1. Introduction
The evolution of innovative technologies has made our daily life more comfortable. Consequently, speech is the most convenient communication method with increasing interactions between humans and machines. People can understand other ways of communicating emotions relatively easily, such as body gestures [
1], facial expressions [
2], image classification [
3], and successfully detecting emotional states (e.g., happiness, anger, sadness, and neutrality). Speech-based emotion recognition tasks are receiving increasing attention in many areas, such as forensic sciences [
4], customer support call review and analysis [
5], mental health surveillance, intelligent systems, and quality assessments of education [
6]. Deep learning technology has accelerated the recognition of emotions from speech, but the research on SER still has deficiencies, such as shortages of training data and inadequate model performance [
7,
8]. However, emotion classification from speech in real-time is difficult due to several dependencies, such as speakers, cultures, genders, ages, and dialects [
9].
Most importantly, the feature extraction step in an SER task can effectively fill the gap between speech samples and the corresponding emotional states. Various hand-crafted features, such as pitch, duration, format, intensity, and linear prediction coefficient (LPC), have been used in SER so far [
10,
11]. However, these hand-crafted features suffer from a limited capability and low accuracy in building an efficient SER system [
12] because they are at a lower level and may not be discriminative enough to predict the respective emotional category [
13]. Nowadays, spectral features are more popular and usable than traditional hand-crafted features as they extract more emotional information by considering the time and frequency [
14]. Due to these advantages, scholars have carried out a considerable amount of research using spectral features [
15,
16,
17]. However, these features cannot adequately express the emotions in an utterance. Therefore, to overcome the limitations of traditional hand-crafted features and spectral features, high-level deep feature representations need to be extracted using efficient deep learning algorithms for SER from speech signals [
12]. Over the last few years, researchers have introduced different deep learning algorithms using various discriminative features [
18,
19,
20]. At present, deep learning methods still use several low-level descriptor (LLD) features, which are different from traditional SER features [
21]. So, extracting more detailed and relevant emotional information from speech is the first issue we have to address.
Newly emerging deep learning methods may provide possible solutions to this issue. Among them, two of the most common are Convolutional Neural Networks (CNNs) [
22] and Recurrent Neural Networks (RNNs), such as long short-term memory (LSTM) and Gated Recurrent Units (GRUs) [
23,
24]. A model with an RNN and a CNN was built to represent high-level features from low-level data for SER tasks [
25]. The CNN represents a high-level feature map, while the RNN extracts long-term temporal contextual information from the low-level acoustic features to identify the emotional class [
26]. Several studies [
14,
27] have been successfully carried out to learn features in speech signal processing using CNNs and RNNs.
Moreover, most speech emotion databases contain only utterance-level class labels, and not all parts of utterances hold emotional information. They contain unvoiced parts, short pauses, background sounds, transitions between phonemes, and so on [
28]. Unfortunately, CNNs and RNNs are not able to efficiently deal with this situation and analyze acoustic features extracted from voices [
29]. So, we must distinguish the emotionally relevant parts and determine whether the speech frame contains voiced or unvoiced parts. Capsule networks (CapNets) have been used to overcome the drawback of CNNs in capturing spatial information [
30]. CapNets have been utilized in various tasks and demonstrated to be effective [
31,
32,
33]. A capsule-based network was developed for emotion classification tasks [
30]. Meanwhile, we applied a self-attention mechanism, emphasizing the capture of prominent features [
34]. Because of this, we moved to the self-attention mechanism from the traditional attention mechanism.
Although these models with deep learning approaches are efficient and adaptable to practical situations, there remain some significant challenges to overcome. These are as follows:
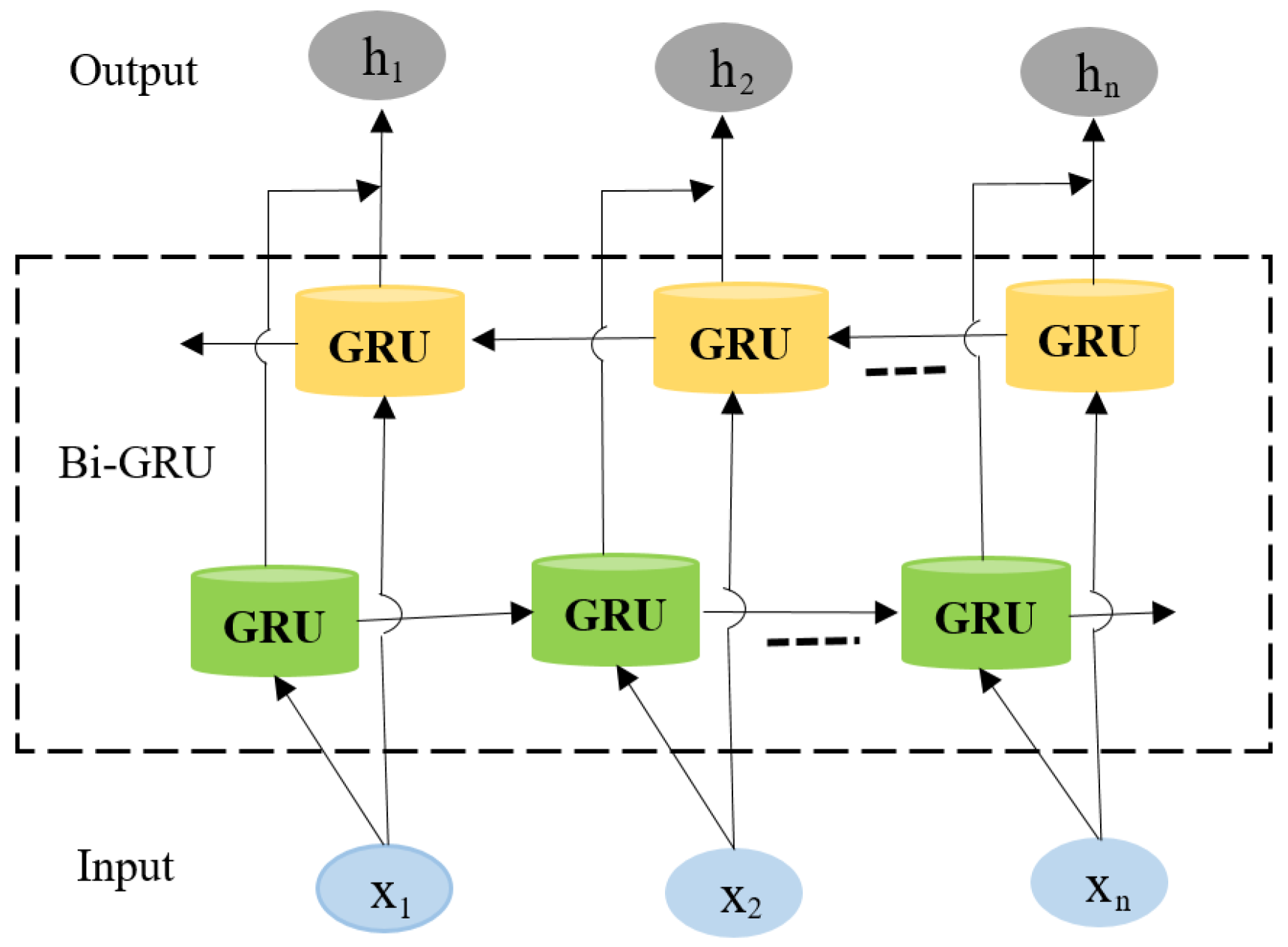
Therefore, a novel system is required to independently learn the local and global contextual emotional features in speech utterances of varied length. We were inspired by the RNNs and capsule networks that have been used in many fields to achieve high accuracy and better generalizability, especially in time-series data. To reduce the redundancy and enhance the complementarity, we propose a novel fusion-based dual-channel self-attention deep learning model using a combination of a CNN and a capsule network (Conv-Cap) and a Bi-GRU (shown in
Figure 1), as presented in
Figure 2. The proposed model effectively uses the advantages of different features in parallel inputs to increase the performance of the system. The final issue is to design a suitably sized input array to meet the needs of other models’ performance.
The contributions and innovations of this study can be summarized as follows:
We propose an efficient speech emotion recognition architecture utilizing a modified capsule network and Bi-GRU modules in two streams with a self-attention mechanism. Our model is capable of learning spatial and temporal cues through low-level features. It automatically models the temporal dependencies. Therefore, we aim to contribute to the SER literature by using different spectral features with an effective parallel input mode and then fusing the sequential learning features;
We propose and explore for the first time a Conv-Cap and Bi-GRU feature-learning-based architecture for SER systems. To the best of our knowledge, the proposed methods are novel. We pass spectrograms through the Conv-Cap network and Mel-frequency cepstral coefficients, chromagrams, the contrast, the zero-crossing rate, and the root mean square through the Bi-GRU network in parallel to enhance the feature learning process in order to capture more detailed emotional information and to improve baseline methods;
We propose a dual-channel self-attention strategy to selectively focus on important emotional cues and ensure the system’s performance using discriminative features. We use a novel learning strategy in attention layers, which utilize the outputs of the proposed capsule network and sequential network simultaneously and capture the attention weight of each cue. Moreover, the proposed SER system’s time complexity is much lower than that of the sole model;
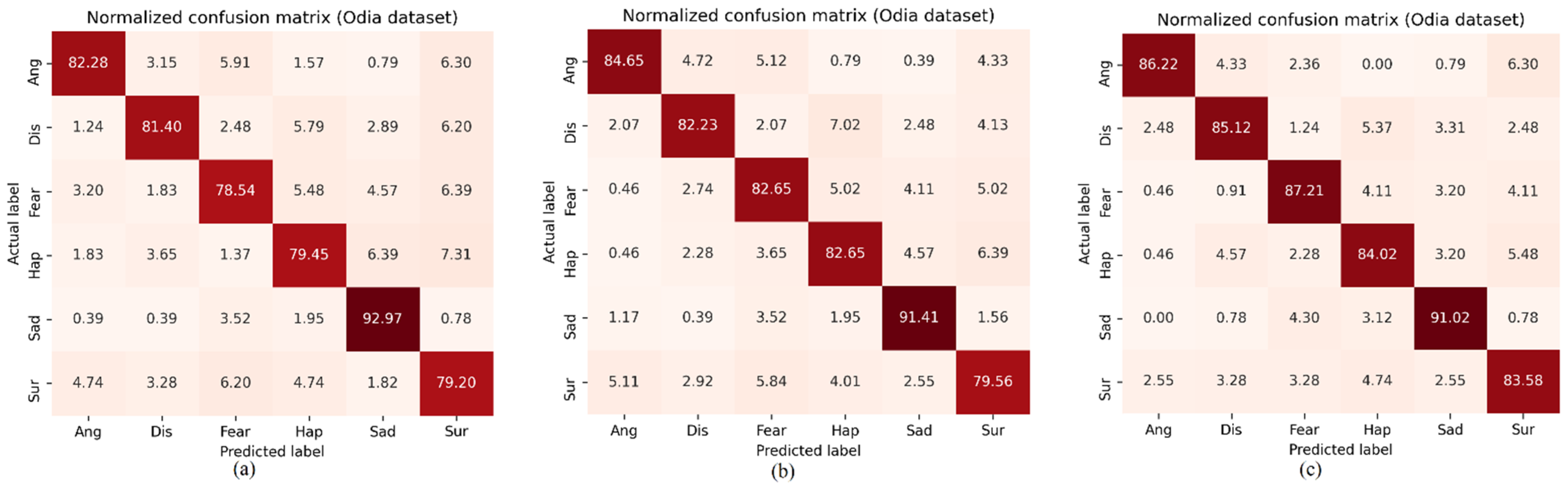
We demonstrate the significance of a fusion strategy by using a confidence-based fusion technique that ensures the best outcomes for these integrated, separately learned features by using a fully connected network (FCN). We demonstrate the effectiveness and efficiency of our proposed method on the IEMOCAP and EMO-DB databases and our own Odia speech corpus (SITB-OSED). We conducted extensive experimentation and obtained results that outperformed state-of-the-art approaches for emotion recognition.
The remainder of this paper is arranged as follows. A review of the literature on SER is given in
Section 2.
Section 3 provides the details of our proposed system.
Section 4 presents the datasets, the experimental setup, and a comparative analysis that demonstrates the model’s efficacy and reliability. Finally, our conclusions and future research directions are provided in
Section 5.
2. Literature Review
SER is an energetic field of research, and researchers have designed numerous strategies over the last few years. With the use of advanced deep learning strategies, researchers have mostly applied complex hand-crafted features (e.g., eGeMaps, ComParE, IS09, etc.) for SER with conventional machine learning approaches such as k-nearest neighbor (kNN), support vector machine (SVM), the Gaussian Mixed Model (GMM), and the Hidden Markov Model (HMM) [
37,
38,
39]. Therefore, scholars have been greatly inspired by the growing use of deep learning methods for SER tasks. In [
40], the authors implemented the first deep learning model for SER. Then, in [
41], the authors utilized a CNN model to learn the salient emotional features. Later, in [
42], the authors implemented a CNN model to obtain emotional information from spectrograms to identify the speech emotion [
43]. A spectrogram is a two-dimensional visualization of a speech signal, is used in 2D-CNN models to extract high-level discriminative features, and has become more prevalent in this era [
44]. Zhao et al. [
45] extracted features using different spectrogram dimensions using CNNs and passed them through to an LSTM network. The LSTM network was used to learn global contextual information from the resulting features of the CNN. Kwon et al. [
46] employed a new method to determine the best sequence segments using Radial Basis Functions (RBFs) and KNN. The authors used the selected vital sequence of the spectrogram and extracted features using a CNN. The obtained features were normalized and classified using bi-directional long short-term memory (BiLSTM). The researchers found that 2D CNN-LSTM networks work much better than traditional classifiers. In addition to 2D CNN [
47] networks, some studies have also used 1D CNNs and achieved satisfying performance in SER. For example, in [
48] Mustaqeem et al. proposed a multi-learning framework using a one-dimensional dilated CNN and a bi-directional GRU sequentially. The authors utilized the residual skip connection to learn the discriminative features and the long-term contextual dependencies. In this way, the authors improved the local learned features from the speech signal for SER. In [
17], a new model was built using five spectral features (the MFCC, the chromagram, the Mel-scale spectrogram, the spectral contrast, and the Tonnetz representation). The authors used a 1D CNN to learn the features for the classification results. However, transfer learning methods can also train pre-trained networks, such as AlexNet [
3] and VGG [
49], for SER using spectrograms.
Moreover, some researchers concluded that LSTM performs better when using a CNN to extract high-level features. The LSTM model is well suited to addressing emotional analysis problems, but it is still time-consuming and difficult to train in parallel for large datasets. Cho et al. [
24] employed a GRU, which has a shorter training time, has fewer parameters than the LSTM network, and can capture global contextual features. The GRU network is an advanced type of RNN and similar to LSTM [
50]. It is easier and less complex to train than the LSTM network, which can help to increase the training efficiency. It has only two ports: an update port and a reset port. The function of the update port is the same as that of the LSTM networks forget port and input port, which make decisions on deleted information and newly stored information, respectively. The reset port decides how to combine the previous information with the newly stored information and determines the degree to which past information will be forgotten [
51].
For time step
, the input feature sequence of
-th utterance
(where
is the feature vector of the utterance) is encoded into forward
and backward
hidden states. Then, the two hidden states are used together at the same time and the output
is jointly calculated by them sequentially, making the result more robust. The formula for the calculation is as follows:
where
and
are the weight matrix form of the forward and backward directions of the
GRU layer and
and
are the bias of the forward and backward directions of the
GRU layer, respectively. Compared with the LSTM network, the number of parameters, the complexity of the GRU model, and the experimental costs are reduced [
50].
In addition, combinations of CNN and LSTM models were proposed by Trigeorgis et al. [
35] to solve the problem of extracting context-aware emotion-related features and obtain a better representation from the raw audio signal. They did not use any hand-crafted features, such as linear prediction coefficients and MFCCs. The CNN and LSTM network combination has received a great deal of attention compared with the FCN network for various tasks. Similarly, Tzirakis et al. [
52] used CNN and LSTM networks to capture the spatial and temporal features of audio data.
Furthermore, the attention mechanism is often used with deep neural networks. Chorowski et al. [
53] first proposed a sample attention mechanism for speech recognition. Recurrent neural networks and attention mechanism approaches have made outstanding achievements in emotion recognition and allowed us to focus on obtaining more emotional information [
54]. Rajamani et al. [
55] adopted a new approach using an attention-mechanism-based Bi-GRU model to learn contextual information and affective influences from previous utterances to help recognize the current utterance’s emotion. The authors used low-level descriptor (LLD) features such as MFCCs, the pitch, and statistics. Zhao et al. [
56] proposed a method that can automatically learn spatiotemporal representations of speech signals. However, the self-attention mechanism has distinct advantages over the attention mechanism [
57]. It can determine the different weights in the frame with different emotional intensities and the autocorrelation between frames [
58]. The self-attention mechanism is an upgraded version of the attention mechanism. The formula for the attention algorithm is as follows:
In Equation (4), and denote the queries, keys, and values of the input matrix, and the dimension of the keys is denoted. When it is a self-attention process. Self-attention models can learn semantic information, such as word dependencies in sentences, more easily.
Although CNNs have provided extremely successful results in the computer vision field and signal classification, they have some limitations [
59]. Recently, capsule networks (CapNets) have been proposed to overcome the drawback of CNNs in capturing spatial information. CNNs cannot learn the relationship between the parts of an object and the positions of objects in an image. Additionally, traditional CNNs will lose some semantic information during the forward propagation of the pooling layer, making it difficult to identify the spatial relationship. To overcome these issues, Hinton et al. built capsule networks to maintain the positions of objects within the image and model the spatial relationships of the object’s properties [
30]. A capsule contains a couple of neurons and is conveyed in the form of vectors. The vector’s length exhibits the probability of the activity described by the capsule and also captures the internal representation parameters of the activity. The capsule and a squashing function are used to obtain the vector form of each capsule. The output of the capsule
is defined as
for each time step
.
where the input to the capsule
is
and the squashing function is
. The squashing function is represented as
Here, all inputs of the capsule
are the weighted summation of the prediction vector, represented as
, except for the first capsule layer. The prediction vector is calculated by the lower layer of the capsule, which is multiplied by a weight matrix
, and the output of the capsule
. Then, the impact of the perspective is modeled by matrix multiplication.
where
clk defines the coupling coefficients, which are calculated by the routing softmax function as expressed in Equation (8).
Wu et al. [
32] implemented a new approach using a capsule network for SER tasks. The authors use spectrograms as the inputs of their model. The capsules are used to minimize the information loss in feature representation and retain more emotional information, which are important in SER tasks. In 2019, Jalal et al. [
60] implemented a hybrid model based on BLSTM, a 1D Conv-Cap, and capsule routing layers for SER. Ng and Liu [
61] used a capsule-network-based model to encode spatial information from speech spectrograms and analyze the performance under various loss functions on several datasets.
Moreover, fusion strategies are used to fuse the different types of features to make a decision on the classification of different modeling methods and reach a more sensible conclusion. Su et al. [
62] developed a model with frame-level acoustic features using an RNN network and an SVM model with HSFs as inputs. The confidence score was determined using the probabilities of the RNN and SVM models. The confidence scores of these two models were averaged for the final classification of each class as the fusion confidence score. Yao et al. [
21] used the decision-level fusion method after obtaining the outputs from three classifiers (HSF-DNN, MS-CNN, and LLD-RNN) for final class prediction.
Considering the limited number of speech samples, we also adopted a decision-level fusion method in this study to fulfill the goal of developing a high-performance SER system. We developed a new approach for SER tasks to efficiently process emotional information through the Conv-Cap and Bi-GRU modules from speech features. After that, we used the self-attention layer in each module to explore the autocorrelation of phonemes between the features. In addition, due to the limited amount of data, we simultaneously applied different learning strategies to manage and classify emotional states. Finally, we integrated a confidence-based fusion approach with the probability score of two models to identify the final emotional state. To the best of our knowledge, this is the first time the proposed framework has been implemented in emotion recognition, and we demonstrate that it is more efficient than other state-of-the-art methods.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}