1. Introduction
With the introduction and rapid development of recommendation systems [
1] (or recommender system), automatically generated suggestions are widely considered and applied in various fields. As the volume of information in the information age grows, recommendation systems have become an effective strategy for overcoming such information overload by filtering valuable messages. The usefulness of recommendation systems cannot be overemphasized, as they are widely adopted in many web applications and have the potential to ameliorate many of the problems associated with over-selection. In recent years, recommendation systems have attracted significant interest in the field of medical research. Some examples would be the use of recommendation systems to recommend pregnancy drugs in epidemics [
2], the use of recommendation systems to find the drugs with the best possible control of neo-coronavirus in neo-coronavirus epidemics [
3], and applications to the sequencing and expression of genes [
4]. Recommendation systems have also achieved some success in healthcare [
5] and have emerged thanks to the excellent performance and the benefit of learning feature representations from scratch. The field of deep learning in recommendation systems is booming, and mathematics is at the core of recommendation systems [
6].
Recommendation systems estimate users’ preferences for items and actively recommend items that users may like [
7]. Recommendation models are typically divided into three categories: collaborative filtering [
8,
9,
10,
11], content-based [
12,
13,
14], and hybrid recommendation systems [
15,
16]. Collaborative filtering makes recommendations by learning the users’ item history interactions (either explicitly like a patient’s previous reviews or implicitly like a diagnosis history).
Content-based recommendations are primarily based on comparisons between items and user-assisted information. A variety of ancillary information can be considered, such as text, images, and videos. Hybrid models are recommendation systems that integrate two or more recommendation strategies. Solutions are usually divided into review-based recommendations [
17,
18,
19], deep learning recommendations [
20,
21], and attention mechanism recommendations [
22].
Collaborative filtering (CF) is the most widely used method in recommendation systems in recent years [
23]. Deep learning is also used to recommend meeting customers’ requirements through parallel neural networks, which are more explanatory. Deep learning are also favored by scholars for its simplicity and effectiveness.
Since our suggestions are merely words and sentences, our presSented recommendation system should be a content-based one [
12]. Our experiment samples are from Jinan University and advice contents were collected from experts. The advice was aimed at those who exercise a lot but still attain unsatisfactory physical examination results.
Sports [
24] can be divided into competitive, recreational, popular, school, and medical sports. Unlike competitive sports having a purpose of “faster, higher and stronger” and school sports emphasizing education scores, popular sports focus on meeting the demand of participants for fitness, heart, beauty, recreation, and medical treatment, which helps improve their physical health during exercise. It meets contemporary college students’ sports requirements, just like Barnett et al. [
25], who brought arts into sports. Improving physical condition and ensuring physical and mental health is the fundamental purpose of mass sports. As well as enriching the leisure life of college students, mass sports meet their fitness needs, shape their forms, and improve their physical condition through physical exercise. The satisfaction of the recreational needs of participants in popular sports is mainly manifested in their leisure time enrichment through various forms of content that are more interesting and less loaded. By satisfying the participants’ needs for fitness, heart, beauty, and recreation, mass sports attract the public, thus providing a guarantee for their physical and mental health, achieving physical and mental conditioning, reducing the occurrence of cardiovascular and cerebrovascular diseases [
26], and reducing the probability of sudden death in the study life of college students.
To best describe our paper, the four main contributions are listed as follows. Since the physical exercise recommendation systems are based on statistical principles and output through natural language processing, it is named SNPERS.
(1) We use natural language processing methods to eliminate and quantify words that have emotional overtones in the opinion text, and keep words that do not have emotional overtones. This would be less abrupt and mechanical when migrating opinions.
(2) We use statistical principles and the probabilistic drift property of the Poisson distribution for stabilizing conceptual drift in order to solve the problem that results may not be as expected due to environmental or other factors during exercise. Consequently, our system could make tiny adjustments to college students’ physical exercise programs in a timely fashion.
(3) We apply the fusedmax function to top-k suitable recommendation results of the recommendation system when quantifying the recommendation text.
(4) We set an efficient recommendation model with double-chain model correction and double-chain recommendation correction.
The rest of this paper is structured as follows.
Section 2 covers related work, which mainly outlines the state-of-the-art recommendation systems and physical exercise methods. The lack of current recommendation system use on physical exercise plan scheduling is stated.
Section 3 is the proposed method. In
Section 3, the significance and main implementation of the recommendation system is explained. We also discuss why Poisson distribution can be used for stabilizing conceptual drift.
Section 4 gives the experiment details combining recommendation systems and natural language processing models.
Section 5 presents the experimental results, proving that our models have better performance and stability compared with the current recommendation systems on physical exercise plan scheduling. Natural language processing models are also available.
Section 6 concludes our work and future work is given in
Section 7.
2. Related Work
This section introduces the development and usage of recommendation systems, some exercise issues, and reasons why recommendation systems could not be easily used in presenting suggestions. An overview of related works is shown in
Table 1.
2.1. Reviews of Recommendation System
Recommendation systems filter out features based on the users’ behaviors or interests to predict the users’ other interests and whether the users will like a particular product. The designer of the recommendation system hopes that the recommendation system will be beneficial and effective for all users. As for college students, regarding sports and exercise advice recommendations, it is suggested to recommend sports programs for college students based on their physical examination scores and exercise behaviors.
Gaspar et al. [
27] designed a recommendation system to help Spinal Cord Injuries (SCI) exercise. They considered studies classified as the substantial and moderate evidence and observed positive effects of aerobic, resistance, and combined exercise and gait training in body structure and function. Positive effects were observed in terms of activity and participation for gait training, balance training, and integrated interventions. In addition, they motivated SCI patients to exercise through a referral system.
Naumov et al. [
28] designed a recommendation model for personalization, which is more targeted compared to the algorithm presented by Gaspar et al. [
27]. Huang et al. [
29] conducted extensive experiments on two real-world datasets. It proved that their proposed DRE can effectively learn from the student interaction data to optimize multiple objectives in a single unified framework and recommend suitable exercise to students.
Hilberdink et al. [
30] implemented enhancements in supervised group exercise for people with axial spondyloarthritis. Furthermore, recommendation systems combining deep learning recommendations and attention mechanism recommendations (hybrid recommendations) are also worth studying, according to Gong and Yao [
31].
The above includes studies on medical recommended exercise programs, educational recommended exercise programs, and studies covering the various exercise purposes mentioned in the introduction. In conclusion, many studies have shown that recommendation systems for recommending exercise programs are feasible.
2.2. Factors Affecting Exercise’s Loads
Exercise intensity and length of time after exercise are significant factors. These two factors contain the following items.
- (1)
Strength: The size of the resistance to weight bearing.
- (2)
Number of groups: The number of times equipment was used.
- (3)
Number: The number of repetitions of the action in a group.
- (4)
Density: The length of rest time between each group.
- (5)
Action speed: Fast and slow action; fast for the development of explosive power, mixed speed for the growth of strength, and slow and medium speed is beneficial to the development of muscle.
Nutritional status performs an imperative role as well. It is recommended to supplement proper nutrition before and after exercise.
General physical conditions such as the adequacy of sleep, the presence of underlying diseases, and any recent illnesses also make sense.
2.3. Lack of Recommendation System
In practical applications, recommendation systems are widely used in significant fields and scenarios [
32] such as machine learning, deep learning, e-commerce, and shopping platforms. They have also been introduced to theoretical research and practical application in health and medicine. However, current recommendation system models on physical health have three major problems, as follows.
- (1)
When training the recommendation model, a large amount of user data needs to be collected. Since the internal security threat is high, the insiders may override the access and use of the data.
- (2)
The recommendation process might have some recommendation and identification mistakes due to an existing recommendation system. In reality, there are often misdiagnosis phenomena when it is taken into use, resulting in a narrow confidence interval and low credibility.
- (3)
The recommendation data multi-party collaborative use and update, and the existing recommendation systems work in a limited computational efficiency. These recommendation systems are bound to automatically make decisions in the future, which may cause more significant obstacles and threats.
According to the above considerations, the theoretical research and practical application of recommendation systems in sports will be limited to some extent. Accurate labeling of physical exercise recommendations for college students would be a challenge if they were to be provided by fitness practitioners who lack front-line physical education, making it difficult to utilize the large amount of data obtained from each diagnosis. It is not easy to quantify the recommendation text. Therefore, there are some limitations of input data that can be used to train the recommendation system, making it difficult to build a well-formed recommendation model.
Scholars tried to solve these problems. Focus on health education, Wang et al. [
33] used Natural Language Processing (NLP) techniques to provide personalized educational materials. Customized service is the biggest feature of their presented models. This is an earlier application of recommendation systems to physical health. Based on expert systems, Lechiakh and Maurer [
34] provided a recommendation framework for beneficial and personalized content. In their framework, users can control the quality of the trusted input data for training. Maintaining the important engagement rate, their framework has better content quality.
Currently, the most considerable limitation of the existing recommendation system models is that if students do not follow the plan one day (too much or too little), the recommendation system might still continue to implement the plan scheduled before, ignoring the impact of one plan not having been implemented on the subsequent plan implementation. This phenomenon belongs to probability drift, which might have limited performance in evaluation indexes like level, approaches, and focuses on aspect-based sentiment [
32]. A recommendation system able to stabilize the probability drift is proposed in this paper.
3. Proposed Method
This section presents how to eliminate and quantify emotion words, why and how we use statistical principles, how fusedmax is selected to work in our experiment, and the realizing of our double-chain recommendation network.
3.1. Extraction and Quantification of Emotion Words
A more general recommendation given by the traditional recommendation system may be as follows: an appropriate combination of exercises of a different nature, different intensities, and appropriate density, which can alternate exercise with high and low motor loads, such as a combination of less intense walking, throwing, and more intense running and jumping content. However, it is easy to see that this advice given is of limited relevance, as it is appropriate for most college students.
For the written suggestions, we extracted the sentiment words and used (1) as the quantitative value, where
d denotes the distance value of the studied indicator from the center of the Normal distribution graph in that sample, and
dmax denotes the maximum value of the distance value of the studied indicator from the center in all samples. The larger the value of
v, the stronger the strength of the recommendation. However, usually, the suggestions marked by experts may contain denying words. For instance, the sentence “Do not run every day” suggests rest instead of exercise. Therefore, denying words should be considered to judge the input and output the strength of suggestions.
Generally speaking, in the statistical interval of the number of denying words, when the count of denying words is even (please note that 0 is also even), positive emotion words are counted as positive emotion units, and negative emotion words are counted as negative emotion units; when the count is odd, positive emotion words are counted as negative emotion units, and negative emotion words are counted as positive emotion units. A quick sentiment reversing method is reversed by symmetry about the midpoint of the value range of the sentiment index. In mathematical language, it is twice the midpoint value minus the sentiment index to be reversed. The counting methods of denying words would be different with different emotion unit definition. The two major definitions go as follows, presented in this paper. One is based on intervals divided by emotion words, the other one is based on manual setting.
Emotion word processing with emotion words as the statistical interval of emotion words is possible. Identify the emotion words in the word segmentation results, and count the number of denying words including rhetorical questions between the current emotion word and the previous emotion word (if the current emotion word is the first emotion word that appears, count the number of denying words that appear in all the word segmentation units before the word). A calculation example is shown in description (a) of
Figure 1.
Negative word processing composed of several consecutive word segmentation units before and after emotion words to form the statistical interval of denying words is also insightful. After specifying the interval, we count the number of denying words including rhetorical questions appearing in the interval before and after the emotion words. A calculation example is shown in description (b) of
Figure 1, where the interval is set to [−3, 0]. Both of the methods can be used after words are turned into vectors by word2vec models like jieba, snownlp. Finally, based on Bert [
35], suggestions in natural language can be generated with different tone intensities of different physical levels.
3.2. Recommendation System Confidence Improvement
Confidence level, also known as reliability, or confidence coefficient, means that when a sample estimates the overall parameters, its conclusion is always uncertain due to the randomness of the sample. The span of the confidence interval is a positive function of the confidence level, i.e., the greater the required degree of certainty, the wider the confidence interval is bound to be obtained, which reduces the accuracy of the estimate accordingly. For example, assuming that the distribution is symmetric, if the support rate of a program in the diagnostic recommendation is 55%, the confidence interval on the confidence level 0.95 is (50%, 60%). There is a 95% chance that the proper support rate of the program falls between 50% and 60%, so the probability that the proper support rate of the recommended program is less than half is less than 2.5%.
Conceptual drift refers to the drift of labels of essentially the same data over time. It can be expressed in medical terms: when a recommendation system first presents a series of recommendations, the patient is subject to environmental and other factors that may cause the results not to match expectations (faster recovery, slower recovery, and deterioration). In this case, if the recommendation system is allowed to make re-recommendations in the treatment flow, it will inevitably waste the recommendation system’ computing resources. In the treatment process, using an algorithm that stabilizes the concept drift enhances the model fault tolerance and corrects the series of schemes recommended by the model, which can save the arithmetic resources and improve the accuracy by reducing the misclassification rate.
We introduce the Poisson distribution model with probabilistic drift property for random variables
to solve this problem. For any
and
satisfying
, for any
k greater than 1, let
, and we would have (2). Thus, we could conclude (3). Consequently,
is a strictly increasing function. This leads us to a more general generalization of (2). Furthermore, we would have (4). In addition,
is a strictly decreasing function on
. We apply the Poisson distribution, a property of probabilistic drift, to recommendation systems for patient recovery from disease processes that deviate from expected values, stabilizing the conceptual drift and improving model stability, leading to improved accuracy.
3.3. Fusedmax Function Performance
In published studies, the scholar who proposed the sparsemax function [
36] proved in his work that sparsemax is superior to softmax. Sparsemax is highly relevant for our study of recommendation systems for physical exercise advice. Assuming that a college student is temporarily unable to go running due to a severe sudden fall injury, the recommendation system should set the probability of the recommendation of running or jogging to 0 after receiving this message. However, the following mathematical projection proves that softmax cannot do so with a probability of 0. When the lung capacity of the college student is calculated to be unsatisfactory, the recommendation system will strongly recommend the student to participate in aerobic exercise. Thus, it leads to a ridiculous situation in which a college student who temporarily uses a wheelchair would be recommended to participate in long-distance running at this stage, as the likelihood of recommending long-distance running in softmax is multiplied by a larger factor than other recommendations.
The calculation of softmax is shown as (5), where e is the base of the natural logarithm. On the one hand, its numerator must be positive, so the fraction value is always greater than 0. On the other hand, for any positive variable
a and any positive variable
b, there is always
a+b>a. So, the denominator must be greater than the numerator, and the fraction value must be less than 1.
Fusedmax [
37], as an improvement of sparsemax in smoothing and interpretability, can achieve more desirable curves with two smoothing factors and has improved interpretability on three different and challenging tasks (text entailment, machine translation, and summarization) while achieving comparable or better accuracy. This function can be used for smoothing between sentences linking various aspects of the output solution of the recommendation system. We introduce fusedmax into the improved attention mechanism of the recommendation system to smooth the output function and use its value domain to reach 0 and 1 to remove self-contradictory, implausible, and severely erroneous recommendations that occur in motion recommendations and to achieve improved accuracy.
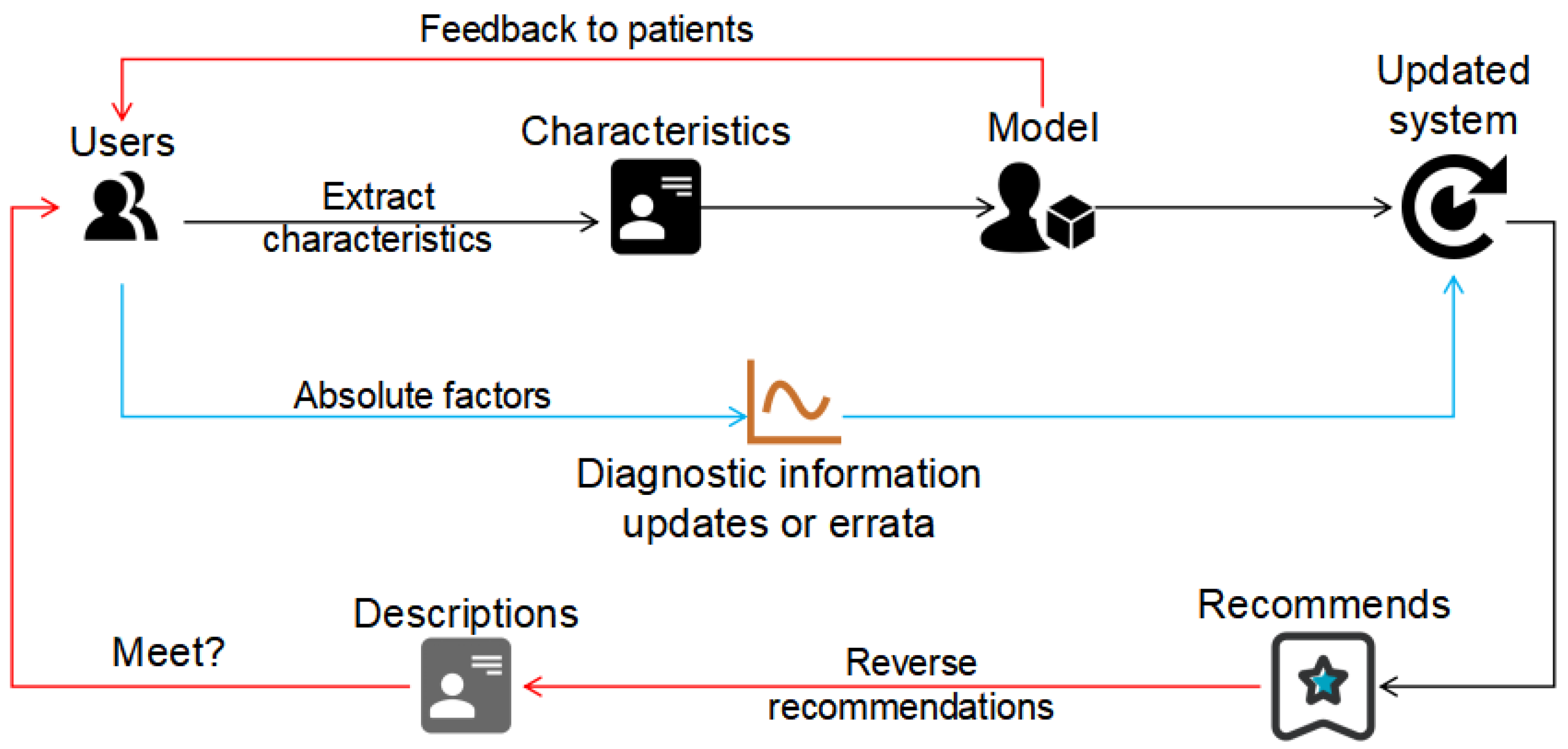
3.4. Double-Chain Feedback Mechanism
In general, many recommendation systems do not infer the actual situation of the referee from the opinion after a given conditional recommendation. If the recommendation is double-chain, absurd recommendations like those described above can be effectively excluded. Therefore, we optimized the existing recommendation system by adding a reverse recommendation, as shown in
Figure 2.
4. Experiment
Our samples are from School of Physical Education, Jinan University. There were a total of 18,101 samples in our datasets. Height, weight, lung capacity, long-distance running, short-distance running, sprinting, standing long jump, sit-ups (girls), pull-ups (boys), and visual acuity were considered. After the training of the original recommendation system model, the dataset was divided as shown in
Table 2.
Let’s take the example of the lung capacity of boys in the training set. There are 2696 male students in the training set. The average lung capacity is about 3924.57, the standard deviation is about 817.49, and the variance is nearly 668,287.25. After being tested by statistical analysis, the distribution can be approximated as satisfying a Normal distribution. Thus, three times the standard deviation is about 2452.47, and 1472.10 should be the minimum value. However, the minimum value of the dataset is 1192. Moreover, only one boy should be considered to improve lung capacity through additional exercise. According to (1), this is a sample that should be given suggestions. So, in the absence of exceptional circumstances, great emphasis needs to be placed on the boy’s ability to perform adequate aerobic exercise. Similarly, students whose difference from the mean lies between twice and three times the standard deviation need to be reminded to take aerobic exercise. The importance can be adjusted according to the calculated value of (1). It is worth mentioning that small probabilities of above-average events do not require advice in such physical examinations, as they perform pretty well in this regard.
It is also worth noting that designers can make their recommendation system more user-friendly by praising users who pass all physical examination items and achieve scores over in one or more particular physical examination items.
Similar recommendations can be made for the evaluation and recommendations of other physical examination items. The data survey of different physical indices is shown in
Table 3. The general evaluation of the students’ situation is the same as that in our experiments before they are scheduled to train. The datasets were collected from School of Physical Education, Jinan University. The data type is numeric.
We performed a statistical analysis of the given sample of 18,101 cases using the Normal distribution method to extract outliers exceeding and in each type of samples, which were subsequently given to the relevant experts for follow-up and written textual advice.
We initially set a recommendation system based on the above experiments and named it SNPERS, but it is not yet perfect. For example, strenuous exercise cannot be performed multiple times a day, and daily strenuous exercise may cause counterproductive effects. Another example is that most college students have reached adulthood, and their eye structure is basically formed, so their vision will no longer fluctuate significantly. Conservatively speaking, their myopias can hardly decrease. Chronic myopia of about 600 degrees will not return to normal vision within 5000 h after the recommendation because they adhere to the physical exercise recommended by the recommendation system every day. A double-chain feedback mechanism has been performed to optimize the recommendation system. It eliminates some absurd or practically impossible recommendation solutions by recommending back and forth.
5. Result
We have tested on extra datasets and found SNPERS to be better than traditional recommendation systems in the following aspects.
Figure 3 shows the reality and the prediction on lung capacity, where the red curve stands for prediction without Poisson, whereas the green curve stands for that with Poisson. In the natural environment, the student works better than both the two prediction results. Thus, there is a conceptual drift in this sample. Prediction with Poisson has fixed its prediction to a better lung capacity, proving to be a better recommendation system. We use
R2, shown as Equation (6), to evaluate, where SST means sum of squares total, SSR means sum of squares regression, and SSE means sum of squares error. Prediction without Poisson is 0.7186, whereas prediction with Poisson is 0.9178. The
R2 increased by about 27.72%.
Figure 4 shows the recommendations and predictions of realistic and with or without dual-chain recommendation systems for long-distance running. It is important to note that a negative value indicates no running or recommending rest on that day. To avoid too many points overlapping in a straight line, we used three negative values, different from each other, to separate rest days in the three cases. As is shown in
Figure 4, the studied college student failed to train for long-distance running precisely as the recommendation systems advised. According to the plan, there were a few days when he should have trained, but he did not.
Additionally, in that case, the more days the college student rested, the longer the days that the system would set for continuous running without the double-train feedback mechanism, which does not meet the requirements of physical exercise. The recommendation system with the mechanism would not schedule to run for more than five days continuously, even if it detects laziness on the part of the student, which is reasonable.
Moreover, when we look at the recommendation system with the double-chain feedback mechanism, we can easily find that the recommended work and rest time is regular (the college student would not be scheduled to run continuously for a long time and then rest for a long time). The predicted time consumption on long-distance running decreases with slight fluctuations, which agrees with reality.
Using SNPERS and the original recommendation system to recommend how college students should exercise respectively, we are able to help college students do targeted exercise.
Table 4 shows that SNPERS performs better than other recommendation systems.
After extraction and quantification of emotion words and fusedmax function performance, the output advice is available. As for textual suggestions, we have tested on various samples. A typical example is shown as follows.
Example: A female college student had a lacklustre sit-ups score and a failing long-distance running score. However, she needed home isolation because her city was at risk for COVID-19. She got the recommendation results after entering her physical examination scores and the circumstances of her quarantine into the physical exercise recommendation system.
Statistical principle only: You should keep running and sit-ups every day.
Traditional recommendation system: You should keep running long distance every day, and sit-ups are relatively minor.
SNPERS using softmax: You are supposed to practice long-distance running outside more often. If possible, please jog from now on.
SNPERS: Isolation at home is required for those affected by the COVID-19, but physical exercise, such as sit-ups, can be done at home. Please resume jogging after the quarantine period is finished.
The recommendation system based on statistical principles only gives a general suggestion. The traditional recommendation system compares the two results and provides suggestions. Using softmax, COVID-19 was considered. However, it could not absolutely delete the suggestions since, after all, the quantified factor of the word poor is excessively huge, even if it is multiplied by a tiny value of the possibility. So, SNPERS using fusedmax achieved a reasonable recommendation result.
6. Conclusions
A recommendation system is usually a hierarchical attention network with multi-level analysis. In this paper, we integrated statistical principles and natural language processing methods. SNPERS extracts and quantifies emotionally charged words in opinion texts to change the strength of recommendations in the output of the recommendation system. SNPERS also uses fusedmax to optimize the output of recommendations, building an efficient recommendation model with double-chain model correction and double-chain recommendation correction, which can make recommendations based on the positive recommendation system, judge whether the recommendation results are reasonable based on possibly harmful recommendations, and make corrections and optimizations to the recommendation system.
7. Future Work
The recommendation system presented in this paper also has some limitations. The physical examination items we considered were limited to height, weight, lung capacity, long-distance running, short-distance running, sprinting, standing long jump, sit-ups (girls), pull-ups (boys), and visual acuity. Furthermore, the examination samples’ covering range is still relatively small. Sentences generated by natural language processing may contain certain grammatical errors, which need to be corrected in the future. In addition, the optimization of tones of the output might be a valuable research point.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}