1. Introduction
The development of artificial intelligence techniques, more specifically Deep Learning (DL), allows several applications to be used as facilitators or as support for the solution of common everyday problems. Some of these problems may be related to the recognition of human actions, such as instructions to perform a task, or the detection of faulty movements in activities that require precision. In computer vision, the term “action recognition” is often treated as a pattern recognition problem with an additional time dimension to recognize human actions in videos [
1].
The studies in the area of action recognition involve the analysis of images, understanding that each image is a frame under a temporal approach (the sequence of the frames, a determining factor for action recognition), which can portray different contexts (such as a person performing karate or fixing a car) and classes (in the karate context, each move performed by the person is a class). There are also models capable of automatically learning the steps necessary to perform a task based on videos with narration and subtitles.
The action recognition task is part of the modernization and adoption of intelligent systems in various sectors of society, in the context of Industry 4.0. There are a lot of applications, such as surveillance [
2,
3], video retrieval [
4,
5], entertainment [
6,
7], human-robot interaction [
8,
9], and autonomous vehicles [
10,
11].
These applications require large datasets to validate their effectiveness. So, the development of several datasets, such as the COmprehensive INstructional Video Analysis (COIN) [
12] dataset, consisting of 11,827 videos and 180 tasks related to everyday life organized in a hierarchical structure (the contexts and their respective classes) with descriptive annotation of actions and temporal boundaries. Another example is EPIC-KITCHENS [
13], a dataset consisting of 100 h of first-person videos, which depict various activities in the context of cooking and are annotated based on the narrations of the participants.
The data present in these datasets can be classified into two groups: unlabeled and labeled. Unlabeled data consists of samples without the presence of data containing information (label) that defines its meaning. On the other hand, labeled data has this information that classifies the data [
14]. For example, an image of a kitchen sink is an unlabeled data, but when we write data for this image with the information “sink”, it becomes characterized as labeled. To construct labeled data, it is necessary to manually map these features, which makes this process expensive for a human activity [
15].
On the other hand, manual video labeling needs precise frame-by-frame labeling of actions, which makes the process time-consuming and challenging [
16]. Ref. [
17] states that manual video labeling isn’t feasible for large sets because it is expensive and requires a domain expert (e.g., to annotate a karate video, you need an expert who understands exactly what the moves are in order to correctly identify them in classes).
This restriction is even more significant for deep learning and artificial neural networks (ANN) techniques, since they are mostly supervised, and require a large amount of labeled data for training and subsequent image recognition [
18]. As an example, to apply a technique for recognizing actions performed in car maintenance tasks, each frame in a set of videos must be labeled, identifying each maintenance context and class, substantially increasing the difficulty in preparing datasets of videos to develop a machine learning model for a specific task, since an extensive effort is required for annotation, considering the amount of frames per second in a video, and its duration. So, in this research we aim to provide an innovative approach that reduces the reliance on labeled data, commonly required in supervised learning approaches, to build machine learning models to recognize human actions in videos, based on the hypothesis of creating solutions with reduced need for fully labeled data, thus mitigating this problem and advancing in the current state-of-the-art.
In this context, this study proposes the Semi-Supervised and Iterative Reinforcement Learning (RL-SSI), which adapts a supervised approach that uses 100% labeled data as part of a semi-supervised and iterative approach using reinforcement learning for human action recognition in videos.
In this way, the main contributions to the literature of this research are:
to provide an innovative approach that reduces the reliance on having a large amount of labeled data, commonly required in supervised learning approaches, to build machine learning models to recognize human actions in videos;
to adapt a supervised learning approach to a semi-supervised and iterative learning, using the reward strength in reinforcement learning;
to compare and assess the approach with equivalent learning methods with publicly available datasets of human action segmentation, aiming at having similar or even better performance, but with less annotated data.
This paper is organized into four parts.
Section 2 presents related works,
Section 3 outlines the methods used,
Section 4 details our findings, and
Section 5 presents our final considerations and recommendations for future investigations.
2. Basic Concepts
ANN are algorithms designed to model the structure or function of biological neural networks, simulated computationally by programming. In short, they are a processor that operates in parallel and a distributed manner through processing units that are neurons, which have the propensity to store experimental knowledge (learning) to be used in the desired application. During the learning process, there is an orderly modification of the synaptic weights of the network [
19].
Thus, the goal of an ANN is to acquire learning from patterns for existing problems. That is, there must be some initial information so that the ANN can build and generate patterns from that data [
19]. In this sense, there are four forms of learning: supervised, unsupervised, semi-supervised, and reinforcement learning, described briefly below:
To understand how supervised learning occurs, one can take as a reference the work of a teacher: the teacher has the knowledge of the environment, but the neural network does not. So, the teacher provides the knowledge so that the neural network can learn it and, in the end, applies a test to check if there was learning [
19]. In this approach, the existence of the teacher is crucial, which in practice means that the input data must be properly labeled. This is because, during the training process, there will be an expected output and, if the output of the ANN does not match what is expected, the weights will be updated so that it can learn the data patterns.
In this approach there is no teacher, that is, the input data is not labeled and there is no expected output. As such, unsupervised learning entails an analysis of the structures present in the data, the goal of which may be to reduce redundancy or to group similar data [
19]
This approach resembles unsupervised learning because it looks for innate patterns in the data. However, this method relies on a certain amount of labeled and unlabeled data to complete its learning. In other words, it is an approach that uses concepts from both supervised and unsupervised approaches [
20].
Reinforcement learning (RL) is a computational approach to decision-making for goal-defined problems [
21], in which an artificial agent learns its choice policy from interactions with the environment. At a given time interval, the agent observes the state of the environment and selects an action, which, as far as it is concerned, affects the environment. The agent earns a numerical reward for each action and updates its policy to maximize future rewards. This sequential decision-making process is formalized as a MDP M: = (S, A, P, R,
) [
21], where:
S represents a finite set of states
A represents a finite set of actions
P: S × A × S → [0, 1] denotes state transition probabilities
R: S × A → R denotes a reward function for each action performed in a given state
∈ [0, 1] is the discount factor that balances the immediate and long-term rewards.
The agent improves with experience to optimize its policy
pi: S × A → [0, 1], usually stochastic (random origin). The goal is to maximize the future reward with a cumulative discount from the current step to the end of the learning episode [
22]. In some ways, this approach is similar to methodologies used in the process of animal training.
Table 1 displays the main characteristics and differences of each of the learning approaches.
3. Related Works
Action segmentation is a task linked to action recognition that aims to identify and specify where each action present in a video starts and ends [
16]. The Temporal Convolutional Network (TCN) [
23] is an action segmentation technique, which uses a hierarchy of temporal convolutions to perform granular action segmentation or detection. The TCN uses pooling and upsampling to efficiently capture long-range temporal patterns. Furthermore, ref. [
23] proves that TCN can capture action compositions and segment durations.
The Self-Supervised Temporal Domain Adaptation (SSTDA) [
16] has reformulated the task of action segmentation in view of cross-domain problems with domain discrepancy caused by spatio-temporal variations, i.e., when there is a difference in action performance because it is performed by multiple persons. The SSTDA contains two self-supervised auxiliary tasks (binary domain prediction and sequential domain predictions), which work cooperatively to align cross domains that have integrated spatial features with local and global temporal dynamics features. This study has performed two experiments: one with part of the labels for training (65% of the labels) to learn the adaptive features of each temporal domain, and another with 100% of the labels.
The work of [
22] has related the task of segmenting surgical gestures (when a gesture starts and when it ends) and assigning a label to untrimmed videos (long videos that have several classes in a single video with some data category specifying them). The innovation of their approach is in sequential decision-making, where an intelligent agent is trained using reinforcement learning. In other words, the agent interacts with the environment (which, in this case, means the videos) and makes decisions (actions), which are related to the temporal aspect and its classification. These actions receive positive or negative feedback, according to the expected response, which characterizes it as a supervised technique. Ref. [
22] further argues that this methodology is integrated with temporal consistency, which allows it to reduce excessive segmentation (when segmentation creates many insignificant boundaries), which is common in the gesture segmentation task. In short, the approach works in two steps: (i) use of TCN [
23] to extract temporal features and (ii) sending of these features to a Reinforcement Learning Network (RLN) modeled so that positive and negative rewards are given according to expected output (ground-truth).
In this work, we present a technique that advances the state of the art by developing a model that adapts a supervised approach to a semi-supervised and iterative approach from a methodology applied to reinforcement learning. Among the techniques described above, the methodology presented by [
22] is considered fruitful for this proposal, given the use of reinforcement learning and its potential of reward strength to measure the quality of the proposed labels. In addition, the model of [
22] is supervised, which provides us with an important basis of comparison to ascertain whether our proposed adaptation was successful in achieving similarity or was superior by using only part of the labels.
4. Materials and Methods
The RL-SSI was applied to the model of [
22] to be able to run the ensemble iteratively with a reduced number of labels so that, at each completed iteration, valid labels are generated. The methodology applied to Reinforcement Learning (RL) allows labels with the highest degree of confidence, as measured through the reward function, to be moved to training in the next iteration. In this way, the supervised nature of the approach described by [
22] is overcome, thus enabling a solution that requires less labeled data. To run the RL-SSI, the dataset had to be split into three parts:
Training part: it contains the original labels from the dataset for the training step in the first iteration. In the following iterations it receives the best labels generated in the flexible data part.
Flexible data part: it contains predicted data, and from this predicted data the best 25% will be moved to the training part in the next iteration. The criterion used to obtain the top 25% best labels is based on the strength of the RL reward.
Testing part: it contains a fixed dataset on which the evaluation metrics will be measured.
The decision to move 25% of the generated labels per iteration, was an empirical choice based on experiments because since the experiment is run in iterations, it is important to move a portion of the best-generated labels to be able to iterate again in cycles.
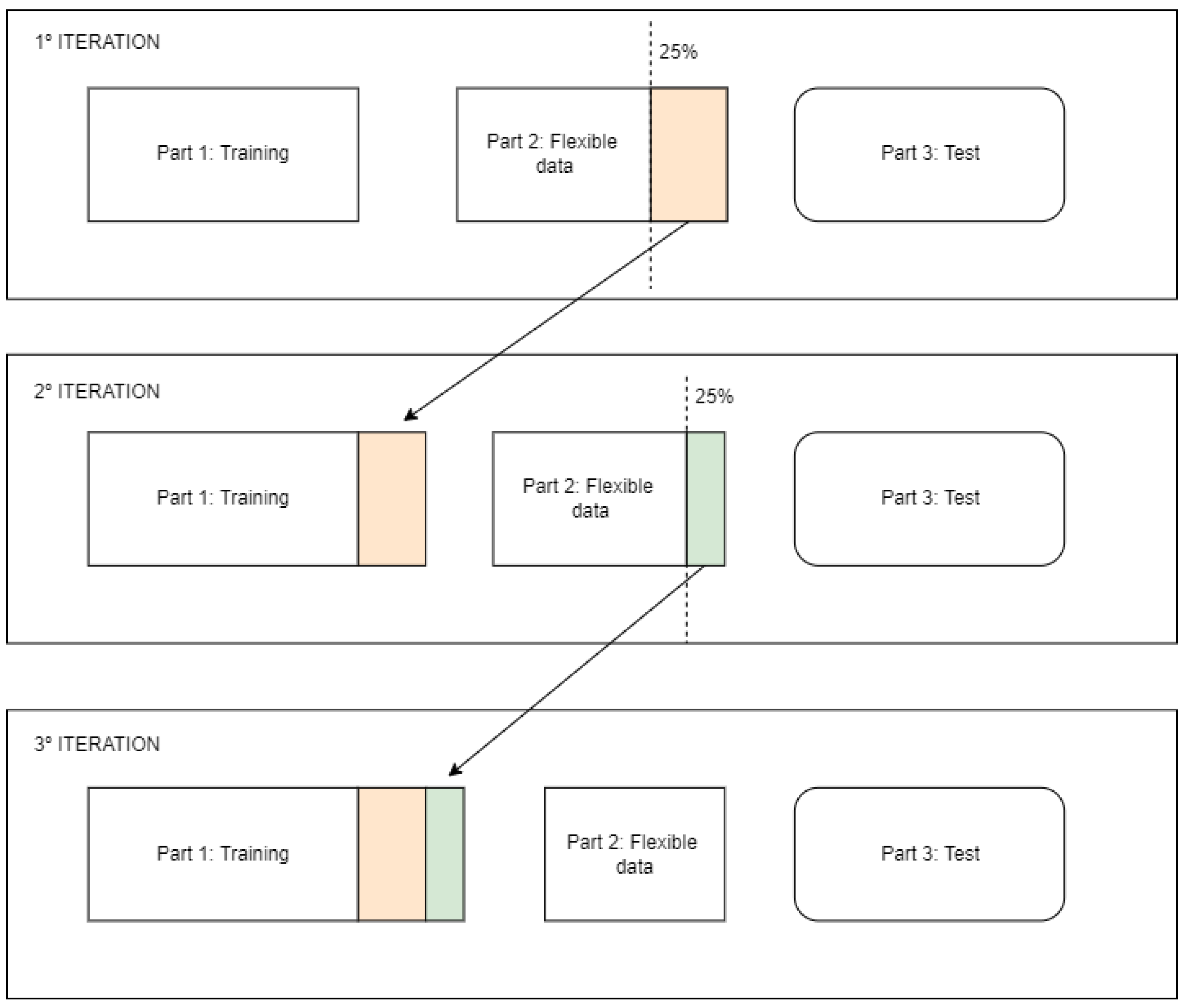
Figure 1 illustrates the operation of the parts of RL-SSI over the course of iterations. As can be seen practically, Part 1 increases by absorbing the 1st quartile of Part 2 over the iterations, i.e., the 25% best labels generated and ranked by the reward function. As far as it is concerned, Part 3 will always be the same for evaluating metrics across all iterations.
In
Figure 2 it is possible to visualize the standard execution flow of the RL-SSI applied to the model proposed by [
22]. As can be seen, our proposal does not change or modify the TCN and RLN of the original model. However, our methodology RL-SSI exploits the reward strength of RL by using it as a criterion to select the top 25% of labels in each iteration.
By establishing the three-part structure, we can see that the training part grows by absorbing the labels from the flexible data part over iterations, i.e., the 25% best labels generated and ranked by the reward function. As far as we are concerned, the testing part will always be the same to evaluate the metrics in all iterations. The standard RL-SSI execution flow does not alter or modify the TCN and RLN of the original model—that is, they function as independent blocks in the flow. However, the methodology proposed by the RL-SSI exploits the strength of reward of the RL by creating an iterative loop that changes the technique to a semi-supervised approach. As the experiment was designed to run cyclically and iteratively, a stopping condition needed to be developed to terminate the execution. This condition is reached when there is no improvement in up to three consecutive runs, since the experiment loses the ability to present good results when subsequent iterations receive incorrect labels. In each interaction, three steps take place: (1) training of the TCN and RLN modules; (2) generation of valid labels; (3) a testing step where the iteration metrics are measured and the stopping condition is tested. When the stopping condition is not met in the testing step, the next iteration is started and the best labels from the generated flexible data are incorporated into the next training step.
4.1. Datasets
This research chose to use two datasets from the action segmentation task: the JIGSAWS and the Breakfast sets. The JIGSAWS is composed of visual data (videos), sensor data from the robotic hands (position, velocity, and angle), and manual annotation. It was collected using the Vinci Surgical System, operated by eight surgeons of different levels of experience load (hours of surgery already performed). For this reason, although the images depict robotic hands, it is possible to consider that the videos show human actions since they are reproducing and mimicking the movements performed by surgeons.
The footage features three elementary surgical activities which are Suturing, Needle Passing, and Knot Tying and the dataset has a total of 15 classes not necessarily present in the three activities [
24]. There are a total of 103 videos with about 2 min long in average, totaling about three hours of recording. This set was used in the work of [
22], making it the primary target of this research, since the proposed adaptation, to be described in the following sections, will be applied to it. The model presented in the work by [
22] used only the Suturing context, thus the experiment developed by this research will use the same context to maintain the same comparison basis.
Breakfast is the largest dataset of human action segmentation tasks, with 77 h of recordings, more than four million frames and 10 contexts (Coffee, Milk, Juice, Tea, Cereals, Fried Eggs, Pancakes, Salad, Sandwich, and Scrambled Egg), totaling 48 classes not necessarily present in all contexts. The videos were recorded by 52 people in 18 kitchens, shot by three to five cameras. To reduce the size of the data, the videos were resized to 320 × 240 pixels with 15 FPS [
25].
Because it is the largest dataset for human action segmentation tasks, it makes it possible to perform a large amount of experiments. Moreover, it is used by other researchers on the same task (segmentation), providing this research with a rich base of comparison of results. For these reasons this set was selected for the experiments.
4.2. Experiment Settings
To ascertain whether the proposed adaptation of the supervised model to a semi-supervised and iterative technique does not negatively impact the results, experiments were developed with two datasets—the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS) [
24] and the Breakfast [
25]. Furthermore, the purpose of using two datasets is to gauge whether the RL-SSI performs well with data from different application areas (in this case, surgical gestures and breakfast preparation). Our interest in the JIGSAWS stems from the fact that it is the dataset used in [
22], so it is possible to directly compare the gains and losses of applying the RL-SSI methodology to the supervised technique by making it semi-supervised and iterative. It is important to point out that only the Suturing context was used, totaling 39 videos. On the other hand, Breakfast was chosen for being the largest dataset mapped to the action segmentation task, which guarantees numerous experiments, besides being used by several references in the state of the art, which allows us to have concrete bases to compare the results of the RL-SSI. Thus, experiments were performed with all the contexts in the dataset, that is, 1989 videos. The experiments performed with Breakfast used, on average, 55.8% of the original labels reserved for training, while the JIGSAWS experiments used 65%. The execution of the experiments was performed individually by each context of the Breakfast and the Suturing of the JIGSAWS, for a total of 11 experiments. Each experiment was run with an NVIDIA Tesla P100- SXM2 video card and the average execution time for each experiment (training, inferences in all iterations) was approximately three days.
4.3. Implementation
“For the implementation of the RL-SSI, some hyperparameters were established. The target metric used to test the stopping conditions of the experiment was F-Score (F1), with a threshold of 10%, reached when there are three consecutive lower values in the iterations. The work of [
26] has introduced this metric to the stock segmentation task because it is efficient in classification and segmentation tasks with three important features: it penalizes excessive segmentation errors; it does not penalize small temporal changes between predictions and expected responses, given the variability that can occur in processes with different human annotators (for example, one annotator may consider that the beginning of the action takes place in frame 50, while another annotator may consider that this same beginning occurs in frame 53); and scoring depends more on the number of actions, not their size. Furthermore, ref. [
26] states that the F1 values of the segments are better represented qualitatively.
A significant element for this choice is that it is the most relevant metric in segmentation challenges, such as the Davis Challenge [
27], which uses it to rank the best works in the domain of multiple object segmentation in videos. Since the RL-SSI exploits a methodology applied to RL of the model itself without changing it internally, the parameters originally used in [
22] have been kept. The TCN has 300 epochs, a learning rate of 0.00001, a batch size of 1, and a weight decay of 0.0001. The RLN, on the other hand, was implemented with the Python programming language and the OpenAI Baselines library [
28]. The policy network Trust Region Policy Optimization (TRPO) is of a hidden layer with 64 hidden units, and the time steps of TRPO were set to a value of 500,000. The discount factor gamma and the reward weight alpha were kept as 0.9 and 0.1, respectively.
Another important parameter of [
22] is the step type, which can be short (
ks) or long (
kl). The RLN will classify a number of frames depending on the steps set. This binary strategy enables the agent to change the step size based on confidence in the label of the action to be made. The agent can adopt the smaller step when the state is not discriminative enough, or the larger step otherwise. In each action of the agent,
k frames are labeled with the same class, explicitly enforcing temporal consistency.
However, the values of the
ks and the
kl needed to be recalculated, since they were defined as the size of the smallest action in the context and the shortest average action length for each class, respectively. The values calculated for each context of a dataset can be seen in
Table 2.
5. Results and Discussion
Table 3 highlights the best results of the RL-SSI metrics for the experiment with JIGSAWS (the best results are in green). Since the model of [
22] has two modules, one from TCN and one from RLN, we can benchmark the results produced in both. We can observe that RLN generated good results, although TCN performed even better for both accuracy and segmentation metrics. This highlights that, in the proposed adaptation, TCN has better benefits from the iterative semi-supervised process on this dataset. Even with this performance for TCN, RLN is critical in the proposed adaptation given that the applied methodology exploiting reward strength is crucial for the iterative process to be semi-supervised, and in this model under study this occurs after the action of the TCN.
Table 4 compares the model of [
22] with the RL-SSI (the best results are in green). We can observe that RL-SSI obtained better results in the metrics Edit Score and F1@10,25,50, losing only in Accuracy to the results of the reference technique [
22]. However, similarly to our prior findings, the best results of the iterations occurred in TCN and, in this case, RL-SSI outperformed in all quantitative metrics the model of [
22]. Both RL-SSI and the model of [
22] used the Suturing context of JIGSAWS, but [
22] is a supervised approach using 100% of the labels, while RL-SSI used only 65% of them. Therefore, we conclude that the RL-SSI accomplishes its goal, that is successfully adapting a supervised technique to a semi-supervised and iterative technique, and it outperforms the results of the base technique on all quantitative metrics in the TCN results and on three of the four RLN metrics.
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12,
Table 13 and
Table 14 summarize the results of the RL-SSI in each Breakfast context (the best results are in green). We can observe that, unlike the JIGSAWS experiment, RLN was predominantly better than TCN in relation to the accuracy metrics and always better in relation to the segmentation metrics. In some cases such as in the context of Coffee, Tea, and Fried Egg the accuracy of TCN was slightly better as the differences were no more than two percentage points.
The best values varied between the first and third iteration, while the maximum amount of iterations of the experiments varied from four to six. Another notable pattern is that the best experiment was always the third, counting inversely from the last iteration. The Juice context obtained the best accuracy results and the Cereals context obtained the best results in relation to the segmentation metrics. The standard deviation for the accuracy metric was 6.37, which is lower than that of the Edit Score and F1@10,25,50 segmentation metrics, which were 14.28 and {14.21, 15.69, 15.05}, respectively. This highlights a greater variation with the segmentation metrics with respect to accuracy.
Table 15 presents the result of each context with its best iteration, maximum amount of iterations, the arithmetic mean, and the standard deviation of all contexts to consolidate the comparative results of RL-SSI in the experiments with the Breakfast dataset.
Table 16 presents the comparison of the results of SSTDA [
16] and RL-SSI (the best results are in green). As a result, RL-SSI outperformed SSTDA by obtaining an accuracy of 66.44% versus 65.8% and F1@50 of 63.19% versus 62.9%. However, RL-SSI was outperformed by SSTDA in the Edit metrics by obtaining 60.36% versus 69.0%, F1@10 of 67.33% versus 69.3%, and F1@50 of 47.86% versus 49.4%. When visualizing the standard deviation, it is possible to see that there was little variation in all metrics when values are below one, except for the Edit Score that obtained 4.32.
Thus, we can observe that RL-SSI outperformed SSTDA with a difference of 0.76% in accuracy, and with 0.29% for the F1@25 metric. However, it lost performance in the quality of segmentation with the Edit Score metric by 8.64%, by a difference of 2.03% for the F1@10 metric, and, for the F1@50 metric, by 1.54%. However, RL-SSI used only 55.8% of the labeled data, while SSTDA used 65% of them.
The experiments with the Breakfast dataset revealed that the application of the RL-SSI model applied in the transformation of the supervised approach, based on [
22], into a semi-supervised and iterative one, was also successful in different contexts of human action recognition, in this way expanding the application of the proposed method. Moreover, the comparison with the SSTDA technique shows that RL-SSI presents competitive results using a reduced number of labels. This work advances the state-of-the-art by obtaining results that are competitive with fully supervised learning techniques, presenting the important characteristic of creating a solution that does not need to use a large number of labels.
6. Conclusions
The experiments with JIGSAWS have revealed that RL-SSI, which has successfully adapted a supervised technique to a semi-supervised and iterative technique, outperformed in all quantitative metrics the technique of [
22] using only 65% of the annotated labels. On the other hand, the results of the Breakfast experiments show that RL-SSI is also successful for other action contexts, thus expanding the proposal to other applications. The RL-SSI proved to be competitive by overcoming the SSTDA with a difference of 0.76% in accuracy and 0.29% in F1@25. On the other hand, it underperformed in the segmentation quality with the Edit Score metric by 8.64%, the F1@10 metric by a difference of 2.03%, and F1@50 by 1.54%. However, it is worth noting that RL-SSI used only 55.8% of the labels, while SSTDA used 65%.
To mitigate the dependence on big amount of labeled data for building machine learning models for human action recognition, which is an existing gap in the literature, the experimental results of RL-SSI demonstrate that our approach outperformed equivalent supervised learning methods and is comparable to SSTDA when evaluated on multiple datasets, having an important innovative aspect by proving to be successful in its purpose of building solutions to reduce the need for fully labeled data, leveraging the work of human specialists in the task of data labeling, thus reducing the required resources to accomplish it.
In future research, we envision application of the RL-SSI methodology in other supervised techniques, keeping its basic structure: execution in iterations, division of the data into three pieces (training, flexible data, and testing), and finally, some mechanism to measure and move the best-generated labels. As well as the possibility of making changes to the policy network aimed at optimizing the reward strength in the RLN. Finally, another recommendation would be to investigate the effect percentages of labeled data, such as 20%, 40%, 60%, and 80% of the original labeled data.







{kind=link}
{kind=link}