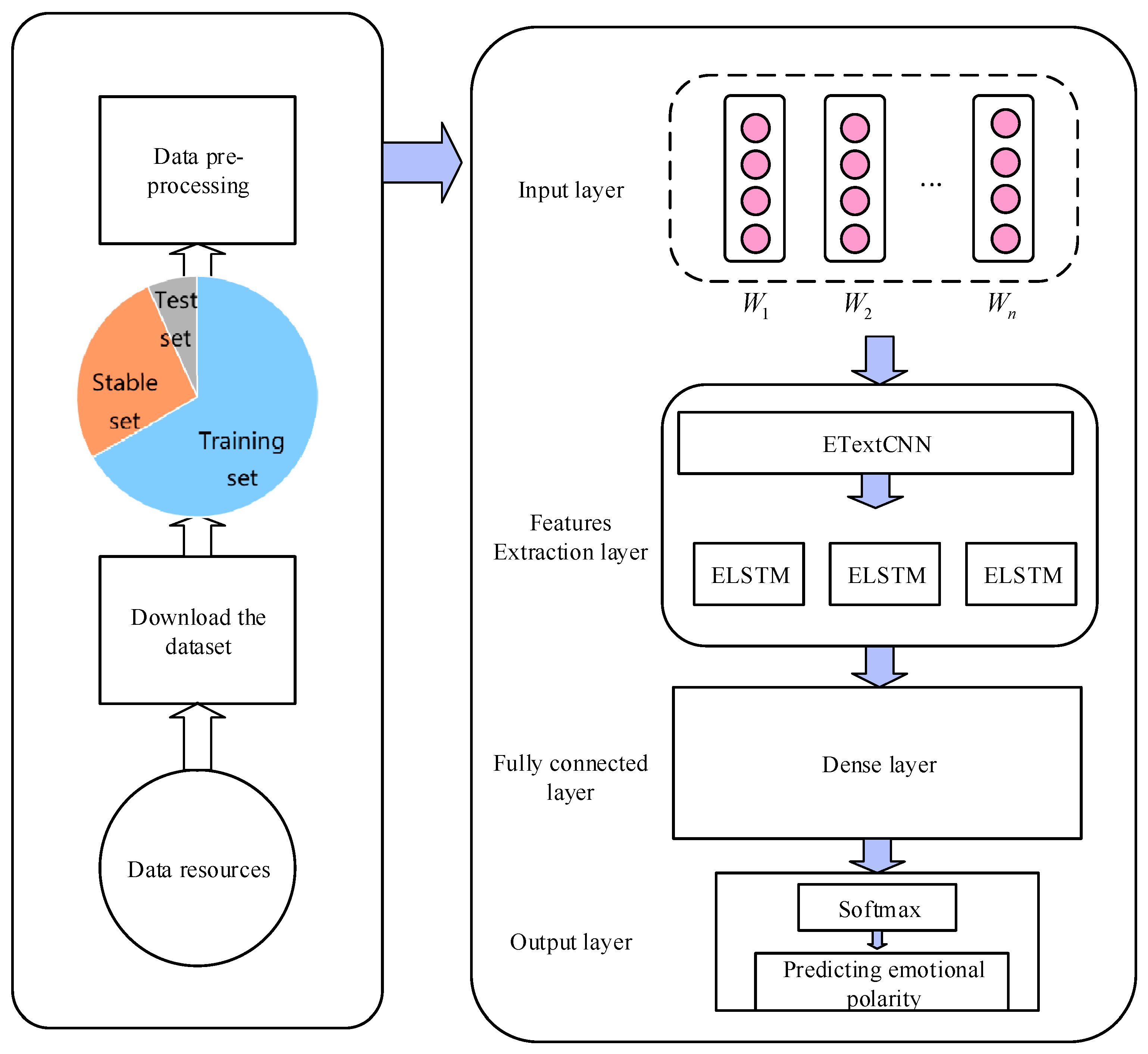
4.1. Datasets and Pre-Processing
To more fully validate the applicability and stability of the model proposed in this paper, experiments were conducted on two Chinese datasets, namely the microblog review dataset simplifyweibo_4_moods and the hotel review dataset ChnSentiCorp_htl_all, which are described below.
The data were prepared from the official Weibo comment dataset simplifyweibo_4_moods downloaded from the web, containing four emotions: joy, anger, disgust, and depression. Each category had about 50,000 comments. The labeling methods and some of the data are shown in
Table 1 and
Table 2. As each comment came from the web and used more symbolic language, regular expressions were applied to clean the comments. The words were split using Jieba in Python, and the length of each comment after breaking was calculated in preparation for creation of the splitter below.
Figure 6 demonstrates that the number of reviews selected for each category in the chosen dataset was evenly distributed. The frequency histogram in
Figure 7 shows the length of each sentence after the word splitting process, and it can be seen that the average size was 95 words and most comments were under 100 words, so the maximum number of words chosen for the next splitter was 100.
After the first part of the analysis, an understanding of the parameters of the word splitter was obtained. The Keras tokenizer was used to process the word-sorted data to obtain a matrix of training, stable, and test datasets, as well as a dictionary of the frequency and number of words corresponding to the occurrences. The dimensionality of the data processed by the sorter was 20,000 × 100 for the training set, 8000 × 100 for the stable set, and 2000 × 100 for the test set, which accounted for 66.7%, 26.7%, and 6.7% of the dataset, respectively.
The ChnSentiCorp_htl_all dataset was a dataset compiled by Mr. Songbo Tan with 7766 hotel reviews, including 5322 positive reviews and 2444 negative reviews. The allocation for the dataset was 4660 training samples, 1553 validation samples, and 1553 test samples for various sentiment analysis-related experiments. They accounted for 60%, 20%, and 20% of the dataset, respectively. The labeling methods and some of the comment data are shown in
Table 3 and
Table 4.
4.5. Analysis of Experimental Results
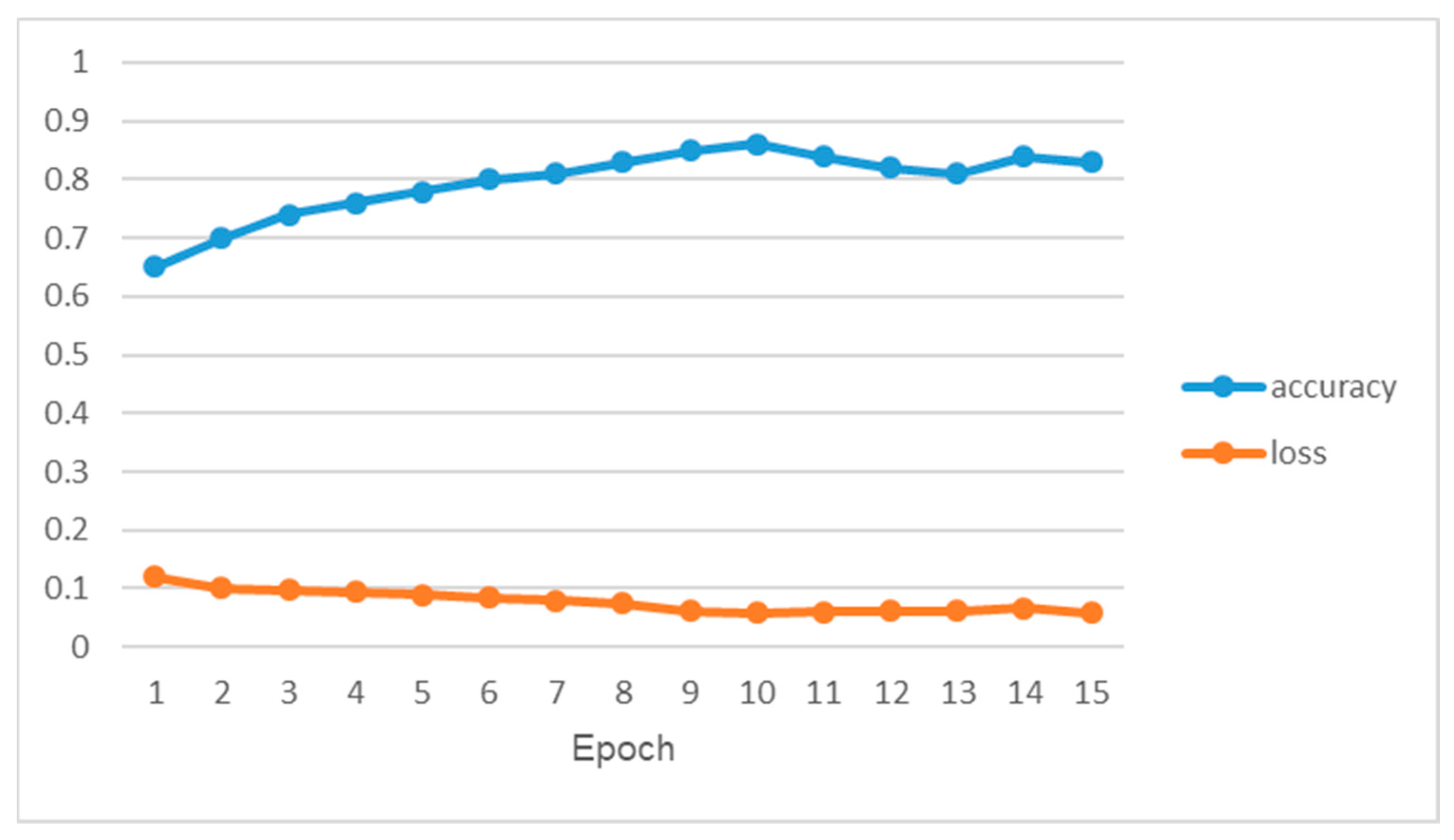
The error and accuracy obtained by the BERT-ETextCNN-ELSTM model trained on the simplifyweibo_4_moods and ChnSentiCorp_htl_all datasets at different numbers of iterations are shown in
Figure 8 and
Figure 9. We can see that the accuracy of the model on the training set reached its highest at the 10th iteration, and therefore the number of iterations for this model was chosen to be 10.
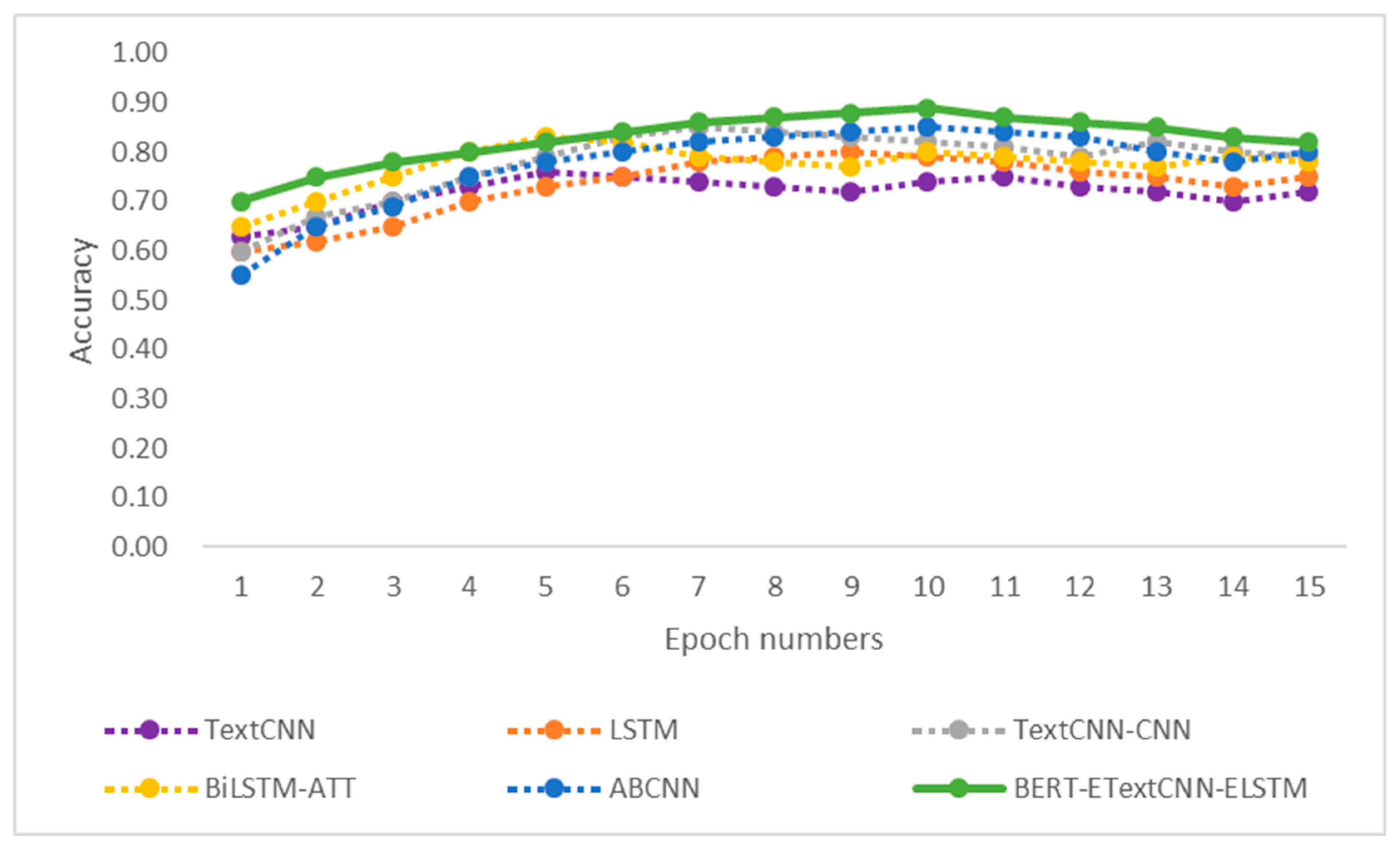
From the above experiments, we can see that the number of iterations also affected the performance of the models, so we compared the results of each comparison model at different iterations to select the most appropriate number of iterations.
Figure 10 and
Figure 11 show the experimental results for the six comparison models on the simplifyweibo_4_moods and ChnSentiCorp_htl_all datasets at different numbers of iterations.
From the above results, it can be seen that the BERT-ETextCNN-ELSTM model achieved the best sentiment analysis performance on both datasets compared to the other five comparison models, and it can also be seen that the best results were achieved when the number of iterations was 10, so the number of iterations for the model in this paper was set to 10.
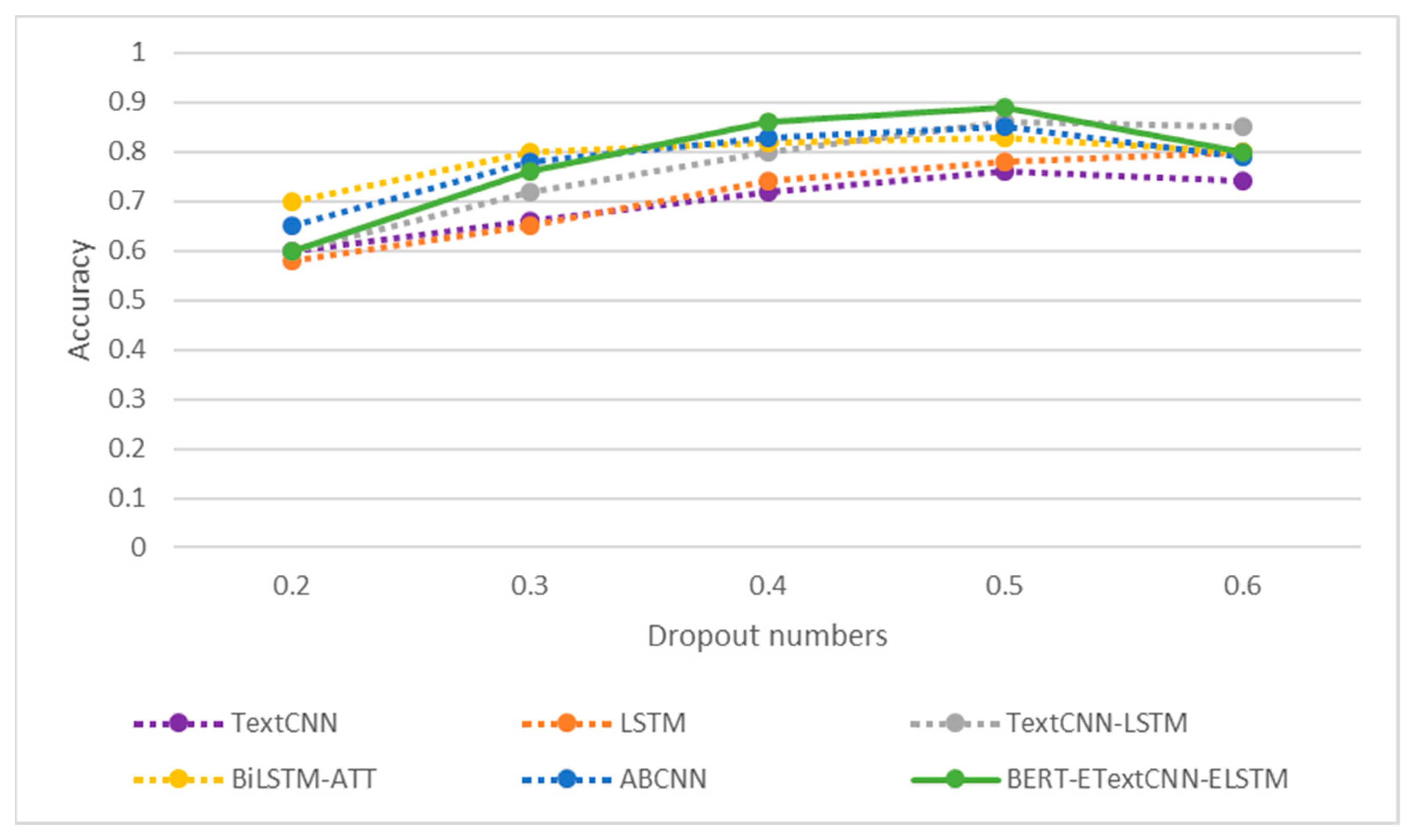
In the training process of the model, this experiment introduced the dropout method. The dropout value is an important parameter, and a suitable value can make the model converge better, prevent the model from overfitting, and improve the performance of the model. Therefore, we chose different dropout values for training. The dropout values set in this experiment were [0.2, 0.3, 0.4, 0.5, 0.6, 0.7], and the best dropout value was selected from the training results of the model. The experiments were conducted on the simplifyweibo_4_moods dataset and the results of the experiments on the simplifyweibo_4_moods and ChnSentiCorp_htl_all dataset are shown in
Figure 12 and
Figure 13. Through the results we can see that only the LSTM model worked best when the dropout value was 0.6, while the rest of the models achieved the best results when the dropout value was 0.5. The dropout value at this time could guarantee the accuracy of the results on the premise of the dropout value effectively preventing the model from overfitting, so the dropout value of the model in this paper was set to 0.5.
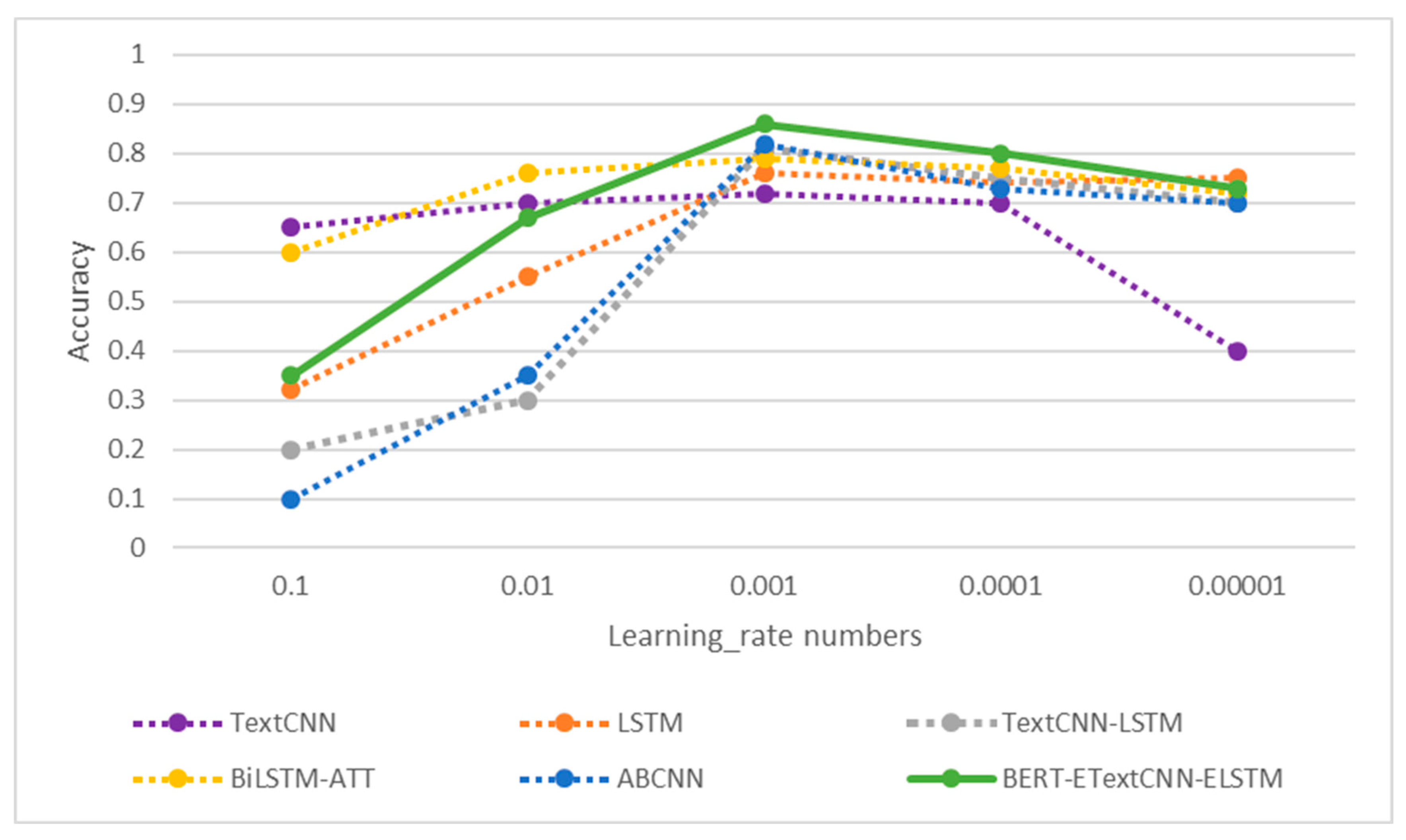
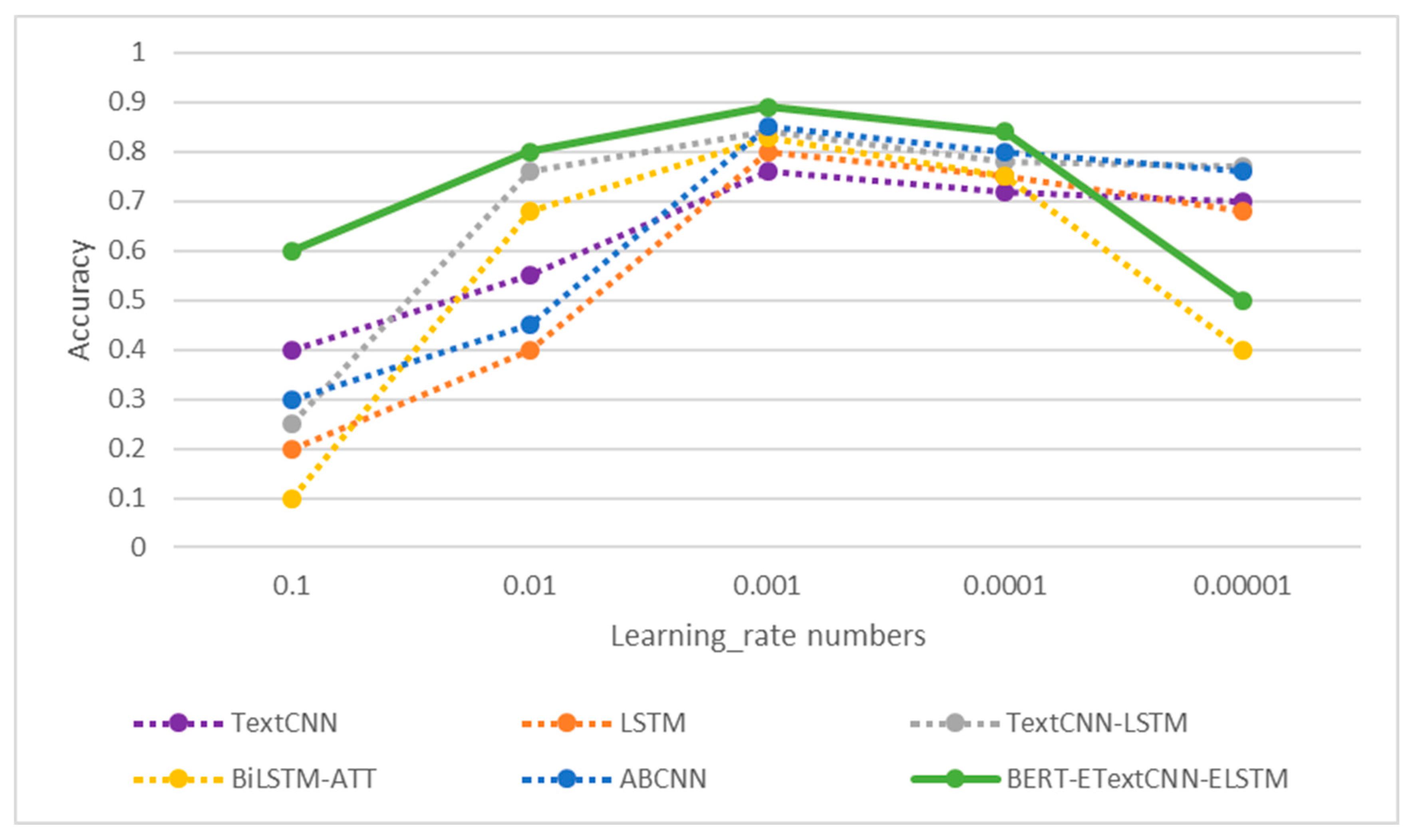
In the process of gradient back propagation to update the parameters of the neural network, the optimizer used in this experiment was Adam. The Adam optimization algorithm is computationally efficient and converges quickly. To better exploit the efficiency of this algorithm, this paper chose different learning rate values to conduct experiments on the simplifyweibo_4_moods and ChnSentiCorp_htl_all datasets. The results on the simplifyweibo_4_moods and ChnSentiCorp_htl_all datasets are shown in
Figure 14 and
Figure 15. From the experimental results, it can be seen that the model had the highest accuracy when the corresponding learning rate of Adam was 0.001. Therefore, the learning rate of the Adam optimizer in this paper was taken to be 0.001.
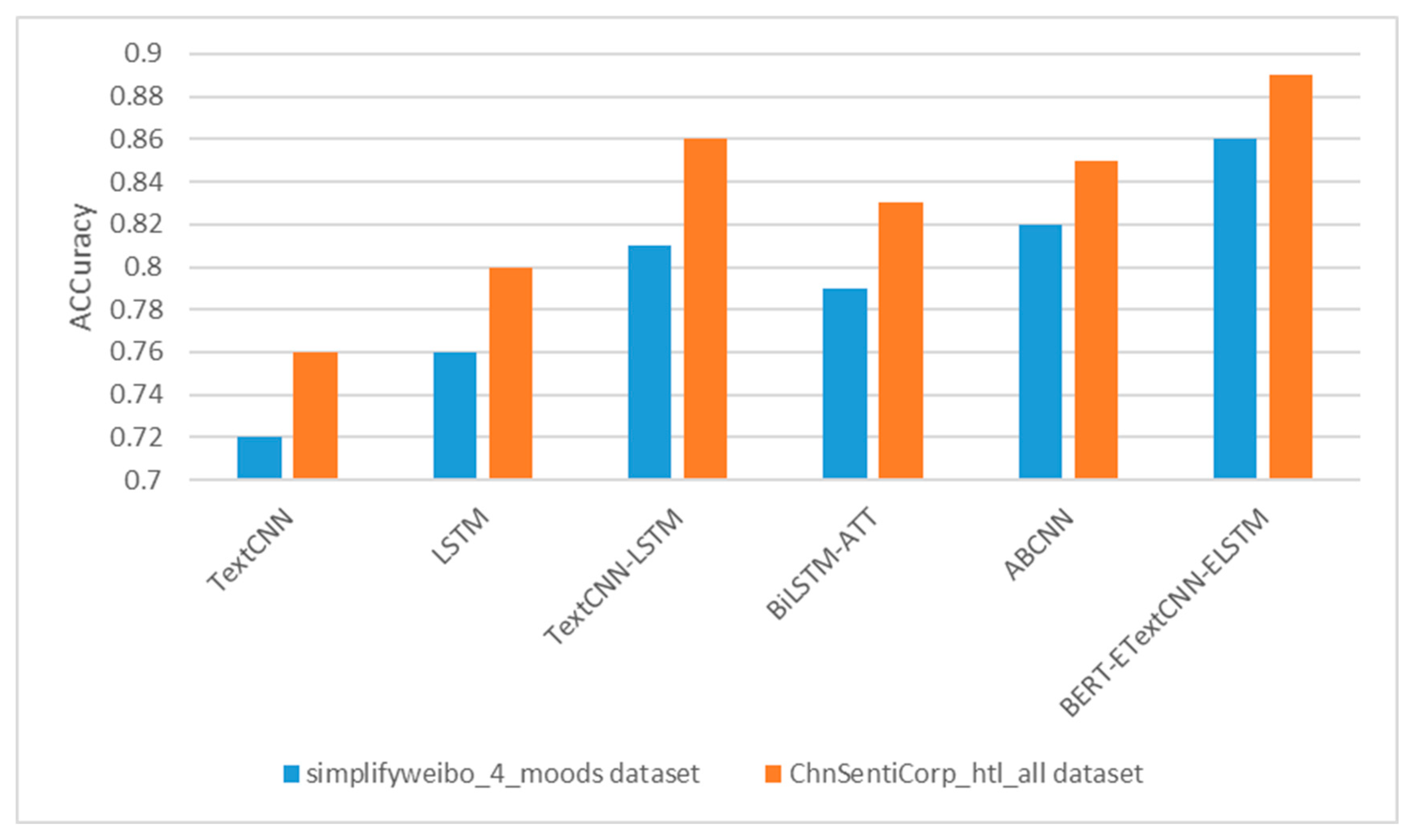
The experimental results of the proposed model and other comparative models on the simplifyweibo_4_moods and ChnSentiCorp_htl_all datasets are shown in
Table 6 and
Table 7 and
Figure 16. To verify the effectiveness of the hybrid (combined, fused) neural network model proposed in this paper, using pre-trained models as well as optimized ones, several classical models were selected for comparison experiments. In the single neural network approach to sentiment analysis, the TextCNN and LSTM models were selected for comparison experiments. In the hybrid (combined, fused) neural network approach to sentiment analysis, among the sentiment analysis methods that introduce an attention mechanism, BiLSTM-ATT and Attention-Based Convolutional Neural Network (ABCNN) were chosen for comparison experiments. In both experiments, the best results of each model were selected for comparison.
From the experimental results, it can be seen that the BERT-ETextCNN-ELSTM model proposed in this paper achieved the best sentiment analysis performance on both the simplifyweibo_4_moods and ChnSentiCorp_htl_all datasets, with the highest accuracy, F1 value, and macro-average F1 value. From the results, it can be seen that the overall performances of TextCNN-LSTM, BiLSTM-ATT, Attention-Based Convolutional Neural Network (ABCNN), and the model in this paper, BERT-ETextCNN-ELSTM, were significantly higher than those of TextCNN and LSTM. Additionally, the hybrid (combined, fused) neural networks for sentiment analysis compared to single neural network approaches were studied, and the advantages of different approaches were considered before combining and improving these approaches. Their use for sentiment analysis achieved good results, indicating that this approach was significantly effective in alleviating the problem of reliance on the model’s structure. Among the hybrid models, the performance of the model proposed in this paper, BERT-ETextCNN-ELSTM, was significantly higher than that of TextCNN-LSTM, BiLSTM-ATT, and ABCNN, indicating that the BERT model incorporated in this paper could better handle contextual information and deal with problems such as polysemy and ambiguity. In addition, the optimization of TextCNN-LSTM in this paper enabled the model to more fully exploit the deep semantic information of short textbooks, thus further improving sentiment analysis of comment data.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}