Abstract
Graph neural networks (GNNs) build on the success of deep learning models by extending them for use in graph spaces. Transfer learning has proven extremely successful for traditional deep learning problems, resulting in faster training and improved performance. Despite the increasing interest in GNNs and their use cases, there is little research on their transferability. This research demonstrates that transfer learning is effective with GNNs, and describes how source tasks and the choice of GNN impact the ability to learn generalisable knowledge. We perform experiments using real-world and synthetic data within the contexts of node classification and graph classification. To this end, we also provide a general methodology for transfer learning experimentation and present a novel algorithm for generating synthetic graph classification tasks. We compare the performance of GCN, GraphSAGE and GIN across both synthetic and real-world datasets. Our results demonstrate empirically that GNNs with inductive operations yield statistically significantly improved transfer. Further, we show that similarity in community structure between source and target tasks support statistically significant improvements in transfer over and above the use of only the node attributes.
1. Introduction and Related Work
Deep learning has achieved success in a wide variety of problems, ranging from time-series data to images and video [1]. Data from these tasks are referred to as Euclidean [2] and specialised models such as recurrent and convolutional neural networks [3,4,5] have been designed to leverage the properties of such data.
Despite these successes, not all problems are Euclidean. One particular class of such problems involve graphs, which naturally model complex real-world settings involving objects and their relationships. Recently, deep learning approaches have been extended to graph-based domains using graph neural networks (GNNs) [6], which leverage certain topological structures and properties specific to graphs [2]. Since graphs comprise entities and the relationships between them, GNNs are said to learn relational information and may have the capacity for relational reasoning [7].
One reason for the success of deep learning models is their ability to transfer previous learning to new tasks. In image classification, this transfer leads to more robust models and faster training [8,9,10,11,12,13]. Despite the importance of transfer in deep learning, there has been little insight into the nature of transferring relational knowledge—that is, the representations learnt by graph neural networks. There is also no comparison of the generalisability of different GNNs when evaluated on downstream task performance. This lack of insight is in part due to the lack of a model-agnostic and task-agnostic framework and standard benchmark datasets and tasks for carrying out transfer learning experiments with GNNs.
Despite transfer learning being useful in traditional deep learning, there has been little insight gained into the nature of transferring relational knowledge, i.e., the representations learnt by graph neural networks. There is also no comparison of the generalisability of different GNNs when evaluated on downstream task performance. This lack is partly due to the lack of a model-agnostic and task-agnostic framework for carrying out transfer learning experiments with GNNs; and partly due to a lack of standard benchmark datasets and tasks.
We conduct an empirical study within the contexts of node classification and graph classification to determine whether transfer in GNNs occur and, if so, what factors influence success. In particular, we make the following contributions: First, we provide a methodology and additional metrics for evaluating GNN transfer learning empirically. Second, we provide a novel method for creating synthetic graph classification tasks with community structure. Finally, we evaluate the transferability of several popular GNNs on both real and synthetic datasets. Our results demonstrate that we can achieve positive transfer using graph neural networks; and that certain models exploit strong community structure properties present in the source task to yield effective transfer.
1.1. Background
In this work, we consider problems for which the data can be modelled as a graph. A graph consists of a set of N vertices, V, and a set of edges E. Let denote a vertex, and denote a directed edge from to . The adjacency matrix, , has where , and 0 otherwise. A graph may have node attributes of length C, where is the node feature matrix, and is the attribute vector for node . Similarly, a graph may have an edge attribute matrix [6]. An important measure of a node’s connectivity is its degree, which is the number of edges the node is connected to [14]. We denote the degree of the ith node as . The degree matrix is the diagonal matrix containing the degrees of all vertices.
1.1.1. Graph Neural Networks
The success of CNNs for computer vision problems motivate the need to formulate a counterpart to the convolution operator for graphs [2]. Similarly to that of Euclidean signals, the problem of convolution for graphs can be tackled from either the spatial domain or spectral domain. One popular model is Graph Convolution Networks (GCNs) [15], which make use of a spectral graph convolution operation stacked layer-wise. We also consider two other models, GraphSAGE [16] and Graph Isomorphism Networks (GINs) [17], which utilise spatial graph convolutions to aggregate information from a node’s neighbourhood. GINs have previously outperformed both GCN and GraphSAGE in experimental performance on social media and biological datasets [17].
These three considered GNNs fall under the category of message-passing neural networks (MPNNs) [18]. To provide comparison of the three GNNs’ operations, we rewrite them as MPNN updates:
where and are the GNN embeddings for node v and the weight matrix at the layer k respectively, is a nonlinear activation function, is the neighbourhood of node v, and are the renormalised degree and in-degree of node v (see Kipf and Welling [15]), and is GIN’s central node weighting parameter.
| Model | Update Rule |
| GCN | |
| GraphSAGE | |
| GIN |
1.1.2. Transfer Learning
Deep neural network and machine learning models are usually trained for a specific task from a random initialisation of their parameters. If the task or nature of the input data changes, the network must be retrained from scratch. This retraining differs from humans, who reuse past knowledge and apply it to new contexts and tasks. The ability to reuse knowledge beyond the context in which it was learnt is known as transfer learning [19]. Transfer with neural networks can be achieved by simply reusing a previously-trained network’s weights. The transferred weights can either be used as a starting point for training a network (fine-tuned transfer), or used as fixed features on the target task (frozen-weight transfer). To formalise transfer learning, Pan and Yang [20] define the notion of domains and tasks as used in this paper.
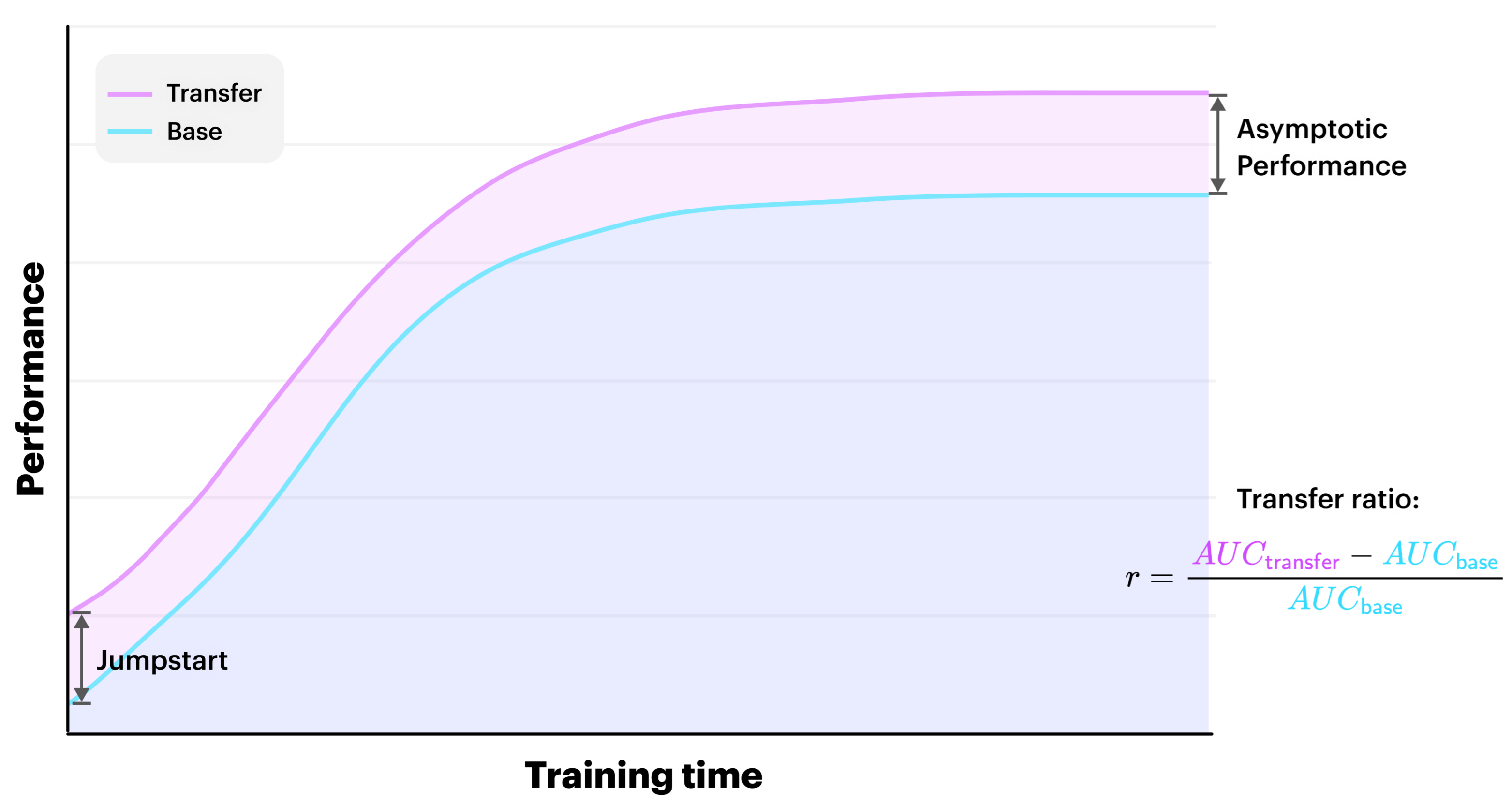
Taylor and Stone [19] present various metrics for the evaluation of transfer learning, including Transfer Ratio, Jumpstart and Asymptotic Performance. The Transfer Ratio is the ratio of the total cumulative performance of the transfer learner to the base learner, while Jumpstart is the initial performance improvement by the transfer over the base learner. Asymptotic Performance refers to the improvement made in the final learnt performance in the target task. Figure 1 below describes these metrics.
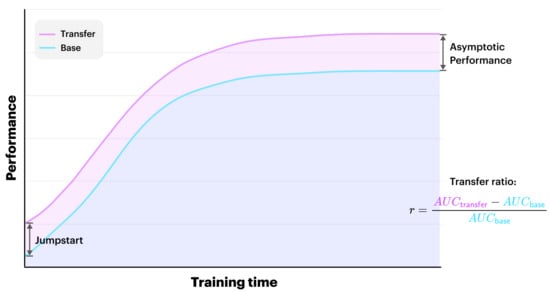
Figure 1.
An illustration of the jumpstart, asymptotic performance and transfer ratio metrics. The transfer ratio is computed using the area under the curve (AUC).
1.1.3. Related Work
Bengio [21] notes that deep learning algorithms seem well suited to transfer learning through learning ‘abstract’ representations. Knowledge is represented at multiple levels, with higher level representations learnt as compositions of lower level features [22]. Kornblith et al. [23] and Huh et al. [24] investigate transfer learning with CNNs pretrained on ImageNet [25] and find that networks train faster, and achieve improved accuracy as a result.
Partly due to recency, and partly due to the multitude of approaches, not much research exists which investigates transfer learning for GNNs. Hamilton [26] notes that little success has been achieved by pretraining GNNs. This may be due to the fact that randomly initialised GNNs extract features that are just as useful as a trained network’s [27].
However, Lee et al. [28] do propose a framework to transfer spectral information between source and target tasks for node classification. Experiments on real-world datasets show transfer is most effective when the source and target graphs are similar. Hu et al. [29] develop a framework to effectively pretrain GNNs for downstream tasks by pretraining a GNN at the level of individual nodes and the entire graphs. Thus, they describe two techniques to exploit node-level knowledge: context prediction and attribute masking, as well as two approaches for graph-level pretraining. More recently, Dai et al. [30] present AdaGCN: a framework for transfer learning based on adversarial domain adaption with GCNs.
2. Materials and Methods
Errica et al. [31] notes that the experimental settings from GNN research papers are often ambiguous, and the results are not reproducible. Reproducibility is, therefore, a core objective, and as such, we provide the code for our experiments. We utilise the PyTorch-Geometric [32] library for efficient GPU-optimised implementations of the three selected GNNs [33]. We track our experiments using Comet.ml, and make them publicly available for transparency.
Our experiments pretrain GNNs on various source tasks and fine-tune them on a target task. All experiments are conducted in a fully supervised setting. The experiments track the performance of pretrained models as well as the randomly initialised models across training. This methodology allows us to compare transferability in terms of the transfer learning metrics described earlier. We make use of synthetic and real-world data in our experiments. To avoid the problems of a lack of meaningful data-splits [31] and the instability of training on small graph datasets [34], we make use of the Open Graph Benchmark [35] datasets for our real-world datasets. To ascertain the statistical significance of our results, we employ a pairwise two-sided t-test for identical means of independent sample statistics with the alternative hypothesis ‘greater than’ throughout.
2.1. Node Classification Experimental Design
Node classification involves assigning a class label to an unlabelled node in a graph. Solving this problem considers structural properties of graphs (e.g., node degree), the node’s attributes, or some relationship between them. Practical applications include real-world contexts, such as social networks [36] or knowledge graphs [37]. Below we describe the datasets and experimental methodology used.
2.1.1. Synthetic Data
For meaningful classifications, instances within a single class should be similar. A graph where nodes in the same class are densely connected is said to contain strong community structure.
The Modularity, defined as
is one measure of a graph’s community structure with respect to the structure of the network [38], where if and belong to the same class, and 0 otherwise.
The Within Inertia ratio is another measure of the community structure that takes into account node attribute values [39]. Given a partition of the graph’s vertices , the Within Inertia is given by:
where is the Euclidean distance between node attribute vectors, is the centre of gravity of the vertices in C, and g the global centre of gravity of all vertices.
To generate synthetic datasets, we make use of DANCer: a generator for dynamic attributed networks with community structure [39]. The generator produces graphs with communities using micro-operations (local operations such as removing a node) and macro-operations (community-level operations such as splitting a community). The generator is designed with both structural and attribute homophily [40] in mind. It also models phenomena such as preferential attachment, where nodes are more likely to connect with nearby or highly connected nodes [41]. These properties make DANCer an ideal generator for our purposes.
We provide four benchmark configurations: one for each combination of strong and weak structural and attribute community structure. We fix a single target task with these datasets (Configuration 4), and pretrain on the other three configurations as described in Table 1. The parentheses indicate the strength of Modularity and Within Inertia respectively—e.g., MI indicates strong Modularity and weak Within Inertia.

Table 1.
The four configurations of the synthetic node classification datasets. The average modularity and Within Inertia ratios are computed on the generated datasets.
2.1.2. Real-World Data
A common node classification domain is citation networks, where each node in the graph represents a publication, and edges indicates citations. We perform several transfer learning experiments using Open Graph Benchmark real-world citation networks, and complement the experiments with synthetic data. In particular, we select Arxiv and MAG—both are directed citation networks, where each node has an attribute vector containing a 128-dimensional word embedding of the paper. In addition, a paper’s year of publication is also associated with its node in the network.
Arxiv contains 169,343 Computer Science papers, and the task is to predict which of the 40 subject areas a paper belongs to. MAG is taken from a subset of the Microsoft-Academic-Graph [42], and contains four types of node entities: papers, authors, institution and field of study. For consistency we will only make use of the papers, which consist of 736,389 nodes, making it a much larger and more complex network than Arxiv. The task here is to predict which of 349 venues (conferences or journals) each paper belongs to. Open Graph Benchmark also provides model evaluators, which use the standard accuracy score.
To evaluate how MAG transfers to itself, we split it into a source and a target graph. Papers from 2010–2014 are placed in the source split, and those from 2015–2019 belong to the target split. Any edges between nodes in separate splits are removed. Table 2 lists the statistics of the above datasets.
Table 2.
Statistics of real-world node classification datasets used in our experiments.
2.1.3. Experimental Methodology
Table 3 presents the source and target tasks for our experiments using both real-world and synthetic datasets. We evaluated transfer from both Arxiv and the MAG source split to the target MAG split. Lastly, to investigate how important attributes are for our node classification tasks, we damaged the node attributes for both Arxiv and the MAG source graph. To damage the attributes, we replaced the attributes with Gaussian distributed random noise with a mean of 0 and a standard deviation of 1.
Table 3.
Experiments conducted for node classification using both real-world and synthetic datasets.
We performed 10 runs of each of the six sets of experiments for each of the three GNNs. We used the same network architecture used by Open Graph Benchmark [35] for their experiments on Arxiv and MAG, which allows us to compare the performance for the base models as a sanity check. The network comprises three GNN layers: with an input dimensionality of 128, an output dimensionality of 349 (for MAG), and a hidden dimensionality of 256. We trained the networks on the target task for 2000 epochs using the Adam optimiser [43]. The best performing learning rate for each GNN was selected and fixed across our 6 experiment sets. GCN, GraphSAGE and GIN were all trained with a learning rate of in this case.
For synthetic data experiments, we generated 10 unique graphs each for Configurations 1, 2, and 3. Throughout, we used a single instance of Configuration 4 so that the target task was fixed. The task was 5-class node classification, and we trained the models for 2000 epochs using the Adam optimiser with a learning rate of for GCN and GraphSAGE, and for GIN.
2.2. Graph Classification Experimental Design
Graph classification is the problem of categorising whole graphs. To investigate GNN transfer for graph classification, we conducted experiments involving both real-world and synthetic problems. We followed the same experimental procedure as for node classification. We wanted to evaluate whether a dataset contains graphs with community structure at a graph-level. To this aim, we present an extension of the concept of community structure from node to graph level for both structural and attribute properties. The Within Inertia is a general measure of community structure since it does not depend on graph-theoretic properties, but only on the Euclidean distance between data points. Given a dataset D, and a partition of classes , a general form of the Within Inertia can be written as:
where is a graph property we are interested in measuring for graph i in class C, is the centre of gravity of the graphs in C and g is the global center of gravity of all the graphs. The Euclidean distance may be replaced by other distance metrics if the generation process is unknown [44,45].
We replace in Equation (1) with any property we want to measure community structure for. For the attribute community structure we substitute the mean of each graph’s attribute matrix, , for :
There is no consensus on how to approach structural community structure. There are numerous ways of measuring graph similarity [46], the most common being graph-edit distance [47]. Another approach is to compare graph spectra. However, these methods are slow to compute and are thus not useful for measuring entire datasets with multiple graphs.
Modularity takes node degrees as a valuable property for determining community structure for nodes. Since we wanted to measure community structure at the graph level, we used the average node degree for a graph. We substituted the average node degree, , for in Equation (1). This serves as the structural community structure measure for our datasets:
2.2.1. Synthetic Data
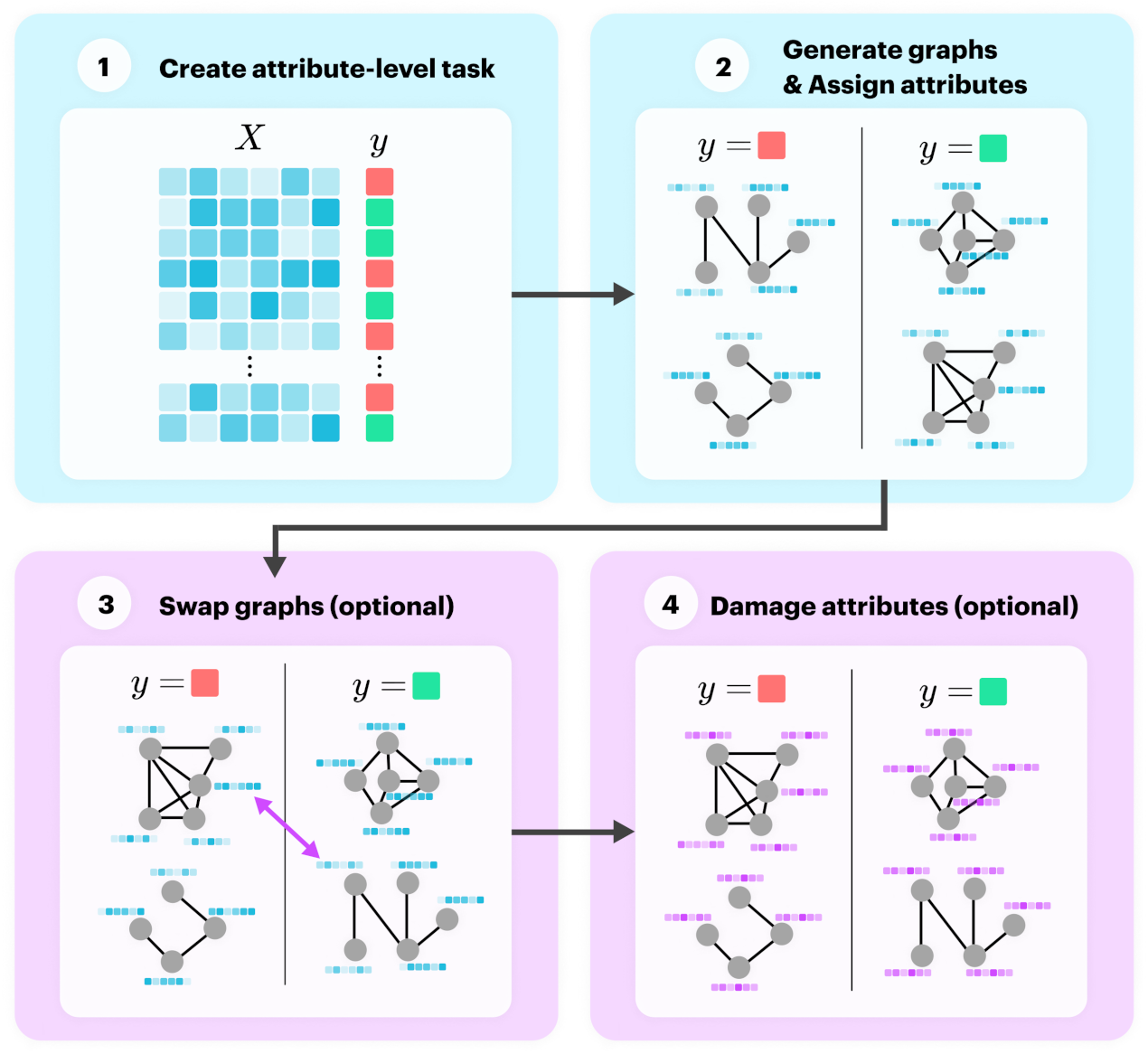
In this subsection we present a novel process for generating synthetic datasets for the task of graph classification. To create a meaningful graph classification task, we parameterise a generator to control the community structure for both structure and attributes. To do this, we generated the dataset using the following four steps:
- Create a random n-class classification problem with a sample and labels ;
- For each label in , generate several graphs and set their node attributes to the relevant example from . Label these graphs with ;
- Optionally, swap the labels assigned to some of the graphs to weaken community structure;
- Optionally, replace node attributes with noise to weaken attribute community structure.
Steps 1 and 2 create community structure for attributes and structure, respectively, and the final two steps weaken the community structure if selected to do so. Figure 2 illustrates this process, where the blue blocks create community structure and the pink blocks weaken it.
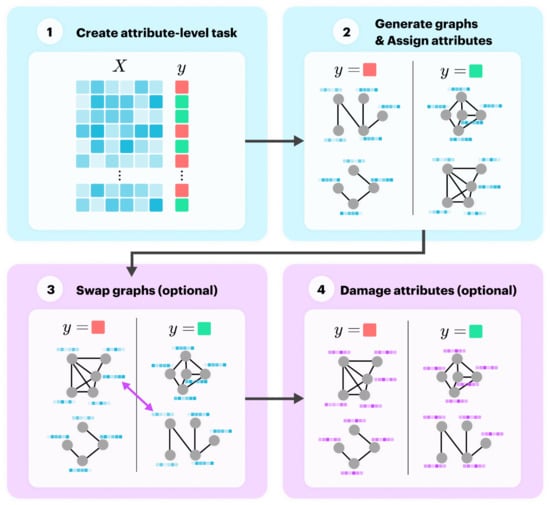
Figure 2.
Generation process for synthetic graph classification datasets.
The generator takes the following parameters as input:
- num_classes: the number of classes or labels in the dataset;
- n_per_class: the number of graphs to generate per class;
- n_features: the length of the node feature vector;
- percent_swap: the percentage of graphs to swap;
- percent_damage: the percentage of graphs where node attributes are to be damaged.
The num_classes, n_per_class and n_features parameters allow for dataset level properties to be varied, while percent_swap and percent_damage influence the structural and attribute community structure respectively. We fixed the size of the graphs at 30 nodes. More details regarding this generation process are provided in the Appendix A.
Similarly to the synthetic node classification datasets, we generated four configurations for each strong and weak community structure combination (see Table 4). We again indicated the strength of the Structural and Attribute Within Inertia using arrows. For example, indicates strong Structural Within Inertia and weak Attribute Within Inertia. We selected Configuration 8 () as our target task, and used the remaining three as source tasks.
Table 4.
The four configurations of synthetic graph classification datasets.
2.2.2. Real-World Data
Many real-world problems within bioinformatics and chemistry present themselves as graph classification problems. We selected datasets from Open Graph Benchmark where the task is molecular property prediction: BBBP and HIV. BBBP (Blood–Brain Barrier Penetration) is a physiological dataset where the task is to predict whether a given compound penetrates the blood–brain barrier or not [48]. HIV is a biophysics dataset where the task is to predict whether a compound has anti-HIV activity or not.
Both datasets are preprocessed in the same manner and are both binary classification tasks. Nodes are atoms and chemical bonds are edges, while node attributes are 9-dimensional and contain information about atomic properties. BBBP is a much smaller dataset than HIV, so we split HIV into a source and target split similar to the real-world node classification experiments: half the HIV is randomly sampled for each split, and this sample is kept fixed. A summary of the datasets is given in Table 5.
Table 5.
Statistics of real-world graph classification datasets used in our experiments.
2.2.3. Experimental Methodology
We conducted experiments similar to those for real-world node classification. The target task, HIV target split, is fixed, and we pretrained our GNNs on BBBP and the HIV source split and then evaluated them on the target task. We also evaluated the transfer performance where the models are pretrained on the source datasets with damaged node attributes, i.e., where the node attributes are replaced by Gaussian distributed random noise with a mean of 0 and a standard deviation of 1. The experiments are described in Table 6.
Table 6.
Experiments conducted for graph classification using both real-world and synthetic datasets.
3. Results
3.1. Node Classification Results
3.1.1. Real-World Data
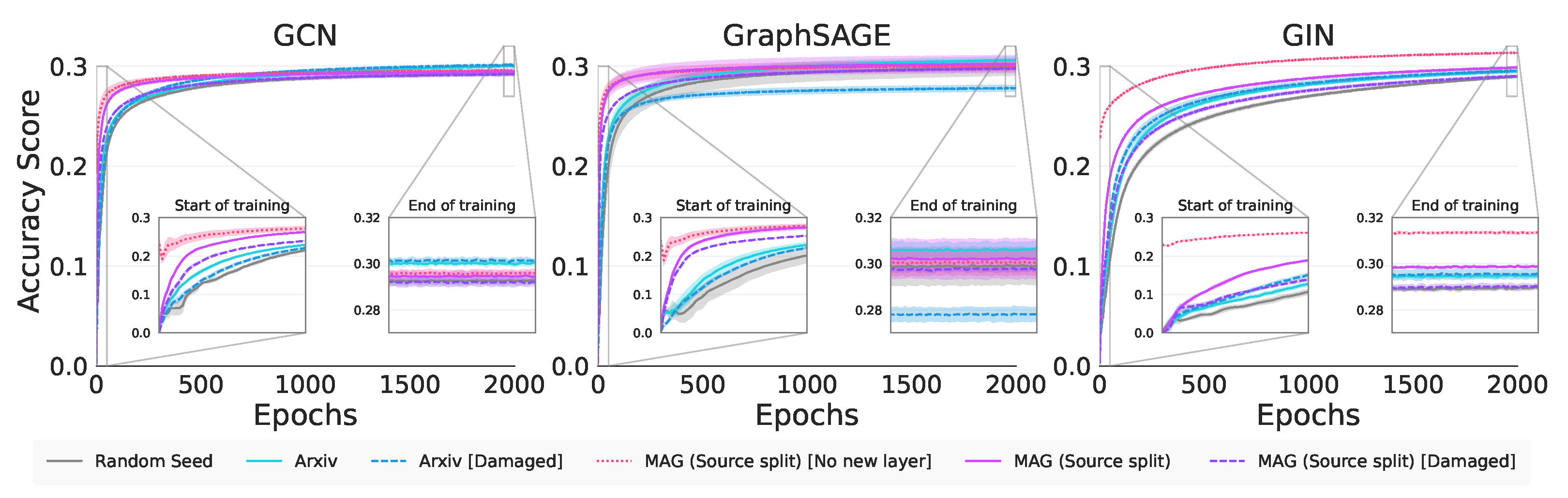
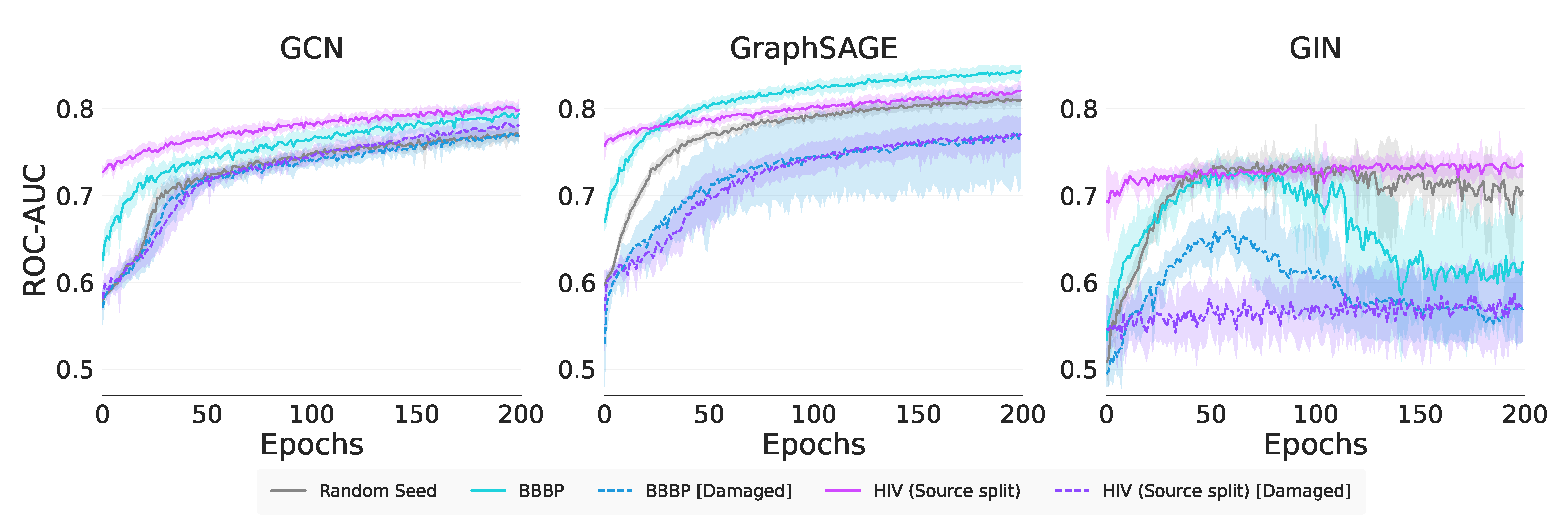
In Figure 3 we see the training curves for the experiments in Table 3. We note for GCN, all the pretrained model curves rise above the base model, indicating we have positive knowledge transfer. This phenomenon is noted for both GraphSAGE (except for Arxiv [Damaged]), and GIN. Since the pretraining datasets are all citation networks, positive transfer is a reasonable outcome.
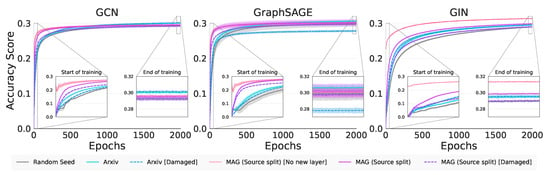
Figure 3.
Real-world node classification training curves.
Concerning the Transfer Ratios in Table 7 we note that only GIN and GCN have significant transfer from the completely new Arxiv dataset. Interestingly, for GCN and GIN, we note that Arxiv with damaged attributes, in absolute terms, performs somewhat better than just Arxiv, indicating that graph characteristics beyond attribute values are being used for transfer. Although some of the GraphSAGE Transfer Ratios are positive, these are not statistically better than the control. Turning to Table 8, we note that GIN statistically always outperforms the other GNNs in this metric, indicating that GIN benefits the most from sharing knowledge from the source domains.
Table 7.
Transfer metrics for real-world node classification experiments (10 runs). Bold results are positive and statistically greater than the control at . We evaluate significance for each model/metric combination.
Table 8.
Transfer metrics for real-world node classification experiments (10 runs). Bold results are not statistically greater than the best at . We evaluate significance for each source-task/metric combination.
The MAG (Source split) [Old layer] tasks, in Table 7, have a greater Jumpstart than the rest, since the ouptut layer does not need to be retrained. We note that both GCN and GraphSAGE show significant Jumpstart with the completely new task Arxiv. In fact GraphSAGE exploits graph characteristics beyond attribute values as evidenced by the Arxiv [Damaged] results. In Table 8 we note that GCN is either on par or significantly better than the other GNNs across all datasets on this metric; however, the result is not compelling.
All GNNs achieve significant positive asymptotic performance above the control on the new Arxiv task. GraphSAGE is inconsistent and does not always show transfer at the end of training. Despite the huge Jumpstart with MAG (Source split) [Old layer], only GIN retains a large absolute improvement in Asymptotic Performance. Both GCN and GIN once again exploit structural characteristics beyond the attribute values as evidenced by the Arxiv [Damaged] results. In Table 8 we see a mixture of best-performing GNNs with both GCN and GraphSAGE performing well on the completely new Arxiv task.
| Takeaway 1: We have statistical evidence that transfer to a new task for node classification does occur across all metrics and GNNs. We demonstrate that GCN and GIN exploit structural rather than attribute information for achieving a positive Transfer Ratio and Asymptotic Performance, as does GraphSAGE for Jumpstart. |
Next we consider our synthetic data to interrogate exactly which characteristics of graphs are being transferred by the above GNNs.
3.1.2. Synthetic Data
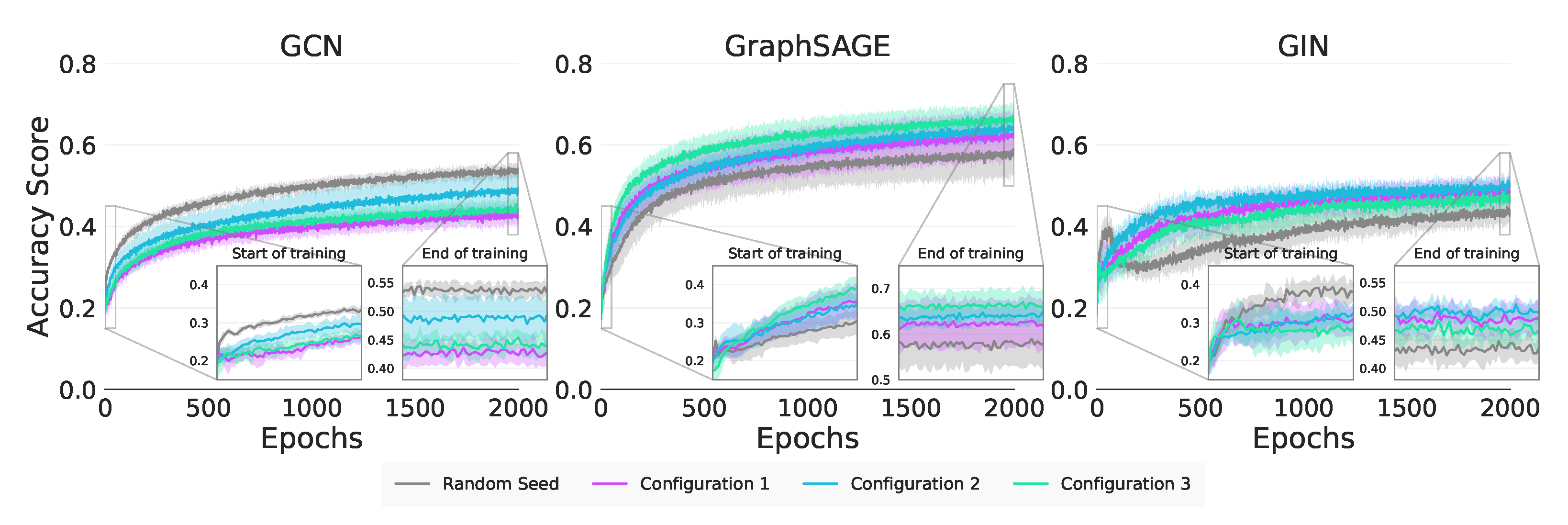
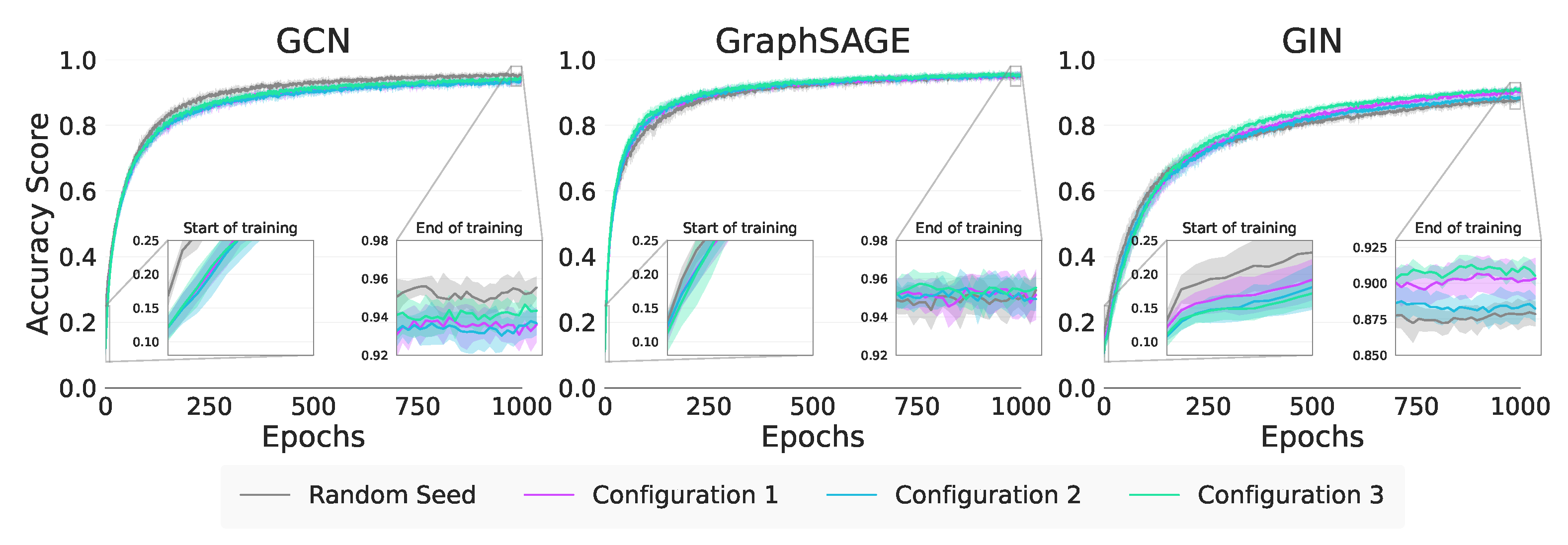
In Figure 4 and Table 9 we note that the performance of GIN is as a result of the strong Modularity in Configurations 1 (MI) and 2 (MI). For GraphSAGE, this distinction between Modularity and Within Inertia is less clear as the results for Configurations 2 (MI) and 3 (MI) are statistically equivalent. The absolute performance of Configuration 3 (MI) for GraphSAGE does suggest that Within Inertia is being exploited, but further investigation is required.
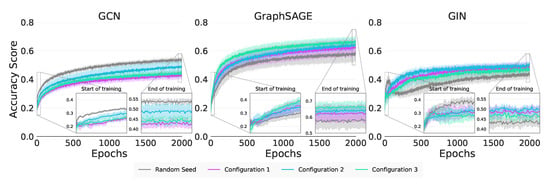
Figure 4.
Synthetic node classification training curves.
Table 9.
Transfer metrics for synthetic node classification (10 runs). Bold results are not statistically greater than the best at . We evaluate significance for each model/metric combination.
For Jumpstart, we are unable to see any significant difference in Table 9 across all configurations for the GCN and GIN, making it unclear as to which of Modularity or Within Inertia is responsible for the positive transfer. GraphSAGE is significantly better in Configuration 1 (MI) indicating both the Strong Modularity and Within Inertia are being exploited, supporting our real-world assertion that it exploits graph characteristics beyond attribute values. We do note in Table 9 that all methods show positive Jumpstart on Configuration 1 (MI) and 2 (MI) suggesting that it is might be the Strong Modularity that all the GNNs are exploiting.
With Asymptotic Performance, our results do not allow us to say anything about which of structure or attributes GraphSAGE is exploiting. However, GIN, as evidenced in Table 9, is able to build on the Modularity from Configuration 1 (MI) as the Weak Inertia of Configuration 2 (MI) is not significantly better.
| Takeaway 2: In general, GIN predominately exploits Strong Modularity for transfer—while GraphSAGE can exploit both Modularity and Within Inertia for Jumpstart—in support of our real-world data findings. |
3.2. Graph Classification Results
3.2.1. Real-World Data
Figure 5 shows that GCN and GraphSAGE have more stable training curves than GIN, which is poorer in its performance. We observe clear transfer with GCN and GraphSAGE for both undamaged source tasks. In addition, we observe negative transfer for both damaged source tasks for GCN and GraphSAGE. GIN achieves positive self-transfer with HIV (Source split), and negative transfer with the remaining pretrainings. GIN’s training curves also show a decay over training with BBBP pretrainings. The training curves indicate GraphSAGE and GIN suffer from worse negative transfer than GCN.
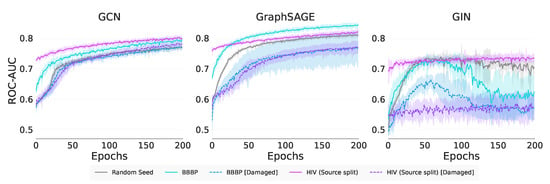
Figure 5.
Real-world graph classification training curves.
From Table 10, we see that across the transfer metrics, GCN and GraphSAGE achieved significant positive Transfer Ratios for HIV (Source split) and BBBP when compared to the control. This result indicates that they are able to transfer to a completely new task. GIN shows transfer from the similar task HIV (Source split) but not from the new task BBBP for any of the metrics. The biggest jumpstart is seen with HIV (Source split), which is understandable since it is a self-transfer task. None of the GNNs for any of the tasks show any significant transfer from the damaged task, indicating that the node attributes are likely exploited over graph structural characteristics.
Table 10.
Transfer metrics for real-world graph classification experiments (10 runs). Bold results are statistically greater than the control at . We evaluate significance for each model/metric combination.
In Table 11 we note that GraphSAGE is significantly better than all other GNNs across all metrics when transferring from the completely new BBBP task. For the transfer from the more similar HIV (Source split) results are mixed with GCN requiring further experimentation to determine outperformance.
| Takeaway 3: We have significant statistical evidence to support that transfer happens for graph classification for both GCN and GraphSAGE across all metrics considered. We can also reject the hypothesis that the transfer is as a result of graph structure beyond the node attributes alone. |
Table 11.
Transfer metrics for real-world graph classification experiments (10 runs). Bold results are not statistically greater than the best at . We evaluate significance for each source-task/metric combination.
In the following section, we consider synthetic data to further investigate which structural characteristics of graphs are being transferred by the GNNs.
3.2.2. Synthetic Data
When considering the graph classification Transfer Ratios in Table 12, only GraphSAGE and GIN showe any positive transfer. Interestingly, for both models, the result is significant for Configuration 7 () indicating that it is the strong Attribute Within Inertia that is being transferred. The amount of Jumpstart achieved by all GNNs is low, as shown in Figure 6, indicating that transfer is not achieved at the start of training, and that the pretrained model performs similarly to the base models initially. For graph classification on the synthetic data, we note from Table 12 that none of the considered methods are able to achieve positive Jumpstart. These values are not discussed further here. The values for the asymptotic performance show similar results to the Transfer Ratios.
Table 12.
Transfer metrics for synthetic graph classification (10 runs). Bold results are not statistically greater than the best at . We evaluate significance for each model/metric combination.
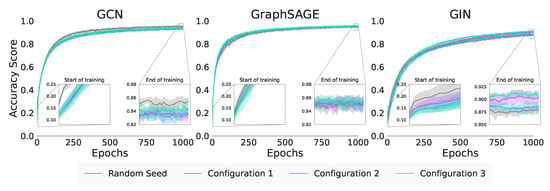
Figure 6.
Synthetic graph classification training curves.
Since there is minimal Jumpstart, any positive or negative transfer appears to be achieved by the GNNs towards the end of training. GraphSAGE and GIN both achieve positive Asymptotic Improvements as seen Table 12; however, for GraphSAGE, these values are not significantly different from negative transfer. We note for both GraphSAGE and GIN that the best transfer occurs for Configuration 5 () and 7 (). In absolute terms, we might infer that due to the higher values in Configuration 7 (), transfer results from the strong Attribute Within Inertia. However, these differences are not statistically significant and require further experimentation to confirm.
The fact that no Jumpstart but improved Asymptotic Performance is observed is interesting: it indicates that the transferred knowledge is not immediately useful but rather leads to better performance on downstream training. This observation would be supported by an argument that the transferred knowledge is not in the linear output layers but instead available in the deeper nonlinear feature layers and exposed later in training.
| Takeaway 4: There is significant evidence that GraphSAGE and GIN exploit Strong Attribute Within Inertia in order to achieve transfer. These results support our real-world findings with respect to GraphSAGE. |
4. Discussion
Our research presented several contributions for understanding transfer learning using graph neural networks. We proposed a framework for evaluating transfer with GNNs by testing various source tasks on a fixed target task. We employed this framework, along with transfer learning metrics and notions of community structure, to evaluate the transferability of three useful GNNs: GCN, GraphSAGE and GIN. We tested and compared these models using real-world and synthetic graph data for node-classification and graph-classification contexts. In addition, we presented a novel procedure for generating synthetic datasets for graph classification.
All three of the GNNs we selected can transfer knowledge across training on the target task. GCN and GIN can exploit Strong Modularity in the source task, while GraphSAGE can leverage both structural and attribute information for node classification. For graph classification, it is less clear that any model exploits either attribute or structural community structure, and they appear to leverage a combination of the two to achieve transfer.
5. Conclusions
This research begins to standardise the procedure and metrics for evaluating transfer learning using GNNs. Research on deep learning with graphs is expanding rapidly, and understanding how we can achieve effective transfer is therefore of great benefit. There remains large scope for future research. Our results considered node and graph classification; but our experiments for transfer learning may be extended to other common graph domains such as link prediction and edge classification. Another avenue for future research is to repeat our experiments with other GNNs such as Graph Attention Network [49], and other Graph Network types described by Battaglia et al. [7].
Author Contributions
Conceptualization, N.K., S.J. and T.v.Z.; methodology, N.K.; software, N.K.; validation, N.K.; formal analysis, N.K.; investigation, N.K., S.J. and T.v.Z.; resources, S.J. and T.v.Z.; data curation, N.K.; writing—original draft preparation, N.K., S.J. and T.v.Z.; writing—review and editing, N.K., S.J. and T.v.Z.; visualization, N.K.; supervision, S.J. and T.v.Z.; project administration, S.J. and T.v.Z.; funding acquisition, N.K., S.J. and T.v.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by the National Research Foundation of South Africa grant number 122158.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://ogb.stanford.edu, accessed on 3 June 2021.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Data Generation for Graph Classification
As described in the main article, we present a novel approach for synthetic graph classification datasets. We want to be able to control the level of community structure for both structure and attributes. To this end, we generated the datasets in the following four steps:
Appendix A.1. Step 1: Create an Attribute-Level Task
The first step in the generation process is to create a attribute-level classification task, where vectors of length n_features are generated belonging to num_classes classes. The total number of these vectors is num_classes × n_per_class × 30, so that each node in each graph for each class has an attribute vector that can be assigned to it. We followed Morris et al. [50] in generating this attribute level task using the scikit-learn library (See https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html, accessed on 4 August 2021). This tool generates the classification task using a modified algorithm from Guyon [51]. After this step, the attributes have a high level of community structure.
Appendix A.2. Step 2: Generate Graphs and Assign Attributes to the Graphs
Now that we have attribute vectors that are labelled, we want to generate graphs to assign them to. We wanted the graphs in each class to have different average degrees, so that strong community structure in terms of exists. A common and useful graph-generation algorithm is the Barabási-Albert (BA) model [52]. The BA algorithm models preferential attachment, and takes in two parameters: the number of nodes n, and m the number of edges to attach from a new node to existing nodes while growing the graph.
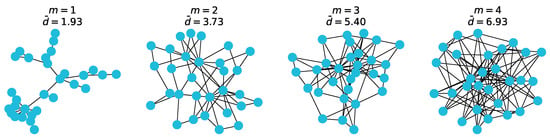
Figure A1.
Average degrees for varying m in the Barabási-Albert model.
Figure A1.
Average degrees for varying m in the Barabási-Albert model.
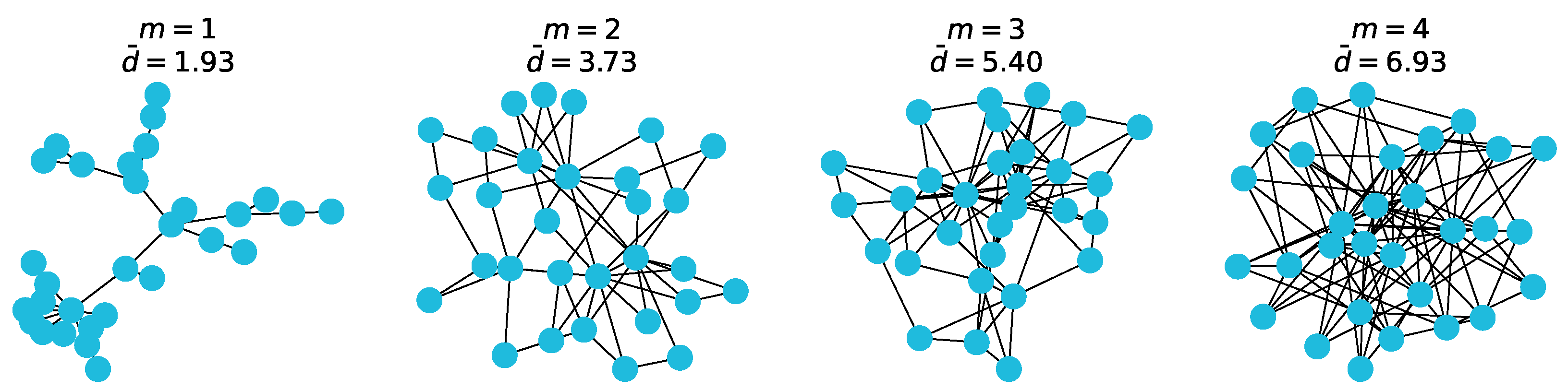
Varying the m parameter changes the connectivity of a generated graph, and thus its average node degree. This can be seen in the figure above. By assigning graphs generated with different values of m to different classes, we ensured structural community structure with respect to average node degrees.
Once n_per_class graphs were generated for num_classes with different m values, the corresponding attribute vectors from the previous step were assigned to graphs with the same label. At the end of this step, we had a labelled dataset with strong community structure for both nodes and attributes.
Appendix A.3. Step 3: Swap Graphs
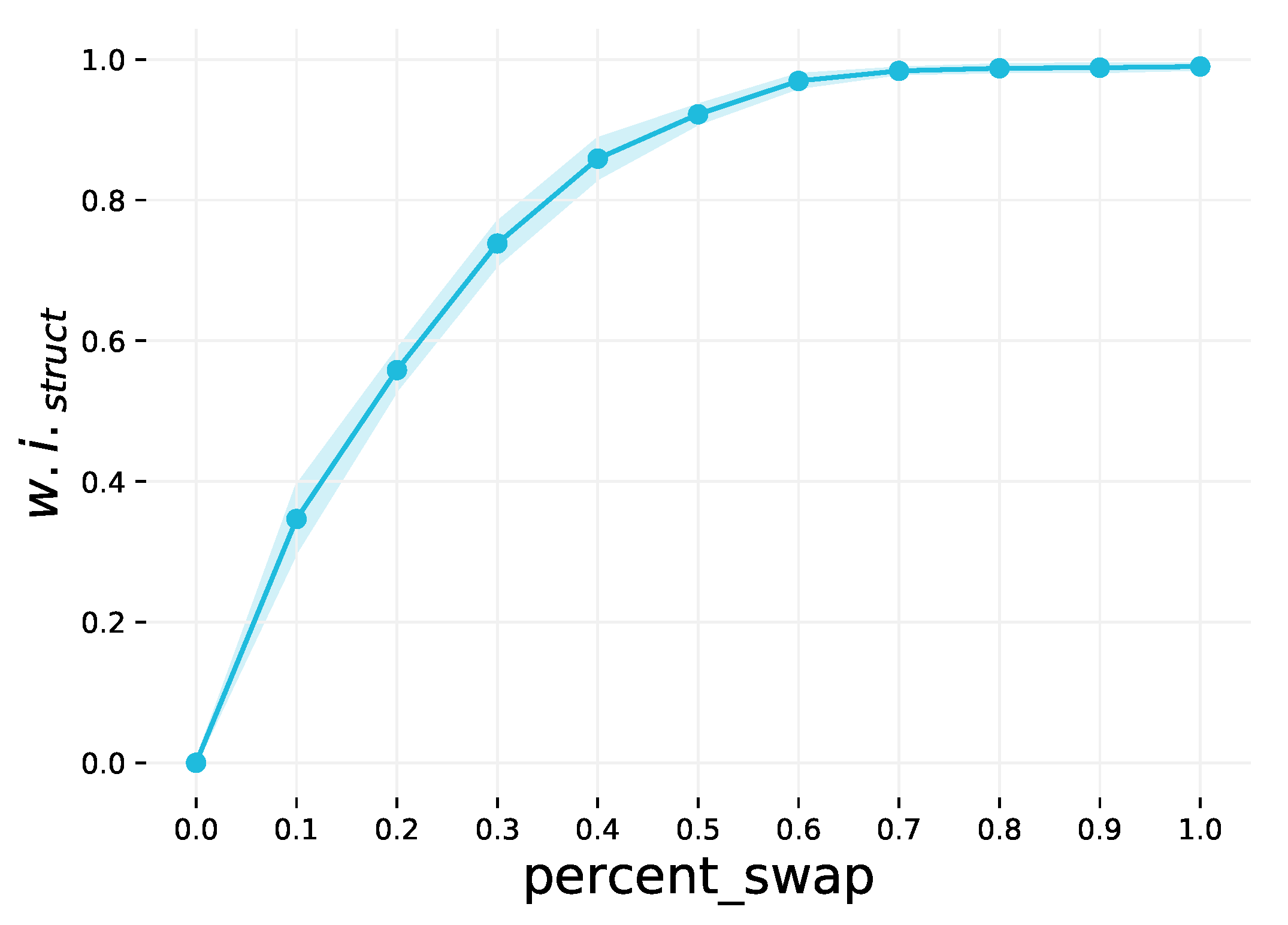
This step weakens the structural community structure of the dataset by swapping graphs. This is an optional step, and the extent to which the community structure is weakened is controlled by the percent_swap parameter. This parameter may be in the range , and the default value is 0 (no graphs are swapped). A random sample of pairs of graphs to swap is selected, corresponding to the specified percentage of the dataset. By swapping more graphs, the classes have less distinct average node degrees compared to one another, resulting in weaker community structure. This is demonstrated in Figure A2.
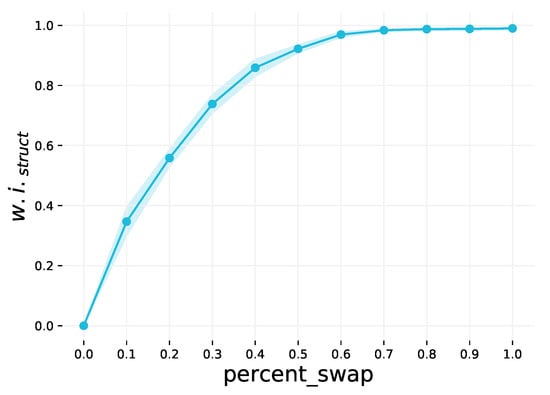
Figure A2.
The effect of varying the percent_swap parameter on . The shaded region is the 1 interval variance over 10 runs.
Figure A2.
The effect of varying the percent_swap parameter on . The shaded region is the 1 interval variance over 10 runs.
Appendix A.4. Step 4: Damage Attributes
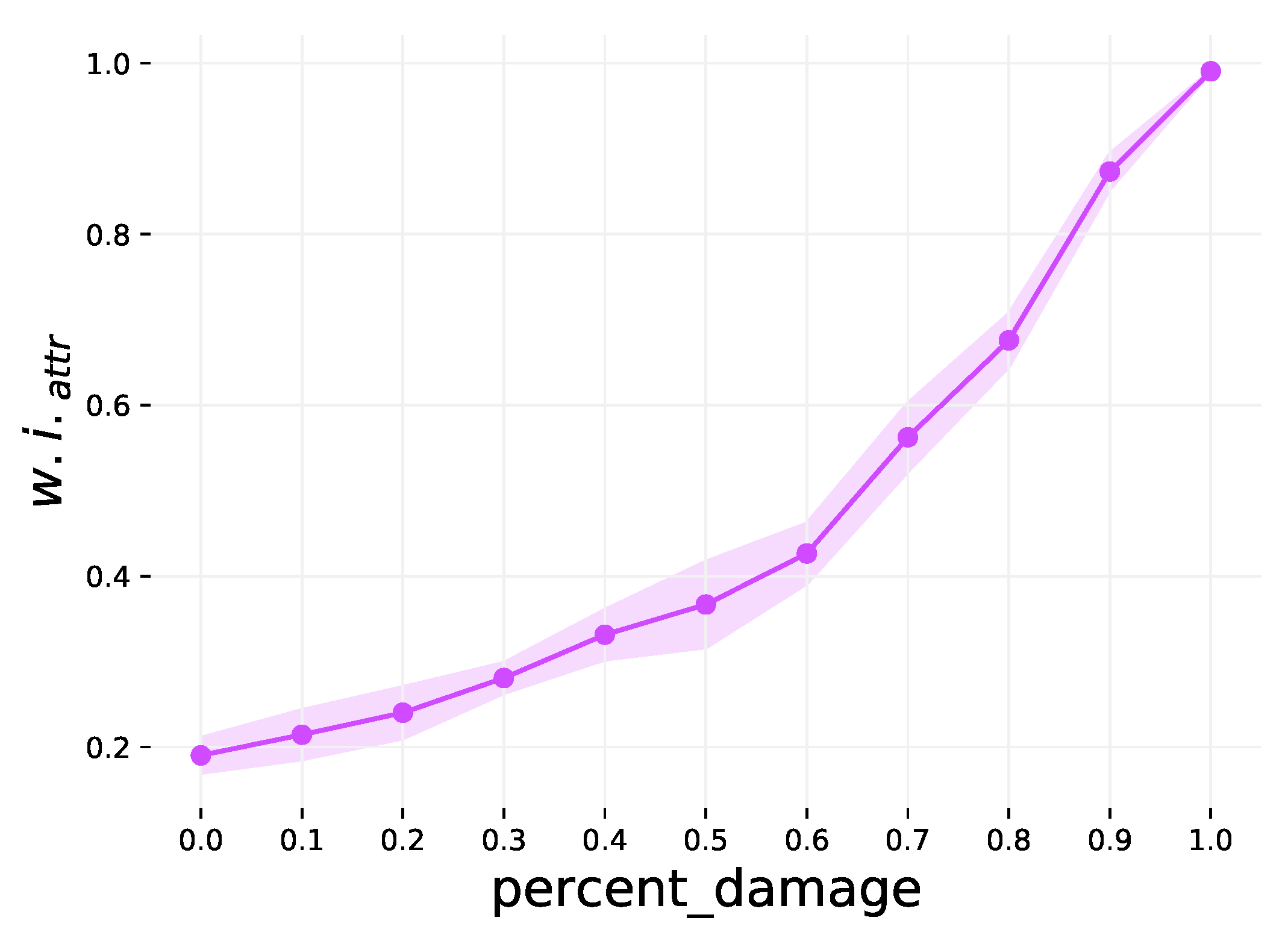
The final step weakens attribute community structure by replacing node attribute vectors with random noise. This step is also optional, and is controlled by the percent_ damage parameter. This parameter also has a range of , with a default value of 0, and defines the percentage of graphs which will have their node attributes damaged (replaced with random values). The higher the percentage is, the less distinct the attributes from different classes are from one another, and thus a weaker community structure. This is demonstrated in Figure A3.
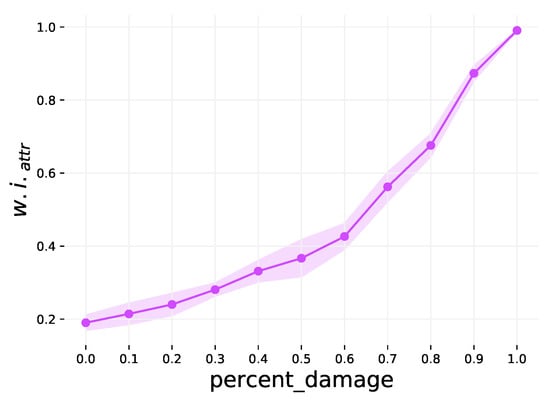
Figure A3.
The effect of varying the percent_damage parameter on . The shaded region is the 1 variance over 10 runs.
Figure A3.
The effect of varying the percent_damage parameter on . The shaded region is the 1 variance over 10 runs.
References
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S.S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond Euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Roy, A.M.; Bose, R.; Bhaduri, J. A fast accurate fine-grain object detection model based on YOLOv4 deep neural network. Neural Comput. Appl. 2022, 34, 3895–3921. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R.; et al. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]
- Hendrycks, D.; Lee, K.; Mazeika, M. Using pre-training can improve model robustness and uncertainty. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Zhang, K.; Robinson, N.; Lee, S.W.; Guan, C. Adaptive transfer learning for EEG motor imagery classification with deep Convolutional Neural Network. Neural Netw. 2021, 136, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Kooverjee, N.; James, S.; Van Zyl, T. Inter-and Intra-domain Knowledge Transfer for Related Tasks in Deep Character Recognition. In Proceedings of the 2020 International SAUPEC/RobMech/PRASA Conference, Cape Town, South Africa, 29–31 January 2020; pp. 1–6. [Google Scholar]
- Van Zyl, T.L.; Woolway, M.; Engelbrecht, B. Unique animal identification using deep transfer learning for data fusion in siamese networks. In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–6. [Google Scholar]
- Karim, Z.; van Zyl, T.L. Deep/Transfer Learning with Feature Space Ensemble Networks (FeatSpaceEnsNets) and Average Ensemble Networks (AvgEnsNets) for Change Detection Using DInSAR Sentinel-1 and Optical Sentinel-2 Satellite Data Fusion. Remote Sens. 2021, 13, 4394. [Google Scholar] [CrossRef]
- Variawa, M.Z.; Van Zyl, T.L.; Woolway, M. Transfer Learning and Deep Metric Learning for Automated Galaxy Morphology Representation. IEEE Access 2022, 10, 19539–19550. [Google Scholar] [CrossRef]
- Barabási, A.L. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks? In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Taylor, M.E.; Stone, P. Transfer learning for reinforcement learning domains: A survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Bengio, Y. Deep learning of representations for unsupervised and transfer learning. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 2 July 2011. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do better ImageNet models transfer better? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Huh, M.; Agrawal, P.; Efros, A.A. What makes ImageNet good for transfer learning? arXiv 2016, arXiv:1608.08614. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Hamilton, W.L. Graph representation learning. In Synthesis Lectures on Artifical Intelligence and Machine Learning; Morgan & Claypool Publishers: San Rafael, CA, USA, 2020. [Google Scholar]
- Velickovic, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Lee, J.; Kim, H.; Lee, J.; Yoon, S. Transfer learning for deep learning on graph-structured data. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Hu, W.; Liu, B.; Gomes, J.; Zitnik, M.; Liang, P.; Pande, V.; Leskovec, J. Strategies for Pre-training Graph Neural Networks. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Dai, Q.; Shen, X.; Wu, X.M.; Wang, D. Network Transfer Learning via Adversarial Domain Adaptation with Graph Convolution. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Errica, F.; Podda, M.; Bacciu, D.; Micheli, A. A fair comparison of graph neural networks for graph classification. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2020. [Google Scholar]
- Fey, M.; Lenssen, J.E. Fast Graph Representation Learning with PyTorch Geometric. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Dwivedi, V.P.; Joshi, C.K.; Laurent, T.; Bengio, Y.; Bresson, X. Benchmarking graph neural networks. arXiv 2020, arXiv:2003.00982. [Google Scholar]
- Hu, W.; Fey, M.; Zitnik, M.; Dong, Y.; Ren, H.; Liu, B.; Catasta, M.; Leskovec, J. Open Graph Benchmark: Datasets for Machine Learning on Graphs. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020. [Google Scholar]
- Bhagat, S.; Cormode, G.; Muthukrishnan, S. Node classification in social networks. In Social Network Data Analytics; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Ehrlinger, L.; Wöß, W. Towards a Definition of Knowledge Graphs. SEMANTiCS 2016, 48, 2. [Google Scholar]
- Clauset, A.; Newman, M.E.; Moore, C. Finding community structure in very large networks. Phys. Rev. E 2004, 70, 066111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Largeron, C.; Mougel, P.N.; Benyahia, O.; Zaïane, O.R. DANCer: Dynamic attributed networks with community structure generation. Knowl. Inf. Syst. 2017, 53, 109–151. [Google Scholar] [CrossRef]
- McPherson, M.; Smith-Lovin, L.; Cook, J.M. Birds of a feather: Homophily in social networks. Annu. Rev. Sociol. 2001, 27, 415–444. [Google Scholar] [CrossRef] [Green Version]
- Leskovec, J.; Backstrom, L.; Kumar, R.; Tomkins, A. Microscopic evolution of social networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Wang, K.; Shen, Z.; Huang, C.; Wu, C.H.; Dong, Y.; Kanakia, A. Microsoft academic graph: When experts are not enough. Quant. Sci. Stud. 2020, 1, 396–413. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Massey, F.J., Jr. The Kolmogorov-Smirnov test for goodness of fit. J. Am. Stat. Assoc. 1951, 46, 68–78. [Google Scholar] [CrossRef]
- Koutra, D.; Parikh, A.; Ramdas, A.; Xiang, J. Algorithms for Graph Similarity and Subgraph Matching. 2011. Available online: https://www.cs.cmu.edu/~jingx/docs/DBreport.pdf (accessed on 5 May 2021).
- Abu-Aisheh, Z.; Raveaux, R.; Ramel, J.Y.; Martineau, P. An exact graph edit distance algorithm for solving pattern recognition problems. In Proceedings of the International Conference on Pattern Recognition Applications and Methods, Lisbon, Portugal, 10–12 January 2015. [Google Scholar]
- Martins, I.F.; Teixeira, A.L.; Pinheiro, L.; Falcao, A.O. A Bayesian approach to in silico blood-brain barrier penetration modeling. J. Chem. Inf. Model. 2012, 52, 1686–1697. [Google Scholar] [CrossRef] [PubMed]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Morris, C.; Kriege, N.M.; Kersting, K.; Mutzel, P. Faster kernels for graphs with continuous attributes via hashing. In Proceedings of the International Conference on Data Mining, Barcelona, Spain, 12–15 December 2016. [Google Scholar]
- Guyon, I. Design of experiments of the NIPS 2003 variable selection benchmark. In Proceedings of the NIPS Workshop on Feature Extraction and Feature Selection, Whistler, BC, Canada, 11–13 December 2003. [Google Scholar]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).