
A Graph Attention Mechanism-Based Multiagent Reinforcement-Learning Method for Task Scheduling in Edge Computing


Abstract
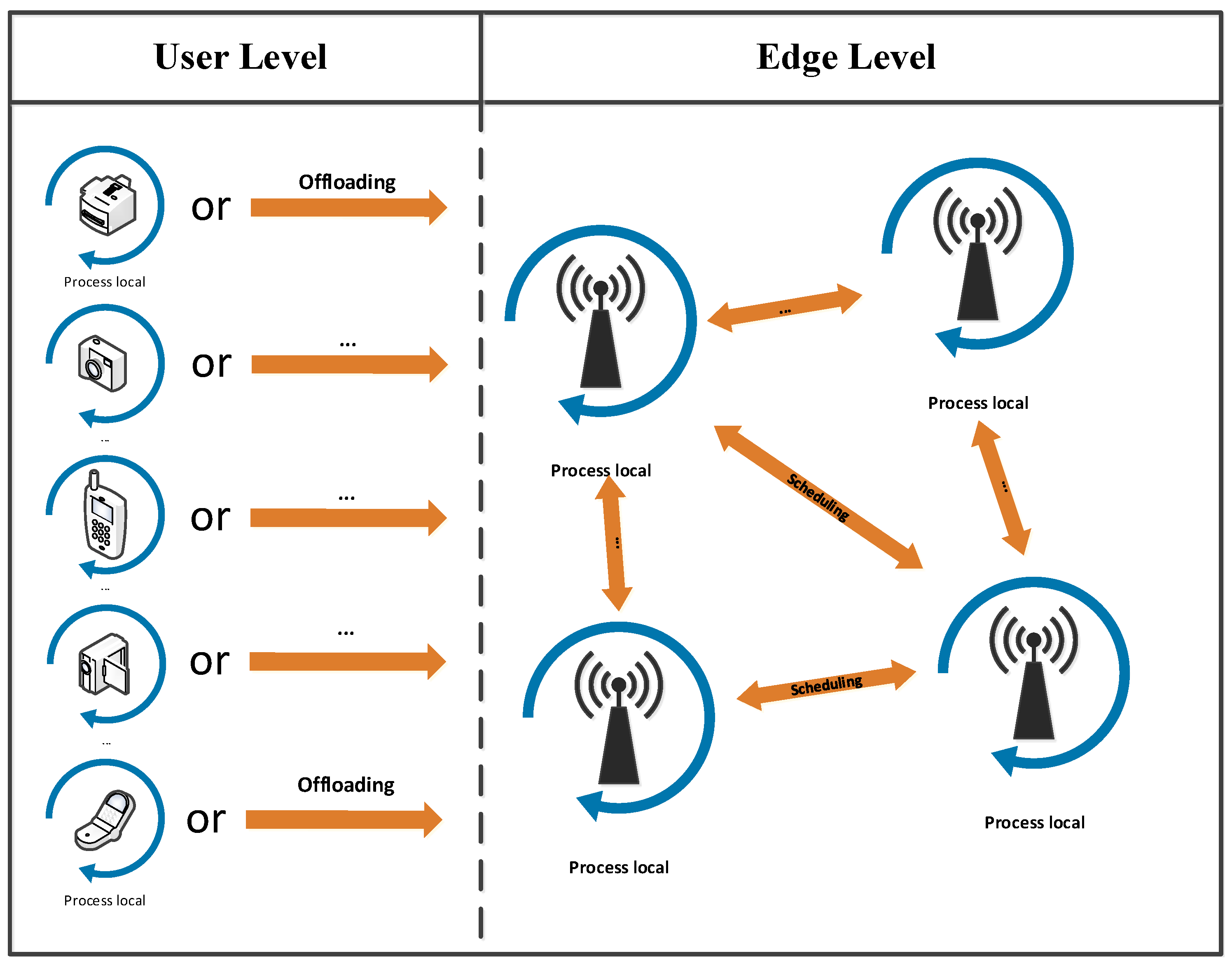
:1. Introduction
- Multitask-offloading problems in MEC scenariosWe formally present the problem of delayed indivisible task offloading in MEC, and then we study and formulate the collaborative computing scheduling problem in terms of both processing time and bandwidth utilization. The main objectives are to minimize the long-term consumption of tasks (dropout rate due to latency and timeouts) and to efficiently schedule tasks according to latency requirements. In our considerations, the MEC distributed scheduling algorithm should consider not only the state information of individual nodes but also the interrelationships that exist between the individual nodes from a global perspective. In addition, the devices in this scenario can generate multiple tasks rather than a single-task problem.
- DRL-based offloading algorithm based on an edge GAT (E-GAT)Two reinforcement learning agents, the graph representation agent and the scheduling agent, are constructed in our proposed multiagent distributed scheduling algorithm with a GAT, and the task scheduling decisions are collaboratively optimized by the two agents. On the one hand, the proposed algorithm can effectively make good use of the potential spatial features contained in the scenario; on the other hand, the algorithm can make effective task-scheduling decisions by learning historical information.
- Dealing with large-scale discrete action spacesAn analysis of the results of simulation experiments validates that our proposed algorithm has a better performance in dealing with large-scale discrete action space problem scenarios than algorithms such as the Wolpertinger architecture proposed by Google [15], and exhibits better generalization in terms of dealing with single-task scenarios.
2. Related Work
3. System Model and Problem Formulation
3.1. Mobile Device Node
3.2. Edge Server
3.2.1. Computation Queue
3.2.2. Transmission Queue
3.3. Problem Formulation in the Multitask MEC Scenario
4. Multiagent Cooperation
4.1. Graph Representation Agent
4.1.1. State
4.1.2. Action
4.1.3. Reward
4.2. Scheduling Agent
| Algorithm 1 Data Processing in Network |
|
4.2.1. State
4.2.2. Action
4.2.3. Reward
5. Graph Attention Mechanism-Based Task-Scheduling Algorithm
5.1. Model Architecture
5.2. Scheduling Algorithm for MEC
| Algorithm 2 GNN-Based DRL Algorithm for |
|
6. Performance Evaluation
7. Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| U | CPU utilization |
| Bandwidth use of link | |
| P | Time point of task processing |
| T | Current time slice |
| Q | Number of active queues |
| H | Node load level of edge layer |
| E | Task information |
| Task size | |
| Time taken to complete task processing | |
| x | Whether the task is scheduled |
| y | Task-scheduling target node index |
| g | Bits remaining in the queue |
| Maximum task lifetime | |
| Task-processing density | |
| r | Task transfer rate |
References
- Taleb, T.; Samdanis, K.; Mada, B.; Flinck, H.; Dutta, S.; Sabella, D. On Multi-Access Edge Computing: A Survey of the Emerging 5G Network Edge Cloud Architecture and Orchestration. IEEE Commun. Surv. Tutor. 2017, 19, 1657–1681. [Google Scholar] [CrossRef] [Green Version]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutorials 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Zhao, F.; Chen, Y.; Zhang, Y.; Liu, Z.; Chen, X. Dynamic Offloading and Resource Scheduling for Mobile Edge Computing With Energy Harvesting Devices. IEEE Trans. Netw. Serv. Manag. 2021, 18, 2154–2165. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Letaief, K.B. Dynamic Computation Offloading for Mobile-Edge Computing With Energy Harvesting Devices. IEEE J. Sel. Areas Commun. 2016, 34, 3590–3605. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Yao, H.; Wang, J.; Jiang, C.; Liu, Y. Multi-UAV Enabled Load-Balance Mobile Edge Computing for IoT Networks (IEEE IoT Journal). IEEE Internet Things J. 2020, 7, 6898–6908. [Google Scholar] [CrossRef]
- Zhang, K.; Hu, Y.; Tian, F.; Li, C. A Coalition-Structure’s Generation Method for Solving Cooperative Computing Problems in Edge Computing Environments. Inf. Sci. 2020, 536, 372–390. [Google Scholar] [CrossRef]
- Zhu, K.; Zhang, T. Deep Reinforcement Learning Based Mobile Robot Navigation:A Review. Tsinghua Sci. Technol. 2021, 26, 18. [Google Scholar] [CrossRef]
- Xu, Y.; Cheng, P.; Chen, Z.; Ding, M.; Li, Y.; Vucetic, B. Task Offloading for Large-Scale Asynchronous Mobile Edge Computing: An Index Policy Approach. IEEE Trans. Signal Process. 2021, 69, 401–416. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, H.; Wu, C.; Mao, S.; Ji, Y.; Bennis, M. Optimized Computation Offloading Performance in Virtual Edge Computing Systems via Deep Reinforcement Learning. IEEE Internet Things J. 2018, 6, 4005–4018. [Google Scholar] [CrossRef] [Green Version]
- Zhu, T.; Shi, T.; Li, J.; Cai, Z.; Zhou, X. Task Scheduling in Deadline-Aware Mobile Edge Computing Systems. IEEE Internet Things J. 2018, 6, 4854–4866. [Google Scholar] [CrossRef]
- Xu, X.; Li, H.; Xu, W.; Liu, Z.; Yao, L.; Dai, F. Artificial intelligence for edge service optimization in Internet of Vehicles: A survey. Tsinghua Sci. Technol. 2022, 22, 270–287. [Google Scholar] [CrossRef]
- Cai, Z.; Zheng, X. A Private and Efficient Mechanism for Data Uploading in Smart Cyber-Physical Systems. IEEE Trans. Netw. Sci. Eng. 2020, 7, 766–775. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, X.; Xia, J.; Fan, L. Deep Reinforcement Learning Based Mobile Edge Computing for Intelligent Internet of Things. Phys. Commun. 2020, 43, 101184. [Google Scholar] [CrossRef]
- Zhan, Y.; Guo, S.; Li, P.; Zhang, J. A Deep Reinforcement Learning Based Offloading Game in Edge Computing. IEEE Trans. Comput. 2020, 69, 883–893. [Google Scholar] [CrossRef]
- Dulac-Arnold, G.; Evans, R.; Hasselt, H.V.; Sunehag, P.; Lillicrap, T.; Hunt, J.; Mann, T.; Weber, T.; DeGris, T.; Coppin, B. Deep Reinforcement Learning in Large Discrete Action Spaces. arXiv 2015, arXiv:1512.07679. [Google Scholar]
- Velikovi, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. Stat 2017, 1050, 20. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Porambage, P.; Okwuibe, J.; Liyanage, M.; Ylianttila, M.; Taleb, T. Survey on Multi-Access Edge Computing for Internet of Things Realization. IEEE Commun. Surv. Tutor. 2018, 20, 2961–2991. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Yu, H.; Xie, S.; Zhang, Y. Deep Reinforcement Learning for Offloading and Resource Allocation in Vehicle Edge Computing and Networks. IEEE Trans. Veh. Technol. 2019, 68, 11158–11168. [Google Scholar] [CrossRef]
- Wang, C.; Liang, C.; Yu, F.R.; Chen, Q.; Lun, T. Computation Offloading and Resource Allocation in Wireless Cellular Networks With Mobile Edge Computing. IEEE Trans. Wirel. Commun. 2017, 16, 4924–4938. [Google Scholar] [CrossRef]
- Wang, Y.; Min, S.; Wang, X.; Liang, W.; Li, J. Mobile-Edge Computing: Partial Computation Offloading Using Dynamic Voltage Scaling. IEEE Trans. Commun. 2016, 64, 4268–4282. [Google Scholar] [CrossRef]
- Sun, J.; Yin, L.; Zou, M.; Zhang, Y.; Zhou, J. Makespan-Minimization Workflow Scheduling for Complex Networks with Social Groups in Edge Computing. J. Syst. Archit. 2020, 108, 101799. [Google Scholar] [CrossRef]
- Meng, J.; Tan, H.; Li, X.Y.; Han, Z.; Li, B. Online Deadline-Aware Task Dispatching and Scheduling in Edge Computing. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1270–1286. [Google Scholar] [CrossRef]
- Han, Z.; Tan, H.; Li, X.Y.; Jiang, H.C.; Lau, F. OnDisc: Online Latency-Sensitive Job Dispatching and Scheduling in Heterogeneous Edge-Clouds. IEEE/ACM Trans. Netw. 2019, 27, 2472–2485. [Google Scholar] [CrossRef]
- Bi, S.; Zhang, Y.J. Computation Rate Maximization for Wireless Powered Mobile-Edge Computing with Binary Computation Offloading. IEEE Trans. Wirel. Commun. 2017, 17, 4177–4190. [Google Scholar] [CrossRef] [Green Version]
- Poularakis, K.; Llorca, J.; Tulino, A.M.; Taylor, I.; Tassiulas, L. Joint Service Placement and Request Routing in Multi-cell Mobile Edge Computing Networks. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019. [Google Scholar]
- Joilo, S.; Dán, G. Wireless and Computing Resource Allocation for Selfish Computation Offloading in Edge Computing. In Proceedings of the IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019. [Google Scholar]
- Neto, J.; Yu, S.Y.; Macedo, D.F.; Nogueira, J.M.S.; Langar, R.; Secci, S. ULOOF: A User Level Online Offloading Framework for Mobile Edge Computing. IEEE Trans. Mob. Comput. 2018, 17, 2660–2674. [Google Scholar] [CrossRef] [Green Version]
- Lee, G.; Saad, W.; Bennis, M. An Online Optimization Framework for Distributed Fog Network Formation with Minimal Latency. IEEE Trans. Wirel. Commun. 2017, 18, 2244–2258. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Zhang, H.; Xi, L.; Hong, J.; Leung, V. A Distributed Computation Offloading Strategy in Small-Cell Networks Integrated With Mobile Edge Computing. IEEE/ACM Trans. Netw. 2018, 26, 2762–2773. [Google Scholar] [CrossRef]
- Xu, J.; Chen, L.; Zhou, P. Joint Service Caching and Task Offloading for Mobile Edge Computing in Dense Networks. In Proceedings of the IEEE Infocom—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018. [Google Scholar]
- Yan, J.; Bi, S.; Zhang, Y. Offloading and Resource Allocation with General Task Graph in Mobile Edge Computing: A Deep Reinforcement Learning Approach. IEEE Trans. Wirel. Commun. 2020, 19, 5404–5419. [Google Scholar] [CrossRef]
- Huang, L.; Bi, S.; Zhang, Y. Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks. IEEE Trans. Mob. Comput. 2018, 19, 2581–2593. [Google Scholar] [CrossRef] [Green Version]
- Tang, M.; Wong, V. Deep Reinforcement Learning for Task Offloading in Mobile Edge Computing Systems. arXiv 2020, arXiv:2005.02459. [Google Scholar] [CrossRef]
- Xiang, S.; Ansari, N. Avaptive Avatar Handoff in the Cloudlet Network. IEEE Trans. Cloud Comput. 2017, 7, 664–676. [Google Scholar]
- Borcea, C.; Ding, X.; Gehani, N.; Curtmola, R.; Debnath, H. Avatar: Mobile Distributed Computing in the Cloud. In Proceedings of the IEEE International Conference on Mobile Cloud Computing, San Francisco, CA, USA, 30 March–3 April 2015. [Google Scholar]
- Kogias, M.; Mallon, S.; Bugnion, E. Lancet: A Self-Correcting Latency Measuring Tool; USENIX ASSOC: Berkeley, CA, USA, 2019; pp. 881–895. [Google Scholar]
- Lv, Z.; Li, J.; Dong, C.; Li, H.; Xu, Z. Deep learning in the COVID-19 epidemic: A deep model for urban traffic revitalization index. Data Knowl. Eng. 2021, 135, 101912. [Google Scholar] [CrossRef]
- Lv, Z.; Li, J.; Dong, C.; Xu, Z. DeepSTF: A Deep Spatial–Temporal Forecast Model of Taxi Flow. Comput. J. 2021, bxab178. [Google Scholar] [CrossRef]
- Xu, Z.; Lv, Z.; Li, J.; Sun, H.; Sheng, Z. A Novel Perspective on Travel Demand Prediction Considering Natural Environmental and Socioeconomic Factors. IEEE Intell. Transp. Syst. Mag. 2022, 2–25. [Google Scholar] [CrossRef]
- Chen, J.; Chen, H. Edge-Featured Graph Attention Network. arXiv 2021, arXiv:2101.07671. [Google Scholar]
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| 2.5 GHz [28] | |
| 41.8 GHz [28] | |
| Mobile end device core C | 4 |
| 3.0, 3.1, ..., 10.0 Mbits [20] | |
| 14 Mbits [34] | |
| 41.8 Mbits | |
| 0.297 gigacycles per Mbits [20] | |
| 0.297 gigacycles per Mbits [20] | |
| 100 time slots (10 s) | |
| Task arrival probability | 0.3 |
| Type | Average Delay (s) | Dropout Rate (Proportion) | Bandwidth Use (Proportion) | Inference Time (s) |
|---|---|---|---|---|
| Our Algorithm_4task | 6.80393 | 0.1185 | 0.04022 | 3.6 × 10 |
| Without GAT_4task | 6.87792 | 0.11982 | 0.04072 | 2.8 × 10 |
| Random_4task | 8.75488 | 0.15914 | 0.03814 | - |
| Wolpertinger_4task | 7.81175 | 0.15914 | 0.04017 | 2.6 × 10 |
| No Scheduling_4task | 9.28424 | 0.2193 | 0 | - |
| Our Algorithm_1task | 1.70151 | 0 | 0.05606 | 1.6 × 10 |
| Without GAT_1task | 1.7196 | 1.15 × 10 | 0.05536 | 9.3 × 10 |
| DRL_1task | 1.65309 | 0 | 0.05618 | 6.3 × 10 |
| Random_1task | 5.74319 | 0.09053 | 0.06026 | - |
| No Scheduling_1task | 7.40783 | 0.08449 | 0 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Li, J.; Pang, J. A Graph Attention Mechanism-Based Multiagent Reinforcement-Learning Method for Task Scheduling in Edge Computing. Electronics 2022, 11, 1357. https://doi.org/10.3390/electronics11091357
Li Y, Li J, Pang J. A Graph Attention Mechanism-Based Multiagent Reinforcement-Learning Method for Task Scheduling in Edge Computing. Electronics. 2022; 11(9):1357. https://doi.org/10.3390/electronics11091357
Chicago/Turabian StyleLi, Yinong, Jianbo Li, and Junjie Pang. 2022. "A Graph Attention Mechanism-Based Multiagent Reinforcement-Learning Method for Task Scheduling in Edge Computing" Electronics 11, no. 9: 1357. https://doi.org/10.3390/electronics11091357
APA StyleLi, Y., Li, J., & Pang, J. (2022). A Graph Attention Mechanism-Based Multiagent Reinforcement-Learning Method for Task Scheduling in Edge Computing. Electronics, 11(9), 1357. https://doi.org/10.3390/electronics11091357