
Enhancing Communication Reliability from the Semantic Level under Low SNR


Abstract
:1. Introduction
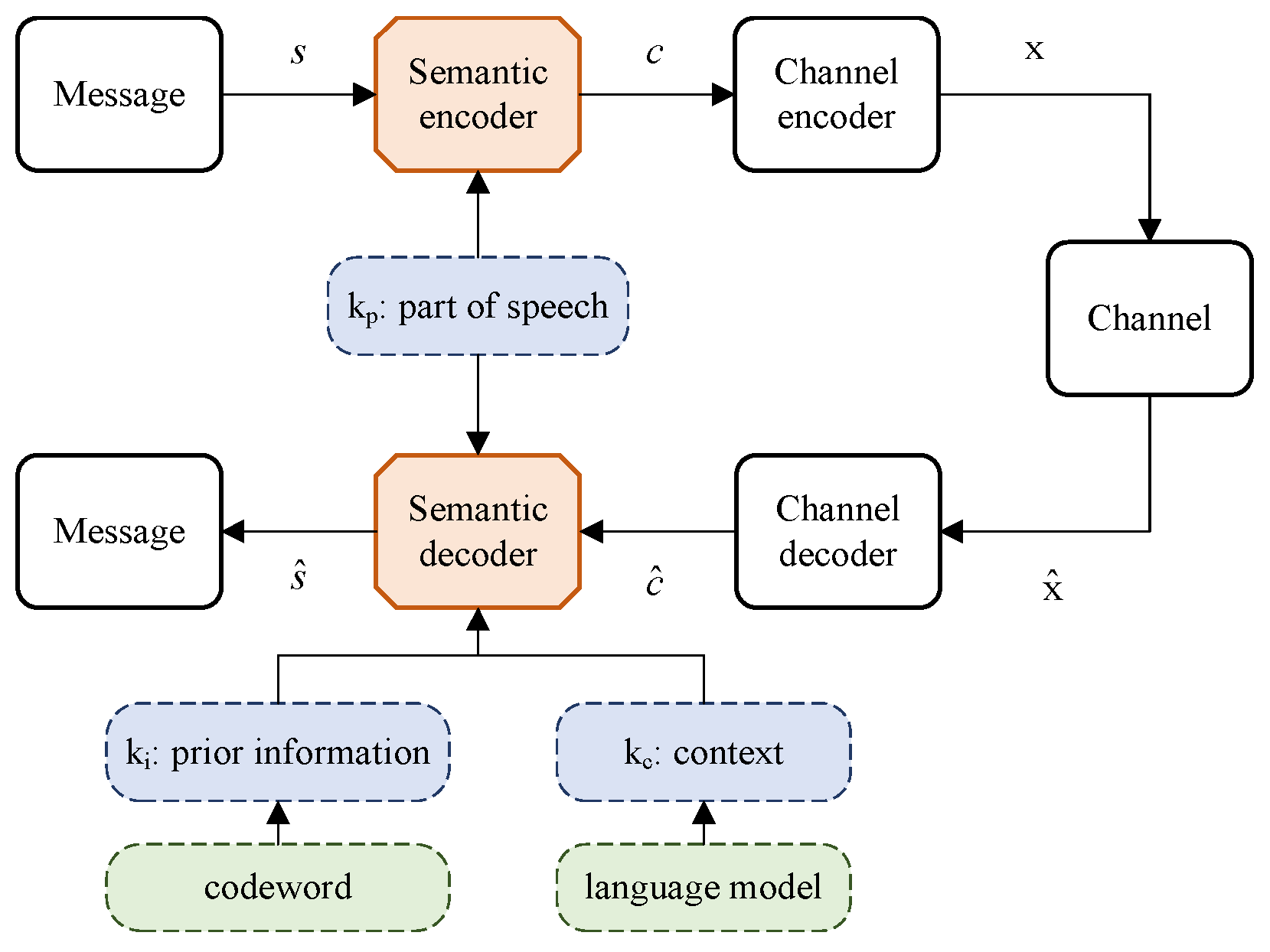
- A part-of-speech-based encoding strategy is proposed. The encoding process tries to add some check information about the semantic features to assist the decoding process at the receiver.
- A context-based decoding strategy for recovering messages is proposed, in which the language model is employed to extract the contextual correlation between items, thereby enhancing the semantic reasoning ability of the receiver. Moreover, the prior information concerning the codewords is utilized to improve the semantic accuracy of the recovered messages.
- Semantic metrics of text such as BLUE, the METEOR score, and the similarity score based on BERT are employed to measure the semantic error. Based on the simulation results, the proposed model outperforms the traditional communication system in the low signal-to-noise ratio (SNR) regime.
2. System Model and Problem Formulation
2.1. System Model
2.2. Performance Metrics
3. Encoding and Decoding Strategy
3.1. Encoding Strategy
| Algorithm 1 Part-of-speech-based encoding method |
| Input: a text corpus; Output: codeword dictionary;
|
3.2. Decoding Strategy
| Algorithm 2 Context- and prior-information-based decoding method |
| Input: codeword dictionary , received codewords ; Parameter: number of bit-flipping N; Output: the optimal sequence;
|
4. Simulation Results
4.1. Parameter Setup
4.2. Performance Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Technol. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Bao, J.; Basu, P.; Dean, M.; Partridge, C.; Swami, A.; Leland, W.; Hendler, J.A. Towards a theory of semantic communication. In Proceedings of the IEEE Network Science Workshop, West Point, NY, USA, 22–24 June 2011; pp. 110–117. [Google Scholar]
- Weaver, W. Recent contributions to the mathematical theory of communication. ETC A Rev. Gen. Semant. 1953, 10, 261–281. [Google Scholar]
- Lan, Q.; Wen, D.; Zhang, Z.; Zeng, Q.; Chen, X.; Popovski, P.; Huang, K. What is semantic communication? A view on conveying meaning in the era of machine intelligence. arXiv 2021, arXiv:2110.00196. [Google Scholar]
- Qin, Z.; Tao, X.; Lu, J.; Li, G.Y. Semantic communications: Principles and challenges. arXiv 2021, arXiv:2201.01389. [Google Scholar]
- Carnap, R.; Bar-Hillel, Y. An outline of a theory of semantic information. J. Symb. Logic 1954, 19, 230–232. [Google Scholar]
- Bar-Hillel, Y.; Carnap, R. Semantic information. Br. J. Philos. Sci. 1953, 4, 147–157. [Google Scholar] [CrossRef]
- Barwise, J.; Perry, J. Situations and attitudes. J. Philos. 1981, 78, 668–691. [Google Scholar] [CrossRef]
- Floridi, L. Outline of a theory of strongly semantic information. Minds Mach. 2004, 14, 197–221. [Google Scholar] [CrossRef] [Green Version]
- Basu, P.; Bao, J.; Dean, M.; Hendler, J. Preserving quality of information by using semantic relationships. In Proceedings of the 2012 IEEE International Conference on Pervasive Computing and Communications Workshops, Lugano, Switzerland, 19–23 March 2012. [Google Scholar]
- Güler, B.; Yener, A.; Swami, A. The semantic communication game. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 787–802. [Google Scholar] [CrossRef]
- Farsad, N.; Rao, M.; Goldsmith, A. Deep learning for joint source–channel coding of text. In Proceedings of the 2018 IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Rao, M.; Farsad, N.; Goldsmith, A. Variable length joint source–channel coding of text using deep neural networks. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018. [Google Scholar]
- Bourtsoulatze, E.; Kurka, D.B.; Gündüz, D. Deep joint source–channel coding for wireless image transmission. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 567–579. [Google Scholar] [CrossRef] [Green Version]
- Kurka, D.B.; Gündüz, D. DeepJSCC-f: Deep joint source–channel coding of images with feedback. IEEE J. Sel. Areas Commun. 2020, 1, 178–193. [Google Scholar] [CrossRef] [Green Version]
- Kurka, D.B.; Gündüz, D. Bandwidth-Agile image transmission with deep joint source–channel coding. IEEE Trans. Wirel. Commun 2021, 20, 8081–8095. [Google Scholar] [CrossRef]
- Jankowski, M.; Gündüz, D.; Mikolajczyk, K. Wireless image retrieval at the edge. IEEE J. Sel. Areas Commun. 2021, 39, 89–100. [Google Scholar] [CrossRef]
- Xie, H.; Qin, Z.; Li, G.Y.; Juang, B.-H. Deep learning enabled semantic communication systems. IEEE Trans. Signal Process. 2021, 69, 2663–2675. [Google Scholar] [CrossRef]
- Xie, H.; Qin, Z. A lite distributed semantic communication system for Internet of Things. IEEE J. Sel. Areas Commun. 2021, 39, 142–153. [Google Scholar] [CrossRef]
- Weng, Z.; Qin, Z. Semantic communication systems for speech transmission. IEEE J. Sel. Areas Commun. 2021, 39, 2434–2444. [Google Scholar] [CrossRef]
- Hu, Q.; Zhang, G.; Qin, Z.; Cai, Y.; Yu, G. Robust semantic communications against semantic noise. arXiv 2022, arXiv:2202.03338v1. [Google Scholar]
- Xie, H.; Qin, Z.; Li, G.Y. Task-oriented multi-user semantic communications for VQA. IEEE Wirel. Commun. Lett. 2022, 11, 553–557. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, P.; Wei, J. Semantic communication for intelligent devices: Architectures and a paradigm. Sci. Sin. Inform. 2021. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, M.; Saad, W.; Luo, T.; Cui, S.; Poor, H.V. Performance optimization for semantic communications: An attention-based learning approach. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005. [Google Scholar]
- Available online: https://pypi.org/project/semantic-text-similarity/ (accessed on 14 March 2022).
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the Joint Conference of the International Committee on Computational Linguistics and the Association for Computational Linguistics (COLING/ACL) on Interactive Presentation Sessions, Sydney, Australia, 17–18 July 2006. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Stroudsburg, PA, USA, 2–7 June 2019. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Number of Attention Heads | The Number of Layers | Hidden Size | Parameters |
|---|---|---|---|
| 12 | 12 | 768 | 110 M |
| Methods | Huffman + LDPC | Tradition + Language | Proposed Model |
|---|---|---|---|
| Time complexity/s | 4.8561 | 7.7494 | 8.2832 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhang, Y.; Luo, P.; Jiang, S.; Cao, K.; Zhao, H.; Wei, J. Enhancing Communication Reliability from the Semantic Level under Low SNR. Electronics 2022, 11, 1358. https://doi.org/10.3390/electronics11091358
Liu Y, Zhang Y, Luo P, Jiang S, Cao K, Zhao H, Wei J. Enhancing Communication Reliability from the Semantic Level under Low SNR. Electronics. 2022; 11(9):1358. https://doi.org/10.3390/electronics11091358
Chicago/Turabian StyleLiu, Yueling, Yichi Zhang, Peng Luo, Shengteng Jiang, Kuo Cao, Haitao Zhao, and Jibo Wei. 2022. "Enhancing Communication Reliability from the Semantic Level under Low SNR" Electronics 11, no. 9: 1358. https://doi.org/10.3390/electronics11091358
APA StyleLiu, Y., Zhang, Y., Luo, P., Jiang, S., Cao, K., Zhao, H., & Wei, J. (2022). Enhancing Communication Reliability from the Semantic Level under Low SNR. Electronics, 11(9), 1358. https://doi.org/10.3390/electronics11091358