Abstract
Steel surface defects have a significant impact on the quality and performance of many industrial products and cause huge economic losses. Therefore, it is meaningful to detect steel surface defects in real time. To improve the detection performance of steel surface defects with variable scales and complex backgrounds, in this paper, a novel method for detecting steel surface defects through a multiscale local and global feature fusion mechanism is proposed. The proposed method uses a convolution operation with a downsampling mechanism in the convolutional neural network model to obtain rough multiscale feature maps. Then, a context-extraction block (CEB) is proposed to adopt self-attention learning on the feature maps extracted by the convolution operation at each scale to obtain multiscale global context information to make up for the shortcomings of convolutional neural networks (CNNs), thus forming a novel multiscale self-attention mechanism. Afterwards, using the feature pyramid structure, multiscale feature maps are fused to improve multiscale object detection. Finally, the channel and spatial attention module and the WIOU (Wise Intersection over Union) loss function are introduced. The model achieved 78.2% and 71.9% mAP respectively on the NEU-DET and GC10-DET dataset. Compared to algorithms such as Faster RCNN and EDDN, this method is effective in improving the detection performance of steel surface defects.
1. Introduction
As a common and important material for industrial production, steel has been used extensively in construction, infrastructure, automobiles, transportation, machinery, and industrial equipment for decades. In modern industrial production, influenced by factors such as manufacturing technology and production environment, different types of defects will occur on the surface of steel, e.g., inclusions, patches, scratches, etc. Defect size, texture, and light source all have a certain influence on the detection [1]. The quality assurance of steel products is important to the use experience, appearance, working performance, and safety guarantee of industrial products. Therefore, improving the detection ability on the steel surface has great significance in industrial applications and theoretical significance for the production of steel products.
Traditional defect detection uses manual identification as the main method, which is time-consuming and unstable in accuracy. In contrast, non-destructive testings are designed to monitor components without extracting or permanently damaging samples for detection [2]. Techniques such as magnetic flux leakage, acoustic emission testing, and ultrasonic testing obtained better interactivity and sensitivity [3]. However, most of the methods are time-consuming and lack intuitive descriptions of the defects’ shapes. After the development of software and hardware equipment, machine vision shows stronger performance, so that more and more studies focus on machine-vision technology.
Convolutional neural networks are one of the usual methods in machine vision for defect detection. Many models use CNNs as the backbone network to extract local features of the input images and generate feature maps and then fuse the feature maps to generate prediction maps. For example, He et al. [4] designed a multilevel feature-fusion network that combines multiple hierarchical features from CNNs so as to have more location details. In [5], the SSD network was improved for the location of fastener defects in contact-wire support devices. For surface defect maps that are difficult to detect due to multiple factors, these CNN-based methods exhibit excellent detection performance. However, CNN-based methods are limited by the receptive field due to the size of the convolution kernel, and feature extraction is often limited to the short-distance pixel area, while ignoring the relevance between long-distance pixels causes poor prediction performance when some complex scenes are detected. Therefore, the method that can obtain global dependencies provides a new idea for improving defect-detection performance.
The self-attention mechanism [6] obtains the global context from the extracted object by obtaining the relationship between the internal elements of the input content and has been widely used in machine vision, including semantic segmentation and object detection. In computer vision, the main idea of the self-attention mechanism is to divide the image into blocks of the same size, encode these image blocks as the basic unit, and learn features through the self-attention mechanism after encoding. However, since this method usually directly divides the image block of the original image and uses segmented image blocks as the basic unit to perform feature extraction [7], the spatial detail information contained in each image block is not fully learned, so the ability to locate defective objects will be limited.
There is an intuitive and effective way to solve the above problems: by scaling the image or using a convolution operation with a downsampling mechanism in the CNN model to extract feature maps of different sizes. Self-attention learning is performed on the local feature maps extracted by convolution at each scale. Based on the above intuition, in this paper, a steel-surface defect-detection model with a multiscale local and global feature-fusion mechanism is proposed. In the backbone network structure, convolution operations with downsampling mechanisms are adopted to obtain local feature maps, which have different sizes to focus on multiscale defect objects. In the neck-network structure, a multiscale self-attention module is used for each size of local feature map extracted by convolution. By dividing different image blocks on multisize feature maps, richer global-context information is obtained to enhance the detection robustness to complex backgrounds. Next, the feature pyramid-structure network is adopted to fuse semantic features from high dimensions to low dimensions to improve the ability to distinguish defect features on different scales. Then, the bottom-up feature pyramid-structure network is adopted to transform the location information from low-dimensional to high-dimensional to improve the ability to locate the object. In the last part of the neck structure, the CBAM (convolutional block attention module) [8] is adopted to further enhance the ability to process complex texture information on the steel surface. This method considers local detail information and the global context and performs detailed and sufficient feature fusion, which bring improvement to the performance of the detection model.
In summary, the main contributions of this paper are as follows.
- The self-attention mechanism is performed on CNN-extracted local feature maps to maintain local details while obtaining global context information.
- A novel multiscale self-attention mechanism is applied to local feature maps. Patch embedding with same image-block division manner is performed on local-feature maps which have different sizes, so different division forms are obtained on the feature maps; thus, the model gains richer global context information during the self-attention learning.
- The CBAM is introduced to improve the detection ability with a complex background texture. The WIOU loss function [9] is introduced to reduce the negative effects of low-quality samples and geometry factors, such as aspect ratios.
2. Related Works
During the development of steel-surface detection, researchers have proposed many methods in related works. This paper discusses the development progress of steel-surface detection, and on this basis, extends to the related discussion of the latest transformer technology.
2.1. Steel Surface Detection
The development of steel-surface detection has gone through three main phases, including manual detection, traditional photoelectric detection, and machine-vision detection. Early manual detection used an artificial method of observation through the eyes, which had disadvantages such as low efficiency and no unified standards. With the development of sensors and optical devices, technologies such as eddy-current testing [10], magnetic flux-leakage testing [11], infrared testing [12], and laser-scanning inspection [13] have been applied, but there are many technical drawbacks. Nowadays, the 3D laser Doppler scanning vibrometry system is one of the most versatile and efficient detection techniques. When using the laser Doppler vibrometer, one only needs a matter of milliseconds to take measurement of one product [14]. In addition, some authors use low-cost solutions to evaluate materials. Scislo [15] used a mobile device to obtain data to calculate the mechanical properties of the samples by adopting the Fourier transform and frequency response. During the development of computer technology, detection methods using machine learning accelerated the progress of detection performance. Caleb et al. [16] proposed a classification model for hot-rolled steel-surface detection based on adaptive learning, which was obtained with 84% accuracy. Ghorai et al. [17] designed a method using the support vector machine (SVM) and a set of wavelet features for the classification of hot-rolled flat steel products. Natarajan et al. [18] designed a method using SVM and transfer learning to overcome the overfitting problem with small datasets. Qu et al. [19] adopted a Gabor filter-optimization algorithm based on composite differential evolution for steel-strip surface detection to reduce algorithm complexity and improve performance. He et al. [20] designed an algorithm based on background subtraction and built a background model to deal with the problems in rail-surface images, such as limited features, reflection inequality, and illumination variation, which achieved a recall rate of 96% and an accuracy rate of 80.1% on defects of steel used in high-speed rails. However, the use of detection methods based on machine learning makes it more and more difficult to meet the higher detection speed and accuracy requirements with the rapid development of industry. These methods require manual segmentation and feature extraction of images, which is difficult, time-consuming, laborious, and cannot handle well a great deal of data generated in real-time detection. Also, when the scene or defects change, the algorithm needs to be changed. Therefore, detection methods that are more suitable for the needs of modern industry have gradually become a new focus.
With the rapid development of deep-learning technology and the improvements in the processing speed of computer hardware, CNN-based methods have achieved excellent performance. For example, Masci et al. [21] designed a max-pooling CNN method to detect the steel surface that achieves better accuracy than the SVM classifier and can directly detect the original image. He et al. [22] designed a classification multigroup CNN, which achieved an accuracy rate of more than 94% and a classification rate of more than 96% in hot-rolled steel detection. Some methods are based on classic CNN models like YOLO and Faster R-CNN. Li et al. [23] designed a method based on YOLOv3, which improved the performance of hot steel defects. Zhu et al. [24] combined the generative adversarial network with Faster R-CNN to detect defects on the auto rim surface. Deep learning has made a major technological breakthrough in the detection of defective objects and has recently become a research hotspot. However, existing CNN-based methods still have some limitations. For example, factors such as background disturbance and object size changes in steel-surface images cannot be handled well, and there are certain detection-performance bottlenecks. How to combine newer technologies to better deal with some existing problems in steel surface images and to further improve performance are the main research directions at present.
2.2. Transformer-Based Methods
Transformer [6], a neural network architecture for NLP (Natural Language Processing) tasks proposed in recent years, has obtained remarkable results. Inspired by the function of Transformer, some research work introduces Transformer into the field of computer vision tasks, providing a new direction of development. Chen et al. [25] predict pixels in an autoregression manner with a sequential Transformer, achieving image classification performance that can compete with CNN. Dosovitskiy et al. [7] proposed the ViT (Vision Transformer) model, which adopted a pure Transformer. By dividing the image into multiple image blocks and encoding them to form a sequence vector, the input method of the Transformer in the image field was formed, and it achieved top performance in image recognition. Carion et al. [26] proposed DETR to introduce Transformer into high-level vision tasks by treating object detection as a straightforward ensemble prediction problem. Liu et al. [27] proposed the Swin-Transformer, which uses the shift window of the spatial dimension to model global and boundary features and enhances the ability to extract local features. In addition, some studies have begun to consider combining CNN with Transformer. Srinivas et al. [28] proposed BoTNet, which improved performance by replacing some convolution operations with self-attention mechanisms in the CNN architecture. On the other hand, Touvron et al. [29] introduced the teacher–student distillation method into the training of ViT, using CNN instead of Transformer as the teacher network for distillation, which could achieve better results. Today, combining CNN with Transformer has been adopted in fields including image segmentation, object detection, and image classification and has obtained remarkable results. Inspired by this, in this paper, a new steel-surface detection architecture based on the characteristics of CNN and Transformer is proposed to further explore the defect-detection potential by combining CNN with Transformer.
3. Methodology
In the backbone network, the proposed model uses CNN to perform convolution operations with a downsampling mechanism on image features multiple times to form multiscale local feature information. In the neck network, at first, the CEB (Context Extraction Block) module is adopted on the local feature maps extracted by convolution at each scale to extract the global context information and enhance the robustness with complex backgrounds. The structure of CEB is shown in the upper part of Figure 1. Then, the extracted features are input into the feature pyramid-structure fusion module to enhance the semantic and location information. Finally, the CBAM is adopted to continue to enhance the ability to resist interference and find defective targets in complex backgrounds. The overall framework of the model is shown in Figure 1.
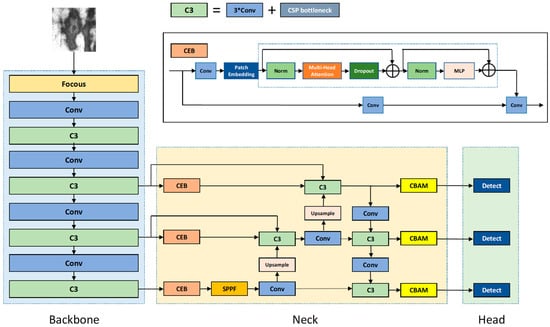
Figure 1.
Model overall framework diagram. The C3 module consists of 3 convolutional layers and BottleneckCSPs; CEB module is a residual structure composed of standard convolutional layers and a Transformer block.
Traditional steel-surface defect-detection algorithms based on convolution operations mainly extract local feature information, ignoring the importance of global information in detecting defects. Compared to the method of multilayer convolution stacking, the self-attention mechanism realizes the acquisition of global information between long-distance pixels with only one structure. However, the self-attention mechanism has a single-scale problem in feature extraction. Due to the limitation of the mechanism, it is impossible to fully learn the spatial detail information contained in each image block, especially for steel-surface defects with multiple scales. It is difficult to obtain the ideal detection effect using only the Transformer. Therefore, in this paper, a method based on CNNs with a multiscale self-attention mechanism is proposed. For one thing, the local feature maps generated by the convolution operation extract spatial detail information, and the self-attention learning based on local feature maps makes up for the lack of detailed features in the image block due to the division manner to obtain more detailed detection results. For another, due to the singleness of image-block division, different image-block divisions are obtained by changing the size of the feature map input to the self-attention module to obtain richer global context information through self-attention learning.
3.1. Backbone Network
To form multiscale self-attention feature extraction and obtain fine local detail information, this paper extracts local feature information through CNN in the backbone network, realizes downsampling through a convolution operation with downsampling mechanism, and generates the multiscale feature map with rich detail information.
To balance the amount of calculation and memory consumption caused by the self-attention mechanism in the model, this paper uses CSPDarknet as the backbone network because it is relatively lightweight. The C3 module consists of 3 convolutional layers and BottleneckCSPs. The setting of the size of the convolution kernel and stride in the C3 module can perform the downsampling mechanism in feature extraction at different stages to generate feature maps with various scales. The layer structure of the backbone network is shown in Table 1.

Table 1.
The layer structure of the backbone network.
3.2. Neck Network
The self-attention mechanism can obtain global information and rich context information to have a better detection effect for some objects with a high aspect ratio and wide distribution. Therefore, this paper introduces the CEB module in a feature-fusion network to extract global context information on different size features through self-attention learning. The CEB module adopts a residual structure and consists of two branches: one consisting of a convolutional layer and a Transformer block, and the other branch using a convolution module for internal skip connection, which alleviates gradient disappearance. There are two sublayers inside the Transformer block: the first is a multiheaded attention layer, and the second is a multilayer perceptron layer, and each sublayer uses a residual connection inside. The mathematical expression of the self-attention mechanism is as follows:
where , , and are tensors () representing the query, key and value, respectively and are the dimensions of and .
Feature maps obtained from Stages 3, 4, and 5 in the backbone network are input to the corresponding CEB modules in the neck network, and then self-attention learning is performed on the basis of local feature maps containing detailed information generated by convolution operations. Then, in each layer, the image blocks are redivided based on the patch-embedding module in a manner similar to convolution, thus obtaining the feature vectors corresponding to the feature maps of each scale and reshaping them into the original dimensions. In this process, due to the different sizes of the input images, the image blocks divided each time show a change from dense to sparse. Therefore, self-attention learning is performed on multiple scales to obtain richer global context information due to the different division forms.
Related research [30] shows that when convolutional features pass through the layer of the self-attention mechanism, some features will be weakened, which is important for feature learning. To enhance the reusability of the original convolutional features, this paper concatenates the feature maps obtained in Stages 3 and 4 of the backbone network with the output of the corresponding CEB module as subsequent input. In this way, the convolutional features and the context features are fused so that the model retains the original feature details while extracting the context information, which can reduce the detection-performance degradation of certain categories of defects caused by self-attention extraction.
Then, high-dimensional semantic information and low-dimensional locational information are fully transmitted through the feature pyramid structure so that the local detail features are fully fused with the global context relevance.
In the end, the CBAM infers the input features in the dimensions of the channel and space to generate an attention map and multiplies the attention map with the input features, and the output is the result of adaptive feature refinement. Through CBAM, the model has a better ability to resist the interference of complex background information, which is helpful for accurately detecting defective objects. The structure of CBAM is shown in Figure 2.

Figure 2.
CBAM structure diagram.
3.3. Loss Function
This paper introduced the WIOU loss as the loss function. There are some low-quality samples in various steel-surface-defect datasets, and geometrical factors such as aspect ratio and distance in the image will amplify the negative impact of these low-quality samples. Compared to traditional IOU, WIOU loss focuses on the area between the ground truth box and the prediction box, which could reduce the possible deviation in the evaluation and better adapt to the influence of geometrical factors and various sizes of objects. The calculation of WIOU loss is as follows:
where and represent the width and height of the minimum bounding box. The aspect ratio factor of the enclosing box may hinder the convergence effect during the propagation of the neural network. To prevent the calculated gradient from hindering the convergence effect, and are separated from the computational graph ( indicates the separation operation).
4. Experiments and Results Analysis
4.1. Datasets
We used steel-surface-defect datasets, including the NEU-DET dataset [4] and the GC10-DET dataset [31] for experiments. NEU-DET is a steel-surface-defect dataset released by Northeastern University (NEU), consisting of 1800 grey images with a size of 200 × 200, as shown in Figure 3.

Figure 3.
Steel-surface defects in the NEU-DET dataset: (a) crazing, (b) inclusion, (c) patches, (d) pitted surface, (e) rolled-in scale, and (f) scratches. Defects are marked in orange boxes.
GC10-DET is an industrial metal surface-defect dataset collected from a real industry that consists of 3570 grey images with a size of 2048 × 1000, as shown in Figure 4.

Figure 4.
Steel-sheet surface defects in the GC10-DET dataset: (a) punching (Pu), (b) weld line (Wl), (c) crescent gap (Cg), (d) water spot (Ws), (e) oil spot (Os), (f) silk spot (Ss), (g) inclusion (In), (h) rolled pit (Rp), (i) crease (Cr), and (j) waist folding (Wf). Defects are marked in orange boxes.
4.2. Evaluation Metrics
Mean average precision (mAP) is an essential evaluation metric in object detection that is obtained from the precision rate P and the recall rate R, where the precision rate P represents the number of correctly predicted positive samples, divided by the predicted positive samples. The recall rate R represents the number of correctly predicted positive samples divided by the actual positive samples. The calculation formula is as follows:
where the value refers to the area of the P-R curve, represents the number of categories, and , , and represent the number of correct detection boxes, the number of incorrect detection boxes, and the number of missed detection boxes, respectively.
4.3. Implementation Details
The experiment was conducted with a PyTorch deep learning framework, an Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20 GHz processor, a 4 NVIDIA GeForce TITAN Xp GPU, and an Ubuntu operating system. We adopted data-augmentation strategies such as mosaic, brightness change, hue change, saturation change, affine transformation, and horizontal flip. In the experiment, the NEU-DET was adjusted to a size of 224 × 224, the GC10-DET was adjusted to a size of 512 × 512, and both were randomly divided into training set, validation set, and test set at a ratio of 7:1:2. We used SGD as the optimizer, and the initial learning rate, weight decay, and momentum were set to 10−2, 5 × 10−4 and 0.937, respectively. The warm-up method was used to initialize the learning rate, and the model was trained for 300 epochs.
4.4. Experimental Results
With the purpose of proving the superiority of the proposed method, we conducted comparisons of the detection result with other detection results, which were from some previous object detectors [32,33,34,35,36,37] and defect detectors [31,38,39,40,41,42,43].
The comparison results on the NEU-DET dataset are shown in Table 2 and Table 3, and the visualization results are shown in Figure 5.
Table 2.
Comparison results with object-detection algorithms on the NEU-DET dataset (Unet was converted from segmentation model to detection model).
Table 3.
Comparison results with defect-detection algorithms on the NEU-DET dataset.

Figure 5.
Visualized detection results on the NEU-DET dataset.
As shown in Table 2, in comparison with other object-detection methods with feature-pyramid structure, the proposed method achieved significant advantages in most defect categories. For defects with various scales, high aspect ratios, and wide distribution (these characteristics require global context-based detection rather than local feature-based detection), such as inclusions, patches and scratches, the method laid out in this paper achieved the highest AP of 90.3%, 94.4%, and 96.1%, respectively, and the two types of inclusions and scratches improved significantly. The results show that the feature-extraction method based on the local area has certain limitations in detecting categories with the above characteristics. The self-attention mechanism obtains the context information between local areas by focusing on the relevance between long-distance pixels and thus can improve the performance on these categories. In addition, because the proposed method relearns self-attention at different scales to obtain global context information and fuses them in the end, the information is further enriched. In the case of categories with more detailed feature information like crazing, pitted surface, and rolled-in scale, although some other algorithms achieve the best results, the proposed method in this paper still achieves competitive results. The reasons are as follows. First, a layer containing a self-attention mechanism will cause part of the input to lose features that contain detailed information, and sometimes these features are also important in the feature learning of the model, which may cause performance loss on certain categories. However, compared to the previous method with a self-attention mechanism, the proposed method extracts local detail information through the convolution operation to generate feature maps at first and then performs self-attention learning on the feature maps (instead of the original image). Second, the output of the self-attention module concatenates with the input, thus reducing the loss of detail information. Third, the self-attention mechanism and CBAM both enhance the robustness for complex backgrounds.
As shown in Table 3, in comparison with other defect-detection methods, the proposed method obtains the highest AP in inclusions, patches, and scratches. The results further verify the improvement brought by the multiscale self-attention structure.
In the two comparative experiments based on the NEU-DET dataset, the proposed method achieved the highest mAP of 78.2%.
The comparison results of the GC10-DET dataset are shown in Table 4 and Table 5, and the visualization results are shown in Figure 6.
Table 4.
Comparison results with object-detection algorithms on the GC10-DET dataset (Unet is converted from the segmentation model to the detection model).
Table 5.
Comparison results with defect-detection algorithms on the GC10-DET dataset.
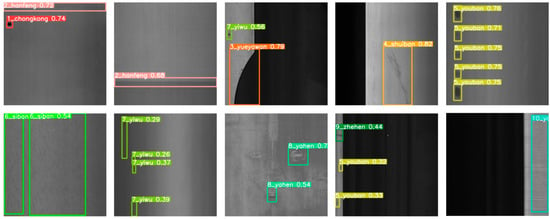
Figure 6.
Visualized detection results on the GC10-DET dataset.
As shown in Table 4, in comparison with other object-detection methods with feature pyramid structure, the proposed method performs better in most defect categories. For defects with high aspect ratios and wide distribution, such as weld line (Wl), crescent gap (Cg), rolled pit (Rp), and crease (Cr), the proposed method achieves the highest AP of 88.9%, 96.2%, 43.7%, and 75.8%, respectively. For the water spot (Ws) and inclusion (In) with more detailed feature information, the proposed method obtains the highest AP of 79.1% and 33.2%, respectively. It is further verified that self-attention learning based on local feature maps extracted by the convolution operation can improve the ability to extract local details.
As shown in Table 5, in comparison with other defect-detection methods, the proposed method obtains the highest AP in punching (Pu), crescent gap (Cg), water spot (Ws), oil spot (Os), and inclusion (In). Although EDDN and Kou’s method also achieve the highest AP in some categories, the proposed method has only a small gap in the categories of weld line (Wl), rolled pit (Rp), crease (Wf) (88.9% vs. 95.0%, 43.7% vs. 43.9%, 83.6% vs. 91.9%), and the proposed method finally achieves the highest mAP.
In the two comparative experiments based on the GC10-DET dataset, the proposed method also achieves the highest mAP of 71.9%, further proving the effectiveness and generalization ability of the proposed method for the detection of steel-surface defects.
4.5. Ablation Study
In this study, ablation experiments were set up to verify the effectiveness of the proposed methods, i.e., the CEB module, the CBAM module, and the WIOU loss function. These experiments all used the NEU-DET dataset, and the initial loss function was set to CIOU.
As shown in Table 6, the model with the CEB module outperformed the model with no proposed key components, and the mAP was improved by 1.9%, especially for two categories (inclusion, rolled-in scale). It shows that the self-attention mechanism has high robustness for images with high aspect ratios, anti-background disturbances, and improvement in accuracy. Compared to the model with the CEB module, the model with the CEB and CBAM module achieved better overall performance with a 1.3% improvement, especially for categories with complex backgrounds (crazing, rolled-in scale). Finally, by replacing CIOU with WIOU as loss function, the performance improved by 1.4%. It shows that the WIOU loss function reduces the negative impact of low-quality samples in the dataset, the effect of geometric factors (such as aspect ratio), and various sizes of objects.
Table 6.
Results of the ablation experiment on the NEU-DET dataset.
5. Conclusions
In this paper, we designed a model for steel surface detection that comprehensively uses some deep learning methods, such as CNN, a self-attention mechanism, multiscale feature fusion, etc., and furthermore uses global context information and local detail information to obtain multiscale features. For the various scales of steel-surface defects, a novel module was designed to fuse multiscale local and global context information. By performing self-attention learning on the rough feature maps extracted by convolution at different scales, the local detail features are preserved. For the complex background, this paper proposes the CEB module to learn the relevance between long-distance pixels and adds CBAM to improve the robustness for complex textures. In addition, the WIOU loss function reduces the negative impact of factors such as low-quality samples and geometric factors. The proposed method has advantages in defect categories with various scales, high aspect ratios, and a wide distribution. On the NEU-DET dataset, the model obtained 78.2% mAP, 8.0% higher than EDDN. On the GC10-DET dataset, the model obtained 71.9% mAP, 10.4% higher than EDDN. Therefore, the proposed model has a good detection performance and good practical value. We plan to continue to improve the model in the future and apply it to other defect datasets to enhance its generalization ability and compress the model for monitoring real-time industrial scenarios.
Author Contributions
L.Z.: methodology, original draft, writing; Z.F.: formal analysis, resources, writing; H.G.: review and editing, visualization; Y.S.: review and editing, supervision.; X.L.: data curation; M.X.: conceptualization, investigation. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Natural Science Foundation of Henan Province (222300420274, 222300420275), the Key Scientific Research Projects of Henan Province (22A520008, 22A220002), the Postgraduate Scientific Research Innovation Fund Project (2022KYJJ069), and the Nanhu Scholars Program for Young Scholars of XYNU.
Data Availability Statement
The datasets used during the current study are available from the corresponding author upon reasonable request. The NEU-DET dataset can be downloaded from http://faculty.neu.edu.cn/songkechen/zh_CN/zdylm/263270/list/index.htm, accessed on 2 May 2023; the GC10-DET dataset can be downloaded from https://github.com/lvxiaoming2019/GC10-DET-Metallic-Surface-Defect-Datasets, accessed on 28 April 2023.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Xiong, Z.; Li, Q.; Mao, Q.; Zou, Q. A 3D laser profiling system for rail surface defect detection. Sensors 2017, 17, 1791. [Google Scholar] [CrossRef]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P. Visual-based defect detection and classification approaches for industrial applications—A survey. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef] [PubMed]
- Luo, Q.; Sun, Y.; Li, P.; Simpson, O.; Tian, L.; He, Y. Generalized completed local binary patterns for time-efficient steel surface defect classification. IEEE Trans. Instrum. Meas. 2019, 68, 667–679. [Google Scholar] [CrossRef]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans. Instrum. Meas. 2020, 69, 1493–1504. [Google Scholar] [CrossRef]
- Chen, J.; Liu, Z.; Wang, H.; Núñez, A.; Han, Z. Automatic defect detection of fasteners on the catenary support device using deep convolutional neural network. IEEE Trans. Instrum. Meas. 2018, 67, 257–269. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An image is worth 16×16 Words: Transformers for image recognition at scale. arXiv 2020. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023. [Google Scholar] [CrossRef]
- Hansen, J.; Gardrner, K. What is eddy current testing? Quality 2016, 55, 41–44. [Google Scholar]
- Chen, Y.W.; Xin, Y.H. An efficient infrared small target detection method based on visual contrast mechanism. IEEE Geosci. Remote Sens. Lett. 2016, 13, 962–966. [Google Scholar] [CrossRef]
- Eisenmann, D.J.; Enyart, D.; Lo, C.; Brasche, L. Review of progress in magnetic particle inspection. AIP Conf. Proc. 2015, 1581, 1505–1510. [Google Scholar]
- Chesnokova, A.A.; Kalayeva, S.Z.; Ivanova, V.A. Development of a flaw detection material for the magnetic particle method. J. Phys. Conf. Ser. 2017, 881, 012022. [Google Scholar] [CrossRef]
- Scislo, L. Single-point and surface quality assessment algorithm in continuous production with the use of 3d laser doppler scanning vibrometry system. Sensors 2023, 23, 1263. [Google Scholar] [CrossRef] [PubMed]
- Scislo, L. Verification of mechanical properties identification based on impulse excitation technique and mobile device measurements. Sensors 2023, 23, 5639. [Google Scholar] [CrossRef]
- Caleb, P.; Steuer, M. Classification of surface defects on hot rolled steel using adaptive learning methods. In Proceedings of the Fourth International Conference on Knowledge-Based Intelligent Engineering Systems and Allied Technologies, Brighton, UK, 30 August–1 September 2000; pp. 103–108. [Google Scholar]
- Ghorai, S.; Mukherjee, A.; Gangadaran, M.; Dutta, P.K. Automatic defect detection on hot-rolled flat steel products. IEEE Trans. Instrum. Meas. 2013, 62, 612–621. [Google Scholar] [CrossRef]
- Natarajan, V.; Hung, T.Y.; Vaikundam, S.; Chia, L.T. Convolutional networks for voting-based anomaly classification in metal surface inspection. In Proceedings of the IEEE International Conference on Information Technology, Piscataway, NJ, USA, 19–20 May 2017; pp. 986–991. [Google Scholar]
- Qu, E.Q.; Cui, Y.J.; Xu, S.; Sun, H.X. Saliency defect detection in strip steel by improved Gabor filter. J. Huazhong Univ. Sci. Technol. 2017, 45, 12–17. [Google Scholar]
- He, Z.; Wang, Y.; Liu, J.; Yin, F. Background differencing based high-speed rail surface defect image segmentation. Chin. J. Sci. Instrum. 2016, 37, 640–649. [Google Scholar]
- Masci, J.; Meier, U.; Ciresan, D.; Schmidhuber, J.; Fricout, G. Steel defect classification with max-pooling convolutional neural networks. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012; Volume 20, pp. 1–6. [Google Scholar]
- He, D.; Xu, K.; Zhou, P. Defect detection of hot rolled steels with a new object detection framework called classification priority network. Comput. Ind. Eng. 2019, 128, 290–297. [Google Scholar] [CrossRef]
- Li, W.G.; Ye, X.; Zhao, Y.T.; Wang, W.B. Strip steel surface defect detection based on improved YOLOV3 algorithm. Acta Electronica Sinica 2020, 48, 1284–1292. [Google Scholar]
- Zhu, C.P.; Yang, Y.B. Online detection algorithm of automobile wheel surface defects based on improved Faster-RCNN model. Surf. Technol. 2020, 49, 359–365. [Google Scholar]
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative pretraining from pixels. In Proceedings of the 37th International Conference on Machine Learning, New York, NY, USA, 13–18 July 2020; pp. 1691–1703. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End object detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Guo, B. Swin Transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16519–16529. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Aksoy, T.; Halici, U. Analysis of visual reasoning on one-stage object detection. arXiv 2022. [Google Scholar] [CrossRef]
- Lv, X.; Duan, F.; Jiang, J.J.; Fu, X.; Gan, L. Deep metallic surface defect detection: The new benchmark and detection network. Sensors 2020, 20, 1562. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 2999–3007. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6053–6062. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 821–830. [Google Scholar]
- Kou, X.; Liu, S.; Cheng, K.; Qian, Y. Development of a YOLO-V3-based model for detecting defects on steel strip surface. Measurement 2021, 182, 109454. [Google Scholar] [CrossRef]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. MSFT-YOLO: Improved YOLOv5 based on transformer for detecting defects of steel surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.; Chen, F.; Huang, H.; Li, D.; Cheng, W. A new steel defect detection algorithm based on deep learning. Comput. Intell. Neurosci. 2021, 2021, 5592878. [Google Scholar] [CrossRef]
- Yu, J.; Cheng, X.; Li, Q. Surface defect detection of steel strips based on anchor-free network with channel attention and bidirectional feature fusion. IEEE Trans. Instrum. Meas. 2022, 71, 5000710. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, H.; Jia, X.; Bao, Y.; Wang, C. Surface defect detection with modified real-time detector YOLOv3. Sensors 2022, 2022, 8668149. [Google Scholar] [CrossRef]
- Tian, R.; Jia, M. DCC-CenterNet: A rapid detection method for steel surface defects. Measurement 2022, 187, 110211. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).