

Network Resource Allocation Algorithm Using Reinforcement Learning Policy-Based Network in a Smart Grid Scenario



Abstract
:1. Introduction
- We introduce edge computing into smart grids and transform the resource allocation of edge computing-assisted smart grids into a multi-domain VNE problem.
- We propose a VNE algorithm based on dual RL, which uses a self-constructed policy network in the node mapping phase and link mapping phase, and designs a reward function with multi-objective optimization to achieve resource allocation.
- Comparing the algorithm in this paper with three other VNE algorithms, it was found that this algorithm outperformed the other algorithms.
2. Related Works
2.1. Edge Computing Network
2.2. Multi-Domain Virtual Network
2.3. VNE Based AI
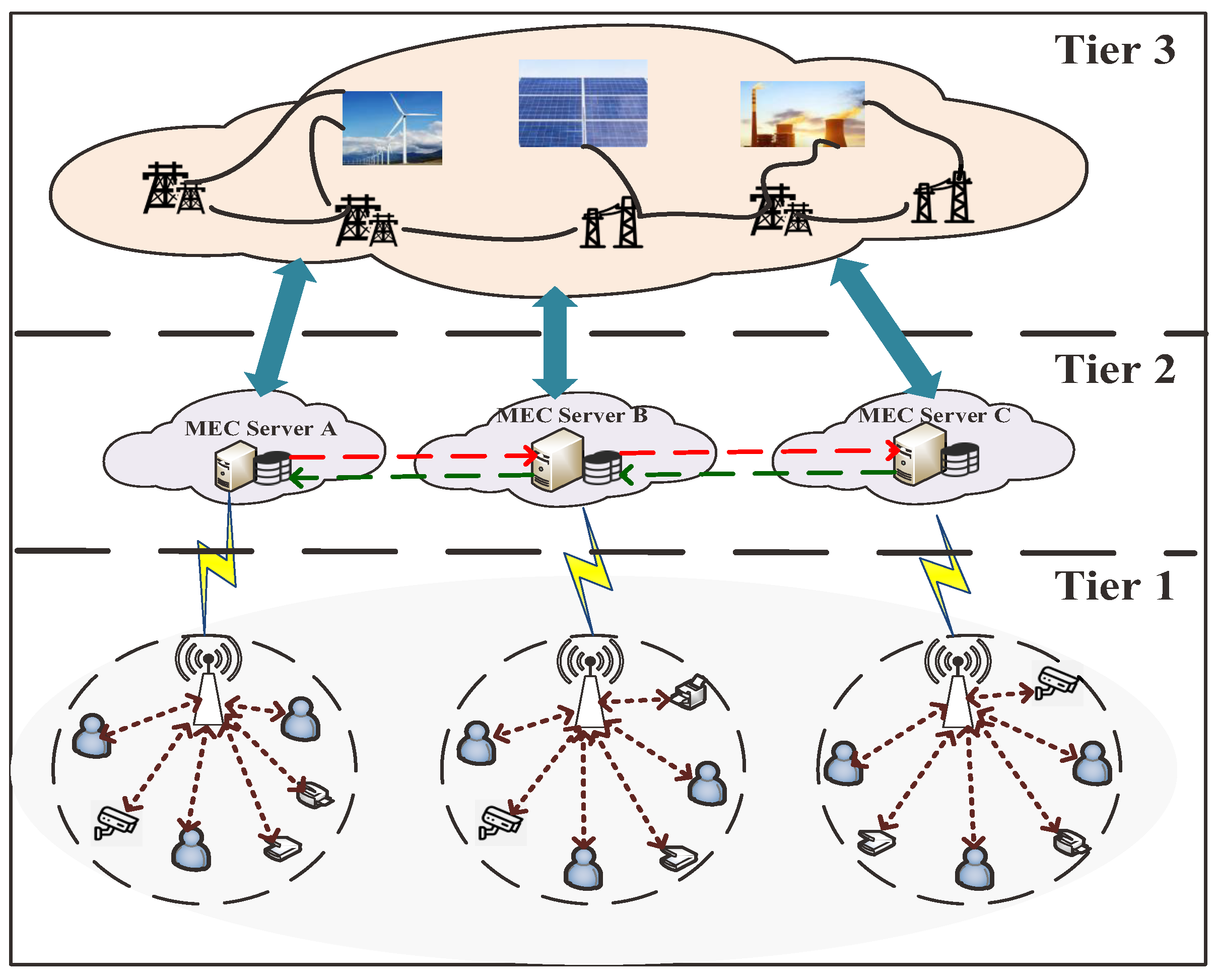
3. Network Structure and Problem Description
Network Models
- Computational capacity: If has been embedded on node , the computational capacity resource requirement of the virtual network node does not exceed the computational capacity resource of the physical node, which can be given by the following formula:In Formula (6), represents the computational capacity needed by the virtual node and represents the computing resource available from the physical node . The total computing resource requirements of all virtual nodes embedded in physical node should not exceed the computational capacity of .Due to the fact that the nodes are divided into three defined types and have signed functions , Formula (7) can be expressed as:
- Security level: When embedding a virtual node onto a physical node, it is essential to ensure that the security level of the physical node is equal to or greater than the level of security required for the virtual node. We can express this as:In Formula (9), the security level of , denoted as , must be higher than the security requirements of denoted as .
- Bandwidth: For the bandwidth, we can give similar constraints to those of computational capacity resources:In Formula (10), represents the bandwidth demand of . represents the bandwidth resources available for . The set of links that were able to successfully connect and integrate nodes we define as . For the physical link , the sum of the bandwidth resource requirements for virtual links embedded in must not exceed the available bandwidth resource of .Another way to express the total bandwidth is:
- Delay: If the link is successfully embedded, the delay constraint means that the delay of the link used for the VNR should not be less than the VNR’s required delay. This can be expressed as:
4. Algorithm
4.1. Algorithm Description
4.2. Node Mapping
4.2.1. Node Features
- Node Computing Resources (): the available CPU resources of .
- Adjacent Link Bandwidth (): the quantity of available link bandwidths connected to .
- Distance Correlation (): the average of distances from to mapped nodes.
- Time Correlation (): the average value of the quantity of the delays used from to all other nodes in the network.
- Node Security (): measures the security of deployable virtual nodes.
4.2.2. Node Policy Network
- Input layer: Obtain the physical node feature matrix of the physical network by reading Formula 15 in the current state.
- Convolution layer: Evaluate the resources of each physical node. In order to acquire the available resource vector of each physical node, this layer performs convolution calculation on the feature matrix of the input layer. Each output of a convolutional layer represents an available resource vector for a physical node. The specific calculation method of this layer is as follows:is a piecewise linear function, which is used as the activation function.
- Filtering layer: Refer to the resource vector obtained in the previous layer to judge whether the physical node is available. An unavailable physical node means that the remaining CPU resources of this physical node cannot support current virtual node mapping. The filtering layer filters out unavailable nodes and outputs the available resource vectors of all candidate physical nodes.
- Softmax layer: Normalize the available resource vectors of each physical node obtained by the filtering layer. The larger the value, the greater the benefits obtained when mapping the virtual node to the physical node.
- Output layer: Output the probability of each physical node being selected as a hosting node.
4.3. Link Mapping
4.3.1. Link Features
- Bandwidth (): The bandwidth value of the link with the smallest available bandwidth resources on the mapping path.
- Link importance (): The more shortest paths passed on the physical link, the more important the link is.represents the number of shortest paths passing through l and represents the number of all shortest paths passing through the network.
4.3.2. Link Policy Network
- Convolution layer: Perform the convolution operation on the link feature matrix obtained by the input layer, so as to evaluate the resource situation of the physical path.
- Softmax layer: The probability is calculated as follows:
- Filtering layer: When physical paths’ bandwidth resources do not meet the VNRs, we abandon such paths. And when the nodes at ends of the physical path are not mapped during mapping nodes, we abandon such paths.
- Output layer: Output the selected probability of each physical link.
4.4. Mapping Algorithm
| Algorithm 1: Training Node Mapping Model |
 |
| Algorithm 2: Training Link Mapping Model |
 |
5. Experimental Results and Analysis
5.1. Experimental Environment and Parameters
5.2. Comparison Algorithms
- •
- RLVNE [31]: RLVNE is an RL-based VNE algorithm. Specifically, the author constructs a four-layer policy network, uses the policy gradient algorithm to update the policy network parameters and selects the mapping nodes according to the node mapping probabilities output by the policy network.
- •
- •
- VNE-HPSO [37]: VNE-HPSO is a heuristic algorithm that combines a particle swarm optimization algorithm and a simulated annealing method.
5.3. Performance Metrics
- (1)
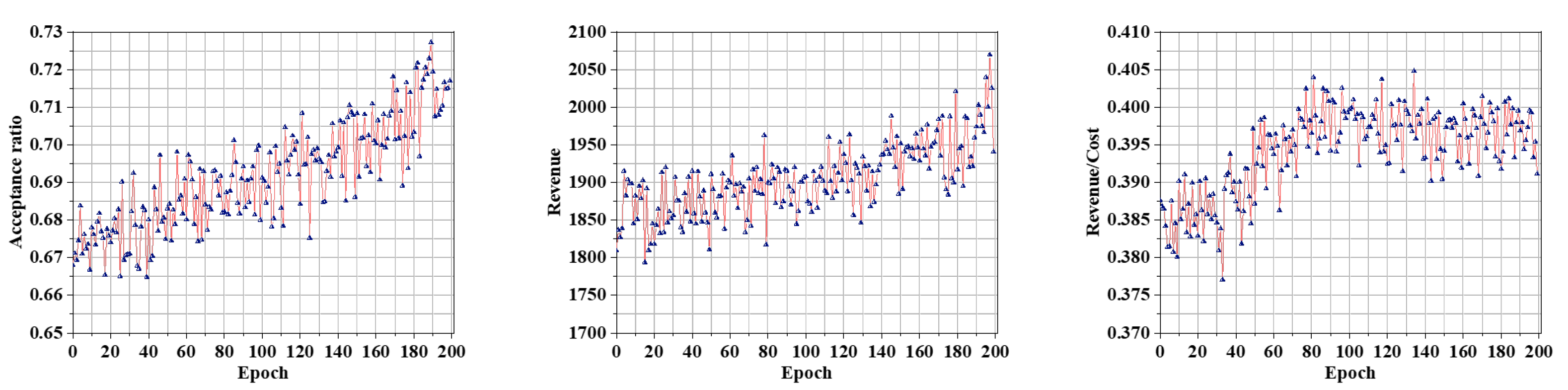
- Acceptance ratio
- (2)
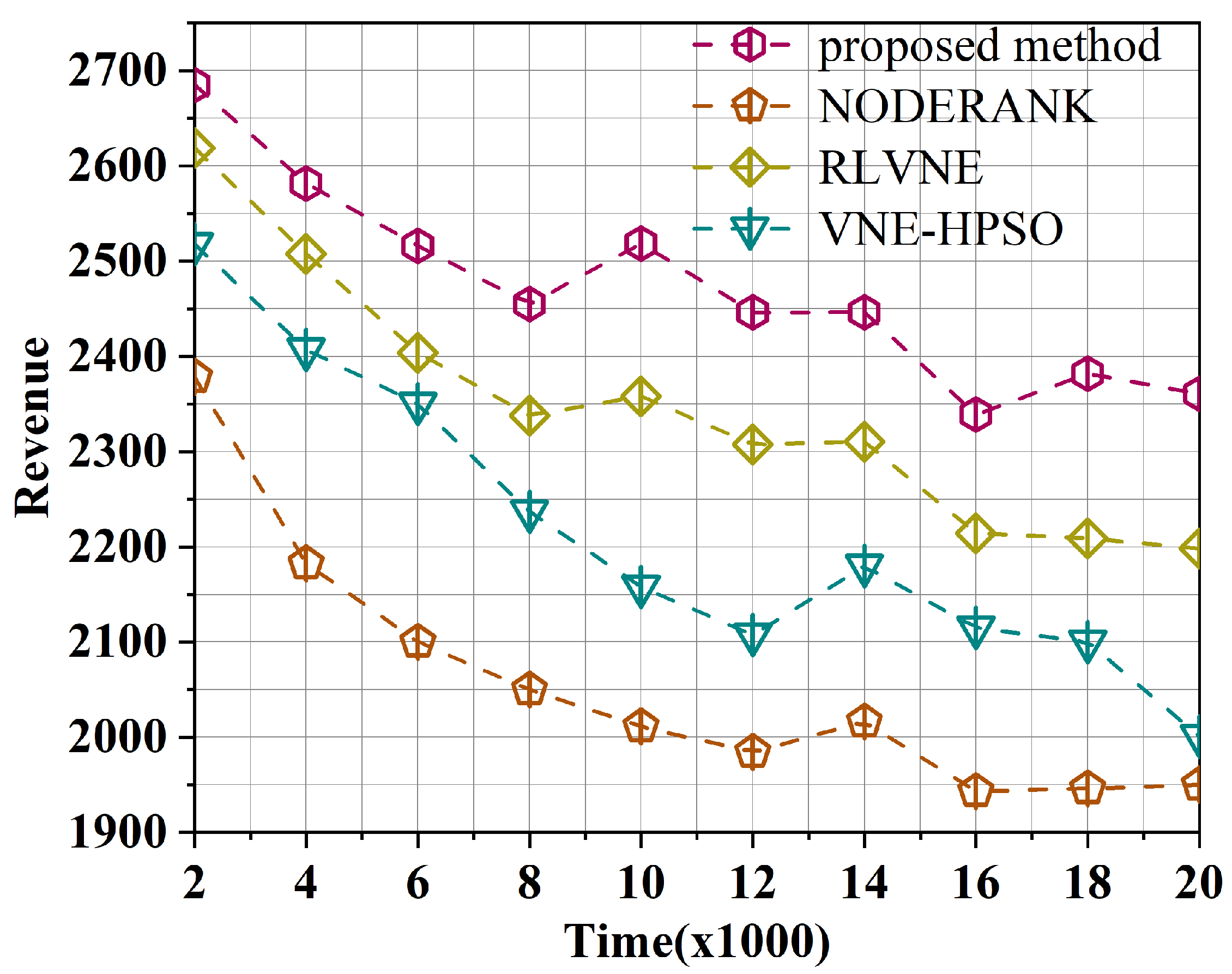
- Long-term average revenue
- (3)
- Long-term average revenue–cost ratio
- (4)
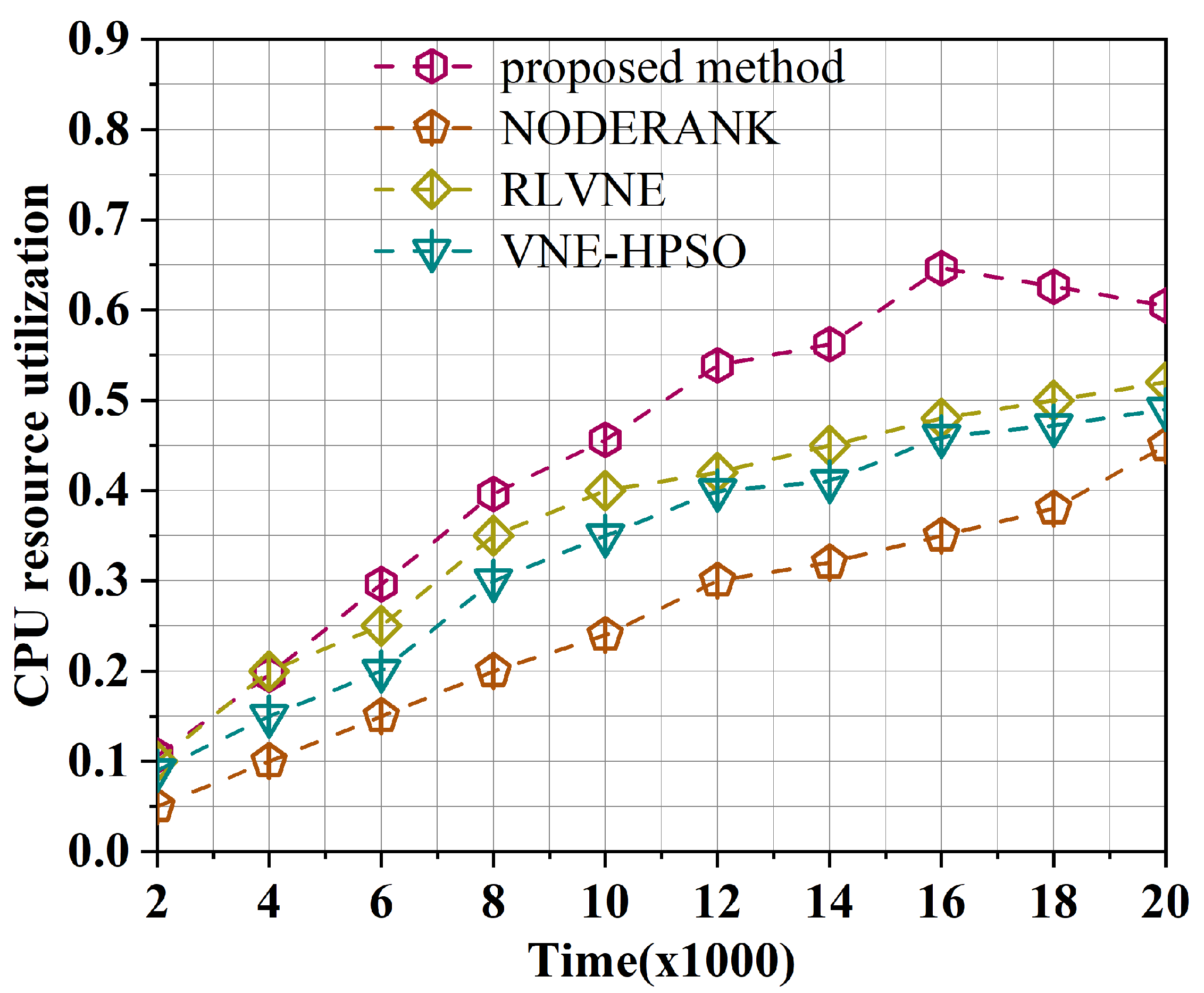
- CPU resource utilization
5.4. Experimental Results and Analyses
5.4.1. Training Results
5.4.2. Comparative Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mapping Stage | Resource Name |
|---|---|
| Node Mapping | Physical nodes |
| CPU resources | |
| Link Mapping | Physical links |
| Bandwidth resources |
References
- Islam, S.; Zografopoulos, I.; Hossain, M.T.; Badsha, S.; Konstantinou, C. A Resource Allocation Scheme for Energy Demand Management in 6G-enabled Smart Grid. In Proceedings of the 2023 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 16–19 January 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Fang, X.; Misra, S.; Xue, G.; Yang, D. Smart grid—The new and improved power grid: A survey. IEEE Commun. Surv. Tutor. 2011, 14, 944–980. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, Z.; Li, D.; Su, Z. Joint Optimization of Computing Offloading and Service Caching in Edge Computing-Based Smart Grid. IEEE Trans. Cloud Comput. 2023, 11, 1122–1132. [Google Scholar] [CrossRef]
- Ma, R.; Yi, Z.; Xiang, Y.; Shi, D.; Xu, C.; Wu, H. A Blockchain-Enabled Demand Management and Control Framework Driven by Deep Reinforcement Learning. IEEE Trans. Ind. Electron. 2023, 70, 430–440. [Google Scholar] [CrossRef]
- Yang, C.; Chen, X.; Liu, Y.; Zhong, W.; Xie, S. Efficient task offloading and resource allocation for edge computing-based smart grid networks. In Proceedings of the ICC 2019–2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar]
- Yang, X.; Yu, X.; Hou, H.; Tan, Z.; Wu, F. Smart grid edge fault detection architecture. In Proceedings of the 2023 IEEE 6th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 24–26 February 2023; Volume 6, pp. 692–700. [Google Scholar] [CrossRef]
- Liao, Y.; He, J. Optimal Smart Grid Operation and Control Enhancement by Edge Computing. In Proceedings of the 2020 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Tempe, AZ, USA, 11–13 November 2020; pp. 1–6. [Google Scholar]
- Liu, R.; Yang, R.; Wang, Z.; Sun, X. Application of Edge Computing in Smart Grid. In Proceedings of the 2022 3rd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Xi’an, China, 15–17 July 2022; pp. 62–65. [Google Scholar]
- Xiao, Y.; Jia, Y.; Liu, C.; Cheng, X.; Yu, J.; Lv, W. Edge computing security: State of the art and challenges. Proc. IEEE 2019, 107, 1608–1631. [Google Scholar] [CrossRef]
- Aloul, F.; Al-Ali, A.; Al-Dalky, R.; Al-Mardini, M.; El-Hajj, W. Smart grid security: Threats, vulnerabilities and solutions. Int. J. Smart Grid Clean Energy 2012, 1, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Bhamare, D.; Jain, R.; Samaka, M.; Erbad, A. A survey on service function chaining. J. Netw. Comput. Appl. 2016, 75, 138–155. [Google Scholar] [CrossRef]
- Huang, L.H.; Hsu, H.C.; Shen, S.H.; Yang, D.N.; Chen, W.T. Multicast traffic engineering for software-defined networks. In Proceedings of the IEEE INFOCOM 2016-The 35th Annual IEEE International Conference on Computer Communications, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]
- Wang, C.; Dong, T.; Duan, Y.; Sun, Q.; Zhang, P. Multi objective resource optimization of wireless network based on cross domain virtual network embedding. In Proceedings of the 2020 IEEE Computing, Communications and IoT Applications (ComComAp), Beijing, China, 20–22 December 2020; pp. 1–6. [Google Scholar]
- Zhang, P.; Wang, C.; Qin, Z.; Cao, H. A multi-domain VNE algorithm based on multi-objective optimization for IoD architecture in Industry 4.0. arXiv 2022, arXiv:2202.12830. [Google Scholar]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Ayoub, A.; Jia, Z.; Szepesvari, C.; Wang, M.; Yang, L. Model-based reinforcement learning with value-targeted regression. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 463–474. [Google Scholar]
- Chen, N.; Zhang, P.; Kumar, N.; Hsu, C.H.; Abualigah, L.; Zhu, H. Spectral graph theory-based virtual network embedding for vehicular fog computing: A deep reinforcement learning architecture. Knowl.-Based Syst. 2022, 257, 109931. [Google Scholar]
- Ren, J.; Guo, Y.; Zhang, D.; Liu, Q.; Zhang, Y. Distributed and efficient object detection in edge computing: Challenges and solutions. IEEE Netw. 2018, 32, 137–143. [Google Scholar] [CrossRef]
- Li, L.; Ota, K.; Dong, M. Deep learning for smart industry: Efficient manufacture inspection system with fog computing. IEEE Trans. Ind. Inform. 2018, 14, 4665–4673. [Google Scholar] [CrossRef] [Green Version]
- Deng, X.; Guan, P.; Wan, Z.; Liu, E.; Luo, J.; Zhao, Z.; Liu, Y.; Zhang, H. Integrated trust based resource cooperation in edge computing. J. Comput. Res. Dev. 2018, 55, 449–477. [Google Scholar]
- Dolui, K.; Datta, S.K. Comparison of edge computing implementations: Fog computing, cloudlet and mobile edge computing. In Proceedings of the 2017 Global Internet of Things Summit (GIoTS), Geneva, Switzerland, 6–9 June 2017; pp. 1–6. [Google Scholar]
- Lin, H.; Chen, Z.; Wang, L. Offloading for edge computing in low power wide area networks with energy harvesting. IEEE Access 2019, 7, 78919–78929. [Google Scholar] [CrossRef]
- Su, X.; Sperlì, G.; Moscato, V.; Picariello, A.; Esposito, C.; Choi, C. An edge intelligence empowered recommender system enabling cultural heritage applications. IEEE Trans. Ind. Inform. 2019, 15, 4266–4275. [Google Scholar] [CrossRef]
- Wang, X.; Han, Y.; Leung, V.C.; Niyato, D.; Yan, X.; Chen, X. Convergence of edge computing and deep learning: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef] [Green Version]
- Tan, K.; Wang, X.; Du, P. Research progress of the remote sensing classification combining deep learning and semi-supervised learning. J. Image Graph. 2019, 24, 1823–1841. [Google Scholar]
- Wang, F.; Wen, H.; Cheng, S. Privacy data protection method for mobile intelligent terminal based on edge computing. Cyberspace Secur. 2018, 9, 47–50. [Google Scholar]
- Deng, R.; Lu, R.; Lai, C.; Luan, T.H.; Liang, H. Optimal workload allocation in fog-cloud computing toward balanced delay and power consumption. IEEE Internet Things J. 2016, 3, 1171–1181. [Google Scholar] [CrossRef]
- Chowdhury, N.M.K.; Rahman, M.R.; Boutaba, R. Virtual network embedding with coordinated node and link mapping. In Proceedings of the IEEE INFOCOM 2009, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 783–791. [Google Scholar]
- Dietrich, D.; Rizk, A.; Papadimitriou, P. Multi-domain virtual network embedding with limited information disclosure. In Proceedings of the 2013 IFIP Networking Conference, Brooklyn, NY, USA, 22–24 May 2013; pp. 1–9. [Google Scholar]
- Yao, H.; Chen, X.; Li, M.; Zhang, P.; Wang, L. A novel reinforcement learning algorithm for virtual network embedding. Neurocomputing 2018, 284, 1–9. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, C.; Kumar, N.; Zhang, W.; Liu, L. Dynamic virtual network embedding algorithm based on graph convolution neural network and reinforcement learning. IEEE Internet Things J. 2021, 9, 9389–9398. [Google Scholar] [CrossRef]
- Zhang, P.; Gan, P.; Kumar, N.; Hsu, C.H.; Shen, S.; Li, S. RKD-VNE: Virtual network embedding algorithm assisted by resource knowledge description and deep reinforcement learning in IIoT scenario. Future Gener. Comput. Syst. 2022, 135, 426–437. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, Y.; Kumar, N.; Hsu, C.H. Deep reinforcement learning algorithm for latency-oriented iiot resource orchestration. IEEE Internet Things J. 2022, 10, 7153–7163. [Google Scholar]
- Cheng, X.; Su, S.; Zhang, Z.; Wang, H.; Yang, F.; Luo, Y.; Wang, J. Virtual network embedding through topology-aware node ranking. ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 38–47. [Google Scholar]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- Zhang, P.; Hong, Y.; Pang, X.; Jiang, C. VNE-HPSO: Virtual network embedding algorithm based on hybrid particle swarm optimization. IEEE Access 2020, 8, 213389–213400. [Google Scholar] [CrossRef]





| Notation | Definition |
|---|---|
| Physical networks of smart grid | |
| Physical nodes set of smart grid | |
| Physical links set of smart grid | |
| Physical network resource attribute of smart grid | |
| Computational capability of nodes in smart grid | |
| Security level of nodes in smart grid | |
| Bandwidth of links in smart grid | |
| Delay of links in smart grid | |
| VNR | |
| Set of virtual nodes in VNR | |
| Set of virtual links in VNR | |
| Resource requirement in VNR | |
| Computational capacity needed by the virtual nodes | |
| Security level requirements for virtual nodes | |
| Bandwidth requirements for the virtual links | |
| Delay of the virtual links |
| Network | Parameter | Value |
|---|---|---|
| Physical nodes | 100 | |
| Physical links | 550 | |
| CPU resources capacity | ||
| Physical Network | Security level | |
| Bandwidth resource capacity | ||
| Delay of link | ||
| Number of VNRs | 2000 | |
| Training set | 1000 | |
| Testing set | 1000 | |
| Virtual nodes | ||
| VNRs | Node connection probability | 0.5 |
| CPU resource requirement | ||
| Bandwidth resource requirement | ||
| Delay requirement of link | ||
| Safety requirement level |
| Learning Rate | Acceptance Ratio | Revenue | Revenue/Cost |
|---|---|---|---|
| 0.001 | 0.625 | 1600 | 0.315 |
| 0.005 | 0.725 | 2050 | 0.405 |
| 0.01 | 0.450 | 1425 | 0.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Z.; Han, Y.; Chi, Y.; Yuan, F.; Cui, W.; Zhu, H.; Zhang, Y.; Zhang, P. Network Resource Allocation Algorithm Using Reinforcement Learning Policy-Based Network in a Smart Grid Scenario. Electronics 2023, 12, 3330. https://doi.org/10.3390/electronics12153330
Zheng Z, Han Y, Chi Y, Yuan F, Cui W, Zhu H, Zhang Y, Zhang P. Network Resource Allocation Algorithm Using Reinforcement Learning Policy-Based Network in a Smart Grid Scenario. Electronics. 2023; 12(15):3330. https://doi.org/10.3390/electronics12153330
Chicago/Turabian StyleZheng, Zhe, Yu Han, Yingying Chi, Fusheng Yuan, Wenpeng Cui, Hailong Zhu, Yi Zhang, and Peiying Zhang. 2023. "Network Resource Allocation Algorithm Using Reinforcement Learning Policy-Based Network in a Smart Grid Scenario" Electronics 12, no. 15: 3330. https://doi.org/10.3390/electronics12153330
APA StyleZheng, Z., Han, Y., Chi, Y., Yuan, F., Cui, W., Zhu, H., Zhang, Y., & Zhang, P. (2023). Network Resource Allocation Algorithm Using Reinforcement Learning Policy-Based Network in a Smart Grid Scenario. Electronics, 12(15), 3330. https://doi.org/10.3390/electronics12153330