Abstract
Wireless traffic prediction can help operators accurately predict the usage of wireless networks, and it plays an important role in the load balancing and energy saving of base stations. Currently, most traffic prediction methods are centralized learning strategies, which need to transmit a large amount of traffic data and have timeliness and data privacy issues. Federated learning, as a distributed learning framework with no client data sharing and multi-client collaborative training, can solve such problems. We propose a federated learning wireless traffic prediction framework based on mutual information clustering (FedMIC). First, a sliding window scheme is used to construct the raw data into adjacent and periodic dual-traffic sequences and capture their traffic characteristics separately to enhance the client model learning capability. Second, clients with similar traffic data distributions are clustered together using a mutual information-based spectral clustering algorithm to facilitate the capture of the personalized features of each clustered model. Then, models are aggregated using a hierarchical aggregation architecture of intra-cluster model aggregation and inter-cluster model aggregation to address the statistical heterogeneity challenge of federated learning and to improve the prediction accuracy of models. Finally, an attention mechanism-based model aggregation algorithm is used to improve the generalization ability of the global model. Experimental results show that our proposed method minimizes the prediction error and has superior traffic prediction performance compared to traditional distributed machine learning methods and other federated learning methods.
1. Introduction
The rapid development of mobile communication technology and the continuous expansion of network scale have led to the explosive growth of traffic data, and the load of the network grows at a high speed. How to optimize the communication network structure, guarantee the network service quality, and improve the network performance are the key concerns of the new generation network [1]. Wireless traffic prediction can help operators to predict the trend of network changes, so as to formulate network management programs in advance and intelligently allocate network resources to improve network services and enhance the user’s online experience. It can play an important role in application scenarios such as network load balancing, base station dormancy, and access control [2,3].
For network traffic prediction, some researchers use linear model prediction, such as the autoregressive-integrated moving average (ARIMA) model and its variants. However, this type of model requires stable data, while the actual network traffic is bursty, resulting in low accuracy of using this type of model. With the development of artificial intelligence, deep learning models have been widely used in traffic prediction tasks. The literature [4] used deep belief network models to predict network traffic, and the literature [5] proposed an ARIMA-BPNN (back propagation neural network) network traffic prediction method based on SA (simulated annealing) optimization, which obtains excellent prediction results. The literature [6,7] used Long Short-Term Memory Network (LSTM) and gated recurrent unit (GRU) for traffic prediction, which outperforms RNN. The literature [8] proposed a hybrid Temporal Convolutional Network (TCN) and LSTM traffic prediction model (ST-LSTM). TCN is used to discover the short-term dependence of data, LSTM is used to capture the long-term dependence, and filter is used to remove the data noise to achieve a higher accuracy prediction. There will be influence between the network nodes of the wireless network, and the network traffic has spatial characteristics. Many studies have considered the spatial characteristics of the traffic. The literature [9] used a densely connected convolutional neural network to capture the spatial and temporal dependencies of communication traffic. The literature [10,11,12] used graph convolutional neural networks to capture spatio-temporal features of network traffic.
All of the above traffic prediction methods are centralized learning, which requires a large amount of traffic data to be transmitted to a data center to learn a generalized prediction model. However, such methods take up network resources, increase communication overhead, and have low timeliness. Moreover, due to data privacy considerations, it is difficult to fully share the traffic data of operators. The data island problem brings challenges to network traffic prediction. Federated learning is emerging as a new distributed machine learning framework [13], bringing new solutions to traffic prediction. In the federated learning framework, clients participating in federated learning (such as base stations) can use local datasets to train local models, then upload local model parameters to the central server and train a global model for traffic prediction under the cooperation of the central server. The model parameters are transmitted between the server and the client instead of the original data, which effectively solves the problems of data privacy and communication overhead. However, the distribution of network traffic data from different base stations may be different, i.e., the traffic data are not independently and identically distributed (IID), and non-IID data are not favorable for federated learning [14,15]. Solving the data heterogeneity problem for federated learning traffic prediction is a challenge.
Based on the above research, we propose a federated learning wireless traffic prediction framework based on mutual information clustering (FedMIC), which is locally trained by a central server in collaboration with multiple edge clients. The framework first clusters the clients based on the mutual information of the models and achieves the following two levels of model aggregation by means of clustering: models aggregating within the same cluster yields a cluster model with personalized features, and cluster models aggregation yields a global model with full knowledge. Using a sliding window to preprocess the traffic data into two-channel traffic sequences and using dual LSTM to learn the adjacent and periodic characteristics of the traffic. An attention-based model aggregation algorithm is used to improve the generalization ability of the global model. In summary, the contributions of this paper are as follows:
- In order to improve the prediction accuracy of the client model, the sliding window mechanism is used to construct the raw traffic data into adjacent traffic sequences and periodic traffic sequences, and double LSTM is used to learn and integrate the adjacent and periodic characteristics of traffic to strengthen the learning ability of the model;
- To address the problem of data heterogeneity in federated learning traffic prediction, we propose a hierarchical aggregation architecture FedMIC. Clients with similar traffic distributions are clustered into one class using a mutual information-based spectral clustering algorithm to capture their unique traffic models. The models within a cluster are first aggregated to obtain a cluster model with individualized characteristics, and later the cluster models are aggregated to obtain a global model for traffic prediction;
- In order to improve the generalization ability of the global model, a model aggregation algorithm based on the attention mechanism is used. By considering the client’s contribution at the time of aggregation to give weight to its aggregation, the aggregated model has better predictive performance;
- Experiments are conducted on three different types of traffic data on publicly available real datasets to validate the effectiveness of the hierarchical aggregation architecture, the spectral clustering algorithm based on mutual information, and the model aggregation algorithm based on the attentional mechanism, and to compare them with existing methods.
The rest of this paper is organized as follows: Section 2 introduces the related research on federated learning methods for traffic prediction and the related theory of mutual information. The third part introduces our proposed framework and method, including data preprocessing, the overall implementation process of the framework, and the specific implementation of clustering algorithm and model aggregation algorithm. Section 4 presents and analyzes the experimental results of the proposed method and compares it with other methods.
2. Related Work
Since the work of this paper is to propose a framework for federated learning traffic prediction based on mutual information clustering, we introduce the federated learning traffic prediction algorithm and the mutual information theory used by the clustering scheme in this section.
2.1. Federated Learning
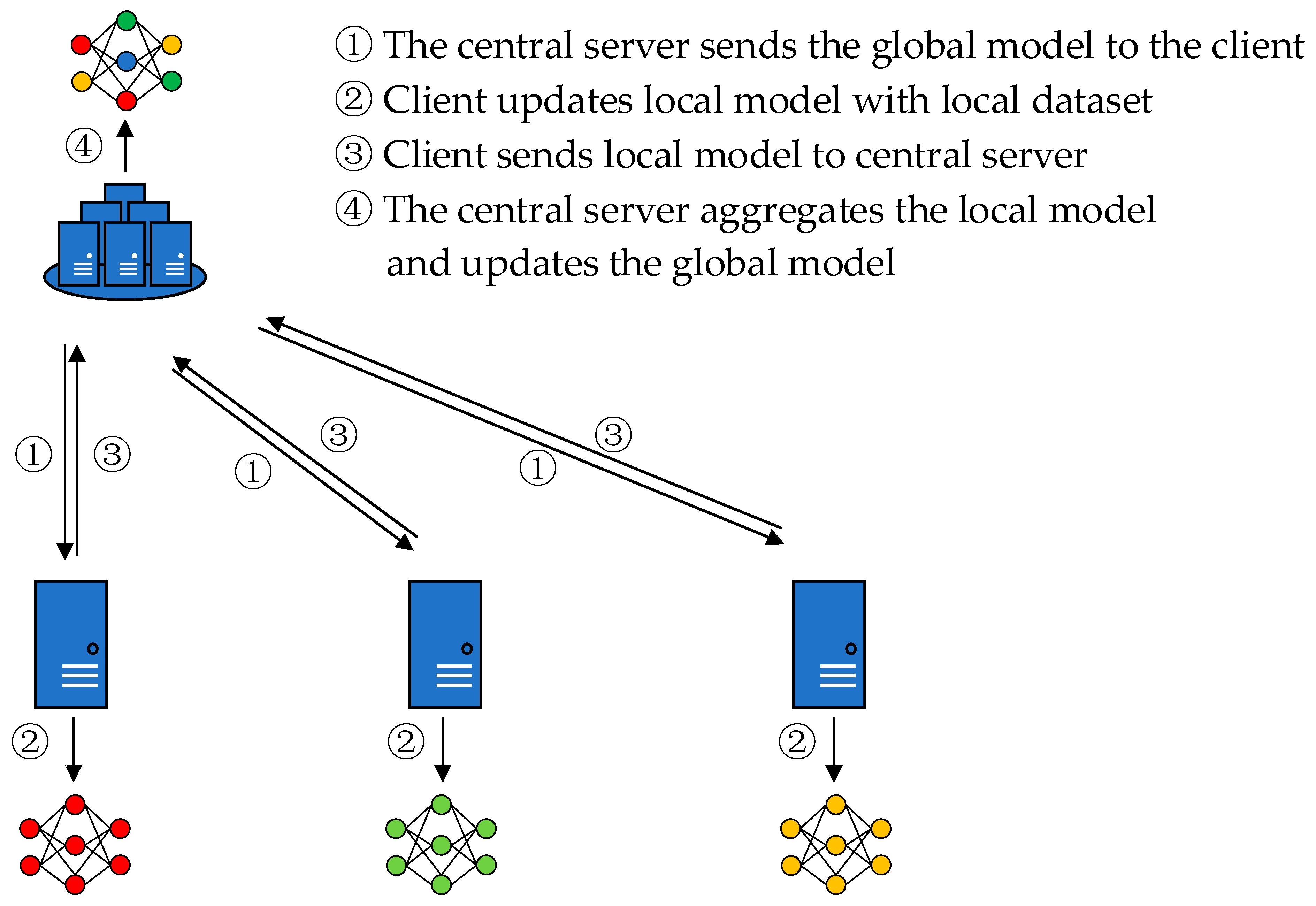
Federated learning is a distributed machine learning framework. Unlike traditional distributed learning, in federated learning, the clients’ data are not uploaded, but each of them trains its own local model and trains a global model in collaboration with a central server [16], so federated learning has the property of protecting data privacy, as shown in Figure 1. Firstly, the central server sends the global model to the client. Second, the client uses the local dataset to train the global model to obtain the local model. Then, the client uploads the local model to the central server. Finally, the central server performs model aggregation on the collected local models and updates the global model to complete a round of federated communication. This cycle repeats to obtain a global neural network model with wide applicability. It can be seen that in the federated learning framework, the communication between the server and the client is model parameters rather than original data, which effectively protects data privacy.
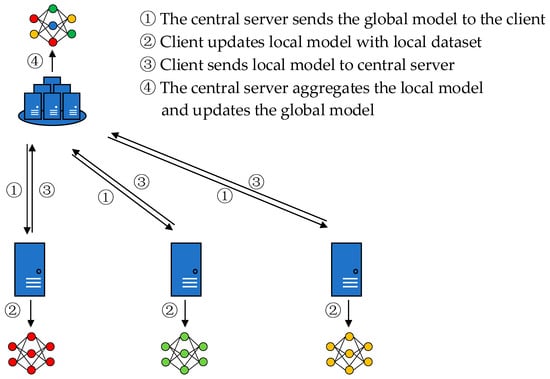
Figure 1.
Classical architecture for federated learning.
In the federated learning framework, the aggregation algorithm of the model is a key concern. Reference [17] proposed a federated average (FedAvg) algorithm to reduce the computational effort of the server, but FedAvg performs poorly for non-IID network traffic data processing and suffers from weight dispersion when performing model aggregation. The FedProx algorithm [18] limits the optimal distance between the local model and the global model through an adjustable regularization term. The FedNova algorithm [19] adaptively adjusts the number of local update steps. The FedAtt algorithm [20] considers the different contributions of different clients to the global model to improve the generalization ability of the global model. These algorithms are fine-tuned to FedAvg and have a limited effect on improving the model prediction performance in traffic prediction tasks. References [21,22] used a data sharing strategy to cope with the data heterogeneity problem of federated learning; however, the data sharing strategy still violates the data privacy protection principle of federated learning. Reference [23] proposed a federated learning framework for regional federation, where the center node only needs to communicate with the regional nodes, which reduces the communication cost. Reference [24] introduced meta-learning into the federated learning traffic prediction framework, which effectively ensures the personalized features of the local model and obtains a high prediction accuracy. Clustered federated learning [25,26,27] solves the data heterogeneity problem by discovering the similarity of data distribution dividing clients into different clusters and learning the personalized features of different clusters. References [21,28] reduce the statistical heterogeneity of federated learning by the clustering method, thus improving the performance of traffic prediction models.
2.2. Mutual Information
Mutual information is a measure used to evaluate the degree of interdependence between two random variables, responding to the correlation of two variables [29]. In federated learning, the communication between the client and the server is the model parameters rather than the raw data, so it is not possible to use the mutual information of the client’s data distribution to evaluate the similarity between the clients. In contrast, machine learning models in federated learning are essentially random variables whose parameters obey a specific data distribution [30], and thus the mutual information between model parameters can be computed to measure model similarity. Reference [31] proposed a mutual information-driven federated learning method that updates local models by minimizing the mutual information between local and aggregated models and selects the most efficient model aggregation based on the mutual information of local and global models. Reference [32] calculates the gradient trend similarity between the local training model and the global model through mutual information to improve the effectiveness of federated learning model parameter aggregation. These methods mainly calculate the mutual information between models based on indicators such as model training loss and training gradient. In our proposed federated learning traffic prediction framework, the similarity between models is computed using mutual information based on model parameters, thereby distinguishing homogeneous clients to achieve client clustering. For two different models and , the mutual information is as follows:
where and are the entropies of the model and , and is the joint entropy of the model. When the model variances obey a Gaussian function of the respective variances, the model mutual information can be calculated as follows:
where is the Euclidean distance between the features of models and . The model features can be reflected in the distribution of parameters in each layer of the model [33]. Therefore, the mutual information between the two models can be obtained by analyzing the similarity of the data distribution of the parameters of the two models. The larger the value of mutual information, the higher the similarity between the two models.
Inspired by the above studies, we propose a framework for federated learning traffic prediction based on mutual information clustering. Clients are clustered to obtain a global model for traffic prediction using a hierarchical model aggregation algorithm to address the statistical heterogeneity challenge of federated learning traffic prediction and improve the prediction accuracy of the model.
3. Proposed Framework and Methods
In this section, we first give the data preprocessing and model architecture of the edge client. It mainly uses two LSTMs to learn the characteristics of the two-channel data, respectively. Then, we introduce the implementation process of the FedMIC framework in general. It is a mode that implements model clustering first and then model aggregation; that is, learning the personalized characteristics of the model through clustering and improving the generalization of the global model through attention aggregation ability. Finally, we detail the implementation details of the mutual information-based spectral clustering algorithm and the attention mechanism-based hierarchical federated aggregation algorithm.
3.1. Data Preprocessing and Client Model
Given base stations, each base station collects a local dataset and updates a local model. The traffic dataset is divided into time slots, and represents the network traffic value of the -th base station in the -th time slot. Wireless traffic prediction is described as predicting future traffic values based on current and past traffic values. For the machine learning task of traffic prediction, can be expressed as the traffic value of the past adjacent time; that is, the input, and the model predicts the traffic at the current moment by learning the adjacent characteristics of the traffic.
Traffic data also has periodic characteristics. For example, the traffic at a certain moment is similar to the traffic at the same moment in the previous days. Therefore, the traffic value at the current moment can be predicted based on the traffic value at this moment in the previous days. In order to capture the periodic characteristics of traffic to enhance the learning ability of the model, the original traffic data is processed into adjacent traffic sequences and periodic traffic sequences by using the sliding window mechanism; that is, the input features are redefined as . Among them, is the number of adjacent time stamps in the past, represents the number of adjacent periods, and represents the number of periods.
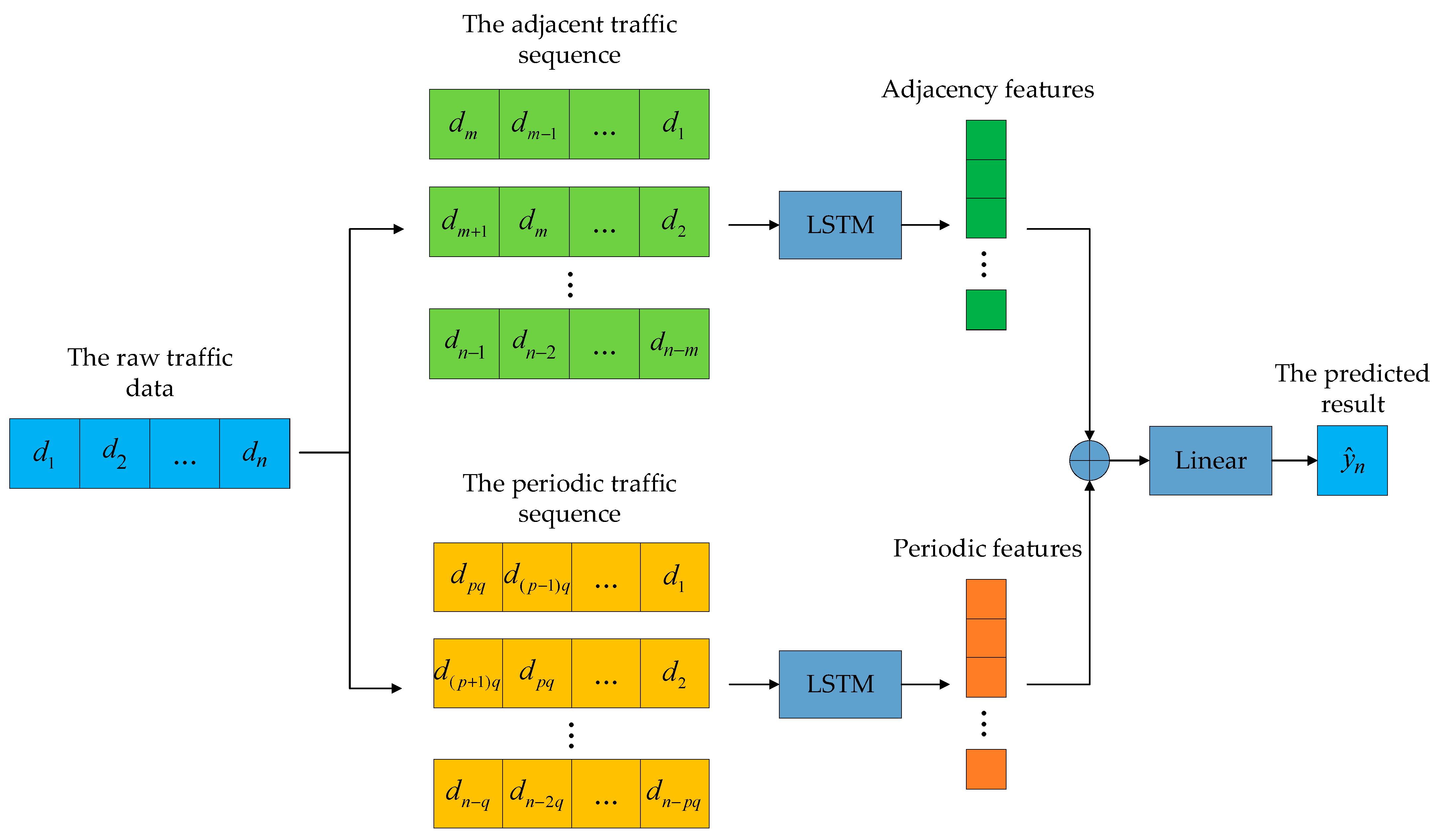
LSTM is a lightweight recurrent neural network. Its core lies in the memory cells and the “gate” structure that can selectively pass on the important information in the sequence, so as to accurately mine the features of the traffic sequence. It is well suited as a traffic prediction model for local clients; therefore, the local client uses the LSTM-based model. The client traffic prediction model is shown in Figure 2. First, the local raw traffic data are preprocessed into adjacent traffic sequences and periodic traffic sequences using the sliding window mechanism. Then these two kinds of sequences are input into the LSTM model, and the two LSTMs capture their adjacency and periodic features, respectively. Finally, the two features are fused by summing and then mapped by linear layers to obtain the predicted values.
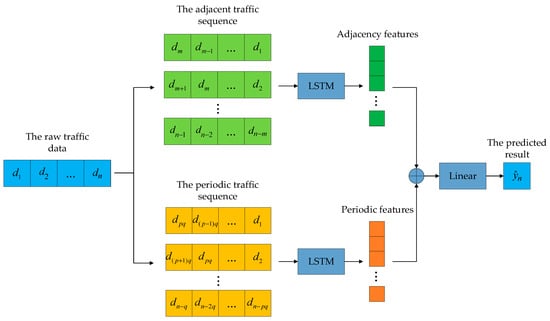
Figure 2.
Client traffic prediction model.
3.2. FedMIC Traffic Prediction Framework
The goal of the centralized machine learning model training approach is to collect the traffic data of all clients together to train a highly accurate prediction model, and then use this model to predict the traffic of all clients and minimize the prediction error as much as possible. In contrast, the goal of our proposed federated learning approach is to locally train the edge clients under the orchestration of a centralized server and obtain a global model through the model aggregation method. Using this global model to predict the traffic of clients and minimize their average error can be defined as follows:
where is the traffic prediction model, is a parameter of the model, and is the loss value function between the predicted value and the true value .
The implementation of the FedMIC framework is shown in Algorithm 1.
| Algorithm 1: Implementation of FedMIC. |
| Input: The wireless traffic data ; Initialized global model ; Fraction of selected BSs ; Learning rate of local model . |
| Output: Global model . |
| 1 for each client do |
| 2 Load initialized global model: |
| 3 Client local training, upload model parameters |
| 4 Obtain cluster label by spectral clustering based on mutual information |
| 5 for each round do |
| 6 |
| 7 Sample a set of clients |
| 8 for each client do |
| 9 Load global model: |
| 10 |
| 11 for cluster do |
| 12 Obtain by federated aggregation based on attention mechanism |
| 13 Obtain by federated aggregation based on attention mechanism |
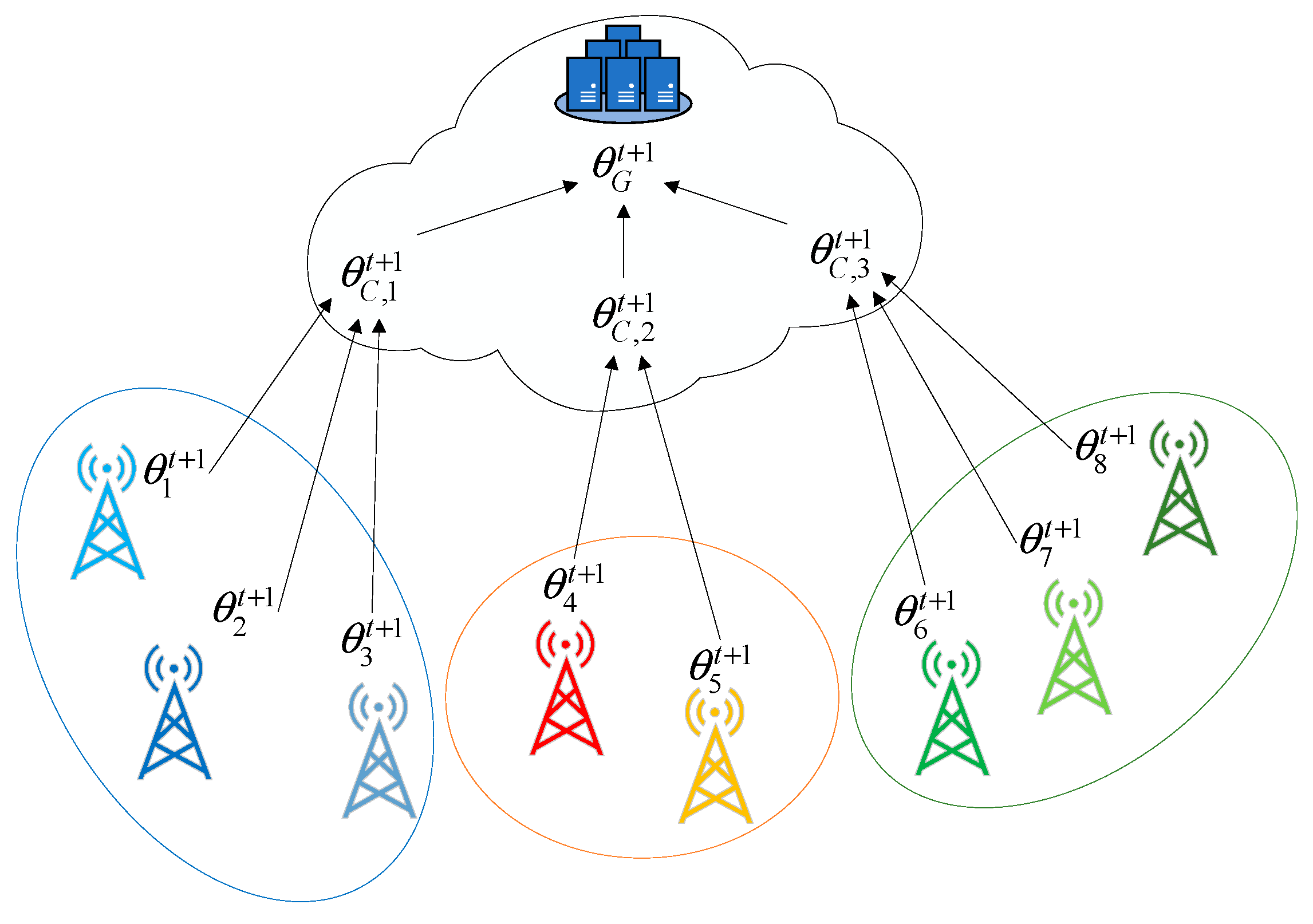
First, before the federated learning starts, all clients load and initialize the global model to train the local dataset, and upload the trained model to the central server. The central server uses the spectral clustering algorithm based on mutual information to realize the clustering of models. That is, it calculates the mutual information between the client models to obtain a similarity matrix, and implements spectral clustering based on the mutual information similarity matrix to obtain the cluster label of the client model. In the subsequent federated learning, a set of is randomly selected for each round of training and denoted as , and represents the hyperparameter of the number of clients selected in each round. For each round of federated learning clients, first clients load the global model, then train the local data, and upload the trained model to the central server. The central server implements a hierarchical aggregation model. As shown in Figure 3, the models within each cluster are first aggregated to obtain the cluster model , and then the cluster models are aggregated to obtain the global model . Model aggregation uses an attention-based aggregation algorithm.
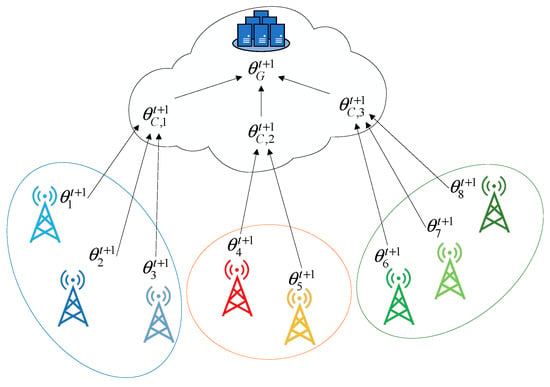
Figure 3.
Hierarchical model aggregation architecture.
3.3. Spectral Clustering Based on Mutual Information
We adopt the method of first clustering and then aggregation to obtain the global model. Clients with similar traffic data distributions are classified into one group by spectral clustering method based on mutual information to capture their unique traffic patterns. If all models are directly aggregated without clustering, the global model obtained in this way cannot capture some personalized characteristics hidden in the data, resulting in poor prediction results.
Clusters are partitioned using a spectral clustering algorithm. The spectral clustering algorithm evolved from graph theory, and it is more adaptable to data distribution than algorithms such as K-means. The essence of the spectral clustering algorithm is to transform the clustering problem into the optimal partition problem of the graph, and regard each object in the dataset as a vertex of the graph, and the vertices are connected by edges. The similarity of vertices is quantified as the weight of the edge connecting the corresponding vertices, and the closer the distance between the points with larger weight, the higher the similarity. The division criterion is to maximize the internal similarity of the divided subgraphs and minimize the similarity between subgraphs.
At the beginning of federated learning, the central server performs spectral clustering based on mutual information after receiving the models uploaded by all clients. The steps of the algorithm are as follows:
| Algorithm 2: Spectral Clustering Based on Mutual Information. |
| 1 Input: Client model parameters , number of clusters |
| 2 Compute the mutual information between models |
| 3 Compute the similarity matrix and the degree matrix D based on |
| 4 Compute the Laplace matrix |
| 5 Compute the first c eigenvectors of |
| 6 Let be the matrix containing the vectors , namely, |
| 7 for , let be the vector corresponding to the i-th row of U |
| 8 Cluster the points in with K-Means algorithm into |
| 9 Output: |
First, the mutual information between the models is calculated by Equation (2). Based on the mutual information, the similarity matrix and degree matrix are constructed and computed to obtain the Laplace matrix . Then, the first eigenvectors of the smallest eigenvalue of the Laplace matrix are computed and the eigenmatrix is constructed. Finally, each row of is used as a sample for K-means clustering to obtain the clustering clusters .
The mutual information between models reflects the similarity of client traffic distribution. The similarity matrix constructed with the mutual information of model parameters maximizes the mutual information between models within a cluster and minimizes the mutual information between cluster models. This achieves a better clustering effect and makes the learned personalized features more accurate.
3.4. Model Aggregation Based on Attention Mechanism
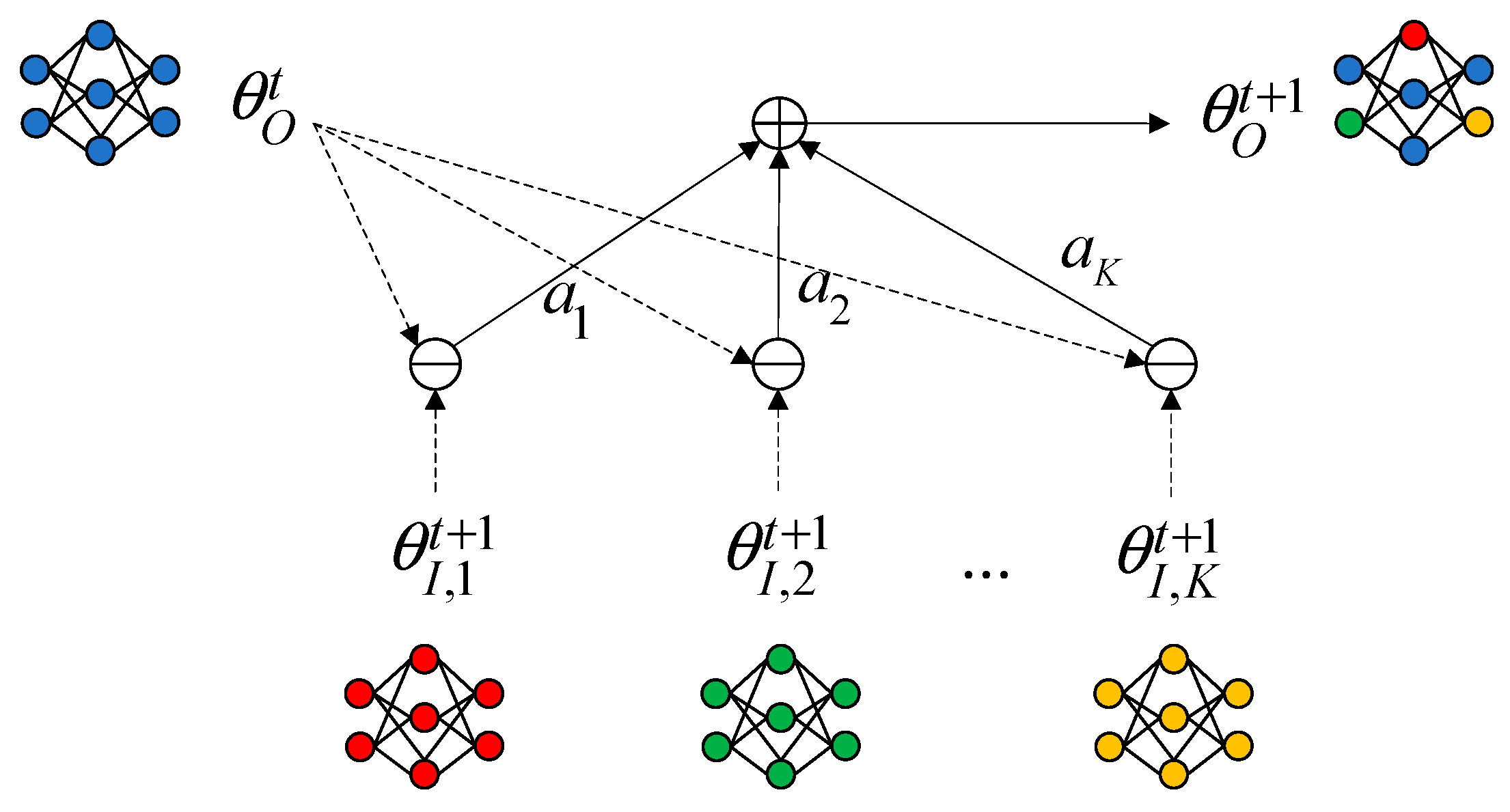
The purpose of model aggregation is to obtain an optimal global model, which has strong generalization ability and can well summarize the features of all client models. The classical FedAvg aggregation algorithm averages the parameters of the client models for aggregation. While the variability of traffic distribution makes the distribution of client model parameters vary widely, the global model obtained by aggregation is far away from the client model and cannot predict the traffic of each client well. We use a model aggregation method based on attention weights, as shown in Figure 4.
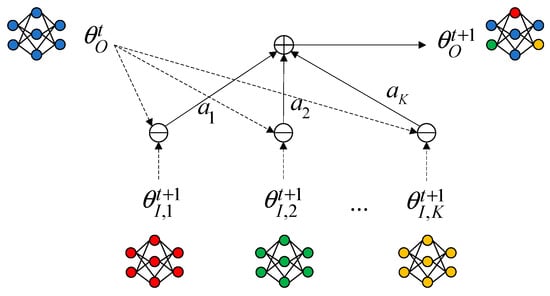
Figure 4.
Model aggregation based on attention mechanism.
In each round of aggregation, the input models are given adaptive weights by considering the importance of the input models selected for aggregation in the aggregation. The distance between the aggregated global model and the input models is minimized, and the generalization performance of the global model is enhanced. The optimization objective of attention aggregation is defined as follows:
where is the distance between the global model parameter and the input model parameter before aggregation, and is a weight vector that measures the size of the input model’s contribution in the aggregation. We use the attention mechanism to compute , i.e., the global model parameters are used as queries and the input model parameters are used as keys, and compute the attention score for each layer of the neural network model. The -th layer parameter of the global model is denoted as , the -th layer parameter of the -th input model is denoted as , and the distance between the global model and the input model can be computed as the number of paradigms of their difference, which is denoted as follows:
Then use the softmax function to normalize to obtain the attention weight of the k-th model. The normalization steps are as follows:
Use ’s Euclidean distance to derive the objective function (4) to obtain the gradient . Let be the step size of the gradient update, then the formula for updating the global model is as follows:
4. Experiments
In this section, we do a lot of experiments to verify the effectiveness of our method. We first introduce the datasets, experimental settings, baseline methods, and evaluation criteria used in this paper. In order to verify the high performance of the proposed method, we compare the proposed method with the existing methods, and finally give the experimental results and performance analysis.
4.1. Dataset
The dataset used in this paper comes from the big data challenge initiated by Telecom Italia. It is mainly the call detail records (CDR) of the province of Trentitto from 4 November 2013 to 29 December 2014, including Internet services, voice calls, and SMS. The province of Trentito is divided into 6259 cells. In the following experiments, we will represent each cell as a base station, and each base station will be used as a federated learning client to collect data and train local models. In order to avoid data sparsity, the sampling time of traffic data is reset to once an hour. The traffic data of the first 7 weeks is used as the training set and the data of the last week is used as the test set.
4.2. Experimental Setup
We randomly select 100 base stations from the dataset as experimental objects. The local client and the central server perform 100 rounds of federated learning, and each round of federated learning randomly selects 10 clients. Data samples are constructed using the sliding window mechanism. The number of adjacent timestamps is set to three, i.e., the traffic in the last three hours of the current timestamp is taken as an adjacent traffic sequence. The number of adjacent periods p is set to three and the number of periods q is set to 24, i.e., the traffic in the last three days of the current timestamp is taken as a periodic traffic sequence.
The client model uses stochastic gradient descent (SGD) with a learning rate set to 0.01. The local batch size is set to 20, and the local data are trained twice to better learn periodic features. The number of hidden layers of the LSTM model is 64, and each LSTM model has two LSTM units.
4.3. Baseline Methods and Evaluation Criteria
In order to verify the superior performance of the proposed methods, five methods are chosen to compare with our proposed FedMIC framework.
- Support Vector Regression (SVR) [34]: SVR is a traditional machine learning model that has been successfully applied to traffic prediction;
- LSTM [6]: LSTM is a deep learning model commonly used to capture time series features and has been widely applied to traffic prediction;
- FedAvg [16]: FedAvg implements mean aggregation of model parameters during model aggregation;
- FedAtt [19]: FedAtt takes into account the contributions of different client models in model aggregation and implements aggregation based on the attention mechanism;
- FedDA [20]: FedDA uses data sharing and K-means algorithm to cluster the clients and uses a two-tier attention mechanism for model aggregation.
Our experiments compare two learning strategies of fully distributed learning and federated learning. SVR and LSTM are trained using the fully distributed learning strategy, i.e., the base stations each train their own local models for predicting their own traffic, and no model aggregation is involved. FedAvg, FedAtt, FedDA, and FedMIC are federated learning strategies. Among them, FedAvg and FedAtt do not involve client clustering, and the central server directly aggregates the models uploaded by clients. FedAtt and FedDA use different clustering schemes. For a fair comparison, all four federated learning methods use client models with the same network structure and parameters as LSTM.
The predictive performance of these algorithms was evaluated using mean absolute error (MAE), mean square error (MSE), and R-squared score. The calculation formulas are as follows:
MAE is the average value of the absolute error, which reflects the real situation of the error of the predicted value. MSE squares the errors, magnifying the gap between the errors. The smaller the value of MSE and MAE, the better the effect of the model. R-squared normalizes the predicted evaluation to [0, 1], and the larger the value, the higher the accuracy of the model.
4.4. Prediction Results and Comparative Analysis
The experimental results are shown in Table 1, where our proposed method has the best prediction performance with the smallest prediction error on three different types of traffic data compared to the baseline method. Compared with the state-of-the-art FedDA, FedMIC has 19.3%, 5.3%, and 4.4% MSE gain and 9.2%, 4.5%, and 1.56% MAE gain for Internet, Call, and SMS data, respectively.

Table 1.
Comparison of prediction performance of different methods in terms of MSE and MAE.
In fully distributed learning strategy, the traditional machine learning algorithm model SVR is unable to capture the deep features hidden in the traffic data and has a weaker accuracy for traffic prediction compared to the deep learning model LSTM. Fully distributed learning strategy is unable to learn the knowledge of different regions, resulting in lower accuracy due to local training of each model, less traffic data, and no model aggregation involved. Therefore, the federated learning traffic prediction algorithm is more advantageous compared to the fully distributed prediction algorithm.
In the federated learning strategy, FedDA and FedMIC with clustering method learn the individualized features of similar traffic distributions, effectively attenuating the detrimental effects of data heterogeneity and enabling the global model to have superior prediction performance. Compared with FedAtt without clustering, FedMIC has MSE gains of 35.49%, 36.14%, and 5.14% and MAE gains of 20.47%, 14.55%, and 1.64% for Internet, Call, and SMS data, respectively. And FedMIC implements base station clustering based on model-based mutual information, which can effectively protect data privacy compared to FedDA’s data sharing strategy.
The traffic prediction method of FedAtt has a lower error than the traffic prediction method of FedAvg. It shows that the attention aggregation algorithms effectively enhance the generalization ability of the global model, thus improving the prediction performance. FedMIC implements hierarchical attention aggregation on the clustered models, and the global model obtained by aggregation has stronger generalization performance than the global aggregation models of FedAvg and FedAtt, which improves the prediction accuracy of the model.
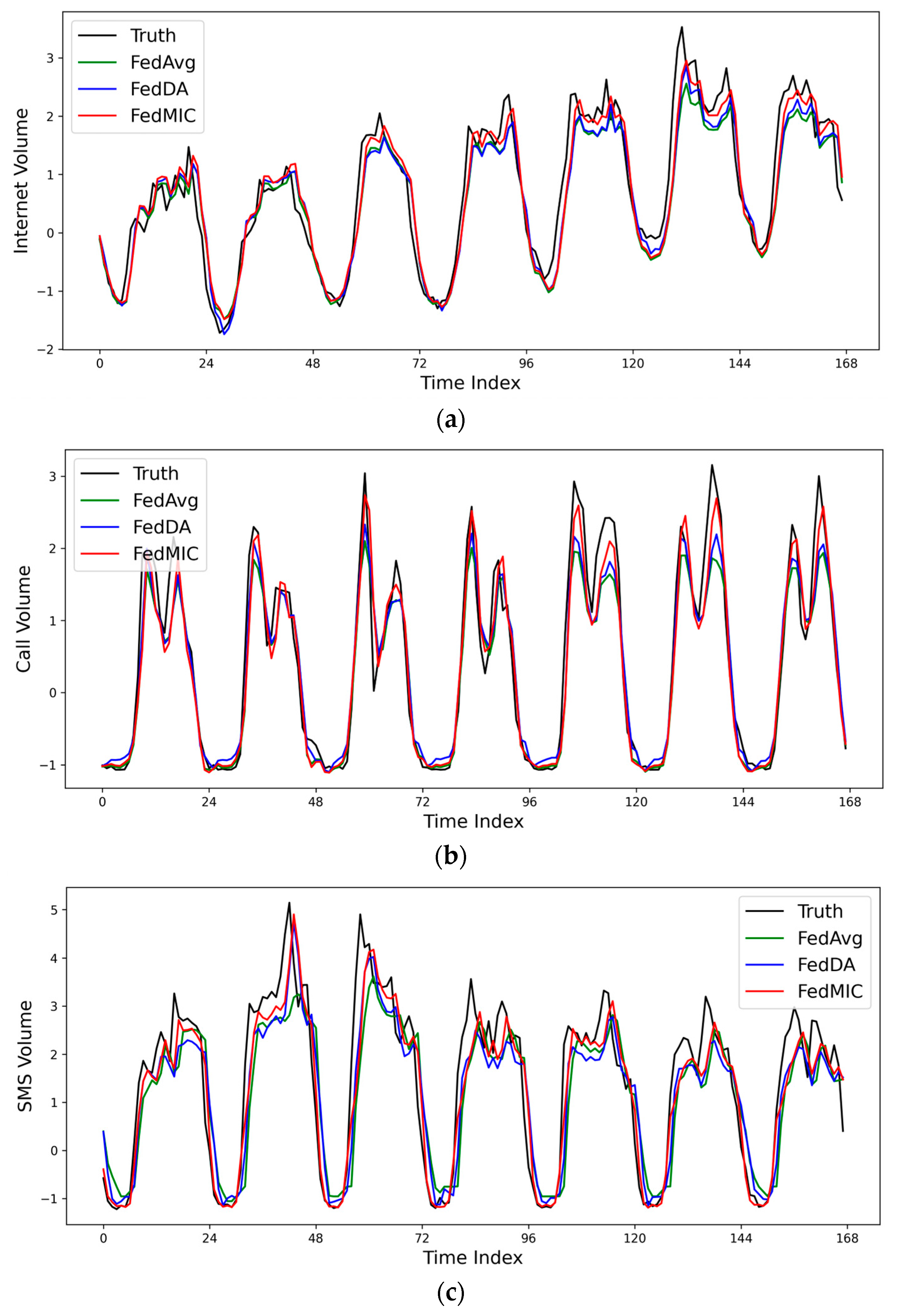
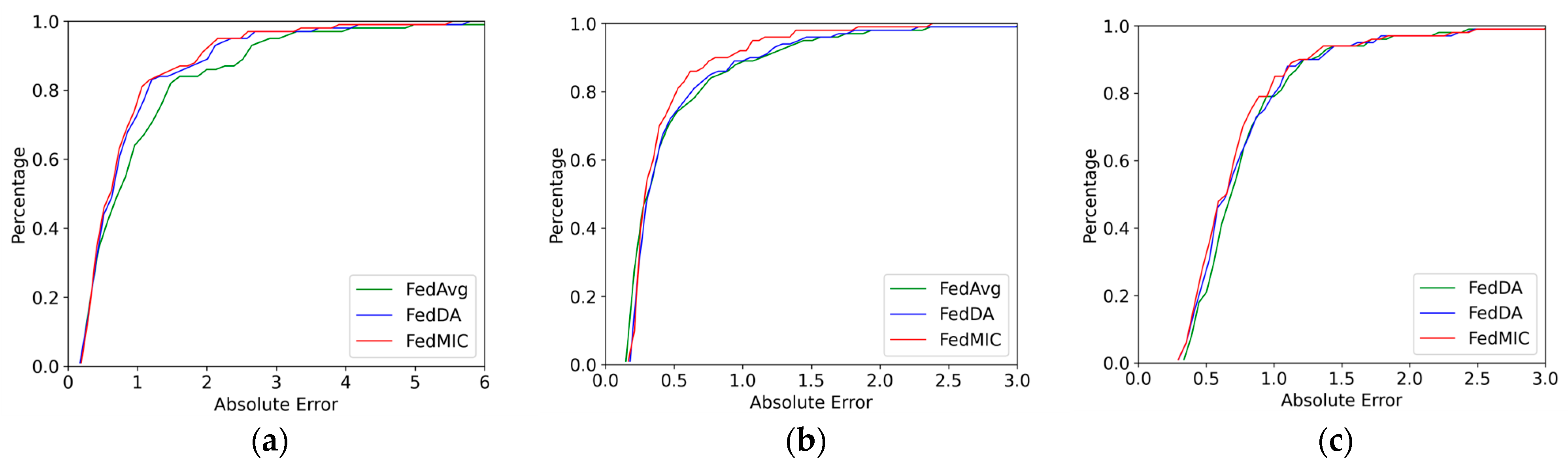
In order to further evaluate the prediction performance of different algorithms, a cell is randomly selected, and the actual traffic values of Internet, Call, and SMS are compared with the predicted values of different algorithms. As shown in Figure 5, FedMIC can predict the trend of traffic very accurately, especially in the case of a sudden surge of traffic, FedMIC has a better response ability to sudden traffic. Figure 6 is the cumulative distribution function (CDF) of the absolute error. It can be seen that the error of FedMIC is the smallest, which is enough to show that our proposed method has a better prediction performance.
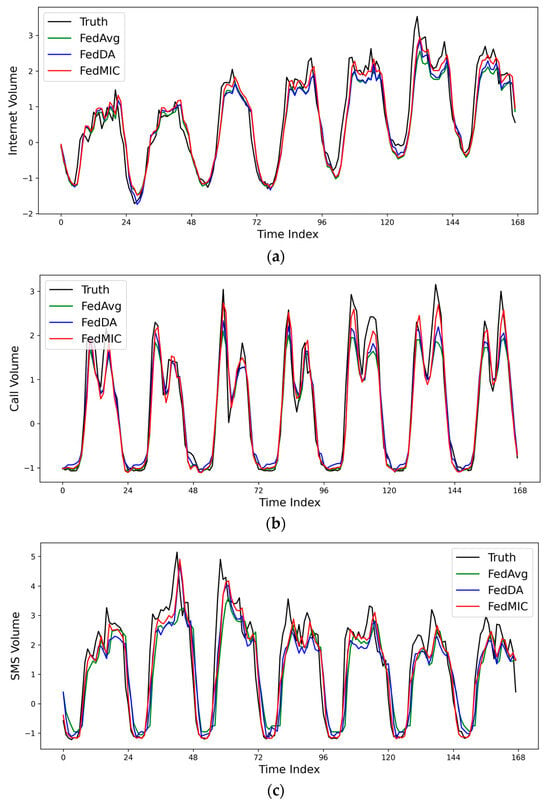
Figure 5.
Comparison of the predicted and true values of different methods on three types of traffic data. (a) Internet data; (b) call data; (c) SMS data.
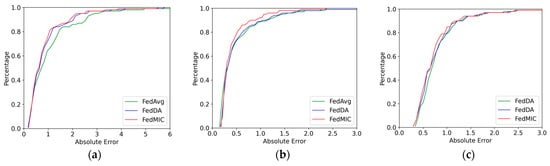
Figure 6.
Comparison of CDF results on three types of traffic data. (a) Internet data; (b) call data; (c) SMS data.
4.5. Communication Rounds and Accuracy
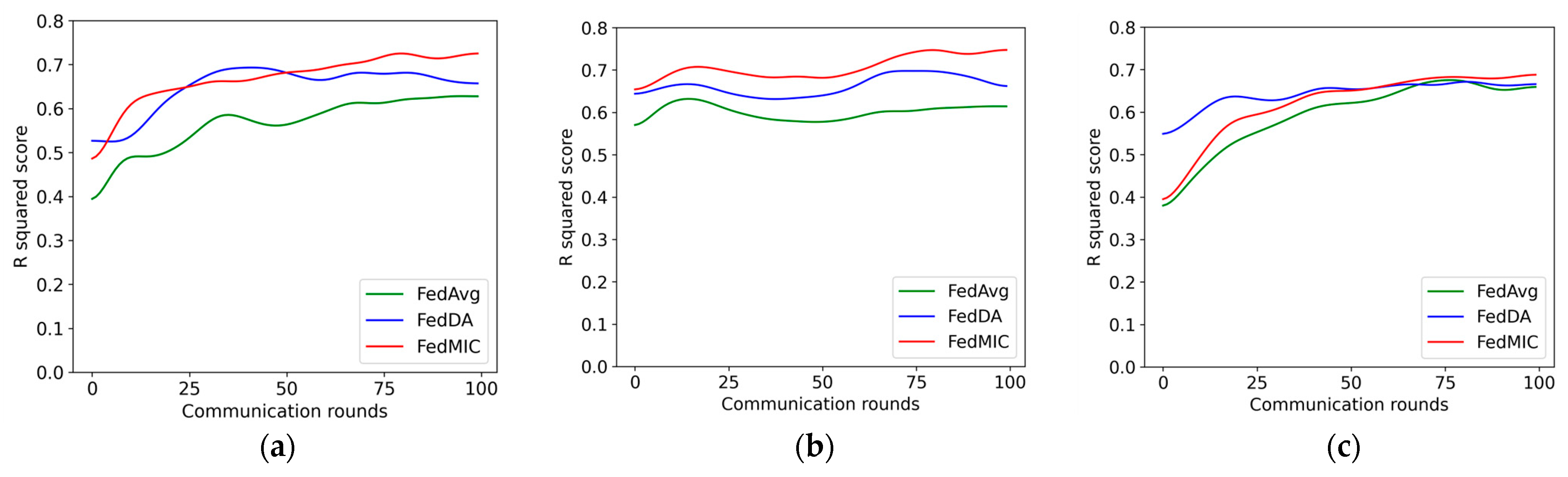
Figure 7 is a comparison of the prediction accuracy of several different algorithms as the federal communication rounds change, and the R-square score is used to represent the prediction accuracy. It can be seen from the figure that with the increase in federated communication rounds, edge clients continue to learn the characteristics of local traffic, and the central server continuously aggregates client models from different regions to enrich the knowledge of the global model, thereby making the accuracy better. come higher. For the learning of network traffic characteristics, FedMIC can achieve higher accuracy with fewer communication rounds. For the learning of Call traffic characteristics, the prediction accuracy of FedMIC is significantly better than that of FedDA and FedAtt. For the prediction of SMS traffic, although FedDA is more accurate than the other two algorithms in a small amount of communication, as the communication rounds increase, FedMIC continuously optimizes its global model, and its accuracy is higher than FedDA in the 72nd round of communication. Overall, within 100 rounds of federated learning, FedMIC can achieve 72.4%, 77.1%, and 70.0% accuracy for Internet, Call, and SMS traffic, respectively, which is higher than the other two algorithms. FedMIC requires fewer communications to achieve a certain level of accuracy than FedAvg.
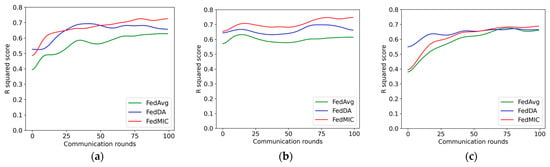
Figure 7.
Prediction accuracy and communication rounds on three types of traffic data. (a) Internet data; (b) call data; (c) SMS data.
From the above experimental results, it can be seen that our method still has some limitations. Although the prediction accuracy of the proposed model is higher than that of the compared methods, for SMS traffic, FedMIC requires more communication rounds to achieve a high prediction accuracy. How to improve the communication efficiency is a problem that needs to be continued in the future.
4.6. Analysis of Clustering Algorithm
In the federated learning traffic prediction framework in this paper, we use the method of clustering first and then aggregation. Since the data in federated learning does not come out of the local area, the characteristics of the network model in federated communication reflect the characteristics of data distribution, so the data we cluster based on are the parameters of the neural network model. In order to verify the effectiveness of the clustering algorithm, this paper uses K-means clustering, Gaussian mixture model (GMM) clustering, and spectral clustering algorithms in the framework of federated learning traffic prediction, and compares them with the clustering methods we use, the results are shown in Table 2. Our proposed clustering algorithm minimizes the error of traffic prediction. This is because mutual information can effectively distinguish the similarity relationship of the model, and the spectral clustering algorithm based on mutual information improves the accuracy of clustering, thereby improving the prediction performance of the model.
Table 2.
Comparison of prediction performance of different clustering strategies.
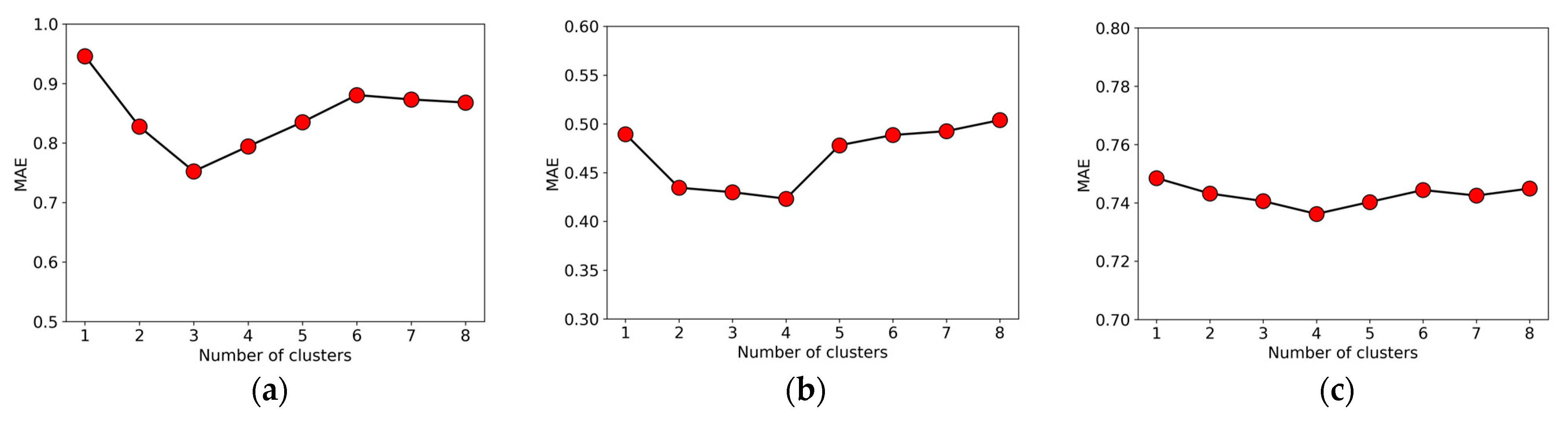
Spectral clustering algorithms need to determine the number of clusters. In the experimental subjects of 100 base stations in this paper, we determined that the number of clusters is appropriate below 8 by combining past research and experiments [21]. Figure 8 presents the MAE of the prediction results under different cluster numbers . indicates that there is no clustering. It can be seen that the clustering algorithm is indeed conducive to improving the prediction performance of the model, especially the improvement of Internet traffic is more obvious. For Internet traffic, the prediction error is the smallest when . For call and SMS traffic, the prediction error is the smallest when . Therefore, the selection of different cluster numbers also has a certain impact on the final prediction results. When the number of base stations increases to a certain amount, we need to consider readjusting the number of clusters to accommodate the training of the new federated learning, so the dynamic adjustment of the clustering results needs to be discussed in future research work.
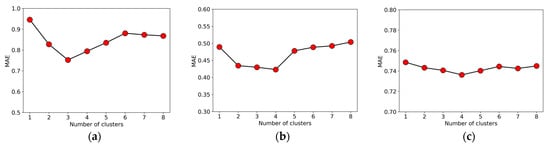
Figure 8.
The impact of clustering number C on prediction performance on three types of traffic data. (a) Internet data; (b) call data; (c) SMS data.
5. Conclusions
In this paper, we propose FedMIC, a federated learning wireless traffic prediction framework based on mutual information clustering. First, the original traffic data are preprocessed into adjacent traffic sequences and periodic traffic sequences using a sliding window mechanism, and the client uses a dual LSTM model to learn the adjacency features and periodic features of the traffic, respectively, and fuses the two features to improve the model’s learning capability. Second, the client is clustered using a spectral clustering algorithm based on mutual information. Measuring the similarity of models with mutual information improves the accuracy of clustering and makes the clustering model capture personalized features more accurately. Then, the architecture of hierarchical model aggregation is implemented. Models within a cluster are first aggregated to obtain a cluster model with personalized features. Then, the cluster models are aggregated to obtain the global model that contains all the knowledge. The global model obtained through the clustering hierarchical aggregation scheme effectively reduces the impact of the data heterogeneity problem and improves the prediction accuracy of the global model. Finally, the model aggregation algorithm based on the attention mechanism is used to improve the generalization ability of the global model by considering the different contributions of the clients during aggregation. Experimental results show that FedMIC has the lowest prediction error and better prediction performance on three different types of wireless traffic compared to the fully distributed approach and other federated learning-based traffic prediction frameworks. But our approach also has some limitations that need to be improved. Fewer federated learning communications are needed to reduce the consumption of communication resources. Improvements in clustering algorithms need to be dynamically adapted to accommodate the extended number of base stations. In addition, online learning techniques can be quickly adapted to changes in the characteristics of traffic data for real-time traffic prediction. Online federated learning for wireless traffic prediction can be investigated in future work.
Author Contributions
Conceptualization, Z.C., J.Z. and X.H.; methodology, J.Z. and X.H.; validation, Z.C., L.Z. and Y.F.; data curation, Y.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China (62072416), Key Research and Development Special Project of Henan Province (221111210500), Key Technologies R&D Program of Henan Province (232102211053, 222102210170, 222102210322).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yao, M.; Sohul, M.; Marojevic, V.; Reed, J.H. Artificial intelligence defined 5G radio access networks. IEEE Commun. Mag. 2019, 57, 14–20. [Google Scholar] [CrossRef]
- Letaief, K.B.; Chen, W.; Shi, Y.; Zhang, J.; Zhang, Y.J.A. The roadmap to 6G: AI empowered wireless networks. IEEE Commun. Mag. 2019, 57, 84–90. [Google Scholar] [CrossRef]
- Jiang, W. Cellular traffic prediction with machine learning: A survey. Expert Syst. Appl. 2022, 201, 117163. [Google Scholar] [CrossRef]
- Nie, L.; Jiang, D.; Yu, S.; Song, H. Network traffic prediction based on deep belief network in wireless mesh backbone networks. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Yang, H.; Li, X.; Qiang, W.; Zhao, Y.; Zhang, W.; Tang, C. A network traffic forecasting method based on SA optimized ARIMA–BP neural network. Comput. Netw. 2021, 193, 108102. [Google Scholar] [CrossRef]
- Fan, J.; Mu, D.; Liu, Y. Research on network traffic prediction model based on neural network. In Proceedings of the 2019 2nd International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 28–30 September 2019; pp. 554–557. [Google Scholar] [CrossRef]
- Ramakrishnan, N.; Soni, T. Network traffic prediction using recurrent neural networks. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 187–193. [Google Scholar] [CrossRef]
- Bi, J.; Yuan, H.; Xu, K.; Ma, H.; Zhou, M. Large-scale Network Traffic Prediction with LSTM and Temporal Convolutional Networks. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 3865–3870. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, H.; Yuan, D.; Zhang, M. Citywide cellular traffic prediction based on densely connected convolutional neural networks. IEEE Commun. Lett. 2018, 22, 1656–1659. [Google Scholar] [CrossRef]
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3848–3858. [Google Scholar] [CrossRef]
- Vinchoff, C.; Chung, N.; Gordon, T.; Lyford, L.; Aibin, M. Traffic prediction in optical networks using graph convolutional generative adversarial networks. In Proceedings of the 2020 22nd International Conference on Transparent Optical Networks (ICTON), Bari, Italy, 19–23 July 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, Y.; Li, Z.; Wang, X.; Zhao, J.; Zhang, Z. Large-scale cellular traffic prediction based on graph convolutional networks with transfer learning. Neural Comput. Appl. 2022, 34, 5549–5559. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. TIST 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Li, Q.; Diao, Y.; Chen, Q.; He, B. Federated learning on non-iid data silos: An experimental study. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 965–978. [Google Scholar] [CrossRef]
- Ma, X.; Zhu, J.; Lin, Z.; Chen, S.; Qin, Y. A state-of-the-art survey on solving non-IID data in Federated Learning. Future Gener. Comput. Syst. 2022, 135, 244–258. [Google Scholar] [CrossRef]
- Li, W.; Wang, S. Federated meta-learning for spatial-temporal prediction. Neural Comput. Appl. 2022, 34, 10355–10374. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Wang, J.; Liu, Q.; Liang, H.; Joshi, G.; Poor, H.V. Tackling the objective inconsistency problem in heterogeneous federated optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 7611–7623. [Google Scholar]
- Ji, S.; Pan, S.; Long, G.; Li, X.; Jiang, J.; Huang, Z. Learning private neural language modeling with attentive aggregation. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, C.; Dang, S.; Shihada, B.; Alouini, M.S. Dual attention-based federated learning for wireless traffic prediction. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Li, L.; Zhao, Y.; Wang, J.; Zhang, C. Wireless Traffic Prediction Based on a Gradient Similarity Federated Aggregation Algorithm. Appl. Sci. 2023, 13, 4036. [Google Scholar] [CrossRef]
- Nan, J.; Ai, M.; Liu, A.; Duan, X. Regional-union based federated learning for wireless traffic prediction in 5G-Advanced/6G network. In Proceedings of the 2022 IEEE/CIC International Conference on Communications in China (ICCC Workshops), Sanshui, Foshan, China, 11–13 August 2022; pp. 423–427. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, C.; Shihada, B. Efficient wireless traffic prediction at the edge: A federated meta-learning approach. IEEE Commun. Lett. 2022, 26, 1573–1577. [Google Scholar] [CrossRef]
- Caldarola, D.; Mancini, M.; Galasso, F.; Ciccone, M.; Rodolà, E.; Caputo, B. Cluster-driven graph federated learning over multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2749–2758. [Google Scholar]
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An efficient framework for clustered federated learning. IEEE Trans. Inf. Theory 2020, 68, 8076–8091. [Google Scholar] [CrossRef]
- Sattler, F.; Müller, K.R.; Samek, W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3710–3722. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Shi, Y.; Xing, Y.; Liao, C.; Yu, M.; Guo, C.; Feng, L. Intra-Cluster Federated Learning-Based Model Transfer Framework for Traffic Prediction in Core Network. Electronics 2022, 11, 3793. [Google Scholar] [CrossRef]
- Cang, S.; Yu, H. Mutual information based input feature selection for classification problems. Decis. Support Syst. 2012, 54, 691–698. [Google Scholar] [CrossRef]
- Li, Q.; He, B.; Song, D. Model-contrastive federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10713–10722. [Google Scholar]
- Uddin, M.P.; Xiang, Y.; Lu, X.; Yearwood, J.; Gao, L. Mutual information driven federated learning. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1526–1538. [Google Scholar] [CrossRef]
- Chen, N.; Li, Y.; Liu, X.; Zhang, Z. A mutual information based federated learning framework for edge computing networks. Comput. Commun. 2021, 176, 23–30. [Google Scholar] [CrossRef]
- Kornblith, S.; Norouzi, M.; Lee, H.; Hinton, G. Similarity of neural network representations revisited. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 3519–3529. [Google Scholar]
- Feng, H.; Shu, Y.; Wang, S.; Ma, M. SVM-based models for predicting WLAN traffic. In Proceedings of the IEEE international Conference on Communications, Istanbul, Turkey, 11–15 June 2006; Volume 2, pp. 597–602. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).