
Conservative but Stable: A SARSA-Based Algorithm for Random Pulse Jamming in the Time Domain

Abstract
:1. Introduction
1.1. Related Works
1.2. Contribution and Structure
- This paper uses the SARSA-based algorithm to counter random pulse jamming in the time domain, filling the gap in the literature on the use of the SARSA-based algorithm in anti-jamming strategies in the time domain.
- The proposed algorithm improves the robustness in countering random pulse jamming in the time domain and can achieve high-quality transmission while maintaining small fluctuations in transmission performance when the risk of external interference is high.
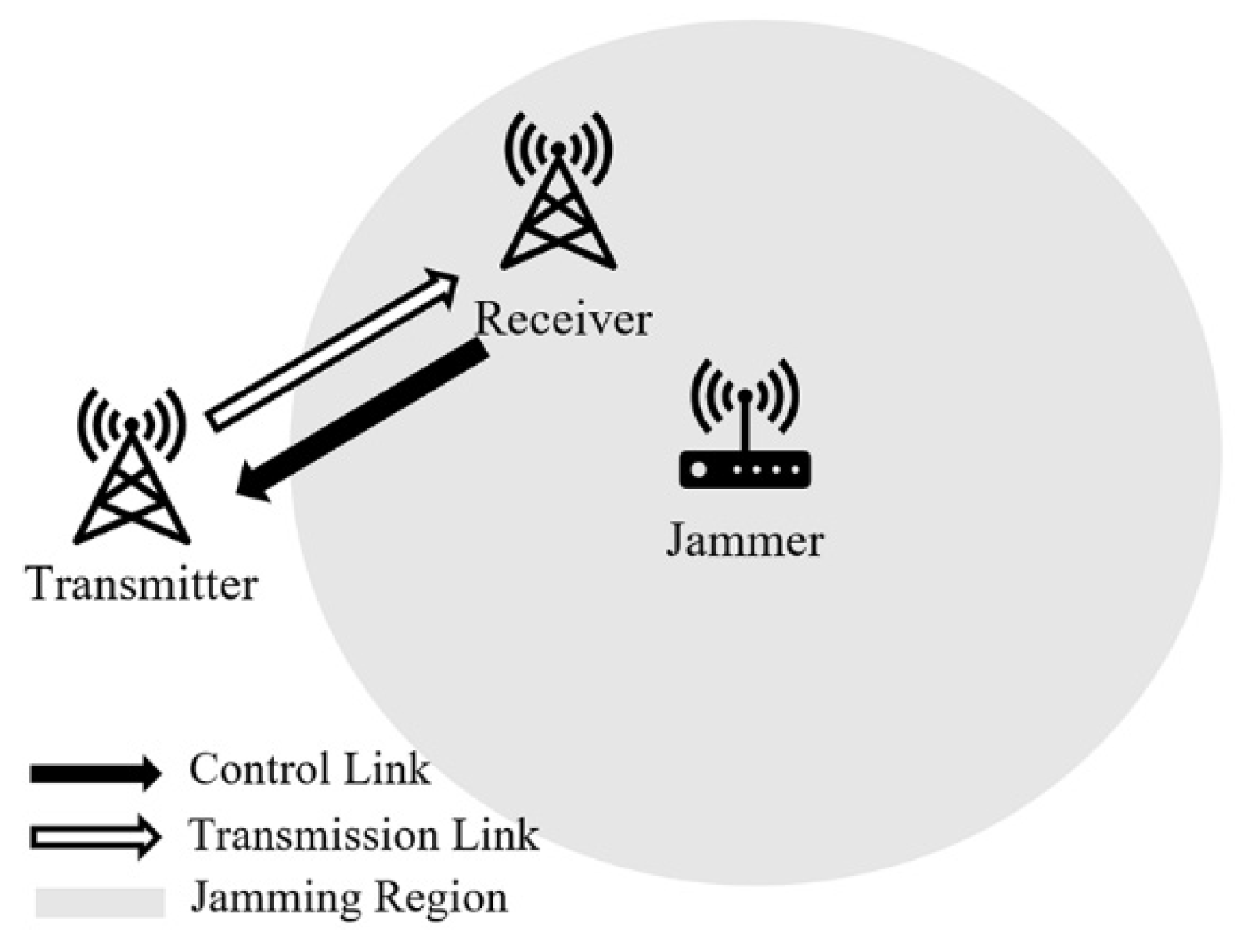
2. System Model and Problem Formulation
2.1. System Model
- Transmission period: we assume that the time slot with a length of is the smallest unit of continuous transmission. A complete transmission period is composed of continuous time slots. This paper assumes that there are time slots, equivalent to periods.
- Jammer: we assume that the jammer grasps the information of the transmitter, such as the possible frequency of communication, the width of the time slot, and the transmission period of the wireless communication system, in advance through reconnaissance. The random pulse jamming signal is able to cover the channel of communication completely, and the duration of a single pulse is equal to the length of the communication time slot .
- Jamming period: in this paper, the jammer is assumed to set the interference period to be the same as and synchronous with the communication transmission period. It consists of time slots in one period, in which the jammer selects time slot to conduct jamming according to a specific probability distribution. The discrete probability density function is defined as , and the probability of jamming in the period can be expressed as follows:where represents the slot number in one jamming period, and represents the probability that the jammer selects the time slot in the period to conduct pulse jamming.
2.2. Problem Formulation
- 1.
- : The state space is defined as follows:
- 2.
- : The action space is defined as follows:
- 3.
- : , whose definition is the probability of transitioning from state to state by executing action . Figure 2b shows the state transition of the system, where is the probability of the timeslot selection in Equation (1). For instance, the current state of the timeslot is , and the transmitter performs an action that is required; afterwards, the external environment transitions into the next state . The next sequence number can be expressed as follows:
- 4.
- : The immediate reward function is that the transmitter takes action in state to obtain immediate benefits from environmental feedback. According to different states and actions, the following four types of instant reward R in specific scenes are distinguished, and the definition formula is as follows:
- If , , and , there is no pulse jamming signal in this interference period and the transmitter conducts the transmission successfully and reaps rewards from the system.
- If , , and , in this timeslot, a pulse jamming signal appears and the transmitter insists on the transmission, which will be a failure, leading to the loss from the system.
- If , , and , according to the principle of ‘One period, One pulse’, there will not be a pulse jamming signal in this single period, so the transmitter will perform the transmission successfully and gain the reward .
- If , the transmitter remains silent no matter the external environment, and there will be neither a reward nor a loss.
- 5.
- The structure of the timeslot:
- : the transmitter conducts the action that was decided in the last .
- : the transmitter observes the external environment and senses whether there is a pulse jamming signal right now.
- : after updating the Q table, the policy of the next time slot is obtained and transmitted back to the transmitter.
3. SARSA-Based Time-Domain Anti-Jamming Algorithm
| Algorthm 1: STAA |
| Initialize,,,, |
| The transmitter performs and calculates and in sub-slot |
| The receiver senses the presence of pulse jamming in sub-slot |
| The receiver deduces the next action according to the update criterion in and the |
| rule is as follows |
|
|
| The receiver updates the Q value according to the above formula. |
| The receiver generates the new strategy |
| The receiver sends the strategy () of the next time slot to the transmitter |
| Outputs |
4. Simulation Result and Analysis
4.1. Parameter Settings
- Continuous Transmission (CT): the transmitter continues to send data to the receiver without taking any anti-interference measures;
- The Time Domain anti-jamming Algorithm (TDAA) based on Q-learning: the anti-jamming algorithm based on Q-learning is used by the transmitter to cope with external interference and realize data communication with the receiver. For a detailed description of the algorithm, see [11].
- Final Collision Rate of Jamming (FCRJ). Firstly, we define the collision rate of jamming , where , which is used to describe the change in the collision probability of transmission and pulse jamming in each interference period, where represents the number of timeslots that are jammed in the interference period when iterating times. represents the number of iterations that the STAA performed; in this paper, we set it to 1000. Finally, we select the final value of the collision rate of jamming, the so-called FCRJ, at the end of an iteration, which is used to describe the algorithm’s ability to survive when jammed.
- Average Reward in Each Period (AREP). Firstly, we define the cumulative rewards in a single period. . Further, we define the average reward in each period, where , , which is used to describe the algorithm’s transmission ability after the interference period.
- Dynamic Fluctuation Ratio (DFR). To describe the stability during transmission, we define , where , which is used to describe the algorithm’s degree of fluctuation during transmission.
- Velocity of Learning Anti-jamming (VLA). In this paper, we define , where . is the number of pre-stable disturbance periods of dynamic fluctuations, which is used to describe how fast the algorithm learns external disturbances.
4.2. Analysis of Simulation
4.2.1. Basic Analysis of Indicators
4.2.2. Risk–Return Ratio
4.2.3. Simulation under Different Conditions
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sampath, A.; Hui, D.; Zheng, H.; Zhao, B.Y. Multi-channel Jamming Attacks using Cognitive Radios. In Proceedings of the 2007 16th International Conference on Computer Communications and Networks, Honolulu, HI, USA, 13–16 August 2007. [Google Scholar]
- Lee, J.J.; Lim, J. Effective and Efficient Jamming Based on Routing in Wireless Ad Hoc Network. IEEE Commun. Lett. 2012, 16, 1903–1906. [Google Scholar] [CrossRef]
- Noels, N.; Moeneclaey, M. Performance of advanced telecommand frame synchronizer under pulsed jamming conditions. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017. [Google Scholar]
- Busoniu, L.; Babuska, R.; Schutter, B.D. A Comprehensive Survey of Multiagent Reinforcement Learning. IEEE Trans. Syst. Man Cybern. Part C 2008, 38, 156–172. [Google Scholar] [CrossRef] [Green Version]
- Slimeni, F.; Chtourou, Z.; Scheers, B.; Nir, V.L.; Attia, R. Cooperative Q-learning based channel selection for cognitive radio networks. Wirel. Netw. 2018, 25, 4161–4171. [Google Scholar] [CrossRef]
- Wang, B.; Wu, Y.; Liu, K.J.R.; Clancy, T.C. An Anti-Jamming Stochastic Game for Cognitive Radio Networks. IEEE J. Sel. Areas Commun. 2011, 29, 877–889. [Google Scholar] [CrossRef] [Green Version]
- Xiao, L.; Lu, X.; Xu, D.; Tang, Y.; Wang, L.; Zhuang, W. UAV Relay in VANETs Against Smart Jamming with Rein-forcement Learning. IEEE Trans. Veh. Technol. 2018, 67, 4087–4097. [Google Scholar] [CrossRef]
- Aref, M.A.; Jayaweera, S.K. A cognitive anti-jamming and interference-avoidance stochastic game. In Proceedings of the 2017 IEEE International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), Oxford, UK, 26–28 July 2017. [Google Scholar]
- Machuzak, S.; Jayaweera, S.K. Reinforcement learning based anti-jamming with wide-band autonomous cognitive radios. In Proceedings of the 2016 IEEE/CIC International Conference on Communications in China (ICCC), Chengdu, China, 27–29 July 2016. [Google Scholar]
- Aref, M.A.; Jayaweera, S.K.; Machuzak, S. Multi-Agent Reinforcement Learning Based Cognitive Anti-Jamming. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017. [Google Scholar]
- Zhou, Q.; Li, Y.; Niu, Y. A Countermeasure Against Random Pulse Jamming in Time Domain Based on Reinforcement Learning. IEEE Access 2020, 8, 97164–97174. [Google Scholar] [CrossRef]
- Lilith, N.; Dogancay, K. Dynamic channel allocation for mobile cellular traffic using reduced-state reinforcement learning. In Proceedings of the Wireless Communications & Networking Conference, Atlanta, GA, USA, 21–25 March 2004. [Google Scholar]
- Lilith, N.; Dogancay, K. Distributed reduced-state SARSA algorithm for dynamic channel allocation in cellular networks featuring traffic mobility. In Proceedings of the IEEE International Conference on Communications, Seoul, Korea, 16–20 May 2005. [Google Scholar]
- Wang, W.; Kwasinski, A.; Niyato, D.; Han, Z. A Survey on Applications of Model-Free Strategy Learning in Cognitive Wireless Networks. IEEE Commun. Surv. Tutor. 2016, 18, 1717–1757. [Google Scholar] [CrossRef]
- Lintner, J. The valuation of risk assets and the selection of risky investments in stock portfolios and capital budgets. Stoch. Optim. Models Financ. 1969, 51, 220–221. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| 0.6 ms | |
| 0.5 ms | |
| 0.04 ms | |
| 0.06 ms | |
| 0.8 | |
| 0.6 | |
| 1 | |
| −3 | |
| 10,000 | |
| 10 |
| ω | ALGORITHM | FCRJ (%) | VLA | AREP | |
|---|---|---|---|---|---|
| 1/4 | TDAA | 9.54 | 12.35 | 8.57 | 3.61 |
| STAA | 9.15 | 9.09 | 8.58 | 2.16 | |
| 1/2 | TDAA | 8.52 | 15.38 | 8.35 | 7.43 |
| STAA | 5.27 | 10.42 | 8.40 | 6.25 | |
| 1 | TDAA | 4.38 | 17.86 | 8.10 | 26.20 |
| STAA | 4.76 | 16.13 | 8.12 | 20.01 | |
| 2 | TDAA | 1.59 | 26.32 | 7.81 | 61.72 |
| STAA | 1.84 | 18.52 | 7.78 | 46.85 | |
| 4 | TDAA | 0.69 | 43.48 | 7.28 | 111.33 |
| STAA | 0.78 | 22.73 | 7.25 | 104.66 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Niu, Y.; Chen, C.; Zhou, Q. Conservative but Stable: A SARSA-Based Algorithm for Random Pulse Jamming in the Time Domain. Electronics 2022, 11, 1456. https://doi.org/10.3390/electronics11091456
Chen Y, Niu Y, Chen C, Zhou Q. Conservative but Stable: A SARSA-Based Algorithm for Random Pulse Jamming in the Time Domain. Electronics. 2022; 11(9):1456. https://doi.org/10.3390/electronics11091456
Chicago/Turabian StyleChen, Yuheng, Yingtao Niu, Changxing Chen, and Quan Zhou. 2022. "Conservative but Stable: A SARSA-Based Algorithm for Random Pulse Jamming in the Time Domain" Electronics 11, no. 9: 1456. https://doi.org/10.3390/electronics11091456
APA StyleChen, Y., Niu, Y., Chen, C., & Zhou, Q. (2022). Conservative but Stable: A SARSA-Based Algorithm for Random Pulse Jamming in the Time Domain. Electronics, 11(9), 1456. https://doi.org/10.3390/electronics11091456