
Improving Norwegian Translation of Bicycle Terminology Using Custom Named-Entity Recognition and Neural Machine Translation


Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. Dataset Generation
3.2. Implementation of the Language-Translation Tool
3.2.1. Custom NER Model
3.2.2. Neural Machine Translation (NMT) Model
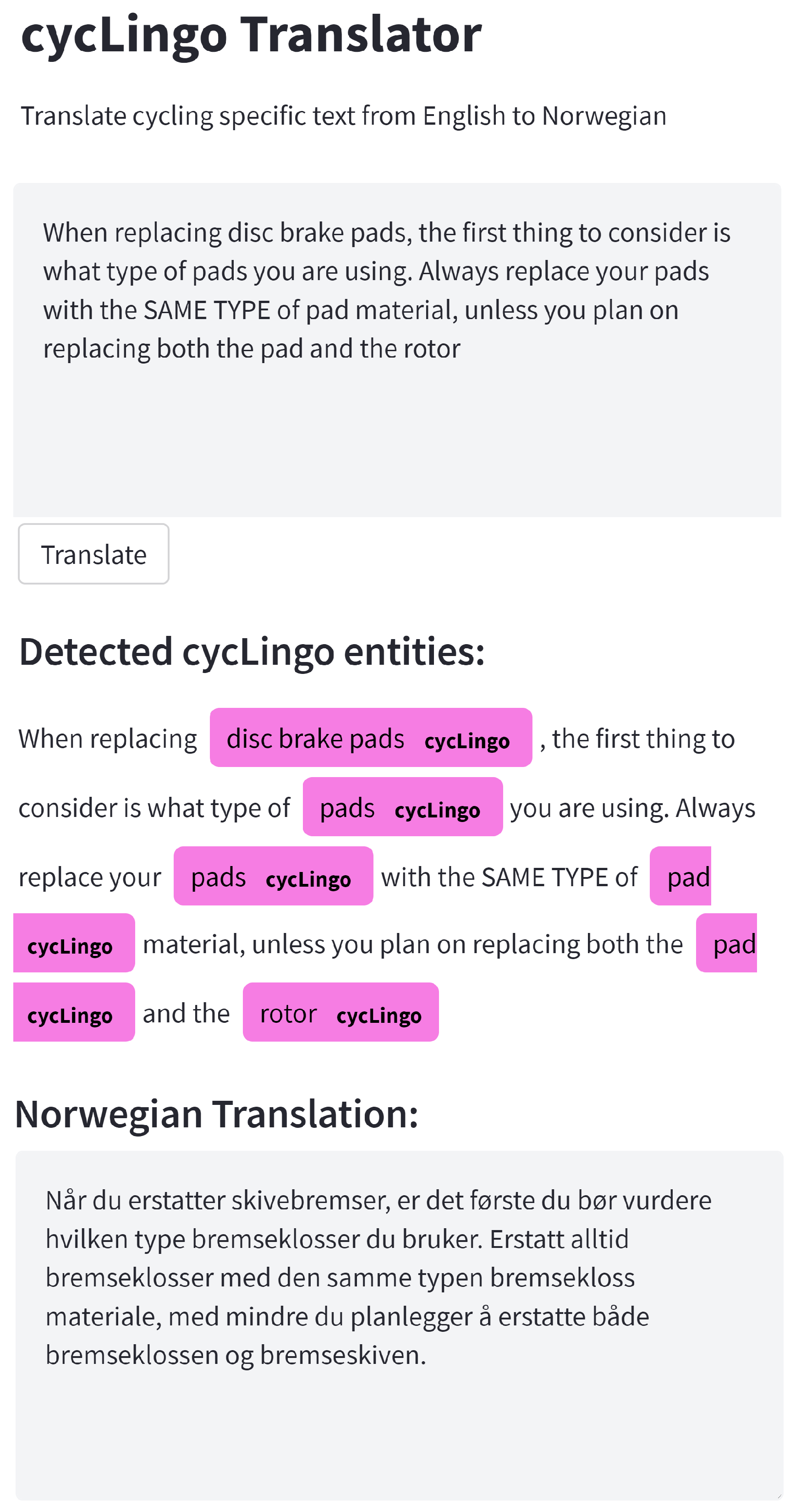
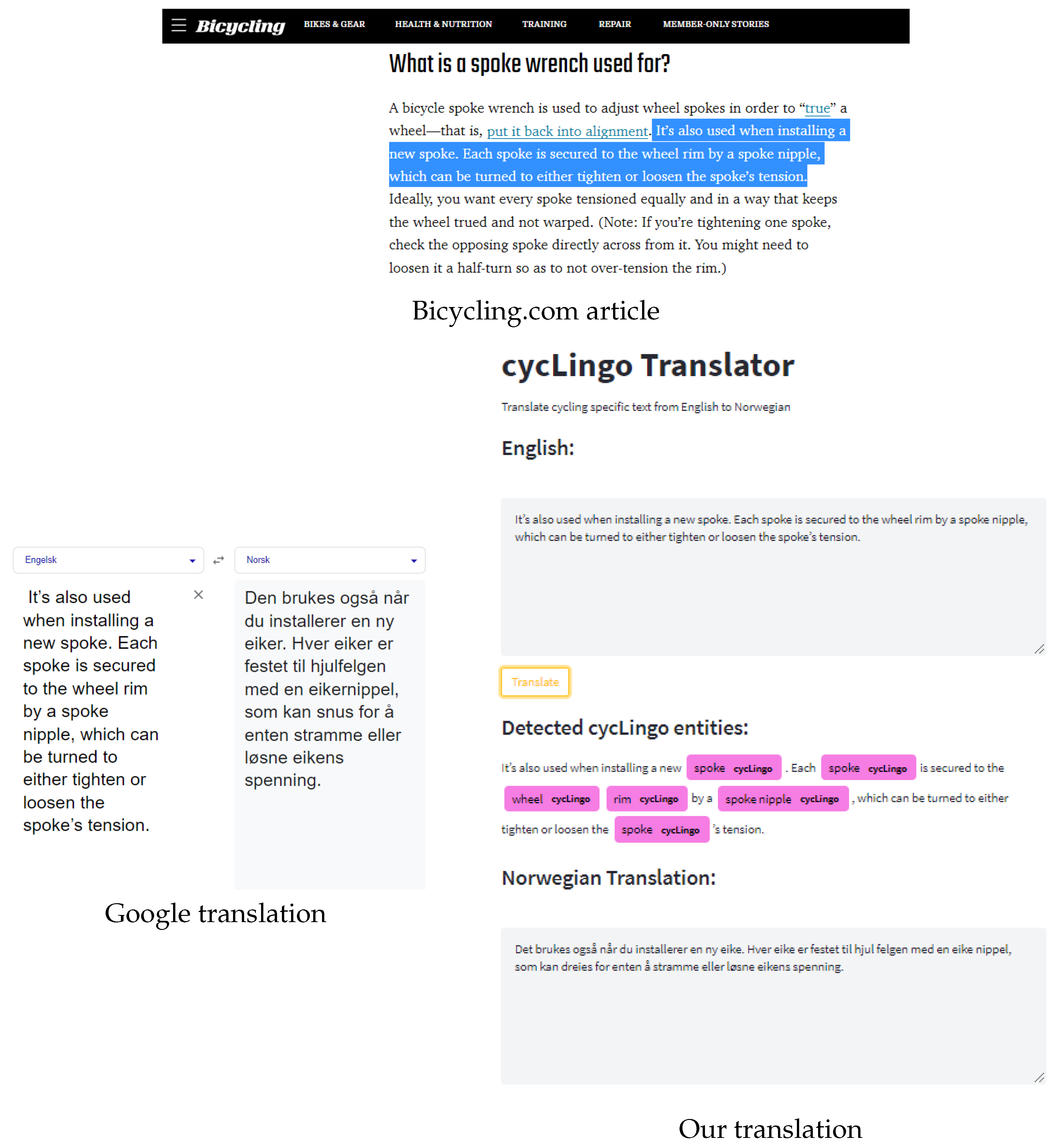
3.2.3. Web Application for Language Translation
4. Evaluation and Discussion
4.1. Evaluation Setup
4.2. Evaluation of Custom NER Model
4.3. Evaluation of the NMT Model
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Corsaro, D.; Anzivino, A. Understanding value creation in digital context: An empirical investigation of B2B. Mark. Theory 2021, 21, 317–349. [Google Scholar] [CrossRef]
- Rusthollkarhu, S.; Hautamaki, P.; Aarikka-Stenroos, L. Value (co-)creation in B2B sales ecosystems. J. Bus. Ind. Mark. 2021, 36, 590–598. [Google Scholar] [CrossRef]
- Gavin, R.; Harrison, L.; Plotkin, C.L.; Spillecke, D.; Stanley, J. The B2B Digital Inflection Point: How Sales Have Changed during COVID-19. McKinsey & Company. 2020. Available online: https://www.mckinsey.com/ (accessed on 5 March 2023).
- Norsk Sportsbransjeforening. Bransjeregisteret. 2022. Available online: https://sportsbransjen.no/bransjeregister (accessed on 20 February 2023).
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2022, 82, 3713–3744. [Google Scholar] [CrossRef] [PubMed]
- Popel, M.; Tomkova, M.; Tomek, J.; Kaiser, Ł.; Uszkoreit, J.; Bojar, O.; Žabokrtský, Z. Transforming machine translation: A deep learning system reaches news translation quality comparable to human professionals. Nat. Commun. 2020, 11, 4381. [Google Scholar] [CrossRef] [PubMed]
- Yan, R.; Li, J.; Su, X.; Wang, X.; Gao, G. Boosting the Transformer with the BERT Supervision in Low-Resource Machine Translation. Appl. Sci. 2022, 12, 7195. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar] [CrossRef]
- Luong, T.; Sutskever, I.; Le, Q.; Vinyals, O.; Zaremba, W. Addressing the Rare Word Problem in Neural Machine Translation. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 27–31 July 2015; pp. 11–19. [Google Scholar] [CrossRef]
- Wikipedia. List of Bicycle Parts. 2022. Available online: https://en.wikipedia.org/wiki/ (accessed on 1 March 2023).
- Chowdhary, K. Natural language processing. In Fundamentals of Artificial Intelligence; Springer: New Delhi, India, 2020; pp. 603–649. [Google Scholar]
- Bago, P.; Castilho, S.; Dunne, J.; Gaspari, F.; Andre, K.; Kristmannsson, G.; Olsen, J.A.; Resende, N.; Gíslason, N.R.; Sheridan, D.D.; et al. Achievements of the PRINCIPLE Project: Promoting MT for Croatian, Icelandic, Irish and Norwegian. In Proceedings of the 23rd Annual Conference of the European Association for Machine Translation, Ghent, Belgium, 1–3 June 2022; pp. 347–348. [Google Scholar]
- Ramirez-Sanchez, G. Custom machine translation. Mach. Transl. Everyone Empower. Users Age Artif. Intell. 2022, 18, 165. [Google Scholar]
- Tunstall, L.; von Werra, L.; Wolf, T. Natural Language Processing with Transformers; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Castilho, S.; Moorkens, J.; Gaspari, F.; Calixto, I.; Tinsley, J.; Way, A. Is Neural Machine Translation the New State of the Art? Prague Bull. Math. Linguist. 2017, 108, 109–120. [Google Scholar] [CrossRef]
- Sennrich, R.; Firat, O.; Cho, K.; Birch, A.; Haddow, B.; Hitschler, J.; Junczys-Dowmunt, M.; Läubli, S.; Miceli Barone, A.V.; Mokry, J.; et al. Nematus: A Toolkit for Neural Machine Translation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; pp. 65–68. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kutuzov, A.; Barnes, J.; Velldal, E.; ∅vrelid, L.; Oepen, S. Large-Scale Contextualised Language Modelling for Norwegian. In Proceedings of the 23rd Nordic Conference on Computational Linguistics (NoDaLiDa), Reykjavik, Iceland, 31 May–2 June 2021. [Google Scholar]
- Liu, X.; Yoo, C.; Xing, F.; Oh, H.; Fakhri, G.E.; Kang, J.W.; Woo, J. Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives. APSIPA Trans. Signal Inf. Process. 2022, 11, e25. [Google Scholar] [CrossRef]
- Jiang, J.; Zhai, C. Instance weighting for domain adaptation in NLP. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Prague, Czech Republic, 25–26 June 2007; pp. 264–271. [Google Scholar]
- Hu, J.; Xia, M.; Neubig, G.; Carbonell, J. Domain Adaptation of Neural Machine Translation by Lexicon Induction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2989–3001. [Google Scholar] [CrossRef]
- Tarcar, A.K.; Tiwari, A.; Dhaimodker, V.N.; Rebelo, P.; Desai, R.; Rao, D. Healthcare NER models using language model pretraining. arXiv 2019, arXiv:1910.11241. [Google Scholar] [CrossRef]
- Yadav, V.; Bethard, S. A survey on recent advances in named entity recognition from deep learning models. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 2145–2158. [Google Scholar]
- Brodzicki, A.; Piekarski, M.; Kucharski, D.; Jaworek-Korjakowska, J.; Gorgon, M. Transfer Learning Methods as a New Approach in Computer Vision Tasks with Small Datasets. Found. Comput. Decis. Sci. 2020, 45, 179–193. [Google Scholar] [CrossRef]
- Junczys-Dowmunt, M.; Grundkiewicz, R.; Dwojak, T.; Hoang, H.; Heafield, K.; Neckermann, T.; Seide, F.; Germann, U.; Aji, A.F.; Bogoychev, N.; et al. Marian: Fast Neural Machine Translation in C++. arXiv 2018, arXiv:1804.00344. [Google Scholar]
- Adelani, D.; Alabi, J.; Fan, A.; Kreutzer, J.; Shen, X.; Reid, M.; Ruiter, D.; Klakow, D.; Nabende, P.; Chang, E.; et al. A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 10–15 July 2022; pp. 3053–3070. [Google Scholar] [CrossRef]
- Eisenschlos, J.; Ruder, S.; Czapla, P.; Kadras, M.; Gugger, S.; Howard, J. MultiFiT: Efficient Multi-lingual Language Model Fine-tuning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 5702–5707. [Google Scholar] [CrossRef]
- Fan, A.; Bhosale, S.; Schwenk, H.; Ma, Z.; El-Kishky, A.; Goyal, S.; Baines, M.; Celebi, O.; Wenzek, G.; Chaudhary, V.; et al. Beyond English-Centric Multilingual Machine Translation. J. Mach. Learn. Res. 2021, 22, 4839–4886. [Google Scholar]
- Tiedemann, J.; Thottingal, S. OPUS-MT–Building open translation services for the World. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Online, 3–5 November 2020. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual Denoising Pre-training for Neural Machine Translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 July 2021; pp. 483–498. [Google Scholar] [CrossRef]
- Alt, C.; Hübner, M.; Hennig, L. Fine-tuning Pre-Trained Transformer Language Models to Distantly Supervised Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1388–1398. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentence Pairs | Generic-Word Vocabulary | Bicycle-Part Vocabulary |
|---|---|---|
| 1000 | 54,666 | 1298 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hellebust, D.; Lawal, I.A. Improving Norwegian Translation of Bicycle Terminology Using Custom Named-Entity Recognition and Neural Machine Translation. Electronics 2023, 12, 2334. https://doi.org/10.3390/electronics12102334
Hellebust D, Lawal IA. Improving Norwegian Translation of Bicycle Terminology Using Custom Named-Entity Recognition and Neural Machine Translation. Electronics. 2023; 12(10):2334. https://doi.org/10.3390/electronics12102334
Chicago/Turabian StyleHellebust, Daniel, and Isah A. Lawal. 2023. "Improving Norwegian Translation of Bicycle Terminology Using Custom Named-Entity Recognition and Neural Machine Translation" Electronics 12, no. 10: 2334. https://doi.org/10.3390/electronics12102334
APA StyleHellebust, D., & Lawal, I. A. (2023). Improving Norwegian Translation of Bicycle Terminology Using Custom Named-Entity Recognition and Neural Machine Translation. Electronics, 12(10), 2334. https://doi.org/10.3390/electronics12102334