In this section, we present our DNN-based decoding scheme and the memory cell analysis.
3.1. The Proposed DNN-Based Decoding Scheme
A block diagram of a communication transmission system is depicted in
Figure 2. The source randomly generates a message sequence of length
K, denoted as
,
,
.
The message sequence
is multiplied by the generation matrix
to obtain the encoded vector
. We will favor
over
under the mapping
, which is called binary phase shift keying (BPSK). Then, the modulated signal
is fed into the AWGN channel for transmission. The receiver gets a superimposed signal vector
with
where
is a zero-mean Gaussian variable with a variance of
, i.e.,
. The DNN-based decoding scheme is performed to recover the message sequence
. The transmission rate is
. The symbols and codeword synchronization are assumed.
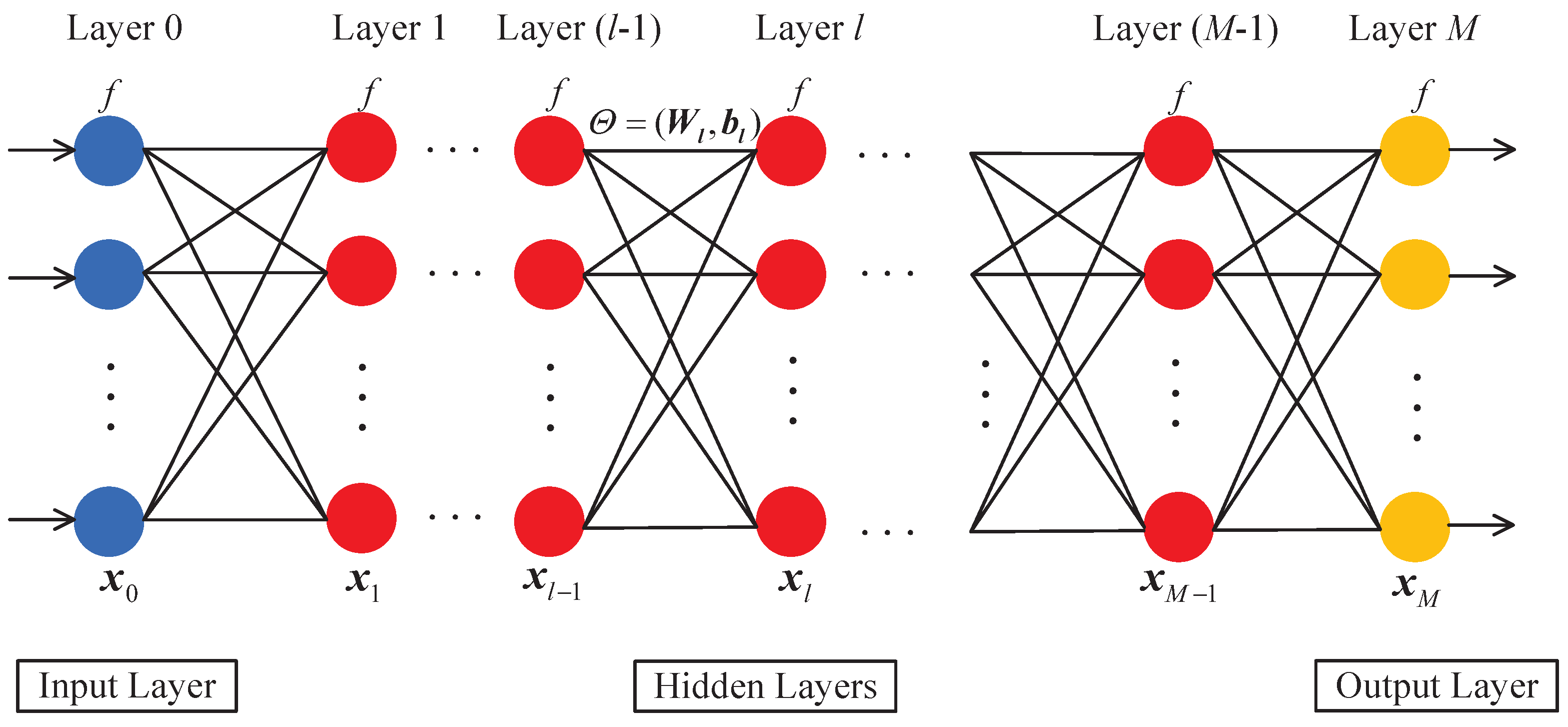
Our DNN-based decoding scheme can also be described by the graph in
Figure 3. The graph has three types of layers: the input layer in blue circles, where the input correspond to the received signal
; the hidden layer in red circles, where the input and output correspond to linear and nonlinear operations, respectively; and the output layer in red circles, where the output correspond to the recovered message sequence
. The edge from the
ith neuron in the
th layer to the
jth neuron in the
lth layer represents the weight parameter
. Moreover, the bias parameter of the
jth neuron in the
lth layer is
.
The DNN-based decoding scheme is accomplished by efficient local decoding at all the neurons and interactions. During a decoding iteration, each neuron acts once to perform local decoding and updates the message on the edges to each of its adjacent neurons. A decoding iteration starts from the local decoding at the neurons in the input layer. Based on the received signal , each neuron performs a local decoding. This local decoding employs a nonlinear operation by an activation function. Based on these activation function results, a local decoding is performed on each edge, which connects the neurons of the input layer and the first hidden layer. This local decoding employs a linear operation of the weights and biases. A similar process is performed in hidden layers and output layer. Here, the sigmoid function is employed as the activation function in the hidden and output layers. In the output layer, the loss values is calculated by the MSE. Based on these loss values, the weights and biases on each edge are updated for the next iteration using the GD algorithm. After a large number of iterations, the message sequence is recovered. It should be emphasized that the DNN-based decoding scheme provides near-optimal performance, by carrying out the local decoding iteratively, compared with hard decision.
For easy understanding, we give an example for the (7, 4) Hamming code. Based on the structure of the (7, 4) Hamming code, the numbers of neurons in the input layer and the output layer are set to 7 and 4, respectively. The signal
is equally divided into multiple groups. Each group contains seven symbols, which are denoted as
. Let
be the output of the
nth neuron in the input layer.
In general, given the outputs
on the right side of the input layer, the overall inputs
of the
jth neuron on the left side in the first hidden layer can be represented as a function of weights and biases
Obviously, this is a linear operation.
In the first hidden layer, for a given overall input
, the
jth neuron performs a nonlinear operation and, thus, its output
is
where
is the sigmoid function.
Similarly, for the outputs
of the
th
layer, a linear operation is performed to produce the overall inputs
of the
jth neuron in the
lth layer
Based on the overall inputs
of the
jth neuron in the
lth layer, a nonlinear operation is performed to get the corresponding output,
In the output layer, the same linear and nonlinear operations are performed, and thus we obtain the output of the kth neurons.
For the output
on the right side of the output layer, the loss value
E is estimated by the MSE function [
20]
where
is a length-4 sequence of a group equally divided by
, based on the (7, 4) Hamming code.
Based on this estimation and the GD algorithm [
21], the update rules of weights and biases on each edge are
where
is the learning rate. The selection of
is used to control the update rate of the weights and biases.
This process above is performed iteratively until the message sequence has been recovered. The procedure of DNN-based decoding scheme is shown in Algorithm 1.
| Algorithm 1: DNN-based Decoding Algorithm |
![Electronics 12 02973 i001]() |
3.2. Memory Cell Analysis
For each group, the code length divided by the received signal is n and the message length after decoding is k. In the DNN-based decoding scheme, it does not require a comparison with the Hamming codebook. As n changes, it only corresponds to the weights between the input layer and the first hidden layer. If the number of neurons in the first hidden layer is P, the size of the weight matrix is . As k changes, it only corresponds to the biases at the output layer. The size of the bias matrix is . No extra memory cells are created during the decoding iteration due to the changes in n or k. Thus, the total memory cells of the DNN-based decoding scheme are .
On the other hand, in the hard decision, the received codeword is required to be compared with the codebook and the codeword that gives the minimum Hamming distance is selected. To compare the minimum Hamming distance, the size of the Hamming distance matrix is
. The codebook has
rows with
n lines per row. Therefore, the total memory cells of hard decision are
, as shown in
Table 3.
Note that, as the message length k of linear codes increases, the exponentiation in hard decision becomes particularly large, which will require especially large memory cells. Therefore, as k increases, the number of memory cells in our proposed scheme is much lower than that of hard decision.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}