
Dual-Arm Cluster Tool Scheduling for Reentrant Wafer Flows


Abstract
:1. Introduction
2. Literature Review
3. The Reentrant Process and Periodical Schedules
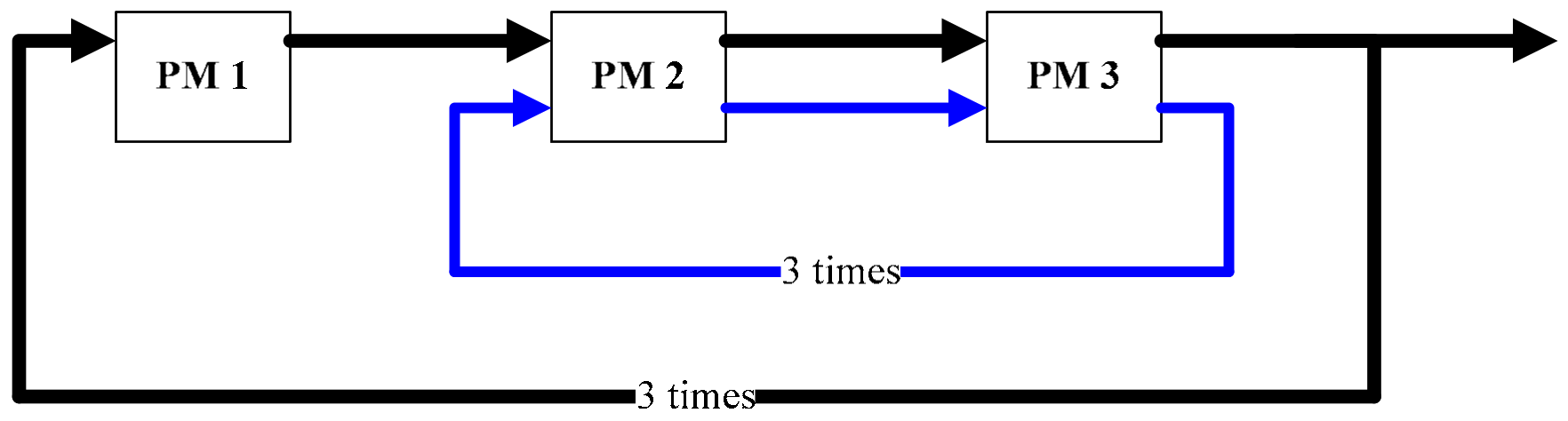
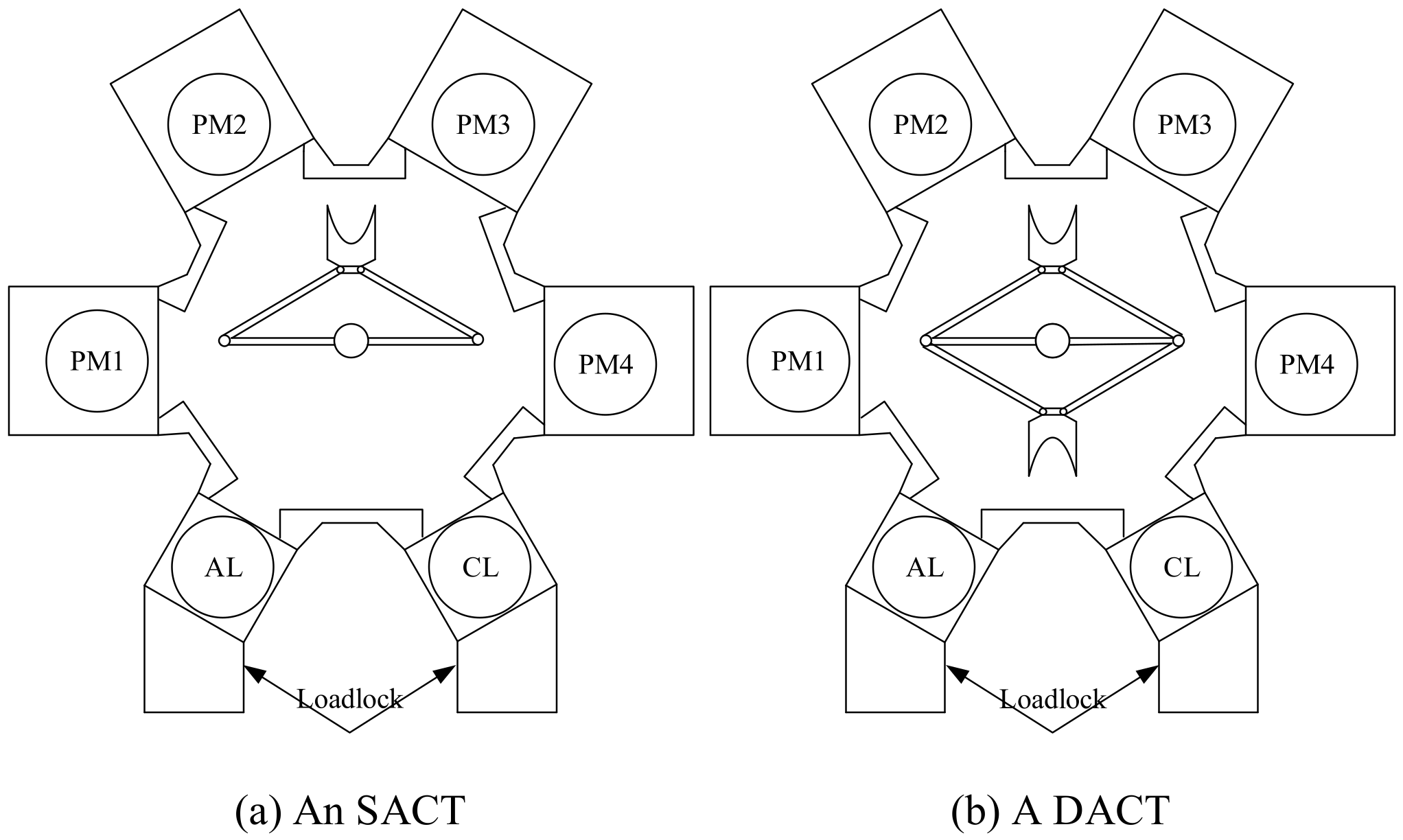
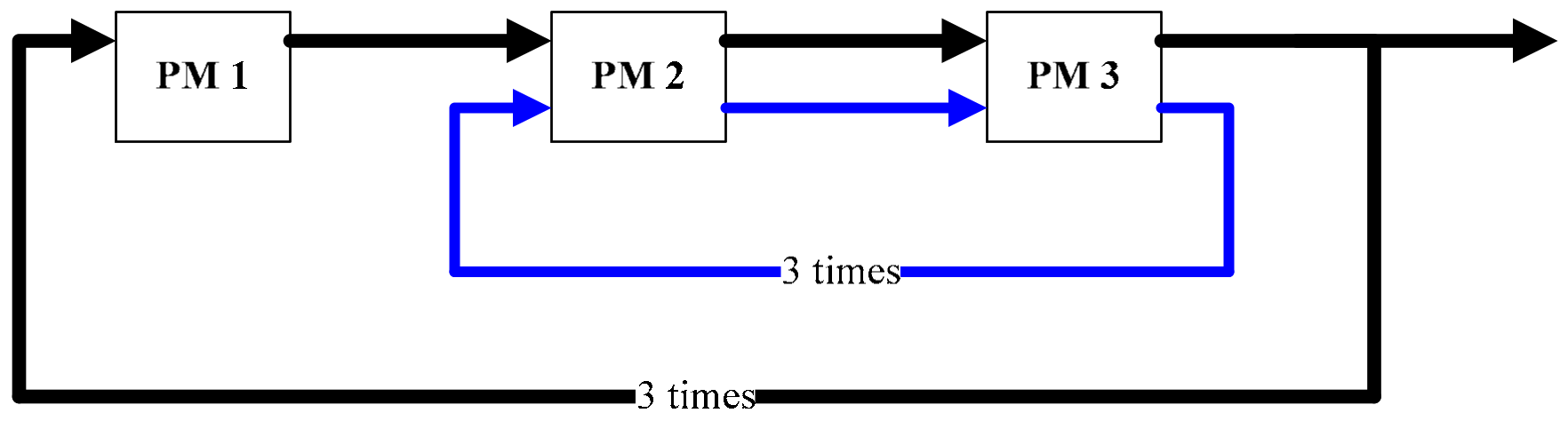
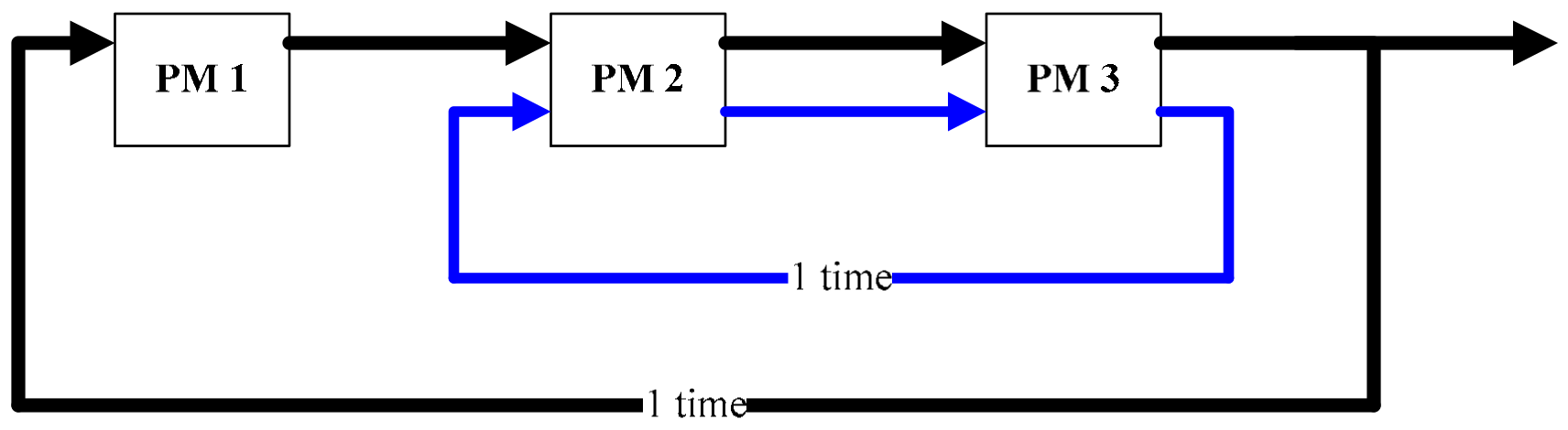
3.1. Reentrant Process
3.2. Activity Description
3.3. Periodical Schedules
4. Scheduling Analysis by One-Wafer Cyclic Schedule
5. Two Novel Scheduling Methods
5.1. Scheduling Method One
5.2. Scheduling Method Two
| Algorithm 1: For a DACT with (PM1, (PM2, PM3)3), the following algorithm is applied to choose one of the N3-WP1 and N3-WP2 schedules for the tool. | |
| Input: ρ1, ρ2, ρ3, α, μ, β, and λ Output: The adopted schedule | |
| 1. | Calculate ψ, Π1, Π2, Π3, and Πlocal; |
| 2. | If max{Π2, Π3} ≤ ψ |
| 3. | If Π1 ≤ Πlocal + ψ |
| 4. | The N3-WP2 schedule is applied, and the cycle time is calculated by Theorem 9; |
| 5. | If Πlocal + ψ < Π1 ≤ 3Πlocal + ψ |
| 6. | Calculate ΠN3-WP1 by Theorem 4 and ΠN3-WP2 by Theorem 13; |
| 7. | If ΠN3-WP1 < ΠN3-WP2 |
| 8. | The N3-WP1 schedule is applied; |
| 9. | Else |
| 10. | The N3-WP2 schedule is applied; |
| 11. | If Π1 > 3Πlocal + ψ |
| 12. | The N3-WP1 schedule is applied, and the cycle time is calculated by Theorem 8; |
| 13. | Else |
| 14. | If Π1 ≤ Πlocal + ψ |
| 15. | The N3-WP2 schedule is applied, and the cycle time is calculated by Theorem 10; |
| 16. | If Πlocal + ψ < Π1 ≤ 2Πlocal |
| 17. | The N3-WP2 schedule is applied, and the cycle time is calculated by Theorem 11; |
| 18. | If 2Πlocal < Π1 ≤ 2.5Πlocal − 0.5ψ |
| 19. | The N3-WP2 schedule is applied, and the cycle time is calculated by Theorem 12; |
| 20. | If 2.5Πlocal − 0.5ψ < Π1 ≤ 3Πlocal + ψ |
| 21. | Calculate ΠN3-WP1 by Theorem 5 and ΠN3-WP2 by Theorem 12; |
| 22. | If ΠN3-WP1 < ΠN3-WP2 |
| 23. | The N3-WP1 schedule is applied; |
| 24. | Else |
| 25. | The N3-WP2 schedule is applied; |
| 26. | If 3Πlocal + ψ < Π1 ≤ 4Πlocal |
| 27. | Calculate ΠN3-WP1 by Theorem 6 and ΠN3-WP2 by Theorem 12. |
| 28. | If ΠN3-WP1 < ΠN3-WP2 |
| 29. | The N3-WP1 schedule is applied; |
| 30. | Else |
| 31. | The N3-WP2 schedule is applied; |
| 32. | If Π1 > 4Πlocal |
| 33. | The N3-WP1 schedule is applied, and the cycle time can be obtained by Theorem 7; |
6. Implementation of the Proposed Methods and Illustrative Examples
6.1. Implementation of the Proposed Methods
6.2. Illustrative Examples
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, W.; Yu, T.-S.; Lee, T.-E. Integrated Scheduling of a Dual-Armed Cluster Tool for Maximizing Steady Schedule Patterns. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 7282–7294. [Google Scholar] [CrossRef]
- Kim, Y.; Lee, G.; Jeong, J. ML-Based JIT1 Optimization for Throughput Maximization in Cluster Tool Automation. Appl. Sci. 2022, 12, 7519. [Google Scholar] [CrossRef]
- Lee, H.Y.; Lee, T.E. Scheduling single-armed cluster tools with reentrant wafer flows. IEEE Trans. Semicond. Manuf. 2006, 19, 226–240. [Google Scholar] [CrossRef]
- Bleakie, A.; Djurdjanovic, D. Feature extraction, condition monitoring, and fault modeling in semiconductor manufacturing systems. Comput. Ind. 2013, 64, 203–213. [Google Scholar] [CrossRef]
- Qiao, Y.; Wu, N.; Zhou, M. A Petri Net-Based Novel Scheduling Approach and Its Cycle Time Analysis for Dual-Arm Cluster Tools with Wafer Revisiting. IEEE Trans. Semicond. Manuf. 2013, 26, 100–110. [Google Scholar] [CrossRef]
- Lopez, M.J.; Wood, S.C. Systems of multiple cluster tools: Configuration, reliability, and performance. IEEE Trans. Semicond. Manuf. 2003, 16, 170–178. [Google Scholar] [CrossRef]
- Lee, T.E.; Lee, H.Y.; Shin, Y.H. Workload balancing and scheduling of a single-amred cluster tool. In Proceedings of the 5th APIEMS Conference, Gold Coast, Australia, 12–15 December 2004; pp. 1–15. [Google Scholar]
- Venkatesh, S.; Davenport, R.; Foxhoven, P.; Nulman, J. A steady-state throughput analysis of cluster tools: Dual-blade versus single-blade robots. IEEE Trans. Semicond. Manuf. 1997, 10, 418–424. [Google Scholar] [CrossRef]
- Perkinson, T.L.; McLarty, P.K.; Gyurcsik, R.S.; Cavin, R.K. Single-wafer cluster tool performance: An analysis of throughput. IEEE Trans. Semicond. Manuf. 1994, 7, 369–373. [Google Scholar] [CrossRef]
- Kim, D.K.; Kim, H.J.; Lee, T.E. Optimal scheduling for sequentially connected cluster tools with dual-armed robots and a single input and output module. Int. J. Prod. Res. 2017, 55, 3092–3109. [Google Scholar] [CrossRef]
- Lee, J.H.; Kim, H.J.; Lee, T.E. Scheduling cluster tools for concurrent processing of two wafer types with PM sharing. Int. J. Prod. Res. 2015, 53, 6007–6022. [Google Scholar] [CrossRef]
- Rostami, S.; Hamidzadeh, B.; Camporese, D. An optimal periodic scheduler for dual-arm robots in cluster tools with residency constraints. IEEE Trans. Robot. Autom. 2001, 17, 609–618. [Google Scholar] [CrossRef]
- Kim, J.H.; Lee, T.E.; Lee, H.Y.; Park, D.B. Scheduling analysis of time-constrained dual-armed cluster tools. IEEE Trans. Semicond. Manuf. 2003, 16, 521–534. [Google Scholar] [CrossRef]
- Jung, C.; Lee, T.E. An Efficient Mixed Integer Programming Model Based on Timed Petri Nets for Diverse Complex Cluster Tool Scheduling Problems. IEEE Trans. Semicond. Manuf. 2012, 25, 186–199. [Google Scholar] [CrossRef]
- Wu, N.; Chu, C.; Chu, F.; Zhou, M.C. A Petri Net Method for Schedulability and Scheduling Problems in Single-Arm Cluster Tools with Wafer Residency Time Constraints. IEEE Trans. Semicond. Manuf. 2008, 21, 224–237. [Google Scholar] [CrossRef]
- Wu, N.; Zhou, M. A Closed-Form Solution for Schedulability and Optimal Scheduling of Dual-Arm Cluster Tools with Wafer Residency Time Constraint Based on Steady Schedule Analysis. IEEE Trans. Autom. Sci. Eng. 2010, 7, 303–315. [Google Scholar] [CrossRef]
- Ko, S.G.; Yu, T.S.; Lee, T.E. Wafer delay analysis and workload balancing of parallel chambers for dual-armed cluster tools with multiple wafer types. IEEE Trans. Autom. Sci. Eng. 2021, 18, 1516–1526. [Google Scholar] [CrossRef]
- Wang, J.F.; Liu, C.F.; Zhou, M.C.; Leng, T.T.; Albeshri, A. Optimal cyclic scheduling of wafer-residency-time-constrained dual-arm cluster tools by configuring processing modules and robot waiting time. IEEE Trans. Semicond. Manuf. 2023, 36, 251–259. [Google Scholar] [CrossRef]
- Wu, N.; Zhou, M. Modeling, Analysis and Control of Dual-Arm Cluster Tools with Residency Time Constraint and Activity Time Variation Based on Petri Nets. IEEE Trans. Autom. Sci. Eng. 2012, 9, 446–454. [Google Scholar] [CrossRef]
- Wu, N.; Zhou, M. Schedulability Analysis and Optimal Scheduling of Dual-Arm Cluster Tools with Residency Time Constraint and Activity Time Variation. IEEE Trans. Autom. Sci. Eng. 2012, 9, 203–209. [Google Scholar] [CrossRef]
- Qiao, Y.; Wu, N.; Zhou, M. Petri Net Modeling and Wafer Sojourn Time Analysis of Single-Arm Cluster Tools with Residency Time Constraints and Activity Time Variation. IEEE Trans. Semicond. Manuf. 2012, 25, 432–446. [Google Scholar] [CrossRef]
- Qiao, Y.; Wu, N.; Zhou, M. Real-Time Scheduling of Single-Arm Cluster Tools Subject to Residency Time Constraints and Bounded Activity Time Variation. IEEE Trans. Autom. Sci. Eng. 2012, 9, 564–577. [Google Scholar] [CrossRef]
- Lim, Y.; Yu, T.S.; Lee, T.E. Adaptive scheduling of cluster tools with wafer delay constraints and process time variation. IEEE Trans. Autom. Sci. Eng. 2020, 17, 375–388. [Google Scholar] [CrossRef]
- Kim, C.; Yu, T.S.; Lee, T.E. Feedback control of cluster tools: Stability against random time disruptions. IEEE Trans. Autom. Sci. Eng. 2022, 19, 2008–2015. [Google Scholar] [CrossRef]
- Yu, T.S.; Kim, H.J.; Lee, T.E. Scheduling Single-Armed Cluster Tools with Chamber Cleaning Operations. IEEE Trans. Autom. Sci. Eng. 2018, 15, 705–716. [Google Scholar] [CrossRef]
- Yu, T.S.; Lee, T.E. Scheduling Dual-Armed Cluster Tools with Chamber Cleaning Operations. IEEE Trans. Autom. Sci. Eng. 2019, 16, 218–228. [Google Scholar] [CrossRef]
- Yu, T.S.; Lee, T.E. Wafer delay analysis and control of dual-armed cluster tools with chamber cleaning operations. Int. J. Prod. Res. 2020, 58, 434–447. [Google Scholar] [CrossRef]
- Qiao, Y.; Lu, Y.; Li, J.; Zhang, S.; Wu, N.; Liu, B. An Efficient Binary Integer Programming Model for Residency Time-Constrained Cluster Tools with Chamber Cleaning Requirements. IEEE Trans. Autom. Sci. Eng. 2022, 19, 1757–1771. [Google Scholar] [CrossRef]
- Li, C.; Yang, F.; Zhen, L. Efficient scheduling approaches to time-constrained single-armed cluster tools with condition-based chamber cleaning operations. Int. J. Prod. Res. 2022, 60, 3555–3568. [Google Scholar] [CrossRef]
- Li, H.P.; Zhu, Q.H.; Hou, Y. Scheduling a single-arm robotic cluster tool with a condition-based cleaning operation. In Proceedings of the 2022 IEEE International Conference on Systems, Man, and Cybernetics, Clarion Congress Hotel, Prague, Czech Republic, 9–12 October 2022. [Google Scholar]
- Zuberek, W.M. Cluster tools with chamber revisiting-modeling and analysis using timed Petri nets. IEEE Trans. Semicond. Manuf. 2004, 17, 333–344. [Google Scholar] [CrossRef]
- Wu, N.; Chu, F.; Chu, C.; Zhou, M. Petri Net-Based Scheduling of Single-Arm Cluster Tools with Reentrant Atomic Layer Deposition Processes. IEEE Trans. Autom. Sci. Eng. 2011, 8, 42–55. [Google Scholar] [CrossRef]
- Wu, N.; Chu, F.; Chu, C.; Zhou, M. Petri Net Modeling and Cycle-Time Analysis of Dual-Arm Cluster Tools with Wafer Revisiting. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 196–207. [Google Scholar] [CrossRef]
- Wu, N.; Zhou, M.; Chu, F.; Chu, C. A Petri-Net-Based Scheduling Strategy for Dual-Arm Cluster Tools with Wafer Revisiting. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 1182–1194. [Google Scholar] [CrossRef]
- Qiao, Y.; Wu, N.; Zhu, Q.; Bai, L. Cycle time analysis of dual-arm cluster tools for wafer fabrication processes with multiple wafer revisiting times. Comput. Oper. Res. 2015, 53, 252–260. [Google Scholar] [CrossRef]
- Qiao, Y.; Wu, N.; Zhou, M. Scheduling of Dual-Arm Cluster Tools with Wafer Revisiting and Residency Time Constraints. IEEE Trans. Ind. Inform. 2014, 10, 286–300. [Google Scholar] [CrossRef]
- Qiao, Y.; Wu, N.; Zhou, M. Schedulability and Scheduling Analysis of Dual-Arm Cluster Tools with Wafer Revisiting and Residency Time Constraints Based on a Novel Schedule. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 472–484. [Google Scholar] [CrossRef]
- Qiao, Y.; Wu, N.; Yang, F.; Zhou, M.; Zhu, Q. Wafer Sojourn Time Fluctuation Analysis of Time-Constrained Dual-Arm Cluster Tools with Wafer Revisiting and Activity Time Variation. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 622–636. [Google Scholar] [CrossRef]
- Qiao, Y.; Wu, N.; Yang, F.; Zhou, M.; Zhu, Q.; Qu, T. Robust Scheduling of Time-Constrained Dual-Arm Cluster Tools with Wafer Revisiting and Activity Time Disturbance. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1228–1240. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| References | Number of Reentrant Times | Other Constraints | The Addressed Problem | Methods | Results |
|---|---|---|---|---|---|
| [31] | k ≥ 2 | None | Deadlock analysis | PNs | No optimality analysis |
| [3] | k ≥ 2 | None | Scheduling | PNs and MIP | Optimal |
| [32] | k = 2 | None | Scheduling | PNs | Optimal for SACTs |
| [33] | k = 2 | None | Scheduling | PNs and 3-WP scheduling | Optimal for some cases |
| [34] | k = 2 | None | Scheduling | PNs and 2-WP scheduling | Optimal for some cases |
| [5] | k = 2 | None | Scheduling | PNs and 1-WP | Optimal |
| [36,37] | k = 2 | WRTCs | Scheduling | 1-WP | Optimal |
| [38,39] | k = 2 | WRTCs, time variation | Control and Scheduling | PNs and 1-WP | Optimal |
| [35] | k ≥ 2 | None | Cycle time analysis | PNs and 3-WP | Optimal for some cases |
| Notations | Robot Tasks | Time |
|---|---|---|
| PIi | Picking a wafer in Step i | α |
| PLi | Placing a wafer in Step i | β |
| Mij | Moving from Steps i to j | μ |
| SWPi | Swapping in Step i | λ |
| No. | ρ1 | ρ2 | ρ3 | N3-WP1 | N3-WP2 | 3-WP | The Adopted Scheduling Method | Improvement | ||
|---|---|---|---|---|---|---|---|---|---|---|
| ΠN3-WP1 | Theorem | ΠN3-WP2 | Theorem | Π3-WP | ||||||
| 1 | 250 | 35 | 50 | 258 | 7 | / | / | 302 | N3-WP1 | 14.57% |
| 2 | 150 | 25 | 30 | 158 | 8 | / | / | 195(1/3) | N3-WP1 | 19.11% |
| 3 | 70 | 25 | 30 | 130 | 4 | 118 | 9 | 142 | N3-WP2 | 16.90% |
| 4 | 70 | 25 | 35 | 140(1/3) | 5 | 129 | 10 | 152 | N3-WP2 | 15.13% |
| 5 | 95 | 40 | 50 | 183(2/3) | 5 | 174 | 11 | 198(2/3) | N3-WP2 | 12.42% |
| 6 | 110 | 40 | 50 | 188(2/3) | 5 | 174 | 12 | 208(2/3) | N3-WP2 | 16.61% |
| 7 | 140 | 25 | 30 | 153(1/3) | 4 | 163(1/3) | 13 | 188(2/3) | N3-WP1 | 18.73% |
| 8 | 100 | 25 | 30 | 140 | 4 | 136(2/3) | 13 | 162 | N3-WP2 | 15.64% |
| 9 | 210 | 35 | 50 | 222 | 6 | 236(2/3) | 12 | 275(1/3) | N3-WP1 | 19.37% |
| 10 | 200 | 35 | 50 | 218(2/3) | 5 | 230 | 12 | 268(2/3) | N3-WP1 | 18.61% |
| 11 | 120 | 35 | 50 | 192 | 5 | 176(2/3) | 12 | 215(1/3) | N3-WP2 | 17.96% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, T.; Qiao, Y.; He, Y.; Wu, N.; Li, Z.; Liu, B. Dual-Arm Cluster Tool Scheduling for Reentrant Wafer Flows. Electronics 2023, 12, 2411. https://doi.org/10.3390/electronics12112411
Song T, Qiao Y, He Y, Wu N, Li Z, Liu B. Dual-Arm Cluster Tool Scheduling for Reentrant Wafer Flows. Electronics. 2023; 12(11):2411. https://doi.org/10.3390/electronics12112411
Chicago/Turabian StyleSong, Tairan, Yan Qiao, Yunfang He, Naiqi Wu, Zhiwu Li, and Bin Liu. 2023. "Dual-Arm Cluster Tool Scheduling for Reentrant Wafer Flows" Electronics 12, no. 11: 2411. https://doi.org/10.3390/electronics12112411
APA StyleSong, T., Qiao, Y., He, Y., Wu, N., Li, Z., & Liu, B. (2023). Dual-Arm Cluster Tool Scheduling for Reentrant Wafer Flows. Electronics, 12(11), 2411. https://doi.org/10.3390/electronics12112411