Abstract
Accurate and efficient sorting of diverse magnetic tiles during manufacturing is vital. However, challenges arise due to visual similarities among types, necessitating complex computer vision algorithms with large sizes and high computational needs. This impedes cost-effective deployment in the industry, resulting in the continued use of inefficient manual sorting. To address this issue, we propose an innovative lightweight magnetic tile detection approach that improves knowledge distillation for a compressed YOLOv5s model. Incorporating spatial attention modules into different feature extraction stages of YOLOv5s during the knowledge distillation process can enhance the ability of the compressed model to learn the knowledge of intermediate feature extraction layers from the original large model at different stages. Combining different outputs to form a multi-scale output, the multi-scale output feature in the knowledge refinement process enhances the capacity of the compressed model to grasp comprehensive target knowledge in outputs. Experimental results on our self-built magnetic tile dataset demonstrate significant achievements: 0.988 mean average precision, 0.5% discrepancy compared to the teacher’s network, and an 85% model size reduction. Moreover, a 36.70% boost in inference speed is observed for single image analysis. Our method’s effectiveness is also validated by the Pascal VOC dataset results, showing potential for broader target detection scenarios. This approach offers a solution to magnetic tile target detection challenges while being expected to expand to other applications.
1. Introduction
The magnet tile [1] holds paramount importance as a critical component within a permanent magnet direct current (DC) motor, serving to provide a consistent and uninterrupted magnetic potential throughout the motor’s operation. With the widespread applications of DC motors in production and daily life, the demand for magnetic tiles is increasing steadily. Moreover, due to the broad range of applications for DC motors, a rich diversity of magnetic tile types has also emerged. As a result, manufacturing magnetic tiles typically entails dealing with large quantities and various types of products [2]. It presents challenges for the product sorting stage within the manufacturing process. The sorting of magnetic tiles aims to simultaneously recognize and separate various product types, allowing them to be categorized on the production line for subsequent quality inspection and packaging preparations. To guarantee production efficiency, it is imperative to accurately and rapidly identify various magnetic tile types in large quantities. Such a task can be treated as a target detection problem in computer vision [3]. Despite significant advancements in computer vision-based target detection techniques, achieving both high detection accuracy and fast processing speed still relies on complex and large-scale algorithm models [4]. The execution of these models incurs a substantial computational burden and demands high computing power. However, magnetic tile manufacturing enterprises commonly prioritize low-cost production equipment, resulting in highly restricted computing power available for deployment on the production line. Therefore, many state-of-the-art target detection algorithms fail to operate effectively, hampering the accomplishment of fast and precise automated detection of magnetic tile targets. Instead, manual sorting methods remain prevalent. The accuracy instability, inconsistent speed, high demand for labor, and the need for long-term training of sorters, all influenced by human factors, continue to hinder the sorting efficiency of magnetic tiles. Consequently, to overcome the outdated state of magnetic tile sorting, it is worth investigating the development of a lightweight model that can operate efficiently with low computing power, enabling fast and accurate detection for magnetic tile targets.
Target detection is a significant task in computer vision, aiming to localize and identify multiple targets of interest from images or videos. Over the past few years, target detection algorithms have experienced remarkable progress, driven by the improvement of computer performance, the development of deep learning techniques, and the availability of extensive datasets. The current prevailing target detection algorithms can be categorized into two major groups: traditional methods and deep learning methods. The former relies on traditional image processing techniques, with well-known approaches like Haar features [5], histogram of oriented gradients (HOG) [6], scale-invariant feature transform (SIFT) [7], and so on. The latter primarily builds upon convolutional neural networks (CNN), with representative methods such as Region-based CNN (R-CNN) [8], Mask R-CNN [9], Faster R-CNN [10], You Only Look Once (YOLO) [11], Single Shot Multibox Detector (SSD) [12], and so forth. The deep learning-based target detection methods can be divided into two forms: single-stage detection and two-stage detection [13]. Single-stage detection transforms the target detection task into an end-to-end regression problem. Predicting the target class and bounding box in the image is performed directly during a single forward pass. Two-stage detection involves the generation of candidate regions followed by classification and accurate bounding box regression on these candidates. The initial stage is commonly utilized to produce candidate regions, and the subsequent stage is responsible for classifying and localizing these regions. YOLO and SSD are representative examples of single-stage detection methods, while the other mentioned approaches belong to two-stage detection methods. Due to the real-time advantage of single-stage detection methods over two-stage detection methods, they are better suited for the rapid detection requirements of large-scale magnetic tile targets. Furthermore, YOLO conducts a single forward pass over the entire image, making it exceptionally well-suited for applications demanding rapid real-time detection, while SSD demonstrates superior flexibility and accuracy in dealing with targets of diverse scales and densities. Thus, YOLO has garnered significant attention and research in rapid target detection, theoretically making it the preferred choice for detecting magnetic tile targets. The YOLO method has evolved to its eighth generation, giving rise to numerous models with distinct architectures, performance levels, and versions, leading to many related research studies and applications. Among them, the fifth-generation YOLO model, YOLOv5, has received considerable research attention in recent years and has demonstrated comparable target detection capabilities to other versions and iterations on specific datasets and usage scenarios. For instance, Zhang et al. [14] compared the performance of YOLOv5 and YOLOv6 in crop pest detection and concluded that YOLOv5 outperforms YOLOv6 on the crop pest dataset. Liu et al. [15] conducted experiments on a facial detection dataset, and the results indicated that the YOLOv5s model exhibits a similar size but higher accuracy than the YOLOv7-tiny model. Nevertheless, to achieve performance beyond YOLOv5s, the considerably larger YOLOv7 model is required, with a parameter count at least seven times that of YOLOv5s. Experiments on the Google Open Images Dataset [16] also revealed that YOLOv5 outperforms YOLOv7. Studies focusing on agricultural weed target detection [17] and medical acute lymphoblastic leukemia cell target detection [18] have similarly indicated that YOLOv5 could exhibit superior performance compared to YOLOv6 and YOLOv7 under the same tasks and datasets. Considering these factors, the fifth-generation YOLO presents a promising solution for detecting magnetic tile targets, especially with YOLOv5s, the most compact model, offering enhanced possibilities for achieving lightweight model performance.
Over the past years, several research works [19,20] have pointed out that a further lightweight YOLOv5s model remains essential as edge devices with low computing power become more prevalent. To operate effectively in application scenarios with lower computing power, the YOLOv5s model needs to undergo downsizing while preserving its original precision. Therefore, the technique of model lightweighting is integrated into the improvement research of the YOLOv5s model, aiming to significantly reduce the model size while only experiencing minimal performance degradation. However, reducing the model size while preserving its original precision presents a contradictory challenge in the efforts to improve YOLOv5s into a lightweight model. The current effective techniques for model lightweightization include the direct design of lightweight network models [21], model pruning [22], parameter quantization [23], neural architecture search-based methods [24], and knowledge distillation (KD) [25]. Among these methods, KD is an emerging approach for obtaining efficient and small-scale networks that possess advantages not present in other ways. The main idea of KD is to transfer knowledge from a complex and large-scale model (referred to as the teacher network) with strong learning capability to a simple and small-scale model (referred to as the student network), thereby enabling the lightweighted small model to retain critical performance from the larger model [26]. Due to its remarkable advantages in model compression and performance enhancement, KD has become a prominent and pivotal research focus within target detection, generating several noteworthy avenues for improvement. With the development of deep learning, neural network models are constantly deepening [27]. Hence, the distilled knowledge from mere output features [28,29] is insufficient to adequately guide the training of the student network during the process of KD from the teacher network. To this end, integrating intermediate feature knowledge [30,31] into KD alleviates the deficiency of transferable knowledge resulting from considerable capacity disparities between the teacher and student networks. The core idea is to leverage the knowledge learned by the teacher network’s intermediate layers during target feature extraction as the output cues for the intermediate layers of the student network. Recent research has proposed the idea of a structured KD [32]. The related approach involves transferring structural information from large-scale networks to compact ones, applying it to dense prediction tasks in computer vision, and achieving significant effects in multi-target detection. Subsequent research highlighted the importance of preserving inter-channel correlations in feature representations [33]. The diversity and homogeneity of the student network’s feature space can align with the teacher network’s feature space, leading to a successful distillation of inter-channel correlations in KD. These advancements provide valuable insights for promoting the lightweighting of the YOLOv5s model through KD.
Despite the widespread attention received by YOLOv5s and KD in target detection, there are still unexplored research areas. Effective attempts and applications of YOLOv5s in detecting magnetic tile targets are yet to be explored; there is currently a lack of evidence to support the determination of the degree of lightweightness for the YOLOv5s model; and the KD techniques serving lightweight YOLOv5s models have not been deeply investigated and enhanced for the problem of magnetic tile target detection. As a result, this study places particular emphasis on the exploration of feature knowledge transfer methods between the intermediate and output layers of the YOLOv5s model, proposing an improved KD approach for the lightweight YOLOv5s model by combining spatial attention (SA) and multi-scale output features (MSOF). The testing and validation are conducted on our self-constructed proprietary magnetic tile target dataset and the Pascal VOC 2012 dataset containing general targets, enabling us to evaluate the performance of our approach in detecting magnetic tile targets and its potential applicability in diverse target scenarios.
The main contributions of this paper are as follows:
- (1)
- An improved KD method based on the YOLOv5s model is devised to achieve a lightweight model capable of rapid and accurate detection for magnetic tile targets.
- (2)
- A novel lightweight evaluation criterion is introduced to assess the rationality of the student network’s scale, establishing a trade-off between compressing model size and maintaining accuracy performance.
- (3)
- The feature extraction knowledge linked to spatial geometric information from specific intermediate layers of the YOLOv5s model is assimilated into the KD process through three SA modules.
- (4)
- The KD mechanism is enriched with the MSOF knowledge derived from the multiple outputs of the YOLOv5 model in classification, confidence, and bounding boxes.
The subsequent sections of this paper are organized as follows: Section 2 elucidates the proposed method’s foundational principles and design elements. In Section 3, the experimental details of our approach are elaborated. Section 4 is dedicated to the analysis and discussion of the experimental results. The final section comprehensively summarizes our study’s conclusions, advantages, limitations, and future directions.
2. Methodology
2.1. YOLO Network
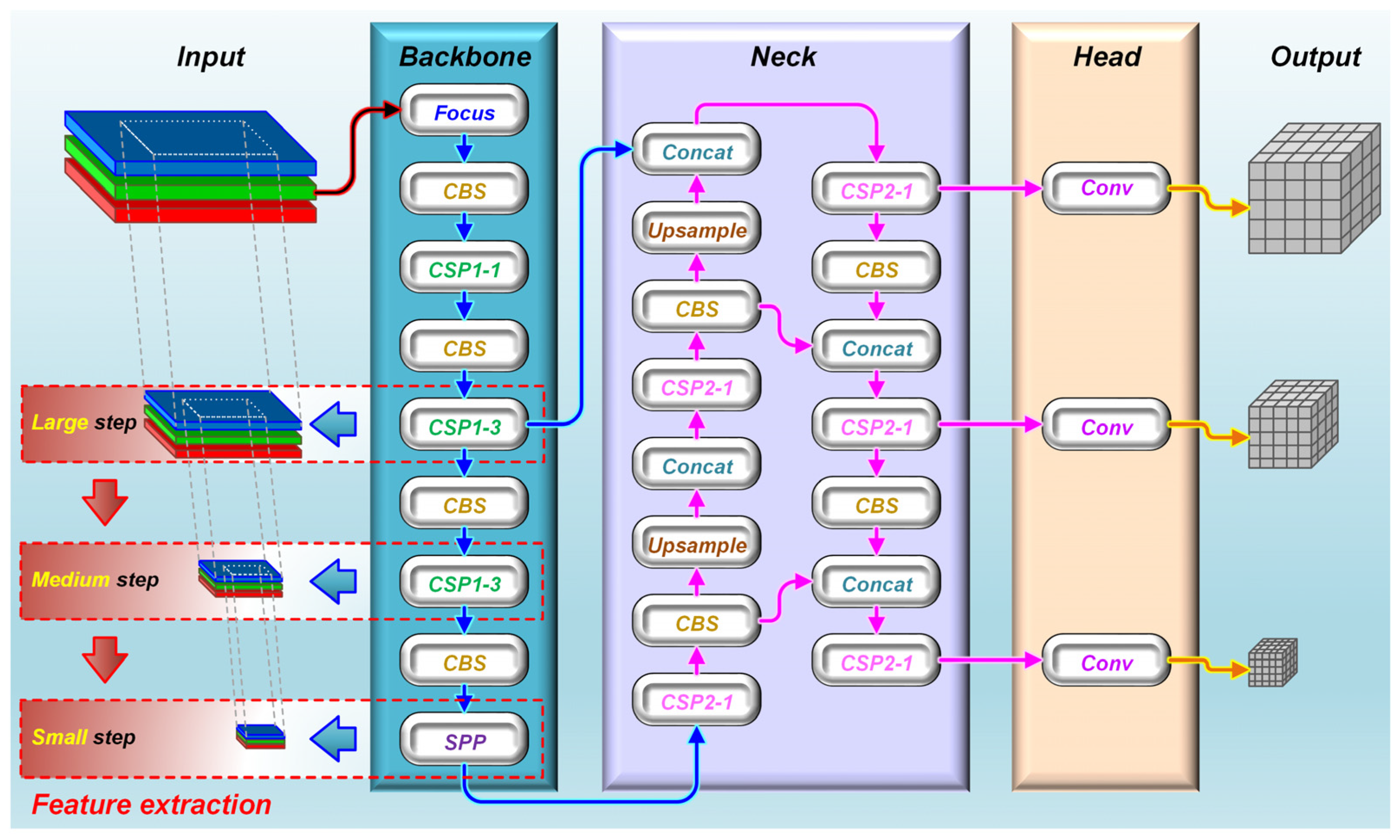
The YOLO network is superior in inspection speed as a single-stage target detection network. The YOLO series has experienced remarkable growth, with notable advancements, including the release of YOLOv5 [34], followed by YOLOv6 [35] and YOLOv7 [36], and the latest iteration, YOLOv8 [37]. In contrast to other iterations and versions, the YOLOv5 series models offer the flexibility to adjust the model size, resulting in a wide array of compact models derived from the foundational model. Notably, YOLOv5s [38], the smallest model version of the fifth generation, has been widely employed for target detection deployment and real-time inference. Typically, as depicted in Figure 1, such a network consists of three components: the backbone, neck, and head networks. The backbone network serves as a feature extractor, the neck is employed to enhance feature extraction further, and the head functions as a classifier or regressor for feature extraction. By integrating these three components, YOLOv5s possesses the capability to extract, enhance, and predict features of the targets. It is worth noting that YOLOv5s’ feature extraction process, which is located in the CSPDarknet structure of the Backbone network, can be divided into three sequential steps [39,40], namely, large, medium, and small, progressively allowing the extracted target features to transition from coarse to fine stepwise.
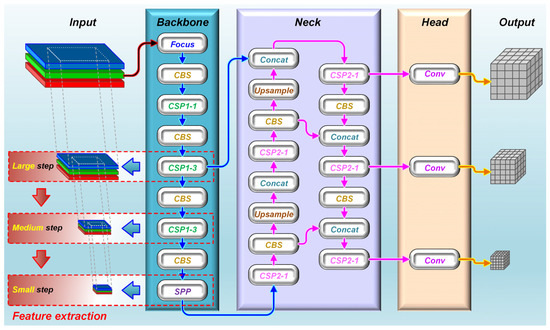
Figure 1.
The YOLOv5s network architecture.
2.2. Knowledge Distillation
The concept of KD was first introduced by Hinton et al. [41]. The KD’s operating architecture typically comprises two components: the teacher and student networks [42]. KD entails the process of knowledge transfer, enabling the student network to acquire the classification accuracy capabilities of the teacher network. Conventional KD algorithms employ soft labels at the output layer of the teacher and student networks to facilitate the training of the student network. This mechanism accomplishes the transfer of knowledge from the teacher network to the student network. The typical training process involves training a high-performance large model as the teacher network. Subsequently, the well-trained teacher network is utilized to guide and complete the training of the student network. The key to guiding the training of the student network lies in controlling the training loss. The overall training loss of the student network can be expressed as follows:
where α is the weighting factor, denotes the loss of the soft label provided by the teacher network corresponding to the predicted value of the student network, and refers to the loss of the truth label corresponding to the predicted value of the student network.
2.3. Improvements in the YOLO-Based Knowledge Distillation
2.3.1. Integration of Spatial Attention Mechanisms in YOLO
According to the study conducted by Gotmare et al. [43], the distillation of soft targets from the teacher network primarily guides the training of the student network at deep network layers, but there is relatively limited training guidance at its feature extraction layers. Therefore, for deeper networks, it is insufficient to solely enable the student network to learn the output feature knowledge of the teacher network. In fact, during the KD process, the intermediate feature layers of the teacher network contain a wealth of spatial structural information about the target. To enhance the performance of the student network, it is crucial for the student network to learn the feature extraction capabilities of the intermediate hidden layers of the teacher network. In this study, SA [44] is adopted as a means for the teacher network to guide the feature extraction of the student network, aiming to enhance the student network’s feature extraction capabilities by leveraging the hidden layer information from the teacher network. The utilization of SA to enhance feature extraction is expected to yield a greater abundance of geometric and spatial structural information from the teacher network. By incorporating more comprehensive inter-pixel association information within these layers, a more intuitive and straightforward acquisition of long-range object dependencies can be achieved. SA is generated by suppressing the influence of the channel dimension on the convolutional feature map, resulting in a relationship feature map between each pixel and all other pixels in the global context. Firstly, the convolutional feature maps of the network model are extracted, followed by individual 1 × 1 conventional convolutional operations performed on the obtained feature maps. After obtaining the feature maps from both the teacher and student networks, the SA map for the N × N convolutional feature maps is generated by leveraging these two feature maps. Several research studies have consistently demonstrated that information redundancy or loss may occur during the adjustment of channel numbers. Nonetheless, the adoption of SA can effectively eliminate the occurrence of such issues. Hence, SA allows for the mitigation of channel number adjustments in the respective feature layers of the student network to match those of the teacher network, effectively addressing the capacity disparity between the two networks. The mathematical formulation of the operation for obtaining the self-attention feature map through SA can be expressed as follows:
where R stands for the SA feature map, C is the number of convolution channels, H and W are the height and width of the feature respectively, and N is the product of H and W.
The calculation process of the attention map is expressed as follows:
where represents the degree of attention to position i in region j; and represent the two feature spaces obtained from the transformation of the hidden layer ; , , .
After obtaining the SA feature maps of both the teacher and student networks, the difference between them can be computed as the SA intermediate feature distillation loss. The calculation process is as follows:
where is the loss function of the teacher and student networks during the distillation of intermediate features of SA, and and are the SA map obtained from the teacher and student networks, respectively.
2.3.2. Design of Multi-Scale Output Feature Distillation for YOLO
Employing teacher network output features to guide student network training and consequently improving the student network’s detection accuracy and model performance has remained an indispensable element within KD studies. Output feature knowledge [45] typically refers to the final layer’s output features of the teacher network, mainly encompassing logical units and soft target knowledge. The primary idea behind output feature KD is to guide the student network to learn the teacher network’s final prediction results, intending to achieve prediction performance similar to that of the teacher network. Due to the diversity of detection tasks and model architectures, different model networks undoubtedly have distinct output features tailored to specific detection tasks [46]. Considering the characteristics of the YOLO network and the requirements of target detection tasks, the complete output feature knowledge of the network should encompass three categories: classification loss, confidence loss, and bounding box loss. As a result, we devised an integrated distillation approach that combines three scales: classification, confidence, and bounding box, for the transfer of output feature knowledge. By distilling classification knowledge from the teacher network’s output features, the student network acquires category probabilities from the teacher’s soft target knowledge, thus guiding the student network to enhance its classification accuracy for the targets. By utilizing confidence KD from the teacher network’s output features, the student network gains insight into the credibility of the prediction boxes from the teacher’s output features, consequently elevating the confidence level of the student network’s prediction boxes. Distilling the bounding boxes from the teacher network’s output features enables the student network to learn the target sizes and specific positional information from the teacher network’s output features, thereby enhancing the student network’s localization accuracy for the targets. The total loss induced by output feature distillation consists of two parts: the student network training loss () and the multiscale output feature distillation loss ().
The student network training loss can be expressed in terms of binary cross entropy as follows:
where denotes the ground-truth labels, represents the predictions of the student network, n stands for the number of label categories, and signifies the Sigmoid function, which can be formulated as follows:
In addition, the MSOF distillation loss can be expressed as follows:
where , , and represent the distillation losses arising from the YOLO model’s output for classification, confidence, and bounding box, respectively. The mean squared error (MSE) is used to represent these three losses, and their general formulas are as follows:
where and indicate the output values of the YOLO model’s classification, confidence, or bounding box predictions for the teacher and the student networks.
2.3.3. Our Proposed Method
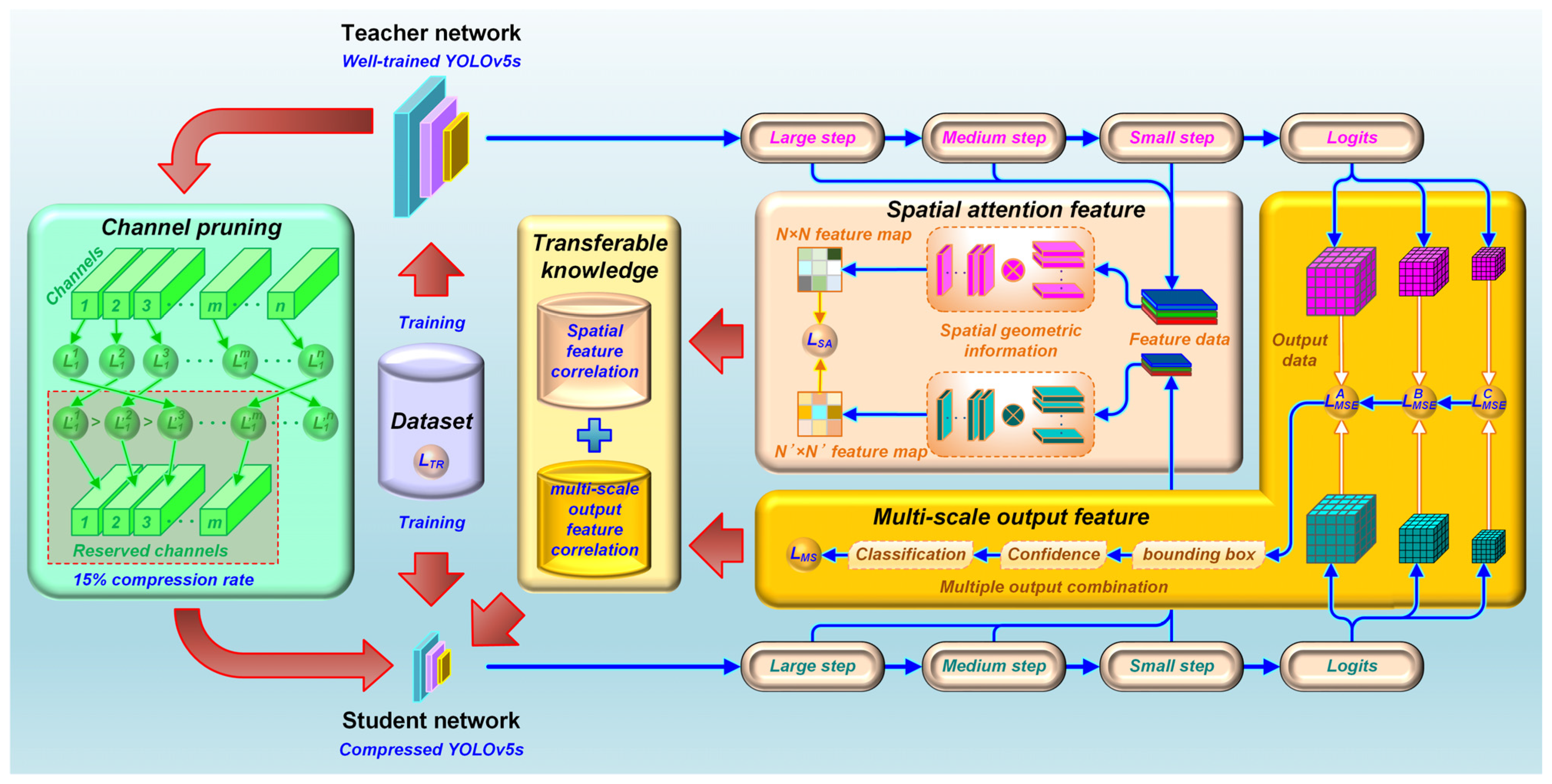
As depicted in Figure 2, we developed a YOLO-based KD approach for detecting magnetic tile targets. Due to the widespread application of the YOLO model in target detection, the YOLOv5s model is chosen as the foundational network for detecting magnetic tile targets. Through extensive iterative training, YOLOv5s achieves high-performance detection of magnetic tile targets. To enhance the performance of a lightweight model through KD, we employ YOLOv5s as the teacher network for KD and utilize a scaled-down version of YOLOv5s as the student network for the distillation process. The student network adopts an isomorphic distillation mode, enabling the teacher network to achieve lightweight simplification easily. By performing model channel pruning, the YOLOv5s model is reduced to a lightweight version, occupying only 15% of the size of the original model. The KD process is accomplished through fine-tuning training of the student network. During this process, we incorporate SA and MSOF to bolster the effectiveness of knowledge transfer. Firstly, we take advantage of the YOLO model’s characteristic of dividing target feature extraction into three steps: large, medium, and small. At each step, an identical SA module is incorporated for transferring feature extraction knowledge of intermediate layers from the teacher network to the student network. During KD, the SA maps are obtained separately from both the teacher and student networks at each step. These maps generally encompass richer geometric and spatial structural information, facilitating knowledge transfer performance. By analyzing associations between each pixel in two SA maps within the same step, the dependency relationship of target features at each step can be established. The inclusion of three SA modules allows the student network to acquire knowledge from diverse feature extraction steps of the teacher network during the retraining process, a capability unavailable with conventional distillation methods. It is used to improve the sensitivity and accuracy of target feature extraction. Next, based on the YOLO model’s division of object detection into three output categories—classification, confidence, and bounding boxes—we enable the student network to learn the regularities of the teacher network’s outputs for various object detections at the logits layer. Integrating MSOF, comprising classification, confidence, and bounding boxes, allows the student network to learn knowledge from the teacher network’s outputs during the retraining process, which conventional distillation methods may overlook. The incorporation of SA and MSOF serves as the improvement and complement to conventional KD methods. As a result, the student network can attain not only the teacher network’s conventional distillation-based generalized knowledge but also gain supplementary knowledge concerning the teacher network’s feature extraction and result output. These additional insights are expected to further enhance the performance of the student network, bringing it closer to the level of the teacher network, while also holding the promising potential to compensate for any performance degradation incurred during subsequent model lightweighting. The loss function () for our proposed KD method is composed of three terms: the SA intermediate feature distillation loss, the student network training loss, and the MSOF distillation loss. The corresponding formulas are as follows:
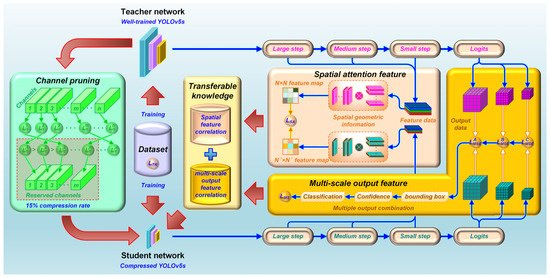
Figure 2.
The proposed YOLO-based KD method.
3. Experiments
3.1. Experimental Setup
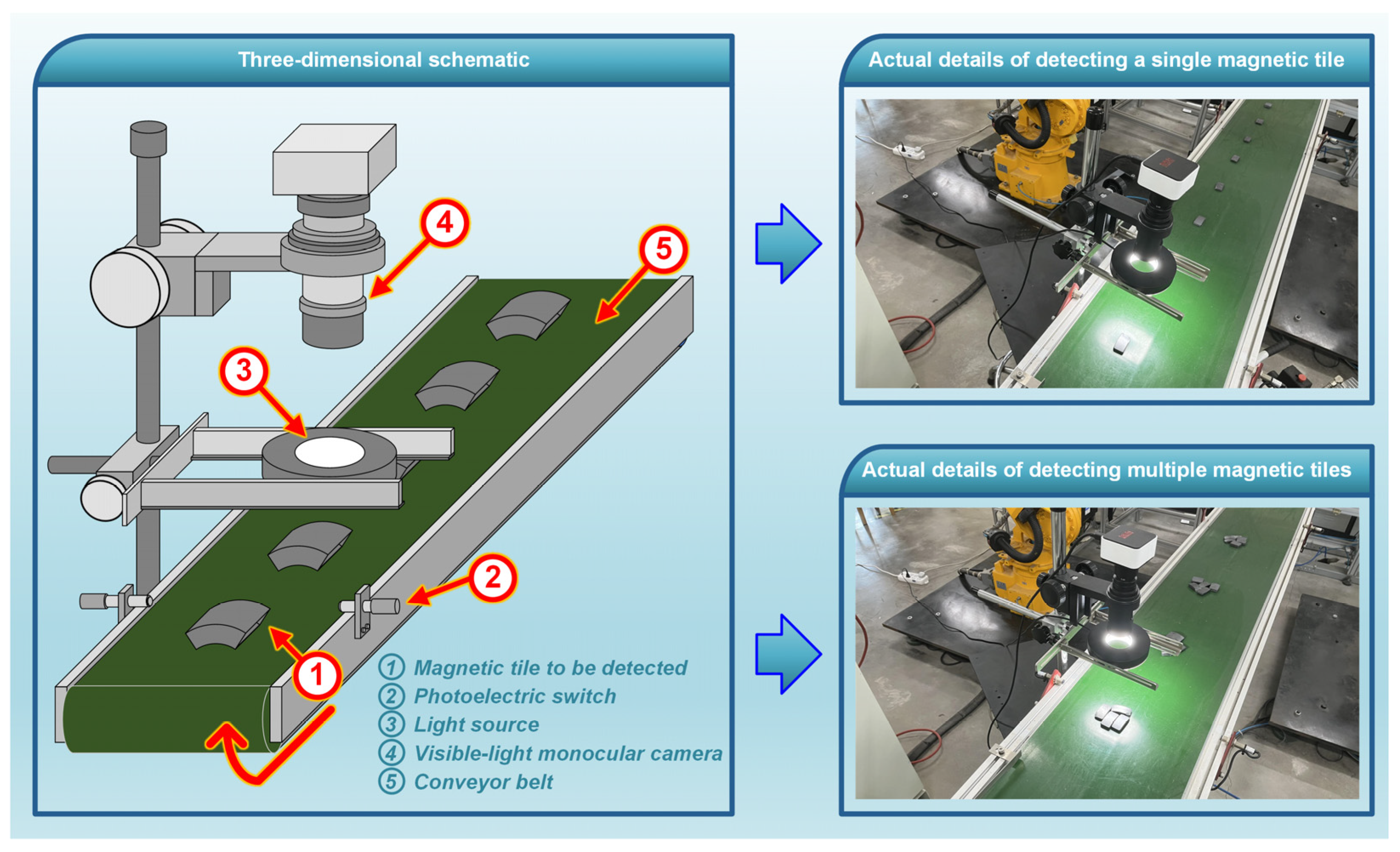
To achieve the detection of magnetic tile targets, we developed a computer vision-based experimental setup, as depicted in Figure 3, to cooperate with our model for automated acquisition and analysis of magnetic tile target images. Such a setup is primarily composed of components, including a conveyor belt, a photoelectric switch, a visible-light monocular camera, a ring-shaped light source, and a computer. The magnetic tiles to be sorted are conveyed along a fixed direction by the conveyor belt. As the magnetic tiles obstruct the optical path of the photoelectric switch beneath the light source during conveyance, a triggering signal is generated to drive the camera for image acquisition. Our proposed model runs in a computer and is tasked with identifying and detecting different types of magnetic tile targets in the acquired images. The devised setup permits simultaneous target detection of single or multiple magnetic tiles. It is responsible for generating detection results to provide sorting guidance for the sorting equipment (e.g., mechanical arms, cylinders, etc.) in magnetic tile production lines. Through the connection facilitated by the conveyor belt, it can seamlessly integrate with the sorting equipment of the production line in a user-friendly manner. Furthermore, the computer used in this research incorporates an AMD Ryzen (TM) 7–5800 H@3.20 GHz CPU made in China, 6 GB of RAMs, and an NVIDIA GeForce GTX3060 GPU made in China, approximating the computational power available under the low-cost, standard operational conditions commonly found in industrial environments. The model presented in this study is developed using the Python programming language and operated within the PyTorch framework. The parameter settings for training the model are as follows: a batch size of 16 for image processing, an image size of 320 × 320, the utilization of the stochastic gradient descent optimizer with an initial learning rate of 0.01, and the maximum number of training epochs not exceeding 150.
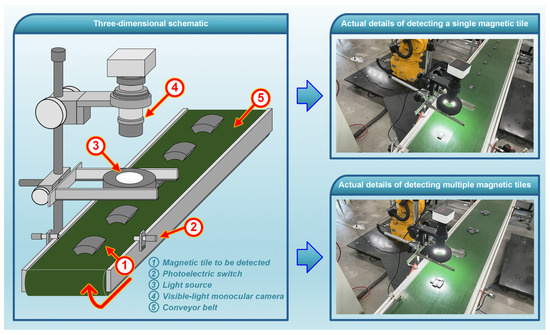
Figure 3.
The experimental rig designed for acquiring images of magnetic tile targets.
3.2. Datasets
To evaluate the performance of our method in detecting magnetic tile targets, we constructed a dedicated dataset specifically for magnetic tile targets. The dataset comprises visible light images of 10 commonly encountered and widely used types of magnetic tiles, covering different shapes and sizes of magnetic tiles to ensure the representativeness of the data with respect to magnetic tile targets. All magnetic tile target images are acquired using the experimental setup designed by us. For the convenience of description in this paper, we assigned the letters A to J to represent the different types of these magnetic tiles, as illustrated in Figure 4a. A total of 6800 magnetic tile target images were collected, including 4712 images for a single magnetic tile in each type, as well as 2088 images for multiple magnetic tiles of different types in the same frame. Those images with multiple magnetic tiles showcase the diverse scenarios of stacked magnetic tiles and their localized occlusions (with occluded area not exceeding 60%) during manufacturing. They ensure the fidelity of data in accurately reproducing the sorting scenes for real-world magnetic tile targets. Considering that the performance of our model relies on a supervised training mechanism, all images are partitioned into two subsets: a training set (4760 images) and a testing set (2040 images), with a split ratio of 7:3. The former is utilized to train the model and establish its robust performance, while the latter is employed to assess the level of performance achieved by the trained model. The individually captured images of single magnetic tiles and the composite images featuring multiple magnetic tiles are evenly distributed between the training and test sets to ensure that the training and testing processes encompassed all target scenarios encountered during magnetic tile sorting.

Figure 4.
Examples of the used datasets: (a) Self-built magnetic tile dataset; (b) Pascal VOC 2012 dataset.
Additionally, as seen in Figure 4b, the Pascal VOC 2012 dataset [47] is employed further to assess the rationality and extensibility of our method. The dataset consists of 17,125 images representing a total of 40,138 targets in 20 different categories, encompassing four major classes of targets, namely, vehicles, indoor items, animals, and persons. As one of the benchmark datasets, it is widely utilized in various fields such as target detection, object segmentation, behavioral recognition, and image classification, serving as a general evaluation tool for assessing the performance of corresponding algorithms or models. Following the 7:3 ratio, the images from the Pascal VOC 2012 dataset are still divided into a training set (11,987 images) and a testing set (5138 images). The optimal detection performance of our proposed model for this dataset is established after sufficient iterations of training. The targets in this dataset exhibit significant differences from magnetic tiles, thereby reflecting the detection capability of our method in other common object domains.
3.3. Evaluation Metrics
Achieving both high accuracy and fast speed is imperative for successfully detecting magnetic tile targets. Accordingly, we devised a comprehensive set of metrics that incorporated both accuracy and speed to comprehensively evaluate the performance of our method in detecting magnetic tile targets. In the realm of accuracy evaluation, metrics such as precision (P), recall (R), average precision (AP), and mean average precision (mAP) have been extensively employed in numerous state-of-the-art studies [48,49]. The assessment of accuracy performance for our models is consistently based on these metrics. Their relevant definitions are listed below:
where TP, FP, and FN denote true positive, false positive, and false negative, respectively.
where is the precision of the i-th recall, M is the number of recalls associated with all interpolation points, N is the number of target types, and denotes the average precision of the i-th type of targets.
In terms of speed evaluation, the computational complexity of the model is directly proportional to the number of parameters (Para) and the storage size (Size). Under constant computing power, employing smaller parameters and storage size generally results in decreased computational complexity, heightened data processing speed, and increased ease of model deployment. Meanwhile, considering the variability in processing speed across different images, the average inference consumption time (AICT) obtained through statistical analysis of individual images offers an objective measure to quantify the overall speed of data processing. Consequently, Para, Size, and AICT are collectively utilized to assess the speed performance of our model.
4. Results and Discussion
4.1. Determination of the YOLO-Based Teacher Network
Within the framework of KD, the teacher network represents a high-performance, large-scale model, leveraging the knowledge obtained through iterative training to extract and identify target features, which is subsequently transferred to the student network, a relatively small-scale model. Therefore, establishing a sufficiently robust teacher network is the primary task that needs to be accomplished. Considering the extensive usage and exceptional performance of YOLO series models in target detection, we employed YOLO as the foundation for training our teacher network. However, the YOLO series has progressed to its eighth generation, with a multitude of model versions and quantities. To determine the most suitable teacher network, we selected seven networks from the commonly used fifth-generation to the latest eighth-generation models, including YOLOv5n, YOLOv5s, YOLOv6n, YOLOv6s, YOLOv7-tiny, YOLOv8n, and YOLOv8s, which are known for their relatively smaller model sizes, for the performance comparison regarding the detection accuracy of magnetic tile targets. The motivation for selecting these networks is that smaller-sized models are more conducive to generating lightweight networks at the same compression ratio. For our self-built dataset of magnetic tiles, each of the seven models achieves its own highest accuracy performance through identical iterative training. Subsequently, P, R, mAP, Para, and Size are combined to determine the optimal network among them. As shown in Table 1, YOLOv5s achieves values of 0.988, 0.979, and 0.993 for P, R, and mAP metrics, respectively. Regardless of P, R, or mAP, YOLOv5s exhibits the highest performance among all six models except YOLOv8s. Concerning the comprehensive accuracy metrics, YOLOv8s outperforms YOLOv5s. However, YOLOv5s attains the same P as YOLOv8s, with only marginal reductions of 0.2% in R and 0.1% in mAP. Such an outcome serves as evidence that YOLOv5s exhibits a high level of accuracy in the magnetic tile dataset test, closely approaching that of YOLOv8s, with a negligible difference in accuracy between them. Notably, the Para and Size of YOLOv5s are much reduced compared to YOLOv8s, with YOLOv8s failing to display distinct Para and Size advantages over models other than YOLOv6s. Furthermore, among all the compared networks, YOLOv6s possesses the highest Para and the largest Size, but it does not outperform the accuracy performance of YOLOv5s. These results imply that a larger parameter count and model size do not necessarily lead to improved object detection outcomes. Consequently, YOLOv5s, with its appropriate parameter count and model size, achieves the relatively optimal detection accuracy of magnetic tile targets, thus establishing itself as the teacher network in our approach.

Table 1.
The performance comparison of different YOLO models for detecting magnetic tile targets.
4.2. Validation of the Student Network with Compressed YOLOv5s
The design of the student network in our approach is inspired by the homogenous distillation pattern, where both the teacher and student networks accomplish the same target detection task. To facilitate model compression and knowledge transfer, the student network directly inherits from the teacher network, which has been compressed using channel pruning. Such a design endows the networks with identical architectures, enabling the transfer of attention-based feature extraction knowledge and MSOF knowledge from the teacher network to the student network. The employed channel pruning, also known as channel sparsity, reduces the number of channels in the network to decrease model parameters and computational complexity, thereby achieving a more lightweight model that operates more efficiently during the inference stage. Using the L1 norm as the quantified weight for each layer’s channels, the pruned channels are those with relatively smaller norms in that layer. Different compression rates for networks can be achieved by pruning different quantities of channels. To investigate the rationality of network compression rates, we selected six different proportions of student networks corresponding to 5%, 10%, 15%, 20%, 25%, and 30% compression rates to demonstrate their respective performances, covering the compression rates set in our approach. For lightweight models, it is always desirable for the student network to be a highly compressed version of the teacher network. However, after model compression and KD, the student network is bound to incur more accuracy loss compared to the teacher network. Hence, reasonable compression entails striking a balance between compression rate and accuracy loss, achieving a maximal compression rate while minimizing the loss in accuracy. To express this balance numerically, we have constructed the following scoring formula:
where Score is a value used to evaluate the degree of the balance, α represents the compression ratio, n stands for the number of indicators for evaluating accuracy (e.g., n = 3 when P, R, and mAP are used), corresponds to the numerical variation of any accuracy evaluation metric for the student network before and after KD (i.e., the rise in accuracy achieved by KD for the compressed model), and signifies the numerical change in any accuracy evaluation metric for the student network compared to the teacher network after KD (i.e., the decrease in accuracy observed after KD).
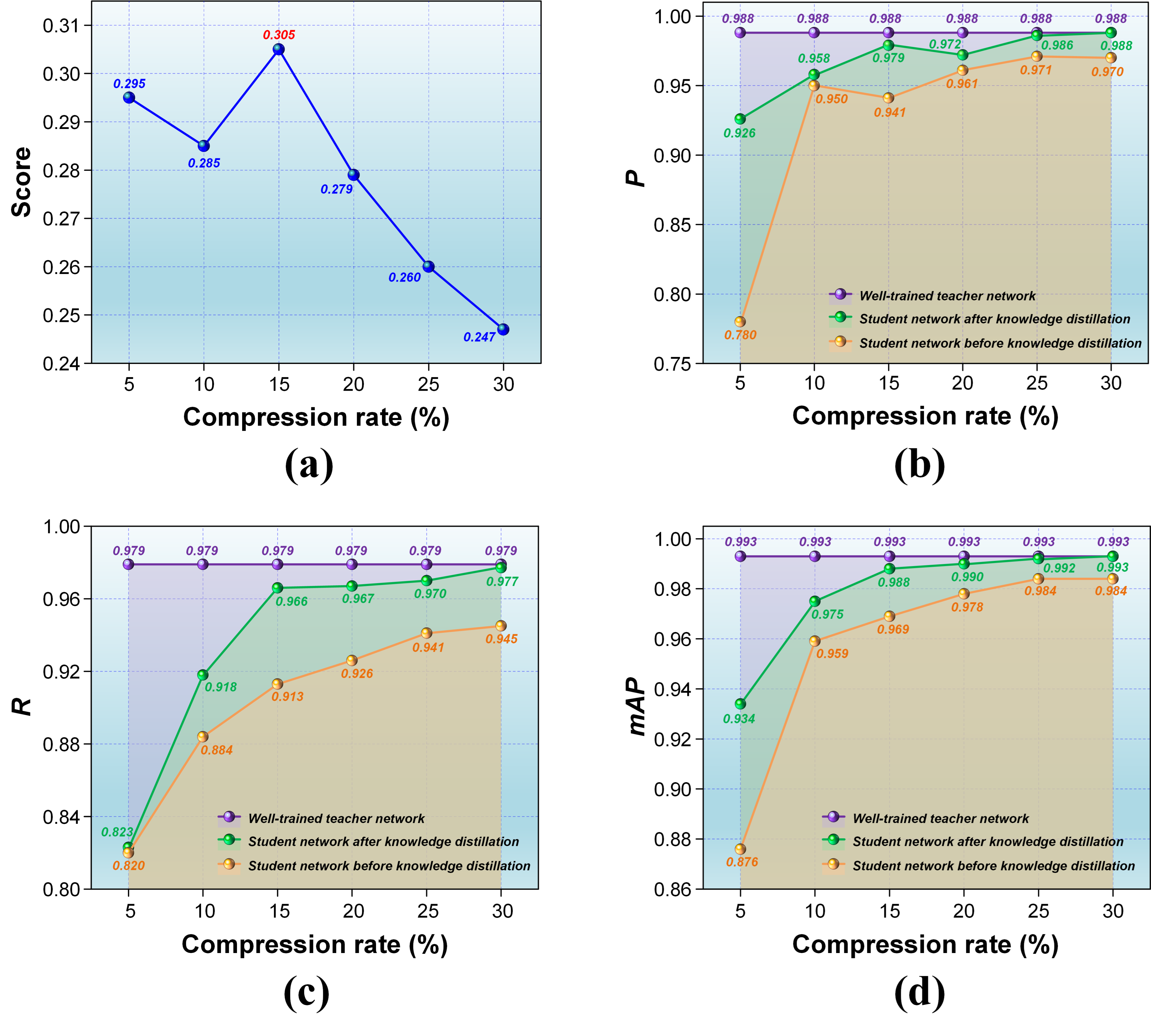
Computed based on the formula above, the scores of the six chosen models corresponding to the respective compression rates are depicted in Figure 5a. As can be observed, reducing the compression rate leads to smaller models and an increasing trend in the scores. At a compression rate of 15%, the score exhibits a maximum inflexion point, indicating a delicate balance between the compression rate and the accuracy loss after KD. To further illustrate this balancing effect, Figure 5b–d showcase the distributions of P, R, and mAP for each model before and after KD. It can be seen that, in general, each accuracy metric decreases synchronously as the compression rate reduces, highlighting that an increase in compression level leads to a corresponding growth in accuracy loss. After KD, the student network exhibits a significant improvement in all accuracy metrics, implying that the accuracy loss caused by compression has been partially compensated. Despite the relatively high model reduction and a certain degree of accuracy improvement achieved after KD for models with 5% and 10% compression rates, the accuracy loss remains relatively prominent. This observation suggests that both these compression rates have resulted in excessive performance degradation for the model, rendering it insufficient to be improved to a usable level through KD. Although the models corresponding to 25% and 30% compression rates exhibit relatively small accuracy losses, they do not have an advantage in achieving the most miniature possible lightweight model. The model compressed at a rate of 15% displays performance that closely resembles models with compression rates of 20% or higher in terms of improving the accuracy of the compressed model and reducing the accuracy loss after KD. Especially concerning P, the model with a compression rate of 15% surpasses the one compressed at 20%. Regardless of P, R, and mAP, when the compression rate falls below 15%, there is a substantial decline in both the accuracy improvement of the compressed model and the accuracy loss after KD. Once the compression rate exceeds 15%, there are relatively small differences in the accuracy’s improvement and loss, and the variations tend to stabilize. Therefore, it can be confirmed that adopting channel pruning in our approach to compress the YOLOv5s teacher network to the student network at a compression rate of 15% is both reasonable and effective.
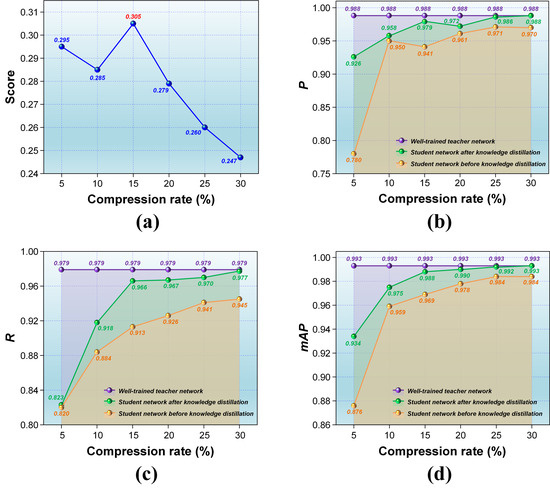
Figure 5.
Compression rates and accuracies of student networks at different compression rates: (a) Balance scores; (b) P; (c) R; (d) mAP.
4.3. Performance of Detecting Magnetic Tile Targets
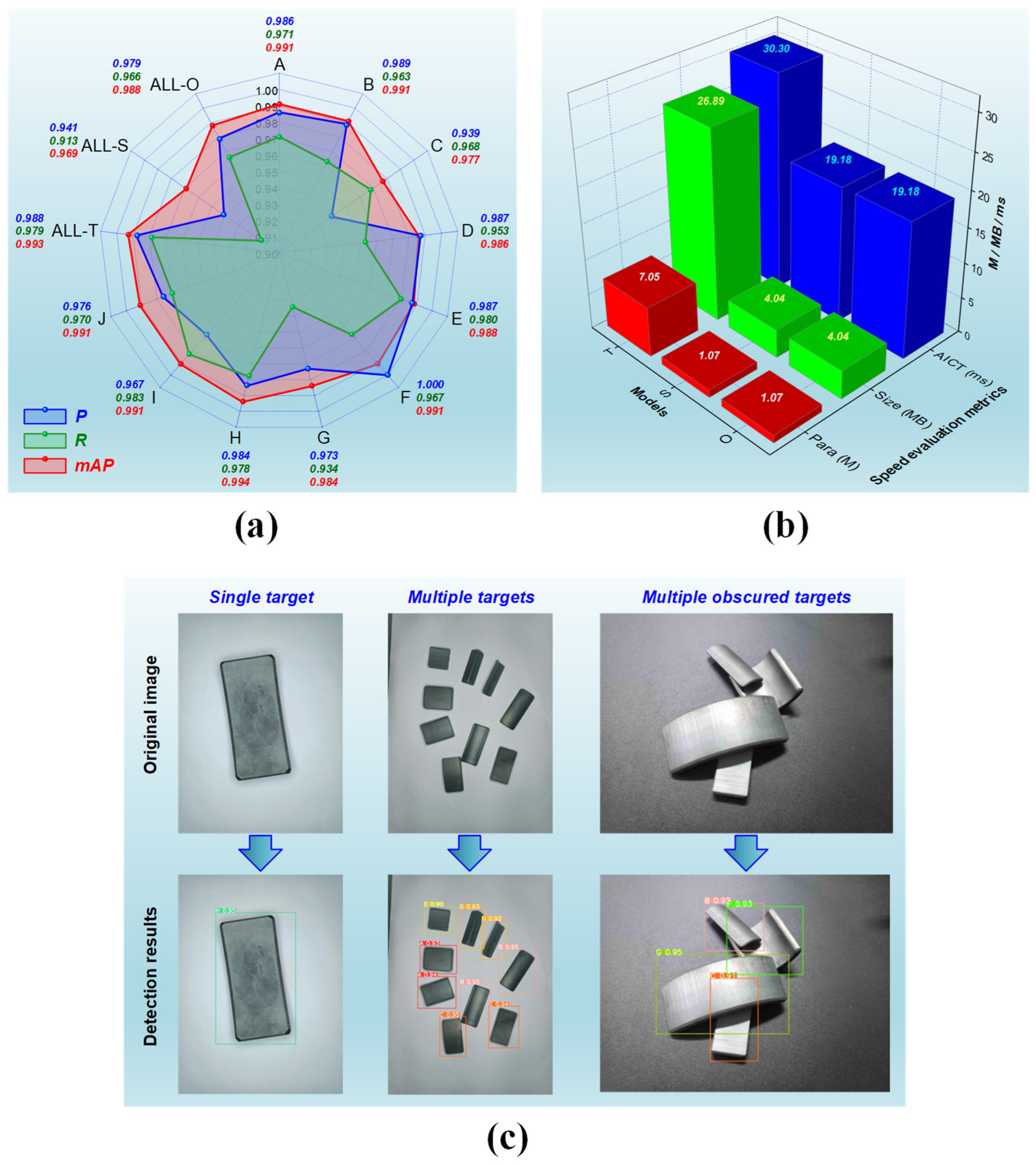
Once the teacher and student networks are determined, the student network can achieve its ultimate performance through the KD process during the retraining phase. The performance, comprising both accuracy and speed, is evaluated using the criteria we formulated. In the testing set of our self-constructed magnetic tile dataset, all ten different categories of targets are used to assess the student network after KD. Since the testing set is not involved in the training process, the detection results can reflect the model’s recognition capability for various categories of magnetic tile targets. To distinctly demonstrate our method’s detection performance across different target categories, we conducted separate statistical analyses for the detection accuracy results of Types A to J. Furthermore, we assessed the overall detection accuracies for the teacher network, pre-KD student network, and our method (i.e., post-KD student network) across all categories, denoted as ALL-T, ALL-S, and ALL-O, respectively. Figure 6a illustrates these accuracy results. It is evident that there are variations in the detection accuracy of our method across each magnetic tile target category. Regarding P, the ideal value of 1 is achieved for Type F, while the relatively lowest value of 0.939 is observed for Type C, with variations among different types within 0.061. Concerning R, the highest relative value of 0.983 is attained for Type I, while the relatively lowest value of 0.934 is recorded for Type G, with variations among different types within 0.049. As for mAP, the highest relative value of 0.994 is obtained for Type H, while the lowest relative value of 0.977 is found for Type C, with variations among different types not exceeding 0.017. With our method, the overall detection precision for all types is 0.979, 0.966, and 0.988 in P, R, and mAP, respectively. It outperforms the accuracy of the student network before KD and comes remarkably close to the performance of the teacher network. Such accuracy performance is sufficient to meet the fundamental requirements of the manufacturing industry for detecting magnetic tile targets.
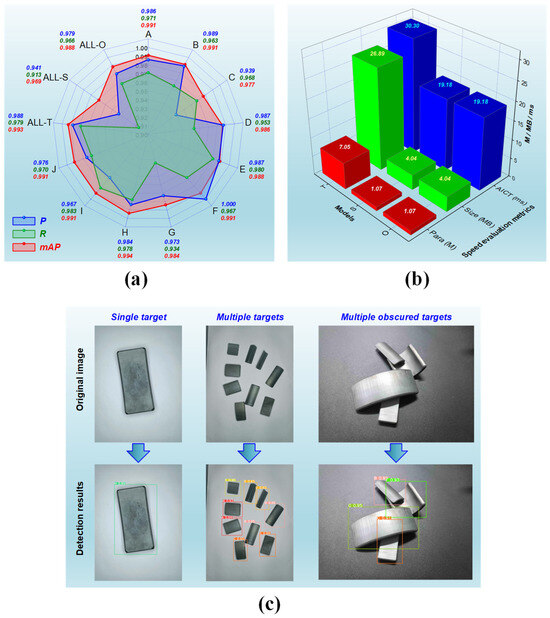
Figure 6.
Detection performance for various magnetic tile targets: (a) the accuracy-related results for detecting magnetic tile targets with ten types using teacher network, student network, and our method, respectively; (b) the speed-dependent results for detecting magnetic tile targets with ten types using teacher network, student network, and our method, respectively; (c) visualization of realistic detection effectiveness.
Figure 6b provides the results of the teacher network, pre-KD student network, and our method for detection speed evaluation metrics, including Para, Size, and AICT. As the student networks before and after KD originate from the identical compressed teacher network, they exhibit almost indistinguishable speed performance results. It can be observed that there are significant distinctions between the teacher network and our method in terms of the detection speed metrics. The teacher network has Para, Size, and AICT values of 7.05 M, 26.89 MB, and 30.30 ms, respectively, whereas our method corresponds to 1.07 M, 4.04 MB, and 19.18 ms, respectively. Our method leads to a reduction of approximately 84.82%, 84.98%, and 36.70% in the values of each metric, as compared to the teacher network. The significant reduction in Para and Size implies a substantial decrease in the model’s parameter count and storage size, thereby resulting in a noticeable reduction in the computational workload and computing resources needed for model execution. Thus, the AICT, indicative of the detection time, is dramatically shortened, leading to a significantly improved speed. Such speed enhancement, accomplished through decreased computational burden and computing capabilities, also implies the potential to deploy our method on more affordable operational platforms. It should be emphasized that the above AICT values are computed based on the computing power of our experimental device and only reflect the general computing capacity of some regular platforms. Our method’s detection speed would be further expedited if computational power is appropriately increased.
Benefiting from the accuracy and speed of our method, diverse categories of magnetic tile targets can be rapidly and precisely detected in practical production settings. Figure 6c displays the real-world detection effectiveness. As seen, single, multiple, and even numerous targets with substantial occlusions can be individually and accurately detected and correctly classified into their respective categories. Such detection performance is poised to play a crucial role in efficiently sorting different magnetic tiles on the production line.
4.4. Influence of Spatial Attention Modules on the YOLOv5s-Based Knowledge Distillation
In our improved KD approach, three identical SA modules for the teacher and student networks are introduced into the KD process, targeting the steps of large, medium, and small feature extraction in YOLOv5s. To validate the contributions of these three modules to KD, we employed an ablation strategy on our method to form five different processes of KD with varying quantities of SA modules. These five processes are individually labelled as Student network, KD-SAM1, KD-SAM2, KD-SAM3, and Our method. They allow us to investigate the effects of incorporating SA at different feature extraction steps for transferring intermediate-layer knowledge from the teacher to the student network. Apart from our approach, all other processes exclude incorporating MSOF, aiming to examine SA’s influence solely. The first case corresponds to the student network, indicating the performance after retraining without utilizing any SA. For KD-SAM1, only one SA module is inserted into the KD process to transfer the knowledge of the large feature extraction step from the teacher to the student networks. Conversely, KD-SAM2 incorporated two such modules, one each in both networks’ large and medium steps. Within KD-SAM3, the SA modules are introduced into the KD process for all three feature extraction steps (large, medium, and small) for both the teacher and student networks, reflecting the essence of our proposed method in applying SA. The final one refers to our method, including not only three SA modules but also MSOF. The motivation behind designing such an ablation experiment stems from the sequential progression of YOLOv5s’ three feature extraction steps, namely, large, medium, and small. The large step is the initial feature extraction phase responsible for obtaining coarse features of the targets; the medium step builds upon the coarse features obtained in the large step to extract finer characteristics; and the small step delves even deeper into the medium step to unearth more intricate and subtle target features. Hence, adding or removing SA modules should align with the hierarchical progression of feature extraction in YOLOv5s, ensuring that the attention mechanism captures sufficient knowledge from intermediate feature layers. To thoroughly validate the proposed approach, all five processes mentioned above undergo separate testing on both the magnetic tile dataset and the Pascal VOC 2012 dataset.
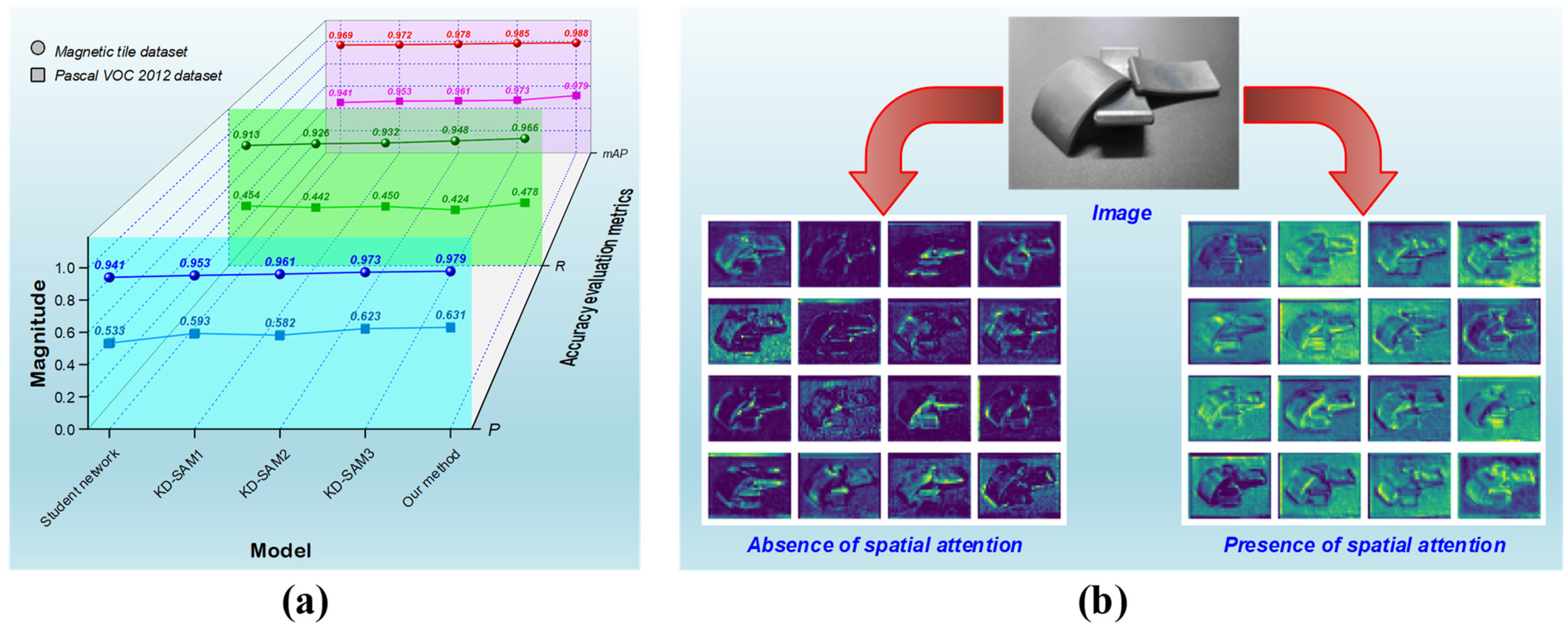
As depicted in Figure 7a, the accuracy performance of five processes is displayed to unveil the influence of introducing SA modules into KD. In the magnetic tile target detection task, it is evident that Student network, without any SA module, exhibits the lowest values for P, R, and mAP, indicating the lowest level of accuracy. As the SA modules gradually integrate into the feature extraction process from shallow to deep levels, all accuracy metrics exhibit synchronous improvements, resulting in KD-SAM2 outperforming KD-SAM1. Profiting from the three SA modules, P, R, and mAP associated with KD-SAM3 reach 0.973, 0.948, and 0.985, respectively, which is superior to other processes except for Our method. Compared to Student network, which lacks SA, our method ultimately improves P, R, and mAP for magnetic tile target detection by 3.8%, 5.3%, and 1.9%, respectively. Our method maintains a 0.6%, 1.8%, and 0.3% advantage over KD-SAM3 in terms of P, R, and mAP. These results indicate that the utilization of three SA modules is the optimal strategy, but the accuracy enhancement remains constrained and calls for the integration of MSOF.
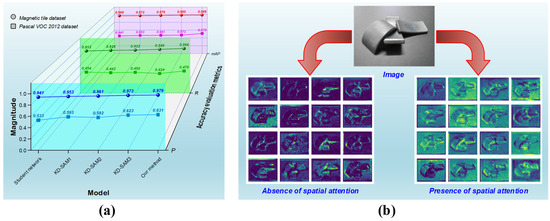
Figure 7.
The accuracy performance influenced by SA modules in KD: (a) variation in accuracy using different numbers of SA modules in KD; (b) visualization of target features extracted by student networks after KD with or without SA modules.
During Pascal VOC target detection, despite the R metric not showing a consistent increase with the addition of SA modules, P and mAP metrics adhere to this trend. Taking into account all accuracy metrics, Student network remains the poorest performer, KD-SAM2 slightly outperforms KD-SAM1, and KD-SAM3 continues to be better than KD-SAM2. Our method is still the top performer. Compared to Student network, which detects Pascal VOC targets, our method achieves improvements of 9.8%, 2.4%, and 3.8% in P, R, and mAP, respectively. The results of the ablation experiments conducted on these two datasets demonstrate that inserting identical SA modules into the KD process to acquire the knowledge linked to the three steps of large, medium, and small feature extraction in YOLOv5s indeed improves accuracy performance.
Such improvements are attributed to SA’s ability to capture knowledge from intermediate layers of the network’s feature extraction process. The captured intermediate-layer knowledge plays a vital role in emphasizing target features. Exemplified by magnetic tile targets, Figure 7b presents partial target feature maps generated from different feature extraction layers of the student network. It is evident that KD with SA renders more distinct and comprehensive target features extracted by the student network, ultimately improving target discrimination capacity. These pieces of knowledge, which are overlooked by conventional KD methods, are the additional valuable knowledge that our approach aims to unearth and transfer during the KD process. More importantly, although there have been some improvements in the accuracy of detecting other targets, the design of integrating identical SA modules into all feature extraction steps of YOLOv5s is particularly well-suited for bolstering the accuracy of magnetic tile target detection.
4.5. Impact of Multi-Scale Output Features on the YOLOv5s-Based Knowledge Distillation
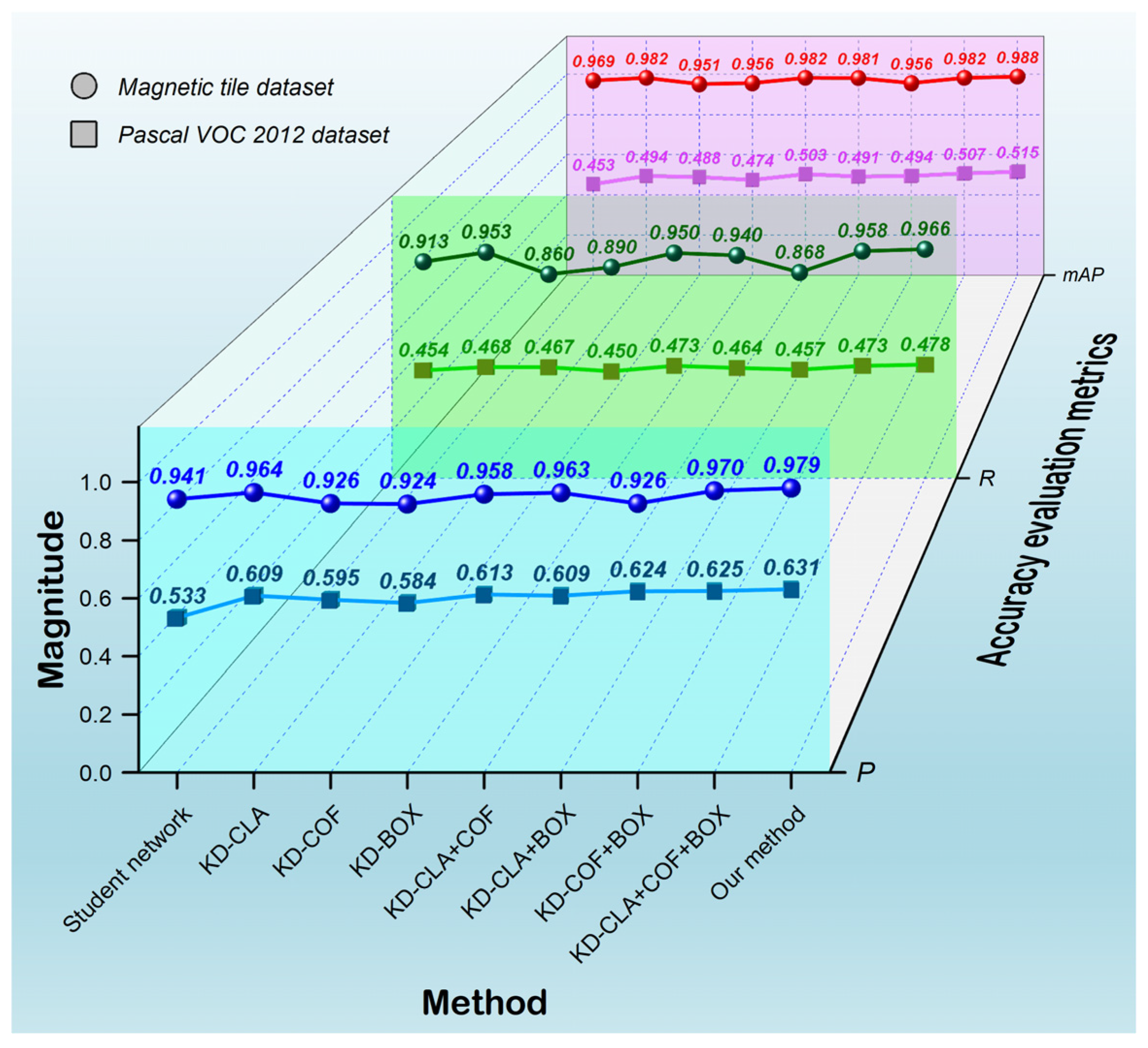
In addition to the intermediate-layer feature extraction knowledge brought by SA, our method also attends to the supplementary expertise associated with the network’s output features. In our approach, the conventional information, which the YOLOv5s network outputs during target detection, is combined by following their respective loss magnitudes. Such a combination includes classification loss, confidence loss, and bounding box loss, establishing multi-scale feature knowledge to correlate target output results. This knowledge is garnered from the teacher network and seamlessly transferred to the student network via the KD process. The supplementation and guidance of expertise within the student network’s retraining contribute to attaining an output prowess comparable to that of the teacher network. To appraise the justification for utilizing the devised MSOF in the context of KD, an ablation experiment focusing solely on the combination of distinct output loss information within our method was conducted. The absence of SA modules is considered within the context of the involved KD experiment. The focus is on discussing the contributions of distinct scale output features merely by manipulating various combinations of output loss information. Considering the ensemble of three diverse outputs, we designed nine distinct KD processes to facilitate the execution of the ablation experiment. They are sequentially referred to as Student network, KD-CLA, KD-COF, KD-BOX, KD-CLA+COF, KD-CLA+BOX, KD-COF+BOX, KD-CLA+COF+BOX, and Our method. The first one lacks any involvement of MSOF, representing a result of retraining the student network alone. KD-CLA, KD-COF, and KD-BOX signify the KD, where the MSOF corresponds to individual classification loss, confidence loss, and bounding box loss, respectively. KD-CLA+COF, KD-CLA+BOX, and KD-COF+BOX represent the KD processes combining two distinct types of output loss information in each case. KD-CLA+COF+BOX indicates the combination of all output loss information, denoting the KD using the MSOF proposed in our work. The last one constitutes our proposed complete KD method, encompassing SA modules for three feature extraction steps and MSOF from three output losses. Similarly, we test these nine KD processes utilizing the magnetic tile and Pascal VOC 2012 datasets. The accuracy performance of the re-trained student networks is comprehensively evaluated, as portrayed in Figure 8.
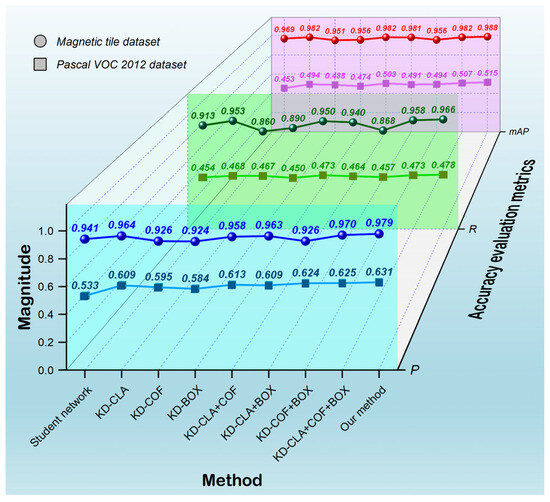
Figure 8.
The accuracy performance influenced by MSOF in KD.
Evidently, within the realm of detecting magnetic tile targets, the accuracy performance attainable through each associated KD process displays distinct variations as different output loss information is incorporated. Certain combinations of output losses lead to a reduction in detection accuracy after KD. For example, the utilization of KD-COF, KD-BOX, and KD-COF+BOX contributes to a decrease spanning 1.5–1.7% for P, 2.3–5.3% for R, and 1.3–1.8% for mAP. Conversely, alternate combinations, such as KD-CLA, KD-CLA+COF, KD-CLA+BOX, KD-CLA+COF+BOX, and Our method, are observed to enhance the detection accuracies. They yield improvements encompassing 1.7–3.8% for P, 2.7–5.3% for R, and 1.2–1.9% for mAP. An important point to highlight is that KD-CLA+COF+BOX achieved the highest accuracy performance among the combinations of output losses, underscoring that the incorporation of classification, confidence, and bounding box losses into the MSOF has the most pronounced impact on KD. The attained P, R, and mAP correspondingly stand at 0.970, 0.958, and 0.988. However, such a performance did not surpass Our method, exhibiting a disparity of 0.9%, 0.8%, and 0.6% in terms of P, R, and mAP, respectively. This observation implies that the contribution of the MSOF remains relatively limited, unable to fully substitute the facilitative role of SA in KD.
These observed phenomena and trends persist in the domain of detecting targets on the Pascal VOC 2012 dataset. The accuracy generated by KD-CLA, KD-CLA+COF, and KD-CLA+BOX consistently surpasses that of KD-COF, KD-BOX, and KD-COF+BOX, with improvements in the range of 7.6–8%, 1–1.9%, and 3.9–5% for P, recall R, and mAP, respectively. KD-CLA+COF+BOX exhibits superior performance compared to other output combinations, achieving P, R, and mAP values of 0.625, 0.473, and 0.507, respectively. Despite this, our method outperforms KD-CLA+COF+BOX, resulting in enhancements of 0.6%, 0.5%, and 0.8% for P, R, and mAP, respectively. As a result, the inclusion of MSOF in our approach can be confirmed as both reasonable and indispensable. The optimal accuracy performance is achieved when the three SA modules are combined with the MSOF based on three types of output losses.
4.6. Comparisons of Different Knowledge Distillation Methods
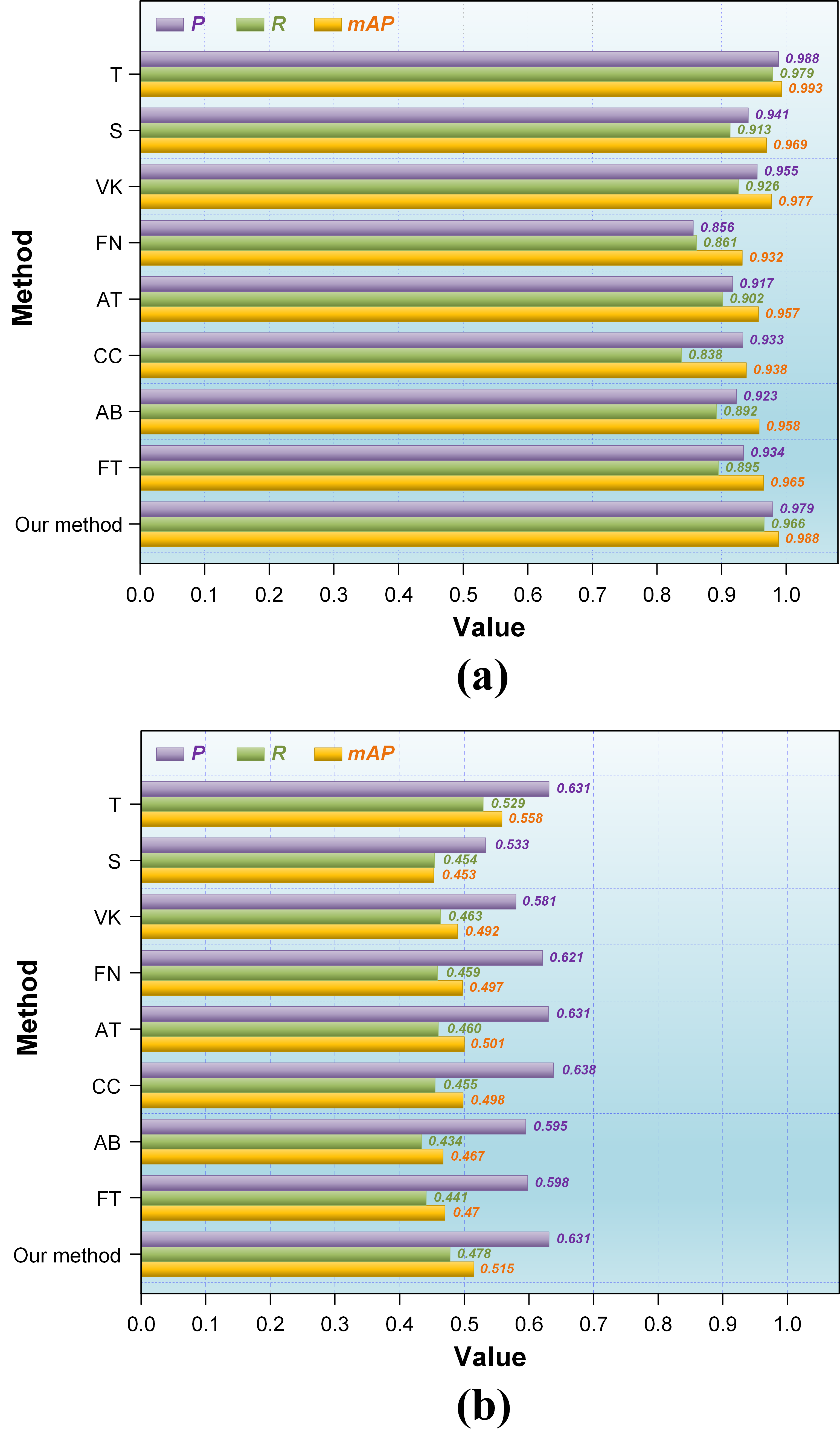
With the advancement of KD techniques, numerous related methods have emerged, leading to a plethora of meaningful applications. Six prevalent or innovative KD methods featured in other studies are selected to assess the superiority of our proposed KD method. These methods include vanilla KD (VK) [50], FitNet (FN) [51], attention transfer (AT) [52], correlation congruence (CC) [53], activation boundaries (AB) [54], and factor transfer (FT) [55]. Among them, VK adopts the fundamental architecture of KD without incorporating any further improvements. FN utilizes a neural network architecture to address knowledge transfer issues, aiming to enhance the distillation process. AT boosts the effectiveness of KD by transferring the attention mechanism from the teacher to the student network. CC employs the correlation between the hidden layer outputs of the teacher and student networks as the distillation loss function, thereby ensuring that the student network exhibits a structure similar to the teacher network in the hidden layer activations. AB enhances the performance of the student network by conveying the activation boundary information from the teacher network. FT improves the performance of the student network by transferring factor information from the teacher network, whose factors refer to specific structures or information in the network, such as filters in convolutional layers or weights in attention mechanisms. All selected KD methods utilize teacher and student networks consistent with the networks employed in our approach. For simplicity in our exposition, we adopt ‘T’ to signify the teacher network and ‘S’ to depict the student network. Each method sequentially conducts target detection on the magnetic tile dataset and the Pascal VOC 2012 dataset. The performance comparison is based on the accuracy metrics P, R, and mAP. To showcase the level of performance similarity achieved by KD between the student and teacher networks, the accuracies of both the well-trained teacher network and the pruned student network are also provided.
The detection accuracy for magnetic tile targets is shown in Figure 9a. As observed, FN, AT, CC, AB, and FT do not increase the accuracy of the student network; instead, they caused a significant reduction. The results indicate that these methods are not capable of uncovering and transferring relatively adequate knowledge concerning the detection of magnetic tile targets from the teacher network to the student network. On the contrary, only VK and our method improve the accuracy of the student network. Moreover, our approach achieved optimal accuracy performance, bringing the student network closest to the performance of the teacher network. In terms of P, R, and mAP, our method outperforms VK by 2.4%, 4%, and 1.1%, respectively, resulting in a respective improvement of 3.8%, 5.3%, and 1.9% in the student network, with a minimal difference of only 0.9%, 1.3%, and 0.5% compared to the teacher network.
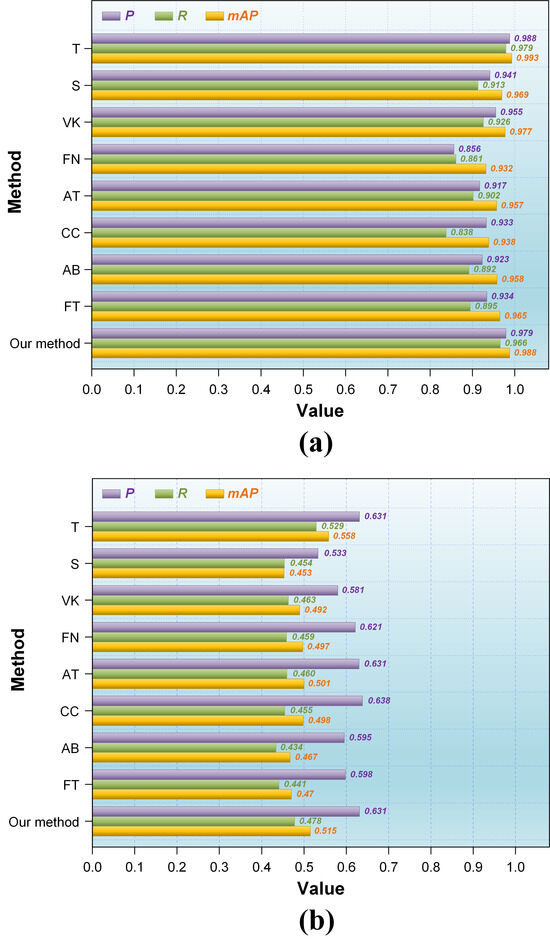
Figure 9.
Accuracy performance comparison of different KD methods in target detection: (a) magnetic tile dataset; (b) Pascal VOC 2012 dataset.
A similar phenomenon is also evident in the target detection accuracy on the Pascal VOC 2012 dataset, as shown in Figure 9b. Each method contributed to a marked improvement in the P and mAP of the student network. Only AB and FT cause a decrease in the R of the student network, while all the other methods contribute to an increase. Crucially, in comparison, our method produces the highest R and mAP for the student network. Although our method falls behind CC by 0.7% in P, it already brings the student network’s P to the same level as the teacher network and outperforms the remaining approaches. Our method significantly outperforms any other approach regarding comprehensive accuracy performance, as it reduces the gaps between the teacher and student networks in P, R, and mAP to 0%, 5.1%, and 4.3%, respectively.
From the above outcomes, it can be observed that our proposed method significantly improves the KD performance based on YOLOv5s, regardless of whether it is applied to magnetic tile target detection or other general target detection scenarios. Such an improvement allows the lightweight student network to approximate the performance of the large-scale teacher network closely.
5. Conclusions
To overcome the inefficiencies of manual sorting in the magnetic tile production process, we present an improved KD approach that integrates SA feature correlation and MSOF correlation. Such a method enhances the accuracy performance of the lightweight YOLOv5s model, addressing the challenge of achieving accurate, rapid, and easily deployable automated detection of various types of magnetic tile targets with low computing power. Within our proposed methodology, we refine the KD mechanism, enabling the compressed model obtained through channel-pruned YOLOv5s to acquire a more comprehensive understanding of target detection knowledge from the original YOLOv5s. This advancement empowers the initially low-performance small-scale model to attain high-performance capabilities that resemble a large-scale complex model. The positive outcome of our KD can be attributed to three significant elements:
- (1)
- Taking advantage of the YOLO model’s characteristic of performing target feature extraction in a stepwise manner with large, medium, and small steps, we introduce the same SA module at each step. This integration facilitates the establishment of corresponding spatial feature correlations for the targets during the distillation process, generating additional transferable knowledge on intermediate layer target feature extraction.
- (2)
- We consolidate the YOLO model’s classification, confidence, and bounding box outputs into MSOF. This amalgamation enables distillation to establish coherent correlations for output features related to target detection, forming supplementary transferable knowledge on output layer target feature recognition.
- (3)
- We devise a tailor-made evaluation metric that takes into account the model’s compression rate and accuracy loss. This metric ensures an optimal degree of compressing the teacher network into the student network in KD, thereby establishing a reasoned foundation for informed lightweight model design, striking a trade-off between compression rate and accuracy loss.
The experimental results demonstrate that in our self-built magnetic tile dataset, the P, R, and mAP for detecting magnetic tile targets reach 0.979, 0.966, and 0.988, respectively. The average processing speed for a single image is below 19.18 ms, and the model size is 4.04 MB, with a compression rate of 85%. In contrast to other commonly employed KD techniques, our method produces the most notable accuracy improvement for the student network. Moreover, it attains equivalent effectiveness in general target detection on the Pascal VOC 2012 dataset. Hence, our improvements in KD uncover a greater wealth of teacher network knowledge to guide the training of appropriately compressed student networks, resulting in superior performance for the final lightweight model. Our proposed approach offers a notable enhancement in magnetic tile target detection, particularly in scenarios involving low computing power and cost-effective deployment, while simultaneously demonstrating promise for broader application in other target detection tasks.
Despite its advancements, our method is not without limitations and potential areas for further enhancement. They can be summarized as follows:
- (1)
- There is still scope for improving the accuracy and speed of detecting magnetic tile targets. The detection performance for a broader range of targets beyond magnetic tiles requires thorough validation.
- (2)
- With the continuous evolution of the YOLO model, there remain numerous novel model versions and additional transferable knowledge that could be explored and incorporated into our KD mechanism.
These aspects will be the subject of ongoing research in our future work.
Author Contributions
Conceptualization, Q.H. and K.Y.; methodology, Q.H.; software, K.Y.; validation, Q.H., K.Y. and Y.Z.; formal analysis, Q.H.; investigation, K.Y.; resources, Q.H.; data curation, Q.H.; writing—original draft preparation, Q.H. and K.Y.; writing—review and editing, Q.H.; visualization, Q.H., K.Y. and L.C. (Long Chen); supervision, L.C. (Lijia Cao); project administration, Q.H.; funding acquisition, L.C. (Lijia Cao). All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by National Natural Science Foundation of China (Grant No. 61701330), the Talent Introduction Project of Sichuan University of Science and Engineering (Grant No. 2021RC30), and the Innovation Fund of Postgraduate, Sichuan University of Science and Engineering (Grant No. Y2022135 and Grant No. Y2022149).
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Huang, Q.Y.; Yin, Y.; Yin, G.F. Automatic classification of magnetic tiles internal defects based on acoustic resonance analysis. Mech. Syst. Signal Proc. 2015, 60, 45–58. [Google Scholar] [CrossRef]
- Huang, Q.Y.; Xie, L.F.; Yin, G.F.; Ran, M.X.; Liu, X.; Zheng, J. Acoustic signal analysis for detecting defects inside an arc magnet using a combination of variational mode decomposition and beetle antennae search. ISA Trans. 2020, 102, 347–364. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Yan, Z. Image target detection algorithm compression and pruning based on neural network. Comput. Sci. Inf. Syst. 2021, 18, 499–516. [Google Scholar] [CrossRef]
- Arkin, E.; Yadikar, N.; Xu, X.; Aysa, A.; Ubul, K. A survey: Object detection methods from CNN to transformer. Multimed. Tools Appl. 2023, 82, 21353–21383. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, L.; Sun, H.; Zhu, C. Longitudinal tear detection of conveyor belt under uneven light based on Haar-AdaBoost and Cascade algorithm. Measurement 2021, 168, 108341. [Google Scholar] [CrossRef]
- Zhou, W.; Gao, S.; Zhang, L.; Lou, X. Histogram of oriented gradients feature extraction from raw bayer pattern images. IEEE Trans. Circuits-II 2020, 67, 946–950. [Google Scholar] [CrossRef]
- Meena, K.B.; Tyagi, V. A hybrid copy-move image forgery detection technique based on Fourier-Mellin and scale invariant feature transforms. Multimed. Tools Appl. 2020, 79, 8197–8212. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Z.; Sun, J.; Zou, X.; Wang, J. A cascaded R-CNN with multiscale attention and imbalanced samples for traffic sign detection. IEEE Access 2020, 8, 29742–29754. [Google Scholar] [CrossRef]
- Zimmermann, R.S.; Siems, J.N. Faster training of Mask R-CNN by focusing on instance boundaries. Comput. Vis. Image Und. 2019, 188, 102795. [Google Scholar] [CrossRef]
- Wu, W.; Yin, Y.; Wang, X.; Xu, D. Face detection with different scales based on faster R-CNN. IEEE Trans. Cybernetics 2018, 49, 4017–4028. [Google Scholar] [CrossRef]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Zhang, H.; Eastwood, J.; Qi, X.; Jia, J.; Cao, Y. Concrete crack detection using lightweight attention feature fusion single shot multibox detector. Knowl.-Based Syst. 2023, 261, 110216. [Google Scholar] [CrossRef]
- Carranza-García, M.; Torres-Mateo, J.; Lara-Benítez, P.; García-Gutiérrez, J. On the performance of one-stage and two-stage object detectors in autonomous vehicles using camera data. Remote Sens. 2020, 13, 89. [Google Scholar] [CrossRef]
- Zhang, W.; Xia, X.; Zhou, G.; Du, J.; Chen, T.; Zhang, Z.; Ma, X. Research on the identification and detection of field pests in the complex background based on the rotation detection algorithm. Front. Plant Sci. 2022, 13, 1011499. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Sun, F.; Gu, J.; Deng, L. Sf-yolov5: A lightweight small object detection algorithm based on improved feature fusion mode. Sensors 2022, 22, 5817. [Google Scholar] [CrossRef] [PubMed]
- Olorunshola, O.E.; Irhebhude, M.E.; Evwiekpaefe, A.E. A Comparative Study of YOLOv5 and YOLOv7 Object Detection Algorithms. J. Comput. Social Inform. 2023, 2, 1–12. [Google Scholar] [CrossRef]
- Dang, F.; Chen, D.; Lu, Y.; Li, Z. YOLOWeeds: A novel benchmark of YOLO object detectors for multi-class weed detection in cotton production systems. Comput. Electron. Agric. 2023, 205, 107655. [Google Scholar] [CrossRef]
- Chen, E.; Liao, R.; Shalaginov, M.Y.; Zeng, T.H. Real-time detection of acute lymphoblastic leukemia cells using deep learning. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–9 December 2022; pp. 3788–3790. [Google Scholar] [CrossRef]
- Zhang, P.; Li, D. Automatic counting of lettuce using an improved YOLOv5s with multiple lightweight strategies. Expert Syst. Appl. 2023, 226, 120220. [Google Scholar] [CrossRef]
- Huang, Q.Y.; Zhou, Y.; Yang, T.; Yang, K.; Cao, L.J.; Xia, Y. A lightweight transfer learning model with pruned and distilled YOLOv5s to identify arc magnet surface defects. Appl. Sci. 2023, 13, 2078. [Google Scholar] [CrossRef]
- Romero, R.; Celard, P.; Sorribes-Fdez, J.M.; Vieira, A.S.; Iglesias, E.L.; Borrajo, L. MobyDeep: A lightweight CNN architecture to configure models for text classification. Knowl.-Based Syst. 2022, 257, 109914. [Google Scholar] [CrossRef]
- Yeom, S.K.; Seegerer, P.; Lapuschkin, S.; Binder, A.; Wiedemann, S.; Müller, K.R.; Samek, W. Pruning by explaining: A novel criterion for deep neural network pruning. Pattern Recogn. 2021, 115, 107899. [Google Scholar] [CrossRef]
- Prakash, P.; Ding, J.H.; Chen, R.; Qin, X.Q.; Shu, M.L.; Cui, Q.M.; Guo, Y.X.; Pan, M. IoT device friendly and communication-efficient federated learning via joint model pruning and quantization. IEEE Internet Things 2022, 9, 13638–13650. [Google Scholar] [CrossRef]
- Lindauer, M.; Hutter, F. Best practices for scientific research on neural architecture search. J. Mach. Learn. Res. 2020, 21, 9820–9837. [Google Scholar]
- Gou, J.P.; Yu, B.S.; Maybank, S.J.; Tao, D.C. Knowledge distillation: A survey. Int. J. Comput. Vision 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Wang, L.; Yoon, K.J. Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks. IEEE Trans. Pattern Anal. 2021, 44, 3048–3068. [Google Scholar] [CrossRef] [PubMed]
- Prieto, A.; Prieto, B.; Ortigosa, E.M.; Ros, E.; Pelayo, F.; Ortega, J.; Rojas, I. Neural networks: An overview of early research, current frameworks and new challenges. Neurocomputing 2016, 214, 242–268. [Google Scholar] [CrossRef]
- Takashima, R.; Sheng, L.; Kawai, H. Investigation of Sequence-Level Knowledge Distillation Methods for CTC Acoustic Models. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2019), Brighton, UK, 12–17 May 2019; pp. 6156–6160. [Google Scholar] [CrossRef]
- Zhang, H.L.; Chen, D.F.; Wang, C. Confidence-Aware Multi-Teacher Knowledge Distillation. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2022), Singapore, 22–27 May 2022; pp. 4498–4502. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, W.; Wang, J. Adaptive multi-teacher multi-level knowledge distillation. Neurocomputing 2020, 415, 106–113. [Google Scholar] [CrossRef]
- Shen, C.C.; Wang, X.C.; Song, J.; Sun, L.; Song, M.L. Amalgamating Knowledge Towards Comprehensive Classification. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; pp. 3068–3075. [Google Scholar] [CrossRef]
- Bian, C.L.; Feng, W.; Wan, L.; Wang, S. Structural knowledge distillation for efficient skeleton-based action recognition. IEEE Trans. Image Process. 2021, 30, 2963–2976. [Google Scholar] [CrossRef]
- Gou, J.P.; Sun, L.Y.; Yu, B.S.; Wan, S.H.; Ou, W.H.; Yi, Z. Multilevel Attention-Based Sample Correlations for Knowledge Distillation. IEEE Trans. Ind. Inform. 2022, 19, 7099–7109. [Google Scholar] [CrossRef]
- Mushtaq, F.; Ramesh, K.; Deshmukh, S.; Ray, T.; Parimi, C.D.; Tandon, P.; Jha, P.K. Nuts&bolts: YOLO-v5 and image processing based component identification system. Eng. Appl. Artif. Intel. 2023, 118, 105665. [Google Scholar] [CrossRef]
- Gupta, C.; Gill, N.S.; Gulia, P.; Chatterjee, J.M. A novel finetuned YOLOv6 transfer learning model for real-time object detection. J. Real-Time Image Process. 2023, 20, 42. [Google Scholar] [CrossRef]
- Gallo, I.; Rehman, A.U.; Dehkordi, R.H.; Landro, N.; Grassa, R.L.; Boschetti, M. Deep object detection of crop weeds: Performance of YOLOv7 on a real case dataset from UAV images. Remote Sens. 2023, 15, 539. [Google Scholar] [CrossRef]
- Talaat, F.M.; Hanaa, Z.E. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 2023, 2023, 1–16. [Google Scholar] [CrossRef]
- Shen, L.; Su, J.Y.; He, R.T.; Song, L.J.; Huang, R.; Fang, Y.L.; Song, Y.Y.; Su, B.F. Real-time tracking and counting of grape clusters in the field based on channel pruning with YOLOv5s. Comput. Electron. Agric. 2023, 206, 107662. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, Z.Y.; Wu, J.Q.; Tian, Y.; Tang, H.T.; Guo, X.M. Real-time vehicle detection based on improved YOLO v5. Sustainability 2022, 14, 12274. [Google Scholar] [CrossRef]
- Kim, M.; Jeong, J.; Kim, S. ECAP-YOLO: Efficient channel attention pyramid YOLO for small object detection in aerial image. Remote Sens. 2021, 13, 4851. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Xu, C.Y.; Gao, W.J.; Li, T.; Bai, N.L.; Li, G.; Zhang, Y. Teacher-student collaborative knowledge distillation for image classification. Appl. Intell. 2023, 53, 1997–2009. [Google Scholar] [CrossRef]
- Gotmare, A.; Keskar, N.S.; Xiong, C.M.; Socher, R. A closer look at deep learning heuristics: Learning rate restarts, warmup and distillation. arXiv 2018, arXiv:1810.13243. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, Z.W.; Chen, Y.P.; Jin, Y.L.; Bai, G.S. Selective kernel convolution deep residual network based on channel-spatial attention mechanism and feature fusion for mechanical fault diagnosis. ISA Trans. 2023, 133, 369–383. [Google Scholar] [CrossRef]
- Chen, Y.M.; Wen, X.; Zhang, Y.W.; He, Q. FPC: Filter pruning via the contribution of output feature map for deep convolutional neural networks acceleration. Knowl.-Based Syst. 2022, 238, 107876. [Google Scholar] [CrossRef]
- Li, Z.H.; Xu, P.F.; Chang, X.J.; Yang, L.Y.; Zhang, Y.Y.; Yao, L.N.; Chen, X.J. When Object Detection Meets Knowledge Distillation: A Survey. IEEE Trans. Pattern Anal. 2023, 45, 10555–10579. [Google Scholar] [CrossRef] [PubMed]
- Tong, K.; Wu, Y.Q. Rethinking PASCAL-VOC and MS-COCO dataset for small object detection. J. Vis. Commun. Image R. 2023, 93, 103830. [Google Scholar] [CrossRef]
- Gong, H.; Mu, T.K.; Li, Q.X.; Dai, H.S.; Li, C.L.; He, Z.P.; Wang, W.J.; Han, F.; Tuniyazi, A.; Li, H.Y.; et al. Swin-transformer-enabled YOLOv5 with attention mechanism for small object detection on satellite images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Lin, Y.D.; Chen, T.T.; Liu, S.Y.; Cai, Y.L.; Shi, H.W.; Zheng, D.K.; Lan, Y.B.; Yue, X.J.; Zhang, L. Quick and accurate monitoring peanut seedlings emergence rate through UAV video and deep learning. Comput. Electron. Agric. 2022, 197, 106938. [Google Scholar] [CrossRef]
- Tan, C.; Liu, J.; Zhang, X. Improving knowledge distillation via an expressive teacher. Knowl.-Based Syst. 2021, 218, 106837. [Google Scholar] [CrossRef]
- Zhao, H.R.; Sun, X.; Dong, J.Y.; Dong, Z.H.; Li, Q. Knowledge distillation via instance-level sequence learning. Knowl.-Based Syst. 2021, 233, 107519. [Google Scholar] [CrossRef]
- Gou, J.P.; Sun, L.Y.; Yu, B.S.; Wan, S.H.; Tao, D.C. Hierarchical multi-attention transfer for knowledge distillation. ACM Trans. Multimedia Comput. Commun. Appl. 2022, 20, 51. [Google Scholar] [CrossRef]
- Peng, B.Y.; Jin, X.; Liu, J.H.; Li, D.S.; Wu, Y.C.; Liu, Y.; Zhou, S.F.; Zhang, Z.N. Correlation Congruence for Knowledge Distillation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 5007–5016. [Google Scholar]
- Heo, B.; Lee, M.; Yun, S.; Choi, J.Y. Knowledge Transfer Via Distillation of Activation Boundaries Formed by Hidden Neurons. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; pp. 3779–3787. [Google Scholar] [CrossRef]
- Kim, J.; Park, S.; Kwak, N. Paraphrasing Complex Network: Network Compression via Factor Transfer. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 2765–2774. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).