

Advanced Misinformation Detection: A Bi-LSTM Model Optimized by Genetic Algorithms

 ,
,
Abstract
:1. Introduction
- Introduction of a GA-tuned Bi-LSTM model: We introduce a novel deep learning model based on Bi-LSTM that is optimized with GA. This unique combination exhibits superior performance in detecting misinformation.
- Implementation and evaluation of multiple machine learning models: Various machine learning models are implemented and evaluated in this study, providing a benchmark to demonstrate the superior performance of our proposed model. Additionally, we integrate these models with TF-IDF vectorization techniques for text data extraction.
- Comprehensive Comparative Analysis: An exhaustive comparative analysis of our proposed GA-tuned Bi-LSTM model is carried out against both the implemented machine learning models and the state-of-the-art techniques. This analysis, performed across a range of performance metrics, provides a holistic and balanced evaluation of the effectiveness of our proposed model.
- Section 2: Methods—Provides an overview of the methods employed in this research.
- Section 3: Methodology—Delivers a detailed explanation of the adopted methodology.
- Section 4: Experimental Design—Outlines the design of our experiments, detailing the set-up of our GA-tuned Bi-LSTM model and discussing the performance metrics used for evaluation.
- Section 5: Results—Presents and discusses the results, provides a comprehensive comparative performance analysis of the proposed Bi-LSTM model with other traditional machine learning models and state-of-the-art techniques.
- Section 6: Conclusion and Future Work—Concludes the study by summarizing the findings and indicating potential directions for future research.
- Appendix A: TF-IDF—Delivers a thorough explanation of the TF-IDF vectorization technique employed in the study.
2. Methods
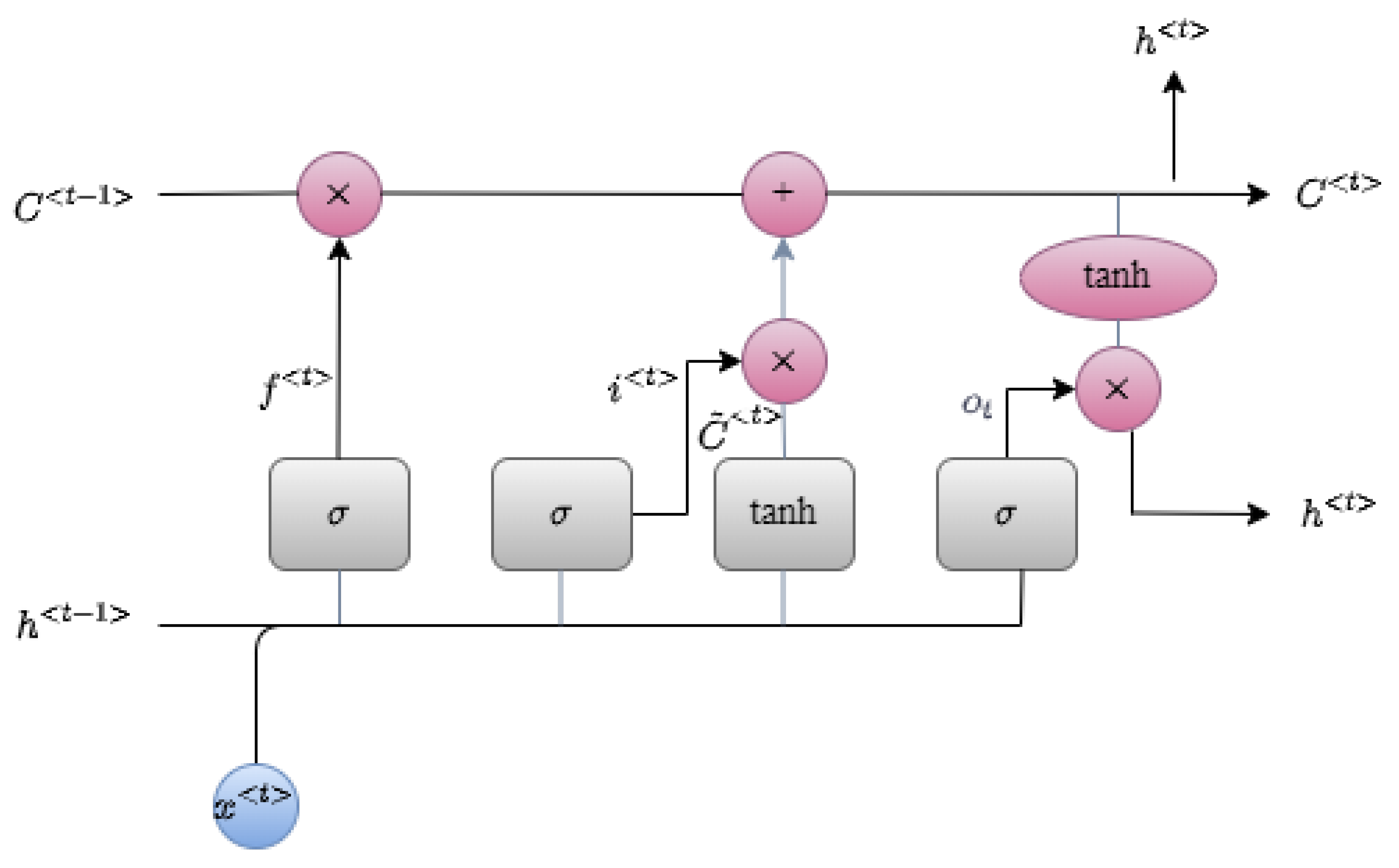
2.1. Long Short-Term Memory
- 1.
- Forget gateThis gate determines whether the information from the previous timestamp should be kept or is irrelevant and should be forgotten. The decision is made by passing the previous hidden state and the current input via a sigmoid function (). This gate’s output is expressed in Equation (1). A value closer to 1 indicates keeping, while a value closer to 0 indicates forgetting:where and are parameters specific to the forget gate.
- 2.
- Input gateThis gate is in charge of adding relevant information to the cell state. This is accomplished in three steps:
- (a)
- A sigmoid function is used to control which values are added to the cell state:where and are the input gate-specific parameter.
- (b)
- Using the tanh function, we generate a vector of new candidate values to be added to the cell state:
- (c)
- We multiply the old cell state () by the forget gate and then add to update the cell state ():
- 3.
- Output gateThis gate outputs the updated information. The output gate’s operation is divided into two steps:
- (a)
- Determine the parts of the cell state to output via the sigmoid function:
- (b)
- Pass the cell state through the tanh function and multiply it by to select the components the hidden state should carry:The new and the new values are then carried over to the next time step.
2.2. Bi-LSTM
2.3. Genetic Algorithm
2.3.1. Basics of GA
| Algorithm 1: Pseudocode for a typical GA |
 |
2.3.2. Chromosome Encoding
2.3.3. GA Operators
- 1.
- SelectionIn the selection process, chromosomes from the current population are selected as parents for mating (crossover). According to Darwin’s theory of evolution, better individuals have a better chance of survival and participation in reproduction in order to produce new offspring. There are several ways to select the best parent chromosomes, such as roulette wheel selection, rank-based selection, tournament selection, Boltzman selection, steady-state selection and others.
- 2.
- CrossoverThe crossover is an essential operator because the offspring would be the same as the parent without it. Crossover in a GA is usually applied with a high probability (). The simplest way to apply crossover is to randomly select a crossover point, which specifies the point for exchanging genes between parents to form new offspring. Such an operator is called a single-point crossover. For example, when the crossover point 2 is selected, all genes from index 3 onwards are exchanged between the two parents to form new offspring, as shown in Figure 5.The multi-point crossover operator is also popularly used. Here, gene exchange occurs at multiple points. It is noteworthy that these crossover operators are very generic, as the crossover can be quite complex and mostly depends on the chromosomes encoding. The architect might prefer to implement a problem-specific crossover operator to improve the GA performance.
- 3.
- MutationMutation is necessary for the convergence of the GA. It is described as a small random alteration in the chromosomes to acquire new solutions. Mutation is employed to maintain and incorporate diversity in the genetic population. In other words, mutation helps to escape local optimum solutions. Typically, mutation is implemented with a low probability (). There are many ways to apply mutation operators. For example, in binary encoding, bit-flip mutation is used, in which one or more random bits are randomly selected and flipped as illustrated in Figure 6.Just like the crossover, the technique to use for mutation depends on how the chromosomes were encoded. For instance, in ordering problems where permutation-based encodings are used, swap mutation could be performed in which two genes are randomly chosen, and their values are interchanged.
3. Methodology
3.1. Data Collection
3.2. Data Cleaning and Preprocessing
- Removing the unnecessary columns, titles, and text is all that is needed
- Concatenating title and text of news
- Removing punctuations such as
- Removing URLs and stop words
- Lowering the text
- Label true news as 1, and fake news as 0
- Lemmatization
- Tokenization
- Splitting the data into random train and test subsets
3.3. Feature Extraction
3.4. Hyperparameter Tuning Using GA
- : the batch size (2-bit) takes values ∈ [32, 64, 128, 196] (or 00, 01, 10, 11, respectively).
- : the LSTM units (2-bit) takes values ∈ [25, 50, 75, 100] (or 00, 01, 10, 11, respectively).
- : the number of dense layers (1-bit) which can be 0 (none) or 1 (1-layer).
- : the number of dense neurons (2-bit) takes values ∈ [25, 50, 75, 100] (or 00, 01, 10, 11, respectively).
- : the dropout probability (1-bit) which can be 0 () or 1 ().
- o: the optimizer (2-bit) takes values o∈ [SGD, Adam, AdaDelta, RMSProp] (or 00, 01, 10, 11, respectively).
- : the learning rate (2-bit) takes values ∈ [0.1, 0.01, 0.001, 0.0001] (or 00, 01, 10, 11, respectively).A Bernoulli distribution is used to generate a random initialization for the binary solution. Roulette wheel selection, single-point crossover, and adaptive mutation are also employed. The concept of adaptive mutation was first proposed in a paper titled “Adaptive Mutation in Genetic Algorithms” [26] as a solution to the problem of constant mutation. The flaw in traditional GAs is that mutations in all chromosomes, no matter how fit they are, are subject to the same randomness. As a result, a good chromosome is just as susceptible to mutation as a poor one.In a nutshell, adaptive mutation works as follows [27]:
- 1.
- Determine the population’s average fitness level ();
- 2.
- Calculate the fitness value (f) of each chromosome;
- 3.
- A solution is considered a low-quality solution if , and hence the mutation rate should be kept high in order to improve the solution’s quality;
- 4.
- A solution is considered a high-quality solution if . To ensure that this high-quality solution is not disrupted, the mutation rate should then be kept at a low level.
For the purpose of this research, if , then the solution is considered high quality. Table 1 summarizes the various hyperparameters used for the GA, along with their values.
4. Experiment Design
4.1. Experimental Setup
4.2. Model Evaluation Metrics
- 1.
- Accuracy: This metric expresses the overall correctness of the model:
- 2.
- Precision: This represents the model’s capability to correctly identify positive instances:
- 3.
- Recall: Also known as sensitivity, this measures the coverage of actual positive instances:
- 4.
- F1-score: This provides the harmonic mean of precision and recall, a useful metric when the classes are imbalanced:
- True positive (TP): The model correctly predicted fake news when the news was indeed fake.
- True negative (TN): The model correctly identified real news when the news was actually real.
- False positive (FP)—Type 1 error: The model inaccurately identified real news as fake.
- False negative (FN)—Type 2 error: The model inaccurately classified fake news as real.
5. Results
5.1. Model Evaluation
5.2. Comparative Performance Analysis
5.3. Performance Benchmarking and Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. TF-IDF
- 1.
- The term frequency of a word in a document, defined in various ways, including:
- Raw count of the number of times a word appears in a document.
- Frequency ratio of the total number of occurrences of a word to the total number of words in the document.
- Logarithmically scaled frequency, such as .
- 2.
- The inverse document frequency of the word across the entire corpus. This metric indicates the commonality or rarity of a word. A word is considered common if it is close to zero. IDF can be calculated using the logarithm of the total number of documents divided by the number of documents containing the word.
References
- Pierri, F.; Ceri, S. False news on social media: A data-driven survey. ACM Sigmod Rec. 2019, 48, 18–27. [Google Scholar] [CrossRef]
- Shu, K.; Bernard, H.R.; Liu, H. Studying fake news via network analysis: Detection and mitigation. In Emerging Research Challenges and Opportunities in Computational Social Network Analysis and Mining; Springer: Berlin/Heidelberg, Germany, 2019; pp. 43–65. [Google Scholar]
- Kumar, S.; Shah, N. False information on web and social media: A survey. arXiv 2018, arXiv:1804.08559. [Google Scholar]
- Feng, S.; Banerjee, R.; Choi, Y. Syntactic stylometry for deception detection. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Jeju, Republic of Korea, 8–14 July 2012; pp. 171–175. [Google Scholar]
- Conroy, N.K.; Rubin, V.L.; Chen, Y. Automatic deception detection: Methods for finding fake news. Proc. Assoc. Inf. Sci. Technol. 2015, 52, 1–4. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Bataineh, A.A.; Mairaj, A.; Kaur, D. Autoencoder based Semi-Supervised Anomaly Detection in Turbofan Engines. Int. J. Adv. Comput. Sci. Appl. 2020, 11. [Google Scholar] [CrossRef]
- Bataineh, A.S.A. A gradient boosting regression based approach for energy consumption prediction in buildings. Adv. Energy Res. 2019, 6, 91–101. [Google Scholar]
- Nasir, J.A.; Khan, O.S.; Varlamis, I. Fake news detection: A hybrid CNN-RNN based deep learning approach. Int. J. Inf. Manag. Data Insights 2021, 1, 100007. [Google Scholar] [CrossRef]
- Monti, F.; Frasca, F.; Eynard, D.; Mannion, D.; Bronstein, M.M. Fake news detection on social media using geometric deep learning. arXiv 2019, arXiv:1902.06673. [Google Scholar]
- Rodríguez, Á.I.; Iglesias, L.L. Fake news detection using Deep Learning. arXiv 2019, arXiv:1910.03496. [Google Scholar]
- Bajaj, S. The Pope Has a New Baby! Fake News Detection Using Deep Learning. 2017, pp. 1–8. Available online: https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1174/reports/2710385.pdf (accessed on 25 May 2023).
- Khan, J.Y.; Khondaker, M.; Islam, T.; Iqbal, A.; Afroz, S. A benchmark study on machine learning methods for fake news detection. arXiv 2019, arXiv:1905.04749. [Google Scholar]
- Yang, Y.; Zheng, L.; Zhang, J.; Cui, Q.; Li, Z.; Yu, P.S. TI-CNN: Convolutional neural networks for fake news detection. arXiv 2018, arXiv:1806.00749. [Google Scholar]
- Wani, A.; Joshi, I.; Khandve, S.; Wagh, V.; Joshi, R. Evaluating deep learning approaches for COVID-19 fake news detection. In Proceedings of the International Workshop on Combating Online Hostile Posts in Regional Languages during Emergency Situation, Virtual, 8 February 2021; Springer: Cham, Switzerland, 2021; pp. 153–163. [Google Scholar]
- Gundapu, S.; Mamidi, R. Transformer based Automatic COVID-19 Fake News Detection System. arXiv 2021, arXiv:2101.00180. [Google Scholar]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Al Bataineh, A.; Kaur, D. Immunocomputing-Based Approach for Optimizing the Topologies of LSTM Networks. IEEE Access 2021, 9, 78993–79004. [Google Scholar] [CrossRef]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Brownlee, J. (Ed.) Clever Algorithms: Nature-Inspired Programming Recipes. 2011. Available online: https://github.com/clever-algorithms/CleverAlgorithms (accessed on 25 May 2023).
- Ahmed, H.; Traore, I.; Saad, S. Detecting opinion spams and fake news using text classification. Secur. Priv. 2018, 1, e9. [Google Scholar] [CrossRef] [Green Version]
- Bronakowski, M.; Al-khassaweneh, M.; Al Bataineh, A. Automatic Detection of Clickbait Headlines Using Semantic Analysis and Machine Learning Techniques. Appl. Sci. 2023, 13, 2456. [Google Scholar] [CrossRef]
- Galván, E.; Mooney, P. Neuroevolution in deep neural networks: Current trends and future challenges. IEEE Trans. Artif. Intell. 2021, 2, 476–493. [Google Scholar] [CrossRef]
- Al Bataineh, A.; Kaur, D.; Al-khassaweneh, M.; Al-sharoa, E. Automated CNN Architectural Design: A Simple and Efficient Methodology for Computer Vision Tasks. Mathematics 2023, 11, 1141. [Google Scholar] [CrossRef]
- Libelli, S.M.; Alba, P. Adaptive mutation in genetic algorithms. Soft Comput. 2000, 4, 76–80. [Google Scholar] [CrossRef]
- Gad, A.F. PyGAD: An Intuitive Genetic Algorithm Python Library. 2021. Available online: http://xxx.lanl.gov/abs/2106.06158 (accessed on 25 May 2023).
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Bataineh, A.A. A comparative analysis of nonlinear machine learning algorithms for breast cancer detection. Int. J. Mach. Learn. Comput. 2019, 9, 248–254. [Google Scholar] [CrossRef]
- Al Bataineh, A.; Kaur, D.; Jalali, S.M.J. Multi-layer perceptron training optimization using nature inspired computing. IEEE Access 2022, 10, 36963–36977. [Google Scholar] [CrossRef]
- Al Bataineh, A.; Manacek, S. MLP-PSO hybrid algorithm for heart disease prediction. J. Pers. Med. 2022, 12, 1208. [Google Scholar] [CrossRef] [PubMed]
- Ozbay, F.A.; Alatas, B. Fake news detection within online social media using supervised artificial intelligence algorithms. Phys. A Stat. Mech. Its Appl. 2020, 540, 123174. [Google Scholar] [CrossRef]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake news detection using machine learning ensemble methods. Complexity 2020, 2020, 8885861. [Google Scholar] [CrossRef]
- Ahmed, H.; Traore, I.; Saad, S. Detection of online fake news using n-gram analysis and machine learning techniques. In Proceedings of the International Conference on Intelligent, Secure, and Dependable Systems in Distributed and Cloud Environments, Vancouver, BC, Canada, 26–28 October 2017; Springer: Cham, Switzerland, 2017; pp. 127–138. [Google Scholar]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef]
- Blackledge, C.; Atapour-Abarghouei, A. Transforming fake news: Robust generalisable news classification using transformers. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3960–3968. [Google Scholar]
- Salton, G. Introduction to Modern Information Retrieval; McGraw-Hill: New York, NY, USA, 1983. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Population size | 20 |
| Maximum number of generations | 100 |
| Number of Genes | 12 |
| Selection | Roulette wheel |
| Number of parents to select for mating | 2 |
| Crossover | Single-point |
| Adaptive Mutation | 0.2 (low), 0.6 (high) |
| Hyperparameter | Value |
|---|---|
| Batch Size | 64 |
| LSTM units | 25 |
| #Dense layers | 0 |
| #Dense Neurons | 0 |
| Dropout | 25% |
| Optimizer | Adam |
| Learning rate | 0.01 |
| Last dense layer activation function | Sigmoid |
| Loss function | Binary cross-entropy |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Bi-LSTM | 99.52% | 99.37% | 99.62% | 99.50% |
| Uni-LSTM | 98.89% | 98.69% | 98.97% | 98.83% |
| MLP | 94.85% | 95.80% | 94.21% | 95.00% |
| KNN | 90.56% | 90.91% | 90.91% | 90.91% |
| Extra Trees | 89.70% | 92.17% | 87.60% | 89.83% |
| Naïve Bayes | 80.69% | 85.19% | 76.03% | 80.35% |
| Gradient Boosting | 88.41% | 89.83% | 87.60% | 88.70% |
| Ada Boost | 88.41% | 92.73% | 84.30% | 88.31% |
| XGBoost | 94.85% | 95.80% | 94.21% | 95.00% |
| LDA | 90.99% | 92.37% | 90.08% | 91.21% |
| Passive Aggressive | 87.55% | 91.82% | 83.47% | 87.45% |
| Decision Tree [32] | – | – | – | 96.80% |
| Random Forest [33] | – | – | – | 99.00% |
| Hybrid CNN-RNN [9] | – | – | – | 99.00% |
| Linear SVM [34] | – | – | – | 92.00% |
| FakeBERT [35] | 98.90% | – | – | – |
| deBERTa [36] | 97.70% | 97.70% | 97.70% | 98.90% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Bataineh, A.; Reyes, V.; Olukanni, T.; Khalaf, M.; Vibho, A.; Pedyuk, R. Advanced Misinformation Detection: A Bi-LSTM Model Optimized by Genetic Algorithms. Electronics 2023, 12, 3250. https://doi.org/10.3390/electronics12153250
Al Bataineh A, Reyes V, Olukanni T, Khalaf M, Vibho A, Pedyuk R. Advanced Misinformation Detection: A Bi-LSTM Model Optimized by Genetic Algorithms. Electronics. 2023; 12(15):3250. https://doi.org/10.3390/electronics12153250
Chicago/Turabian StyleAl Bataineh, Ali, Valeria Reyes, Toluwani Olukanni, Majd Khalaf, Amrutaa Vibho, and Rodion Pedyuk. 2023. "Advanced Misinformation Detection: A Bi-LSTM Model Optimized by Genetic Algorithms" Electronics 12, no. 15: 3250. https://doi.org/10.3390/electronics12153250
APA StyleAl Bataineh, A., Reyes, V., Olukanni, T., Khalaf, M., Vibho, A., & Pedyuk, R. (2023). Advanced Misinformation Detection: A Bi-LSTM Model Optimized by Genetic Algorithms. Electronics, 12(15), 3250. https://doi.org/10.3390/electronics12153250