




Attention-Guided HDR Reconstruction for Enhancing Smart City Applications




Abstract
:1. Introduction
- (1)
- A novel HDR reconstruction framework designed specifically for enhancing image quality in edge–cloud-based video surveillance systems. This model integrates a unique FEM and a WAM to produce HDR images of exceptional quality across diverse scenarios.
- (2)
- Within the FEM, this study introduces a hybrid architecture that melds the strengths of self-attention mechanisms with convolution operations. This approach adeptly captures global image dependencies while retaining essential local image contexts, ensuring optimal HDR image reconstruction.
- (3)
- Acknowledging the significance of saturated areas in HDR images, the WAM is equipped with a supervised weight map and attention map. This design emphasizes the reconstruction of these pivotal areas, refining intricate details and boosting the perceptual quality of the resultant images, even under challenging lighting conditions.
- (4)
- We conducted an extensive series of experiments on multiple publicly available HDR image reconstruction datasets. The quantitative and qualitative results emphatically underscore the superior performance and robustness of the proposed method.
2. Related Studies
2.1. Single-Image HDR Reconstruction
2.2. Attention Mechanism
2.3. Vison Transformer
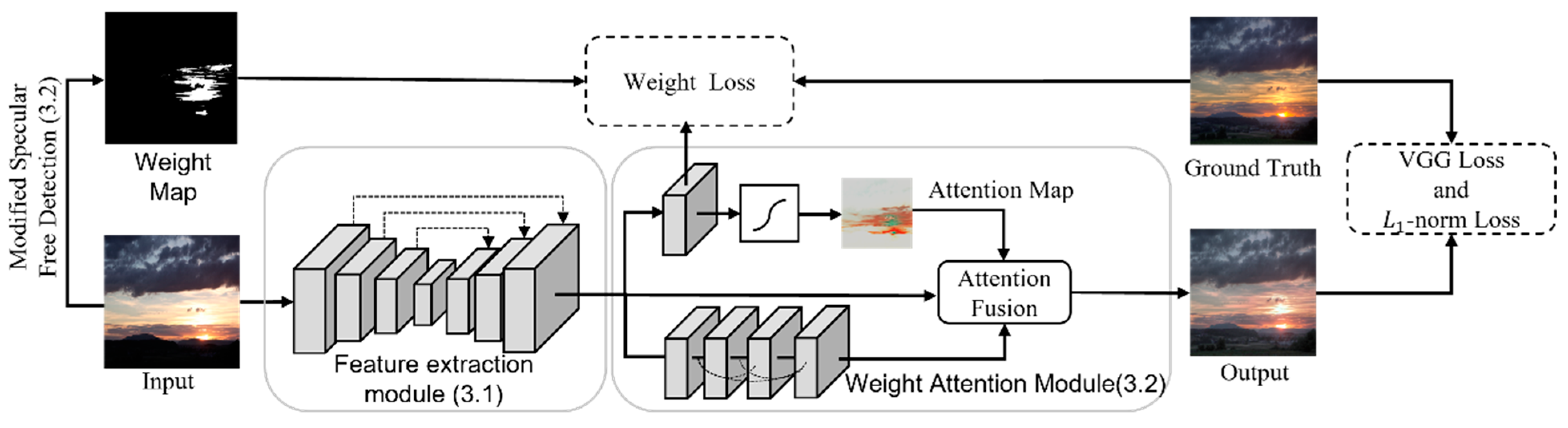
3. Proposed Single-Image HDR Reconstruction Framework
3.1. Feature Extraction Module
| Algorithm 1: Edge-guided reinforcement block |
| Input: Feature map F, guidance image G, radius r, regularization term |
| Output: Feature map |
| Step 1: Utilize box filter (.) to compute the correlation coefficient, which includes , , , and |
| Step 2: Determine the optimal linear transformation parameter coefficients and based on the given formulas. |
| Step 3: Compute the mean values of parameters and using the provided formulas and derive the output image O using guided filtering. |
| Step 4: Concatenate F with O and perform a convolution to fuse the feature and modify the channel size of the feature. |
3.2. Weight Attention Module
3.3. Loss Function
- Perceptual loss. To generate more reasonable and realistic details in the output HDR image, we use perceptual loss [46]. This loss function attempts to evaluate the match degree of the reconstructed image features with the features extracted from the ground truth, enabling the model to produce a feature representation akin to the ground truth. The perceptual loss function calculation formula is as follows:
- Weight loss. To generate higher quality HDR images in the output saturation areas, we designed a weight loss, as detailed in Section 3.2. This loss function identifies the location of saturated areas in the image and generates a weight map, enabling the network to focus on evaluating values in pixel-level saturated areas during training. The weight loss function calculation formula is as follows:
4. Experiment
4.1. Datasets and Experiment Settings
4.2. Qualitative Comparison
4.3. Quantitative Comparison
4.4. Ablation Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.-Y.; Lin, Y.-H.; Hu, Y.-C.; Hsia, C.-H.; Lian, Y.-A.; Jhong, S.-Y. Distributed Real-Time Object Detection Based on Edge-Cloud Collaboration for Smart Video Surveillance Applications. IEEE Access 2022, 10, 93745–93759. [Google Scholar] [CrossRef]
- Hsiao, S.-J.; Sung, W.-T. Intelligent Home Using Fuzzy Control Based on AIoT. Comput. Syst. Sci. Eng. 2023, 45, 1063–1081. [Google Scholar] [CrossRef]
- Ezzat, M.A.; Ghany, M.A.A.E.; Almotairi, S.; Salem, M.A.-M. Horizontal Review on Video Surveillance for Smart Cities: Edge Devices, Applications, Datasets, and Future Trends. Sensors 2021, 21, 3222. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Qiao, Y.; Ruichek, Y. Multiframe-Based High Dynamic Range Monocular Vision System for Advanced Driver Assistance Systems. IEEE Sens. J. 2015, 15, 5433–5441. [Google Scholar] [CrossRef]
- Barten, P.G.J. Contrast Sensitivity of the Human Eye and Its Effects on Image Quality; SPIE: Bellingham, WA, USA, 1999; Volume PM72. [Google Scholar]
- Purohit, M.; Singh, M.; Kurmar, A.; Kaushik, B.K. Enhancing the Surveillance Detection Range of Image Sensors using HDR Techniques. IEEE Sens. J. 2021, 21, 19516–19528. [Google Scholar] [CrossRef]
- Xu, Q.; Su, Z.; Zheng, Q.; Luo, M.; Dong, B. Secure Content Delivery with Edge Nodes to Save Caching Resources for Mobile Users in Green Cities. IEEE Trans. Industr. Inform. 2018, 14, 2550–2559. [Google Scholar] [CrossRef]
- Yan, X.; Yin, P.; Tang, Y.; Feng, S. Multi-Keywords Fuzzy Search Encryption Supporting Dynamic Update in An Intelligent Edge Network. Connect. Sci. 2022, 34, 511–528. [Google Scholar] [CrossRef]
- Ren, J.; Guo, H.; Xu, C.; Zhang, Y. Serving at the Edge: A Scalable IoT Architecture Based on Transparent Computing. IEEE Netw. 2017, 31, 96–105. [Google Scholar] [CrossRef]
- Kalantari, N.K.; Ramamoorthi, R. Deep High Dynamic Range Imaging of Dynamic Scenes. ACM Trans. Graph. 2017, 36, 1–12. [Google Scholar] [CrossRef]
- Wu, S.; Xu, J.; Tai, Y.-W.; Tang, C.-K. Deep High Dynamic Range Imaging with Large Foreground Motions. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 120–135. [Google Scholar]
- Liu, Y.-L.; Lai, W.S.; Chen, Y.S.; Kao, Y.L.; Yang, M.H.; Chuang, Y.Y.; Huang, J.B. Single-Image HDR Reconstruction by Learning to Reverse the Camera Pipeline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1648–1657. [Google Scholar]
- Eilertsen, G.; Kronander, J.; Denes, G.; Mantiuk, R.K.; Unger, J. HDR Image Reconstruction from A Single Exposure using Deep CNNs. ACM Trans. Graph. 2017, 36, 1–15. [Google Scholar] [CrossRef]
- Banterle, F.; Ledda, P.; Debattista, K.; Chalmers, A. Inverse Tone Mapping. In Proceedings of the 4th International Conference on Computer Graphics and Interactive Techniques in Australasia and Southeast Asia, Perth, Australia, 1–4 December 2006; pp. 349–356. [Google Scholar]
- Landis, H. Production-Ready Global Illumination. In Proceedings of the International Conference on Computer Graphics and Interactive Techniques, San Antonio, TX, USA, 21–26 July 2002; pp. 93–95. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Conference Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration using Swin Transformer. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 5718–5729. [Google Scholar]
- Masia, B.; Agustin, S.; Fleming, R.W.; Sorkine, O.; Gutierrez, D. Evaluation of Reverse Tone Mapping through Varying Exposure Conditions. ACM Trans. Graph. 2009, 28, 1–8. [Google Scholar] [CrossRef]
- Bist, C.; Cozot, R.; Madec, G.; Duclox, X. Tone Expansion using Lighting Style Aesthetics. Comput. Graph. 2017, 62, 77–86. [Google Scholar] [CrossRef]
- Didyk, P.; Mantiuk, R.; Hein, M.; Seidel, H.P. Enhancement of Bright Video Features for HDR Displays. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2008; pp. 1265–1274. [Google Scholar]
- Rempel, A.G.; Trentacoste, M.; Seetzen, H.; Young, H.D.; Heidrich, W.; Whitehead, L.; Ward, G. LDR2HDR: On-The-Fly Reverse Tone Mapping of Legacy Video and Photographs. ACM Trans. Graph. 2007, 26, 39-es. [Google Scholar] [CrossRef]
- Wu, G.; Song, R.; Zhang, M.; Li, X.; Rosin, P.L. LiTMNet: A Deep CNN for Efficient HDR Image Reconstruction from a Single LDR Image. Pattern Recognit. 2022, 127, 108620. [Google Scholar] [CrossRef]
- Marnerides, D.; Bashford-Rogers, T.; Hatchett, J.; Debattista, K. ExpandNet: A Deep Convolutional Neural Network for High Dynamic Range Expansion from Low Dynamic Range Content. Comput. Graph. Forum 2018, 37, 37–49. [Google Scholar] [CrossRef]
- Khan, Z.; Khanna, M.; Raman, S. FHDR: HDR Image Reconstruction from a Single LDR Image using Feedback Network. In Proceedings of the IEEE Global Conference on Signal and Information Processing, Ottawa, ON, Canada, 11–14 November 2019; pp. 1–5. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3242–3250. [Google Scholar]
- Fan, H.; Zhou, J. Stacked Latent Attention for Multimodal Reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1072–1080. [Google Scholar]
- Yan, Q.; Gong, D.; Shi, Q.; van den Hengel, A.; Shen, C.; Reid, I.; Zhang, Y. Attention-Guided Network for Ghost-Free High Dynamic Range Imaging. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1751–1760. [Google Scholar]
- Tel, S.; Wu, Z.; Zhang, Y.; Heyrman, B.; Demonceaux, C.; Timofte, R.; Ginhac, D. Alignment-Free HDR Deghosting with Semantics Consistent Transformer. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 12836–12845. [Google Scholar]
- Tao, H.; Duan, Q.; An, J. An Adaptive Interference Removal Framework for Video Person Re-Identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 5148–5159. [Google Scholar] [CrossRef]
- Abdusalomov, A.B.; Mukhiddinov, M.; Whangbo, T.K. Brain Tumor Detection Based on Deep Learning Approaches and Magnetic Resonance Imaging. Cancers 2023, 15, 4172. [Google Scholar] [CrossRef] [PubMed]
- Tao, H.; Duan, Q.; Lu, M.; Hu, Z. Learning Discriminative Feature Representation with Pixel-Level Supervision for Forest Smoke Recognition. Pattern Recognit. 2023, 143, 109761. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, X.; Sun, L.; Liang, Z.; Zeng, H.; Zhang, L. Joint HDR Denoising and Fusion: A Real-World Mobile HDR Image Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 13966–13975. [Google Scholar]
- Yan, Q.; Zhang, L.; Liu, Y.; Zhu, Y.; Sun, J.; Shi, Q.-F.; Zhang, Y. Deep HDR Imaging via a Non-Local Network. IEEE Trans. Image Process. 2020, 29, 4308–4322. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training Data-Efficient Image Transformers and Distillation through Attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 10347–10357. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Li, K.; Yu, R.; Wang, Z.; Yuan, L.; Song, G.; Chen, J. Locality Guidance for Improving Vision Transformers on Tiny Datasets. In Proceedings of the European Conference on Computer Vision, Tel-Aviv, Israel, 23–27 October 2022; pp. 110–127. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Huang, T.; Li, S.; Jia, X.; Lu, H.; Liu, J. Neighbor2Neighbor: Self-Supervised Denoising from Single Noisy Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14781–14790. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Yin, P.; Yuan, R.; Cheng, Y.; Wu, Q. Deep Guidance Network for Biomedical Image Segmentation. IEEE Access 2020, 8, 116106–116116. [Google Scholar] [CrossRef]
- Wang, L.; Yoon, K.-J. Deep Learning for HDR Imaging: State-of-the-Art and Future Trends. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8874–8895. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wang, Y.; Tohidypour, H.; Pourazad, M.T.; Nasiopoulos, P. A Generative Adversarial Network Based Tone Mapping Operator for 4K HDR Images. In Proceedings of the IEEE International Conference on Computing, Networking and Communications, Honolulu, HI, USA, 20–22 February 2023; pp. 473–477. [Google Scholar]
- Shen, H.; Zhang, H.; Shao, S.; Xin, J. Chromaticity-based separation of reflection components in a single image. Pattern Recognit. 2008, 41, 2461–2469. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Li, F.F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Funt, B.; Shi, L. The Effect of Exposure on MaxRGB Color Constancy. In Proceedings of the Human Vision and Electronic Imaging XV, San Jose, CA, USA, 18–21 January 2010. [Google Scholar]
- Feng, X.; DiCarlo, J.; Catrysse, P.; Wandell, B. High dynamic range imaging of natural scenes. In Proceedings of the Color and Imaging Conference, Scottsdale, AZ, USA, 12–15 November 2002; pp. 337–342. [Google Scholar]
- Reinhard, E.; Heidrich, W.; Debevec, P.; Pattanaik, S.; Ward, G.; Myszkowski, K. High Dynamic Range Imaging: Acquisition, Display, and Image-Based Lighting; Morgan Kaufmann: Burlington, MA, USA, 2010. [Google Scholar]
- Fairchild, M. The HDR Photographic Survey. In Proceedings of the Color and Imaging Conference, Albuquerque, NM, USA, 5–9 November 2007; pp. 233–238. [Google Scholar]
- Lee, B.; Sunwoo, M. HDR Image Reconstruction Using Segmented Image Learning. IEEE Access 2021, 9, 142729–142742. [Google Scholar] [CrossRef]
- Zhou, C.; Smith, J.; Wang, Q.; Chen, L.; Wu, Z. Polarization Guided HDR Reconstruction via Pixel-Wise Depolarization. IEEE Trans. Image Process. 2023, 32, 1774–1787. [Google Scholar] [CrossRef]
- Joffre, G.; Puech, W.; Comby, F.; Joffre, J. High Dynamic Range Images from Digital Cameras Raw Data. In Proceedings of the International Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 31 July–4 August 2005; p. 72-es. [Google Scholar]
- Nemoto, H.; Korshunov, P.; Hanhart, P.; Ebrahimi, T. Visual Attention in LDR and HDR Images. In Proceedings of the International Workshop on Video Processing and Quality Metrics for Consumer Electronics, Chandler, AZ, USA, 5–6 February 2015. [Google Scholar]
- Kovaleski, R.; Oliveira, M. High-Quality Reverse Tone Mapping for a Wide Range of Exposures. In Proceedings of the Conference on Graphics, Patterns, and Images, Columbus, OH, USA, 26–30 August 2014; pp. 49–56. [Google Scholar]
- Masia, B.; Serrano, A.; Gutierrez, D. Dynamic Range Expansion Based on Image Statistics. Multimed. Tools Appl. 2017, 76, 631–648. [Google Scholar] [CrossRef]
- Wang, H.; Ye, M.; Zhu, X.; Li, S.; Zhu, C.; Li, X. KUNet: Imaging Knowledge-Inspired Single HDR Image Reconstruction. In Proceedings of the International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 1408–1414. [Google Scholar]
- Hore, A.; Ziou, D.; Image Quality Metrics: PSNR, vs. SSIM. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Wang, Z.; Simoncelli, P.; Bovik, C. Multiscale Structural Similarity for Image Quality Assessment. In Proceedings of the Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Narwaria, M.; Mantiuk, R.; Da Silva, M.; Le Callet, P. HDR-VDP-2.2: A Calibrated Method for Objective Quality Prediction of High-Dynamic Range and Standard Images. J. Electron. Imaging 2015, 24, 010501. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | HDR-Synth-Real | HDR-EYE | ||||||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | MS-SSIM | Q-Score | PSNR | SSIM | MS-SSIM | Q-Score | |
| MEO [56] | 14.3587 | 0.5558 | 0.7273 | 47.9059 | 15.3920 | 0.6789 | 0.8143 | 50.7127 |
| rTMO [55] | 15.7702 | 0.5903 | 0.7906 | 49.9514 | 15.6703 | 0.6932 | 0.8492 | 50.9251 |
| HDRCNN [13] | 15.8559 | 0.5893 | 0.7982 | 51.1234 | 16.9791 | 0.7024 | 0.8520 | 52.2274 |
| ExpandNet [24] | 15.7862 | 0.6122 | 0.7877 | 50.0693 | 17.4671 | 0.7555 | 0.8753 | 52.4345 |
| Liu et al. [12] | 16.8019 | 0.6322 | 0.8123 | 52.5716 | 19.5234 | 0.7999 | 0.9255 | 54.7989 |
| FHDR [25] | 17.1186 | 0.6542 | 0.8308 | 52.1636 | 19.4047 | 0.7913 | 0.9307 | 53.7691 |
| KUNet [57] | 17.2050 | 0.6206 | 0.8159 | 52.1499 | 18.9806 | 0.7531 | 0.9202 | 53.6063 |
| This work | 17.4261 | 0.6503 | 0.8376 | 52.7729 | 19.5814 | 0.8105 | 0.9367 | 54.9493 |
| FEM | WAM | PSNR | SSIM | MS-SSIM | Runtime (ms) | |
|---|---|---|---|---|---|---|
| LASwin Transformer Block | ERB | |||||
| Unet backbone (Baseline) [13] | 12.2037 | 0.5753 | 0.7675 | 205 | ||
| ✓ | 16.9339 | 0.6443 | 0.8370 | 322 | ||
| ✓ | ✓ | 17.1641 | 0.6490 | 0.8404 | 343 | |
| ✓ | ✓ | 17.0415 | 0.6451 | 0.8370 | 381 | |
| ✓ | ✓ | ✓ | 17.4261 | 0.6503 | 0.8376 | 395 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-Y.; Hsia, C.-H.; Jhong, S.-Y.; Lai, C.-F. Attention-Guided HDR Reconstruction for Enhancing Smart City Applications. Electronics 2023, 12, 4625. https://doi.org/10.3390/electronics12224625
Chen Y-Y, Hsia C-H, Jhong S-Y, Lai C-F. Attention-Guided HDR Reconstruction for Enhancing Smart City Applications. Electronics. 2023; 12(22):4625. https://doi.org/10.3390/electronics12224625
Chicago/Turabian StyleChen, Yung-Yao, Chih-Hsien Hsia, Sin-Ye Jhong, and Chin-Feng Lai. 2023. "Attention-Guided HDR Reconstruction for Enhancing Smart City Applications" Electronics 12, no. 22: 4625. https://doi.org/10.3390/electronics12224625
APA StyleChen, Y.-Y., Hsia, C.-H., Jhong, S.-Y., & Lai, C.-F. (2023). Attention-Guided HDR Reconstruction for Enhancing Smart City Applications. Electronics, 12(22), 4625. https://doi.org/10.3390/electronics12224625