
A Short-Text Similarity Model Combining Semantic and Syntactic Information

Abstract
:1. Introduction
2. Related Work
2.1. Semantic Similarity
2.2. Syntactic Similarity
3. Methodology
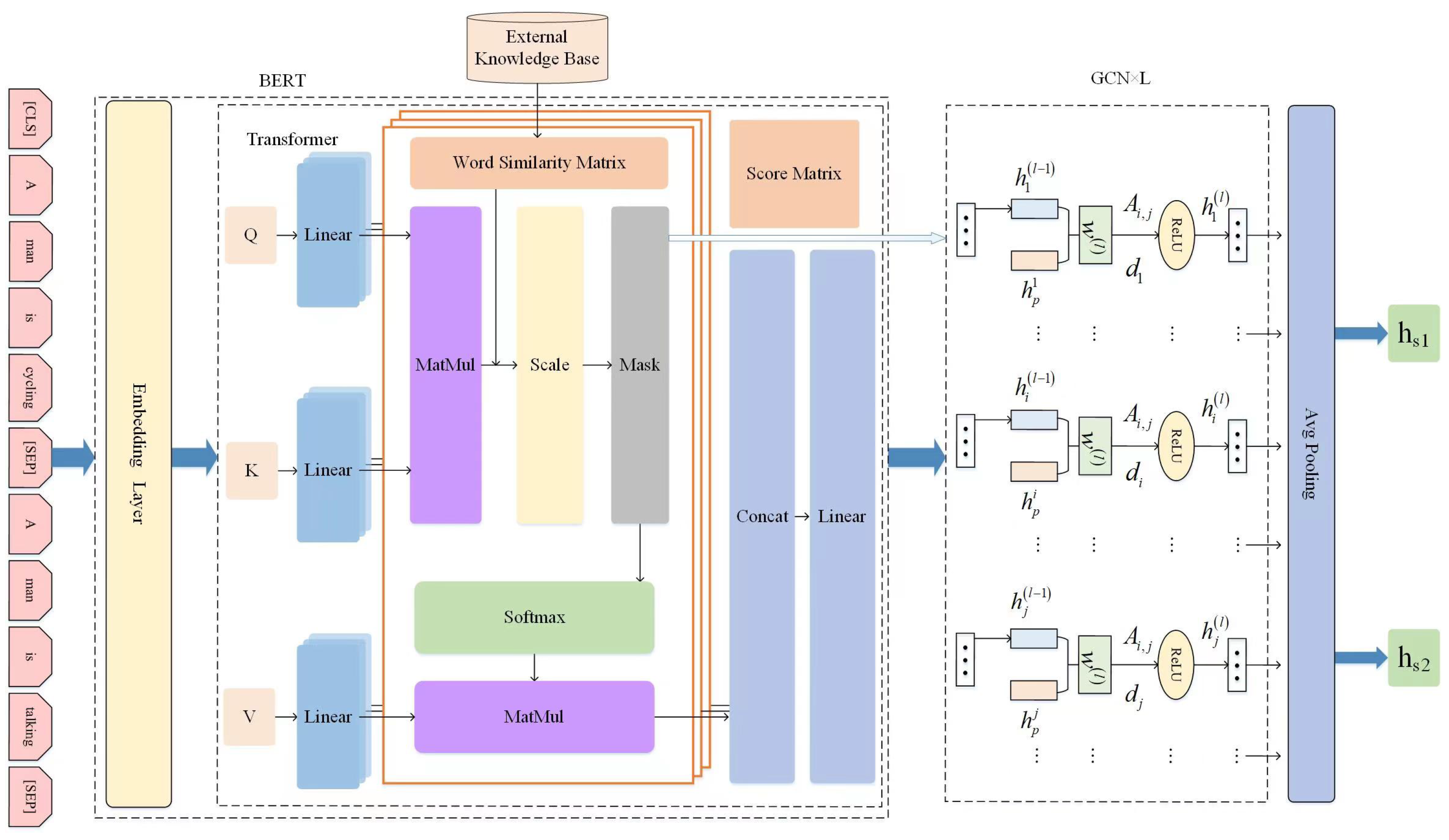
3.1. Semantic Similarity Model Framework
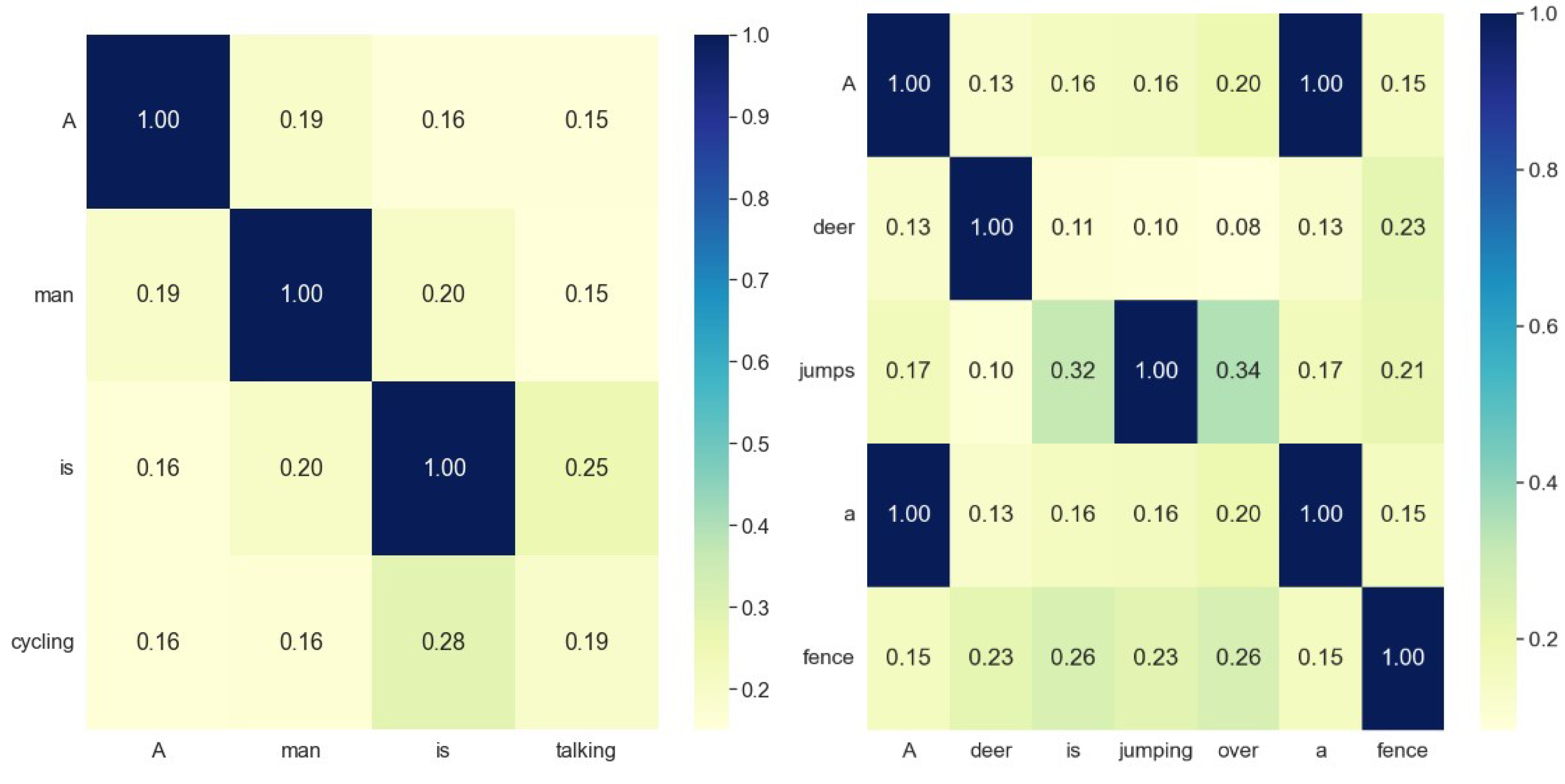
3.1.1. Construction of the Word Similarity Matrix
3.1.2. External Knowledge Integration into BERT for Multi-Headed Attention
3.1.3. Scores Matrix Integration into the GCN
- The dataset is preprocessed and the word similarity matrix S of sentences and is constructed according to Section 3.1.1;
- In the BERT embedding stage, a (CLS) token is added to the first part of the first sentence , and an (SEP) token is added to the middle of the two sentences and the end of the last sentence. The sum of the three parts. In the Transformer stage, external knowledge is incorporated into the BERT multi-headed attention, and the Hadamard product is calculated using and S to obtain the score matrix scores;
- The score matrix is incorporated into the GCN, using the score matrix scores to act as the adjacency matrix in the standard GCN model. Based on the score matrix, the token embeddings of sentences and obtained by BERT are used as input to the two-layer GCN, and the vector representation of each token is obtained after the two-layer GCN, and then the vectors of the two sentences are obtained separately by averaging pooling. Then, it is conventional to pick up a fully connected layer to get Logits, then a Softmax layer to obtain probabilities, after which the loss is calculated based on the true labels.
3.1.4. Setting of Loss Function
3.2. Syntactic Similarity Model Framework
3.2.1. Constructing the Constituency Parse Trees of the Short Text
3.2.2. Similarity between CPTs Is Calculated Using the Tree Kernel Method
3.3. Short Textual Similarity Model Framework
4. Experiments
4.1. Dataset and Experimental Setup
4.1.1. Dataset
- MRPC (the dataset can be downloaded from https://www.microsoft.com/en-us/download/details.aspx?id=52398 accessed on 11 November 2022) [48]: Microsoft Research’s standard dataset for paraphrase recognition, which is extracted from news sources on the web and also carries a corpus of human-annotated sentence pairs, where each text pair is manually binary determined to be similar or not, explains whether the two sentences are paraphrased. It contains a total of 5801 text pairs, 4076 training pairs, and 1725 test pairs. In this experiment, we segmented 10% of the training data according to the GLUE [49] criterion as the validation set. The accuracy and F1 values are reported in the experiments.
- QQP (The dataset can be downloaded from https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs accessed on 11 November 2022) [50]: is a collection of question pairs from the community question-and-answer site Quora. The task is to determine whether a pair of questions is semantically equivalent. The QQP dataset consists of 404,350 question pairs, and each question pair is annotated with a binary value indicating whether the two questions are paraphrased or not. We used the partitioning approach in the article in [51] to randomly select 5000 annotated and 5000 non-annotated as the validation set, and externally 5000 annotated and 5000 non-annotated as the test set. We keep the remaining instances for training. As with MRPC, we report accuracy and F1 values.
- STS-B (the dataset can be downloaded from http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark accessed on 11 November 2022) [52]: text from image captions, news headlines, and user forums. This includes 5749 training data, 1500 development data, and 1379 test data. Each sentence pair was annotated by humans with a similarity score of 0–5 (a floating point number greater than or equal to 0 and less than or equal to 5. A score of 0 indicates that the two sentences are unrelated, while a score of 5 indicates that the two sentences are very related. Each score is the average of 10 scores marked by 10 different human annotators. We report the Pearson correlation coefficient (PCC) and Spearman correlation coefficient (SCC) as evaluation metrics.
- SICK (the dataset can be downloaded from http://clic.cimec.unitn.it/composes/sick.html accessed on 11 November 2022) [53]: contains 10,000 English sentence pairs from two pre-existing paraphrase datasets: an 8k imageFlickrbuilt dataset, and the SEMEVAL-2012 semantic text similarity video description dataset. It consists of 4439 training data, 495 development data, and 4906 test data. Each sentence pair was annotated by humans as 1–5 (a floating point number greater than or equal to 0 and less than or equal to 5). A score of 0 indicates that the two sentences are unrelated, while a score of 5 indicates that the two sentences are significantly related. Again, we report Pearson correlation coefficient (PCC) and Spearman correlation coefficient (PCC).
4.1.2. Baseline as well as Comparison Methods
- Neural network models include:
- Skip-Thought [39]: a sentence-embedding model for predicting contextual sentences from central sentences.
- Constituency Tree-LSTM [38]: a model that analyzes the syntactic information of sentences and calculates the similarity of sentences using constructed constituency parse trees.
- SIF [41]: a sentence-embedding model considering word frequency and attention weighting mechanisms.
- Pre-trained neural network models include:
- SemBERT [9]: a model for language representation using explicit semantic role annotation.
- Tsinghua ENRIE [28]: a pre-trained language model based on BERT that introduces a priori knowledge of named entities in the knowledge graph.
- Baidu ENRIE2.0 [11]: a sustainable learning framework with external knowledge and multi-task training.
- CF-BERT [54]: a language model that introduces a weighting factor by emphasizing syntactic relations.
- FEFS3C [55]: a joint method for computing frame and item-focused sentence similarity.
- PromptBERT [56]: a cue-based sentence embedding method using denoising techniques for unsupervised training targets;
4.1.3. Other Settings and Implementation Details
4.2. Experimental Results and Analysis
4.3. Influence of Parameters
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Martinez-Rodriguez, J.L.; Hogan, A.; Lopez-Arevalo, I. Information extraction meets the semantic web: A survey. Semant. Web 2020, 11, 255–335. [Google Scholar] [CrossRef]
- Karpukhin, V.; Oğuz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.T. Dense passage retrieval for open-domain question answering. arXiv 2020, arXiv:2004.04906. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning–based text classification: A comprehensive review. ACM Comput. Surv. CSUR 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Chandrasekaran, D.; Mago, V. Evolution of semantic similarity—A survey. ACM Comput. Surv. CSUR 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A survey on contrastive self-supervised learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the NIPS, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Zhang, Z.; Wu, Y.; Zhou, J.; Duan, S.; Zhao, H.; Wang, R. SG-Net: Syntax-Guided Machine Reading Comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2019. [Google Scholar]
- Zhang, Z.; Wu, Y.; Hai, Z.; Li, Z.; Zhang, S.; Zhou, X.; Zhou, X. Semantics-aware BERT for Language Understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2019. [Google Scholar]
- Chen, Q.; Zhu, X.D.; Ling, Z.; Inkpen, D.; Wei, S. Neural Natural Language Inference Models Enhanced with External Knowledge. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 34, pp. 8968–8975. [Google Scholar]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-bert: Enabling language representation with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 2901–2908. [Google Scholar]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. In Proceedings of the North American Chapter of the Association for Computational Linguistics, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Severyn, A.; Nicosia, M.; Moschitti, A. Building structures from classifiers for passage reranking. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013. [Google Scholar]
- Croce, D.; Moschitti, A.; Basili, R. Structured Lexical Similarity via Convolution Kernels on Dependency Trees. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011. [Google Scholar]
- Mohamed, M.; Oussalah, M. SRL-ESA-TextSum: A text summarization approach based on semantic role labeling and explicit semantic analysis. Inf. Process. Manag. 2019, 56, 1356–1372. [Google Scholar] [CrossRef]
- Zou, W.Y.; Socher, R.; Cer, D.; Manning, C.D. Bilingual word embeddings for phrase-based machine translation. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1393–1398. [Google Scholar]
- Chen, L.C. An Improved Corpus-Based NLP Method for Facilitating Keyword Extraction: An Example of the COVID-19 Vaccine Hesitancy Corpus. Sustainability 2023, 15, 3402. [Google Scholar] [CrossRef]
- Lopez-Gazpio, I.; Maritxalar, M.; Gonzalez-Agirre, A.; Rigau, G.; Uria, L.; Agirre, E. Interpretable semantic textual similarity: Finding and explaining differences between sentences. Knowl. Based Syst. 2017, 119, 186–199. [Google Scholar] [CrossRef] [Green Version]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the North American Chapter of the Association for Computational Linguistics, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.G.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. Deberta: Decoding-enhanced bert with disentangled attention. arXiv 2020, arXiv:2006.03654. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Chen, Q.; Zhu, X.; Ling, Z.; Wei, S.; Jiang, H.; Inkpen, D. Enhanced LSTM for natural language inference. arXiv 2016, arXiv:1609.06038. [Google Scholar]
- Tian, Y.; Chen, G.; Song, Y. Aspect-based Sentiment Analysis with Type-aware Graph Convolutional Networks and Layer Ensemble. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Online, 6–11 June 2021. [Google Scholar]
- Mandya, A.; Bollegala, D.; Coenen, F. Graph Convolution over Multiple Dependency Sub-graphs for Relation Extraction. In Proceedings of the International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020. [Google Scholar]
- Wei, J.; Ren, X.; Li, X.; Huang, W.; Liao, Y.; Wang, Y.; Lin, J.; Jiang, X.; Chen, X.; Liu, Q. NEZHA: Neural Contextualized Representation for Chinese Language Understanding. arXiv 2019, arXiv:1909.00204. [Google Scholar]
- Su, J.; Lu, Y.; Pan, S.; Wen, B.; Liu, Y. RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv 2021, arXiv:2104.09864. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.S.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the International Conference on Learning Representations, Scottsdale, Arizona, 2–4 May 2013. [Google Scholar]
- Tien, H.N.; Le, N.M.; Tomohiro, Y.; Tatsuya, I. Sentence Modeling via Multiple Word Embeddings and Multi-level Comparison for Semantic Textual Similarity. Inf. Process. Manag. 2019, 56, 102090. [Google Scholar] [CrossRef] [Green Version]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.R.; Zemel, R.; Urtasun, R.; Torralba, A.; Fidler, S. Skip-thought vectors. arXiv 2015, arXiv:1506.06726. [Google Scholar]
- Wang, S.; Zhang, J.; Zong, C. Learning sentence representation with guidance of human attention. arXiv 2016, arXiv:1609.09189. [Google Scholar]
- Arora, S.; Liang, Y.; Ma, T. A simple but tough-to-beat baseline for sentence embeddings. In Proceedings of the International Conference on Learning Representations, Palais des Congrès Neptune, Toulon, France, 24–26 April 2017. [Google Scholar]
- Vishwanathan, S.V.N.; Smola, A. Fast Kernels for String and Tree Matching. In Proceedings of the NIPS, Cambridge, MA, USA, 1 January 2002. [Google Scholar]
- Moschitti, A. Making Tree Kernels Practical for Natural Language Learning. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 5–6 April 2006. [Google Scholar]
- Moschitti, A. Efficient Convolution Kernels for Dependency and Constituent Syntactic Trees. In Proceedings of the European Conference on Machine Learning, Berlin, Germany, 18–22 September 2006. [Google Scholar]
- Wu, W.; Li, H.; Wang, H.; Zhu, K.Q. Probase: A probabilistic taxonomy for text understanding. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012. [Google Scholar]
- Wu, Z.; Palmer, M. Verb Semantics and Lexical Selection. arXiv 1994, arXiv:cmp-lg/9406033. [Google Scholar]
- Mrini, K.; Dernoncourt, F.; Bui, T.; Chang, W.; Nakashole, N. Rethinking Self-Attention: Towards Interpretability in Neural Parsing. In Proceedings of the Findings, Online, 16–20 November 2020. [Google Scholar]
- Dolan, W.B.; Brockett, C. Automatically Constructing a Corpus of Sentential Paraphrases. In Proceedings of the International Joint Conference on Natural Language Processing, Jeju Island, Republic of Korea, 11–13 October 2005. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Chandra, A.; Stefanus, R. Experiments on Paraphrase Identification Using Quora Question Pairs Dataset. arXiv 2020, arXiv:2006.02648. [Google Scholar]
- Wang, Z.; Hamza, W.; Florian, R. Bilateral Multi-Perspective Matching for Natural Language Sentences. In Proceedings of the International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Cer, D.M.; Diab, M.T.; Agirre, E.; Lopez-Gazpio, I.; Specia, L. SemEval-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation. In Proceedings of the International Workshop on Semantic Evaluation, Vancouver, BC, Canada, 3–4 August 2017. [Google Scholar]
- Marelli, M.; Menini, S.; Baroni, M.; Bentivogli, L.; Bernardi, R.; Zamparelli, R. A SICK cure for the evaluation of compositional distributional semantic models. In Proceedings of the International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014. [Google Scholar]
- Yin, X.; Zhang, W.; Zhu, W.; Liu, S.; Yao, T. Improving Sentence Representations via Component Focusing. Appl. Sci. 2020, 10, 958. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Shi, H.; Liu, W.; Yan, X. A joint FrameNet and element focusing Sentence-BERT method of sentence similarity computation. Expert Syst. Appl. 2022, 200, 117084. [Google Scholar] [CrossRef]
- Jiang, T.; Jiao, J.; Huang, S.; Zhang, Z.; Wang, D.; Zhuang, F.; Wei, F.; Huang, H.; Deng, D.; Zhang, Q. Promptbert: Improving bert sentence embeddings with prompts. arXiv 2022, arXiv:2201.04337. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Learning Rate | Epochs | Max Length | Batch Size |
|---|---|---|---|---|
| MRPC | 3 | 128 | 32 | |
| QQP | 3 | 75 | 16 | |
| STS-B | 3 | 128 | 64 | |
| SICK | 3 | 80 | 64 |
| Model\Datasets | MRPC | SICK | STS-B | QQP |
|---|---|---|---|---|
| BERT | 84.80/88.90 | 87.83/81.40 | 87.10/85.80 | 91.93/91.70 |
| BERT-GCN (ours) | 87.01/90.33 | 87.86/82.78 | 87.39/86.62 | 92.74/92.49 |
| KEBERT-GCN (ours) | 87.99/90.58 | 88.33/82.83 | 87.87/87.07 | 94.75/94.60 |
| Model | PCC | SCC |
|---|---|---|
| Skip-Thought | 71.80 | 69.70 |
| Constituency Tree-LSTM | 71.90 | - |
| SIF | 72.00 | - |
| BERT | 87.10 | 85.80 |
| 87.30 | - | |
| - | 83.20 | |
| 87.60 | 86.50 | |
| 87.58 | 86.29 | |
| - | 86.78 | |
| 84.56 | - | |
| KEBERT-GCN (ours) | 87.74 | 87.07 |
| CPT-PK (ours) | 76.42 | 75.31 |
| KEBERT-GCN+CPT-PK (ours) | 88.05 | 87.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Li, C.; Huang, G.; Guo, Q.; Li, H.; Wei, X. A Short-Text Similarity Model Combining Semantic and Syntactic Information. Electronics 2023, 12, 3126. https://doi.org/10.3390/electronics12143126
Zhou Y, Li C, Huang G, Guo Q, Li H, Wei X. A Short-Text Similarity Model Combining Semantic and Syntactic Information. Electronics. 2023; 12(14):3126. https://doi.org/10.3390/electronics12143126
Chicago/Turabian StyleZhou, Ya, Cheng Li, Guimin Huang, Qingkai Guo, Hui Li, and Xiong Wei. 2023. "A Short-Text Similarity Model Combining Semantic and Syntactic Information" Electronics 12, no. 14: 3126. https://doi.org/10.3390/electronics12143126
APA StyleZhou, Y., Li, C., Huang, G., Guo, Q., Li, H., & Wei, X. (2023). A Short-Text Similarity Model Combining Semantic and Syntactic Information. Electronics, 12(14), 3126. https://doi.org/10.3390/electronics12143126