1. Introduction
In augmented reality applications, estimating the 6D pose (3D rotation and translation) of objects with respect to the camera is a fundamental task. This task, such as many other vision tasks, witnessed a complete renaissance with the advent of deep learning. The classical approach for reliable 6D pose estimation is based on finding 2D–3D feature point pairs from input images, followed by the Perspective-n-Point (PnP) algorithm [
1] to predict the object pose. The key to this approach is to extract informative features that facilitate pose estimation using well-designed convolutional neural networks (CNN) [
2,
3,
4]. The accuracy of pose estimation depends heavily on the performance of CNNs. CNNs are the basic building blocks of deep learning models for vision tasks. The strength of CNNs lies in their ability to learn local spatial features. Building deep learning models using CNNs has become a common and dominant method for all kinds of vision tasks [
5,
6]. However, since convolution is an operation that deals with one local neighborhood at a time, CNN-based models usually suffer from capturing long-range dependencies. Capturing long-range dependencies is of central importance in deep neural networks, which helps global understanding of visual scenes [
7,
8]. There is no doubt that long-range dependencies also play an important role in estimating object poses. Commonly, long-range dependencies are modeled by the large receptive fields formed by deep stacks of convolutional operations. However, this approach still provides a weak and limited understanding of global features, rather making networks cumbersome, difficult to run on resource-constrained environments such as mobile or embedded systems. Although previous studies have attempted to overcome this problem [
9,
10], the performance has been validated for only a few limited vision tasks.
Transformer is an architecture based on a self-attention mechanism that has achieved state-of-the-art results in many natural language processing (NLP) tasks [
11,
12]. Recently, Transformer has also been extremely active in the field of computer vision. The Vision Transformer (ViT) is the first Transformer-based model for vision tasks that relies exclusively on the Transformer architecture, which aims to adapt the Transformer architecture with minimal modifications [
13]. The input images are split into discrete non-overlapping patches, the patches are treated as markers (similar to tokens in NLP), summed up with positional encoding vectors to incorporate spatial information, and input into repeated Transformer layers to model global relationships for classification. Due to its excellent ability to model long-range dependencies, ViT has obtained competitive performance in large-scale image classification compared to CNN-based models, which has recently been extended and utilized in various vision tasks [
14,
15].
Despite the success of ViT and its variants, the performance is still lower than that of CNNs of similar size when trained on small amounts of data. One possible reason is that ViT lacks certain properties (usually known as inductive bias) that are inherent in CNNs and make CNNs well-suited for solving vision tasks; Images have a strong two-dimensional local structure and spatially adjacent pixels are usually highly correlated. CNN architectures force this local structure to be captured by using local receptive fields, shared weights, and spatial subsampling, and thus also achieve some degree of shift, scale, and distortion invariance [
16,
17].
To address the above limitations, inspired by previous studies [
9,
10,
18,
19], we hypothesize that Transformer architecture can be strategically introduced to the convolutional structure to improve performance and robustness, while concurrently maintaining a high degree of computational and memory efficiency. To verify the hypothesis, we present FusionNet, a novel architecture for PnP-based 6D object pose estimation. Similar to the state-of-the-art model [
20], it takes RGB images as the input and estimates object poses in an end-to-end manner. However, FusionNet uses modified CNN blocks to extract informative features efficiently and incorporates Transformer blocks to capture long-range dependencies between features. Specifically, FusionNet has the following structural properties: First, the convolutional operations are partitioned into multiple stages that form a hierarchical structure. The hierarchical design helps to extract multi-scale features and reduces the computational burden associated with high resolution. Unlike ResNet blocks [
21,
22] commonly used in previous 6D object pose estimation studies, FusionNet has a newly designed CNN building block consisting of a convolutional block and an attention block. The convolutional block consists of 3 × 3 and 1 × 1 convolutional layers to keep the model lightweight while enhancing the ability to handle nonlinear features. The attention block helps to learn global context within intermediate features, reducing unnecessary computation and improving the representation ability of the network. Second, global dependency encoder (GDE), a Transformer, is introduced, and it receives features extracted from CNN blocks and encodes long-range dependencies. The encoder helps FusionNet to learn global features without making the CNN blocks deeper and wider, which allows for the light weight of FusionNet despite the fusion of two kinds of architectures (see
Figure 1).
The primary contributions of this study focusing on developing an end-to-end hybrid model for 6D object pose estimation are as follows:
We propose FusionNet, the first hybrid model designed specifically for 6D object pose estimation with the introduction of a CNN-based transformer. FusionNet takes advantages of both architectures: CNN and Transformer.
We design an efficient CNN building block with self-attention that is lightweight but has excellent performance in extracting informative features for pose estimation.
We also design a Transformer called GDE to encode long-range dependencies between local features.
FusionNet is a lightweight model that is more suitable for resource-constrained devices common in real-life conditions than other 6D object pose estimation models. It can be easily implanted into mobile or embedded devices.
FusionNet is flexible enough to be applied to other vision tasks requiring the ability of extracting informative features and capturing their long-range dependencies with minor modifications.
The performance of FusionNet is validated on a benchmark dataset in various aspects. The experiments show that FusionNet outperforms other 6D object pose estimation models.
We note that research has been conducted such as CvT [
17] and CMT [
23] merging CNN and Transformer to leverage the advantages of both architectures. Recently, attempts of merging CNN and Transformer to solve low-level and high-level vision problems have also been reported [
24,
25,
26,
27]. However, to the best of our knowledge, there have been no attempts to merge both architectures in 6D object pose estimation, except by simply using CNNs at a pre-processing step for extracting features used as the input in Transformer-based models [
28,
29,
30,
31].
3. FusionNet
3.1. Overall Architecture
FusionNet is a hybrid model that combines the advantages of Transformer and CNN.
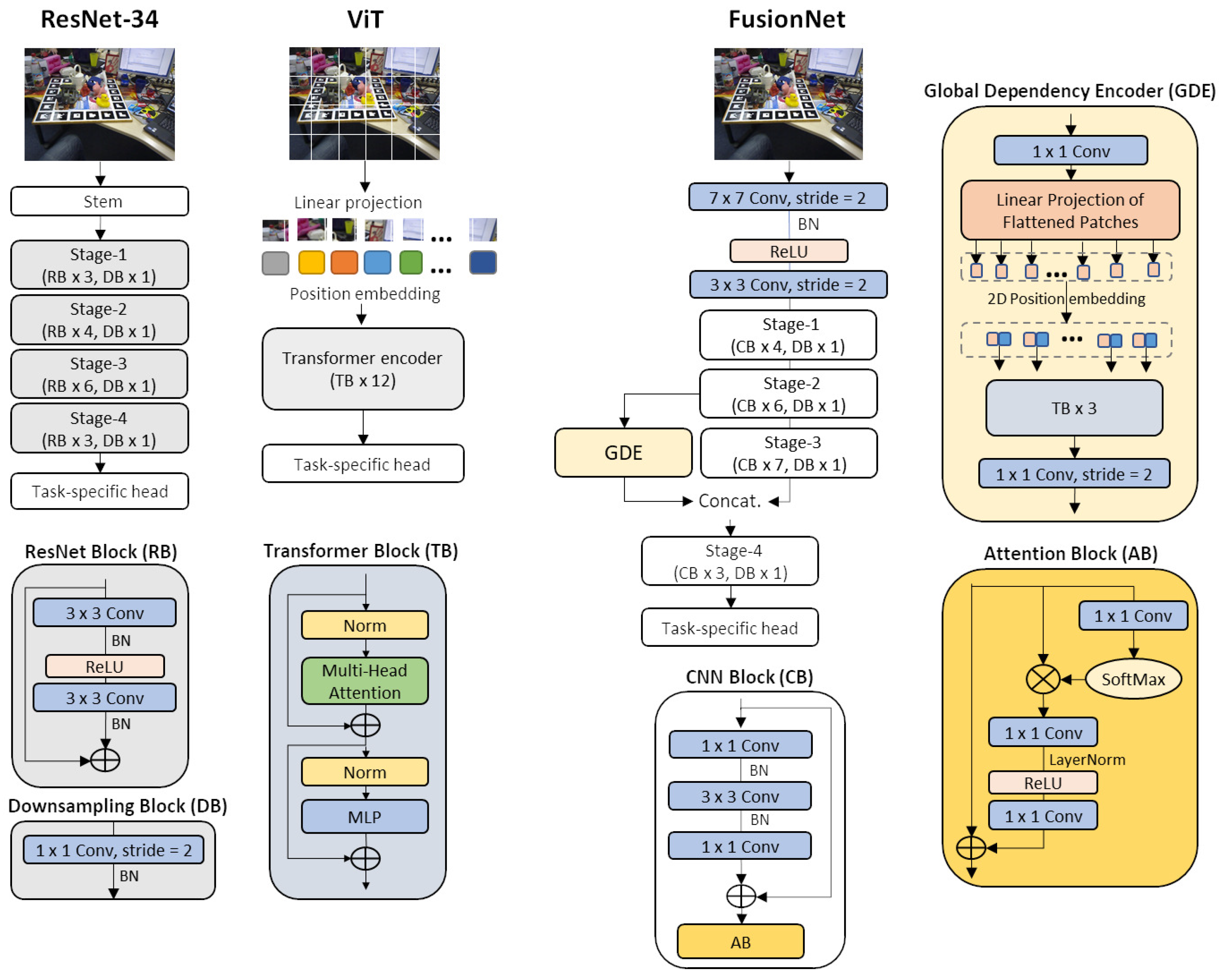
Figure 2 provides an overview of the network architecture of the representative CNN and Transformer models for vision tasks, ResNet-34 [
21] and ViT [
13], and the proposed FusionNet. ViT splits the input image into multiple patches, and the information within the patches is modeled by linear projection and position embedding. Then, the dependencies between the patches are modeled by self-attention operations in the subsequent Transformer encoder. ViT is a good model for vision tasks requiring global understanding of the input image/scene, such as classification, but not for vision tasks heavily depending on local features as well, such as object pose estimation. Furthermore, ViT directly uses high-dimensional input images in the Transformer encoder, which increases the computational complexity dramatically. To mitigate these limitations, FusionNet is basically designed to extract features using CNN blocks from input images. Specifically, referring to the design policy of ResNet-34 used in EPro-PnP [
20], FusionNet generates feature maps at different scales through four stages in which several CNN blocks are stacked sequentially, while maintaining the same resolution as the input within each stage. Feature maps are downsampled using one 1 × 1 convolution with stride = 2 and batch normalization at the end of each stage. However, the CNN building block has a different structure from that of ResNet-34 and also has an attention block, which is described in detail in
Section 3.2. At each stage, four, six, seven, and three CNN blocks are connected sequentially. In addition, the output of Stage-2 is fed into the GDE and concatenated with the output of Stage-3, where the long-range dependencies are captured. The GDE has the similar structure to the Transformer encoder of ViT, but it is much lighter because it uses low-dimensional feature maps as the input, which is elaborated in
Section 3.3. The reason why GDE is placed in parallel with Stage-3 is as follows. As aforementioned, the convolutional operation encodes long-range dependencies by deeply stacking itself, and the dependencies cannot be sufficiently captured at early stages even if the attention block is included in the CNN blocks. However, early-stage feature maps require a huge amount of model parameters for GDE because of their large resolution. Therefore, we believe that placing the GDE in parallel with Stage-3, which is in the middle of the CNN pipeline, is more suitable in terms of model efficiency and functionality.
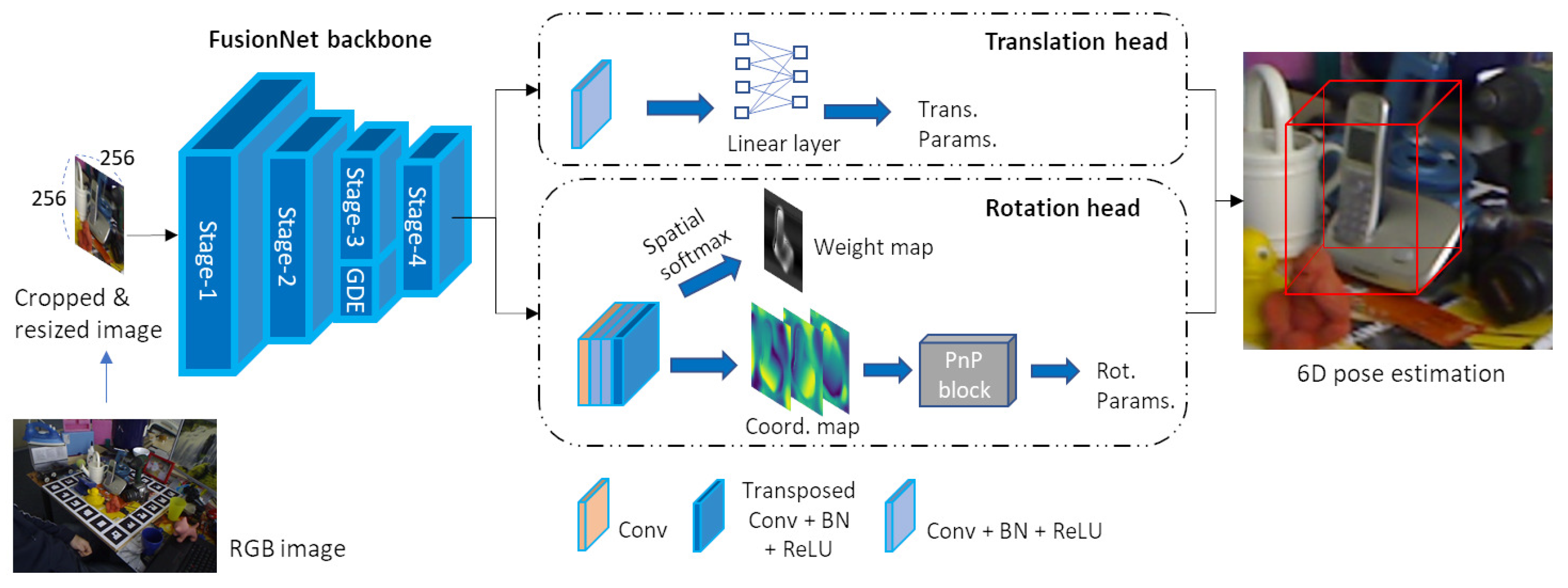
The full network architecture of FusionNet for 6D object pose estimation is shown in
Figure 3. From an RGB input image, object areas are cropped and resized to 256 × 256 pixels. Object areas may be detected using existing detection methods, but this study assumes that they are given in advance. FusionNet extracts informative features using the CNN blocks and GDE from the resized object images and the features are fed into the EPro-PnP head [
20] that consists of two sub-heads: one is a regression model for predicting translation parameters, the other is to extract a dense 3D coordinate map and a weight map via convolutional layers and to predict rotation parameters from the maps in an end-to-end manner using a PnP block that replaces the PnP algorithm. In the training phase, the translation head minimizes the L2 loss between predicted and ground-truth parameters, and the rotation head minimizes the KL divergence loss [
20].
3.2. CNN Block
As shown in
Figure 2, the ResNet blocks of ResNet-34 consist of two sets of 3 × 3 convolution, batch normalization, and ReLU activation. In contrast, aiming to achieve good performance while ensuring that the network is lightweight, we extract features using only one 3 × 3 convolution and replace the other 3 × 3 convolution with two 1 × 1 convolutions. The 1 × 1 convolution reduces the channel size, reducing the number of model parameters (see
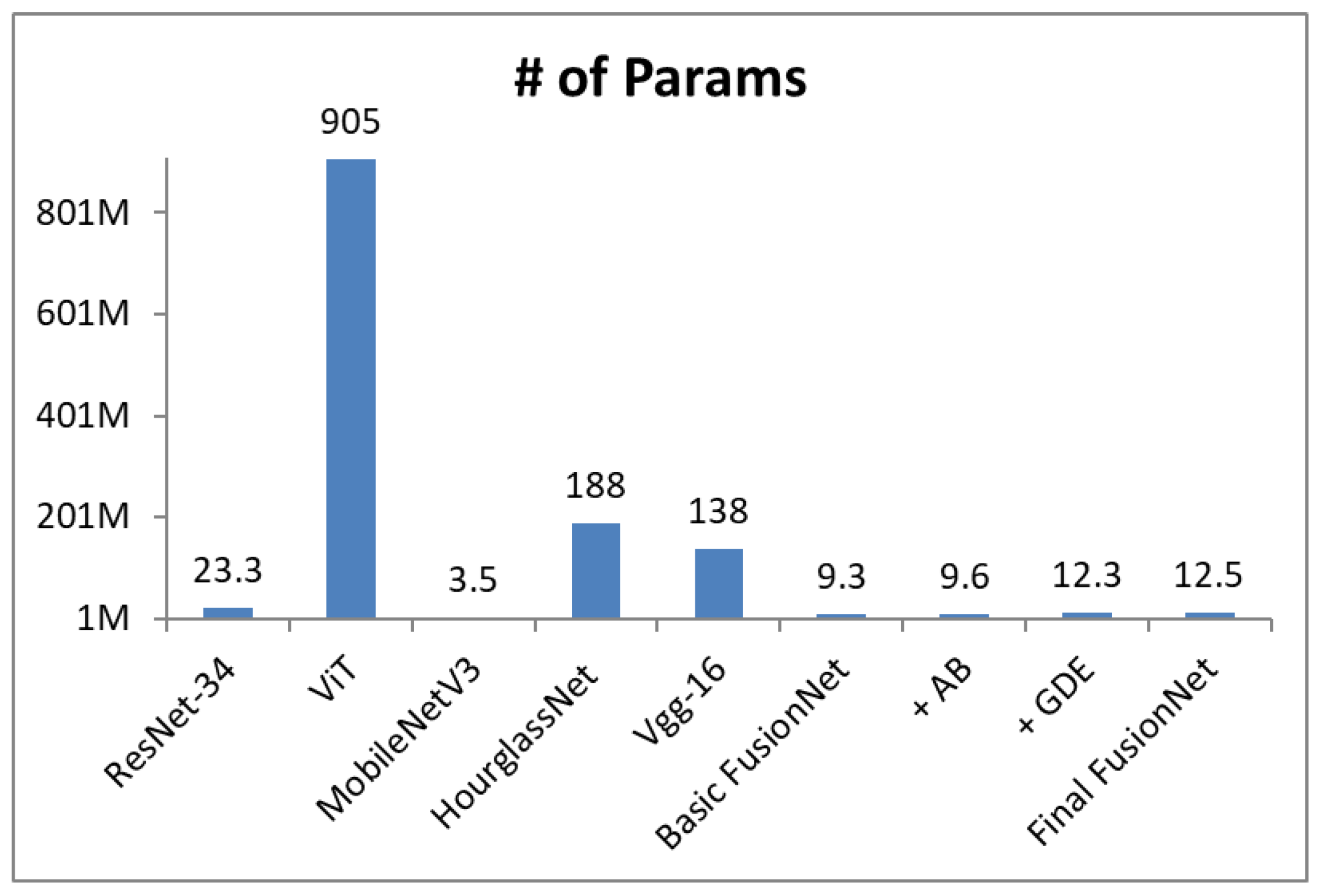
Figure 1). Instead, we increase the number of output channels of convolution at each stage to 80, 160, 304, and 680, respectively. This modification also has the advantage of increasing the nonlinearity of the network, allowing for the network learning of more complex features. For this reason, we omit the ReLU activation layer.
Inspired by [
9,
10,
18], the attention mechanism is introduced to improve the ability of CNN blocks to capture the context information. A non-local block is connected to the second 1 × 1 convolution layer, in which non-local operations enhance features by aggregating information from other locations. For model simplicity, the simplified non-local block proposed in [
10] is used. The simplified block is much lighter than the original non-local block, but with little decrease in accuracy.
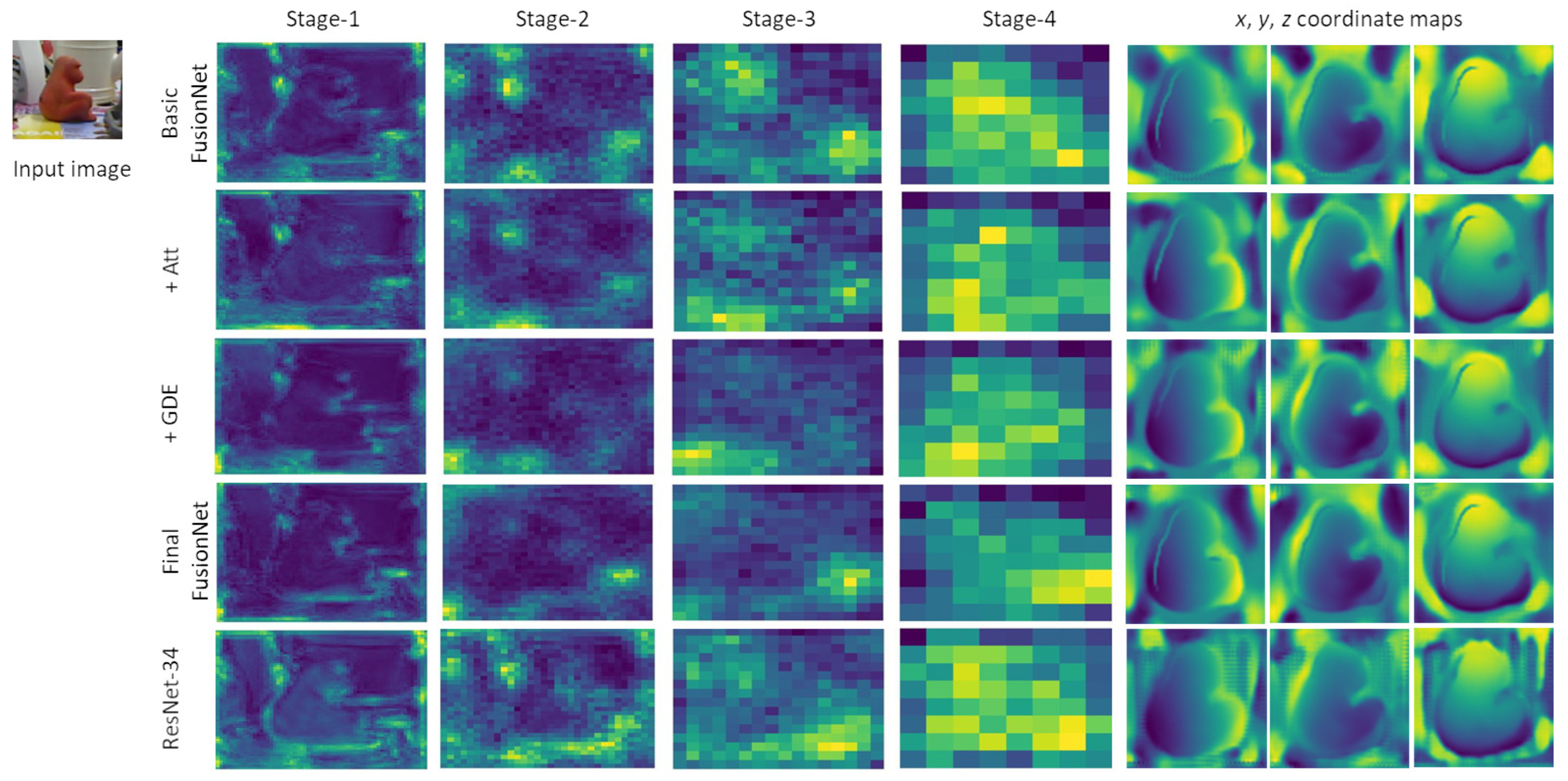
To investigate how FusionNet facilitates feature learning, we visualize feature maps generated at each stage and the resulting coordinate maps in
Figure 4. In the visualization, the regions of brighter colors correspond to stronger features. We can observe that our CNN blocks have similar capabilities to those of ResNet blocks in feature extraction. However, ResNet-34 has many bright regions, focusing on irrelevant objects. In contrast, FusionNet filters out unnecessary information using the attention block and more using GDE. This advantage allows for FusionNet obtaining more reliable coordinate maps, enabling more accurate pose estimation in the PnP block.
3.3. GDE
GDE has a similar structure to ViT’s Transformer encoder, but unlike ViT, it has only three standard Transformer blocks. In addition, GDE does not directly process the input image. Instead, it receives the convolutional feature map from CNN blocks and splits it into multiple patches which are then reshaped into 1D tokens. Next, the tokens are linearly projected, summed with position embeddings, and fed to the first standard Transformer block. For position embedding, we use 2D sine position embedding because it may help to generalize better the pose estimation of objects of different scales [
53]. GDE includes one 1 × 1 convolutional layer before the linear projection block and after the last Transformer block, respectively. The first one is to increase the number of channels in the input feature map, which allows us the capture of more features useful for pose estimation because each channel captures different features. The second one is to downsample the output dependency map by a factor of two to be concatenated with the feature map of Stage-3 as shown in
Figure 2.
To summarize, we first extract features via multi-stage convolutions. Then, long-range dependencies between the features are captured by self-attention mechanism in the Transformer blocks of GDE. Finally, the dependency map is reshaped and downsampled, concatenated with the output of the Stage-3, and input to the Stage-4 of Fusion-Net.
The GDE structure has two advantages in terms of efficiency. First, it allows us a simple building of a hybrid model with minor modifications to the CNN-based body while taking full advantage of the Transformer’s capabilities. Second, even if fusing two different architectures, it allows the light weight of the fusion model.
Unlike the attention block in the CNN blocks, GDE processes image blocks as sequence data at once, and explicitly encodes the dependencies of individual image blocks through the self-attention mechanism, which enhances the global understanding of feature maps. The attention block operates on a similar principle to GDE, but it calculates the contribution of individual convolutional localizations. This also explains why CNNs have a hard time mitigating the problem of weak long-range dependencies even when combined with attentions, whereas Transformer is better at capturing long-range dependencies.
4. Experimental Results and Discussion
4.1. Datasets and Metrics
We used the LINEMOD dataset [
54] consisting of 13 sequences for testing and training, each sequence containing approximately 1.2 K images annotated with 6D poses and 2D bounding boxes of a single object. A 3D CAD model of each object was also provided. The images were divided into training and test sets according to [
43], with approximately 200 images per object for training. For data augmentation, we used the same synthetic data as in CDPN [
55]. We used two common metrics for evaluation: ADD(-S) and 2D reprojection error. ADD measures whether the mean 3D distance between object’s mesh vertices transformed by the ground-truth pose and by the predicted pose is less than a certain fraction of the object diameter. For example, ADD-0.1d determines that the predicted pose is correct when the distance is less than 10% of the object diameter and computes the percentage of images where the predicted pose is correct to all test images. A 2D reprojection error is the mean distance between the 2D projection of the object’s 3D mesh vertices applying the predicted and the ground-truth pose, and the predicted pose is correct if the error is less than 5 pixels. For both metrics, we measure the percentage of images where the object pose is estimated correctly.
4.2. Experimental Setup
For the convenience of implementation, FusionNet was implemented based on the open source code of EPro-PnP [
20]. Our source code is accessible at
https://github.com/helloyuning/FusionNet (accessed on 22 August 2023). For fair comparison, the general settings were the same as in EPro-PnP, except that we replaced the dense correspondence network with our FusionNet. The implementation was performed with PyTorch on a desktop computer (i7 2.5 GHz CPU and 32 GB RAM) with a single RTX 2060 GPU. For training, the RMSProp optimizer with
,
, and
was used. The learning rate was set to
and the number of epochs was 320. We adopted the fine-tuning strategy of EPro-PnP. FusionNet was first pre-trained on the ImageNet dataset [
56] for image classification. The pre-trained model was then used as a backbone for CDPN and fine-tuned on the LINEMOD dataset for pose estimation. Finally, the fine-tuned model was combined with the EPro-PnP head for end-to-end pose estimation and fine-tuned again on the LINEMOD dataset for pose estimation.
Unfortunately, due to equipment limitations, it was not possible to use the entire ImageNet dataset to obtain the pre-trained model. Therefore, we only used 300 images for each of the 1000 categories of ImageNet dataset to obtain the pre-trained model. We also decreased the training batch size from 32 to 16. This is why the accuracy of CDPN and EPro-PnP is lower in our results, compared with those reported in the previous studies. Therefore, we focused on showing the superiority of FusionNet relative to CDPN and EPro-PnP in the same conditions. In our experiments, we found that the performance of the fine-tuning strategy used in EPro-PnP and FusionNet is heavily dependent on the accuracy of the pre-trained model. Therefore, in order not to be overly influenced by the pre-trained model for a fair comparison, we also trained all the models from scratch and compared their performance.
4.3. Ablation Study
Compared to the baseline EPro-PnP model, FusionNet has three modifications: a newly designed CNN building block, introduction of an attention block within the CNN block, and introduction of GDE. Therefore, we analyzed how each modification contributes to the performance of FusionNet. Therefore, in the following tables, “EPro-PnP” represents the original EPro-PnP model with no modifications, “Basic FusionNet” represents the EPro-PnP model of which the ResNet blocks are replaced with the newly designed CNN blocks, and “Final FusionNet” represents the EPro-PnP model with all three modifications. In addition, “ViT-PnP” represents the ViT model of which the head was changed to the EPro-PnP header (
Figure 3) for 6D object pose estimation.
Table 1 shows the contribution of each modification, where we trained the models from scratch for a fair comparison and to eliminate the effect of pre-training. The followings can be observed from the results:
The original EPro-PnP model uses ResNet-34 as a backbone, and in our experiments, it seemed to rely heavily on model initialization. When trained from scratch, the ADD-0.1d score remained at 73.78.
Using Transformers alone without the help of CNNs in the EPro-PnP framework significantly reduced accuracy. The ADD-0.1d score decreased by 27.16.
Replacing the ResNet blocks in EPro-PnP with our CNN blocks significantly improved accuracy. The ADD-0.1d score increased to 77.63.
The performance of Basic FusionNet was further improved when the attention block and the GDE were added. The ADD-0.1d score increased to 79.38 and 81.86, respectively. Finally, when both were included, the performance was most improved. The ADD-0.1d score increased up to 83.07.
In GDE, we used 2D sine position embedding instead of 1D learnable position embedding used in ViT. This also contributed to improved performance, increasing the ADD-0.1d score by 0.69.
We then conducted the same ablation study on the trained models with pre-training. The results are shown in
Table 2, and the followings can be observed:
The performance of EPro-PnP was significantly improved with pre-training, e.g., from 73.78 to 92.61 at the ADD-0.1d score.
Pre-training also contributed to FusionNet’s performance improvement, but not as dependent as EPro-PnP. The ADD-0.1d score of Final FusionNet increased from 83.07 to 93.48.
It is clear that the three modifications resulted in significant performance improvements over EPro-PnP.
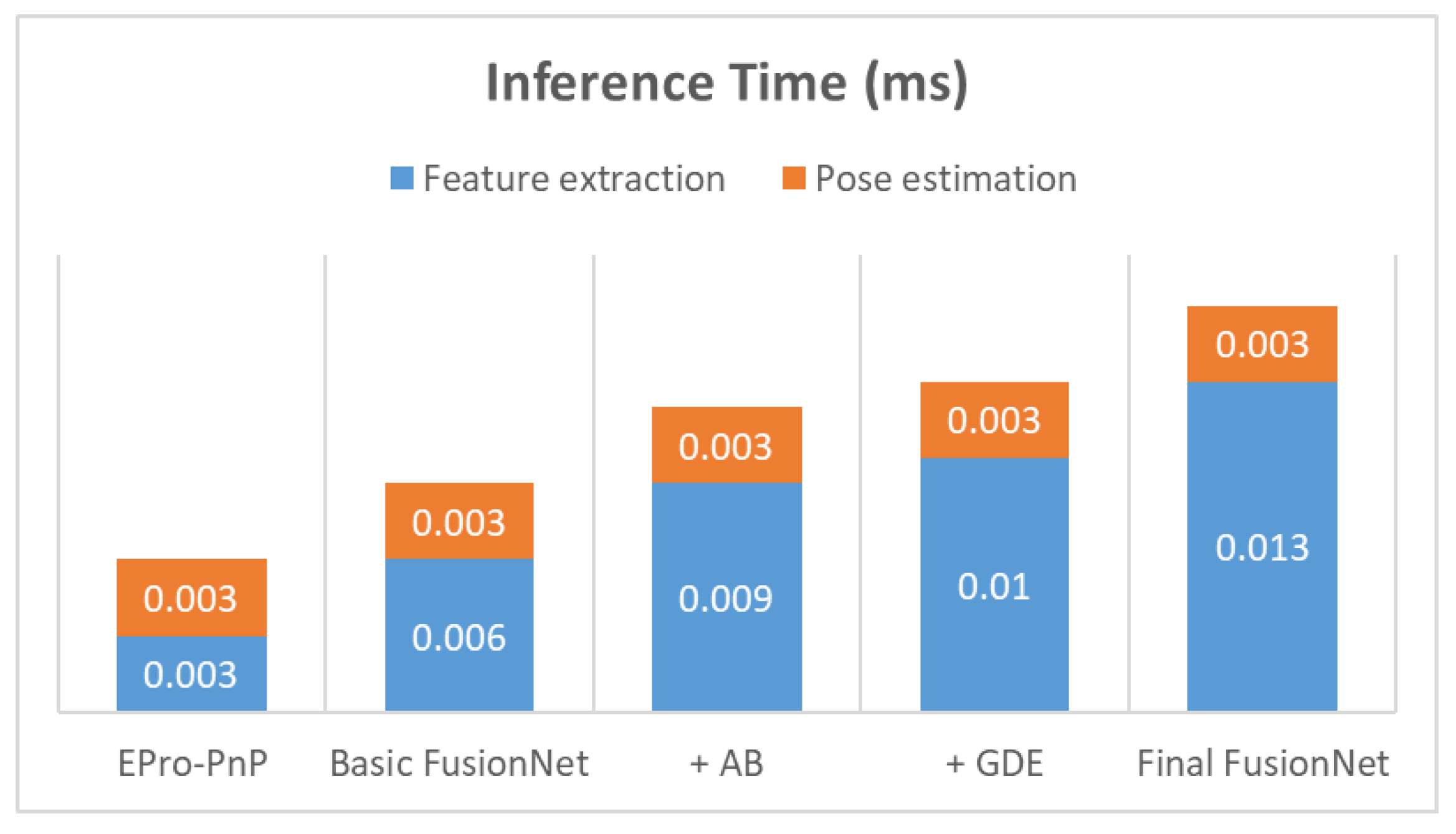
Figure 5 shows the inference time of each model. Basic FusionNet was 1.5 times slower than EPro-PnP. The reasons are as follows: First, it has more CNN blocks in each stage than EPro-PnP (
Figure 2); Second, its CNN building block has one more convolution layer than EPro-PnP’s ResNet building block; Third, each convolution layer has more output channels than EPro-PnP. Final FusionNet has more processing blocks (AB and GDE take 3 ms and 4 ms, respectively); thus, is slower than Basic FusionNet. As a result, Final FusionNet requires approximately 2.67 times longer inference time than EPro-PnP. However, Final FusionNet is still fast (>62 fps) enough to operate in real time.
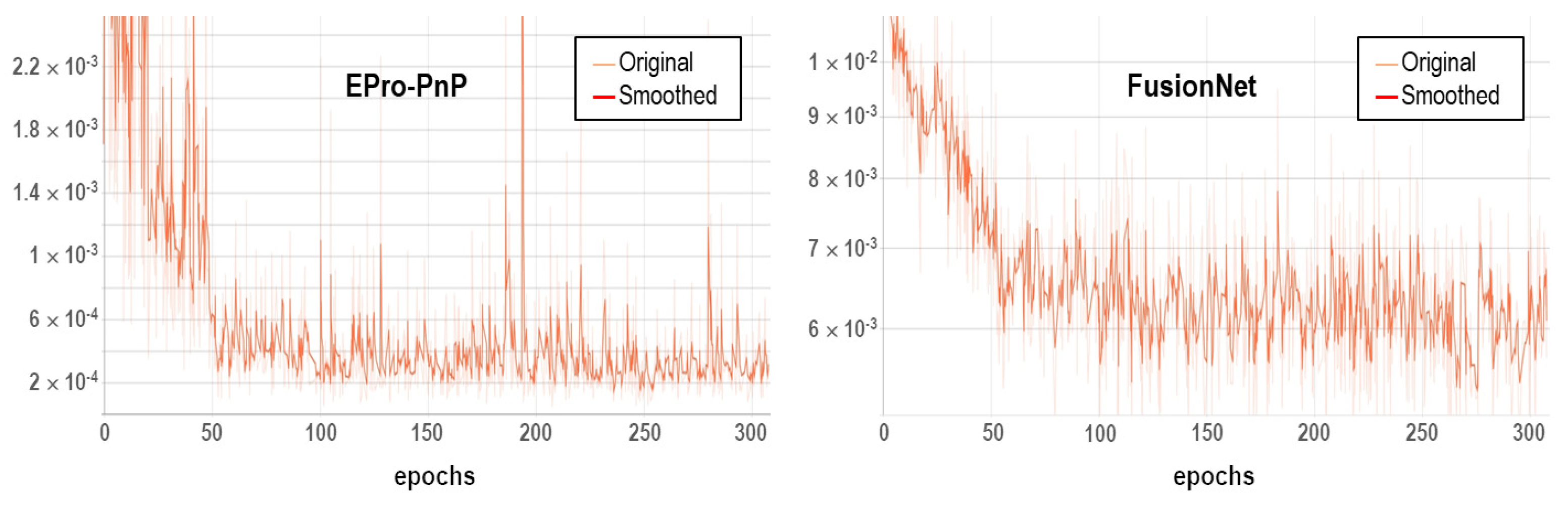
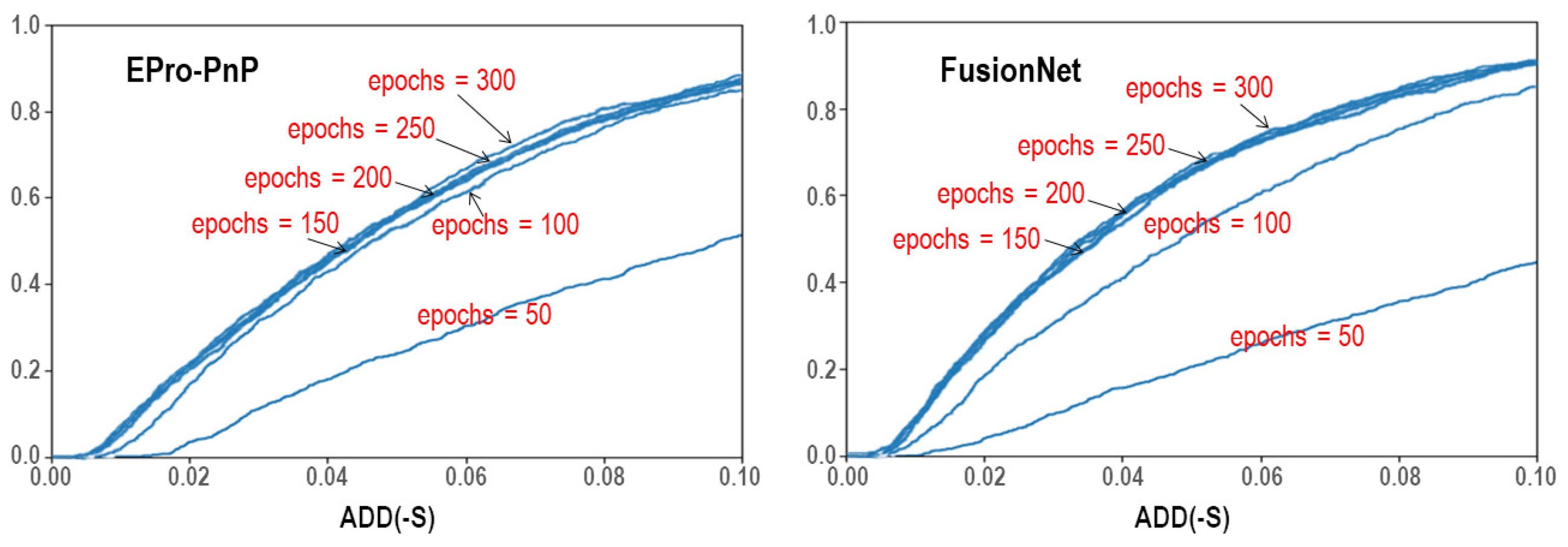
To ensure that the models were properly trained, the training errors over the number of epochs are visualized in
Figure 6. In addition, to verify their generalization capabilities, the validation accuracies are visualized in
Figure 7. For both EPro-PnP and FusionNet, the rate of decline decreased, but the training errors decreased steadily. The validation accuracies also steadily increased as the number of epochs increased. This means that the models were properly and sufficiently trained with good generalization capabilities. In terms of the training speed, FusionNet with the Transformer architecture was slower than EPro-PnP.
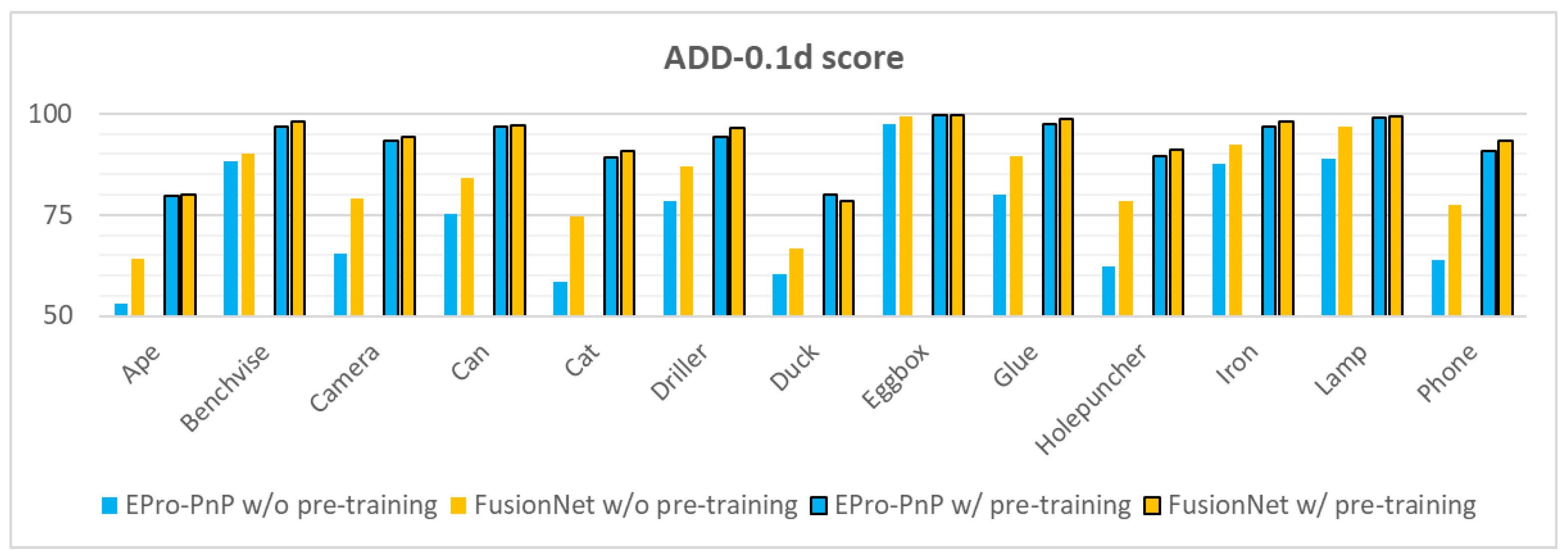
Table 3 shows object-wise ADD-0.1d scores of FusionNet. Although object-dependent, each modification had a positive effect on most objects, and Final FusionNet, which included a combination of three modifications, received significantly higher ADD scores than EPro-PnP for all objects. The degree of improvement can be observed more clearly in
Figure 8. The tendency has hardly changed with or without pre-training except for “Duck” and “Eggbox”. However, we observed a difference in the overall dependence of each model on pre-training. For each object, the ADD scores significantly increased with pre-training. However, FusionNet had a weaker dependence than EPro-PnP, which is good for the practical use of the model. In fact, the pre-training is tedious and time consuming, particularly in our pre-training process where the model needs to be pre-trained twice using the ImageNet and LINEMOD datasets.
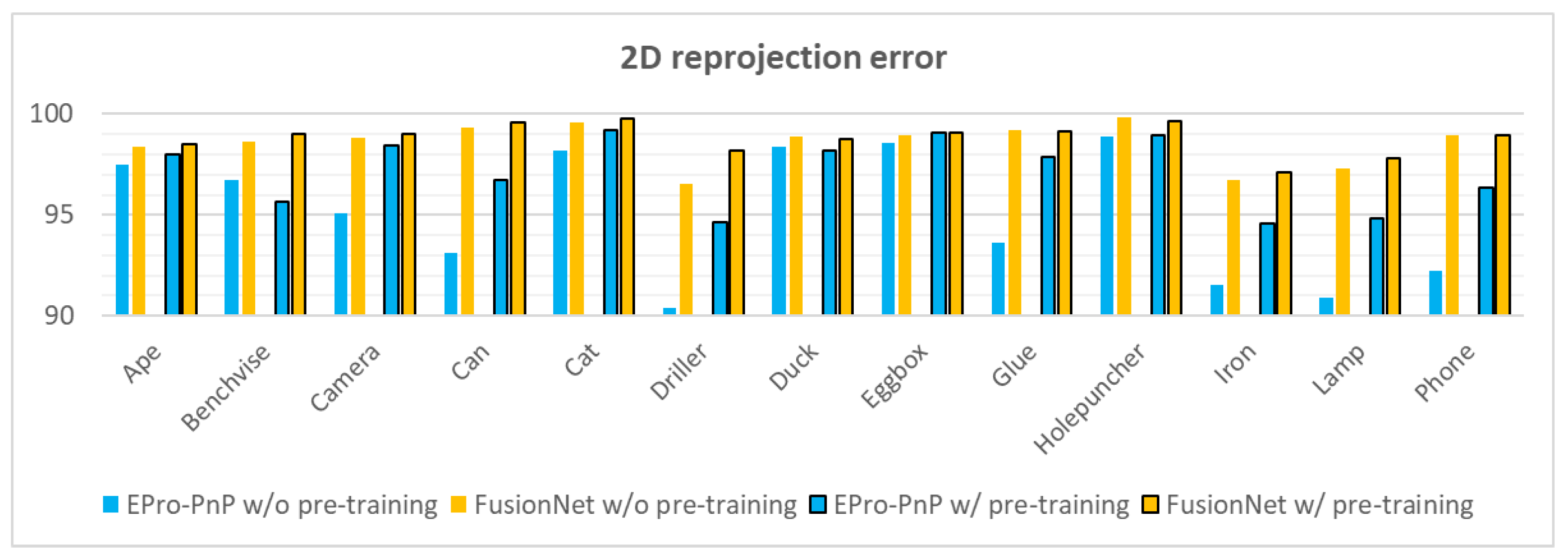
Table 4 shows 2D reprojection errors of FusionNet with and without modifications. Even the resulting values of the baseline model (EPro-PnP) are high (>90), so the degree of improvement does not seem significant, but all the modifications contributed to further increasing the values for most objects. The degree of improvement is clearly observed in
Figure 9. The weaker dependence of FusionNet on pre-training was also observable. However, unlike the ADD scores, we found it difficult to interpret. For some objects, although each modification individually contributed to improving the performance of EPro-PnP, when all modifications were applied, the performance was rather lower than when some of the modifications were applied. This became more severe with pre-training. We believe that the reasons for this should be analyzed in depth, so we leave it for further research.
4.4. Comparison with Other 6D Object Pose Estimation Methods
In
Table 5, the results of CDPN, EPro-PnP, and FusionNet were obtained in our experiments and the others were brought from the related papers. Although CDPN and GDR-Net used additional synthetic image datasets for training, all the results were obtained using the same publicly available train and test datasets. All the methods performed pre-training using the ImageNet dataset, but for CDPN, EPro-PnP, and FusionNet, the entire ImageNet dataset was not used.
As mentioned earlier, we could not obtain pre-trained models using the entire ImageNet dataset due to equipment limitations. However, as shown in
Table 5, FusionNet achieved comparable accuracy to that of methods (such as HybridPose and GDR-Net) with pre-training using the entire ImageNet dataset, despite pre-training using only a small portion of the ImageNet dataset. This demonstrates the great potential of FusionNet, and it is expected that pre-training FusionNet using the entire ImageNet dataset will result in higher accuracy. The accuracy of GDR-Net may be due, in part, to the use of additional synthetic training datasets. Considering these points, we can say that FusionNet outperforms other methods without pose refinement. Under the same conditions, FusionNet achieved higher accuracy than EPro-PnP, which provides state-of-the-art performance using only RGB images without pose refinement. DPOD and PVNet+RePOSE have shown that pose refinement can significantly increase accuracy. However, their accuracies were much lower than that of FusionNet without pose refinement. Since PVNet focused on occlusion handling, it seemed to be less accurate without the refinement by RePOSE on the LINEMOD dataset with no or mild occlusion.
Table 6 shows object-wise ADD-0.1d scores of 6D object pose estimation methods. The GDR-Net does not provide the object-wise scores and DPOD and PVNet+RePOSE do not provide the object-wise scores without pose refinement. FusionNet achieved object-dependent but comparable accuracy to that of DPOD and PVNet+RePOSE, without pose refinement. Except for “Duck” and “Eggbox”, FusionNet consistently achieved better accuracy than EPro-PnP.
Figure 1 shows the number of model parameters of FusionNet and the backbone networks commonly used in vision tasks. We can see that FusionNet is very lightweight despite the state-of-the-art performance shown in the previously presented results. Compared to ResNet-34, which is the most popular backbone, FusionNet has nearly 2× fewer model parameters even after fusing the Transformer (GDE). This efficiency stems primarily from our CNN blocks replacing ResNet blocks. In addition, despite significant contributions to FusionNet’s performance improvement, the attention block and GDE slightly increased the model parameters. Compared to ViT, FusionNet has nearly 75× fewer model parameters, which demonstrates the efficiency of FusionNet for practical use under real-world conditions.
4.5. Discussion and Limitations
There are a few things that need to be discussed and confirmed. First, existing PnP-based 6D object pose estimation methods have continuously improved feature extraction capabilities using CNNs of various architectures, but there is still room for improvement. This is the main motivation of this study. From the results presented above, we confirmed that FusionNet achieved more accurate pose estimation by improving the feature extraction capability of EPro-PnP. Second, the strategic introduction of Transformers into convolutional structures was expected to facilitate global features extraction, which plays a critical role in object pose estimation. From the experimental results, we confirmed that the GDE block of Transformer structure contributed to FusionNet achieving higher accuracy in pose estimation. Third, this study assumed that object areas are accurately detected in advance. However, object areas are often detected incorrectly due to incompleteness of object detection methods, occlusion, small size, and so on. Incorrect detection of object areas negatively affects FusionNet’s performance, but it was not considered in this study. Fourth, in this study, the GDE block was simply designed using only three standard Transformer blocks for the model efficiency of FusionNet. However, for higher accuracy in pose estimation, it can be designed by stacking more Transformers with advanced architectures. The design optimization of GDE is beyond our scope and was not considered in this study.
Experimental results on the performance of FusionNet show that FusionNet has some limitations. FusionNet’s performance is still highly dependent on tedious and time-consuming pre-training. With the introduction of Transformer, training time has increased significantly, approximately doubling the training time of EProPnP. FusionNet is lighter than ResNet-based models, including EPro-PnP, but its longer inference time can be another obstacle to the practical use of FusionNet.
5. Conclusions and Future Work
In this paper, we proposed FusionNet, which is a mixture of CNN and Transformer, to take advantages of both architectures. The newly designed CNN blocks with attention mechanism enabled FusionNet to efficiently extract informative features for 6D object pose estimation. The newly designed Transformer, GDE, helped FusionNet explicitly capture the long-range dependencies. As a result, FusionNet achieved high accuracy in 6D object pose estimation on the LINEMOD dataset while significantly reducing the model parameters. It outperformed other 6D object pose estimation methods, including EPro-PnP, which achieved state-of-the-art performance in 6D object pose estimation using RGB images.
However, as mentioned in
Section 4.3, FusionNet behaved unexpectedly for some objects, when all the proposed modifications were applied. We need to analyze the results in depth and find ways to further improve FusionNet’s performance through future study. In addition, as mentioned in
Section 1, we stated that FusionNet can be used in other vision tasks by changing the heads; thus, applying FusionNet to other vision tasks and analyzing its performance would be an interesting future study topic.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}