
An FPGA Design with High Memory Efficiency and Decoding Performance for 5G LDPC Decoder


Abstract
:1. Introduction
2. Related Definitions and Preliminaries
2.1. Definitions
2.2. 5G Quasi-Cyclic LDPC Codes
| Algorithm 1 Layered HOMS decoding algorithm [19]. | |
| Input: | ▹ received word |
| Output: | ▹ estimated codeword |
| |
| ▹ Loop over iterations |
| ▹ Loop over horizontal layers |
| ▹ VN-processing |
| |
| ▹ CN-processing |
| |
| ▹ AP-update |
| |
| is the maximum number of iterations. | |
| is the position of . In cases where there exists more than one value, | |
| is determined as the position with the smallest index. | |
| is the offset factors. | |
| is the value of saturated to q-bit. | |
3. The Proposed Decoder Architecture
3.1. Check Node Unit
3.2. Variable Node Units and A Posteriori Blocks
3.3. Memory Blocks
3.4. Decompress Block
4. Results and Discussion
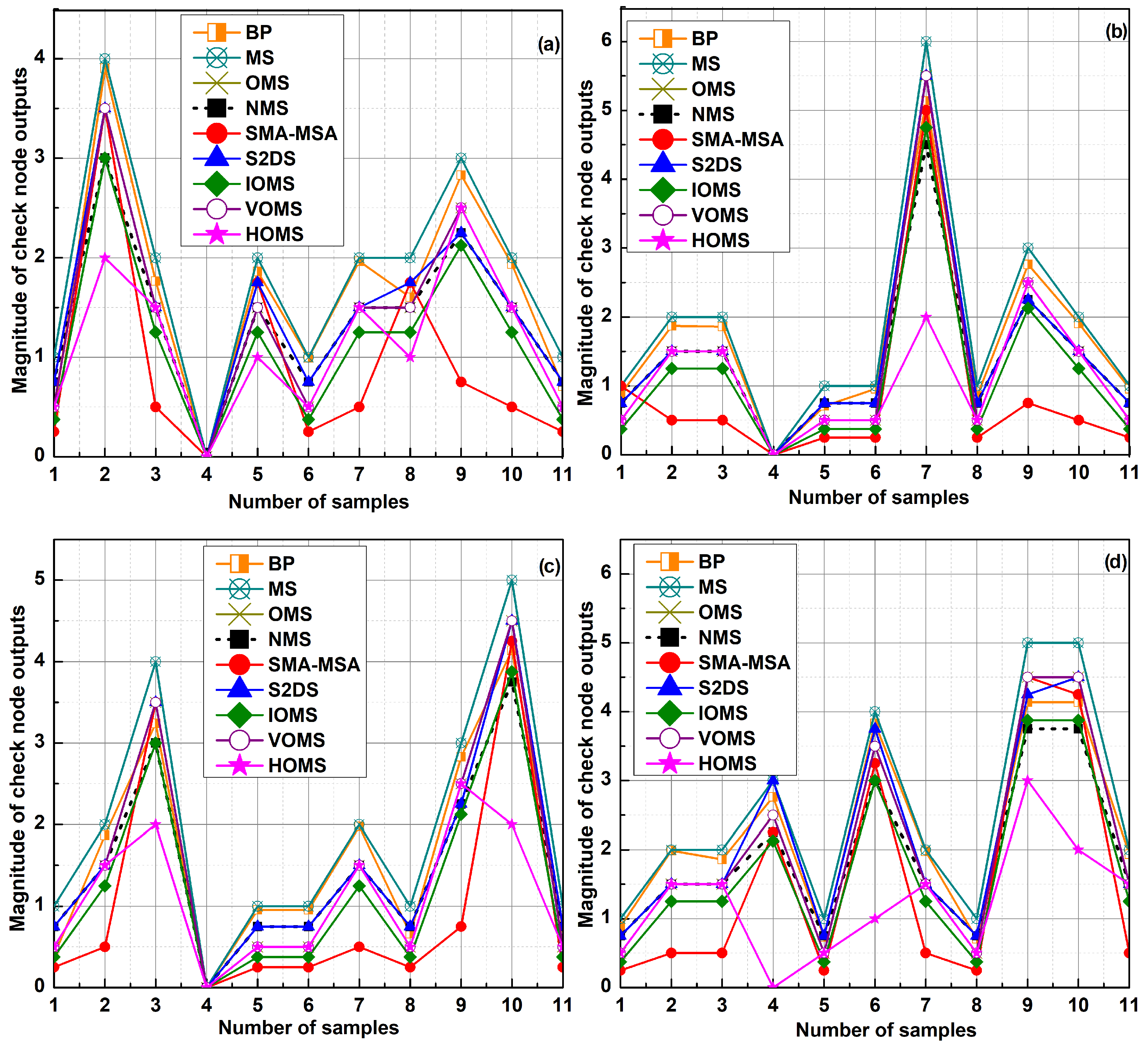
4.1. Performance Results
4.2. Implementation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AP | A Posteriori |
| APB | A Posteriori Block |
| AP-MB | A Posteriori Memory Block |
| AWGN | Additive White Gaussian Noise |
| BP | Belief-Propagation |
| BPSK | Binary Phase Shift Keying |
| CN | Check Node |
| CN-MB | Check Node Memory Block |
| CNU | Check Node Unit |
| CTV | Check-to-Variable |
| DECOM | Decompress unit |
| FEC | Forward Error Correction |
| FPGA | Field Programmable Gate Array |
| HOMS | Hybrid Offset Min-Sum |
| HUE | Hardware Usage Efficiency |
| IG | Index Generator |
| IOMS | Improved Offset Min-Sum |
| LDPC | Low-Density Parity-Check |
| LSB | Least-SignificantBits |
| MP | Message-Passing |
| MS | Min-Sum |
| MSB | Most Significant Bit |
| MUX | Multiplexer |
| mVU | minimum Value Unit |
| NMS | Normalized Min-Sum |
| NR | New Radio |
| OMS | Offset Min-Sum |
| PCM | Parity-Check Matrix |
| QC-LDPC | Quasi-Cyclic LDPC |
| Read-PU | Read Permutation Unit |
| R-SB | Read-Shifter Blocks |
| S2DS | Simplified 2-Dimensional Scaled |
| SMA-MSA | Second Minimum Approximation |
| Min-Sum algorithm | |
| SOMS | Simplified Offset Min-Sum |
| SP | Sum-Product |
| TS | Tree-Structure |
| VN | Variable Node |
| VNU | Variable Node Unit |
| VOMS | Variable Offset Min-Sum |
| VTC | Variable-to-Check |
| Write-PU | Write Permutation Unit |
References
- Gallager, R. Low-density parity-check codes. IRE Trans. Inf. Theory 1962, 8, 21–28. [Google Scholar] [CrossRef]
- Chung, S.Y.; Forney, G.D.; Richardson, T.J.; Urbanke, R. On the design of low-density parity-check codes within 0.0045 dB of the Shannon limit. IEEE Commun. Lett. 2001, 5, 58–60. [Google Scholar] [CrossRef]
- MacKay, D.J.; Neal, R.M. Near Shannon limit performance of low-density parity check codes. Electron. Lett. 1997, 33, 457–458. [Google Scholar] [CrossRef]
- Lin, C.H.; Su, H.H.; Chen, T.S.; Lu, C.K. Reconfigurable Low-Density Parity-Check (LDPC) Decoder for Multi-Standard 60 GHz Wireless Local Area Networks. Electronics 2022, 11, 733. [Google Scholar] [CrossRef]
- Liu, C.H.; Yen, S.W.; Chen, C.L.; Chang, H.C.; Lee, C.Y.; Hsu, Y.S.; Jou, S.J. An LDPC decoder chip based on self-routing network for IEEE 802.16e applications. IEEE J. Solid-State Circuits 2008, 43, 684–694. [Google Scholar] [CrossRef]
- Wu, Y.; Wu, B.; Zhou, X. High-Performance QC-LDPC Code Co-Processing Approach and VLSI Architecture for Wi-Fi 6. Electronics 2023, 12, 1210. [Google Scholar] [CrossRef]
- Kim, S.M.; Park, C.S.; Hwang, S.Y. A novel partially parallel architecture for high-throughput LDPC decoder for DVB-S2. IEEE Trans. Consum. Electron. 2010, 56, 820–825. [Google Scholar] [CrossRef]
- Cohen, A.E.; Parhi, K.K. A low-complexity hybrid LDPC code encoder for IEEE802.3an (10GBase-T) ethernet. IEEE Trans. Signal Process. 2009, 57, 4085–4094. [Google Scholar] [CrossRef]
- Richardson, T.; Kudekar, S. Design of low-density parity-check codes for 5G new radio. IEEE Commun. Mag. 2018, 56, 28–34. [Google Scholar] [CrossRef]
- Thi Bao Nguyen, T.; Nguyen Tan, T.; Lee, H. Low-complexity high-throughput QC-LDPC decoder for 5G new radio wireless communication. Electronics 2021, 10, 516. [Google Scholar] [CrossRef]
- Richardson, T.J.; Urbanke, R.L. The capacity of low-density parity-check codes under message-passing decoding. IEEE Trans. Inf. Theory 2001, 47, 599–618. [Google Scholar] [CrossRef]
- Kschischang, F.R.; Frey, B.J.; Loeliger, H.A. Factor graphs and the sum-product algorithm. IEEE Trans. Inf. Theory 2001, 47, 498–519. [Google Scholar] [CrossRef]
- Fossorier, M.P.; Mihaljevic, M.; Imai, H. Reduced complexity iterative decoding of low-density parity-check codes based on belief propagation. IEEE Trans. Commun. 1999, 47, 673–680. [Google Scholar] [CrossRef]
- Chen, J.; Dholakia, A.; Eleftheriou, E.; Fossorier, M.P.; Hu, X.Y. Reduced-complexity decoding of LDPC codes. IEEE Trans. Commun. 2005, 53, 1288–1299. [Google Scholar] [CrossRef]
- Chen, J.; Fossorier, M.P. Near optimum universal belief propagation based decoding of low-density parity check codes. IEEE Trans. Commun. 2002, 50, 406–414. [Google Scholar] [CrossRef]
- Tran-Thi, B.N.; Nguyen-Ly, T.T.; Hong, H.N.; Hoang, T. An improved offset min-sum LDPC decoding algorithm for 5G new radio. In Proceedings of the 2021 International Symposium on Electrical and Electronics Engineering (ISEE), Ho Chi Minh, Vietnam, 15–16 April 2021. [Google Scholar]
- Català-Pérez, J.M.; Lacruz, J.O.; Garcia-Herrero, F.; Valls, J.; Declercq, D. Second minimum approximation for min-sum decoders suitable for high-rate LDPC codes. Circuits Syst. Signal Process. 2019, 38, 5068–5080. [Google Scholar] [CrossRef]
- Cho, K.; Lee, W.H.; Chung, K.S. Simplified 2-dimensional scaled min-sum algorithm for LDPC decoder. J. Electr. Eng. Technol. 2017, 12, 1262–1270. [Google Scholar] [CrossRef]
- Tran-Thi, B.N.; Nguyen-Ly, T.T.; Hoang, T. High-performance and low complexity decoding algorithms for 5G Low-Density Parity-Check codes. J. Commun. 2022, 17, 358–364. [Google Scholar] [CrossRef]
- Boncalo, O.; Kolumban-Antal, G.; Amaricai, A.; Savin, V.; Declercq, D. Layered LDPC decoders with efficient memory access scheduling and mapping and built-in support for pipeline hazards mitigation. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 66, 1643–1656. [Google Scholar] [CrossRef]
- Petrović, V.L.; Marković, M.M.; El Mezeni, D.M.; Saranovac, L.V.; Radošević, A. Flexible high throughput QC-LDPC decoder with perfect pipeline conflicts resolution and efficient hardware utilization. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 5454–5467. [Google Scholar] [CrossRef]
- Cui, H.; Ghaffari, F.; Le, K.; Declercq, D.; Lin, J.; Wang, Z. Design of high performance and area-efficient decoder for 5G LDPC codes. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 68, 879–891. [Google Scholar] [CrossRef]
- Verma, A.; Shrestha, R. Low computational-complexity SOMS-algorithm and high-throughput decoder architecture for QC-LDPC codes. IEEE Trans. Veh. Technol. 2023, 72, 66–80. [Google Scholar] [CrossRef]
- Tanner, R. A recursive approach to low complexity codes. IEEE Trans. Inf. Theory 1981, 27, 533–547. [Google Scholar] [CrossRef]
- Fossorier, M.P. Quasicyclic low-density parity-check codes from circulant permutation matrices. IEEE Trans. Inf. Theory 2004, 50, 1788–1793. [Google Scholar] [CrossRef]
- Nguyen-Ly, T.T.; Savin, V.; Le, K.; Declercq, D.; Ghaffari, F.; Boncalo, O. Analysis and design of cost-effective, high-throughput LDPC decoders. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2017, 26, 508–521. [Google Scholar] [CrossRef]
- Wey, C.L.; Shieh, M.D.; Lin, S.Y. Algorithms of finding the first two minimum values and their hardware implementation. IEEE Trans. Circuits Syst. I Regul. Pap. 2008, 55, 3430–3437. [Google Scholar]
- Nadal, J.; Baghdadi, A. Parallel and flexible 5G LDPC decoder architecture targeting FPGA. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2021, 29, 1141–1151. [Google Scholar] [CrossRef]
- Li, Y.; Li, Y.; Ye, N.; Chen, T.; Wang, Z.; Zhang, J. High Throughput Priority-Based Layered QC-LDPC Decoder with Double Update Queues for Mitigating Pipeline Conflicts. Sensors 2022, 22, 3508. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning |
|---|---|
| Base matrix | |
| Parity-Check Matrix (PCM) | |
| Z | The expansion factor |
| N | The length of the codeword |
| K | Information bits |
| R | The code rate |
| A codeword | |
| The transmitted codeword | |
| The received information | |
| Noise variance | |
| n | The coded bit |
| m | The parity check bit |
| The set of Check Nodes (CNs) connected to the Variable Node (VNs) n | |
| The set of with check node m excluded. | |
| The set of Variable Nodes (VNs) connected to the Check Node (CNs) m | |
| The set of with check node n excluded. | |
| The number of neighbors of a VN is called its degree, | |
| The number of neighbors of a CN is called its degree, | |
| A Posteriori (AP) information update | |
| A priori information for each variable node n | |
| Check-to-Variable (CTV) messages sent from CN m to VN n | |
| Variable-to-Check (VTC) messages sent from VN n to CN m | |
| The number of bits that represent , , messages (in this paper, bits) | |
| q | The number of bits that represent messages (in this paper, bits) |
| The -bit quantization map of , that rounds each element of to the nearest integer | |
| less than or equal to . |
| Z | a | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 5 | 7 | 9 | 11 | 13 | 15 | ||
| 0 | 2 | 3 | 5 | 7 | 9 | 11 | 13 | 15 | |
| 1 | 4 | 6 | 10 | 14 | 18 | 22 | 26 | 30 | |
| 2 | 8 | 12 | 20 | 28 | 36 | 44 | 52 | 60 | |
| k | 3 | 16 | 24 | 40 | 56 | 72 | 88 | 104 | 120 |
| 4 | 32 | 48 | 80 | 112 | 144 | 176 | 208 | 240 | |
| 5 | 64 | 96 | 160 | 224 | 288 | 352 | |||
| 6 | 128 | 192 | 320 | ||||||
| 7 | 256 | 383 | |||||||
| Conventional CN-MB | Proposed CN-MB | ||||
|---|---|---|---|---|---|
| Width | Depth | Total | Width | Depth | Total |
| 30Z | 24 | 720Z | 27Z | 24 | 648Z |
| Specifications | This Work | 2023 [23] | 2022 [29] | 2021 [28] | 2020 [21] |
|---|---|---|---|---|---|
| FPGA Board | Xinlinx Kintex Ultrascale+ | Xinlinx Zynq Ultrascale+ | Xinlinx Virtex-7 | Xinlinx Kintex-7 | Xinlinx Kintex Ultrascale+ |
| Quantization Bits | (4,6)-bit | 7-bit | 8-bit | 8-bit | 8-bit |
| Throughput (Gbps) | 2.82 | 3.6–13.31 | 2.85 | 0.391–1.1 | 3.2–4.9 |
| Code Length | 8832 | 10,368–26,112 | 10,368 | 3456 | 10,368–26,112 |
| Expansion Factor | 192 | 384 | 384 | 384 | 384 |
| Clock Frequency (MHz) | 153.5 | 128.36 | 255 | 160 | 404.8 |
| Code Rate | 1/2 | 1/3–8/9 | 22/27 | 1/2–5/6 | 22/68–22/27 |
| Number of Layers | 24 | 5–46 | 7 | 5–46 | 7–46 |
| Number of Iterations | 10 | 10 | 11 | 8 | 10 |
| Pipeline Stages | 2 | 3 | 13 | - | 13 |
| Memory Size (kb) | 173.25 | 765.8 | 3888 | 7146 | 4914 |
| Decoding Algorithm | HOMS | SOMS | OMS | OMS | OMS |
| Hardware Utilization | 314,968 | 1,200,394 | 4,204,122 | 7,438,394 | 5,233,977 |
| Memory Type | BRAM | Registers | BRAM | BRAM | BRAM |
| Permutation Network | Barel Shifter | Bit Rotational Mapping | Barel Shifter | Barel Shifter | Barel Shifter |
| HUE * | 4.65 | 1.96 | 20.85 | 147.54 | 23.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran-Thi, B.N.; Nguyen-Ly, T.T.; Hoang, T. An FPGA Design with High Memory Efficiency and Decoding Performance for 5G LDPC Decoder. Electronics 2023, 12, 3667. https://doi.org/10.3390/electronics12173667
Tran-Thi BN, Nguyen-Ly TT, Hoang T. An FPGA Design with High Memory Efficiency and Decoding Performance for 5G LDPC Decoder. Electronics. 2023; 12(17):3667. https://doi.org/10.3390/electronics12173667
Chicago/Turabian StyleTran-Thi, Bich Ngoc, Thien Truong Nguyen-Ly, and Trang Hoang. 2023. "An FPGA Design with High Memory Efficiency and Decoding Performance for 5G LDPC Decoder" Electronics 12, no. 17: 3667. https://doi.org/10.3390/electronics12173667
APA StyleTran-Thi, B. N., Nguyen-Ly, T. T., & Hoang, T. (2023). An FPGA Design with High Memory Efficiency and Decoding Performance for 5G LDPC Decoder. Electronics, 12(17), 3667. https://doi.org/10.3390/electronics12173667