
FedSpy: A Secure Collaborative Speech Steganalysis Framework Based on Federated Learning





Abstract
:1. Introduction
2. Related Work
3. The Description of FedSpy
3.1. The Building Blocks of FedSpy
- . TA runs this algorithm to generate the system public parameter , the server’s secret key , and each client ’s secret key , , where is the security parameter.
- . Each client runs this algorithm to encrypt a private message with its secret key . The ciphertext is denoted by .
- . This algorithm is run by the server. It takes as input n ciphertexts from the n client, and outputs the ciphertext of aggregated results, where .
- . Given a ciphertext output by , the server runs this algorithm to decrypt it with its secret key , and obtains the aggregated results.
3.2. The Details of FedSpy
| Algorithm 1 The training Algorithm of FedSpy |
|
4. Performance Evaluation
4.1. Basic Steganalysis and Target Steganography Methods
4.2. Utilized Dataset
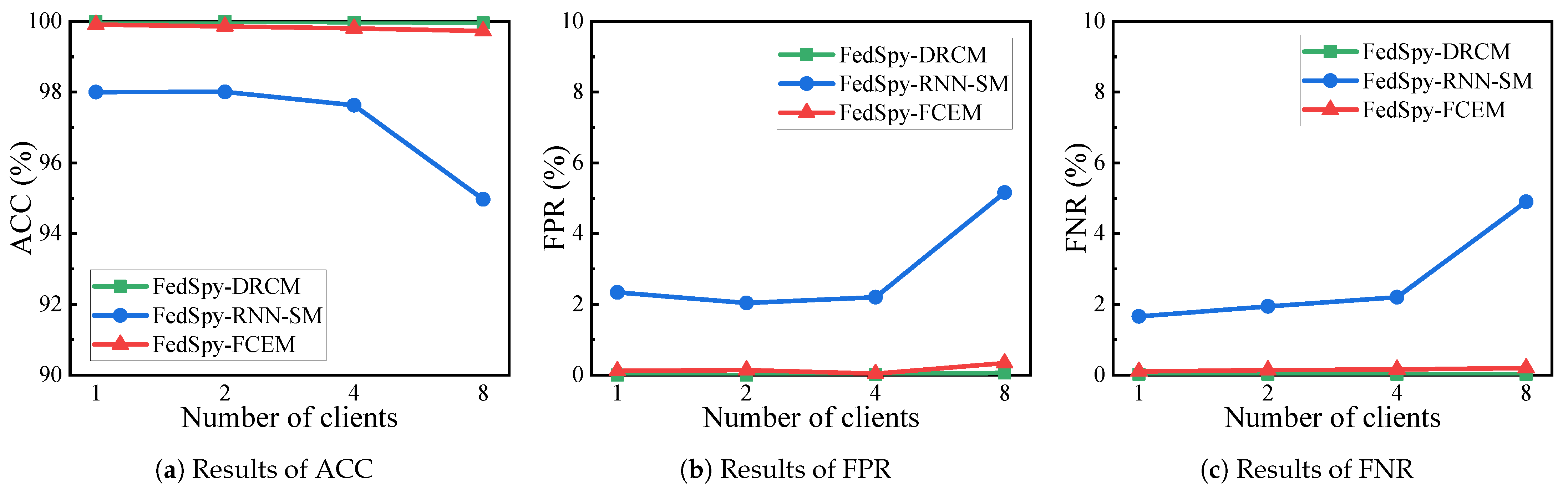
4.3. Experimental Results and Performance Evaluation
- 1
- FedSpy-RNN-SM (resp. FedSpy-FCEM or FedSpy-DRCM), incorporating RNN-SM (resp. FCEM or DRCM) into FedSpy.
- 2
- FedSteg-RNN-SM (resp. FedSteg-FCEM or FedSteg-DRCM), incorporating RNN-SM (resp. FCEM or DRCM) into FedSteg [12]. In FedSteg, each client has a personalized steganalysis model after transfer learning. Here, we take the average performance of all personalized models as a reference.
- 3
- Loc-RNN-SM (resp. Loc-FCEM or Loc-DRCM), leveraging RNN-SM (resp. FCEM or DRCM) to create a local model for each client with the corresponding local sample set. Here, we take the average performance of all local models as a reference.
- 4
- Cen-RNN-SM (resp. Cen-FCEM or Cen-DRCM), leveraging RNN-SM (resp. FCEM or DRCM) to implement a centralized model with all clients’ samples in a centralized manner.
4.3.1. The Analysis on Detection Performance
4.3.2. The Analysis on Detection Time
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FL | Federated Learning |
| QIM | Quantization Index Modulation |
| SVM | Support Vector Machine |
| RNN | Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| LSTM | Long Short-Term Memory |
| TA | Trusted Authority |
| CNV | Complementary Neighbor Vertices |
| ACC | Accuracy |
| FPR | False-Positive Rate |
| FNR | False-Negative Rate |
| IID | Independent and Identically Distributed |
References
- Tian, H.; Sun, J.; Chang, C.C.; Huang, Y.; Chen, Y. Detecting bitrate modulation-based covert voice-over-IP communication. IEEE Commun. Lett. 2018, 22, 1196–1199. [Google Scholar] [CrossRef]
- Huang, Y.F.; Tang, S.; Yuan, J. Steganography in inactive frames of VoIP streams encoded by source codec. IEEE Trans. Inf. Forensics Secur. 2011, 6, 296–306. [Google Scholar] [CrossRef]
- Lin, Q.H.; Yin, F.L.; Mei, T.M.; Liang, H. A blind source separation based method for speech encryption. IEEE Trans. Circuits Syst. I Regul. Pap. 2006, 53, 1320–1328. [Google Scholar]
- Xie, S.; Yang, Z.; Fu, Y. Nonnegative matrix factorization applied to nonlinear speech and image cryptosystems. IEEE Trans. Circuits Syst. I Regul. Pap. 2008, 55, 2356–2367. [Google Scholar]
- Li, S.B.; Tao, H.Z.; Huang, Y.F. Detection of quantization index modulation steganography in G. 723.1 bit stream based on quantization index sequence analysis. J. Zhejiang Univ. Sci. C 2012, 13, 624–634. [Google Scholar] [CrossRef]
- Li, S.; Jia, Y.; Kuo, C.C.J. Steganalysis of QIM steganography in low-bit-rate speech signals. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1011–1022. [Google Scholar] [CrossRef]
- Lin, Z.; Huang, Y.; Wang, J. RNN-SM: Fast steganalysis of VoIP streams using recurrent neural network. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1854–1868. [Google Scholar] [CrossRef]
- Yang, H.; Yang, Z.; Huang, Y. Steganalysis of VoIP streams with CNN-LSTM network. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Paris, France, 3–5 July 2019; pp. 204–209. [Google Scholar]
- Yang, H.; Yang, Z.; Bao, Y.; Liu, S.; Huang, Y. Fast steganalysis method for VoIP streams. IEEE Signal Process. Lett. 2019, 27, 286–290. [Google Scholar] [CrossRef]
- Yang, H.; Yang, Z.; Bao, Y.; Huang, Y. Hierarchical representation network for steganalysis of qim steganography in low-bit-rate speech signals. In Information and Communications Security; Springer: Berlin/Heidelberg, Germany, 2019; pp. 783–798. [Google Scholar]
- Yang, H.; Yang, Z.; Bao, Y.; Liu, S.; Huang, Y. Fcem: A novel fast correlation extract model for real time steganalysis of VOIP stream via multi-head attention. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2822–2826. [Google Scholar]
- Qiu, Y.; Tian, H.; Tang, L.; Mazurczyk, W.; Chang, C.C. Steganalysis of adaptive multi-rate speech streams with distributed representations of codewords. J. Inf. Secur. Appl. 2022, 68, 103250. [Google Scholar] [CrossRef]
- Wei, M.; Li, S.; Liu, P.; Huang, Y.; Yan, Q.; Wang, J.; Zhang, C. Frame-level steganalysis of QIM steganography in compressed speech based on multi-dimensional perspective of codeword correlations. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 8421–8431. [Google Scholar] [CrossRef]
- Tian, H.; Qiu, Y.; Mazurczyk, W.; Li, H.; Qian, Z. STFF-SM: Steganalysis Model Based on Spatial and Temporal Feature Fusion for Speech Streams. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 31, 277–289. [Google Scholar] [CrossRef]
- Qiu, Y.; Tian, H.; Li, H.; Chang, C.C.; Vasilakos, A.V. Separable Convolution Network with Dual-Stream Pyramid Enhanced Strategy for Speech Steganalysis. IEEE Trans. Inf. Forensics Secur. 2023, 18, 2737–2750. [Google Scholar] [CrossRef]
- Hu, Y.; Huang, Y.; Yang, Z.; Huang, Y. Detection of heterogeneous parallel steganography for low bit-rate VoIP speech streams. Neurocomputing 2021, 419, 70–79. [Google Scholar] [CrossRef]
- Li, S.; Wang, J.; Liu, P.; Wei, M.; Yan, Q. Detection of multiple steganography methods in compressed speech based on code element embedding, Bi-LSTM and CNN with attention mechanisms. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1556–1569. [Google Scholar] [CrossRef]
- Tian, H.; Wu, J.; Quan, H.; Chang, C. Detecting Multiple Steganography Methods in Speech Streams Using Multi-Encoder Network. IEEE Signal Process. Lett. 2022, 29, 2462–2466. [Google Scholar] [CrossRef]
- Yang, H.; He, H.; Zhang, W.; Cao, X. FedSteg: A federated transfer learning framework for secure image steganalysis. IEEE Trans. Netw. Sci. Eng. 2020, 8, 1084–1094. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Wikipedia Contributors. Gradient Descent—Wikipedia, The Free Encyclopedia. 2023. Available online: https://en.wikipedia.org/wiki/Gradient_descent (accessed on 23 June 2023).
- Zhu, L.; Liu, Z.; Han, S. Deep leakage from gradients. Adv. Neural Inf. Process. Syst. 2019, 32, 14747–14756. [Google Scholar]
- Melis, L.; Song, C.; De Cristofaro, E.; Shmatikov, V. Exploiting unintended feature leakage in collaborative learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 691–706. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the Advances in Cryptology—EUROCRYPT’99, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar]
- Wang, F.; Zhu, H.; Lu, R.; Zheng, Y.; Li, H. A privacy-preserving and non-interactive federated learning scheme for regression training with gradient descent. Inf. Sci. 2021, 552, 183–200. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Xiao, B.; Huang, Y.; Tang, S. An approach to information hiding in low bit-rate speech stream. In Proceedings of the IEEE GLOBECOM 2008-2008 IEEE Global Telecommunications Conference, New Orleans, LA, USA, 8 December 2008; pp. 1–5. [Google Scholar]
- Chen, B.; Wornell, G.W. Quantization index modulation: A class of provably good methods for digital watermarking and information embedding. IEEE Trans. Inf. Theory 2001, 47, 1423–1443. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, J.; Wang, X.; Hu, J.; Qin, Z.; Ren, K. Threats to Training: A Survey of Poisoning Attacks and Defenses on Machine Learning Systems. ACM Comput. Surv. 2022, 55, 1–36. [Google Scholar] [CrossRef]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated learning on non-IID data: A survey. Neurocomputing 2021, 465, 371–390. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FedSpy | FedSteg | Local Model | Central Model | |
|---|---|---|---|---|
| RNN-SM | ||||
| FCEM | ||||
| DRCM |
| FedSpy | FedSteg | Local Model | Central Model | |
|---|---|---|---|---|
| RNN-SM | ||||
| FCEM | ||||
| DRCM |
| FedSpy | FedSteg | Local Model | Central Model | |
|---|---|---|---|---|
| RNN-SM | ||||
| FCEM | ||||
| DRCM |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, H.; Wang, H.; Quan, H.; Mazurczyk, W.; Chang, C.-C. FedSpy: A Secure Collaborative Speech Steganalysis Framework Based on Federated Learning. Electronics 2023, 12, 2854. https://doi.org/10.3390/electronics12132854
Tian H, Wang H, Quan H, Mazurczyk W, Chang C-C. FedSpy: A Secure Collaborative Speech Steganalysis Framework Based on Federated Learning. Electronics. 2023; 12(13):2854. https://doi.org/10.3390/electronics12132854
Chicago/Turabian StyleTian, Hui, Huidong Wang, Hanyu Quan, Wojciech Mazurczyk, and Chin-Chen Chang. 2023. "FedSpy: A Secure Collaborative Speech Steganalysis Framework Based on Federated Learning" Electronics 12, no. 13: 2854. https://doi.org/10.3390/electronics12132854
APA StyleTian, H., Wang, H., Quan, H., Mazurczyk, W., & Chang, C.-C. (2023). FedSpy: A Secure Collaborative Speech Steganalysis Framework Based on Federated Learning. Electronics, 12(13), 2854. https://doi.org/10.3390/electronics12132854