1. Introduction
A smart site is created through a combination of Internet big data, artificial intelligence, and other synergies of various technologies, along with deep integration in physical construction to achieve intelligent and efficient site safety information management in construction sites [
1]. Compared with traditional building sites, it is more efficient, less expensive, and allows for the real-time monitoring of worker health and safety. Smart site construction occupies an important position in the modern development process, making construction environment management more secure and reliable [
2]. The construction industry, which is one of China’s pillar industries, has ushered in a rapid development at the moment; however, the construction site environment is complex, the scope of the project is challenging, and there are risks to workers’ safety and health as a result of accidents such as land collapse, falls from great heights, electrocution, and summer construction workers passing out from heatstroke. Therefore, the timely detection of whether a patient has fallen or is lying down and the provision of medical assistance are critical factors to the patient’s health, especially for older workers, as a delay could otherwise be fatal. The detection of abnormal human behavior in complex backgrounds at construction sites is a difficult topic because there are still many challenges to doing so, including occlusions, camera movements, the large scale of contemporary engineering projects with large amounts of information, and the similarity between actions.
Traditional behavior recognition algorithms rely on the manual design of feature vectors that can represent behavior [
3]. For example, Ahmad et al. [
4] extracted specific information from multiple features to identify targeted regions; the authors extracted variables such as the velocity features, color features, and texture features of abnormal behavior and then combined them with particle filtering algorithms for pedestrian tracking. Wang et al. [
5] combined three features, namely a gradient histogram, optical flow gradient histogram, and motion boundary histogram, wherein a method based on multi-feature fusion was beneficial for improving the accuracy of behavior recognition. These traditional methods only perform well on specific datasets with weak model generalization, making it difficult to apply to complex, real-world contexts.
Deep learning has quickly grown in recent years and is now frequently utilized in the research of human behavior recognition, bettering traditional algorithms in terms of their performance. For example, Xie et al. [
6] proposed inputting RGB images and optical flow information images of video frames to the same convolutional neural network (CNN) separately; the RGB images provide contour information and the optical flow frames provide timing information so as to obtain two prediction results, and the two resultant features are finally fused together for classification. However, the sequence motion features extracted by the dual-stream network are not complete enough, and the temporal convolution can only extract the sequence motion features of adjacent frames and split the time and space, which will reduce the accuracy rate. Shen et al. [
7] proposed a random pooling method based on dropout improvement and applied it to a 3D convolutional neural network (3DCNN) for human behavior recognition to solve the overfitting problem and enhance the generalization ability. Ma et al. [
8] proposed a dual-stream CNN combined with Bi-LSTM and created a behavior recognition model by adding a convolutional attention module for dual-stream feature extraction, which is capable of adaptively assigning weights and improving the accuracy of unsafe behavior recognition for construction workers. However, these algorithms are susceptible to complex backgrounds in the video, and high-resolution pixel images are used to directly enter the convolutional model calculation, which is computationally extensive and affects the speed of behavior recognition.
Compared with behavior recognition that is based on RGB images and videos, which were studied relatively early, skeletal behavior recognition is more intuitive; has a relatively small amount of data computation; is more resistant to complex environments, body proportions, occlusion lighting changes, and camera shooting angles; and has more research potential, as domestic and foreign research scholars have only drawn attention to behavior recognition based on the human skeleton as of 2017. The essential points of the human body can be retrieved from the video sequence by using a pose estimation technique, or the depth camera can directly acquire the skeleton sequence, where the skeleton sequence information is then fed into graph convolutional networks (GCNs), convolutional neural networks (CNNs), or recurrent neural networks (RNNs) for classification.
The graph convolutional network is an advanced deep learning technique that is based on a graph structure. The human skeleton structure sequence is a naturally occurring topological graph structure, with the skeleton nodes serving as the graph’s vertices and the skeleton points acting as its edges. Standard neural networks like CNNs and RNNs have limitations in processing graph inputs because they stack the features of nodes in a specific order [
9]. To overcome this constraint, GCNs are separately propagated at each node while ignoring the input order of the nodes, which is more advantageous than CNNs and RNNs in terms of processing graph data and learning feature information more efficiently.
Yan et al. [
10] first combined a GCN with skeletal key points recognition and proposed the spatio-temporal graph convolutional network (ST-GCN) model, which had better robustness and novelty and triggered a series of subsequent improvement studies. For example, Li et al. [
11] designed a trainable actional links inference module (AIM) to extend the previously set linkage relations on the original graph convolution to model long-range global dependencies, which compensates for the previous deficiency where the more distant linkage relations of ST-GCN were ignored and extracts more global information. Zhou et al. [
12] proposed a PoseC3D-based action recognition model, which first extracts information about the key points of the human skeleton and then generates a 3D heat map, which is stacked and inputted into a 3D-CNN classification network to output the recognition results, improving the robustness of the model to noise-laden skeleton sequences in complex motion backgrounds. All of these techniques have enhanced network performance, but the network structures are intricate and still have drawbacks.
To address the aforementioned issues, this paper adopts the high-precision human posture estimation algorithm Alphapose to extract the key point data of the human skeleton in the video and selects the ST-GCN as the base model for behavior recognition and for monitoring whether there is abnormal behavior in falling and lying down.
In the
Section 1, we discuss the significance of the study, the current state of research, and the limitations of behavior recognition. In
Section 2, we present the theory related to the conventional methods and pose estimation algorithms for the foreground extraction and action recognition models. In
Section 3, we improve the detection accuracy of the Alphapose algorithm and propose a new NAM-STGCN action recognition model that includes an attention mechanism module and whose structure is optimized by using the activation function PReLU. The model’s training and validation experiments are conducted in
Section 4 of this work, which significantly increases the model’s accuracy for identifying abnormal behavior and lowers its loss value. Finally, we compare the model with other classical classification models to draw conclusions and enhance intelligent information security management at construction sites.
4. Experiments and Results Analysis
4.1. Dataset Creation
Due to the lack of behavioral datasets with construction sites as the application setting and due to their poor generality, we created a behavioral recognition dataset and identified and classified the abnormal behaviors that construction workers are likely to engage in.
Given that workers often carry out construction work, directing machine operations, equipment inspection, and other activities in the summer, they are prone to heat stroke or fainting from illness. This study defines five types of normal movements, such as sitting down, waving hands, sitting, standing up, and walking, and two types of abnormal movements, such as falling and lying down, forming a total of seven categories. Four of the fall videos are from the publicly available Le2i fall detection dataset; the rest were taken by eight volunteers from the lab in two locations, the hallway and the living room, to simulate normal and abnormal actions that may occur during worker construction, and they were captured on video using cell phones.
We used both horizontal flip and luminance enhancement to enhance the video data; there was a total of 303 videos with a video resolution of 640 × 480 and a frame rate of 25 fps and about 45,400 frames of skeletal sequence maps for training and testing, which contained 195 normal action videos and 108 abnormal action videos. The duration of each video shot is 5–7 s. The data were shot utilizing various angles, distances, and periods of acquisition while accounting for the actual project camera angle, a light background, and other aspects. Some of the self-built dataset keyframe images are shown in
Figure 9.
The self-constructed behavioral dataset consists of a total of 303 videos, with 80% of the dataset used being randomly divided into the training set and 20% being divided into the test set. Before training and evaluating the model, the human skeleton information in the action video was extracted frame-by-frame using the Alphapose algorithm and was saved at a frame rate of 25 fps, with each video being shot for 5–7 s and about 45,400 frames of skeletal sequence maps being created. The extracted skeletal key point information was saved as a key-value pair (JavaScript object notation, JSON), which was used for the training and testing of the anomalous behavior recognition network. Given that the real shooting videos were limited and that most of them were used for training, there were 242 JSON files in the training set and 61 JSON files in the test set.
4.2. Experimental Platform and Model Performance Experiments
In order to verify the feasibility and practical effect of the method used in this paper, the improved model was trained and tested. The experiments were conducted based on a 64-bit Windows 10 operating system with the following hardware configurations: the CPU was an Intel(R) Core (TM) i5-8300H @ 2.3GHZ processor, and the GPU was an NVIDIA GeForce GTX 1050Ti with 8GB of RAM. The equipment is all HP Pavilion Gaming Laptop from Baoding, China; software environment: the graphics processing gas pedal was CUDA11.6 and cudnn8.2.1, the programming language was Python3.9, and the deep learning framework was Pytorch1.12.1. The model was trained using the SGD optimizer, the momentum was 0.9, the batch size was set to 16, the number of training iterations (epochs) was set to 150, the base learning rate was 10−2, and the weight decay factor was 10−4.
4.2.1. Discussing the Performance Impact of Different Activation Functions
We optimized the activation functions of the TCN and residual modules in the ST-GCN network. The results on the test set are shown in
Table 2, and the model’s identification accuracy was greatly increased by using the PReLU function. The original ST-GCN model uses the ReLU activation function to solve the gradient disappearance problem caused by sigmoid, but it converts to zero when the input is negative, which causes some neurons to “die” easily during training. To solve this problem, we replaced ReLU with the ParametricReLU (PReLU) function, which has more learning ability and effective features.
Although the LeakyReLU function was used to adjust the gradient in the training experiments by providing a very small constant slope value in the region where the input was negative, which improved the situation where some neurons were never activated, the top 1 accuracy improved by 1.64% relative to the ReLU function of the original model, and the top 5 accuracy reached 100%. However, its gradient depends on manual adjustment and the settings are fixed, which is not flexible; this could result in a poor performance in some cases.
To circumvent these restrictions, we used the PReLU activation function, which converts the gradient values of the negative half-axis into dynamically learnable parameters. This provides us with more freedom to dynamically modify the parameter values during the training process in order to achieve the best training results. This study builds a deeper network layer, and the use of PReLU function is beneficial for ensuring that the gradient runs through the entire model structure while speeding up the convergence of the algorithm and improving the network performance. It was experimentally verified that the accuracy of the top 1 using the PReLU function improved by 3.28% relative to the ReLU function of the original model and by 1.64% relative to the LeakyReLU function; the accuracy of the top 5 also reached 100% with the best results.
4.2.2. Validating the Model Recognition on the Dataset
The performance comparison experiments of the model verified the effectiveness of the optimized model in this paper for recognition on the self-built behavioral dataset. The overall test results of the method in this paper were a 96.72% accuracy for the top 1 and a 98.36% accuracy for the top 5; the accuracy of the top 1 was selected as the final accuracy judging criterion in this paper.
Figure 10 shows a graph of the change in accuracy of the top 1 test set, which was plotted according to the accuracy of the model saved once every 10 iterations. The accuracy curve of the original classical ST-GCN model with the ReLU activation function starts to converge after 50 iterations, and the accuracy rate fluctuates around 90%. However, the curve showed local mutations in the early training period, indicating unstable results, and only reached a maximum accuracy of 91.80% after 140 iterations. The NAM-STGCN model incorporating the normalized attention mechanism module has a higher accuracy than the original model during the first 10 iterations, and the accuracy rate increases slowly in the early stage but gradually converges after 40 iterations; finally, the accuracy rate after convergence is smoothly maintained at 93.44%, and the model performance is improved.
Our final model is a further optimization of the proposed NAM-STGCN model with the activation function being replaced by the PReLU function. It was tested on a self-built dataset with no local mutation in the early stages and started to converge after 40 iterations with a faster convergence rate. Its test accuracy is 96.72%, which is 4.92% better than the original ST-GCN model and 3.28% better than the NAM- STGCN model, and it has the properties of smooth convergence and the best model performance.
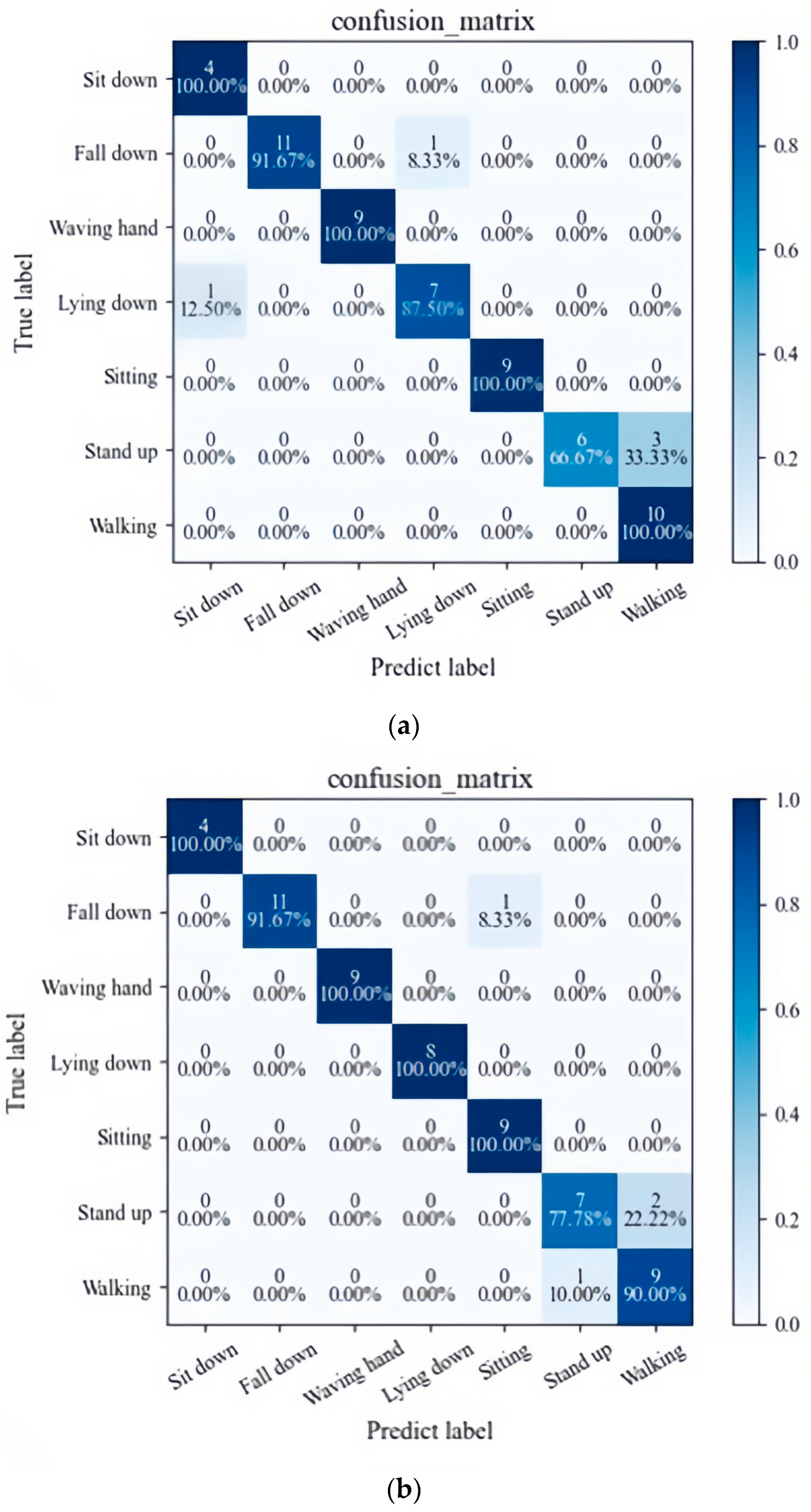
Figure 11 illustrates the validation of the modified model on the test set and shows its confusion matrices for identifying the seven classes of actions with the best accuracy. Our model clearly has the highest recognition accuracy, and only the transient behavior of standing up has a lower recognition accuracy. Considering the temporal information extraction of the ST-GCN model, the duration of each action of the self-built dataset is around 5–7 s, but for transient behavior such as standing up, where the subject can only try to get up slowly to ensure the singularity of the data label action, a video corresponds to only one label; thus, standing up contains standing action it is easy to confuse with walking action. The recognition rate of the remaining six types of behaviors all reached 100%, respectively. These results indicate that the improved model has a high recognition rate as well as good robustness.
Figure 12 shows the comparison of the loss value curves obtained from the improved before and after models that were validated on the self-built behavioral dataset. As can be seen from the figure, the original ST-GCN model starts to converge around 50 iterations, and the loss value floats around 0.6. However, the NAM-STGCN model with a fused normalized attention and our improved final model had a lower drop in the loss value. Compared with the original model, our modified model starts to converge after 45 iterations, converging faster and more smoothly after convergence, and the loss values all converge to below 0.2 with little change. This indicates that our modified model has a reduced loss value and better learning ability.
4.3. Algorithm Comparison Analysis
The study model was evaluated using the KTH public dataset and the Le2i fall detection dataset, and the model was compared with other model algorithms in the literature to better validate the effectiveness of the improved model proposed here. The hardware device and software environment used in the comparison experiment are the same as above; the batch size was 8, the initial learning rate was 10−3, and the weight decay coefficient was 10−4.
4.3.1. Testing on the KTH Public Data Set
The KTH dataset is a milestone in the field of computer vision and selects 6 types of actions performed by 25 people in 4 different scenes and shooting angles (outdoor S1, outdoor near and far scale change S2, outdoor different clothes S3, indoor S4). With the dataset including boxing, hand clapping, hand waving, jogging, running, walking, we selected boxing as abnormal behavior and the remaining five types of action as normal behavior. There are a total of 600 videos, and each frame in the video is preprocessed as a 640 × 480 pixel image; we placed 480 videos in the training set and 120 videos in the test set.
The results of the proposed model tested on the KTH dataset in this study are plotted on the confusion matrix shown in
Figure 13, with a test accuracy (top1) of 94.96%. The results show that jogging and running, two behaviors with similar movements, are more difficult to distinguish and are easily confused, resulting in a low accuracy rate of about 85%. Even so, the model still managed to reach 100% accuracy for regular actions such as hand clapping and hand waving and a 96% accuracy for walking, which is similar to running. These results indicate that our proposed improved ST-GCN model still has a high recognition rate for behaviors with significant variances.
The research approach used in this study is contrasted with the typical behavior recognition method used in recent years in order to further validate the efficacy of our proposed model, and the results are displayed in
Table 3. It is clear that the model approach in this paper improves the recognition accuracy by 11.56%, 2.42% and 0.86% compared to HigherHRnet-VGG16, VGG16-CNN and PARNet models, respectively. The literature [
19] used a CNN model based on the VGG16 backbone network, and in order to solve the problem of inefficient CNN caching of feature information per layer, the CAE module was introduced to enhance the information interactivity between different layers so that the extracted feature information is richer, reducing the feature redundancy. The average accuracy on the KTH dataset is 92.54%, and the CNN network structure is only 5 layers, while the deeper layers of our model can better extract the temporal information of continuous video sequences. The literature [
20] used a pose-appearance relational network (PARNet) to identify 14 skeletal key points of the human body and a temporal attention mechanism-based LSTM model (TA-LSTM) for action recognition to capture long-term contextual information in action videos to improve the robustness of the network. And the Spatial Appearance (SA) module was used to improve the aggregation between adjacent frames, with an accuracy of 94.10% tested on the dataset. This author divided the skeleton key points into five body parts (head, left and right arms, left and right legs) and then aggregated them to get the human posture feature information. Compared to the spatial type division strategy in this paper, it’s easy to ignore the action feature information carried by the local skeleton key points. The literature [
21] used Higher HRnet to extract skeletal key points, and the redundant background information was filtered out through the fusion of spatio-temporal information of key points to reduce the dimensionality and retain the action trajectory information, which was finally identified by Resnet101 network classification. Although our method is slightly less accurate compared to the HigherHRnet-ResNet101 method, it has a greater advantage in terms of the number of model parameters and the complexity of the network structure.
4.3.2. Testing on the Le2i Fall Detection Public Data Set
Database Description
In the proposed work, we considered the Le2i fall detection dataset [
22]. This dataset contains 191 videos in 4 different contexts, which comprised a total of 382 videos after we expanded the dataset with horizontal flipping. Among the data, there are 252 videos of falling behavior and 130 videos of normal behavior. The latter is a video of activities of daily living, containing movements such as walking, sitting, standing up, and squatting. Based on a fixed camera, the photos were taken by the actors in four different locations (coffee room as in
Figure 14, home as in
Figure 15, lecture room as in
Figure 16, and office as in
Figure 17). The actors wore a variety of clothing and attempted to simulate various kinds of normal daily activities and falls to increase the diversity of the dataset. Furthermore, this dataset presents occlusions, shadows, and variations in illumination. Eighty percent of the videos from the dataset were randomly selected as training videos, and the remaining twenty percent were used as test videos. The categories of the dataset and the number of videos for training and testing are shown in
Table 4.
Dataset Evaluation Experiment
The test evaluation was based on the top 1 accuracy, sensitivity, and specificity, which are the most commonly used performance indicators. As shown in Equations (11) and (12), the performance measures were derived using the concepts of true positive (
TP), true negative (
TN), false positive (
FP), and false negative (
FN). In this study, the videos containing falling behavior were identified as positive samples, and the videos with other normal behavioral activities were identified as negative samples.
In this paper, four different scenes in the Le2i fall detection dataset are tested sepa-rately for training, and the best trained model in each scenario has an accuracy of 100%. To better test the generalization ability of the evaluated models, the trained models in each scenario are tested separately for the validation set of the overall Le2i dataset (containing different scenes). The results of the test accuracy, sensitivity, and specificity experiments are shown in
Figure 18. The test accuracies of the model trained in coffee room, home, lec-ture room, and office scenes were 97.40%, 96.10%, 97.40%, and 94.81%, respectively, and the average accuracy of the test results for the four scenes was calculated to be 96.43%, the average sensitivity was 95.65%, and the average specificity was 97.75%, proving that our model still has high detection accuracy under different scenes, different viewpoints, and different fall poses.
The sensitivity of the test in the lecture room is 100%, and the sensitivity in the home and office scenes is lower at 93.30%. The videos in these two scenes have many overhead shots and fall on the ground with their backs to the camera, and the key points in some frames should not be extracted completely, which in turn affects the spatio-temporal graph convolutional network model for action recognition. The test specificity of the mod-el trained in the coffee room and home scenes was 100%. The specificity rates of the mod-els trained in lecture room and office scenes are 97% and 94%, respectively, which means that normal behaviors are incorrectly predicted as fall behaviors. The two scenes in the dataset contain many behaviors with high similarity to falls, such as squatting and tying shoelaces, sitting, and bending to pick up things, which may lead to misjudgment of the model, but the sensitivity of the lecture room is as high as 100%, indicating that abnormal behaviors such as falls are correctly predicted.
We conducted test experiments on the Le2i fall detection dataset after overall training, and the accuracy was 98.70%, sensitivity was 97.78%, specificity was 100%, and the average error was as low as 0.02. On the other hand, a comparison with similar works is given in
Table 5. The results of this paper’s model are compared with those of other authors who tested their proposed method on the dataset.
The literature [
23] used a lightweight human pose estimation model to extract 14 skeletal key points of the human body using only 30 consecutive frames of skeletal sequence input and a simplified ST-GCN network using only 6 layers of feature extraction modules, including the ATT (attention) module, which improved the detection speed of the model but affected the recognition accuracy. The attention mechanism added by our method is more novel and efficient than the attention module of Lightweight ST-GCN, with a 2.6% increase in test accuracy, a 5.28% increase in sensitivity, and a 4.3% increase in specificity. The literature [
24] detects human skeleton information used V2V-PoseNet and then used a dynamic time warping (DTW) algorithm to calculate the variability of action execution speed between adjacent sequences and thus classify whether they have fallen or not. The method is relatively simple, but it is easy to misjudge movements with large speed differences between adjacent frames, such as squatting and bending, which leads to a low accuracy rate. Our spatio-temporal convolutional neural network not only considers the confidence level and the spatio-temporal location coordinates for key skeleton points, but it also collects these action features effectively after nine ST-GCN convolutional layers and the NAM attention mechanism module. Despite the relatively low sensitivity, the test specificity of our method improved by 13.0% and the accuracy by 5.03%. The literature [
25] used an exposure correction technique that pre-treats all the under-illuminated videos in the Le2i dataset with dual illumination estimation (DUAL) before detecting them using YOLOv7 and then uses deep SORT tracking to determine human behavior. Although this can improve the detection accuracy, the practical applicability is poor, especially on a site with such a complex background affected by the weather. Light time is difficult to put into application. Compared to our model that directly handles continuous multi-frame video input, it still has high accuracy and sensitivity for difficult videos that are obscured by tables and chairs, as well as poor lighting, and has some applicability. Our method improves accuracy by 4.2% and specificity by 3.0% compared to YOLOv7-DeepSORT.
5. Conclusions
An improved ST-GCN model combined with the Alphapose posture estimation algorithm was proposed to intelligently monitor and identify the abnormal behavior of workers’ health and safety conditions, which is in line with the advanced concept of smart sites and helps to reduce major safety accidents. The main contributions and experimental findings of this research paper are as follows:
- (1)
Most of the existing studies on the identification of unsafe behaviors at construction sites are directed at the unsafe behaviors of workers not wearing helmets, safety undershirts, or other protective equipment; meanwhile we have paid more attention to the abnormal health behaviors of workers falling and lying down. Identifying the abnormal behaviors of workers is helpful for getting workers medical assistance in times when they are in danger and guarantees safe construction.
- (2)
The top-down, high-precision Alphapose pose estimation algorithm model is used to detect key points of the human skeleton on image sequences. Among them, we use the YOLOv5x model for human target detection, which improved the problems of human miss detection and the weak anti-interference ability of the model in complex environments. We also validated the self-built dataset, the KTH dataset, and the Le2i fall detection dataset, which all achieved high accuracy in behavior recognition.
- (3)
This paper proposes the NAM-STGCN model, which is built on the spatio-temporal graph convolutional neural network and a novel fusion of normalization-based attention modules. This combination increases the model identification accuracy and more efficiently extracts action information in the spatiotemporal dimension without adding to the computational load; it also adjusts the appropriate learning rate for the phenomenon where deep neural networks are prone to overfitting when loaded with many parameters, and it addresses the problem of high model complexity in the process of behavior classification. We also improved the NAM-STGCN model by replacing the ReLU activation function with the PReLU activation function. After optimization, our training network was tested on the self-built dataset with an accuracy of 96.72%, which is a 4.92% improvement relative to the original model and a 3.28% improvement relative to the NAM-STGCN model; the model loss value converges to below 0.2.
- (4)
To better validate the effectiveness of the model proposed in this paper, it is compared with other advanced methods proposed in the literature on the publicly available KTH dataset and Le2i dataset. The results show that our model has an accuracy of 94.96% tested on the KTH dataset, with a small number of model parameters, and still has a high recognition accuracy for walking movements with a high similarity to jogging; the test was conducted on the Le2i dataset and achieved 98.7% accuracy, 97.78% sensitivity, and 100% specificity despite the inclusion of difficult scenes such as occlusion and dim light. It shows that the improved model displays better performance in abnormal behavior recognition than other models.
Although the Alphapose pose estimation algorithm used in this paper has strong robustness to complex background environments, it is not easy to extract the complete key points of the human body after a fast fall when the human body falls with its back to the camera, and the algorithm performance of the pose estimation algorithm is considered to be further improved in the future. Some application scenarios of behavior recognition require high accuracy, in which case using multimodal data is a better choice to guarantee performance. At present, the research on behavior recognition on three modal data sets—video, depth image sequence, and skeleton sequence—is relatively independent. In the future, with the upgrade of the arithmetic power of hardware devices, it will be more feasible to consider the fusion of data from these modalities and then realize high-precision behavior recognition.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}