
A Non-Intrusive Automated Testing System for Internet of Vehicles App Based on Deep Learning
Abstract
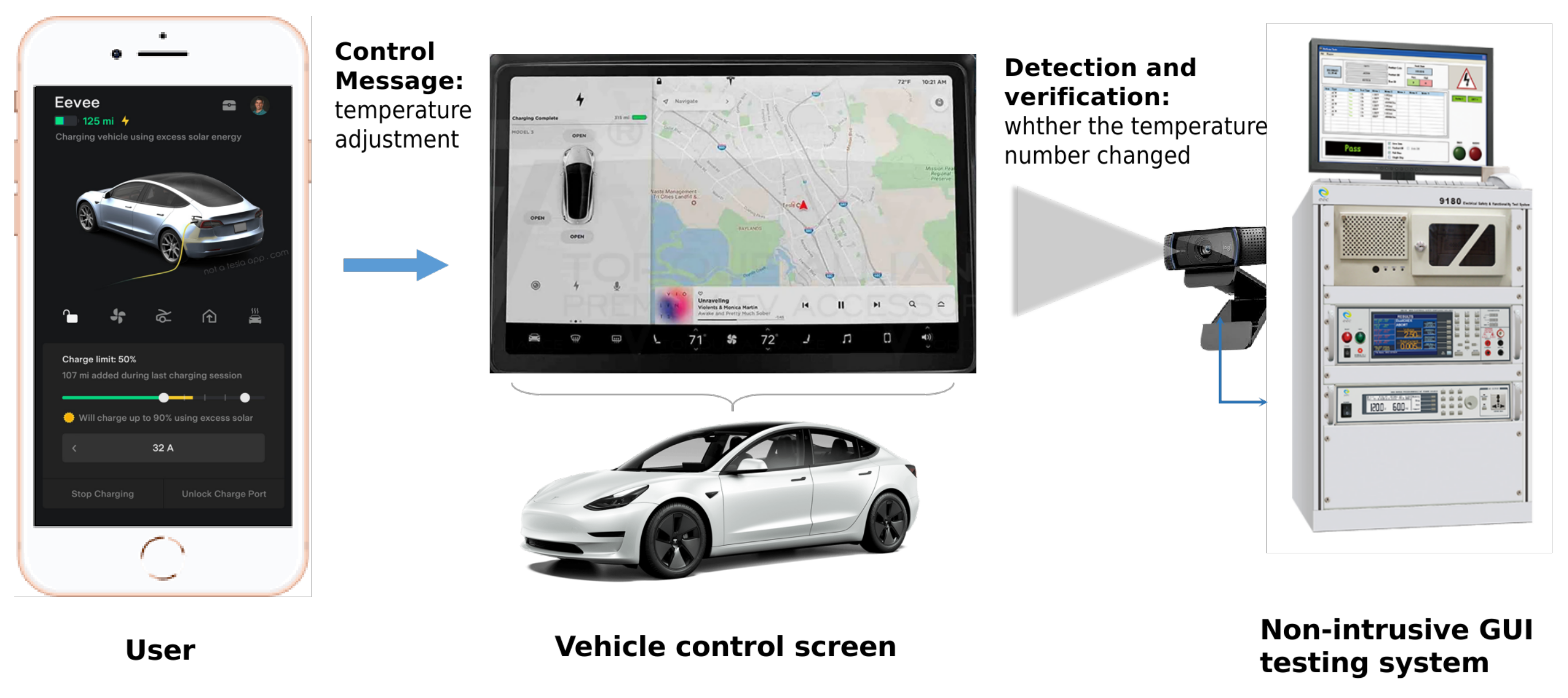
:1. Introduction
- We initially present the VSTDR-2023 dataset, tailored for the detection and recognition of text on vehicular screens. This dataset encompasses a multitude of in-car control images with varying characteristics, thereby enabling text detection and recognition networks to more effectively discern text within vehicular screens.
- We introduce an innovative vehicular control screen text detection and recognition approach based on an enhanced FOTS framework, achieving end-to-end single-stage text detection and recognition. This method bolsters feature semantic representation capacity by sharing text detection and recognition stage features, effectively reducing computational consumption while preserving result accuracy.
- Utilizing a feature transformation module in the enhanced FOTS-based vehicular control screen text detection and recognition approach, we resolve the feature reuse issue in text detection and recognition, augmenting multi-scale feature detection capabilities and ensuring text detection efficacy.
2. Related Works
2.1. Non-Intrusive GUI Testing System
2.2. Text Detection and Recognition Technology
- Lack of mature central control screen dataset. In the application of deep learning or machine learning, a large and high-quality dataset is crucial. For automotive central control screens, there is a wide variety of vehicle models, brands, and interface designs, resulting in highly diverse data. Additionally, the inclusion of various languages, fonts, colors, graphics, dynamic elements, etc., further complicates the data. Currently, there is a lack of comprehensive and high-quality datasets that encompass these factors, making it challenging to train effective models.
- Lack of deep learning GUI text extraction methods suitable for complex automotive central control screens. Non-intrusive testing often requires parsing the GUI of central control screens to identify various elements such as buttons, text, images, etc. However, current deep learning techniques have certain limitations in this regard. The interface designs of automotive central control screens are typically complex and variable, potentially containing multiple languages, various fonts, sizes, colored text, and even dynamic elements and animations. Existing deep learning techniques may struggle to accurately recognize and extract these elements, presenting a major challenge in the field currently.
3. Methods
3.1. Dataset
3.1.1. Image Acquisition and Selection
- Diverse car interiors. Variations in car interiors create differing backgrounds for the vehicle’s central control system, thereby presenting a significant challenge for neural network training. Consequently, it is imperative to select original data images that capture a broad spectrum of car interiors. Typically, car interior designs echo the overall vehicle style, necessitating consideration of different manufacturers and vehicle types.
- Distinct screen materials: The types of screens employed in car central control systems present considerable diversity. For instance, TFT-LCD screens utilize thin-film transistor technology, ensuring high resolution and color performance. Conversely, OLED screens deploy organic light-emitting diode technology, delivering superior brightness, while AMOLED screens, an evolution of OLED screens, feature enhanced brightness and reduced power consumption, typically found in high-end vehicle dashboards or infotainment screens.
- Various screen sizes: Infotainment screens of 6–8 inches are suitable for compact cars, providing smaller size but superior clarity and response speed. Screens ranging from 9–10 inches are more commonplace, suitable for mid-sized vehicles, while 11–13 inch screens are generally reserved for high-end vehicles, boasting larger sizes, multi-touch support, and high-definition video playback capabilities. Figure 2 illustrates the screen in various sizes. As the vehicle manufacturing industry advances, screens larger than 9 inches have gained popularity within vehicle central control systems. Therefore, the dataset should prioritize the collection of such data during the image acquisition process.
- Various screen shapes: Square screens, typically designed with a 4:3 or 16:9 aspect ratio, are commonplace, displaying an array of information and user interfaces. Rectangular screens are lengthier, often featuring a 21:9 aspect ratio, while trapezoidal screens innovate with differing angles at the top and bottom, adapting more effectively to the shape and position of the central control panel. Circular screens are uniquely employed in some high-end vehicle designs, providing drivers with a distinctive visual experience. As square and rectangular screens prevail within the market and circular and trapezoidal screens are typically found in high-end vehicles with a smaller market share, data collection should prioritize square and rectangular screens. Figure 3 illustrates the screen in various shapes.
- Different scenarios: The content displayed on screens varies significantly across different scenarios, primarily in terms of text positioning, font size, and background content, all of which can significantly impact recognition results. Several interfaces should generally be included: media interfaces (music, radio, etc.), phone interfaces (calls, dialing screens), basic settings interfaces (infotainment settings, device connections), and basic information interfaces (fuel consumption, oil life, etc.).
3.1.2. Data Region and Character Content Annotation
- Text region annotation. Text region annotation for vehicle central control screen identification tasks. This entails marking all areas within the vehicle central control screen images that contain text with rectangular boxes and subsequently documenting them. The annotators must ensure that the text regions are comprehensively and accurately encapsulated, while vigilantly preventing the misclassification of non-text regions as text-bearing areas.
- character information Annotation. Annotation of specific character information in vehicle screens. This comprises the creation of annotation information for the images within the dataset. Existing Optical Character Recognition (OCR) tools can be deployed to expedite this process, although manual proofreading is requisite for non-standard, blurred, or distorted texts.
3.1.3. Dataset Splitting
3.1.4. Data Augmentation
3.2. Enhanced FOTS
3.2.1. Shared Feature Extraction Layer
3.2.2. Text Detection
3.2.3. Feature Transformation Module
- Calculate affine transformation coefficients. Calculate the affine transformation coefficients using the predicted or true text box coordinates:In this context, refers to the affine transformation matrix, and represent the height and width of the feature map after affine transformation, respectively. denotes the coordinates of a point in the shared feature map, represent the distance of the pixel to the top, bottom, left, and right sides of the text box, and indicates directionality. These parameters can be either actual label data or predicted data attributes.
- Perform affine transformations. Affine transformations are performed on the shared feature maps of each region to attain standardized horizontal text region feature maps. This can be achieved through the following equation:Affine transformation parameters are calculated using the ground truth coordinates, and these transformations are then applied to the shared feature maps of each candidate region. This results in standardized horizontal feature maps of the text regions. During the network training process, the actual text regions are utilized to train the network. In the testing process, thresholding and Non-Maximum Suppression (NMS) are employed to filter the predicted text regions. Once the data has been processed through the RoIRotate module, the transformed feature maps are fed into the text recognition branch.
3.2.4. Text Recognition
- Initially, transformed feature maps are input, passing through multiple linear convolution and pooling layers. This process reduces the height dimension of the spatial feature map while extracting features of higher dimensionality. Subsequent to this step, we derive the feature vectors to be recognized, forming them into a feature sequence. For simplification, we present the convolution parameters of the VGG network in Table 1.
- Subsequently, the high-dimensional feature sequence is encoded within an RNN network, facilitating the prediction of the label distribution for each feature vector within the sequence. Here, we employ a bidirectional LSTM and designate 256 output channels for each direction. This step yields a probability list of predicted results.
- Following this, the hidden states are computed at each time point in both directions, and the results are summed. These outcomes are then input into a fully connected network, resulting in the distribution of each state within the character classification. Through this step, we obtain the probability distribution of all characters, represented as a vector with a length equivalent to the number of character categories. To circumvent overfitting during training, a dropout layer is inserted prior to full connection.
- Lastly, the probability vector is input into the Connectionist Temporal Classification (CTC) layer. This stage transforms the predictions rendered by each feature vector into a label sequence, addressing the redundancy issue that can occur within the RNN network.
4. Experimental Results
4.1. Experimental Setup
4.2. Evaluation Metrics
4.3. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, F.; Wang, S.; Li, J.; Liu, Z.; Sun, Q. An overview of internet of vehicles. China Commun. 2014, 11, 1–15. [Google Scholar] [CrossRef]
- Elmoiz Alatabani, L.; Sayed Ali, E.; Mokhtar, R.A.; Saeed, R.A.; Alhumyani, H.; Kamrul Hasan, M. Deep and Reinforcement Learning Technologies on Internet of Vehicle (IoV) Applications: Current Issues and Future Trends. J. Adv. Transp. 2022, 2022, 1947886. [Google Scholar] [CrossRef]
- Hamid, U.Z.A.; Zamzuri, H.; Limbu, D.K. Internet of vehicle (IoV) applications in expediting the implementation of smart highway of autonomous vehicle: A survey. In Performability in Internet of Things; Springer: Cham, Switzerland, 2019; pp. 137–157. [Google Scholar]
- Svangren, M.K.; Skov, M.B.; Kjeldskov, J. The connected car: An empirical study of electric cars as mobile digital devices. In Proceedings of the 19th International Conference on Human-Computer Interaction with Mobile Devices and Services, Vienna, Austria, 4–7 September 2017; pp. 1–12. [Google Scholar]
- Schipor, O.A.; Vatavu, R.D.; Vanderdonckt, J. Euphoria: A Scalable, event-driven architecture for designing interactions across heterogeneous devices in smart environments. Inf. Softw. Technol. 2019, 109, 43–59. [Google Scholar] [CrossRef]
- Rohm, A.J.; Gao, T.T.; Sultan, F.; Pagani, M. Brand in the hand: A cross-market investigation of consumer acceptance of mobile marketing. Bus. Horiz. 2012, 55, 485–493. [Google Scholar] [CrossRef]
- Menzel, T.; Bagschik, G.; Maurer, M. Scenarios for development, test and validation of automated vehicles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1821–1827. [Google Scholar]
- Banerjee, I.; Nguyen, B.; Garousi, V.; Memon, A. Graphical user interface (GUI) testing: Systematic mapping and repository. Inf. Softw. Technol. 2013, 55, 1679–1694. [Google Scholar] [CrossRef]
- Chang, T.H.; Yeh, T.; Miller, R.C. GUI testing using computer vision. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; pp. 1535–1544. [Google Scholar]
- Borjesson, E.; Feldt, R. Automated system testing using visual gui testing tools: A comparative study in industry. In Proceedings of the 2012 IEEE Fifth International Conference on Software Testing, Verification and Validation, Montreal, QC, Canada, 17–21 April 2012; pp. 350–359. [Google Scholar]
- Herbold, S.; Grabowski, J.; Waack, S.; Bünting, U. Improved bug reporting and reproduction through non-intrusive gui usage monitoring and automated replaying. In Proceedings of the 2011 IEEE Fourth International Conference on Software Testing, Verification and Validation Workshops, Berlin, Germany, 21–25 March 2011; pp. 232–241. [Google Scholar]
- Singh, S.; Gadgil, R.; Chudgor, A. Automated testing of mobile applications using scripting technique: A study on appium. Int. J. Curr. Eng. Technol. (IJCET) 2014, 4, 3627–3630. [Google Scholar]
- Li, A.; Li, C. Research on the Automated Testing Framework for Android Applications. In Proceedings of the 12th International Conference on Computer Engineering and Networks, Haikou, China, 4–7 November 2022; pp. 1056–1064. [Google Scholar]
- Zadgaonkar, H. Robotium Automated Testing for Android; Packt Publishing: Birmingham, UK, 2013. [Google Scholar]
- Dhanapal, K.B.; Deepak, K.S.; Sharma, S.; Joglekar, S.P.; Narang, A.; Vashistha, A.; Salunkhe, P.; Rai, H.G.; Somasundara, A.A.; Paul, S. An Innovative System for Remote and Automated Testing of Mobile Phone Applications. In Proceedings of the 2012 Annual SRII Global Conference, San Jose, CA, USA, 24–27 July 2012; pp. 44–54. [Google Scholar] [CrossRef]
- Qian, J.; Shang, Z.; Yan, S.; Wang, Y.; Chen, L. RoScript: A Visual Script Driven Truly Non-Intrusive Robotic Testing System for Touch Screen Applications. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering (ICSE ’20), Seoul, Republic of Korea, 27 June–19 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 297–308. [Google Scholar] [CrossRef]
- Xie, M.; Ye, J.; Xing, Z.; Ma, L. NiCro: Purely Vision-based, Non-intrusive Cross-Device and Cross-Platform GUI Testing. arXiv 2023, arXiv:2305.14611. [Google Scholar]
- Chen, J.; Xie, M.; Xing, Z.; Chen, C.; Xu, X.; Zhu, L.; Li, G. Object Detection for Graphical User Interface: Old Fashioned or Deep Learning or a Combination? Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Zuo, L.Q.; Sun, H.M.; Mao, Q.C.; Qi, R.; Jia, R.S. Natural scene text recognition based on encoder-decoder framework. IEEE Access 2019, 7, 62616–62623. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, Y.; Cheng, Z.; Pu, S.; Niu, Y.; Wu, F.; Zou, F. SPIN: Structure-preserving inner offset network for scene text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 3305–3314. [Google Scholar]
- Chen, X.; Jin, L.; Zhu, Y.; Luo, C.; Wang, T. Text recognition in the wild: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Wang, Y.; Xie, H.; Zha, Z.J.; Xing, M.; Fu, Z.; Zhang, Y. Contournet: Taking a further step toward accurate arbitrary-shaped scene text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11753–11762. [Google Scholar]
- Tian, Z.; Shu, M.; Lyu, P.; Li, R.; Zhou, C.; Shen, X.; Jia, J. Learning shape-aware embedding for scene text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4234–4243. [Google Scholar]
- Odeh, A.; Odeh, M.; Odeh, H.; Odeh, N. Hand-Written Text Recognition Methods: Review Study; International Information and Engineering Technology Association: Washington, DC, USA, 2022. [Google Scholar]
- Hwang, W.Y.; Nguyen, V.G.; Purba, S.W.D. Systematic survey of anything-to-text recognition and constructing its framework in language learning. Educ. Inf. Technol. 2022, 27, 12273–12299. [Google Scholar] [CrossRef]
- Liu, X.; Meng, G.; Pan, C. Scene text detection and recognition with advances in deep learning: A survey. Int. J. Doc. Anal. Recognit. (IJDAR) 2019, 22, 143–162. [Google Scholar] [CrossRef]
- Long, S.; He, X.; Yao, C. Scene text detection and recognition: The deep learning era. Int. J. Comput. Vis. 2021, 129, 161–184. [Google Scholar] [CrossRef]
- Liao, M.; Wan, Z.; Yao, C.; Chen, K.; Bai, X. Real-time scene text detection with differentiable binarization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11474–11481. [Google Scholar]
- Aberdam, A.; Litman, R.; Tsiper, S.; Anschel, O.; Slossberg, R.; Mazor, S.; Manmatha, R.; Perona, P. Sequence-to-sequence contrastive learning for text recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–20 June 2021; pp. 15302–15312. [Google Scholar]
- Alsamadony, K.L.; Yildirim, E.U.; Glatz, G.; Waheed, U.B.; Hanafy, S.M. Deep learning driven noise reduction for reduced flux computed tomography. Sensors 2021, 21, 1921. [Google Scholar] [CrossRef] [PubMed]
- Abdallah, A.; Hamada, M.; Nurseitov, D. Attention-based fully gated CNN-BGRU for Russian handwritten text. J. Imaging 2020, 6, 141. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.H.; Jo, J.H.; Teng, Z.; Kang, D.J. Text detection with deep neural network system based on overlapped labels and a hierarchical segmentation of feature maps. Int. J. Control. Autom. Syst. 2019, 17, 1599–1610. [Google Scholar] [CrossRef]
- Hozhabr Pour, H.; Li, F.; Wegmeth, L.; Trense, C.; Doniec, R.; Grzegorzek, M.; Wismüller, R. A machine learning framework for automated accident detection based on multimodal sensors in cars. Sensors 2022, 22, 3634. [Google Scholar] [CrossRef]
- Celaya-Padilla, J.M.; Galván-Tejada, C.E.; Lozano-Aguilar, J.S.A.; Zanella-Calzada, L.A.; Luna-García, H.; Galván-Tejada, J.I.; Gamboa-Rosales, N.K.; Velez Rodriguez, A.; Gamboa-Rosales, H. “Texting & Driving” detection using deep convolutional neural networks. Appl. Sci. 2019, 9, 2962. [Google Scholar]
- Hardalaç, F.; Uysal, F.; Peker, O.; Çiçeklidağ, M.; Tolunay, T.; Tokgöz, N.; Kutbay, U.; Demirciler, B.; Mert, F. Fracture detection in wrist X-ray images using deep learning-based object detection models. Sensors 2022, 22, 1285. [Google Scholar] [CrossRef]
- Zhang, R.; Shao, Z.; Huang, X.; Wang, J.; Li, D. Object detection in UAV images via global density fused convolutional network. Remote Sens. 2020, 12, 3140. [Google Scholar] [CrossRef]
- Shanmugavel, A.B.; Ellappan, V.; Mahendran, A.; Subramanian, M.; Lakshmanan, R.; Mazzara, M. A Novel Ensemble Based Reduced Overfitting Model with Convolutional Neural Network for Traffic Sign Recognition System. Electronics 2023, 12, 926. [Google Scholar] [CrossRef]
- Liu, M.; Li, B.; Zhang, W. Research on Small Acceptance Domain Text Detection Algorithm Based on Attention Mechanism and Hybrid Feature Pyramid. Electronics 2022, 11, 3559. [Google Scholar] [CrossRef]
- Ganesan, J.; Azar, A.T.; Alsenan, S.; Kamal, N.A.; Qureshi, B.; Hassanien, A.E. Deep Learning Reader for Visually Impaired. Electronics 2022, 11, 3335. [Google Scholar] [CrossRef]
- Peng, H.; Yu, J.; Nie, Y. Efficient Neural Network for Text Recognition in Natural Scenes Based on End-to-End Multi-Scale Attention Mechanism. Electronics 2023, 12, 1395. [Google Scholar] [CrossRef]
- Gong, H.; Liu, T.; Luo, T.; Guo, J.; Feng, R.; Li, J.; Ma, X.; Mu, Y.; Hu, T.; Sun, Y.; et al. Based on FCN and DenseNet Framework for the Research of Rice Pest Identification Methods. Agronomy 2023, 13, 410. [Google Scholar] [CrossRef]
- Akhtar, M.J.; Mahum, R.; Butt, F.S.; Amin, R.; El-Sherbeeny, A.M.; Lee, S.M.; Shaikh, S. A Robust Framework for Object Detection in a Traffic Surveillance System. Electronics 2022, 11, 3425. [Google Scholar] [CrossRef]
- Lee, H.J.; Ullah, I.; Wan, W.; Gao, Y.; Fang, Z. Real-time vehicle make and model recognition with the residual SqueezeNet architecture. Sensors 2019, 19, 982. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, T.; Li, L.; Wu, X.; Chen, R.; Li, H.; Lu, G.; Cheng, L. TSA-SCC: Text semantic-aware screen content coding with ultra low bitrate. IEEE Trans. Image Process. 2022, 31, 2463–2477. [Google Scholar] [CrossRef] [PubMed]
- Nagy, V.; Kovács, G.; Földesi, P.; Kurhan, D.; Sysyn, M.; Szalai, S.; Fischer, S. Testing Road Vehicle User Interfaces Concerning the Driver’s Cognitive Load. Infrastructures 2023, 8, 49. [Google Scholar] [CrossRef]
- Gao, Y.; Feng, J.; Liu, F.; Liu, Z. Effects of Organic Vehicle on the Rheological and Screen-Printing Characteristics of Silver Paste for LTCC Thick Film Electrodes. Materials 2022, 15, 1953. [Google Scholar] [CrossRef]
- Xue, H.; Zhang, Q.; Zhang, X. Research on the Applicability of Touchscreens in Manned/Unmanned Aerial Vehicle Cooperative Missions. Sensors 2022, 22, 8435. [Google Scholar] [CrossRef]
- Yu, Z.; Xiao, P.; Wu, Y.; Liu, B.; Wu, L. A Novel Automated GUI Testing Echnology Based on Image Recognition. In Proceedings of the 2016 IEEE 18th International Conference on High Performance Computing and Communications, IEEE 14th International Conference on Smart City IEEE 2nd International Conference on Data Science and Systems (HPCC/SmartCity/DSS). Sydney, Australia, 12–14 December 2016; pp. 144–149. [Google Scholar] [CrossRef]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN variants for computer vision: History, architecture, application, challenges and future scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- You, N.; Han, L.; Zhu, D.; Song, W. Research on image denoising in edge detection based on wavelet transform. Appl. Sci. 2023, 13, 1837. [Google Scholar] [CrossRef]
- Tadic, V. Study on Automatic Electric Vehicle Charging Socket Detection Using ZED 2i Depth Sensor. Electronics 2023, 12, 912. [Google Scholar] [CrossRef]
- Alaskar, H.; Hussain, A.; Al-Aseem, N.; Liatsis, P.; Al-Jumeily, D. Application of convolutional neural networks for automated ulcer detection in wireless capsule endoscopy images. Sensors 2019, 19, 1265. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Zhu, G.; Shu, J. A combination of lie group machine learning and deep learning for remote sensing scene classification using multi-layer heterogeneous feature extraction and fusion. Remote Sens. 2022, 14, 1445. [Google Scholar] [CrossRef]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [Green Version]
- Panhwar, M.A.; Memon, K.A.; Abro, A.; Zhongliang, D.; Khuhro, S.A.; Memon, S. Signboard detection and text recognition using artificial neural networks. In Proceedings of the 2019 IEEE 9th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 12–14 July 2019; pp. 16–19. [Google Scholar]
- Xiao, Y.; Xue, M.; Lu, T.; Wu, Y.; Palaiahnakote, S. A text-context-aware CNN network for multi-oriented and multi-language scene text detection. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; pp. 695–700. [Google Scholar]
- Chen, X.; Lv, Z.; Zhu, D.; Yu, C. Ticket Text Detection and Recognition Based on Deep Learning. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 3922–3926. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Convolution Kernel Size [Scale, Step-Size] | Output Channels |
|---|---|---|
| Convolutional layers | [3, 1] | 64 |
| Convolutional layers | [3, 1] | 64 |
| Height dimension pooling | [(2, 1), (2, 1)] | 64 |
| Convolutional layers | [3, 1] | 128 |
| Convolutional layers | [3, 1] | 128 |
| height dimension pooling | [(2, 1), (2, 1)] | 128 |
| Convolutional layers | [3, 1] | 256 |
| Convolutional layers | [3, 1] | 256 |
| height dimension pooling | [(2, 1), (2, 1)] | 256 |
| Bidirectional LSTM | [3, 1] | 256 |
| Text Detection Module | Feature Transformation Module | Precision (%) | Recall (%) | F Score (%) |
|---|---|---|---|---|
| 67.23 | 63.21 | 65.16 | ||
| √ | 79.52 | 75.58 | 77.52 | |
| √ | 70.12 | 66.43 | 68.26 | |
| √ | √ | 95.77 | 91.27 | 93.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Guo, Z.; Sun, T. A Non-Intrusive Automated Testing System for Internet of Vehicles App Based on Deep Learning. Electronics 2023, 12, 2873. https://doi.org/10.3390/electronics12132873
Zhang Y, Guo Z, Sun T. A Non-Intrusive Automated Testing System for Internet of Vehicles App Based on Deep Learning. Electronics. 2023; 12(13):2873. https://doi.org/10.3390/electronics12132873
Chicago/Turabian StyleZhang, Yanan, Zhen Guo, and Tao Sun. 2023. "A Non-Intrusive Automated Testing System for Internet of Vehicles App Based on Deep Learning" Electronics 12, no. 13: 2873. https://doi.org/10.3390/electronics12132873