1. Introduction
As one of the transportation facilities in everyday life, bridges make an important contribution to the economic development of a region. Existing bridge structures are vulnerable to damage from factors such as material degradation and external loads during operation. Visual inspection is highly subjective when assessing bridge structures [
1], so more and more bridges are being fitted with structural health monitoring systems [
2]. These monitoring systems continuously collect various types of sensing data from the bridge, including a dynamic response, a static response, and an apparent morphology, which contain a large amount of damage information and form the basis for assessing the condition of the bridge [
3]. Therefore, the interpretation of these data from the perspective of structural safety has become the focus of bridge damage identification research.
To improve the efficiency of damage identification, feature engineering is required to design more sensitive features before algorithmic identification. Features commonly used in data analysis include statistical features, frequency domain features, and time-frequency domain features. Among these, statistical features are usually calculated from existing features to account for their internal uncertainties. Zhang et al. [
4] used the mean and standard deviation of data for the reliability analysis of structures. Mattson and Pandit [
5] used variance, skewness, and peak values as damage features for structural damage identification.
Frequency domain features, including frequency, mode, and modal strain, have gained wide application over the past few decades [
6]. Moughty and Casas [
7] used vibration features for analysis in damage detection and system identification. However, this method is insensitive to local and small damages and cannot obtain the complete modal information of the structure. Time-frequency domain features can describe the local details of measurements in both the time and frequency domains and are therefore able to detect changes caused by damage promptly. Some researchers have used wavelet packet component energy [
8] and instantaneous frequency after the Hilbert-Huang transform [
9] to construct different damage features. Shahsavari et al. [
10] and Suarez et al. [
11] chose the coefficients and energy ratio of the wavelet transform for damage identification of structures with good results, respectively.
Existing damage identification methods can be divided into model-based and data-driven methods. Model-based approaches predict the outcome by building many mechanical and mathematical computational models [
12]. However, the presence of a large amount of monitoring data makes it difficult to build finite element models to reflect information on the properties of the bridge structure, resulting in too little physical interpretability [
13]. Data-driven methods can directly analyse measured structural change data, such as probability density functions [
14], without any a priori knowledge and can therefore take into account the uncertainties in the raw data.
In recent years, deep learning architectures have shown great promise for automated structural health monitoring processes [
15]. Deep learning can be used to obtain higher-level representations by combining lower-level representations. These high-level features can amplify the fundamental parts of the input used for differentiation and suppress irrelevant parts, so their performance will improve with the use of more data, where traditional methods may encounter bottlenecks [
16,
17].
Bao et al. [
18] chose to convert raw time series measurements into image vectors and then input the image vectors into a deep neural network to identify various anomalies. In 2019, Zhenqing Liu et al. [
19] used U-Net for the first time to detect concrete cracks, and the trained U-Net was able to accurately identify the crack locations from the original images under different conditions with high robustness. Parisi et al. [
20] used finite element models of steel frame bridges under different damage scenarios to obtain strain data, extracted and selected features from the data that were more sensitive to damage, and fed these features into a one-dimensional convolutional neural network (CNN) with an accuracy of 93% for damage identification. In classification applications, recurrent neural networks are used specifically to process sequential data by combining previous outputs and current inputs into the current prediction and are typically used in structural damage recognition for feature extraction and end-to-end classification. For example, long short-term memory (LSTM) is used to classify and diagnose clinical monitoring data with poor data conditions [
21]. A deep auto-encoder (DAE) consists of a stack of multiple auto-encoders, which is a three-layer network typically used for dimensionality reduction or feature extraction. Pathirage et al. [
22] constructed two variants of a DAE with different hidden layers for early damage detection in bridges, localising and quantifying damage in both numerical and experimental frame structures, showing better performance than the artificial neural network.
For the classification problem of damaged data, most studies choose to take the raw data as input directly or select statistical features such as extreme value, mean, and variance for analysis, but these features can hardly reflect the correspondence between the implicit information of the data and the structural damage. Based on this, the research in this paper consists of the following three parts: the first part is the parameter optimisation of wavelet threshold decomposition; the second part is the feature extraction and selection of structural damage information; and the third part is the damage identification by deep neural networks. Specifically, firstly, the optimisation algorithm of random search introduces two adjustment parameters in the threshold function to accommodate different wavelet decomposition layers. Secondly, in the feature extraction process, the Fast Fourier Transform and sliding window are used to extract modal frequency features in the spectrum that contain differences in damage categories, and then the principal component analysis is used to discard the principal components with small weight contributions and only retain the sensitive features with the largest amount of category information. Finally, different deep neural networks are used for impairment identification, and the corresponding experimental comparisons and performance analyses are conducted.
The remainder of the paper is organised as follows: In
Section 2, a brief overview of data processing and neural network-related methods is given. In
Section 3, noise reduction methods based on wavelet threshold decomposition with parameter optimisation and feature engineering of the data are described in detail. In
Section 4, experiments on damage identification are arranged, and the results are analysed and compared. In
Section 5, the full paper is summarised.
4. Experiments
In this section, CNN, LSTM, and DAE are trained and tested, respectively, and the performance of damage identification, the impact of feature engineering, and the generalisation ability of the neural networks are compared and discussed in the corresponding experiments and analyses.
4.1. Experimental Method
This experiment is a classification problem based on damage identification, so a cross-entropy loss function suitable for multiple classifications is chosen for training to calculate the difference between the actual and predicted categories, which is calculated as follows:
In Equation (10),
denotes the number of samples,
denotes the label category,
is a symbolic function that takes 1 if the predicted category of the sample is equal to the true label and 0 otherwise, and
is the predicted probability that the sample belongs to category
. All labels of the dataset are processed in one-hot encoding, for example, the Damage 1 of data are labelled [0,1,0,0,0,0], and all deep neural networks are pre-initialised randomly using a normal distribution.
Table 3 shows the parameter settings for this experiment.
To reflect the independence of the test samples, 80% of the total data is randomly selected as the training set and the remaining 20% as the test set each time, after which the training and test sets are pre-processed and feature-engineered separately to ensure that there is no information interaction or data leakage between the two independent units. The algorithms in this paper are implemented using the Python language, and the deep learning computing platform is the TensorFlow framework. All experiments are run on a computer with an Intel Core i9-10900k@3.70 GHz CPU and an NVIDIA GeForce RTX3080 10 GB graphics processing unit.
4.2. Model Training
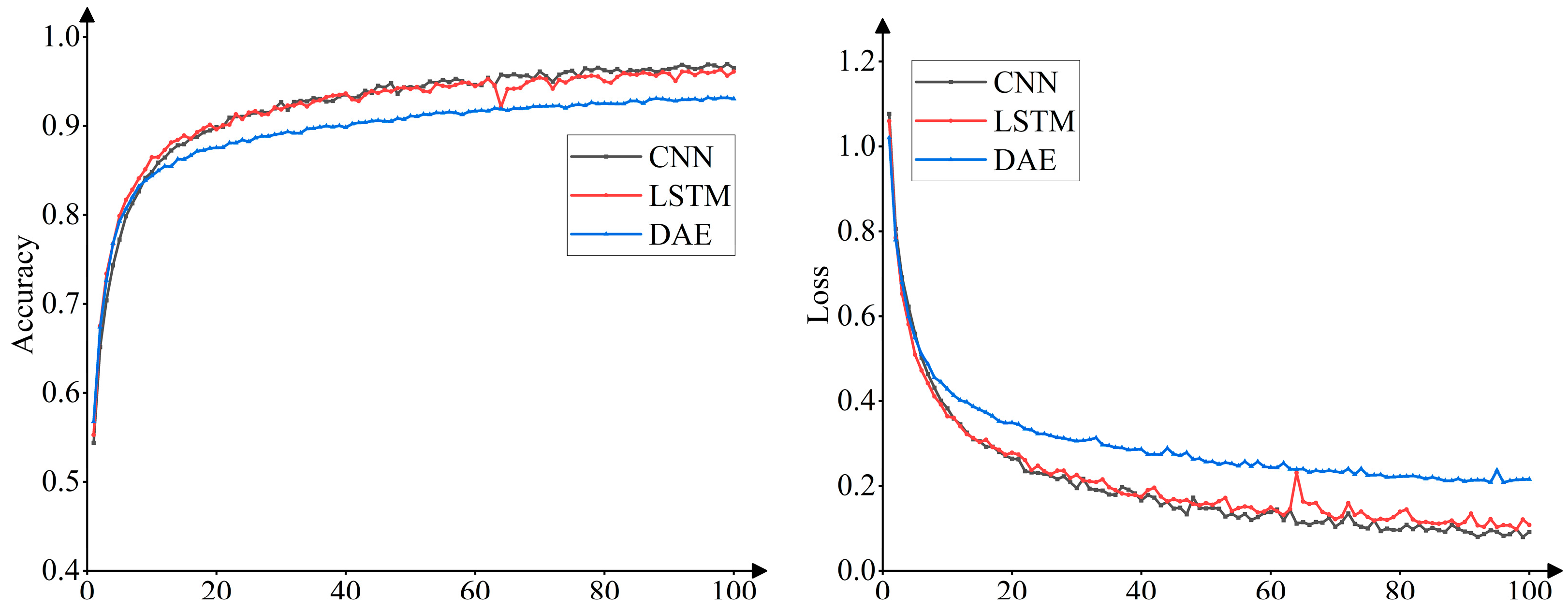
A total of 100 epochs are iteratively trained in this experiment, and
Figure 8 shows the changes in accuracy and loss values during the training process. In
Figure 8, with the increasing number of training iterations, the training curves of all three types of deep neural networks gradually reach convergence, and the final training accuracies of the CNN, LSTM, and DAE are 96.49%, 96.1%, and 93.03%.
4.3. Experimental Results
4.3.1. Evaluation Metrics
Evaluation metrics commonly used in damage classification problems include precision, recall, and F1-score, which are defined as follows:
The precision indicates how many of the samples predicted to be in the damage category are correct, the recall indicates how many damage samples are correctly predicted, and the F1-score is the summed average of these two.
4.3.2. Experimental Results
Table 4 shows the test results of the three types of deep neural networks. With only three feature dimensions retained, the recognition accuracy of all three types of deep neural networks exceeds 93%, with the CNN having the highest recognition accuracy of 94.89%. The experimental results show that deep neural networks are still very good at recognising damage based on structural vibration signals when only selecting the feature dimension that accounts for 3.2% of the frequency statistics dataset after using sliding windows to extract modal frequencies and discarding many features with invalid damage information.
The confusion matrix for the CNN is shown in
Table 5. As seen in
Table 5, the CNN has high recognition accuracy for all six types of data, especially for the normal and Damage 5 types of data, with the highest F1-scores of 97.93% and 96.94%, respectively. Even for the Damage 1 type of data, which has relatively low recognition accuracy, the precision, recall, and F1-score exceed 92% when tested.
4.4. Experimental Comparison and Analysis
4.4.1. Influence of Feature Extraction Methods
To analyse the validity of the modal frequency features, this paper also uses the extreme and mean values most commonly used in previous studies as feature representatives for time domain analysis for experimental comparison. Firstly, the maximum, minimum, and mean values are extracted for each sampling point using the same size sliding window and shift step as in the Fast Fourier Transform for feature extraction; secondly, the PCA is used for dimensionality reduction; and finally, the same model is used for training and the best model is retained using the five-fold cross-validation method.
Table 6 shows the damage identification results. Compared to our proposed method, the recognition accuracy of the method using time-domain features on the three deep neural networks decreased by 4.96%, 3.04%, and 4.33%, respectively, indicating that the information extracted from the spectrograms did characterise the deeper damage class differences in the data.
4.4.2. Influence of Feature Selection Methods
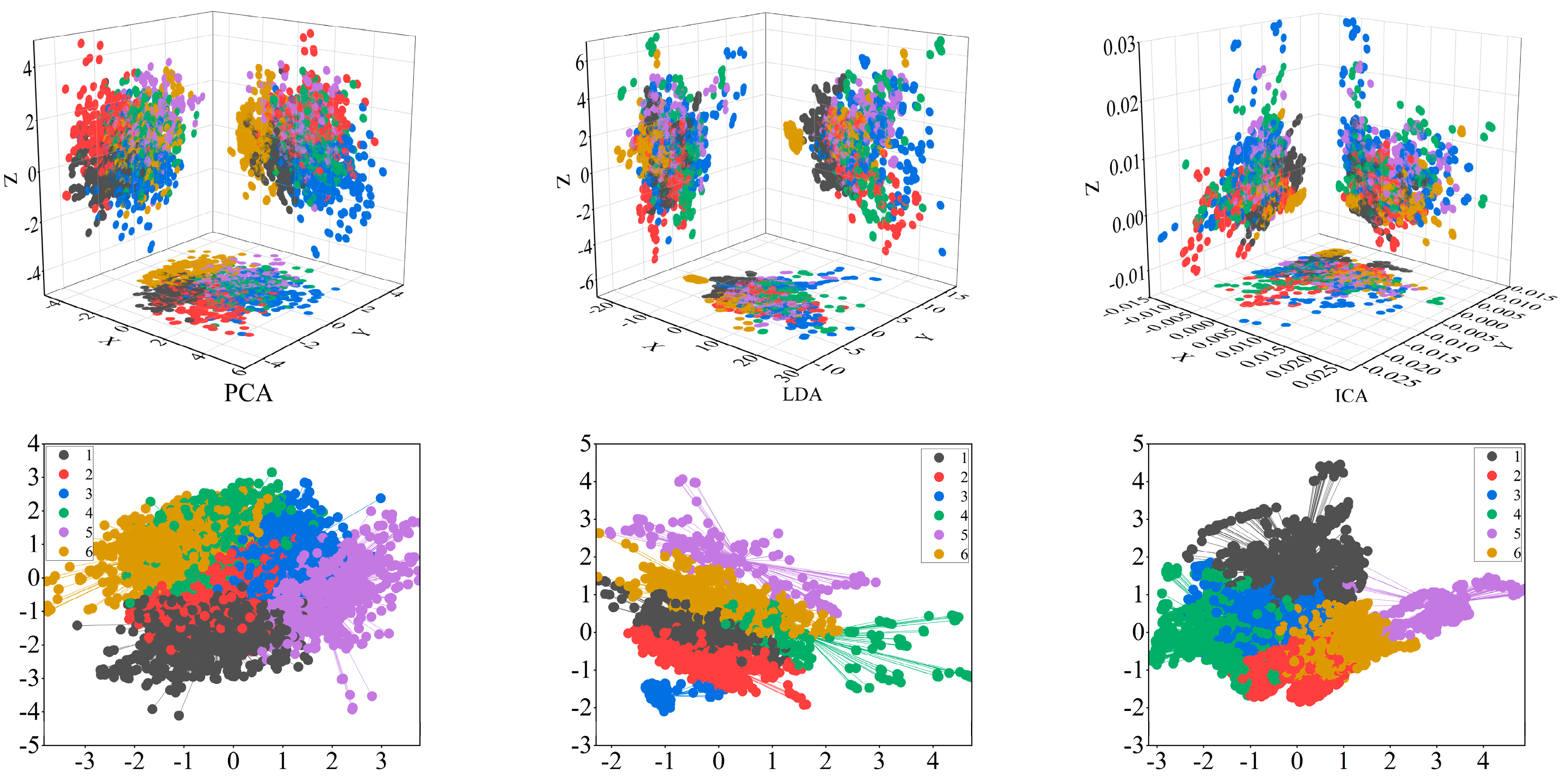
This paper also validates the effectiveness of PCA by investigating the impact of correlation and damage identification on data classification using two methods, linear discriminant analysis (LDA) and independent component analysis (ICA), respectively.
Figure 9 shows the correlation distribution of data categories after processing using these three methods. Compared to these two methods, PCA reduces the dimensionality of the data while maintaining maximum differentiability through variance maximisation, effectively retaining information about the data categories, while the category distribution is generally consistent with the results obtained using the k-means clustering algorithm. Finally, using the same model, the damage recognition accuracy of PCA is also higher than the other two methods, and the results are shown in
Table 7.
Only the first three features are selected for data downscaling using PCA, and the vast majority of features are discarded, so the effect of different feature dimensions on damage identification is investigated, as shown in
Table 8. As the feature dimensionality increases, the recognition accuracy improves only slightly, the complexity of the model gradually increases exponentially, and the model starts to overfit. In contrast, our method achieves high accuracy in damage identification while keeping the computational effort to a minimum.
4.4.3. Influence of Different Algorithms
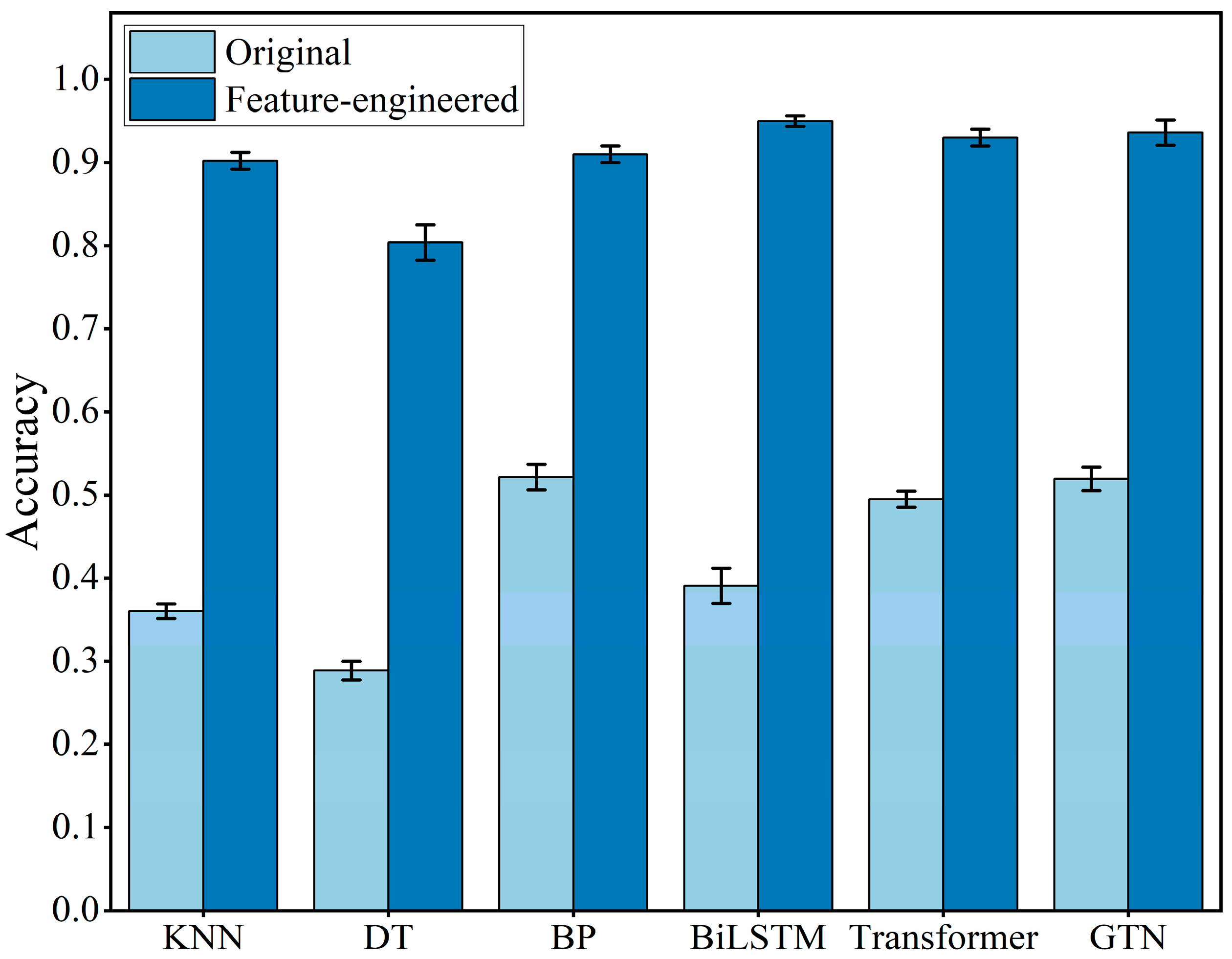
This paper uses other algorithms for comparison on the original dataset and the feature-engineered dataset, respectively, including KNN [
31], DT [
32], BP [
33], BiLSTM [
34], Transformer [
35], and GTN [
36]. For the machine learning algorithms, accuracy improvement is used as the objective function, and its hyperparameters are tuned through the Bayesian optimisation method in the fetch space by continuous iteration. The Transformer and GTN model architectures are both adopted from the original paper, and other relevant settings are used as described in this paper.
Figure 10 shows the damage identification results. The recognition accuracy of the various algorithms is greatly improved on the feature-engineered dataset, which validates the effectiveness of our proposed feature engineering.
4.4.4. Influence of the Various Components in Feature Engineering
To investigate in detail the impact of the various aspects of feature engineering on the performance of damage identification, three different datasets are prepared, including the original dataset, the PCA-only dataset, and the fusion dataset, which is obtained by combining the PCA-only dataset with the feature-engineered dataset in the feature direction and by downsampling. In this paper, a shared model with parameters in the source and target domains is used to achieve transfer learning on the three datasets, thereby improving training speed and learning accuracy. Specifically, the pre-trained model based on the previous section is retrained on each of the three datasets. First, freezing the feature extraction layer of the model and training the fully connected layer near the output for 50 epochs to adapt it to the feature distribution in the new dataset, and then unfreezing it and fine-tuning the entire model architecture for 100 epochs. The initial learning rate is adjusted to 0.0001 for both stages, and other relevant settings are described in this paper; the test results are shown in
Table 9.
Apart from the feature-engineered dataset, the fusion dataset performs relatively well because it contains not only the most original information but also the information after feature extraction and integration. The other two datasets both have lower recognition accuracy due to the inconspicuous distribution of the original features. This indicates that the modal frequency features extracted from the spectrograms in the damage feature extraction process greatly improve the sensitivity and accuracy of recognition.
4.5. Generalization Capability
To show the generalisation capability of the recognition method based on the combination of data mining and deep neural networks, a bridge model is built in this paper and acquisition equipment such as sensors are arranged to obtain a monitoring dataset by collecting data in real-time. The dataset is the change data of vibration acceleration of the bridge when passing through the vehicle, the bridge structure and data acquisition equipment are shown in
Figure 11.
The bridge as a whole is a cable-stayed bridge structure with a length of 5.1 m, and its cross-section is a uniform rectangle with a cross-section of . To simulate the damage of the bridge, we artificially damage a rectangular skeleton base plate with a size of in the shape of a metre at the bottom of the beams in the centre position of the two pylons. The vehicle is operated at a uniform speed of , on which six loaded iron blocks with a total mass of 3.6 kg are placed as vehicle loads, and four acceleration sensors on the bridges are mounted at the very top of both sides of the two pylons, with a sampling frequency of 1024 Hz. Through the experimental measurements, we obtain a dataset with a size of , which consisted of 19,118 normal data and 4882 abnormal data.
Our proposed data pre-processing approach is applied to this dataset, while features are extracted in the frequency domain and downscaled by PCA; finally, the same model is used for experimental analysis.
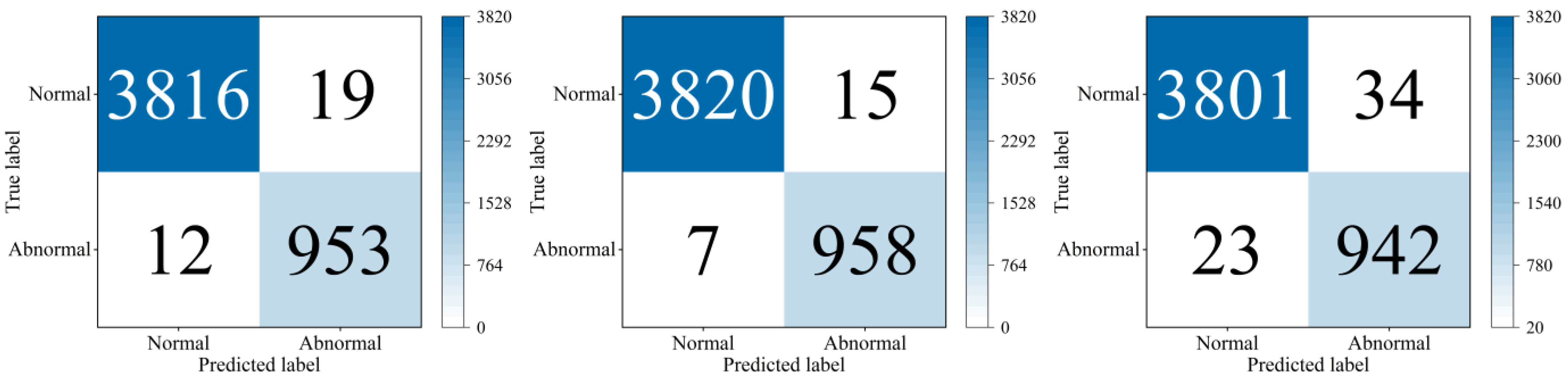
Figure 12 shows the confusion matrix for the three types of deep neural networks when tested.
As seen in the results, the detection accuracy of all three types of deep neural networks reaches over 98%, indicating that the trained deep neural networks can also give suitable outputs when our proposed method is applied to abnormal data detection.
5. Conclusions
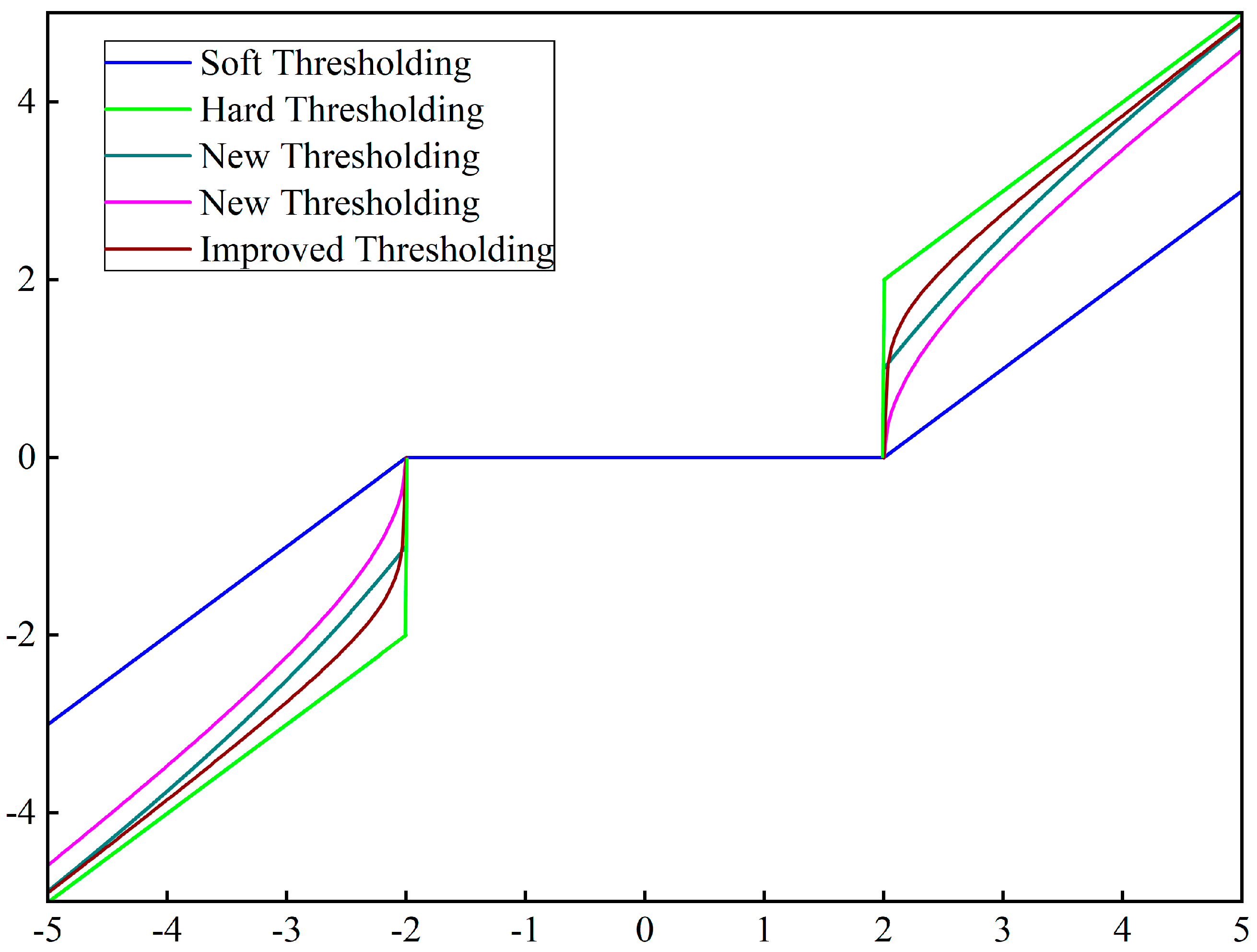
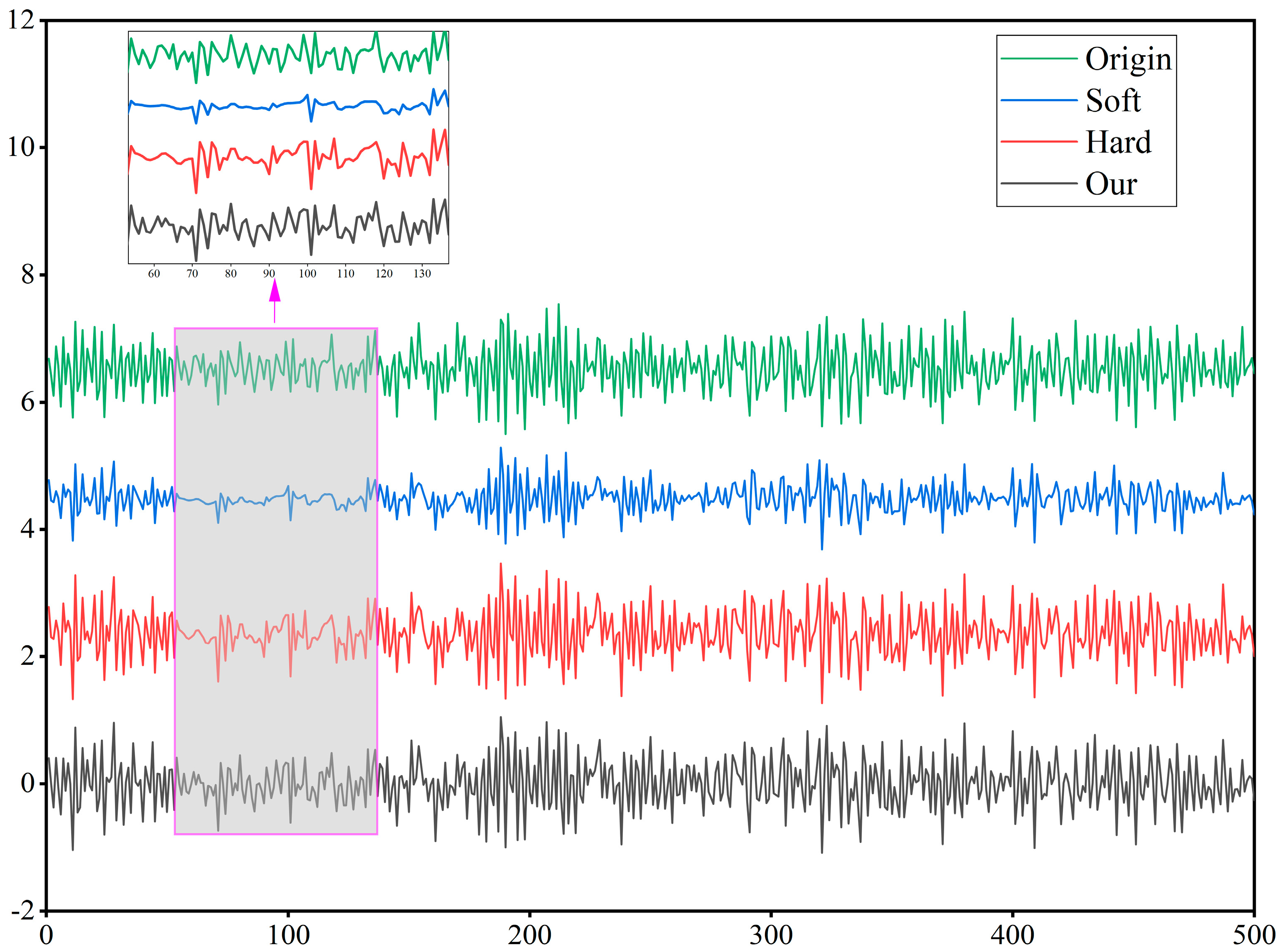
Based on structural vibration data and deep neural networks, this paper investigates data pre-processing, feature engineering, and damage identification techniques in the field of bridge health monitoring. Firstly, for the problem of noise interference in the original data, a wavelet threshold decomposition method based on parameter optimisationoptimisation is proposed, which effectively overcomes the discontinuity of the hard threshold function and the constant deviation of the wavelet coefficients in the soft threshold function by introducing two adjusting parameters in the threshold function to adapt to the different number of wavelet decomposition layers.
On the basis of this, to reflect the damage characteristics of the bridge structure, an in-depth analysis of the feature differences reflected in the signal spectrograms is carried out, and a feature extraction method based on the Fast Fourier Transform and sliding window extraction of modal frequencies and a feature selection method based on PCA are proposed so as to excavate the key information of the damage categories contained in the data. Finally, different deep neural networks are applied to identify the damaged data, the role of different feature engineering and data dimensions in damage identification is discussed, and the effectiveness of our method is verified by transfer learning.
The experimental results show that, compared with the original acceleration response, the new damage metrics effectively retain the information of the data categories and improve recognition ability and computational efficiency. Under the premise of retaining only three feature dimensions, the recognition performance and generalisation ability of the deep neural networks are extremely good, and their recognition accuracy on the test set exceeds 93%, with the highest F1-score of 97.93%. Therefore, our damage identification scheme achieves high recognition accuracy with minimal computational effort, has the ability to identify large amounts of monitoring data, and has the potential to be applied to real bridges.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}