
Flexible Load Multi-Step Forecasting Method Based on Non-Intrusive Load Decomposition


Abstract
:1. Introduction
2. Non-Intrusive Load Decomposition
2.1. Principle of Decomposition
2.2. Model Principle
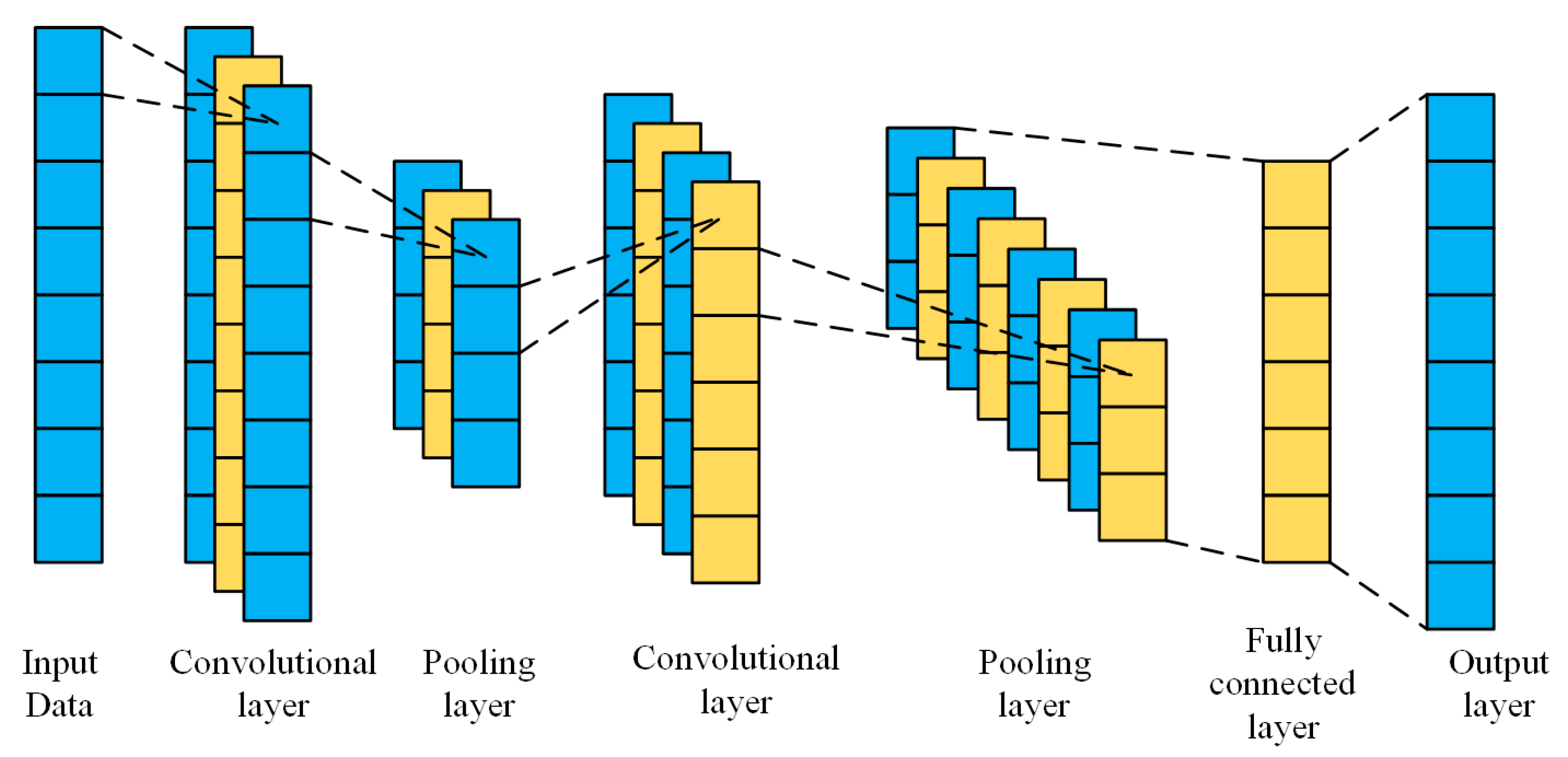
2.2.1. Convolutional Neural Network (CNN)
2.2.2. Bi-Directional Long Short Term Memory Network (BiLSTM)
2.3. Decomposition Network
3. Load Forecasting Model
3.1. Principle of Informer Model
3.2. Forecasting Model Structure
4. Analysis of Algorithms
Data Normalization and Evaluation Criteria
5. Experimental Verification
5.1. Model Parameters
5.2. Experiment 1
5.2.1. Load Decomposition
5.2.2. Prediction and Result Analysis
5.2.3. Decomposition of Prediction Results
5.2.4. Total Load Prediction Evaluation Index Results
5.2.5. Comparative Analysis of Experimental Results
5.2.6. Total Load Prediction Results
5.3. Experiment 2
Decomposition Prediction Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input sequence length of Informer encoder: 600 | Start token length of Informer decoder: 60 | Prediction sequence length: 1 or 5 or 10 or 20 |
| Encoder input size: 1 | Decoder input size: 1 | Output size: 1 |
| Dimension of model: 512 | Number of self-attended heads: 8 | ProbSparse attn factor: 5 |
| Number of encoder layers: 2 | Number of decoder layers: 1 | Batch size of train input data: 20 |
| Dropout: 0.05 | Activation functions: gelu | Optimizer learning rate: 0.0001 |





References
- Wang, B.; Yang, Z.; Pham, T.L.H.; Deng, N.; Du, H. Can social impacts promote residents’ pro-environmental intentions and behaviour: Evidence from large-scale demand response experiment in China. Appl. Energy 2023, 340, 121031. [Google Scholar] [CrossRef]
- Li, P.; Li, F.; Song, X.; Zhang, G. Rotational reserve optimization of new energy access system considering flexible load. Power Grid Technol. 2021, 45, 7. [Google Scholar]
- Chan, S.H.; Ngan, H.W.; Chow, W.L. A flexible load forecasting model for integrated resources planning. In Proceedings of the DRPT2000. International Conference on Electric Utility Deregulation and Restructuring and Power Technologies, Proceedings (Cat. No.00EX382), London, UK, 4–7 April 2000; IEEE: Piscataway, NY, USA, 2000; pp. 562–565. [Google Scholar]
- Chen, Y.; Fu, G.; Liu, X. Air-conditioning load forecasting for prosumer based on meta ensemble learning. IEEE Access 2020, 8, 123673–123682. [Google Scholar] [CrossRef]
- Cui, J.; Liu, S.; Yang, J.; Ge, W.; Zhou, X.; Wang, A. A load combination prediction algorithm considering flexible charge and discharge of electric vehicles. In Proceedings of the 2019 IEEE 10th International Symposium on Power Electronics for Distributed Generation Systems (PEDG), Xi’an, China, 3–6 June 2019; IEEE: Piscataway, NY, USA, 2019; pp. 711–716. [Google Scholar]
- Wang, J.; Du, C. Short-term load forecasting model based on Attention-BiLSTM neural network and meteorological data correction. Power Autom. Equip. 2022, 42, 7. [Google Scholar]
- Karsaz, A.; Mashhadi, H.R.; Eshraghnia, R. Cooperative co-evolutionary approach to electricity load and price forecasting in deregulated electricity markets. In Proceedings of the IEEE Power India Conference, New Delhi, India, 10–12 April 2006. [Google Scholar]
- Li, P.; He, S.; Han, P.; Zheng, M.; Huang, M.; Sun, J. Short-term load forecasting of smart grid based on long-short-term memory recurrent neural networks in condition of real-time electricity price. Power Syst. Technol. 2018, 42, 4045–4052. (In Chinese) [Google Scholar]
- Chen, T.; Qin, H.; Li, X.; Wan, W.; Yan, W. A Non-Intrusive Load Monitoring Method Based on Feature Fusion and SE-ResNet. Electronics 2023, 12, 1909. [Google Scholar] [CrossRef]
- Hamdi, M.; Messaoud, H.; Bouguila, N. A new approach of electrical appliance identification in residential buildings. Electr. Power Syst. Res. 2020, 178, 106037. [Google Scholar] [CrossRef]
- Sethom, H.; Ben’S, H. Statistical Assessment of Abrupt Change Detectors for Non Intrusive Load Monitoring. In Proceedings of the 2018 IEEE International Conference on Industrial Technology (ICIT), Lyon, France, 20–22 February 2018; IEEE: Piscataway, NY, USA, 2018. [Google Scholar]
- Yan, X.; Zhai, S.; Wang, Z.; Wang, F.; He, G. Application of Deep Neural Network in Non-intrusive Load Disaggregation. Autom. Electr. Power Syst. 2019, 43, 8. [Google Scholar]
- Fang, Y.; Jiang, S.; Fang, S.; Gong, Z.; Xia, M.; Zhang, X. Non-Intrusive Load Disaggregation Based on a Feature Reused Long Short-Term Memory Multiple Output Network. Buildings 2022, 12, 1048. [Google Scholar] [CrossRef]
- Xia, M.; Liu, W.; Wang, K.; Zhang, X.; Xu, Y. Non-intrusive load disaggregation based on deep dilated residual network. Electr. Power Syst. Res. 2019, 170, 277–285. [Google Scholar] [CrossRef]
- He, K.; Stankovic, L.; Liao, J.; Stankovic, V. Non-Intrusive Load Disaggregation using Graph Signal Processing. IEEE Trans. Smart Grid 2018, 9, 1739–1747. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Tsai, M. Development of an Improved Time–Frequency Analysis-Based Nonintrusive Load Monitor for Load Demand Identification. IEEE Trans. Instrum. Meas. 2014, 63, 1470–1483. [Google Scholar] [CrossRef]
- Ma, H.; Jia, J.; Yang, X.; Zhu, W.; Zhang, H. MC-NILM: A Multi-Chain Disaggregation Method for NILM. Energies 2021, 14, 4331. [Google Scholar] [CrossRef]
- Feng, R.; Yuan, W.; Ge, L.; Ji, S. Nonintrusive Load Disaggregation for Residential Users Based on Alternating Optimization and Down sampling. IEEE Trans. Instrum. Meas. 2021, 70, 9005312. [Google Scholar] [CrossRef]
- Zhou, X.; Feng, J.; Li, Y. Non-intrusive load decomposition based on CNN-LSTM hybrid deep learning model. Energy Rep. 2021, 7, 5762–5771. [Google Scholar] [CrossRef]
- Li, B.; Zhang, J.; He, Y.; Wang, Y. Short-term load-forecasting method based on wavelet decomposition with second-order gray neural network model combined with ADF test. IEEE Access 2017, 5, 16324–16331. [Google Scholar] [CrossRef]
- Deng, D.; Li, J.; Zhang, Z.; Teng, Y.; Huang, Q. Short-term Electric Load Forecasting Based on EEMD-GRU-MLR. Power Syst. Technol. 2020, 44, 227–236. [Google Scholar]
- Zhi, L.; Guoqiang, S.; Hucheng, L.; Zhinong, W.; Haixiang, Q.; Yizhou, Z.; Shuang, C. Short-Term Load Forecasting Based on VMD and PSO Optimized Deep Belief Network. Power Syst. Technol. 2018, 42, 598–606. [Google Scholar]
- Qian, Z.; Pei, Y.; Zareipour, H.; Chen, N. A review and discussion of decomposition-based hybrid models for wind energy forecasting applications. Appl. Energy 2019, 235, 939–953. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Zhu, M.; Xie, J. Investigation of nearby monitoring station for hourly PM2. 5 forecasting using parallel multi-input 1D-CNN-biLSTM. Expert Syst. Appl. 2023, 211, 118707. [Google Scholar] [CrossRef]
- Zhang, S.; Li, J.; Jiang, A.; Huang, J.; Liu, H.; Ai, H. New two-stage short-term power load forecasting based on FPA-VMD and BiLSTM neural network. Grid Technol. 2022, 46, 3269–3279. [Google Scholar] [CrossRef]











| Informer | CNN-BiLSTM, VMD-CNN-BiLSTM | ||
|---|---|---|---|
| Encoder input sequence length | 600 | Number of VMD decomposition | 6 |
| Decoder start length | 60 | Penalty factor | 100 |
| Encoder input size | 1 | Number of convolution layer filters | 64 |
| Decoder input size | 1 | Convolution kernel size | 5 |
| Model size | 512 | Pooling kernel size | 3 |
| Number of heads | 8 | Number of neurons | 32 |
| Load | RMSE | |
|---|---|---|
| Air Conditioning | 0.987191 | 101.654828 |
| Electric Vehicles | 0.997382 | 38.932672 |
| Load | RMSE | MAE | |
|---|---|---|---|
| Air Conditioning | 226.8348 | 74.12682 | 0.932912 |
| Electric Vehicles | 64.50621 | 6.940884 | 0.989217 |
| Model | RMSE | MAE | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 5-Step | 10-Step | 20-Step | 1-Step | 5-Step | 10-Step | 20-Step | 1-Step | 5-Step | 10-Step | 20-Step | |
| CNN-BiLSTM | 236.21 | 361.67 | 469.09 | 627.67 | 90.32 | 125.23 | 203.84 | 305.13 | 0.9539 | 0.9123 | 0.8561 | 0.7282 |
| VMD-CNN-BiLSTM | 224.06 | 366.61 | 554.50 | 725.26 | 73.63 | 155.35 | 242.26 | 355.52 | 0.9663 | 0.9024 | 0.8013 | 0.6476 |
| Informer | 198.00 | 332.70 | 431.67 | 565.54 | 67.34 | 114.61 | 178.25 | 274.84 | 0.9744 | 0.9258 | 0.8833 | 0.7792 |
| NILD-Informer | 183.71 | 306.11 | 378.20 | 486.82 | 55.81 | 102.08 | 150.80 | 210.24 | 0.9813 | 0.9389 | 0.9041 | 0.8462 |
| Load | RMSE | MAE | |
|---|---|---|---|
| Air Conditioning | 111.3321 | 36.61094 | 0.964581 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, T.; Wan, W.; Li, X.; Qin, H.; Yan, W. Flexible Load Multi-Step Forecasting Method Based on Non-Intrusive Load Decomposition. Electronics 2023, 12, 2842. https://doi.org/10.3390/electronics12132842
Chen T, Wan W, Li X, Qin H, Yan W. Flexible Load Multi-Step Forecasting Method Based on Non-Intrusive Load Decomposition. Electronics. 2023; 12(13):2842. https://doi.org/10.3390/electronics12132842
Chicago/Turabian StyleChen, Tie, Wenhao Wan, Xianshan Li, Huayuan Qin, and Wenwei Yan. 2023. "Flexible Load Multi-Step Forecasting Method Based on Non-Intrusive Load Decomposition" Electronics 12, no. 13: 2842. https://doi.org/10.3390/electronics12132842
APA StyleChen, T., Wan, W., Li, X., Qin, H., & Yan, W. (2023). Flexible Load Multi-Step Forecasting Method Based on Non-Intrusive Load Decomposition. Electronics, 12(13), 2842. https://doi.org/10.3390/electronics12132842