1. Introduction
Smart grids are based on high-speed communication networks, advanced sensing devices and algorithms which are used to realize low delay, high quality of service, high flexibility, security, and green, reliable and intelligent application of power systems [
1]. Among them, calculation determines the execution method of smart grid data analysis and is the basis of smart grid services; the data volume of smart grids is also growing rapidly [
2,
3,
4]. Edge computing is one of the best ways to solve the power grid data explosion problem and smart power grids are considered as one of the best landing sites for edge computing [
5]. Edge computing pushes some computing applications from the center to the edge of the communications network. Unload technology is used to unload part of the computing logic to the edge of the network near the device and the client to perform the real-time data analysis task, and it can meet the demand of large bandwidth, reduce processing load on computing centers, and enhance the scalability and availability of the system [
6]. Edge computing has been integrated with smart grids through chip and communication technology, empowering them with ample computing prowess and enabling short-range, low-delay information transfer [
7]. This integration has established a foundation for intelligent production, transmission, distribution and electricity, and simple applications have already been achieved [
8,
9].
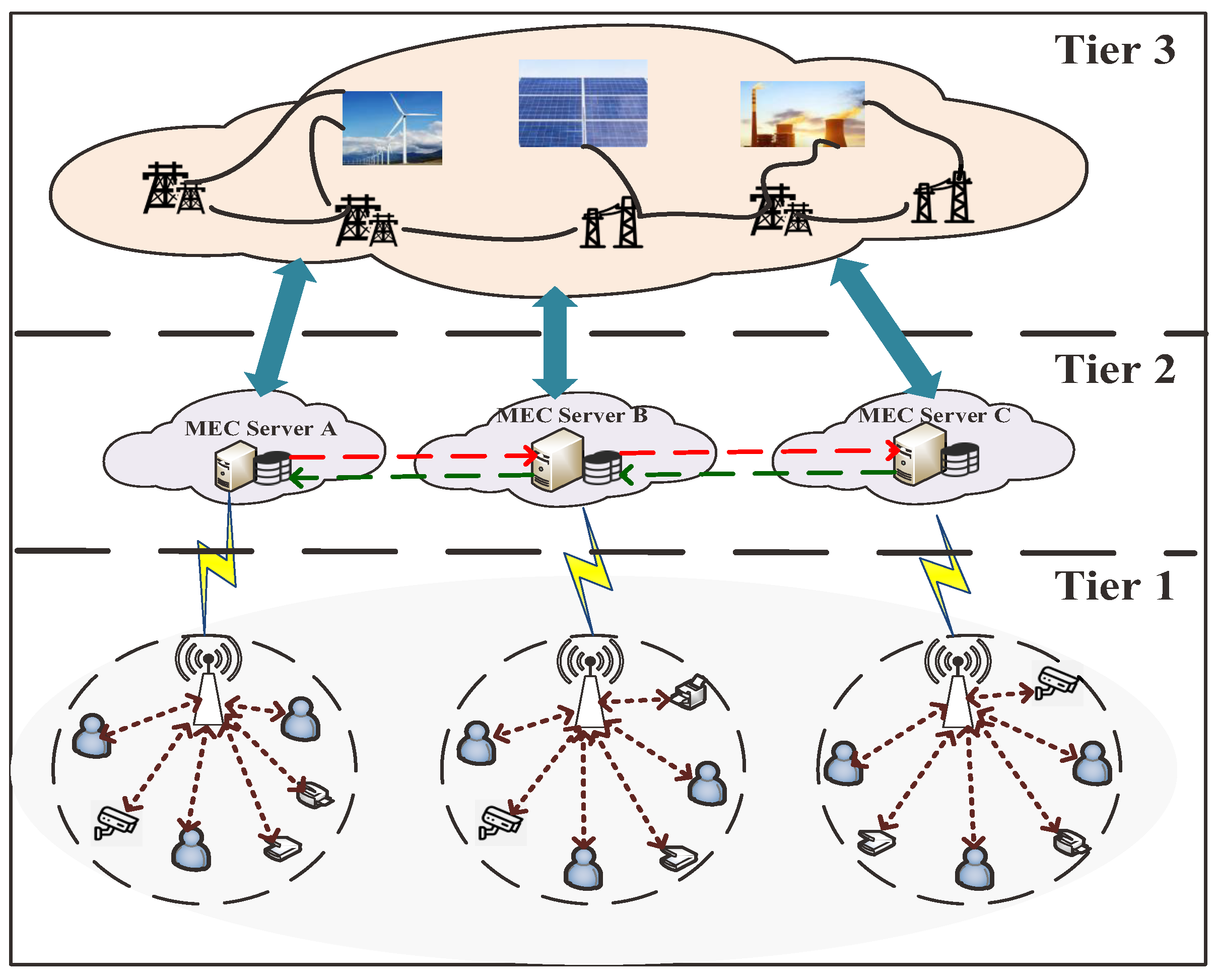
Figure 1 shows the scenario graph of an edge computing assisted smart grid.
However, as a new computing mode, edge computing still has some problems, such as lack of unified programming model, dynamic scheduling method and security standards. Even though edge computing has a great advantage in application, there are also application bottlenecks [
10]. Firstly, the high geographic distribution and heterogeneous characteristics of power grid equipment make it difficult to determine uniform standards and interfaces. Secondly, because the smart grid processes so much data per second, it can lead to the offloading of large-scale computing tasks. In addition, research on the edge computing security of smart grids is still in the initial stage, and some achievements have been attained but a complete research system has not been formed [
11].
In a virtual network environment, the infrastructure provider (INP) controls the physical network’s resources, while the service provider (SP) rents INP resources to construct a virtual network (VN) [
12]. VN technology makes it possible to generate several VNs on the same physical network or to connect different physical networks to form a multi-domain virtual network [
13]. These VNs can be deployed and managed independently without interfering with each other. Based on a grid-oriented edge computing network background, the bottom network nodes are divided into smart terminal data receiving points, sensor data receiving points and transformer data acquisition points. For the convenience of modeling and simulation, network resources are described as node and link resources [
14]. The multi-domain scene of edge computing networks is divided into two problems: VN partition and virtual subnetwork mapping. A virtual subnet is a part of the VN that can be solved using a single-domain mapping algorithm. The multi-domain virtual network mapping algorithm focuses on VN partitioning between multiple domains [
15].
As a branch of machine learning, RL aims to maximize the reward signal to optimize the updating algorithm [
16]. The RL agent explores continuously in the environment to obtain information, first chooses the corresponding action in a certain state, then interacts with the environment to get the reward of this state; finally, according to the reward, it constantly adjusts its own strategy. RL is generally used to solve strategy optimization problems, including strategy, reward, value function and environmental model [
17]. The four elements are as follows. (1) A policy represents a mapping from a given state to the actions taken in that state. (2) Reward is used to judge the behavior of the RL agent. (3) The value function represents the expectation of a cumulative discount reward. (4) The environment model is the key of RL: the agent acquires the state and takes the action in the environment, thus realizing the interaction with the environment; at the same time, the environment will feed back the corresponding reward signal according to the action that the agent takes. In addition to these four factors, an agent’s choice of actions at a given moment can affect not only the reward value at that moment but also its future performance.
The balance between the exploration and utilization of agents remains unresolved. Exploration is the hope that agents try different action choices on the basis of the existing strategies, so as to fully traverse the action space. Utilization is to expect the agent to learn the corresponding strategy on the basis of quickly grasping the existing experience. It can effectively save computing resources and ensure the stability of the algorithm. Exploration can prevent the strategy from falling into a local optimum but it also leads to a slow convergence rate of the algorithms [
18]. Therefore, how to improve the agent’s exploring ability is a problem worth discussing and studying. In this paper, we improve the existing policy network model from the point of view of policy network optimization, with low cost, high bandwidth and low delay as the goals of optimization for multi-objective allocation of edge computing network resources.
In the face of limited network resources, it is necessary to reasonably manage and allocate resources in the smart grid to improve the utilization of network resources to meet the needs of different application scenarios. Therefore, in this paper, we study the problem of resource management and scheduling to improve the utilization of network resources in smart grids. Specifically, we transform the resource management problem into a virtual network embedding (VNE) problem and then propose an RL-based VNE algorithm. The resources involved in the VNE process to be allocated are shown in
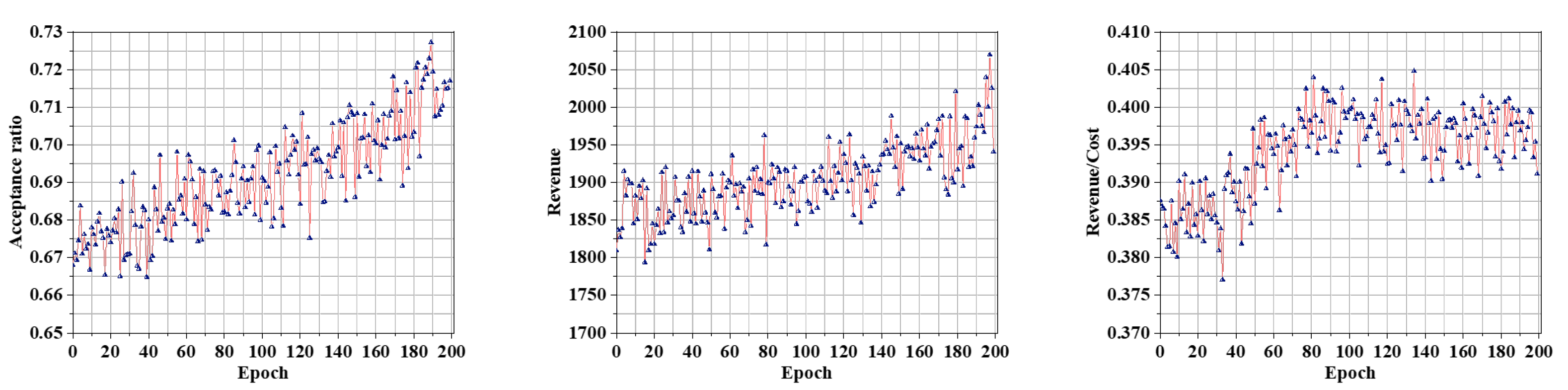
Table A1. Simulation results show that the algorithm significantly improved resource utilization in edge computation networks, reduced task processing delays and reduced costs. The major contributions of this article are as follows:
We introduce edge computing into smart grids and transform the resource allocation of edge computing-assisted smart grids into a multi-domain VNE problem.
We propose a VNE algorithm based on dual RL, which uses a self-constructed policy network in the node mapping phase and link mapping phase, and designs a reward function with multi-objective optimization to achieve resource allocation.
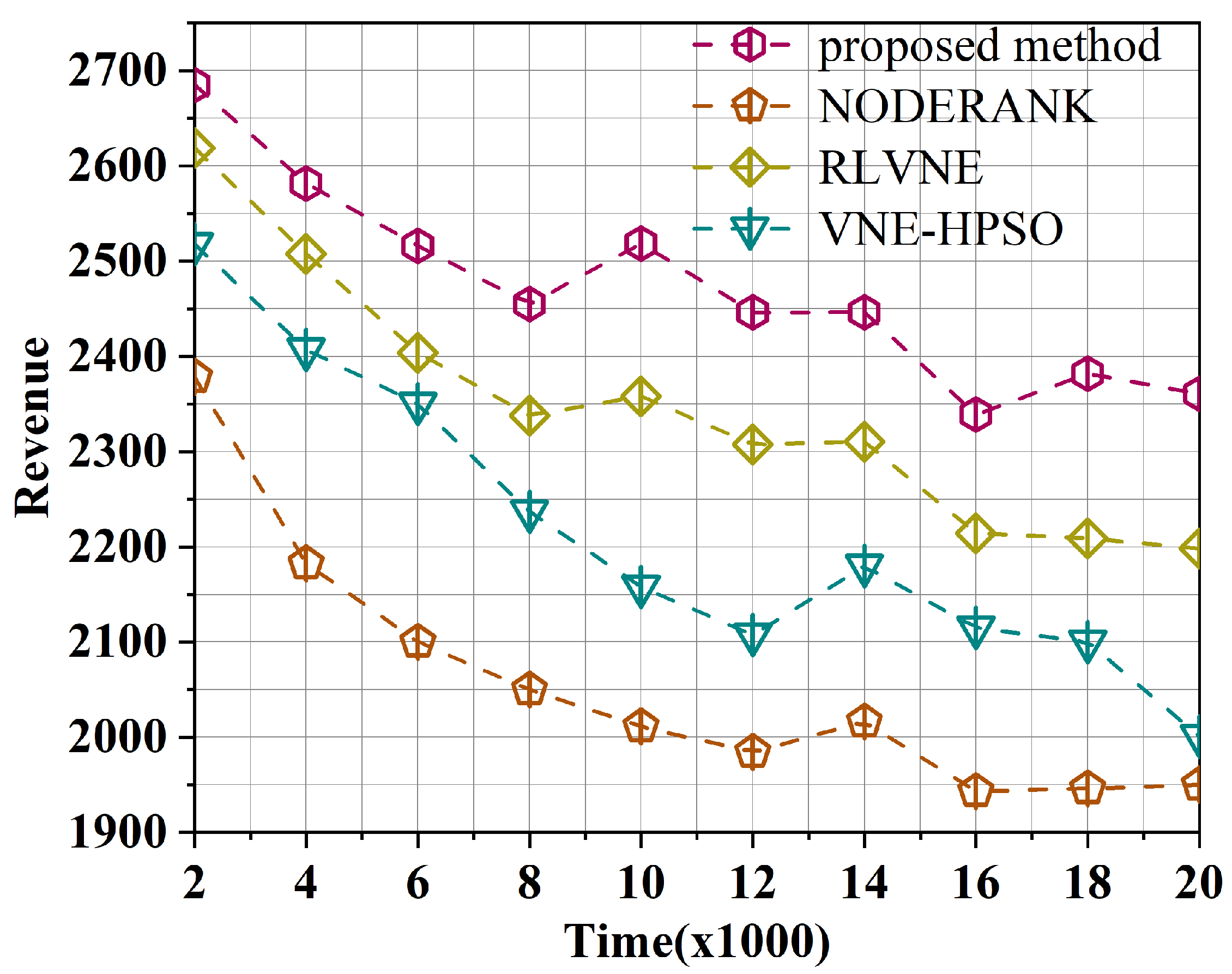
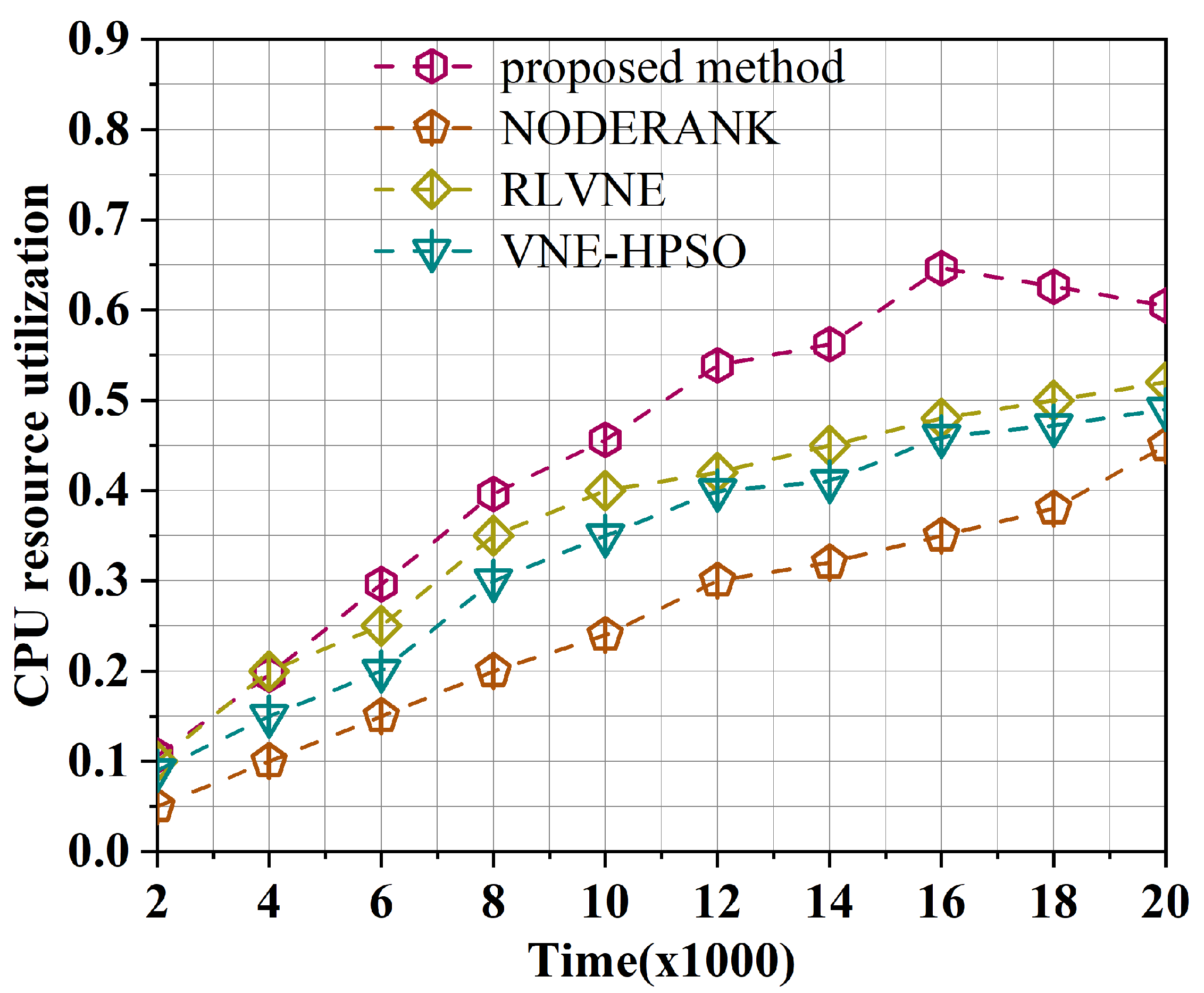
Comparing the algorithm in this paper with three other VNE algorithms, it was found that this algorithm outperformed the other algorithms.
The remainder of this paper is organized as follows. We review related work on edge computing, multi-domain virtual networks and VNE algorithms in
Section 2, and discuss network system models and related concepts in
Section 3. In
Section 4, we explain our proposed method in detail. Performance evaluation results and conclusion are described in
Section 5 and
Section 6, respectively.
4. Algorithm
4.1. Algorithm Description
For the multi-objective allocation of network resources in edge computing networks, we propose a policy network-based RL intelligent resource allocation algorithm. The algorithm mainly consists of two main components: security-based node mapping and security-based link mapping.
4.2. Node Mapping
During the virtual node mapping phase, the physical node with the greatest possibility of being selected can be the mapping solution for the virtual node. In order to obtain the selected probability of physical nodes, extracting the state features of the physical nodes in the current state can be necessary; then, obtain the state matrix and put the state matrix into the trained node mapping policy network to output the selected probability of the physical nodes.
4.2.1. Node Features
In order to describe the node status more accurately and describe the current physical network status more accurately, this paper extracts node-related features. The main extracted features include Node Computing Resources, Adjacent Link Bandwidth, Distance Correlation, Time Correlation and Node Security; this paper also connects all the features of a single node into a feature vector, and the feature vectors of nodes are combined into a node feature state matrix that represents the physical network state.
Node Computing Resources (): the available CPU resources of .
Adjacent Link Bandwidth (): the quantity of available link bandwidths connected to .
Distance Correlation (): the average of distances from to mapped nodes.
Time Correlation (): the average value of the quantity of the delays used from to all other nodes in the network.
Node Security (): measures the security of deployable virtual nodes.
After extracting the features of all the physical nodes, their values are adjusted to be between 0 and 1 by the min–max normalization method:
So, the eigenvector of the
k-th physical node can be represented by
:
Take the eigenvectors of each physical node as a row to construct the node eigenstate matrix.
4.2.2. Node Policy Network
Due to the continuous assignment of the state space of the VNE problem, this paper uses a policy-based approach for RL. Policy-based methods are usually combined with deep learning to evolve into policy network-based methods. The most important step in the process of node mapping is to calculate the probability of all possible choices through the current state of the physical network. This step can be achieved through a policy network. When mapping available virtual nodes, the policy network is used to find the best physical node to host virtual nodes. The node strategy network constructed in this paper includes input layer, convolution layer, softmax layer, filter layer and output layer.
Input layer: Obtain the physical node feature matrix of the physical network by reading Formula 15 in the current state.
Convolution layer: Evaluate the resources of each physical node. In order to acquire the available resource vector of each physical node, this layer performs convolution calculation on the feature matrix of the input layer. Each output of a convolutional layer represents an available resource vector for a physical node. The specific calculation method of this layer is as follows:
is a piecewise linear function, which is used as the activation function.
Filtering layer: Refer to the resource vector obtained in the previous layer to judge whether the physical node is available. An unavailable physical node means that the remaining CPU resources of this physical node cannot support current virtual node mapping. The filtering layer filters out unavailable nodes and outputs the available resource vectors of all candidate physical nodes.
Softmax layer: Normalize the available resource vectors of each physical node obtained by the filtering layer. The larger the value, the greater the benefits obtained when mapping the virtual node to the physical node.
Output layer: Output the probability of each physical node being selected as a hosting node.
Reward function: The agent learns about the working state of the model through rewards. The reward function is fed back to the agent, so that the agent understands whether the current action is correct or wrong, and the agent performs self-regulation according to the reward function. In this paper, we use the weights method (
,
) to face different QoS requirements and the reward function is defined as:
represents the delay of
, defined as
where
represents the set of physical links mapped by
and
represents the delay of
. When
mapping is successful, revenue and cost are mainly related to the amount of resources required by
, and can be defined as Formulas (
22) and (
23), respectively. Among them,
and
, respectively, represent the amount of CPU resources required by
and the amount of bandwidth resources required by
;
represents the duration of
;
represents the number of hops of the virtual link.
4.3. Link Mapping
When mapping a virtual link, checking whether the physical link has sufficient resources is necessary. In this paper, link mapping also introduces RL. Actions are output according to the current physical network state matrix.
4.3.1. Link Features
During this phase, a virtual link may correspond to multiple paths of a physical link, so the features extracted by link mapping should be the features of the connectable paths between the two physical nodes in the physical network. This paper uses bandwidth and link importance as features.
Bandwidth (): The bandwidth value of the link with the smallest available bandwidth resources on the mapping path.
Link importance (
): The more shortest paths passed on the physical link, the more important the link is.
represents the number of shortest paths passing through l and represents the number of all shortest paths passing through the network.
These physical path features are normalized to form a feature vector.
The eigenvectors of all physical links form the state matrix of the link.
4.3.2. Link Policy Network
We take the link state matrix as input and the probability of the physical path being chosen as output. The policy network is divided into five layers like the node mapping stage.
Convolution layer: Perform the convolution operation on the link feature matrix obtained by the input layer, so as to evaluate the resource situation of the physical path.
Softmax layer: The probability is calculated as follows:
Filtering layer: When physical paths’ bandwidth resources do not meet the VNRs, we abandon such paths. And when the nodes at ends of the physical path are not mapped during mapping nodes, we abandon such paths.
Output layer: Output the selected probability of each physical link.
4.4. Mapping Algorithm
In this paper, policy gradients are used to train the node mapping policy network. As the initial parameters are randomly given, which may not lead to a good policy, we introduce the minibatch gradient descent to dynamically update parameters. The update of parameters is implemented in batches; we update the policy parameters when reaching the iteration threshold . We adjust the gradient and the calculation speed of the training by introducing the learning rate . A gradient that is too small will make it difficult for the model to converge and one that is too large will cause an unstable model.
The flowchart of node mapping model training is shown in
Figure 2. We randomly set all the node policy network parameters and then select the most suitable physical node for virtual nodes in the VNR. We obtain the node feature matrix by extracting features on all physical nodes and normalize the matrix, and use the normalized results as the input of the node mapping policy network.
After that, the probabilities of a set of candidate nodes are obtained. When selecting the physical nodes to be mapped, we choose the node with the highest probability from the candidate nodes. Current physical network resources are updated each time a virtual node is mapped. After all nodes in the VNR are successfully mapped, we map links using the shortest path algorithm. The reward function and gradient at this time are calculated after successfully mapping the link. The policy network parameters are updated in batches and the above process is repeated until the optimal node mapping policy network parameters are obtained when the VNR reaches the threshold. Algorithm 1 gives the pseudocode for the training of the node mapping model.
| Algorithm 1: Training Node Mapping Model |
![Electronics 12 03330 i001]() |
Figure 3 shows the training flowchart of the link map model. The parameters in the policy network are randomly initialized above all while training the link model and, when processing the VNR, the node mapping plan is obtained by utilizing the trained node mapping policy network. Then, the link features of the physical network are extracted to obtain the link state matrix. The probability of physical path candidates is obtained by putting the state matrix into the link policy network. According to the probability distribution, the highest probability path is selected as the physical path for this mapping. Then, each time a virtual node is mapped, the current physical network resources are updated. Repeat the above steps until all the virtual links of the current VNR are mapped. If no physical link is available, the mapping fails and the next VNR is mapped.
To adjust the training direction and obtain a better solution, we use the reward function as the feedback of the mapping policy network. The policy network parameters are updated in batches and the above process is repeated until the optimal link mapping policy network parameters are obtained when the VNR reaches the threshold.
When virtual node mapping is applied, the current node state matrix is sent to the trained node policy network. Obtain the selection probability of the available physical nodes. Then, take the highest probability physical node as the mapping of the current virtual node. After all nodes of the VNR are mapped, the link state matrix is sent to the trained link policy network. The selection probability of available physical links is obtained and the highest probability physical link is taken as the mapping of the current virtual link. When the nodes and links of VNR are mapped successfully, the output is that VNR mapping is successful; otherwise, output that VNR mapping is failing. The training process of the link mapping model is shown in Algorithm 2.
| Algorithm 2: Training Link Mapping Model |
![Electronics 12 03330 i002]() |
6. Conclusions
This paper introduces edge computing into the smart grid, transforms resource allocation into a multi-domain virtual network embedding problem to improve the utilization of network resources and proposes a virtual network embedding algorithm based on double reinforcement learning. Unlike previous reinforcement learning-based studies, we simultaneously optimize node mapping and link mapping using reinforcement learning. Specifically, we extract the features of nodes and links, construct a policy network for node maps and link maps, respectively, and design reward functions with multi-objective optimization. Through training, our self-built neural network has good convergence and can make an optimal resource allocation strategy to improve the utilization of network resources. In addition, our algorithm can process dynamically arriving virtual network requests immediately, instead of processing a large number of requests at one time, which is in line with the actual network environment. Finally, we compared the proposed algorithm with the existing research on resource allocation algorithms. Overall, in this paper, we address the resource allocation to improve the utilization of network resources problem in edge computing-assisted smart grid scenarios from the perspective of virtual network embedding.
Although our algorithm improve the utilization of resources of the smart grid, it still has certain limitations. First of all, what we simulated in the experimental part is a medium-scale network. We should consider how to design a more complex policy network model and a more effective feature extraction method to deal with large-scale networks. Secondly, in the face of joint optimization of multi-grid resources, we should further consider the issue of data security, which is very important. In future work, we need to study how to improve data security with the help of blockchain and federated learning technology. Finally, we need to consider more network attributes, which are more in line with the real network environment.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}