
ModDiff: Modularity Similarity-Based Malware Homologation Detection

Abstract
:1. Introduction
- We propose a binary program modularity algorithm that decomposes programs into function-based modules.
- We propose a method for detecting function similarity using Siamese BERT networks.
- We propose a module similarity detection method for detecting the similarity of binary program modules.
1.1. Motivating Example
1.2. Background Information
2. Related Work
2.1. Program Modularization
2.2. Binary Code Similarity Detection
3. Methodology
3.1. Overview
3.2. Binary Code Modularization
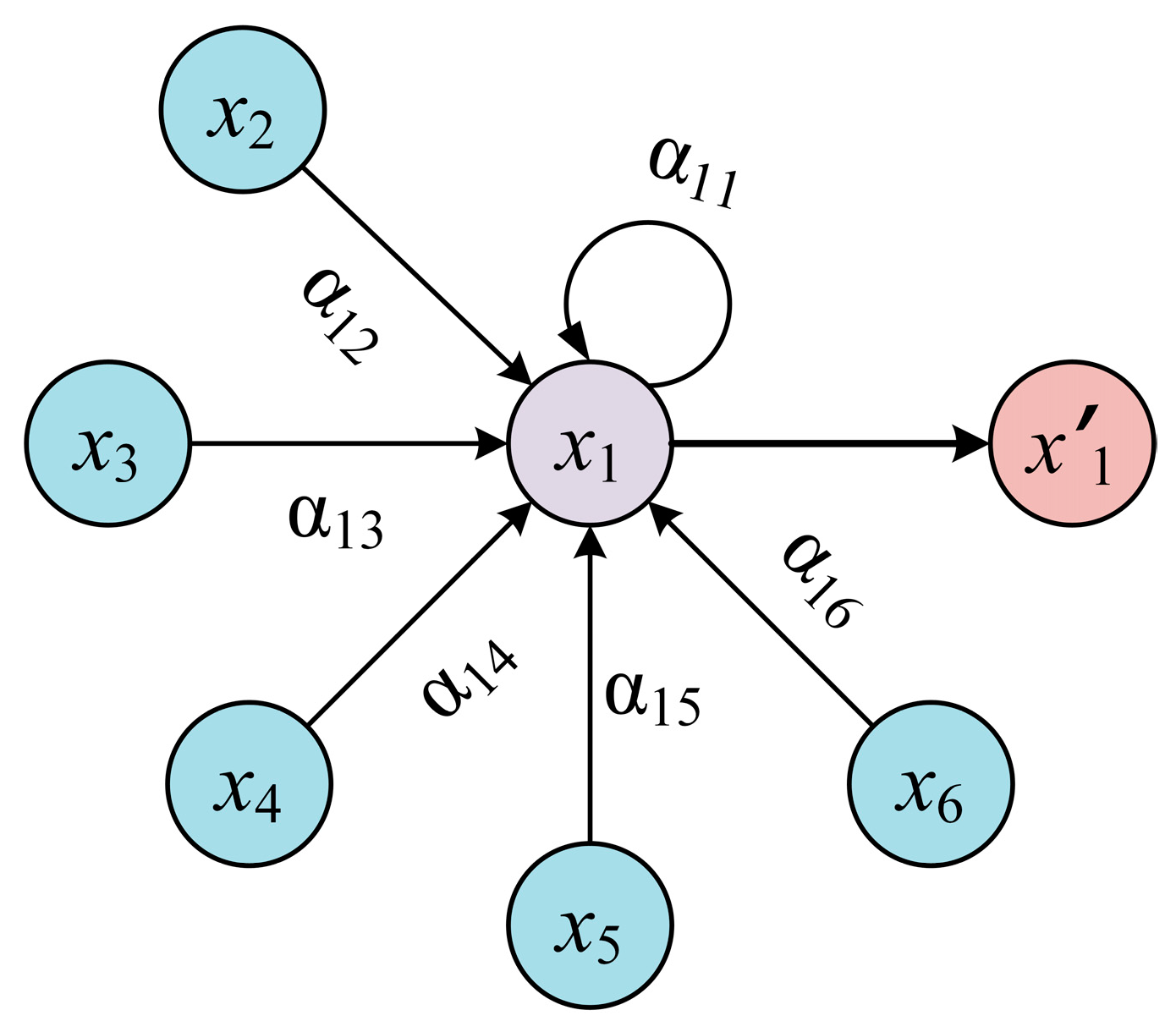
3.2.1. Attribute Graph Construction
3.2.2. Attribute Graph Embedding
3.2.3. Target-Oriented Node Clustering
3.3. Module Similarity Detection
3.3.1. Function Encoding via Siamese Network
3.3.2. Module Similarity Calculation
| Algorithm 1 Module similarity calculation algorithm | |
| Input: | |
| Output: | Module Similarity |
| 1: | if then |
| 2: | virtual nodes to X |
| 3: | for virtual node i in X do |
| 4: | Add virtual edges between virtual node i and all node in Y |
| 5: | Set the weight of new virtual edges to zero |
| 6: | end for |
| 7: | end if |
| 8: | Use KM algorithm to find an maximum weight matching M and maximum weight W for G |
| 9: | as the similarity of module X to module Y |
| 10: | as the similarity of module Y to module X |
4. Evaluation
4.1. Binary Code Modularization Evaluation (RQ1)
4.2. Homologation Detection Accuracy Evaluation (RQ2)
4.3. Robustness Evaluation (RQ3)
4.4. Scalability Evaluation (RQ4)
5. Discussion
5.1. Applications
5.2. Limitation and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- About Malware and Pua. Available online: https://portal.av-atlas.org/malware (accessed on 5 April 2023).
- Almomani, I.M.; Ahmed, M.; El-shafai, W. Android malware analysis in a nutshell. PLoS ONE 2022, 17, e0270647. [Google Scholar] [CrossRef] [PubMed]
- El-shafai, W.; Almomani, I.M.; Alkhayer, A. Visualized Malware Multi-Classification Framework Using Fine-Tuned CNN-Based Transfer Learning Models. Appl. Sci. 2021, 11, 6446. [Google Scholar] [CrossRef]
- Almomani, I.; Alkhayer, A.; El-Shafai, W. An Automated Vision-Based Deep Learning Model for Efficient Detection of Android Malware Attacks. IEEE Access 2022, 10, 2700–2720. [Google Scholar] [CrossRef]
- Haq, I.U.; Caballero, J. A Survey of Binary Code Similarity. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Duan, Y.; Li, X.; Wang, J.; Yin, H. DeepBinDiff: Learning Program-Wide Code Representations for Binary Diffing. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 23–26 February 2020. [Google Scholar]
- Xue, Y.; Xu, Z.; Chandramohan, M.; Liu, Y. Accurate and Scalable Cross-Architecture Cross-OS Binary Code Search with Emulation. IEEE Trans. Softw. Eng. 2019, 45, 1125–1149. [Google Scholar] [CrossRef]
- Xu, Y.; Xu, Z.; Chen, B.; Song, F.; Liu, Y.; Liu, T. Patch based vulnerability matching for binary programs. In Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing Analysis, Virtual Event, USA, 18–22 July 2020. [Google Scholar]
- Ding, S.H.H.; Fung, B.C.M.; Charland, P. Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 472–489. [Google Scholar] [CrossRef]
- Massarelli, L.; Luna, G.A.D.; Petroni, F.; Querzoni, L.; Baldoni, R. SAFE: Self-Attentive Function Embeddings for Binary Similarity. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, Saclay, France, 28–29 June 2018. [Google Scholar]
- Li, X.; Yu, Q.; Yin, H. PalmTree: Learning an Assembly Language Model for Instruction Embedding. In Proceedings of the ACM SIGSAC Conference on Computer Communications Security, Virtual Event, 15–19 November 2021. [Google Scholar]
- Wang, H.; Qu, W.; Katz, G.; Zhu, W.; Gao, Z.; Qiu, H.; Zhuge, J.; Zhang, C. jTrans: Jump-aware transformer for binary code similarity detection. In Proceedings of the 31st ACM SIGSOFT International Symposium on Software Testing Analysis, Seoul, Republic of Korea, 18–22 July 2022. [Google Scholar]
- Antonakakis, M.; April, T.; Bailey, M.; Bernhard, M.; Bursztein, E.; Cochran, J.; Durumeric, Z.; Halderman, J.A.; Invernizzi, L.; Kallitsis, M.; et al. Understanding the Mirai Botnet. In Proceedings of the USENIX Security Symposium, Vancouver, BC, Canada, 16–18 August 2017. [Google Scholar]
- GAFGYT. Available online: https://www.trendmicro.com/vinfo/us/threat-encyclopedia/malware/GAFGYT/ (accessed on 5 April 2023).
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.M.; LeCun, Y.; Moore, C.; Säckinger, E.; Shah, R. Signature Verification Using a “Siamese” Time Delay Neural Network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 669–688. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Sarhan, Q.I.; Ahmed, B.S.; Bures, M.; Zamli, K.Z. Software Module Clustering: An In-Depth Literature Analysis. IEEE Trans. Softw. Eng. 2022, 48, 1905–1928. [Google Scholar] [CrossRef]
- Xia, H.; Zhang, Y.; Chen, Y.; Zhang, H.; Wang, Z.; Wang, F. Software Module Clustering Using the Hierarchical Clustering Combination Method. In Proceedings of the 7th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), Chengdu, China, 22–24 April 2022; pp. 155–160. [Google Scholar] [CrossRef]
- Papachristou, M. Software clusterings with vector semantics and the call graph. In Proceedings of the 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Tallinn, Estonia, 26–30 August 2019. [Google Scholar]
- Pan, W.; Song, B.; Li, K.; Zhang, K. Identifying key classes in object-oriented software using generalized k-core decomposition. Future Gener. Comput. Syst. 2018, 81, 188–202. [Google Scholar] [CrossRef]
- Karande, V.; Chandra, S.; Lin, Z.; Caballero, J.; Khan, L.; Hamlen, K. BCD: Decomposing Binary Code into Components Using Graph-Based Clustering. In Proceedings of the Asia Conference on Computer and Communications Security, Incheon, Republic of Korea, 29 May 2018; pp. 393–398. [Google Scholar] [CrossRef]
- Newman, M.E. Fast algorithm for detecting community structure in networks. Phys. Rev. E Stat. Nonlin. Soft Matter Phys. 2004, 69 Pt 2, 066133. [Google Scholar] [CrossRef]
- Yang, C.; Xu, Z.; Chen, H.; Liu, Y.; Gong, X.; Liu, B. ModX: Binary Level Partially Imported Third-Party Library Detection via Program Modularization and Semantic Matching. In Proceedings of the 2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE), Pittsburgh, PA, USA, 25–27 May 2022; pp. 1393–1405. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Hex-Rays. IDA FLIRT. Available online: https://hex-rays.com/products/ida/tech/flirt/ (accessed on 5 April 2023).
- Eschweiler, S.; Yakdan, K.; Gerhards-Padilla, E. discovRE: Efficient Cross-Architecture Identification of Bugs in Binary Code. In Proceedings of the Network and Distributed System Security Symposium (NDSS 2016), San Diego, CA, USA, 21–24 February 2016. [Google Scholar]
- Dullien, T.; Rolles, R. Graph-based comparison of Executable Objects. Sstic 2005, 5, 3. [Google Scholar]
- Feng, Q.; Zhou, R.; Xu, C.; Cheng, Y.; Testa, B.; Yin, H. Scalable Graph-based Bug Search for Firmware Images. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016. [Google Scholar]
- Chandramohan, M.; Xue, Y.; Xu, Z.; Liu, Y.; Cho, C.Y.; Tan, H.B.K. BinGo: Cross-architecture cross-OS binary search. In Proceedings of the 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Seattle, WA, USA, 13–18 November 2016. [Google Scholar]
- Wang, S.; Wu, D. In-memory fuzzing for binary code similarity analysis. In Proceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering, Urbana, IL, USA, 30 October–3 November 2017. [Google Scholar]
- Xu, X.; Liu, C.; Feng, Q.; Yin, H.; Song, L.; Song, D.X. Neural Network-based Graph Embedding for Cross-Platform Binary Code Similarity Detection. In Proceedings of the ACM SIGSAC Conference on Computer Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Gao, J.; Yang, X.; Fu, Y.; Jiang, Y.; Sun, J. VulSeeker: A Semantic Learning Based Vulnerability Seeker for Cross-Platform Binary. In Proceedings of the 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 896–899. [Google Scholar] [CrossRef]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Levine; John, R. Linkers and Loaders. Acm Comput. Surv. 1999, 4, 149–167. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio’, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Xie, J.; Girshick, R.B.; Farhadi, A. Unsupervised Deep Embedding for Clustering Analysis. arXiv 2016, arXiv:1511.06335. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Gu, Y.; Shu, H.; Hu, F. UniASM: Binary Code Similarity Detection without Fine-tuning. arXiv 2022, arXiv:2211.01144. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Rokon, M.O.F.; Islam, R.; Darki, A.; Papalexakis, E.E.; Faloutsos, M. SourceFinder: Finding Malware Source-Code from Publicly Available Repositories in GitHub. In Proceedings of the 23rd International Symposium on Research in Attacks, Intrusions and Defenses (RAID 2020), San Sebastian, Spain, 14–16 October 2020; USENIX Association: Berkeley, CA, USA, 2020; pp. 149–163. [Google Scholar]
- MalwareBazaar. Available online: https://bazaar.abuse.ch/ (accessed on 5 April 2023).
- Zynamics BinDiff. Available online: https://www.zynamics.com/bindiff.html (accessed on 5 April 2023).
- Diaphora-A Free and Open Source Program Diffing Tool. Available online: http://diaphora.re/ (accessed on 5 April 2023).
- Xu, X.; Fan, M.; Jia, A.; Wang, Y.; Yan, Z.; Zheng, Q.; Liu, T. Revisiting the Challenges and Opportunities in Software Plagiarism Detection. In Proceedings of the IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER), London, ON, Canada, 18–21 February 2020; pp. 537–541. [Google Scholar] [CrossRef]
- Lin, G.; Wen, S.; Han, Q.L.; Zhang, J.; Xiang, Y. Software Vulnerability Detection Using Deep Neural Networks: A Survey. Proc. IEEE 2020, 108, 1825–1848. [Google Scholar] [CrossRef]
- Huang, Y.; Shu, H.; Kang, F. DeMal: Module decomposition of malware based on community discovery. Comput. Secur. 2022, 117, 102680. [Google Scholar] [CrossRef]
- Yadegari, B.; Johannesmeyer, B.; Whitely, B.; Debray, S. A Generic Approach to Automatic Deobfuscation of Executable Code. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 17–21 May 2015; pp. 674–691. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Family | Mirai | Gafgyt |
|---|---|---|
| MD5 | cd3b462b35d86fcc 26e4c1f50e421add | 4b94d1855b55fb26 fc88c150217dc16a |
| Popular threat label (VirusTotal) | Trojan.linux/mirai | Trojan.linux/gafgyt |
| File size | 160.84 KB | 95.79 KB |
| Original Instructions | Normalized Expression |
|---|---|
| Indirect addressing with register “eip/rip” | PTR |
| Indirect addressing with register “esp/rsp” | SSP |
| Indirect addressing with register “ebp/rbp” | SBP |
| Other indirect addressing | MEM |
| Relevant addressing | REL |
| Immediate number | NUM |
| Float instruction with register “xmm” | XMM |
| Conditional jump | cjmp |
| Dataset | Samples | Average Functions | Average Clusters | Average Size (KB) |
|---|---|---|---|---|
| S1 | 82 | 847 | 17 | 979 |
| S2 | 1056 | 931 | 16 | 883 |
| M1 | 728 | 256 | 13 | 325 |
| Dataset | Method | Prc | NMI | F1 |
|---|---|---|---|---|
| S1 | BCD | 0.623 | 0.505 | 0.641 |
| ModX | 0.648 | 0.547 | 0.687 | |
| ModDiff | 0.783 | 0.737 | 0.802 | |
| S2 | BCD | 0.539 | 0.498 | 0.589 |
| ModX | 0.592 | 0.512 | 0.635 | |
| ModDiff | 0.703 | 0.687 | 0.701 | |
| M1 | BCD | 0.539 | 0.513 | 0.557 |
| ModX | 0.571 | 0.532 | 0.633 | |
| ModDiff | 0.632 | 0.674 | 0.692 |
| O0 vs. O1 | O0 vs. O2 | O0 vs. O3 | Avg | |
|---|---|---|---|---|
| GCC | 0.83 | 0.76 | 0.65 | 0.75 |
| Clang | 0.81 | 0.72 | 0.60 | 0.71 |
| Datasets | Version | Binary Pairs | |
|---|---|---|---|
| Binutils | 2.30 | 2.40 | 16 |
| Coreutils | 6.6 | 9.0 | 97 |
| Diffutils | 2.9 | 3.8 | 4 |
| Findutils | 4.2 | 4.9 | 4 |
| Precision | Recall | F1 | |
|---|---|---|---|
| ModDiff | 0.94 | 0.92 | 0.93 |
| BinDiff | 0.90 | 0.80 | 0.85 |
| Diaphora | 0.91 | 0.85 | 0.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, H.; Shu, H.; Kang, F.; Guang, Y. ModDiff: Modularity Similarity-Based Malware Homologation Detection. Electronics 2023, 12, 2258. https://doi.org/10.3390/electronics12102258
Sun H, Shu H, Kang F, Guang Y. ModDiff: Modularity Similarity-Based Malware Homologation Detection. Electronics. 2023; 12(10):2258. https://doi.org/10.3390/electronics12102258
Chicago/Turabian StyleSun, Huaqi, Hui Shu, Fei Kang, and Yan Guang. 2023. "ModDiff: Modularity Similarity-Based Malware Homologation Detection" Electronics 12, no. 10: 2258. https://doi.org/10.3390/electronics12102258
APA StyleSun, H., Shu, H., Kang, F., & Guang, Y. (2023). ModDiff: Modularity Similarity-Based Malware Homologation Detection. Electronics, 12(10), 2258. https://doi.org/10.3390/electronics12102258