
An Evaluation of Link Prediction Approaches in Few-Shot Scenarios


Abstract
:1. Introduction
2. Related Work
2.1. Link Prediction
2.1.1. Translational Models
2.1.2. Product-Based Models
2.1.3. Neural-Network-Based Models
2.2. Few-Shot Link Prediction
2.3. Link Prediction in Semantic Model Creation
3. Selection of Approaches
3.1. Datasets
3.2. Comparison
3.3. Model Selection
4. Experiments
4.1. Evaluation Data
4.2. Evaluation
4.2.1. Performance
4.2.2. Grid Search
5. Discussion
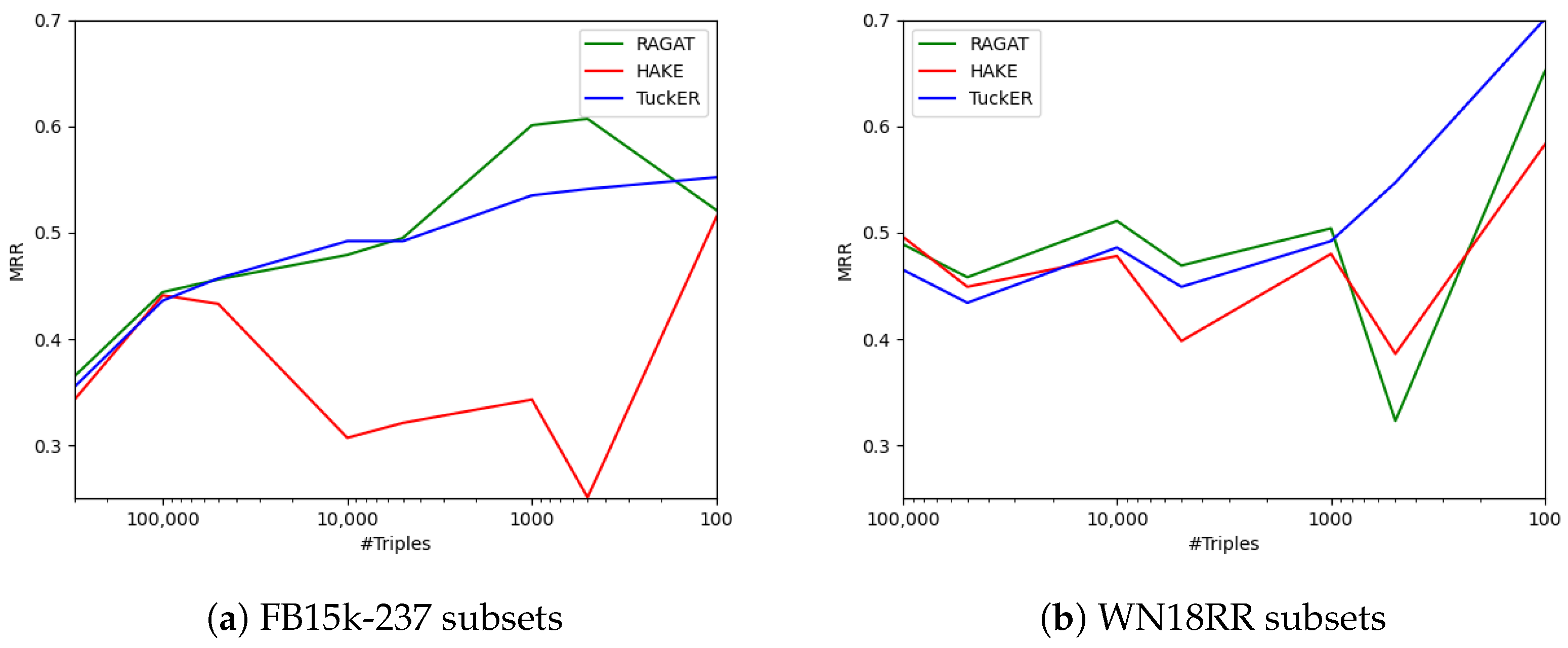
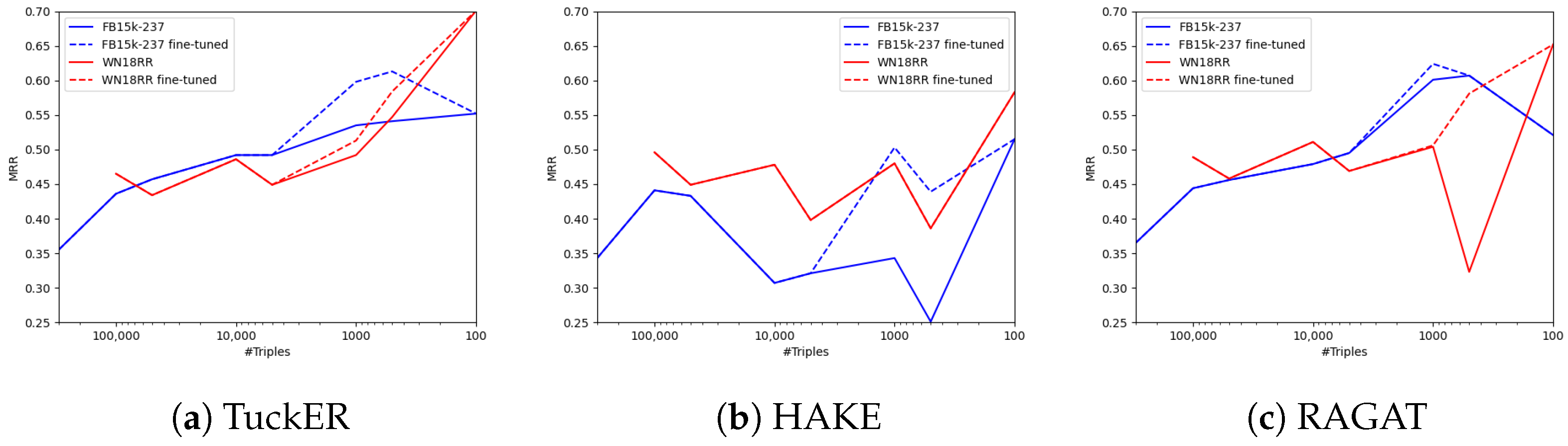
5.1. Performance Increase in Few-Shot Scenarios
5.2. RAGAT Performance Drop
5.3. HAKE Performance Gap
5.4. Comparison with Previous Studies
5.5. Summary
6. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Grid Search Parameters, Space, and Results
Appendix A.1. TuckER

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| lr | dr | edim | rdim | in_d | H_d1 | H_d2 | ls | batch |
|---|---|---|---|---|---|---|---|---|
| 0.0005 | 0.99 | 30 | 30 | 0.2 | 0.2 | 0.3 | 0 | 32 |
| 0.001 | 0.995 | 200 | 200 | 0.3 | 0.4 | 0.5 | 0.1 | 64 |
| 0.003 | 1 | - | - | 0.6 | 0.6 | 0.6 | - | 128 |
| 0.01 | - | - | - | 0.8 | 0.8 | 0.8 | - | - |
| Dataset | lr | dr | edim | rdim | in_d | H_d1 | H_d2 | ls | batch |
|---|---|---|---|---|---|---|---|---|---|
| FB15k-237 | 0.0005 | 1 | 200 | 200 | 0.3 | 0.4 | 0.5 | 0.1 | 128 |
| WN18RR | 0.003 | 1 | 200 | 30 | 0.2 | 0.2 | 0.3 | 0.1 | 128 |
| FB1k | 0.01 | 0.995 | 200 | 30 | 0.8 | 0.6 | 0.3 | 0.1 | 32 |
| FB500 | 0.01 | 0.99 | 200 | 200 | 0.3 | 0.8 | 0.6 | 0 | 64 |
| WN1k | 0.005 | 0.995 | 200 | 200 | 0.3 | 0.6 | 0.3 | 0 | 32 |
| WN500 | 0.01 | 0.99 | 200 | 200 | 0.6 | 0.6 | 0.3 | 0 | 64 |
Appendix A.2. HAKE
| batch | n | dim | lr | test_batch | mod_w | phase_w | ||
|---|---|---|---|---|---|---|---|---|
| 256 | 512 | 1000 | 9 | 1 | 0.01 | 16 | 4 | 4 |
| 128 | 256 | 500 | 6 | 0.5 | 0.001 | 8 | 3.5 | 2 |
| 64 | 64 | 125 | 3 | - | 0.00005 | - | 1 | 1 |
| - | - | - | - | - | - | - | 0.5 | 0.5 |
| Dataset | batch | n | dim | lr | test_batch | mod_w | phase_w | ||
|---|---|---|---|---|---|---|---|---|---|
| FB15k-237 | 512 | 256 | 1000 | 9 | 1 | 0.00005 | 16 | 3.5 | 1 |
| WN18RR | 512 | 512 | 500 | 6 | 0.5 | 0.00005 | 8 | 0.5 | 0.5 |
| FB1k | 256 | 256 | 500 | 6 | 1 | 0.001 | 8 | 1 | 4 |
| FB500 | 128 | 256 | 500 | 6 | 1 | 0.01 | 16 | 4 | 4 |
| WN1k | 128 | 64 | 500 | 3 | 1 | 0.001 | 16 | 1 | 1 |
| WN500 | 128 | 256 | 125 | 6 | 1 | 0.01 | 16 | 1 | 1 |
Appendix A.3. RAGAT
| gcn_drop | batch | ifeat_drop | ihid_drop | iker_sz | iperm | H |
|---|---|---|---|---|---|---|
| 0.3 | 256 | 0.2 | 0.3 | 5 | 1 | 1 |
| 0.4 | 128 | 0.4 | 0.5 | 7 | 2 | 2 |
| - | 64 | 0.6 | - | 9 | 4 | - |
| - | - | - | - | 11 | - | - |
| Dataset | gcn_drop | batch | ifeat_drop | ihid_drop | iker_sz | iperm | H |
|---|---|---|---|---|---|---|---|
| FB15k-237 | 0.4 | 256 | 0.2 | 0.3 | 11 | 1 | 1 |
| WN18RR | 0.4 | 1024 | 0.4 | 0.3 | 9 | 4 | 1 |
| FB1k | 0.3 | 64 | 0.6 | 0.5 | 11 | 1 | 2 |
| FB500 | 0.3 | 64 | 0.6 | 0.3 | 9 | 4 | 2 |
| WN1k | 0.3 | 64 | 0.4 | 0.3 | 5 | 1 | 2 |
| WN500 | 0.4 | 64 | 0.2 | 0.5 | 11 | 2 | 2 |
References
- Seagate; IDC. Rethink Data: Put More of Your Business Data to Work—From Edge to Cloud; Technical Report; Seagate Technology: Fremont, CA, USA, 2020. [Google Scholar]
- Halevy, A. Why Your Data Won’t Mix. Queue 2005, 3, 50–58. [Google Scholar] [CrossRef]
- Kamm, S.; Jazdi, N.; Weyrich, M. Knowledge Discovery in Heterogeneous and Unstructured Data of Industry 4.0 Systems: Challenges and Approaches. Procedia CIRP 2021, 104, 975–980. [Google Scholar] [CrossRef]
- Pomp, A.; Paulus, A.; Kirmse, A.; Kraus, V.; Meisen, T. Applying Semantics to Reduce the Time to Analytics within Complex Heterogeneous Infrastructures. Technologies 2018, 6, 86. [Google Scholar] [CrossRef]
- International Data Spaces Association. Reference Architecture Model: Version 3.0; International Data Spaces Association: Dortmund, Germany, 2019. [Google Scholar]
- GAIA-X European Association for Data and Cloud. Gaia-X Architecture Document. Available online: https://docs.gaia-x.eu/technical-committee/architecture-document/22.10/ (accessed on 14 May 2023).
- Paulus, A.; Pomp, A.; Poth, L.; Lipp, J.; Meisen, T. Recommending Semantic Concepts for Improving the Process of Semantic Modeling. In Proceedings of the Enterprise Information Systems—20th International Conference, ICEIS 2018, Funchal, Madeira, Portugal, 21–24 March 2018; Hammoudi, S., Smialek, M., Camp, O., Filipe, J., Eds.; Revised Selected PapersLecture Notes in Business Information Processing. Springer: Berlin, Germany, 2018; Volume 363, pp. 350–369. [Google Scholar] [CrossRef]
- Studer, R.; Benjamins, V.R.; Fensel, D. Knowledge Engineering: Principles and Methods. Data Knowl. Eng. 1998, 25, 161–197. [Google Scholar] [CrossRef]
- Futia, G.; Vetrò, A.; Martin, J.C.D. SeMi: A SEmantic Modeling machIne to build Knowledge Graphs with graph neural networks. SoftwareX 2020, 12, 100516. [Google Scholar] [CrossRef]
- Paulus, A.; Burgdorf, A.; Puleikis, L.; Langer, T.; Pomp, A.; Meisen, T. PLASMA: Platform for Auxiliary Semantic Modeling Approaches. In Proceedings of the 23rd International Conference on Enterprise Information Systems, ICEIS 2021, Online Streaming, 26–28 April 2021; Filipe, J., Smialek, M., Brodsky, A., Hammoudi, S., Eds.; SCITEPRESS: Setúbal, Portugal, 2021; Volume 2, pp. 403–412. [Google Scholar] [CrossRef]
- Paulus, A.; Burgdorf, A.; Stephan, A.; Pomp, A.; Meisen, T. Using Node Embeddings to Generate Recommendations for Semantic Model Creation. In Proceedings of the ICEIS 2022—24th International Conference on Enterprise Information Systems, Online, 25–27 April 2022. [Google Scholar] [CrossRef]
- Paulus, A.; Burgdorf, A.; Pomp, A.; Meisen, T. Collaborative Filtering Recommender System for Semantic Model Refinement. In Proceedings of the 2023 IEEE 17th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 1–3 February 2023. [Google Scholar]
- Sun, Z.; Deng, Z.; Nie, J.; Tang, J. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Parnami, A.; Lee, M. Learning from Few Examples: A Summary of Approaches to Few-Shot Learning. arXiv 2022, arXiv:2203.04291. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; Burges, C.J.C., Bottou, L., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates Inc.: Hook, NY, USA, 2013; pp. 2787–2795. [Google Scholar]
- Zhang, Z.; Cai, J.; Zhang, Y.; Wang, J. Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar] [CrossRef]
- Balazevic, I.; Allen, C.; Hospedales, T.M. Hypernetwork Knowledge Graph Embeddings. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2019: Workshop and Special Sessions: 28th International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; Springer: Berlin, Germany, 2019; pp. 553–565. [Google Scholar]
- Nathani, D.; Chauhan, J.; Sharma, C.; Kaul, M. Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs. arXiv 2019, arXiv:1906.01195. [Google Scholar]
- Ali, M.; Berrendorf, M.; Hoyt, C.T.; Vermue, L.; Galkin, M.; Sharifzadeh, S.; Fischer, A.; Tresp, V.; Lehmann, J. Bringing Light Into the Dark: A Large-scale Evaluation of Knowledge Graph Embedding Models under a Unified Framework. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8825–8845. [Google Scholar] [CrossRef]
- Nickel, M.; Tresp, V.; Kriegel, H. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011; Getoor, L., Scheffer, T., Eds.; Omnipress: Madison, WI, USA, 2011; pp. 809–816. [Google Scholar]
- Balazevic, I.; Allen, C.; Hospedales, T.M. TuckER: Tensor Factorization for Knowledge Graph Completion. arXiv 2019, arXiv:1901.09590. [Google Scholar]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Bengio, Y., LeCun, Y., Eds.; Conference Track Proceedings. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex Embeddings for Simple Link Prediction. arXiv 2016, arXiv:1606.06357. [Google Scholar]
- Nickel, M.; Rosasco, L.; Poggio, T.A. Holographic Embeddings of Knowledge Graphs. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Schuurmans, D., Wellman, M.P., Eds.; AAAI Press: Washington, DC, USA, 2016; pp. 1955–1961. [Google Scholar]
- Hayashi, K.; Shimbo, M. On the Equivalence of Holographic and Complex Embeddings for Link Prediction. arXiv 2017, arXiv:1702.05563. [Google Scholar]
- Zhang, S.; Tay, Y.; Yao, L.; Liu, Q. Quaternion Knowledge Graph Embeddings. arXiv 2019, arXiv:1904.10281. [Google Scholar]
- Tucker, L.R. The Extension of Factor Analysis to Three-Dimensional Matrices; Holt, Rinehart and Winston: New York, NY, USA, 1964; pp. 110–127. [Google Scholar]
- Kazemi, S.M.; Poole, D. SimplE Embedding for Link Prediction in Knowledge Graphs. arXiv 2018, arXiv:1802.04868. [Google Scholar]
- Hitchcock, F.L. The expression of a tensor or a polyadic as a sum of products. J. Math. Phys. 1927, 6, 164–189. [Google Scholar] [CrossRef]
- Sun, Z.; Vashishth, S.; Sanyal, S.; Talukdar, P.P.; Yang, Y. A Re-evaluation of Knowledge Graph Completion Methods. arXiv 2019, arXiv:1911.03903. [Google Scholar]
- Wang, M.; Qiu, L.; Wang, X. A Survey on Knowledge Graph Embeddings for Link Prediction. Symmetry 2021, 13, 485. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural Message Passing for Quantum Chemistry. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; Proceedings of Machine Learning Research. PMLR: New York City, NY, USA, 2017; Volume 70, pp. 1263–1272. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; van den Berg, R.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In Proceedings of the The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; Proceedings 15. Springer: Berlin, Germany, 2018; pp. 593–607. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D Knowledge Graph Embeddings. arXiv 2017, arXiv:1707.01476. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D.Q. A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network. arXiv 2017, arXiv:1712.02121. [Google Scholar]
- Shang, C.; Tang, Y.; Huang, J.; Bi, J.; He, X.; Zhou, B. End-to-end Structure-Aware Convolutional Networks for Knowledge Base Completion. arXiv 2018, arXiv:1811.04441. [Google Scholar] [CrossRef]
- Ye, R.; Li, X.; Fang, Y.; Zang, H.; Wang, M. A Vectorized Relational Graph Convolutional Network for Multi-Relational Network Alignment. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19), Macao, China, 10–16 August 2019. [Google Scholar] [CrossRef]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Talukdar, P.P. Composition-based Multi-Relational Graph Convolutional Networks. arXiv 2019, arXiv:1911.03082. [Google Scholar]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Agrawal, N.; Talukdar, P. InteractE: Improving Convolution-based Knowledge Graph Embeddings by Increasing Feature Interactions. arXiv 2019, arXiv:1911.00219. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Liu, X.; Tan, H.; Chen, Q.; Lin, G. RAGAT: Relation Aware Graph Attention Network for Knowledge Graph Completion. IEEE Access 2021, 9, 20840–20849. [Google Scholar] [CrossRef]
- Rossi, A.; Barbosa, D.; Firmani, D.; Matinata, A.; Merialdo, P. Knowledge Graph Embedding for Link Prediction: A Comparative Analysis. arXiv 2021, arXiv:2002.00819. [Google Scholar] [CrossRef]
- Ferrari, I.; Frisoni, G.; Italiani, P.; Moro, G.; Sartori, C. Comprehensive Analysis of Knowledge Graph Embedding Techniques Benchmarked on Link Prediction. Electronics 2022, 11, 3866. [Google Scholar] [CrossRef]
- Xiong, W.; Yu, M.; Chang, S.; Guo, X.; Wang, W.Y. One-Shot Relational Learning for Knowledge Graphs. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2018; pp. 1980–1990. [Google Scholar] [CrossRef]
- Chen, M.; Zhang, W.; Zhang, W.; Chen, Q.; Chen, H. Meta Relational Learning for Few-Shot Link Prediction in Knowledge Graphs. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 4216–4225. [Google Scholar] [CrossRef]
- Sheng, J.; Guo, S.; Chen, Z.; Yue, J.; Wang, L.; Liu, T.; Xu, H. Adaptive Attentional Network for Few-Shot Knowledge Graph Completion. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2020; pp. 1681–1691. [Google Scholar] [CrossRef]
- Taheriyan, M.; Knoblock, C.A.; Szekely, P.; Ambite, J.L. Learning the semantics of structured data sources. J. Web Semant. 2016, 37–38, 152–169. [Google Scholar] [CrossRef]
- Toutanova, K.; Chen, D. Observed versus latent features for knowledge base and text inference. In Proceedings of the 3rd Workshop on Continuous Vector Space Models and their Compositionality, Beijing, China, 26–31 July 2015; Association for Computational Linguistics: Cedarville, OH, USA, 2015. [Google Scholar] [CrossRef]
- Ruffinelli, D.; Broscheit, S.; Gemulla, R. You CAN Teach an Old Dog New Tricks! On Training Knowledge Graph Embeddings. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Brodley, C.E., Stone, P., Eds.; AAAI Press: Washington, DC, USA, 2014; pp. 1112–1119. [Google Scholar]
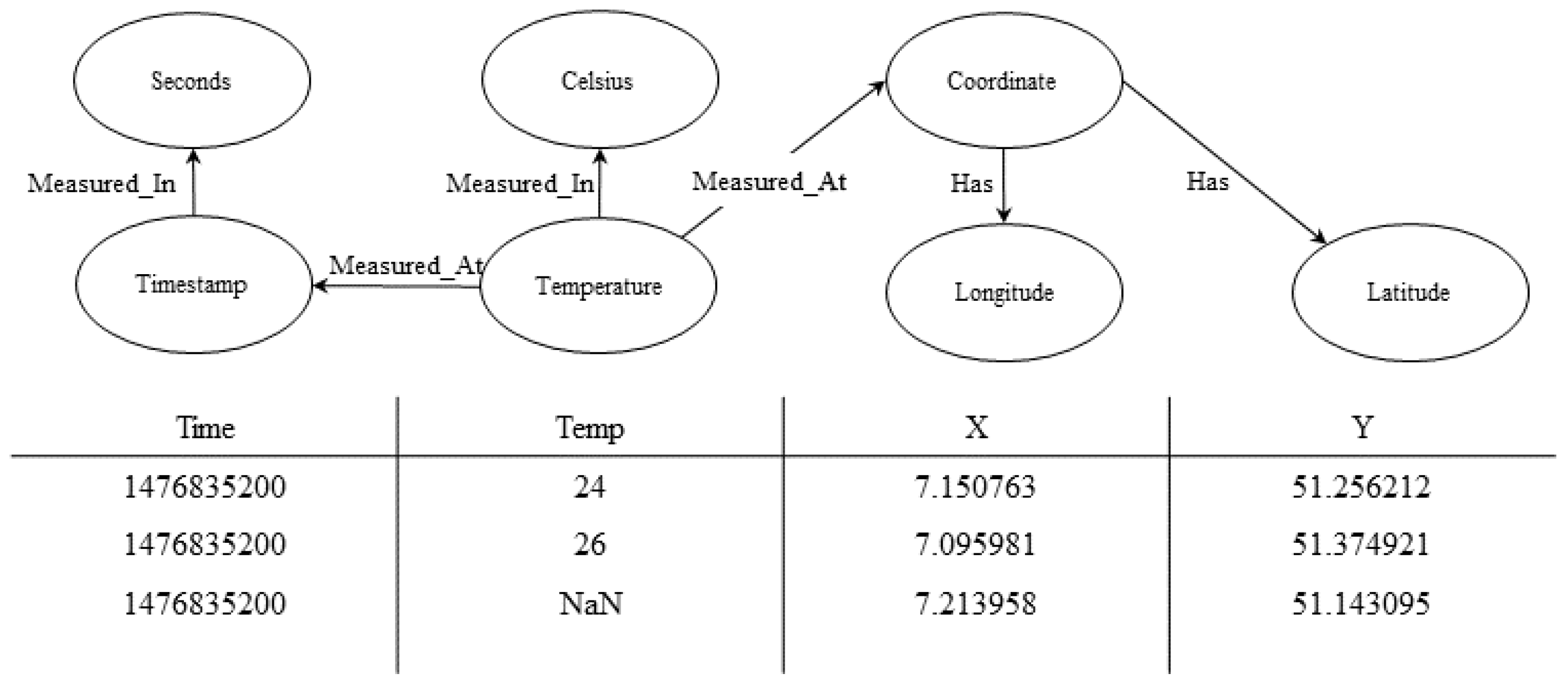
| Time | Temp | X | Y |
|---|---|---|---|
| 1476835200 | 24 | 7.150763 | 51.256212 |
| 1476835200 | 26 | 7.095981 | 51.374921 |
| 1476835200 | NaN | 7.213958 | 51.143095 |
| Dataset | # Entities | # Relations | # Triples |
|---|---|---|---|
| FB15k [15] | 14,951 | 1345 | 592,213 |
| FB15k-237 [49] | 14,541 | 237 | 310,116 |
| WN18 [15] | 40,943 | 18 | 151,442 |
| WN18RR [35] | 40,943 | 11 | 93,003 |
| FB15k-237 | WN18RR | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Cat. | MRR | Hits@1 | Hits@3 | Hits@10 | MRR | Hits@1 | Hits@3 | Hits@10 |
| RESCAL [20,50] | P | 0.356 | 0.263 | 0.393 | 0.541 | 0.467 | 0.439 | 0.480 | 0.517 |
| TransE [15,50] | T | 0.313 | 0.221 | 0.347 | 0.497 | 0.228 | 0.053 | 0.368 | 0.520 |
| DistMult [22,50] | P | 0.343 | 0.250 | 0.378 | 0.531 | 0.452 | 0.413 | 0.466 | 0.530 |
| ComplEx [23,50] | P | 0.348 | 0.253 | 0.384 | 0.536 | 0.475 | 0.438 | 0.490 | 0.547 |
| R-GCN [34] | N | 0.151 | 0.264 | 0.417 | - | - | - | - | |
| ConvE [35,50] | N | 0.339 | 0.248 | 0.369 | 0.521 | 0.442 | 0.411 | 0.451 | 0.504 |
| ConvKB [18,36] | N | 0.289 | 0.198 | 0.324 | 0.471 | 0.265 | 0.058 | 0.445 | 0.558 |
| SimplE [28,31] | P | 0.162 | 0.09 | 0.17 | 0.317 | - | - | - | - |
| HypER [17] | N | 0.341 | 0.252 | 0.376 | 0.520 | 0.465 | 0.436 | 0.516 | 0.582 |
| SACN [37] | N | 0.350 | 0.26 | 0.39 | 0.54 | 0.47 | 0.43 | 0.48 | 0.54 |
| RotatE [13] | T | 0.338 | 0.241 | 0.375 | 0.533 | 0.476 | 0.428 | 0.492 | 0.571 |
| QuatE [26] | P | 0.348 | 0.248 | 0.382 | 0.550 | 0.488 | 0.438 | 0.508 | 0.582 |
| TuckER [21] | P | 0.358 | 0.266 | 0.394 | 0.544 | 0.47 | 0.443 | 0.482 | 0.526 |
| CrossE [16] | P | 0.299 | 0.211 | 0.331 | 0.474 | - | - | - | - |
| VR-GCN [38] | N | 0.248 | 0.159 | 0.272 | 0.432 | - | - | - | - |
| CompGCN [39] | N | 0.355 | 0.264 | 0.390 | 0.535 | 0.479 | 0.443 | 0.494 | 0.546 |
| Fixed KBGAT [30] | N | 0.157 | - | - | 0.331 | 0.412 | - | - | 0.554 |
| HAKE [16] | T | 0.346 | 0.250 | 0.381 | 0.542 | 0.497 | 0.452 | 0.516 | 0.582 |
| InteractE [40] | N | 0.354 | 0.263 | - | 0.535 | 0.463 | 0.43 | - | 0.528 |
| RAGAT [42] | N | 0.365 | 0.273 | 0.401 | 0.547 | 0.489 | 0.452 | 0.503 | 0.562 |
| Identifier | Triples | Entities | Relations | # Training | # Validation | # Test |
|---|---|---|---|---|---|---|
| FB15k-237 | 310,116 | 14,541 | 237 | 272,115 | 17,535 | 20,466 |
| FB100k | 100,028 | 11,459 | 226 | 85,025 | 7449 | 7554 |
| FB50k | 50,040 | 9820 | 223 | 42,529 | 3705 | 3806 |
| FB10k | 10,435 | 5786 | 169 | 8884 | 743 | 808 |
| FB5k | 5019 | 2807 | 91 | 4269 | 359 | 391 |
| FB1k | 1016 | 585 | 31 | 867 | 69 | 80 |
| FB500 | 510 | 399 | 29 | 438 | 32 | 40 |
| FB100 | 109 | 60 | 26 | 95 | 4 | 10 |
| WN18RR | 93,003 | 11 | 40,943 | 86,835 | 3034 | 3134 |
| WN50k | 50,003 | 25,386 | 11 | 42,503 | 3747 | 3753 |
| WN10k | 10,005 | 6131 | 11 | 8505 | 748 | 752 |
| WN5k | 5005 | 3347 | 11 | 4252 | 372 | 379 |
| WN1k | 1001 | 672 | 7 | 850 | 75 | 76 |
| WN500 | 508 | 340 | 9 | 432 | 35 | 41 |
| WN100 | 109 | 63 | 6 | 94 | 7 | 8 |
| Dataset | Model | MRR | Hits@1 | Hits@3 | Hits@5 | Hits@10 |
|---|---|---|---|---|---|---|
| TuckER | 0.436 | 0.324 | 0.495 | 0.568 | 0.658 | |
| FB100k | HAKE | 0.441 | 0.323 | 0.511 | 0.583 | 0.663 |
| RAGAT | 0.444 | 0.333 | 0.504 | 0.575 | 0.658 | |
| TuckER | 0.47 | 0.443 | 0.482 | - | 0.526 | |
| WN18RR | HAKE | 0.497 | 0.452 | 0.516 | - | 0.582 |
| RAGAT | 0.489 | 0.452 | 0.503 | - | 0.562 | |
| TuckER | 0.457 | 0.36 | 0.511 | 0.572 | 0.639 | |
| FB50k | HAKE | 0.433 | 0.332 | 0.492 | 0.555 | 0.617 |
| RAGAT | 0.456 | 0.36 | 0.509 | 0.571 | 0.639 | |
| TuckER | 0.434 | 0.418 | 0.441 | 0.451 | 0.466 | |
| WN50k | HAKE | 0.449 | 0.419 | 0.459 | 0.48 | 0.507 |
| RAGAT | 0.458 | 0.429 | 0.47 | 0.489 | 0.514 | |
| TuckER | 0.492 | 0.426 | 0.527 | 0.568 | 0.621 | |
| FB10k | HAKE | 0.307 | 0.25 | 0.332 | 0.376 | 0.416 |
| RAGAT | 0.479 | 0.408 | 0.515 | 0.562 | 0.608 | |
| TuckER | 0.486 | 0.472 | 0.494 | 0.499 | 0.51 | |
| WN10k | HAKE | 0.478 | 0.463 | 0.48 | 0.489 | 0.508 |
| RAGAT | 0.511 | 0.485 | 0.52 | 0.537 | 0.557 | |
| TuckER | 0.492 | 0.425 | 0.529 | 0.566 | 0.623 | |
| FB5k | HAKE | 0.321 | 0.27 | 0.344 | 0.373 | 0.423 |
| RAGAT | 0.495 | 0.423 | 0.535 | 0.582 | 0.637 | |
| TuckER | 0.449 | 0.418 | 0.476 | 0.491 | 0.5 | |
| WN5k | HAKE | 0.398 | 0.376 | 0.398 | 0.42 | 0.45 |
| RAGAT | 0.469 | 0.429 | 0.484 | 0.517 | 0.544 | |
| TuckER | 0.535 | 0.45 | 0.588 | 0.663 | 0.681 | |
| FB1k | HAKE | 0.343 | 0.269 | 0.388 | 0.413 | 0.444 |
| RAGAT | 0.601 | 0.538 | 0.638 | 0.669 | 0.706 | |
| TuckER | 0.492 | 0.467 | 0.493 | 0.513 | 0.533 | |
| WN1k | HAKE | 0.48 | 0.461 | 0.493 | 0.5 | 0.507 |
| RAGAT | 0.504 | 0.474 | 0.507 | 0.539 | 0.572 | |
| TuckER | 0.541 | 0.488 | 0.575 | 0.638 | 0.65 | |
| FB500 | HAKE | 0.251 | 0.2 | 0.25 | 0.275 | 0.3 |
| RAGAT | 0.607 | 0.55 | 0.613 | 0.7 | 0.7 | |
| TuckER | 0.547 | 0.524 | 0.549 | 0.549 | 0.573 | |
| WN500 | HAKE | 0.386 | 0.378 | 0.378 | 0.39 | 0.39 |
| RAGAT | 0.323 | 0.244 | 0.353 | 0.409 | 0.465 | |
| TuckER | 0.552 | 0.45 | 0.6 | 0.6 | 0.7 | |
| FB100 | HAKE | 0.515 | 0.45 | 0.55 | 0.55 | 0.6 |
| RAGAT | 0.521 | 0.4 | 0.55 | 0.6 | 0.6 | |
| TuckER | 0.701 | 0.688 | 0.688 | 0.688 | 0.75 | |
| WN100 | HAKE | 0.583 | 0.5 | 0.625 | 0.688 | 0.875 |
| RAGAT | 0.652 | 0.625 | 0.625 | 0.625 | 0.813 |
| Dataset | Model | Configuration | MRR | Hits@1 | Hits@3 | Hits@5 | Hits@10 |
|---|---|---|---|---|---|---|---|
| FB1k | TuckER | Original | 0.535 | 0.45 | 0.588 | 0.623 | 0.681 |
| TuckER | Grid Search | 0.598 | 0.531 | 0.631 | 0.681 | 0.713 | |
| HAKE | Original | 0.343 | 0.269 | 0.388 | 0.413 | 0.444 | |
| HAKE | Grid Search | 0.503 | 0.431 | 0.55 | 0.569 | 0.613 | |
| RAGAT | Original | 0.601 | 0.536 | 0.638 | 0.669 | 0.706 | |
| RAGAT | Grid Search | 0.624 | 0.569 | 0.638 | 0.675 | 0.7 | |
| TuckER | Original | 0.541 | 0.488 | 0.575 | 0.638 | 0.65 | |
| TuckER | Grid Search | 0.613 | 0.588 | 0.625 | 0.65 | 0.65 | |
| FB500 | HAKE | Original | 0.439 | 0.375 | 0.475 | 0.488 | 0.55 |
| RAGAT | Original | 0.607 | 0.55 | 0.613 | 0.7 | 0.7 | |
| RAGAT | Grid Search | 0.606 | 0.55 | 0.613 | 0.65 | 0.688 | |
| TuckER | Original | 0.492 | 0.467 | 0.493 | 0.513 | 0.533 | |
| TuckER | Grid Search | 0.513 | 0.493 | 0.513 | 0.533 | 0.566 | |
| WN1k | HAKE | Original | 0.48 | 0.461 | 0.493 | 0.5 | 0.507 |
| RAGAT | Original | 0.504 | 0.474 | 0.507 | 0.539 | 0.572 | |
| RAGAT | Grid Search | 0.506 | 0.474 | 0.507 | 0.539 | 0.572 | |
| TuckER | Original | 0.547 | 0.524 | 0.549 | 0.549 | 0.573 | |
| TuckER | Grid Search | 0.584 | 0.573 | 0.585 | 0.585 | 0.598 | |
| WN500 | HAKE | Original | 0.386 | 0.378 | 0.378 | 0.39 | 0.39 |
| RAGAT | Original | 0.323 | 0.244 | 0.353 | 0.409 | 0.465 | |
| RAGAT | Grid Search | 0.581 | 0.549 | 0.585 | 0.585 | 0.646 |
| Category | hpt | tph |
|---|---|---|
| n − n | ≥1.5 | ≥1.5 |
| 1 − 1 | <1.5 | <1.5 |
| n − 1 | ≥1.5 | <1.5 |
| 1 − n | <1.5 | ≥1.5 |
| Dataset | # n − n | # n − 1 | # 1 − n | # 1 − 1 |
|---|---|---|---|---|
| FB15k-237 | 72% | 21% | 6% | 1% |
| FB100k | 72% | 17% | 10% | 1% |
| FB50k | 65% | 20% | 13% | 2% |
| FB10k | 26% | 47% | 24% | 2% |
| FB5k | 33% | 35% | 27% | 5% |
| FB1k | 39% | 39% | 20% | 3% |
| FB500 | 28% | 0% | 73% | 0% |
| FB100 | 50% | 20% | 30% | 0% |
| WN18RR | 36% | 47% | 15% | 1% |
| WN50k | 43% | 42% | 14% | 2% |
| WN10k | 47% | 44% | 7% | 2% |
| WN5k | 39% | 28% | 32% | 2% |
| WN1k | 50% | 45% | 0% | 5% |
| WN500 | 37% | 0% | 41% | 22% |
| WN100 | 62% | 38% | 0% | 0% |
| Dataset | Category | MRR | Hits@1 | Hits@3 | Hits@5 | Hits@10 |
|---|---|---|---|---|---|---|
| FB500 | Head | 0.931 | 0.9 | 0.95 | 0.975 | 0.975 |
| Tail | 0.283 | 0.2 | 0.275 | 0.425 | 0.425 | |
| Average | 0.607 | 0.55 | 0.613 | 0.7 | 0.7 | |
| WN500 | Head | 0.452 | 0.354 | 0.475 | 0.568 | 0.672 |
| Tail | 0.195 | 0.135 | 0.232 | 0.251 | 0.258 | |
| Average | 0.323 | 0.244 | 0.353 | 0.409 | 0.465 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Braken, R.; Paulus, A.; Pomp, A.; Meisen, T. An Evaluation of Link Prediction Approaches in Few-Shot Scenarios. Electronics 2023, 12, 2296. https://doi.org/10.3390/electronics12102296
Braken R, Paulus A, Pomp A, Meisen T. An Evaluation of Link Prediction Approaches in Few-Shot Scenarios. Electronics. 2023; 12(10):2296. https://doi.org/10.3390/electronics12102296
Chicago/Turabian StyleBraken, Rebecca, Alexander Paulus, André Pomp, and Tobias Meisen. 2023. "An Evaluation of Link Prediction Approaches in Few-Shot Scenarios" Electronics 12, no. 10: 2296. https://doi.org/10.3390/electronics12102296