
Short-Term Traffic-Flow Forecasting Based on an Integrated Model Combining Bagging and Stacking Considering Weight Coefficient


Abstract
:1. Introduction
- (1)
- Linear model
- (2)
- Non-linear model
2. Establishment of the DW-Ba-Stacking Model
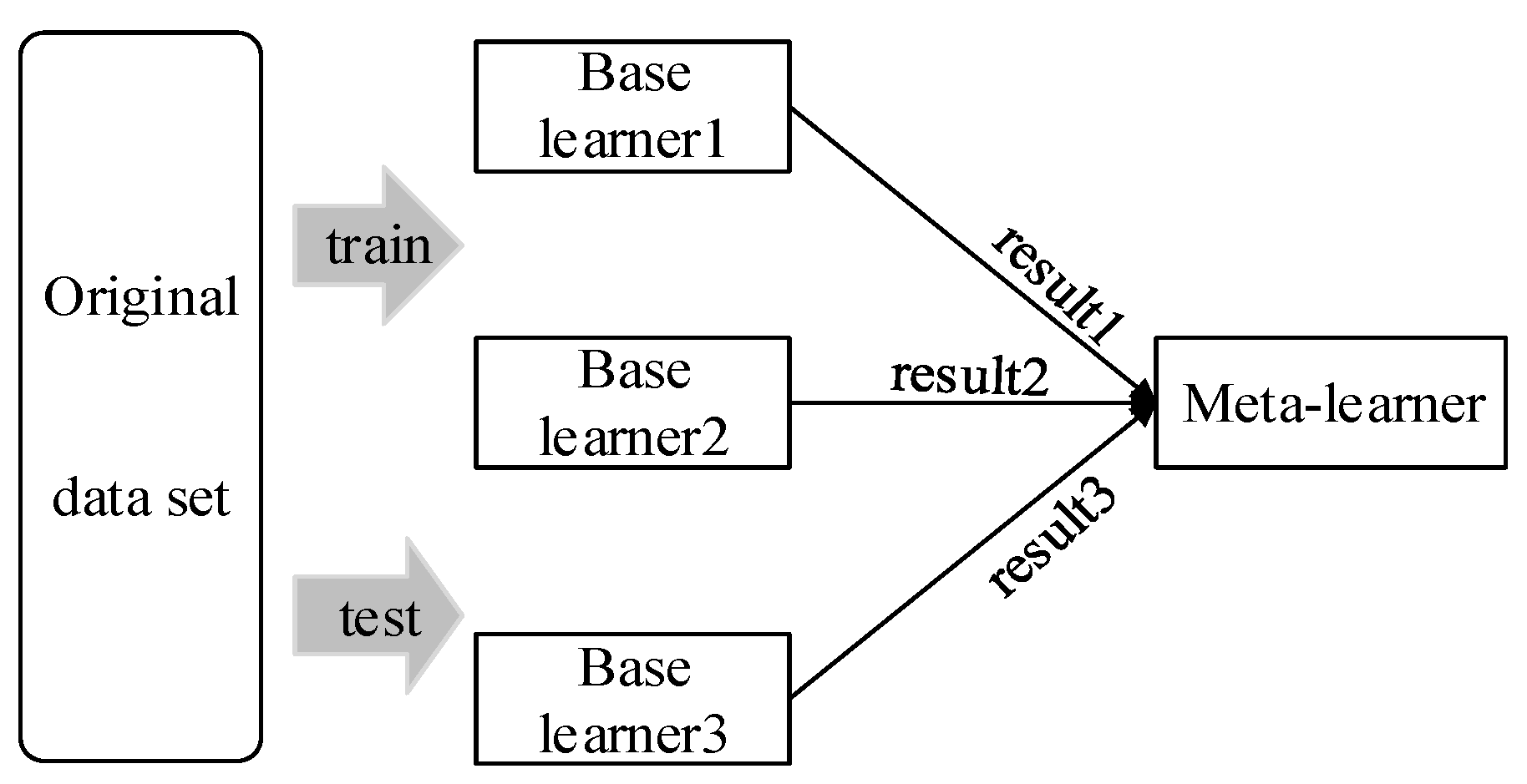
2.1. Stacking Model
2.1.1. Principle of the Stacking Model
2.1.2. Machine Learning Models
Random Forest and KNN Models
Decision Trees, and the GBDT and XGBoost Models
GRU Model
2.2. Bagging Model
2.3. DW Model
2.4. Model Construction
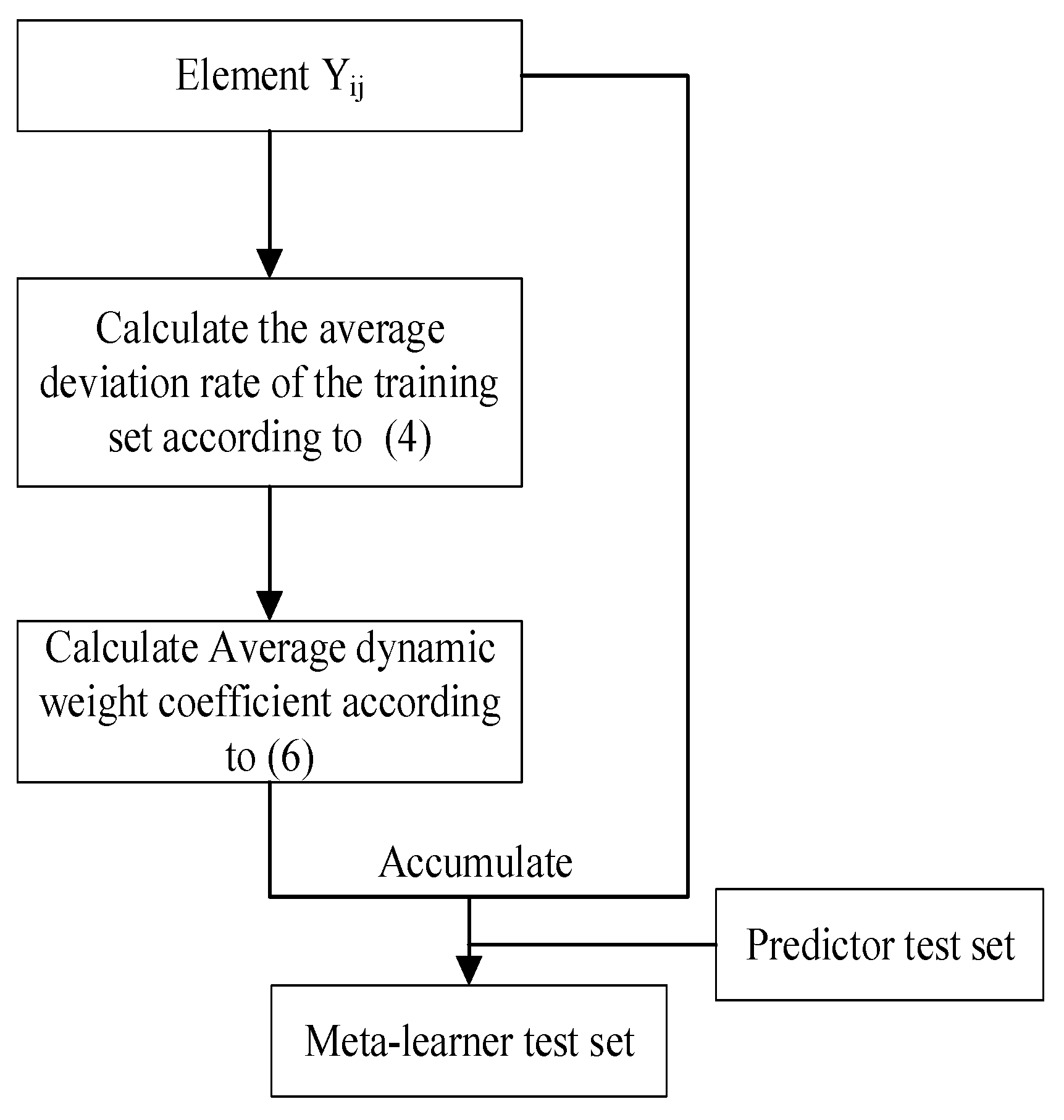
2.4.1. Dynamic Weighting Adjustment Model Process
- (1)
- Calculate the absolute error of each element , that is, the degree of deviation of each element: the absolute value of the difference between the predicted value and the actual value of the base learner;
- (2)
- Calculate the deviation rate and average deviation rate of each element , the normalized value of absolute error , and the normalized mean value of absolute error of each column n , respectively;
- (3)
- Calculate the contribution rate and the average contribution rate of each element , the value of 1 minus the deviation rate, and the value of 1 minus the average deviation rate, respectively.
- Training set
- Test set
2.4.2. Ba-Stacking Model Optimization Process
- (1)
- Divide the original data into the training set and test set;
- (2)
- Construct the corresponding prediction models, including random forest, XGBoost, the GBDT, and the decision-tree model;
- (3)
- Use and to obtain the corresponding predicted values of different models through the bagging algorithm, denoted as ;
- (4)
- Using , obtain the weight coefficients by different adjustment methods, followed by the flow data of the adjusted base learner model, noted as ;
- (5)
- Using,, build a meta-learner ridge regression mode to obtain the final traffic prediction values of the improved stacking integration model;
- (6)
- Train the model with the training set. Once trained, the model will be tested using the test set.
3. Problem Description and Data Progress
3.1. Overview of Short-Term Traffic Flows
3.2. Data Sources and Pre-Processing
3.2.1. Data Sources
3.2.2. Feature Construction
- (1)
- Structured rest day features
- (2)
- Construction work peak characteristics
- (3)
- Constructing historical indicator characteristics
- (4)
- One-hot encoding processing
3.2.3. Data Pre-Processing
Missing Value Handling
Data Normalization
4. Experiment
4.1. Evaluation Indicators
4.2. Model Prediction
4.2.1. Analysis of Feature Prediction Effect
4.2.2. Single Model Parameter Setting
4.2.3. Pearson Characteristic Coefficient Analysis
4.2.4. Ba-Stacking Model Prediction
4.2.5. DW-Ba-Stacking Model Prediction
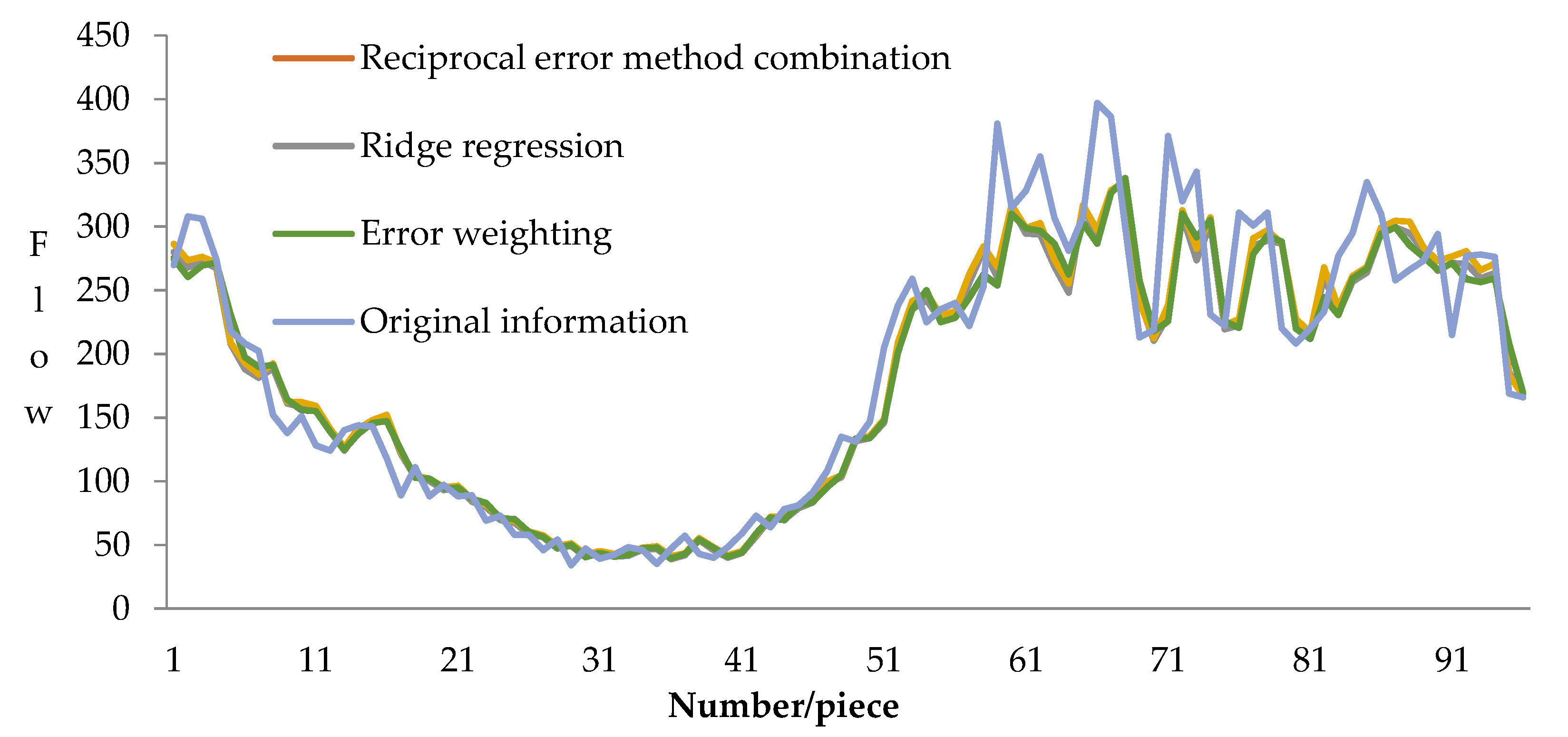
4.2.6. Comparative Analysis of Experimental Results
5. Conclusions
- (1)
- In order to improve the shortcomings of the traffic prediction model with a single feature, temporal features such as holidays and historical features such as speed are constructed. Traffic flow is always recorded in the detector, so the time for the recorded parameters is clearer. In this paper, different time-feature information is extracted according to the specific time of the record: holiday information, weekend information features, and peak information; historical speed and occupancy features related to traffic flow are constructed according to the original data features, and the rationality of the introduced features is verified through the comparative analysis of different features. Thus, the best effect is obtained.
- (2)
- The stacking integration model with the highest accuracy is obtained by filtering and optimizing the learners. First, we build machine learning models with different merits; then, we analyze the correlation coefficient between each model and the actual information by using the Pearson correlation coefficient; next, we select the stacking-integrated model with the highest prediction accuracy based on the weight of each model; and, finally, we embed the bagging model in this model to further improve the prediction accuracy of the model.
- (3)
- According to the shortcomings of the stacking-integrated model, the stacking model two-layer is used as the object of improvement. With the goal of enhancing the variability between models and the correlation between predicted and actual information, the weights of different base learner models are adjusted so that the prediction accuracy is higher.
- (1)
- Realize the effective combination of the stacking model and bagging model, i.e., the construction of Ba-Stacking. The bagging model is used to optimize the output information features of the base learner in the stacking model, and the construction of the Ba-Stacking model is completed.
- (2)
- Based on the Ba-Stacking model, the DW-Ba-Stacking model is constructed by weighting coefficients. The Ba-Stacking model with the meta-learners as ridge regression optimizes the base learner feature information by error coefficient.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alghamdi, T.; Elgazzar, K.; Bayoumi, M.; Sharaf, T.; Shah, S. Forecasting Traffic Congestion Using ARIMA Modeling. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 1227–1232. [Google Scholar]
- Min, X.; Hu, J.; Zhang, Z. Urban traffic network modeling and short-term traffic flow forecasting based on GSTARIMA model. In Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Portugal, 19–22 September 2010; pp. 1535–1540. [Google Scholar]
- Liu, X.W. Research on Highway Traffic Flow Prediction and Comparison based on ARIMA and Long-Short-Term Memory Neural Network. Master’s Thesis, Southwest Jiaotong University, Chengdu, China, 2018. (In Chinese). [Google Scholar]
- Cvetek, D.; Muštra, M.; Jelušić, N.; Abramović, B. Traffic Flow Forecasting at Micro-Locations in Urban Network using Bluetooth Detector. In Proceedings of the 2020 International Symposium ELMAR, Zadar, Croatia, 14–15 September 2020; pp. 57–60. [Google Scholar]
- Iwao, J.; Stepphanedes Yorgos, J. Dynamic prediction of traffic volume through Kalman filtering theory. Pergamon 1984, 18, 1–11. [Google Scholar]
- Guo, J.; Huang, W.; Williams, B.M. Adaptive Kalman filter approach for stochastic short-term traffic flow rate prediction and uncertainty quantification. Transp. Res. Part C Emerg. Technol. 2014, 43, 50–64. [Google Scholar] [CrossRef]
- Ullah, I.; Fayaz, M.; Naveed, N.; Kim, D. ANN Based Learning to Kalman Filter Algorithm for Indoor Environment Prediction in Smart Greenhouse. IEEE Access 2020, 8, 159371–159388. [Google Scholar] [CrossRef]
- Vlahogianni, E.I.; Karlaftis, M.G.; Golias, J.C. Short-term traffic forecasting: Where we are and where we’re going. Transp. Res. Part C Emerg. Technol. 2014, 43, 3–19. [Google Scholar] [CrossRef]
- Gao, J.; Leng, Z.; Qin, Y.; Ma, Z.; Liu, X. Short-term traffic flow forecasting model based on wavelet neural network. In Proceedings of the Control and Decision Conference (CCDC), Guiyang, China, 25–27 May 2013; pp. 5081–5084. [Google Scholar]
- Qin, Y.; Adams, S.; Yuen, C. Transfer Learning-Based State of Charge Estimation for Lithium-Ion Battery at Varying Ambient Temperatures. IEEE Trans. Ind. Inform. 2021, 17, 7304–7315. [Google Scholar] [CrossRef]
- Xiong, T.; Qi, Y.; Zhang, W.B.; Li, Q.M. Short-term traffic flow prediction model based on spatiotemporal correlation. Comput. Eng. Des. 2019, 40, 501–507. (In Chinese) [Google Scholar]
- Lu, W.; Rui, Y.; Yi, Z.; Ran, B.; Gu, Y.A. Hybrid Model for Lane-Level Traffic Flow Forecasting Based on Complete Ensemble Empirical Mode Decomposition and Extreme Gradient Boosting. IEEE Access 2020, 8, 42042–42054. [Google Scholar] [CrossRef]
- Alajali, W.; Zhou, W.; Wen, S.; Wang, Y. Intersection Traffic Prediction Using Decision Tree Models. Symmetry 2018, 10, 386. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Li, Y.; Sheng, G.; Lv, J. Research on Short-Term Traffic Flow Forecasting Based on KNN and Discrete Event Simulation. In Proceedings of the 15th International Conference on Advanced Data Mining and Applications, Foshan, China, 12–15 November 2019; pp. 853–862. [Google Scholar]
- Qin, Y.; Yuen, S.C.; Qin, M.B.; Li, X.L. Slow-varying Dynamics Assisted Temporal Capsule Network for Machinery Remaining Useful Life Estimation. arXiv 2022, arXiv:2203.16373. [Google Scholar] [CrossRef] [PubMed]
- Dai, G.W.; Ma, C.X.; Xu, X.C. Short-Term Traffic Flow Prediction Method for Urban Road Sections Based on Space Time Analysis and GRU. IEEE Access 2019, 7, 143025–143035. [Google Scholar]
- Hu, H.; Yan, W.; Li, H.M. Short-term traffic flow prediction of urban roads based on combined forecasting method. Ind. Eng. Manag. 2019, 24, 107–115. [Google Scholar]
- Zhu, P.F.; Liu, Y. Prediction of distributed optical fiber monitoring data based on GRU-BP. In Proceedings of the 2021 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Xi’an, China, 27–28 March 2021; pp. 222–224. [Google Scholar]
- Barboza, F.; Kimura, H.; Altman, E. Machine learning models and bankruptcy prediction. Expert Syst. Appl. 2017, 83, 405–417. [Google Scholar] [CrossRef]
- Wang, S.; Yao, Y.; Xiao, Y.; Chen, H. Dynamic Resource Prediction in Cloud Computing for Complex System Simulatiuon: A Probabilistic Approach Using Stacking Ensemble Learning. In Proceedings of the 2020 International Conference on Intelligent Computing and Human-Computer Interaction (ICHCI), Sanya, China, 4–6 December 2020; pp. 198–201. [Google Scholar]
- Liu, Y.; Yang, C.; Gao, Z.; Yao, Y. Ensemble deep kernel learning with application to quality prediction in industrial polymerization processes. Chemom. Intell. Lab. Syst. 2018, 174, 15–21. [Google Scholar] [CrossRef]
- Zhang, X.M.; Wang, Z.J.; Liang, L.P. A Stacking Algorithm for Convolutional Neural Networks. Comput. Eng. 2018, 44, 243–247. [Google Scholar]
- Li, B.S.; Zhao, H.Y.; Chen, Q.K.; Cao, J. Prediction of remaining execution time of process based on Stacking strategy. Small Microcomput. Syst. 2019, 40, 2481–2486. (In Chinese) [Google Scholar]
- Sun, X.J.; Lu, X.X.; Liu, S.F. Research on combined traffic flow forecasting model based on entropy weight method. J. Shandong Univ. Sci. Technol. (Nat. Sci. Ed.) 2018, 37, 111–117. (In Chinese) [Google Scholar]
- Gong, Z.H.; Wang, J.N.; Su, C. A weighted deep forest algorithm. Comput. Appl. Softw. 2019, 36, 274–278. (In Chinese) [Google Scholar]
- Zheng, Z.H.; Huang, M.F. Traffic Flow Forecast Through Time Series Analysis Based on Deep Learning. IEEE Access 2020, 8, 82562–82570. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.L.; Tang, D.H.; Jiang, G.Y.; Xiao, Z.T.; Geng, L.; Zhang, F.; Wu, J. Residual LSTM Short-Term Traffic Flow Prediction Based on Dimension Weighting. Comput. Eng. 2019, 45, 1–5. (In Chinese) [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Base Learner | Historical Characteristics | Time Characteristics | MSE | MAE |
|---|---|---|---|---|
| Random forest | + | + | 662.11 | 17.38 |
| + | - | 745.40 | 18.08 | |
| - | - | 761.44 | 18.26 | |
| XGBoost | + | + | 649.15 | 17.27 |
| + | - | 762.76 | 18.40 | |
| - | - | 773.18 | 18.40 | |
| GBDT | + | + | 648.21 | 17.25 |
| + | - | 760.87 | 18.32 | |
| - | - | 778.18 | 18.44 | |
| Decision tree | + | + | 754.31 | 18.45 |
| + | - | 778.73 | 18.70 | |
| - | - | 789.33 | 18.81 | |
| KNN | + | + | 754.37 | 18.63 |
| + | - | 776.90 | 18.36 | |
| - | - | 789.40 | 18.50 | |
| GRU | + | - | 744.73 | 18.54 |
| - | - | 768.01 | 18.72 |
| Base Learner | Parameter Setting | MSE | MAE |
|---|---|---|---|
| Random forest | The tree depth is 10, the number of trees is 160, the minimum number of samples for leaf nodes is 2, and the minimum number of samples for the node division is 5 | 662.11 | 17.38 |
| XGBoost | The number of trees is 390, the minimum leaf node sample weight is 8, the random sampling ratio is 0.9, the number of columns randomly sampled in each tree accounts for 0.8, and the learning rate is 0.12 | 649.15 | 17.27 |
| GBDT | The tree depth is 3, the number of trees is 470, the minimum number of samples for leaf nodes is 6, and the minimum number of samples for node division is 10 | 648.21 | 17.25 |
| KNN | Take the number of adjacent points: 48 | 754.37 | 18.63 |
| Decision tree | The tree depth is 7, the minimum number of samples for leaf nodes is 2, and the minimum number of samples for node division is 7 | 754.31 | 18.45 |
| GRU | GRU has two layers of neurons, of which the number in the first layer is 64 and that in the second layer is 32. The dropout is 0.1 | 744.73 | 18.54 |
| R | X | GB | D | K | G | Y | |
|---|---|---|---|---|---|---|---|
| R | 1 | 0.9962 | 0.9964 | 0.9890 | 0.9932 | 0.9895 | 0.9441 |
| X | 0.9962 | 1 | 0.9988 | 0.9869 | 0.9898 | 0.9891 | 0.9444 |
| GB | 0.9964 | 0.9988 | 1 | 0.9870 | 0.9900 | 0.9891 | 0.9442 |
| D | 0.9890 | 0.9869 | 0.9870 | 1 | 0.9829 | 0.9849 | 0.9354 |
| K | 0.9932 | 0.9898 | 0.9901 | 0.9829 | 1 | 0.9877 | 0.9355 |
| G | 0.9895 | 0.9891 | 0.989123 | 0.9849 | 0.9877 | 1 | 0.9357 |
| Y | 0.9441 | 0.9444 | 0.9442 | 0.9354 | 0.9354 | 0.9357 | 1 |
| Model Selection | Y/N | Y/N | Y/N | Y/N | Y/N | Y/N |
|---|---|---|---|---|---|---|
| Random forest | 1 | 1 | 1 | 1 | 1 | 1 |
| GBDT | 1 | 1 | 0 | 1 | 1 | 1 |
| XGBoost | 1 | 0 | 1 | 1 | 1 | 1 |
| KNN | 1 | 1 | 0 | 0 | 0 | 0 |
| Decision tree | 1 | 1 | 1 | 0 | 1 | 0 |
| GRU | 1 | 1 | 1 | 1 | 1 | 1 |
| MSE | 638.15 | 638.92 | 638.71 | 643.67 | 638.63 | 643.01 |
| MAE | 17.07 | 17.06 | 17.07 | 17.17 | 17.08 | 17.15 |
| Meta-Learner | Bagging | Evaluation Index | |||||
|---|---|---|---|---|---|---|---|
| Random Forest | XGBoost | GBDT | Decision Tree | KNN | MSE | MAE | |
| Ridge regression | - | - | - | - | - | 638.15 | 17.07 |
| + | - | - | - | - | 641.15 | 17.11 | |
| - | + | - | - | - | 637.33 | 17.06 | |
| - | - | + | - | - | 637.51 | 17.06 | |
| - | - | - | + | - | 638.14 | 17.07 | |
| - | - | - | - | + | 633.83 | 17.00 | |
| + | + | + | + | + | 634.95 | 17.00 | |
| - | + | + | + | + | 632.85 | 16.99 | |
| Method | MSE | MAE |
|---|---|---|
| Random forest | 662.11 | 17.38 |
| XGBoost | 649.15 | 17.27 |
| GBDT | 648.21 | 17.25 |
| KNN | 754.37 | 18.63 |
| Decision tree | 754.31 | 18.45 |
| GRU | 744.73 | 18.54 |
| Stacking model | 638.15 | 17.07 |
| Ba-Stacking model | 632.85 | 16.99 |
| DW-Ba-Stacking model | 619.59 | 16.87 |
| Reciprocal error method combination | 659.31 | 17.28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Wang, L.; Wang, D.; Yin, M.; Huang, Y. Short-Term Traffic-Flow Forecasting Based on an Integrated Model Combining Bagging and Stacking Considering Weight Coefficient. Electronics 2022, 11, 1467. https://doi.org/10.3390/electronics11091467
Li Z, Wang L, Wang D, Yin M, Huang Y. Short-Term Traffic-Flow Forecasting Based on an Integrated Model Combining Bagging and Stacking Considering Weight Coefficient. Electronics. 2022; 11(9):1467. https://doi.org/10.3390/electronics11091467
Chicago/Turabian StyleLi, Zhaohui, Lin Wang, Deyao Wang, Ming Yin, and Yujin Huang. 2022. "Short-Term Traffic-Flow Forecasting Based on an Integrated Model Combining Bagging and Stacking Considering Weight Coefficient" Electronics 11, no. 9: 1467. https://doi.org/10.3390/electronics11091467
APA StyleLi, Z., Wang, L., Wang, D., Yin, M., & Huang, Y. (2022). Short-Term Traffic-Flow Forecasting Based on an Integrated Model Combining Bagging and Stacking Considering Weight Coefficient. Electronics, 11(9), 1467. https://doi.org/10.3390/electronics11091467