N.D. Eml-net: An expandable multi-layer network for saliency prediction. Image Vis. Comput. 2020, 95, 103887. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Shen, J. Deep visual attention prediction. IEEE Trans. Image Process. 2017, 27, 2368–2378. [Google Scholar] [CrossRef] [Green Version]
- Gorji, S.; Clark, J.J. Attentional push: A deep convolutional network for augmenting image salience with shared attention modeling in social scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 2510–2519. [Google Scholar]
- Wang, W.; Shen, J.; Xie, J.; Cheng, M.-M.; Ling, H.; Borji, A. Revisiting Video Saliency Prediction in the Deep Learning Era. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 220–237. [Google Scholar] [CrossRef] [Green Version]
- Lai, Q.; Wang, W.; Sun, H.; Shen, J. Video Saliency Prediction using Spatiotemporal Residual Attentive Networks. IEEE Trans. Image Process. 2019, 29, 1113–1126. [Google Scholar] [CrossRef]
- Xu, M.; Yang, L.; Tao, X.; Duan, Y.; Wang, Z. Saliency Prediction on Omnidirectional Image With Generative Adversarial Imitation Learning. IEEE Trans. Image Process. 2021, 30, 2087–2102. [Google Scholar] [CrossRef]
- Pang, L.; Zhu, S.; Ngo, C.-W. Deep multimodal learning for affective analysis and retrieval. IEEE Trans. Multimed. 2015, 17, 2008–2020. [Google Scholar] [CrossRef]
- Yang, J.; She, D.; Sun, M. Joint Image Emotion Classification and Distribution Learning via Deep Convolutional Neural Network. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 3266–3272. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Cordel, M.O.; Fan, S.; Shen, Z.; Kankanhalli, M.S. Emotion-aware human attention prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4026–4035. [Google Scholar]
- Fan, S.; Shen, Z.; Jiang, M.; Koenig, B.L.; Xu, J.; Kankanhalli, M.S.; Zhao, Q. Emotional attention: A study of image sentiment and visual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7521–7531. [Google Scholar]
- Borji, A.; Itti, L. Cat2000: A large scale fixation dataset for boosting saliency research. arXiv 2015, arXiv:1505.03581. [Google Scholar]
- Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–9 December 2006; Volume 19. [Google Scholar]
- Zhang, J.; Sclaroff, S. Exploiting surroundedness for saliency detection: A boolean map approach. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 889–902. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | AUC-Judd | NSS | CC | EMD |
|---|---|---|---|---|
| SALICON | 0.86 | 2.18 | 0.79 | 1.13 |
| SAM-ResNet | 0.88 | 2.38 | 0.89 | 1.04 |
| EML-Net | 0.87 | 2.38 | 0.88 | 1.05 |
| IttiKoch2 | 0.77 | 1.06 | 0.42 | 3.44 |
| GBVS | 0.80 | 1.23 | 0.50 | 2.99 |
| BMS | 0.78 | 1.16 | 0.39 | 1.95 |
| Our Model | 0.88 | 2.39 | 0.89 | 1.05 |
| Metric | AUC-Judd | NSS | CC | EMD |
|---|---|---|---|---|
| SALICON | 0.87 | 1.59 | 0.84 | 1.32 |
| SAM-ResNet | 0.87 | 1.74 | 0.86 | 1.14 |
| EML-Net | 0.87 | 1.75 | 0.86 | 1.13 |
| IttiKoch2 | 0.73 | 0.98 | 0.39 | 3.2 |
| GBVS | 0.79 | 1.18 | 0.47 | 2.92 |
| BMS | 0.77 | 1.12 | 0.49 | 2.06 |
| Our Model | 0.87 | 1.76 | 0.88 | 1.12 |
| Metric | AUC-Judd | NSS | CC | EMD |
|---|---|---|---|---|
| B + I + S | 0.88 | 2.39 | 0.89 | 1.05 |
| B + S | 0.80 | 2.11 | 0.81 | 1.33 |
| B + I | 0.79 | 2.03 | 0.85 | 1.43 |
| B | 0.75 | 1.85 | 0.71 | 2.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, F.; Wang, Z.; Qi, S.; Xiao, R. A Saliency Prediction Model Based on Re-Parameterization and Channel Attention Mechanism. Electronics 2022, 11, 1180. https://doi.org/10.3390/electronics11081180
Yan F, Wang Z, Qi S, Xiao R. A Saliency Prediction Model Based on Re-Parameterization and Channel Attention Mechanism. Electronics. 2022; 11(8):1180. https://doi.org/10.3390/electronics11081180
Chicago/Turabian StyleYan, Fei, Zhiliang Wang, Siyu Qi, and Ruoxiu Xiao. 2022. "A Saliency Prediction Model Based on Re-Parameterization and Channel Attention Mechanism" Electronics 11, no. 8: 1180. https://doi.org/10.3390/electronics11081180
APA StyleYan, F., Wang, Z., Qi, S., & Xiao, R. (2022). A Saliency Prediction Model Based on Re-Parameterization and Channel Attention Mechanism. Electronics, 11(8), 1180. https://doi.org/10.3390/electronics11081180