Abstract
With the rapid development of deep learning technology, many algorithms for mask-wearing detection have achieved remarkable results. However, the detection effect still needs to be improved when dealing with mask-wearing in some complex scenes where the targets are too dense or partially occluded. This paper proposes a new mask-wearing detection model: YOLOv7-CPCSDSA. Based on YOLOv7, this model replaces some convolutions of the original model, CatConv, with FasterNet’s partial convolution (PConv) to form a CatPConv (CPC) structure, which can reduce computational redundancy and memory access. In the case of an increase in the network layer, the parameters are reduced instead. The Small Detection (SD) module is added to the model, which includes structures such as upsampling, concat convolution, and MaxPooling to enhance the ability to capture small targets, thereby improving detection accuracy. In addition, the Shuffle Attention (SA) mechanism is introduced, which enables the model to adaptively focus on important local information, thereby improving the accuracy of detecting mask-wearing. This paper uses comparative and ablation experiments in the mask dataset (including many images in complex scenarios) to verify the model’s effectiveness. The results show that the mean average precision@0.5 (mAP@0.5) of YOLOv7-CPCSDSA reaches 88.4%, which is 1.9% higher than that of YOLOv7, and its frames per second (FPS) rate reaches 75.8 f/s, meeting the real-time detection requirements. Therefore, YOLOv7-CPCSDSA is suitable for detecting mask-wearing in complex scenarios.
1. Introduction
In recent years, with global public health events, one of the most effective ways to prevent the spread of viruses is to wear masks [1,2]. However, many people get infected by neglecting to wear masks, which burdens the public healthcare system more. Mask-wearing detection has become a hot topic in the field of computer vision. In order to ensure the safety of specific public places, mask-wearing detection technology has been widely used in many scenarios, such as hospitals, nursing homes, and schools. Mask-wearing detection utilizes deep learning techniques to automatically detect and identify masks on human faces, which has become a crucial method to help control disease spread. Mask-wearing regulations can be effectively enforced by automatically identifying who is wearing a mask in public places, workplaces, and other social settings. So far, much in-depth research has been carried out on face mask detection. Khandelwal et al. [3] proposed a mask classification technique using the MobileNetv2 object classifier, which can binarize the images into two classes: faces with and without masks. Puja et al. [4] reported having combined mask-wearing detection with the field of artificial intelligence to check whether a person is wearing a mask through existing monitoring systems and innovative neural network algorithms. He et al. [5] proposed an algorithm for face-mask based on HSV, HOG features, and SVM to check faces wearing masks on a regular basis. In the past few years, deep learning and object detection technology have achieved remarkable results in many fields. However, there are still some challenges in the task of mask-wearing detection, such as situations where the target is too dense in a complex scene or the local scene is occluded. Therefore, it has great theoretical importance and practical application to accurately handle the task of mask-wearing detection in complex scenarios. This study aims to propose an improved YOLOv7 mask-wearing detection model to improve the performance of mask-wearing detection.
Deep learning is an essential part of machine learning. Sutskever et al. [6] proposed deep learning, which can simulate the operation of the human brain and build a neural network for autonomous learning. Deep learning can be widely applied to robot vision [7], natural language processing [8], speech signal processing [9] and other application fields. The commonly used deep learning model is a convolutional neural network (CNN) [10], which consists of multiple convolutional and pooling layers and uses sparse concatenation methods. By computing in layers, rich feature information can be extracted from images for target classification and regression tasks. The local connection and parameter-sharing properties of CNN make feature extraction more efficient.
Object detection is mainly employed for object categorization and positioning. Object detection algorithms based on deep learning are primarily divided into two categories [11]. The first is a two-stage object detection algorithm, such as R-CNN series algorithms [12,13,14,15]; the second is a one-stage object detection algorithm, such as RetinaNet [16] and YOLO series algorithms [17,18,19,20,21,22]. The first step of the two-stage algorithm is to obtain the input image and extract candidate regions. The second step is to perform CNN classification and recognition on the regions. The two-stage algorithm can achieve high accuracy but low detection speed. The one-stage algorithm performs deep sampling of different scales on each region of the image, then extracts the image features and classifies the objects, outputting the class and bounding box information of the target directly from the image. Deep sampling is a technique used to deal with targets of different scales, introducing multiple layers of receptive field sizes into the network. For example, feature pyramid networks [23] achieve multi-scale object detection by introducing multiple-feature pyramid layers of different scales, thereby improving the overall detection performance, although the computational efficiency and classification speed of the one-stage algorithm are relatively high, due to its uniform and dense sampling method, which poses a certain challenge to the training and fitting of the model.
This paper uses the one-stage algorithm for mask-wearing detection based on the comprehensive consideration of performance and complexity. Specifically, the one-stage algorithm has a high processing speed and low computational complexity and directly predicts objects from the image without a complex region proposal process, which is very important for real-time applications and processing large amounts of data. Because mask-wearing detection requires real-time performance, the one-stage algorithm is chosen. This paper aims to detect masks and obtain accurate detection results, and treat mask detection as an end-to-end object detection task, which can provide more accurate mask detection results.
Since mask-wearing images in complex scenes often face problems such as overly dense targets and localized scene occlusion, it is difficult to identify target features, making it difficult for traditional object detection algorithms to achieve satisfactory results. YOLOv7 not only meets real-time detection demand but is also very suitable for deployment in the actual environment. This article presents a new mask-wearing detection model, YOLOv7-CPCSDSA, which combines CPC structure, SD structure, and SA mechanism [24] based on YOLOv7.
The contributions of this paper are as follows:
- (1)
- This paper validates and analyzes the model through comparison and ablation experiments. YOLOv7 is chosen as the base model to demonstrate the superiority of YOLOv7-CPCSDSA in balancing accuracy and speed by comprehensively evaluating various metrics.
- (2)
- The CPC structure is added to YOLOv7, which can better use computing power, effectively extract spatial features, and reduce computing redundancy and memory access.
- (3)
- The SD structure is added to the YOLOv7 to enhance the detailed information and the range of the perceptual field of the feature map.
- (4)
- The SA mechanism is combined in the YOLOv7, which can make the model focus on the local information in the image with a lower computational cost and improve the model’s accuracy.
The rest of the paper is organized as follows: Section 2 outlines the related work in relevant fields. Section 3 presents the network structure of YOLOv7 and YOLOv7-CPCSDSA, and introduces the principles of CPC, SD, and SA modules. Section 4 introduces the experimental environment, experimental datasets, experimental parameter settings, comparative experiments, ablation experiments, and visualization. Section 5 summarizes the advantages and disadvantages of the work and introduces further research.
2. Related Work
In recent years, both one-stage and two-stage algorithms have achieved remarkable results in the research of object detection. Ge et al. [25] proposed a CNN model based on LLE-CNNs capable of recognizing human faces and those wearing masks. This model includes a proposal, embedding and verification modules, and has an average precision of 76.4%. Jiang et al. [26] proposed a multi-scale facial detection algorithm that solves the difficulty of recognizing small and medium-scale faces based on Faster R-CNN. Although the model exhibits high precision in face detection, its model structure is relatively complex, and the detection effect on small targets is not so good. Loey et al. [27] proposed a mask-wearing detection model based on deep learning, which uses the YOLOv2 model combined with ResNet50 for feature extraction. Attention is introduced to improve the model’s performance on mask-wearing detection tasks. Experimental results show that the proposed model outperforms other algorithms in accuracy. However, the model needs to improve in generalization ability. Su et al. [28] proposed an improved YOLOv3 mask-wearing detection algorithm, which combines transfer learning and uses EfficientNet as the backbone network, which reduces the number of network parameters and improves the accuracy of mask-wearing detection. Wu et al. [29] presented a mask-wearing detection model based on FMD-YOLO, which combines the deep residual network and the Res2Net module in feature enhancement network and uses the enhanced path aggregation network for feature fusion. In addition, the model adopts localization loss during the training stage and employs the Non-Maximum Suppression (NMS) technique during the inference phase to optimize detection efficiency and accuracy, resulting in a superior mAP value. Kumar et al. [30] proposed an improved mask vision model based on YOLOv4-tiny, combining a spatial pyramid pooling module and an additional small detection layer. K-means++ clustering is used to determine the best initial value of the anchor box to achieve faster and more accurate regression, the CIoU loss function is used, and the mAP of the proposed improved network is 6.6% higher than that of YOLOv4-tiny. Zhao et al. [31] presented an improved algorithm for face mask detection based on YOLOv4. The algorithm introduces an attention mechanism module at an appropriate network level, focusing on key facial feature points with masks and reducing irrelevant data. Feature extraction from images is carried out by employing a path-aggregation network and feature pyramid. The experimental data suggest better results when the Convolutional Block Attention Module (CBAM) is inserted before YOLOv4’s three heads and within the neck network. Guo et al. [32] proposed the YOLOv5-CBD model, fusing a coordinated attention mechanism and a weighted bidirectional feature pyramid network for the purpose of bolstering detection accuracy. However, this model focuses on the recognition problem of the mask itself. Wang et al. [33] proposed a mask detection technique employing the YOLO-GBC network designed to address issues of incorrect identification and high missed detection rate of existing mask detection algorithms in actual scenarios. The network adopts the global attention mechanism and content-aware reassembly of features, enabling key information extraction and retain global features. There are varying degrees of improvements in both accuracy and recall. The main problem of the above methods is the limited ability to express features in complex scenarios, and the detection accuracy needs to be improved.
3. Models
3.1. YOLOv7
The basic architecture of YOLOv7 includes input, backbone, and head. Input first preprocesses the input image and aligns it into a 640 × 640 RGB image. The backbone includes CBS, ELAN, and MP modules. The input image undergoes feature extraction through the backbone. Then, the multi-scale feature fusion mode is adopted in the head, which can retain more details and help improve the model’s ability to represent the target. YOLOv7 has three detection heads, and the features after feature fusion will be passed to the output layer, which will predict the location and category of the target and generate the corresponding bounding box. The detection head outputs three feature scales: 20 × 20, 40 × 40 and 80 × 80, with the three scales detecting targets at scales corresponding to large, medium and small targets, respectively. YOLOv7 applies the NMS algorithm in the prediction results to remove redundant bounding boxes and ensure that each target has only one bounding box corresponding to it. The activation function of YOLOv7 uses SiLu. The structure diagram of YOLOv7 is shown in Figure 1.
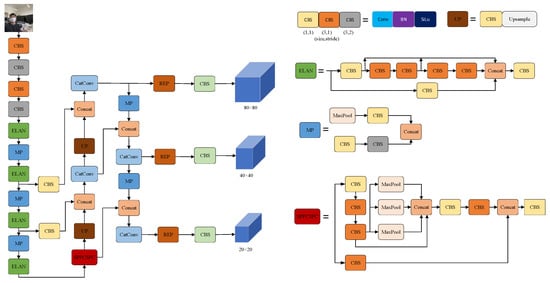
Figure 1.
YOLOv7 structure diagram.
3.2. CPC
PConv [34] is an efficient convolutional neural network structure that can improve network performance and efficiency. PConv takes advantage of the redundancy in feature maps, applying regular Conv to only some of the input channels while leaving the rest unchanged. Figure 2 shows the feature redundancy map. PConv reduces the amount of redundant calculations and memory accesses, has lower floating point operations (FLOPs) than regular Conv, and can extract spatial features more efficiently.
Figure 2.
Feature redundancy map.
Figure 3 shows the schematic diagram of PConv. PConv applies a regular Conv method for spatial feature extraction on a portion of the input channels, leaving the rest unaffected. represents the number of channels of the input feature map. represents the channels employed for spatial feature extraction within PConv. Moreover, the input and output feature maps have the same channels. * represents convolution operation.
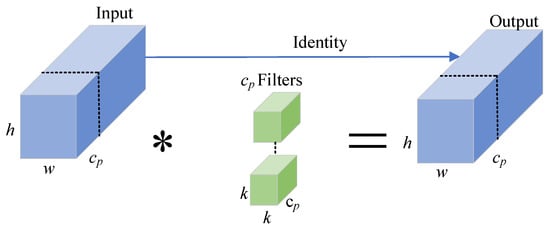
Figure 3.
Schematic diagram of PConv.
The choice of value can be considered based on the following factors: observe the degree of redundancy between input feature map channels, if the redundancy between different channels is large, by using some channels for calculation, the amount of calculation and memory access can be reduced; A balance needs to be found between accuracy and computational efficiency based on performance requirements. Larger values may decrease accuracy, so a trade-off is required between accuracy and computational efficiency. The optimal value of can be selected according to the results of experiments and verifications to maintain a reasonable level of accuracy while reducing computational redundancy and memory access. In this paper, is set to .
The FLOPs of PConv are only , where is the height, is the width, is the height and width of the filters. Since , the FLOPs of PConv are only 1/16 of regular Conv. In addition, the memory access of PConv is small, that is, . Because , the memory access of PConv is only 1/4 of that of regular Conv. Because PConv only needs to read and process the data of some channels, while the conventional convolution operation needs to read and process the data of all channels. Therefore, PConv is beneficial to reduce FLOPs and memory access.
Replacing part of the convolution of CatConv in the YOLOv7 with PConv to generate a CPC structure can effectively reduce redundant computation and memory access while maintaining good feature extraction capabilities. Since the output feature maps of PConv have the same number of channels as the input feature maps, this enables PConv to integrate with the CatConv seamlessly. The structure of the CatConv module is shown in Figure 4a, and that of the CPC module is shown in Figure 4b.
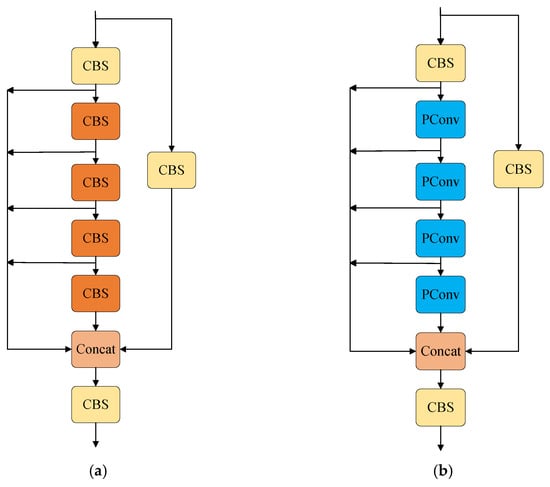
Figure 4.
(a) CatConv structure diagram; (b) CPC structure diagram.
3.3. SD
YOLOv7 can only capture small targets with a feature scale of 80 × 80. Small targets may contain finer details and structural information, which smaller feature maps may not adequately capture. By using larger feature maps, the range of the receptive field can be increased, thereby improving the ability to detect and recognize small targets. Larger feature maps can cover wider context information, enabling the model to understand the surrounding environment of small targets comprehensively.
Therefore, this paper designs the SD structure to capture small targets better. The input to the SD structure is an 80 × 80 feature map. The feature scale is first expanded to 160 × 160 by an upsampling operation and combined with a 160 × 160 feature map in the backbone, a step that increases the detailed information and the range of the perceptual field of the feature map. CPC can enable the network to learn the information of the feature map better and can better maintain the convergence when the model is scaled. The size of the feature map is then reduced back to 80 × 80 via the MaxPooling operation, which reduces the spatial size of the feature map while retaining the main features, thus controlling the complexity of the network and enabling information transfer from a higher to a lower scale. The SD structure is shown in Figure 5.
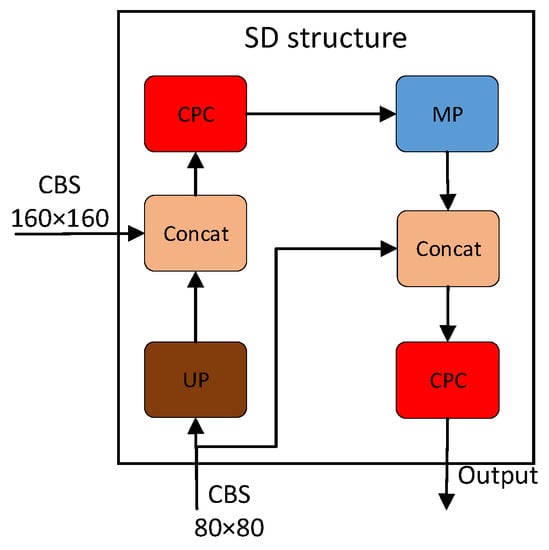
Figure 5.
SD structure diagram.
3.4. SA
The SA module can focus on the important information in the input feature map to improve the model’s performance. Compared with the CBAM, the SA module introduces channel shuffle, further enhancing attention features’ diversity. Its channel shuffle and the combination of channel and spatial attention give the SA module better generalization ability in various complex scenarios. The SA structure is shown in Figure 6.
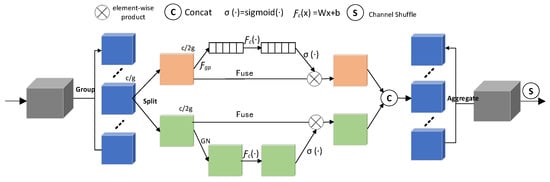
Figure 6.
SA structure diagram.
The SA module mainly includes three parts: a grouping feature, fusing attention, and an aggregating feature. The input feature map is divided into groups along the channel dimension, expressed as , where each sub-feature will capture a specific semantic response with training, which makes feature extraction more accurate and detailed.
Then, is divided into two branches along the channel dimension, and two sub-features are denoted as . The channel attention branch adopts the interrelationships of channels to generate channel attention maps, and uses global average pooling (GAP) to generate to embed global information, which can be calculated by shrinking on the spatial dimension . is formulated as:
where is height, is width, and is GAP.
Then, create a compact feature through the simple gating mechanism with sigmoid activation. The output of channel attention is formulated as:
there are only two transformation parameters in the Formula (2), namely and .
The spatial attention branch captures the spatial dependencies between features to generate spatial attention maps. The spatial attention branch performs group norm calculation on the input feature map and then uses to enhance the representation of the input. The output of spatial attention is formulated as:
where the parameters are and .
The outputs of the two branches are connected: . Channel shuffle is adopted to realize cross-group information exchange, and the final output of the SA module is consistent with the size of the input feature map.
3.5. YOLOv7-CPCSDSA
As shown in Figure 7, the model structure of YOLOv7-CPCSDSA is shown. The backbone network continues the backbone of YOLOv7 and is used for feature extraction. Replacing part of the convolution of CatConv in the YOLOv7 with PConv to generate a CPC structure can reduce the redundancy of calculation and memory access. This combination significantly reduces the number of parameters and FLOPs and improves computational efficiency. Adding the SD structure to the network, as shown in the blue box in Figure 7, enables the model to capture small targets better and improve the accuracy of dense objects. Adding SA to the model can make the model focus on the local information in the image with a lower computational cost, increase the detail of the output features, and improve the model’s accuracy.
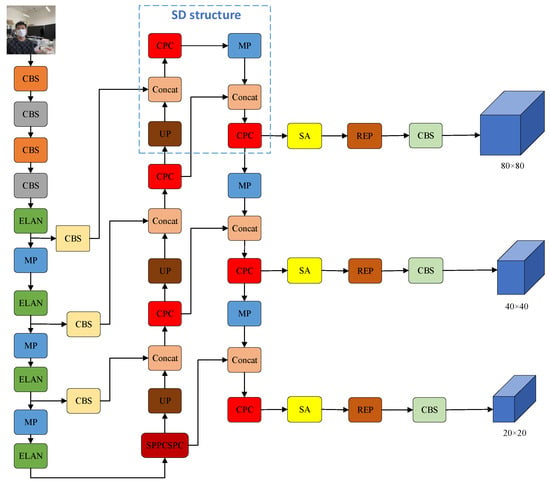
Figure 7.
YOLOv7-CPCSDSA structure diagram.
4. Experiment
4.1. Experimental Environment
All experiments in this paper are conducted on a computer with Windows 10 operating system with Intel i7-11800H processor and NVIDIA GeForce RTX 3070 Laptop graphics card. The software environments are CUDA 11.1, CUDNN 8.1.0 and PyTorch1.9. The compiler is PyCharm, and the programming language is python3.8. In the model training, the epoch is configured to 100, with a batch size of 8.
4.2. Experimental Dataset
The dataset used in all experiments is based on the VOC_MASK dataset on the Baidu AI Studio website and some self-made mask image data were added. There are 7972 images in this dataset, including two categories: mask-wearing (face_mask) and not mask-wearing (face). The dataset contains 3232 images with face_mask and 4740 images with face. The dataset is divided into training set, verification set, and test set, according to the ratio of 6:2:2. There are 4771 images and their labels in the training set, 1590 images and their labels in the validation set, and 1611 images and their labels in the test set.
4.3. Experimental Parameter Settings
The parameter settings of all experiments in this paper are shown in Table 1.

Table 1.
Parameter settings.
4.4. Comparison Experiment
This paper conducts a comparison experiment of Faster R-CNN, RetinaNet, YOLOv5s, YOLOX, YOLOv7, and YOLOv7-CPCSDSA using the same experimental data and environment. The comparison experiment results are shown in Table 2 and Figure 8. The accuracy of the YOLOv7-CPCSDSA is higher than other models. In this study, the mAP@0.5 is increased by 11% relative to Faster R-CNN, 6.9% relative to RetinaNet, 2.6% relative to YOLOv5s, 2.5% relative to YOLOX, and 1.9% relative to YOLOv7. The effectiveness of the YOLOv7-CPCSDSA in detecting mask datasets is proved.
Table 2.
Comparison experiments of different detection models.
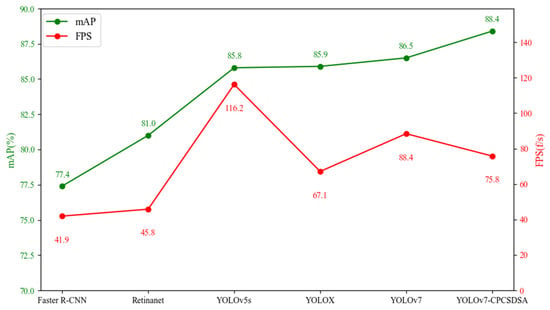
Figure 8.
Comparison chart of mAP and FPS of different detection models.
4.5. Ablation Experiment
This paper verifies the effectiveness of the CPC module, SD module, and SA module in mask-wearing detection using the same experimental data and experimental environment. In the ablation experiment, YOLOv7 is used as the basic model, the resolution of the input image is 640 × 640, and each model is trained for 100 epochs. The ablation experiment results are shown in Table 3 and Figure 9.
Table 3.
Ablation experiment results.
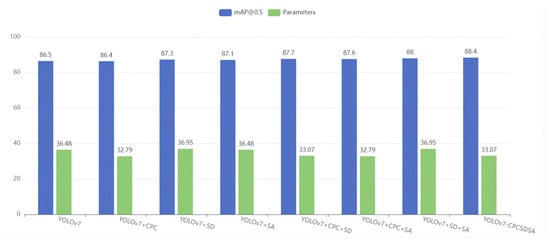
Figure 9.
Comparison chart of mAP@0.5 and parameters of ablation experiment.
According to Table 3 and Figure 9, under the same conditions, for mAP@0.5 and mAP@0.5:0.95, the improved YOLOv7 model has a significant improvement. The mAP@0.5 of YOLOv7 is 86.5%. After adding the CPC module, the mAP@0.5 drops slightly by 0.1%, but the parameters are reduced by 3.69 M, effectively reducing the model complexity. Adding the SD structure to the model improves mAP@0.5 by 0.8%, enhancing feature capture and detection of small objects. However, due to the addition of the SD module, the amount of parameters is increased by 0.47 M. By adding the SA module, mAP@0.5 increases by 0.6%, while the amount of parameters remains almost unchanged. The SA module can effectively extract channel and spatial information from input features and utilize multi-dimensional effective information to enhance the detection performance of the network. Combined YOLOv7 with the above modules, the detection accuracy of YOLOv7-CPCSDSA is enhanced, and the amount of parameters is reduced.
4.6. Visualization
In order to verify the visual effect of the model proposed in this paper in various mask-wearing detection scenarios, the images with too-dense targets or occluded local scenes in complex scenarios were selected from the test set for detection. Figure 10, Figure 11 and Figure 12 depict visual comparisons of the effects of the YOLOv7 and YOLOv7-CPCSDSA models in the same scene.

Figure 10.
Dense mask-wearing detection comparison chart.

Figure 11.
Comparison of face occlusion detection.

Figure 12.
Detection comparison chart in light conditions.
Figure 10a,b are comparison diagrams of dense mask-wearing detection. YOLOv7 failed to detect small targets wearing masks in the distance, while YOLOv7-CPCSDSA can detect people wearing masks in the distance, marked with a red box and enlarged in Figure 10b.
Figure 11a,b show the comparison of the detection of face masks. YOLOv7 misses the detection of people wearing masks. However, YOLOv7-CPCSDSA can correctly recognize faces wearing masks, and the results become better, as shown by the red box in Figure 11b.
Figure 12a,b present a detection comparison chart under light conditions; YOLOv7 mistakenly identified the person wearing the mask as not wearing the mask. In contrast, YOLOv7-CPCSDSA can correctly identify the person wearing the mask, marked with a red box and enlarged in Figure 12b.
Figure 13 shows the P-R diagrams of YOLOv7 and YOLOv7-CPCSDSA.
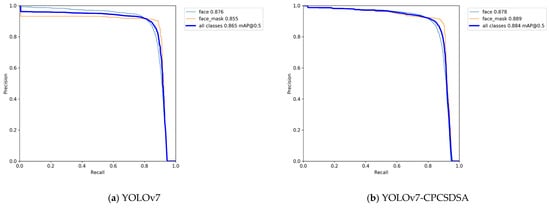
Figure 13.
P-R diagram.
Figure 13a,b show the P-R diagrams of YOLOv7 and YOLOv7-CPCSDSA, respectively, which contain mAP@0.5 values of face, face_mask, and all classes. The abscissa is the recall value, and the ordinate is the precision value. The YOLOv7-CPCSDSA model proposed in this paper has significantly higher accuracy than YOLOv7.
5. Conclusions
This paper proposes a mask-wearing detection model, YOLOv7-CPCSDSA, for mask-wearing detection tasks in complex scenarios. In the YOLOv7 network, the CPC structure is formed by replacing the part of convolution in CatConv with PConv. By introducing this structure, computational redundancy, memory accesses, and model parameters can be reduced, thus improving the computational efficiency of the network. The SD structure is added to the model to optimize the model for dense targets, which can better capture small targets and improve the detection accuracy of dense targets. The SA is added to the network to focus on locally important information in the image with a lower computational cost, and increase the details in the output features.
In the dataset of this article, compared with YOLOv7, the mAP@0.5 and mAP@0.5:0.95 of YOLOv7-CPCSDSA have been increased, and the number of parameters has been reduced. The comparison experiment has shown that the mAP of the proposed model is higher than other classical models. The ablation experiment results show that each module improves the detection performance. The visualization results show that YOLOv7-CPCSDSA has a good detection effect in complex scenarios. However, the FPS of this model is lower than that of YOLOv7.
The YOLOv7-CPCSDSA has certain limitations in the dataset. A dataset may mainly contain samples from specific populations or samples collected in specific environments, affecting models’ generalization ability in complex scenarios. The model also has certain limitations in performance, it may be difficult to detect masks accurately under certain lighting conditions, and the covering may pose a challenge for accurate detection, resulting in potential false positives or false negatives.
The YOLOv7-CPCSDSA can be used for real-time monitoring of public places, such as airports, railway stations, shopping malls, and schools, and can also be applied to other fields, such as healthcare and industrial safety, which can be used to detect whether patients and medical staff in hospitals are wearing masks correctly and to monitor whether factory workers are adhering to safety regulations. YOLOv7-CPCSDSA detection still has some defects when the mask-wearing is seriously occluded. Future research can focus on further optimizing the algorithm to improve the accuracy and robustness of mask-wearing detection.
Author Contributions
Conceptualization, J.W. (Jingyang Wang); methodology, J.W. (Jingyang Wang) and N.Y.; software, J.W. (Junkai Wang); validation, X.Z.; investigation, X.Z. and J.W. (Junkai Wang); writing—original draft preparation, J.W. (Junkai Wang) and X.Z.; writing—review and editing, J.W. (Jingyang Wang) and N.Y.; visualization, J.W. (Junkai Wang) and X.Z.; supervision, N.Y. and J.W. (Jingyang Wang); project administration, J.W. (Junkai Wang) and X.Z.; funding acquisition, J.W. (Jingyang Wang). All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Innovation Foundation of Hebei Intelligent Internet of Things Technology Innovation Center under Grant AIOT2203.
Informed Consent Statement
As the data come from the public data set, the informed consent is exempted.
Data Availability Statement
Data are available on request due to restrictions regarding privacy. The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Palanisamy, V.; Thirunavukarasu, R.; Galos, K. Implications of Big Data Analytics in developing Healthcare Frameworks—A review. J. King Saud. Univ. 2017, 31, 4. [Google Scholar] [CrossRef]
- Chu, D.K.; Akl, E.A.; Duda, S.; Solo, K.; Yaacoub, S.; Schünemann, H.J. Physical distancing, face masks, and eye protection to prevent person-to-person transmission of SARS-CoV-2 and COVID-19: A systematic review and meta-analysis. Lancet 2021, 395, 10242. [Google Scholar]
- Khandelwal, P.; Khandelwal, A.; Agarwal, S. Using computer vision to enhance safety of workforce in manufacturing in a Post COVID world. arXiv 2020, arXiv:2005.05287. [Google Scholar]
- Pooja, S.; Preeti, S. Face Mask Detection Using AI. In Predictive and Preventive Measures for COVID-19 Pandemic; Springer: Singapore, 2021; pp. 293–305. [Google Scholar]
- He, Y.; Wang, Z.; Guo, S.; Yao, S.; Hu, X. Face mask detection algorithm based on HSV+ HOG features and SVM. J. Meas. Sci. Instrum. 2022, 13, 267–275. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Zhang, F.; Leitner, J.; Milford, M.; Upcroft, B.; Corke, P. Towards Vision-Based Deep Reinforcement Learning for Robotic Motion Control. arXiv 2015, arXiv:1511.03791. [Google Scholar]
- Tom, Y.; Devamanyu, H.; Soujanya, P.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing. J. Chin. Inst. Eng. 2018, 13, 55–75. [Google Scholar]
- Mary, L.; Yegnanarayana, B. Extraction and representation of prosodic features for language and speaker recognition. Speech Commun. 2008, 50, 782–796. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Zhang, J.; Nong, C.; Yang, Z. Review of object detection algorithms based on convolutional neural network. J. Ordnance Equip. Eng. 2022, 43, 37–47. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Piotr, D.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. arXiv 2021, arXiv:2102.00240. [Google Scholar]
- Ge, S.; Li, J.; Ye, Q.; Zhao, L. Detecting Masked Faces in the Wild with LLE-CNNs. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Jiang, H.; Learned-Miller, E. Face Detection with the Faster R-CNN. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face and Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017. [Google Scholar]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. Fighting against COVID-19: A novel deep learning model based on YOLO-v2 with ResNet-50 for medical face mask detection. Sustain. Cities Soc. 2020, 65, 102600. [Google Scholar] [CrossRef] [PubMed]
- Su, X.; Gao, M.; Ren, J.; Li, Y.H.; Dong, M.; Liu, X. Face mask detection and classification via deep transfer learning. Multimed. Tools Appl. 2022, 81, 4475–4494. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Li, H.; Zeng, N.; Li, F. FMD-Yolo: An efficient face mask detection method for COVID-19 prevention and control in public. Image Vis. Comput. 2022, 117, 10341. [Google Scholar] [CrossRef]
- Kumar, A.; Kalia, A.; Verma, K.; Sharma, A.; Kaushal, M. Scaling up face masks detection with YOLO on a novel dataset. Optik 2021, 239, 166744. [Google Scholar] [CrossRef]
- Zhao, G.; Zou, S.; Wu, H. Improved Algorithm for Face Mask Detection Based on YOLO-v4. Int. J. Comput. Intell. Syst. 2023, 16, 104. [Google Scholar] [CrossRef]
- Guo, S.; Li, L.; Guo, T.; Cao, Y.; Li, Y. Research on Mask-Wearing Detection Algorithm Based on Improved YOLOv5. Sensors 2022, 22, 4933. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Zhang, B.; Cao, Y.; Sun, M.; He, K.; Cao, Z.; Wang, M. Mask Detection Method Based on YOLO-GBC Network. Electronics 2023, 12, 408. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.H.; He, H. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. arXiv 2023, arXiv:2303.03667. [Google Scholar]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).