Abstract
As a special form of recurrent neural network (RNN), echo state networks (ESNs) have achieved good results in nonlinear system modeling, fuzzy nonlinear control, time series prediction, and so on. However, the traditional single-reservoir ESN topology limits the prediction ability of the network. In this paper, we design a multireservoir olfactory feelings echo state network (OFESN) inspired by the structure of the Drosophila olfactory bulb, which provides a new connection mode. The connection between subreservoirs is transformed into the connection between each autonomous neuron, the neurons in each subreservoir are sparsely connected, and the neurons in different subreservoirs cannot communicate with each other. The OFESN greatly simplifies the coupling connections between neurons in different libraries, reduces information redundancy, and improves the running speed of the network. The findings from the simulation demonstrate that the OFESN model, as introduced in this study, enhances the capacity to approximate sine superposition function and the Mackey–Glass system when combined. Additionally, this model exhibits improved prediction accuracy by 98% in some cases and reduced fluctuations in prediction errors.
1. Introduction
A recurrent neural network (RNN) is a class of artificial neural networks that use their internal memory to process arbitrary sequences of inputs, forming internal states of the network through cyclic connections between the units, allowing their dynamic time behavior to be displayed [1]. The echo state network (ESN) is a member of the RNN family [2]. Like RNNs, ESNs have the ability of nonlinear autoregression, but they also solve the challenges related to slow convergence speed and complex training process encountered in traditional RNNs. ESNs hav been employed for the purpose of forecasting the renowned Mackey–Glass chaotic time series. Remarkably, the application of an ESN resulted in a substantial enhancement of prediction accuracy, achieving an impressive rise of 2400 times, as reported in [3]. ESNs are composed of three main components: an input layer, a reservoir, and an output layer. The reservoir can be considered analogous to the hidden layer of ESNs. It is comprised of several neurons that exhibit sparse connections. The reservoir of an ESN has the following characteristics: (1) In contrast to the hidden layer of conventional neural networks, the reservoir can accommodate a relatively higher number of neurons without significantly augmenting the difficulty of the training algorithm or the time complexity. (2) The connections between neurons are formed in a random manner, and no subsequent adjustments are performed following their initial formation. (3) Neurons exhibit a sparse connectivity pattern.
The training procedure of ESNs involves the adjustment of connection weights between the reservoir and the output layer. Given the aforementioned attributes of the reservoir, ESNs exhibit the subsequent noteworthy features: (1) ESNs employ a hidden layer that consists of a sparsely linked reservoir, which is produced randomly. (2) The reservoir generation process is autonomous and occurs prior to the training phase of the ESN, hence guaranteeing the stability of the ESN throughout training and its ability to generalize after training. (3) With the exception of output connection weights, all other connection weights are initially created randomly and stay unaltered during the training process. (4) The output connection weights can be acquired through the utilization of linear regression or the least square approach [4]. This streamlines the training procedure of the neural network. The architecture of ESNs is characterized by their straightforward design, while the training procedure is known for its efficiency in terms of speed. ESNs have been applied successfully to a wide range of domains, including nonlinear modeling [5], pattern recognition [6], fuzzy nonlinear control [7,8], time series prediction [9,10,11,12], and so on.
ESNs have a fixed reservoir composed of randomly sparsely connected neurons, which makes ESNs have the advantage of certain universality. However, this reservoir is usually not optimal. Usually, a good reservoir needs to meet the following conditions: (1) The reservoir parameters must be taken to ensure the echo state property. (2) Reservoir neurons are dynamically rich and capable of representing classification features or approximating complex dynamic systems. (3) The coupling connection of reservoir neurons is as simple as possible. (4) Overfitting or underfitting phenomena should be avoided. The reservoir is the core factor that determines the performance of an ESN. There have been many attempts to find more efficient reservoir schemes to improve the performance of ESNs, for example, the reservoir structure [13,14,15,16,17], the type of reservoir neurons [18,19], reservoir parameter optimization [20,21,22], obtaining echo state property (ESP) condition [23,24], etc.
In [3], H. Jaeger pointed out that an ESN with a single reservoir can be well trained to generate a sinusoidal function superposition generator, but performance becomes worse when faced with the task of implementing multiple sinusoidal function superposition. The reason may be that the neurons in the same reservoir are coupled, while the task requires the existence of multiple uncoupled neurons [25]. The topology of a single reserve pool limits the application of ESN in time series prediction and other fields. In order to further improve the prediction accuracy, researchers have proposed a series of multireservoir ESN models, including deep reservoir [16,26], growing reservoir [13], and chain reservoir [27], etc.
This paper proposes a novel multireservoir echo state network, called olfactory feelings echo state network (OFESN), to improve the approximation ability and classification ability of ESNs. Each subreservoir of OFESN is composed of a master neuron and several other neurons called sister neurons. The master neuron plays a key role and is the core representative of its own subreservoir. The sister neurons belonging to the same subreservoir can communicate with each other, but the sister neurons belonging to different subreservoir cannot.
The OFESN model can provide a new connection mode, as follows: (i) The connections between subreservoirs are transformed into the connections between their respective master neurons. (ii) The sister neurons within each subreservoir are sparsely connected. (iii) There are no connections between the sister neurons in different subreservoir. Such a new connection mode greatly simplifies the coupling connection between neurons in different reservoirs and then reduces the information redundancy. The sparse connection between the master neurons actually creates a virtual subreservoir, which makes the reservoir add a new subreservoir composed of master neurons with large diversity and thus be equivalent to an increasing the number of neurons. Therefore, the OFESN model may be deemed more appropriate in scenarios where the network’s approximation capability is limited due to a small number of neurons in the overall network reservoir. This is particularly relevant in cases where both the number of neurons in each subreservoir is small and the number of subreservoirs is large. The validity of the OFESN is assessed by utilizing two time series, i.e., sine superposition function and the Mackey–Glass system. The findings from the simulation demonstrate that the OFESN enhances the capacity to approximate several sinusoidal functions in a superposition job. Moreover, it exhibits attributes such as increased prediction accuracy and reduced fluctuations in prediction errors.
The rest of this article is organized as follows. In Section 2, the basic theory of Leaky-ESN is introduced. In Section 3, the OFESN model is proposed, considering the stability of the OFESN and the sufficient conditions for the OFESN to ensure the echo state properties are given, as well as the implementation steps of the OFESN. In Section 4, the OFESN model is simulated and discussed. Finally, the conclusion is given in Section 5.
2. Basic Theories of the Standard Leaky-ESN
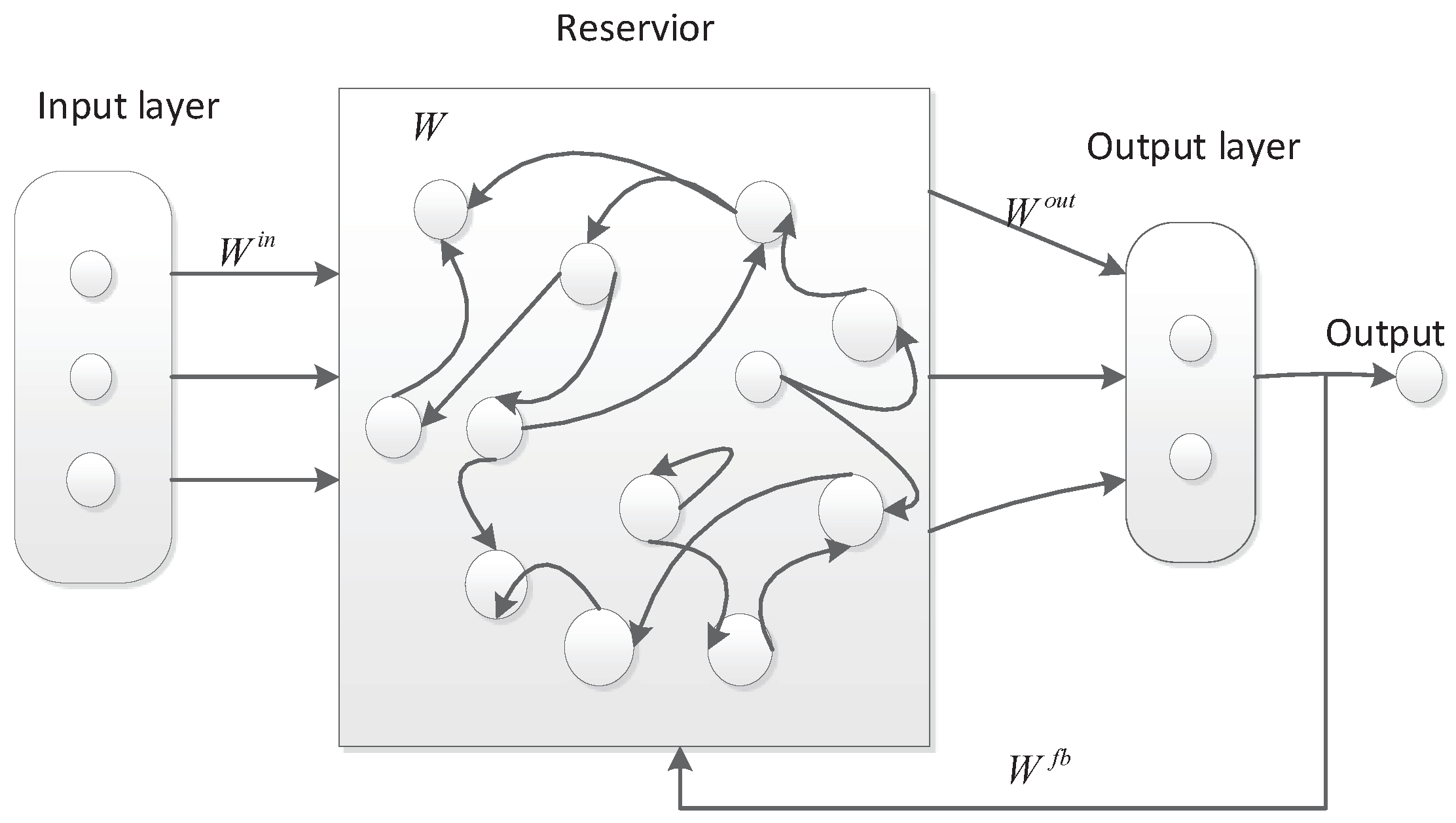
A standard ESN typically consists of an input layer, a reservoir, and an output layer, as shown in Figure 1. The circles in Figure 1 represent neurons.
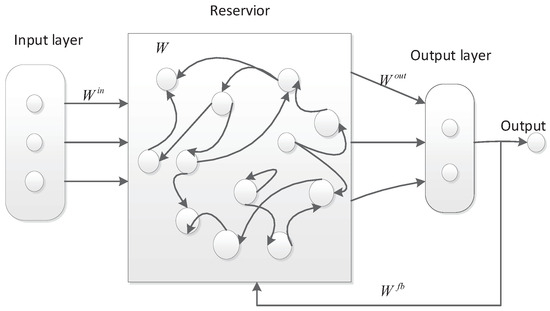
Figure 1.
The structure of a standard ESN.
The quantities of input neurons, reservoir neurons, and output neurons are denoted as K, N, and L, respectively. At time step n, the input vector is denoted as , the state of the reservoir is represented by , and the output vector is given by . The given expression can be rewritten as . The input weight matrix, denoted as with dimensions , represents the weights associated with the input of a system. The reservoir weight matrix, denoted as W with dimensions , represents the weights within the reservoir of the system. The feedback weight matrix, denoted as with dimensions , represents the weights associated with the feedback connections in the system. Lastly, the output weight matrix, denoted as with dimensions , represents the weights associated with the output of the system. Typically, the initial values of , W, and are predetermined and remain constant during the training of an ESN. Conversely, the weight matrix is acquired through the training process of the ESN, representing one of the notable benefits of this approach. The Leaky-ESN is an enhanced variant of the normal ESN, characterized by a reservoir composed of Leaky Integral neurons. The reservoir equation of state proposed by Leaky-ESN is represented as follows [17]:
where represents the time constant of the Leaky-ESN model. The parameter corresponds to the leaking rate of the reservoir nodes, which can be interpreted as the rate at which the reservoir state update equation is discretized in time. The function f refers to a sigmoid function used within the reservoir, commonly either the hyperbolic tangent (tanh) or logistic sigmoid function. The function g represents the output activation function, typically either the identity function or the hyperbolic tangent (tanh) function. The notation denotes the concatenation of two vectors. By employing Euler’s discretization method to the ordinary differential Equation (1) with respect to time, we can accurately derive the discrete equation for the Leaky-ESN model:
In Equation (2), the variable is both unknown and adjustable, and its computation is necessary throughout the training process of the desired network. During the training phase, the echo states are organized into a state collection X in a row-wise manner. Similarly, the learned output values that correspond to the are arranged in a row-wise vector Y. Next, the calculation of is determined using the learning equation in the following manner:
where represents the transpose of matrix X, while represents the inverse of the square matrix .
The objective of training the ESN is to minimize the error function . The error, denoted as , is commonly represented as a normalized root-mean-square error (NRMSE). The formula for NRMSE is given by
where denotes the ith data of the actual output; denotes the ith data of the desired output; means the Euclidean distance of a variable; and denotes the standard deviation of the desired output.
3. Olfactory Feelings Echo State Network
3.1. The Structure of the OFESN
The subreservoirs of the OFESN may be composed of different types of neurons or the same types of neurons. Here, we assume that the reservoir of the OFESN is composed of m subreservoirs, and each subreservoir is composed of the same types of neurons, i.e., the neuron state update model of each subreservoir is the same. The enrichment of the dynamics of the reservoir can be achieved by constructing an echo state network with the following idea:
- (1)
- First, m neurons with different initial states are generated, and the Euclidean distance between any two initial states is greater than or equal to a certain number that can be either specified or generated randomly. If this number is randomly generated, the state of neurons of the subreservoirs subsequently generated will be guaranteed to have more complex differences. The m neurons generated above are referred to as master neurons, similar to the master neurons of typical neural circuits, such as olfactory cortex, cerebellar cortex, and hippocampal structures, that are responsible for the input and output of the circuit. Each master neuron becomes the core of each subreservoir and thus becomes the representative of each subreservoir. Let , , ⋯ denote these m neurons, respectively. Their initial states need to meet the inequality . Here, may be either specified or randomly generated.
- (2)
- Next, with each master neuron as the center, a subreservoir is constructed around the master neuron. In each subreservoir, the other neurons except the master neuron are called sister neurons. The master neuron and the sister neurons of a subreservoir need to ensure high similarity and correlation. Thus, the master neuron can represent its own subreservoir. The communication between subreservoirs can be realized by the communication between master neurons. The sister neurons belonging to the same subreservoir can communicate with each other, but the sister neurons belonging to a different subreservoir cannot communicate with each other. The m master neurons can construct an m subreservoir, called the actual subreservoir. Let the neurons of the subreservoir satisfy . Here, denotes the sister neuron of the subreservoir, and denotes the number of neurons of the subreservoir.
- (3)
- The OFESN model can provide a new connection mode as follows: (i) The connections between subreservoirs are transformed into the connections between their respective master neurons, which can be determined by the small-world network method or sparse connection. The connections between these master neurons actually generate a virtual and flexible subreservoir. The biggest difference between the virtual reservoir and the actual subreservoir is that the virtual reservoirs are only composed of the master neurons, and thus their neuron states have a bigger difference and less redundant information than those of the actual subreservoir. Therefore, the OFESN is equivalent to having a flexible virtual subreservoir and m actual subreservoirs. (ii) The sister neurons within each subreservoir are sparsely connected. (iii) The sister neurons in different subreservoirs cannot communicate with each other, and there are no connections among them. Such a new connection mode greatly simplifies the coupling connection between neurons in different reservoirs and then reduces the information redundancy. The sparse connection between the master neurons actually creates a virtual subreservoir, which makes the reservoir add a new subreservoir composed of master neurons with large diversity and thus is equivalent to increasing the number of neurons. Therefore, the OFESN model can be more suitable for the situation where the network approximation ability is poor due to the small number of neurons in the whole network reservoir, especially the situation where the number of neurons in each subreservoir is small and the number of subreservoirs is large.
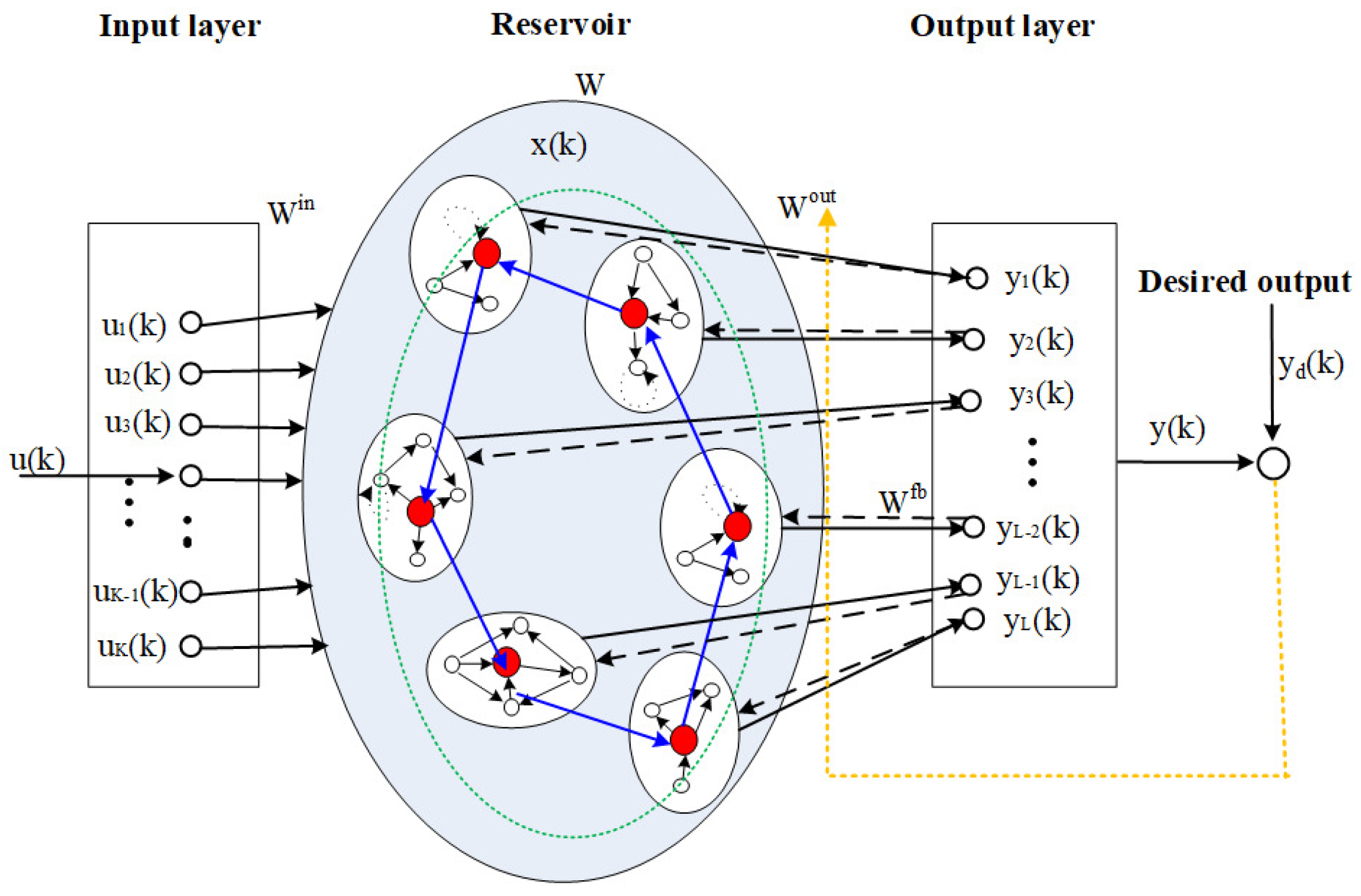
The structure of the OFESN is shown in Figure 2. In Figure 2, the dashed lines from the output layer to the reservoir represent , the solid lines from the reservoir to the output layer represent , and the colored dotted line means that can be adjusted online such that the network output follows , in addition to being calculated by Equation (4). The ellipses of the black line in the reservoir represent actual subreservoirs, respectively. In each subreservoir, a circle filled with red denotes its master neuron. All master neurons construct a virtual subreservoir denoted by the ellipses of the green dotted line. The neurons of each actual subreservoir, including its master neuron and the sister neurons, use the sparse connection. Each subreservoir can be represented by its master neuron, and then the connections between actual subreservoirs can be determined by the connections between master neurons. The master neurons, i.e., the neurons of the virtual subreservoir, may use sparse connection or the small-world network method.
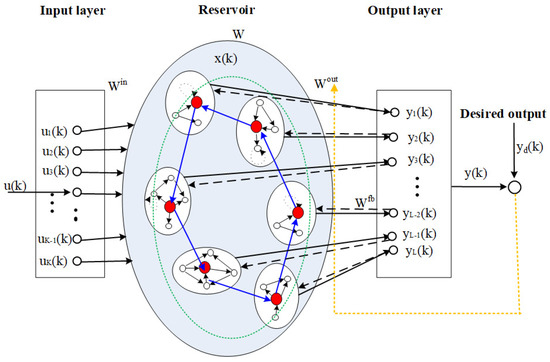
Figure 2.
The structure of the OFESN.
The state update equation of the OFESN is as follows:
where denotes the state vector of the reservoir and denotes the state of the subreservoir. indicates the number of neurons of the ith subreservoir. , W, are the input connection weight matrix, the reservoir neuron connection weight matrix, and the output feedback connection weight matrix, respectively. The reservoir neuron connection weight matrix takes the following form:
where is the connection weight matrix between the ith subreservoir and the jth subreservoir, , , ⋯, denote the internal connection weight matrix of m actual subreservoirs, which can be generated randomly with a certain sparsity. The dimensions of W, , and are , , and , respectively.
The following is an example of how to generate , , ⋯, to explain how to generate . denotes the connection weight matrix between the 1st subreservoir and the 2nd subreservoir. To reduce information redundancy and simplify the connections between neurons, the OFESN uses the connections between the master neuron of the 1st subreservoir and the master neuron of the 2nd subreservoir to represent the connections between the 1st subreservoir and the 2nd subreservoir. We assume that the first neuron of the first subreservoir is the principal neuron and the second neuron of the second subreservoir is the master neuron. Thus, the element in the 1st row and the 2nd column of denotes the connection weights between the master neuron of the 1st subreservoir and the master neuron of the 2nd subreservoir, which can be expressed as . may be a zero or nonzero value. represents that there is no connection between the master neuron of the 1st subreservoir and the master neuron of the 2nd subreservoir. represents that there is a connection between the master neuron of the 1st subreservoir and the master neuron of the 2nd subreservoir. In other words, only of may be a nonzero element, and the rest of the elements are zero. Similarly, the element in the 1st row and 3rd column of , denoted by , represents the connection weights between the master neuron of the 1st subreservoir and the master neuron of the 3rd subreservoir. Only the of may be a nonzero element, and the rest of the elements are zero. So, the element in the 1st row and mth column of is denoted by . Only the of may be a nonzero element, and the rest of the elements are zero. The values of , , ⋯, are determined by the connection weights between the neurons of the virtual subreservoir, and , , ⋯, is actually the corresponding element of the connection weight matrix of the virtual subreservoir.
From the above, the element in the ith row and the jth column of , denoted by , represents the connection weights between the master neuron of the ith subreservoir and the master neuron of the jth subreservoir. Only one element of is possibly nonzero, and the rest of the elements of are zero. The possibly nonzero element characterizes the master neuron of the ith subreservoir possibly connected with the master neuron of the jth subreservoir, and its value is determined by the random sparse connection of the virtual subreservoir. represents the connection of the master neuron itself in the ith subreservoir. So, is made up of . Let , which is the equivalent of added to . can be generated randomly with a spectral radius less than 1 and a certain sparsity. It is especially worth noting that the connection weight matrix of reservoir W is asymmetric; that is, the connection between reservoir neurons is duplex.
In addition, in Equation (7), the input matrix and feedback connection weight matrix are in the following form:
After the matrix is normalized, Equation (6) is rewritten as
where is the input scaling factor, is the spectral radius, and is the output feedback scaling factor.
After normalization, W, , can be, respectively, rewritten as
among them, , , is the normalized matrix.
3.2. The Echo State Property of the OFESN
Theorem 1 ([28]).
For a discrete OFESN model (8), if the following conditions are satisfied:
- (i)
- f selects sigmoid function (tanh);
- (ii)
- The output activation function g is a bounded function (for example, tanh) or ;
- (iii)
- There are no output feedbacks, that is, ;
- (iv)
- (where is the maximal singular value of W);
the OFESN model has the echo state property.
In order to ensure that the OFESN satisfies the echo state property, the reservoir connection weight matrix must satisfy Theorem 1. In fact, each subreservoir does not need to meet the echo state property, as long as the entire reservoir does.
Proof.
For any two states and of the reservoir at time [23], the following holds:
Thus, is a global Lipschitz rate by which any two states approach each other in the state update. To guarantee that the OFESN has the echo state property, the inequality (10) must be satisfied.
hence, the proof is complete. □
3.3. Optimizing the Global Parameters of OFESN
The models to be optimized here are Equations (7) and (8). The parameters to be optimized are a, , , , (spectral radius of matrix), and . can be solved by linear regression method, such as pseudoinverse method. In order to simplify the operation, , , is not optimized and is given in advance. Only the parameters are optimized, and echo state property conditions are satisfied. In this paper, stochastic gradient descent method is used to optimize these parameters. Here, .
When , invoke the chain rule and observe (8); we obtain :
where denotes the element-wise product of two vectors.
When containing , let . Here, we use a simple symbol to represent the input vector whose entries are all zeros; the , and we obtain :
In other words, to train the output weight matrix , the output should be as close as possible to the teacher output during the training process. The error expression is as follows:
we define the squared error as follows:
to , there is
the global parameter update expression is as follows:
K represents the learning rate of the global parameter q. The parameters modified in this process must ensure that the OFESN model has the echo state property in practical applications.
3.4. Implementation of the OFESN
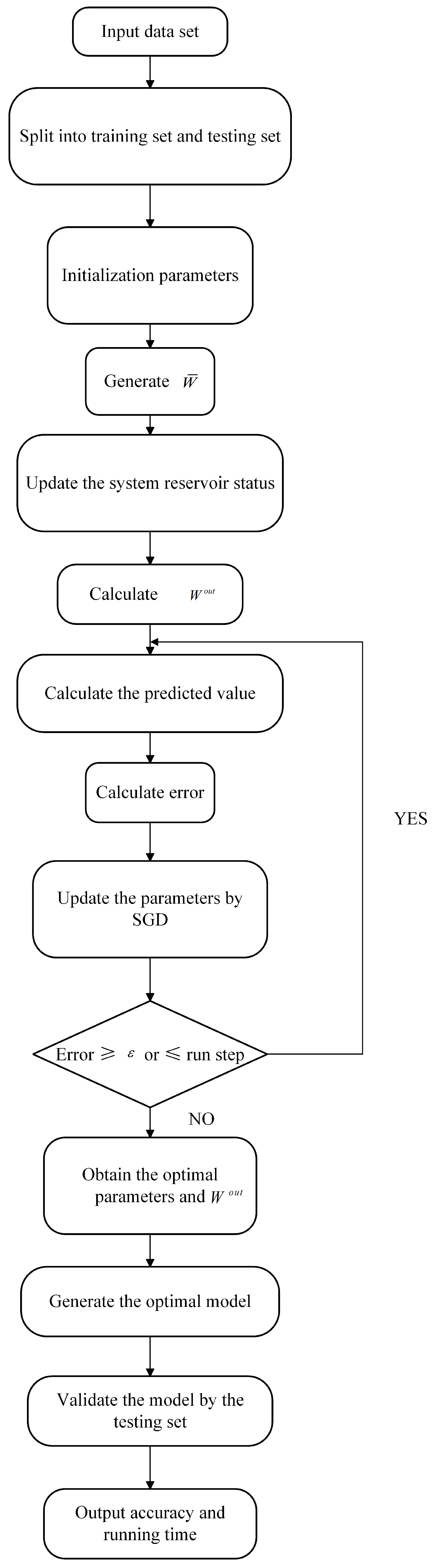
The simulation flow chart is shown in Figure 3, and the steps for OFESN implementation are as follows:
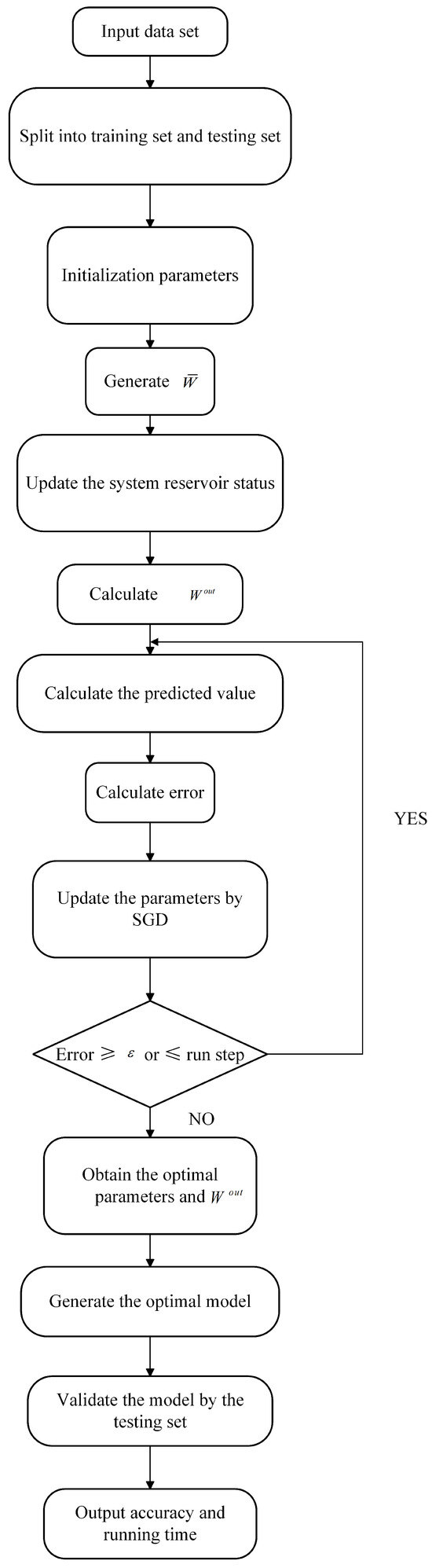
Figure 3.
OFESN test error at different initial value and different connection.
- (i)
- Assume that the reservoir of the OFESN is composed of m classes of neurons, and each class of neurons constitutes a subreservoir, and the number of neurons in the ith reservoir is , then the total number of neurons in the reservoir is .
- (ii)
- Initialize the parameters, including the sparse degree, run step, learning rate, and connection weight matrix and , as well as the parameters to be optimized a, , , .
- (iii)
- The master neurons of m subreservoir constitute a virtual subreservoir, and its corresponding connection weight is that is randomly generated and has a certain sparsity.
- (iv)
- Initialization of m master neurons. Let (m) be given, respectively, and let their initial state satisfy , and can be either specified or randomly generated.
- (v)
- The other sister neurons of m subreservoirs generate initial states. With master neuron as the center, multiple sister neurons with high similarity and high correlation are formed into the ith subreservoir, and the neuron state of the ith subreservoir meets .
- (vi)
- The internal connection weight matrix of the ith actual subreservoir can be randomly generated, has certain sparsity, and may satisfy the spectral radius of less than 1. is composed of , among which can be randomly generated with a spectral radius less than 1 and a certain sparsity. The spectral radius of and may not be less than 1, but the echo state property condition must be satisfied as inequality (10).
- (vii)
- Update the system reservoir states according to (8).
- (viii)
- The optimal parameters and were obtained at the end of the training.
- (ix)
- Test OFESN accuracy and running time.
The implementation pseudocode is shown in Algorithm 1:
| Algorithm 1: OFESN algorithm | |
| Input: Dataset, number of reservoirs m, number of ith reservoir , sparse degree, run step, learning rate K, , | |
| Output: Testing set accuracy and running time | |
| 1 | Split the dataset into a training set and a testing set; |
| 2 | Initialize parameters: , , |
| 3 | ← master neurons:, subreservoir: |
| 4 | while error ≥ or n≤ run step do |
| 5 | Update the system reservoir states according to Equation (8); |
| 6 | Calculate according to Equation (4); |
| 7 | Calculate the predicted value according to Equation (7); |
| 8 | Calculate error; |
| 9 | Update the parameters by SGD; |
| 10 | ; |
| 11 | end |
| 12 | Return , ; |
| 13 | Generate the optimal model; |
| 14 | Validate accuracy by the testing set; |
4. Verification by Experiment Simulation
To verify the effectiveness of the OFESN, sine superposition function and Mackey–Glass were used, and comparisons between the OFESN with Leaky-ESN are given in terms of run time and prediction accuracy.
4.1. Simulation Example 1
In this section, a sine superposition function is given as follow:
The teacher output is
According to Equations (23) and (24), we generate 20,500 data samples, which are divided into three parts: 20,000 training samples (100 initial washout samples) and 500 testing samples. The sample point, or epoch, is set at 500 times, and a total of 20,000 times results in 40 points. In this context, it is necessary to examine two scenarios pertaining to the size of the reservoir. The first group consists of 36 neurons, while the second group consists of 17 neurons. When the size of the reservoir, denoted as N, is equal to 36, the reservoir can be categorized into two categories based on the number of subreservoirs it contains, i.e., the reservoir with either 6 subreservoirs or 3 subreservoirs. In each case, the model performs 20 times in a random manner. The resulting mean and standard deviation of the NRNSE are then gathered. Subsequently, error bar graphs are constructed to visually represent these values.
4.1.1. The Structure of 3 Actual Subreservoirs
The reservoir contains 3 actual subreservoirs, the number of neurons in the ith actual subreservoir is denoted by (i = 1, 2, 3). Here, the number of neurons in the virtual subreservoir is denoted by . Assuming that the actual subreservoirs are and the virtual subreservoir is , different initial values were selected for parameter a, , , and the different sparsity of neuron connections in the subreservoir was tested. In this section, a, , take two different initial values. The first case is , and the second case is . Here, denotes a random number uniformly distributed within the interval . Then, the connections between neurons in each subreservoir can be divided into two cases of fully connections and partially connections. In view of different initial values of the parameters and the different connections between neurons in each subreservoir, simulation tests are carried out in this section. The results are shown in Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9, respectively. The figure is an error bar diagram of NRMSE. Error bars are calculated using mean and standard deviation. The standard deviation is obtained by dividing by M − 1, where M represents the number of samples.
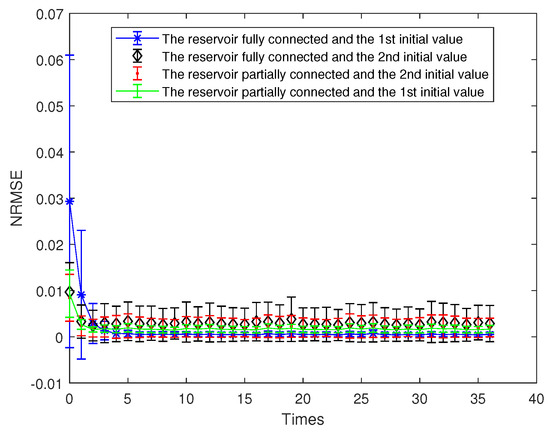
Figure 4.
OFESN test error at different initial value and different connection.
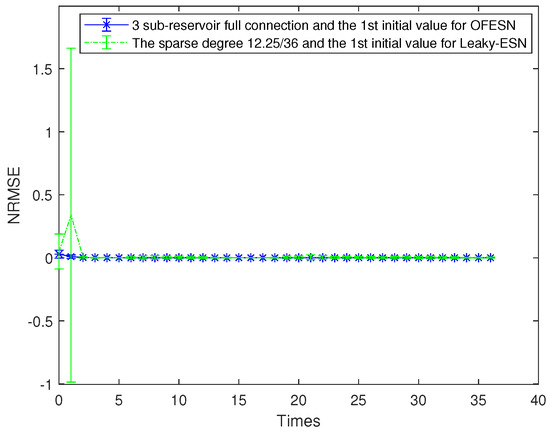
Figure 5.
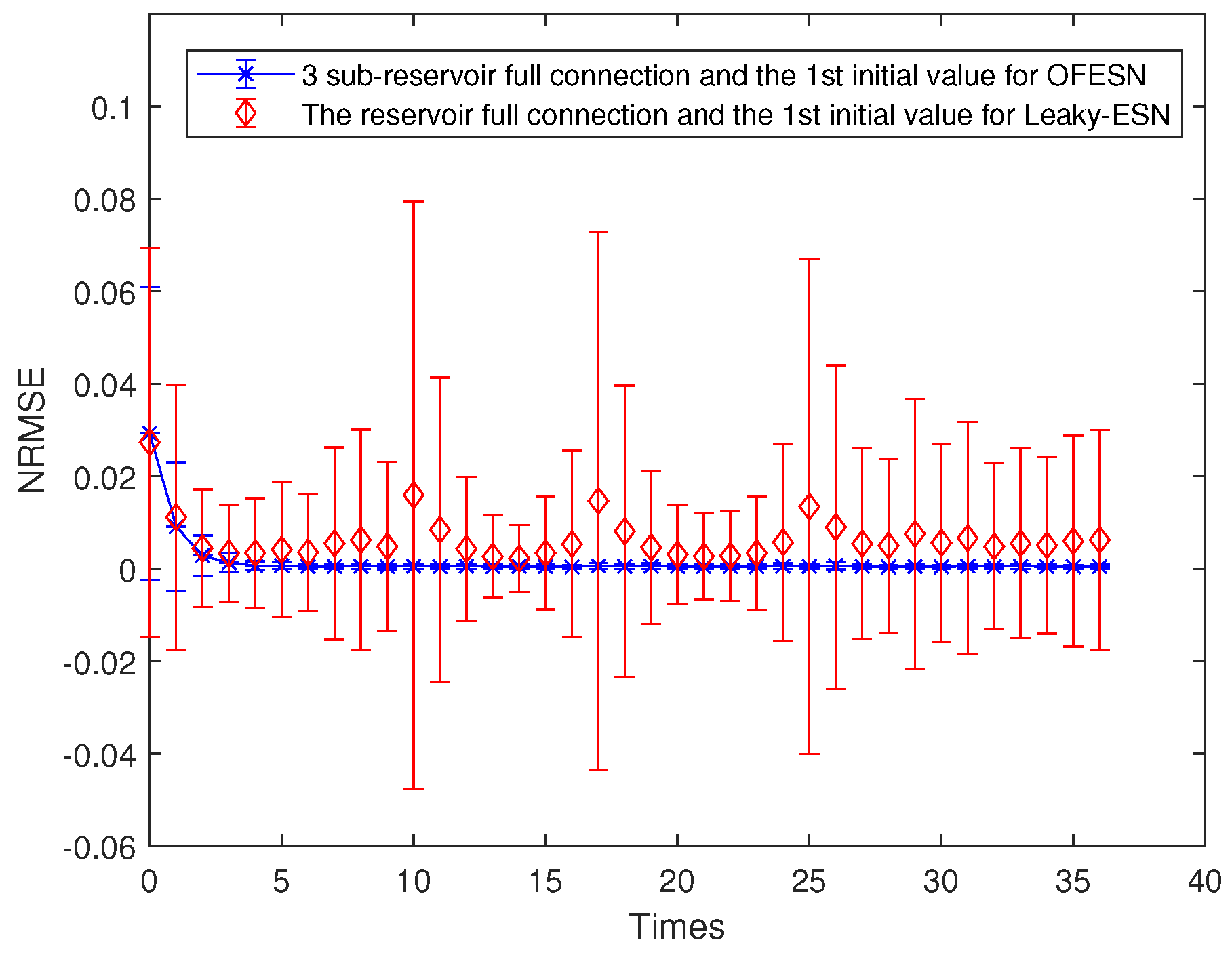
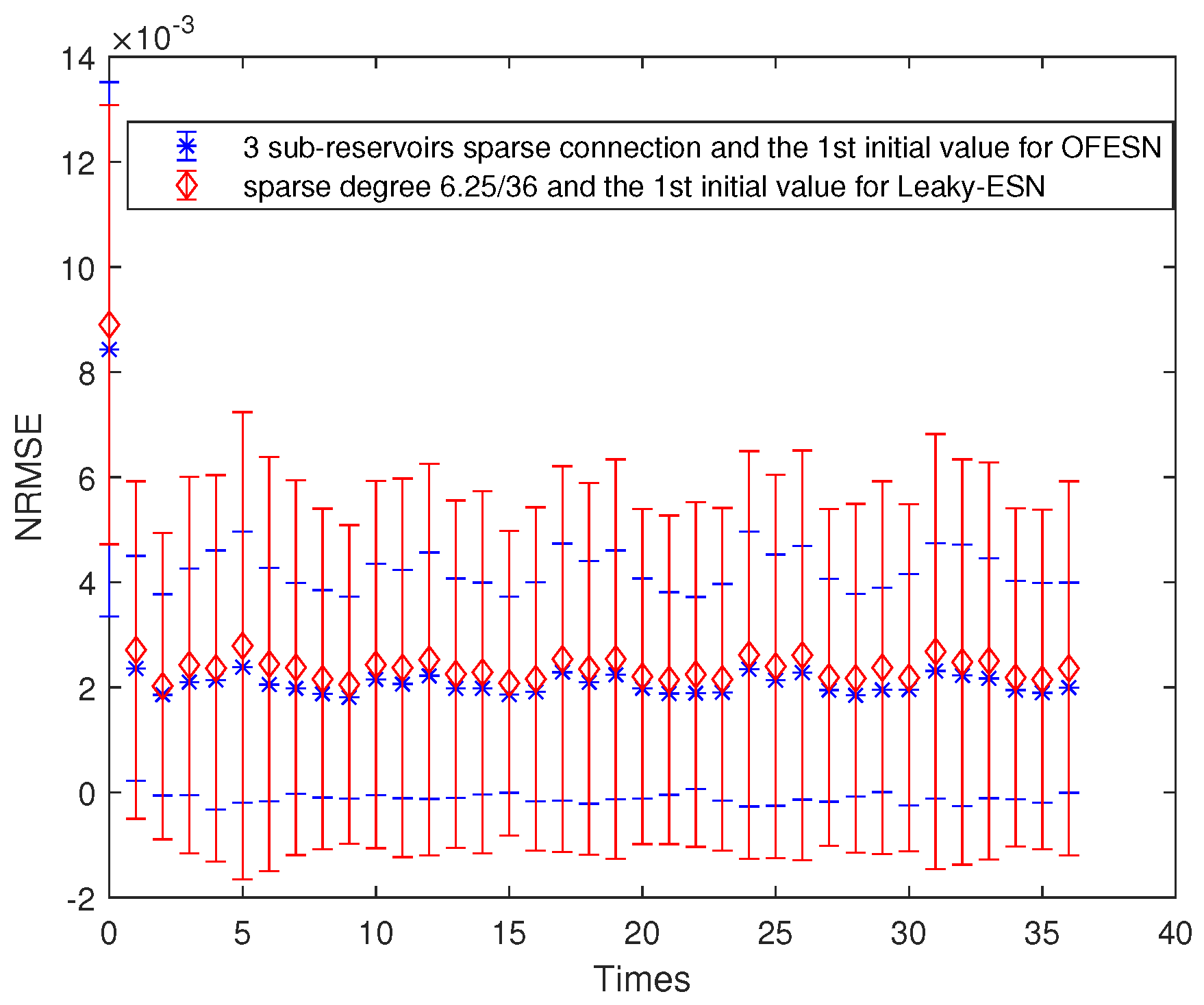
Comparison between the OFESN with full connection and Leaky-ESN with a sparse degree of at the first initial value.
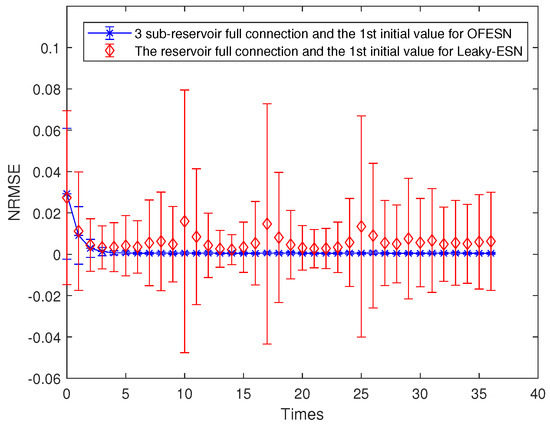
Figure 6.
Comparison between the OFESN with subreservoirs fully connected and Leaky-ESN with full connection at the first initial value.
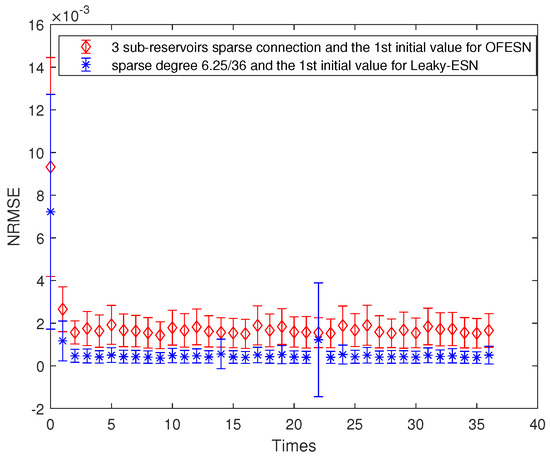
Figure 7.
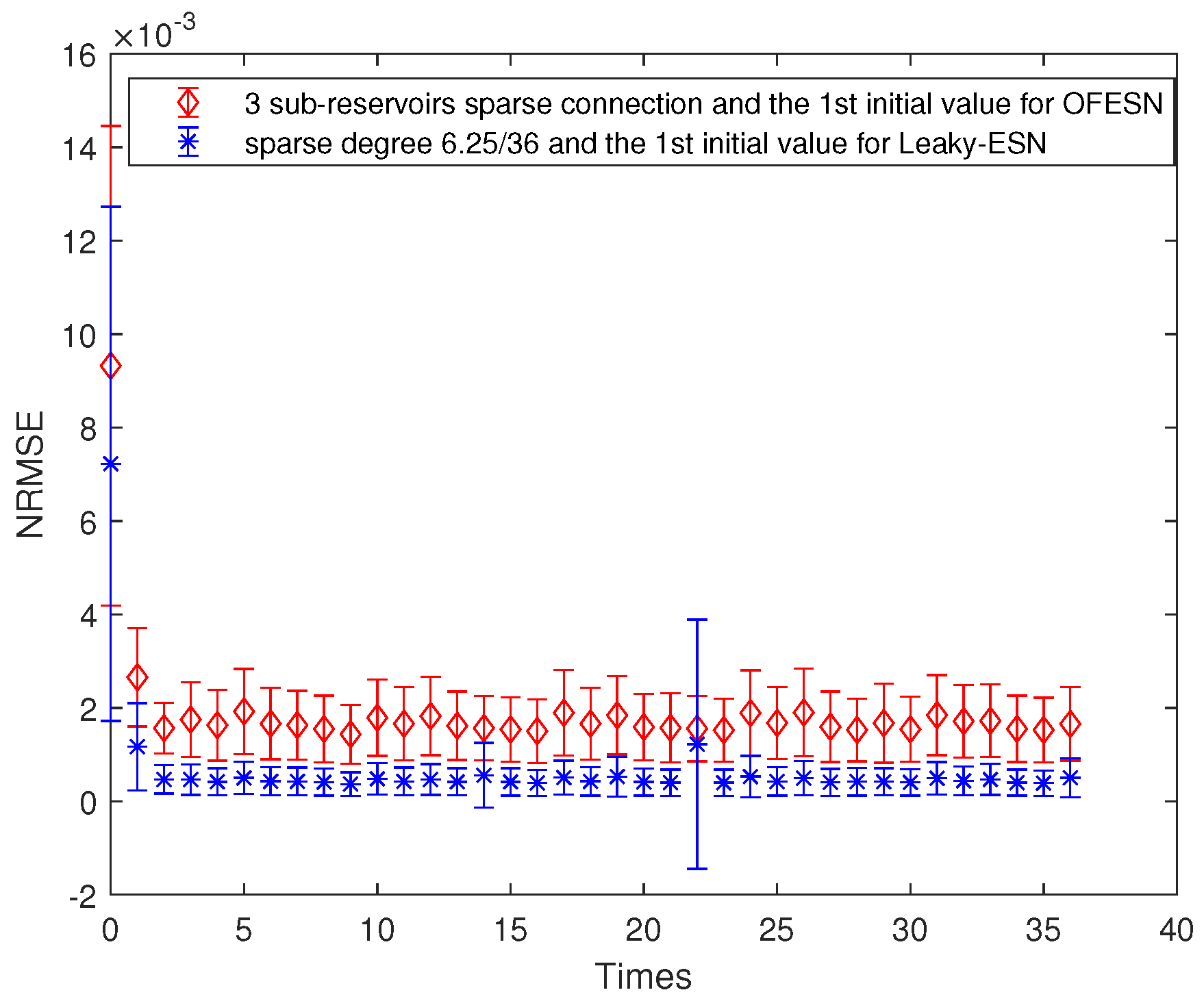
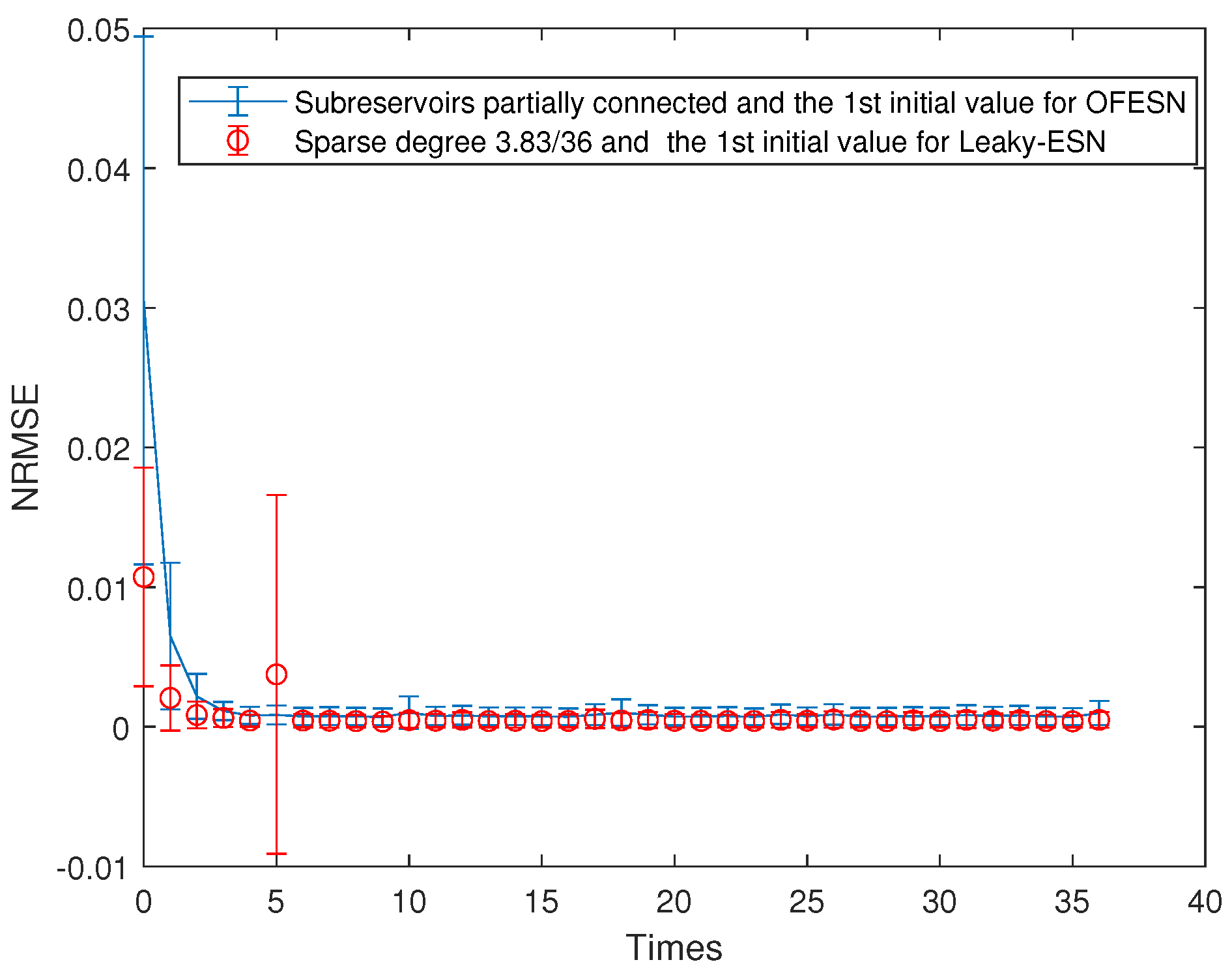
Comparison between the OFESN and Leaky-ESN at the partially connected reservoir and the first initial value.
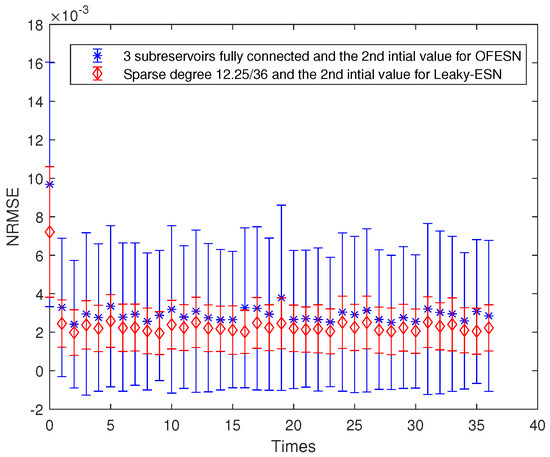
Figure 8.
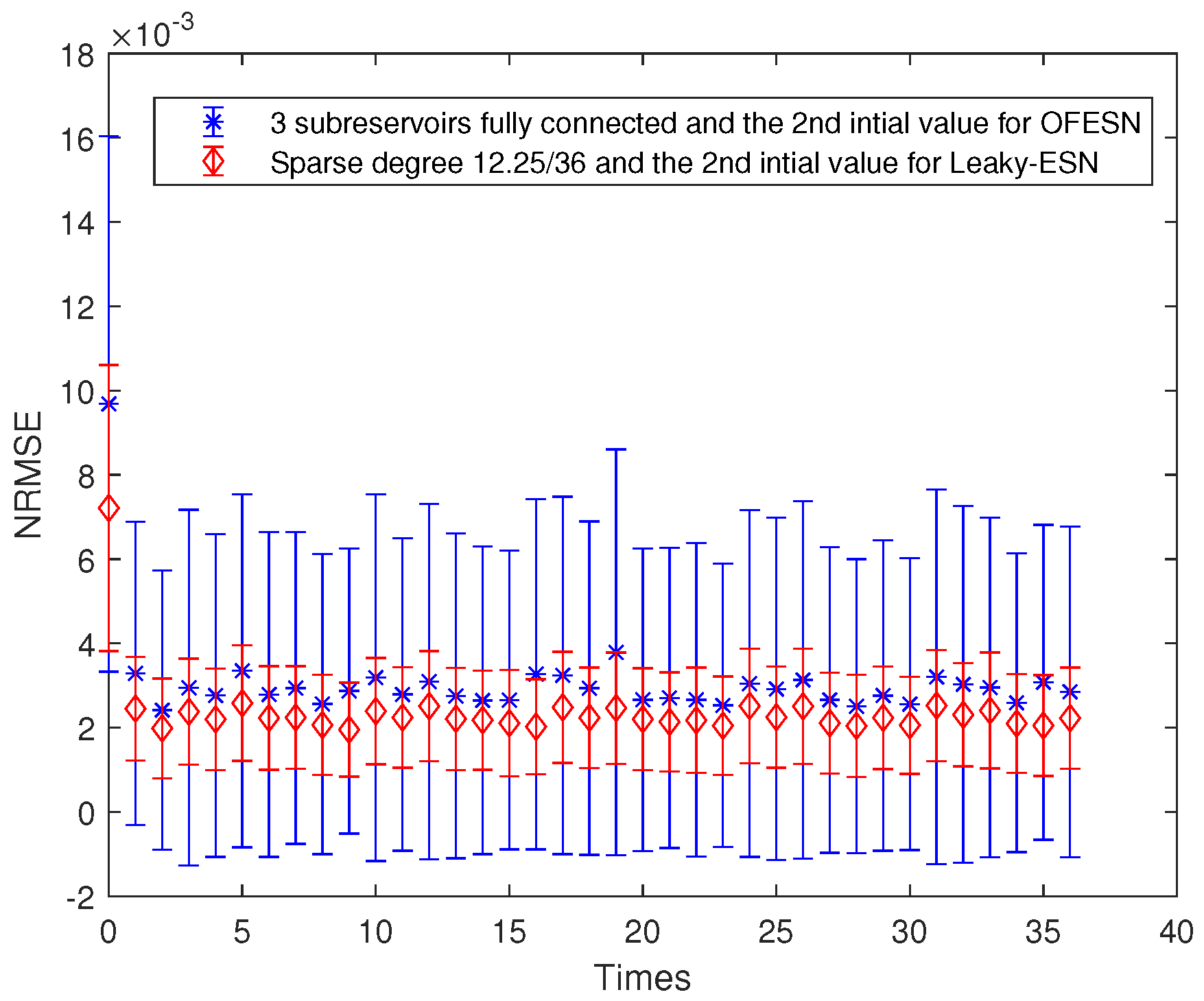
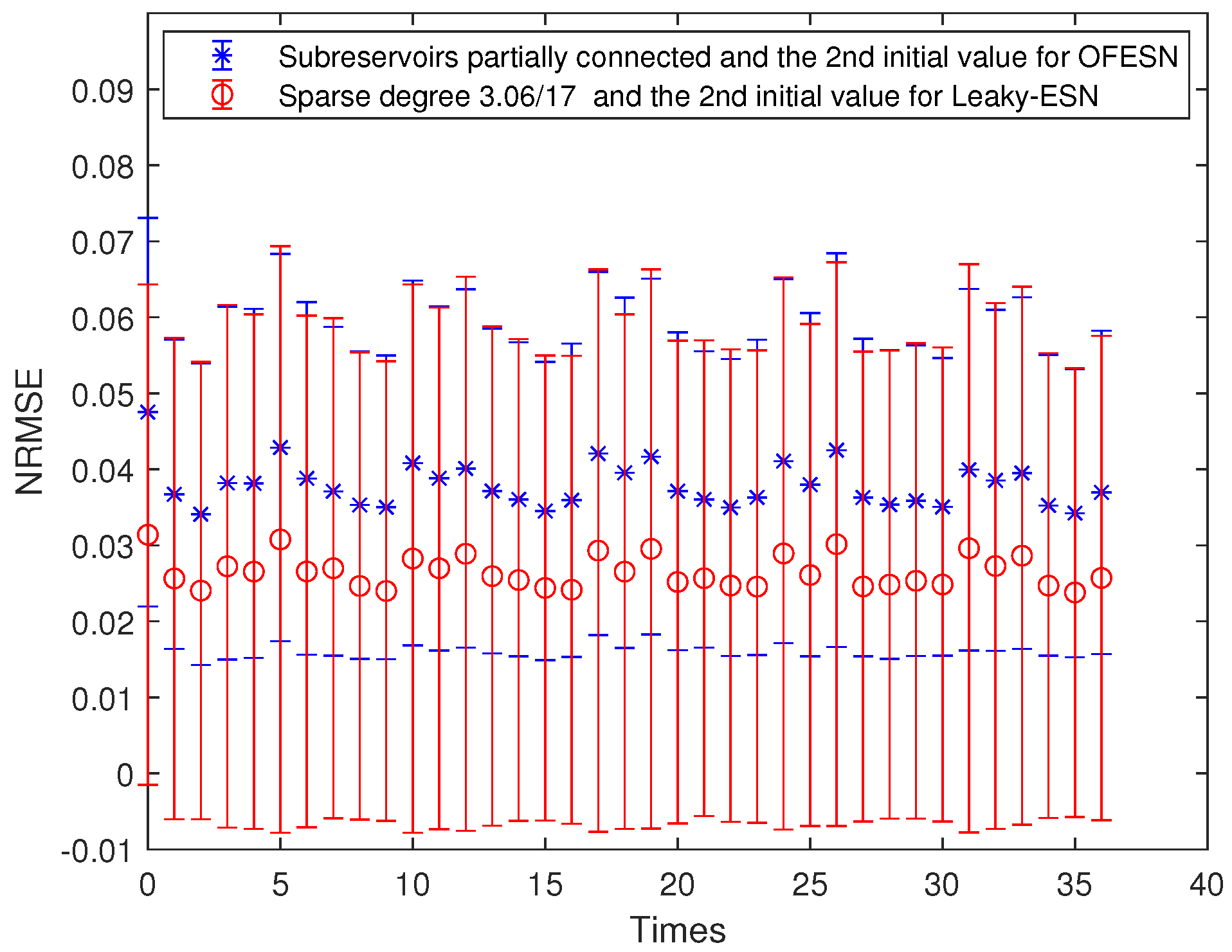
Comparison between the OFESN with fully connected subreservoir and Leaky-ESN with the sparse degree of at the second initial value.
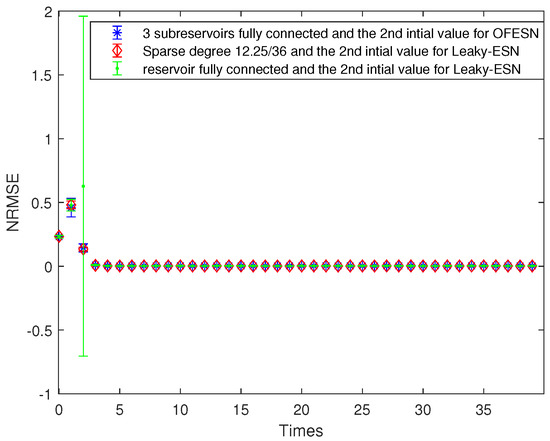
Figure 9.
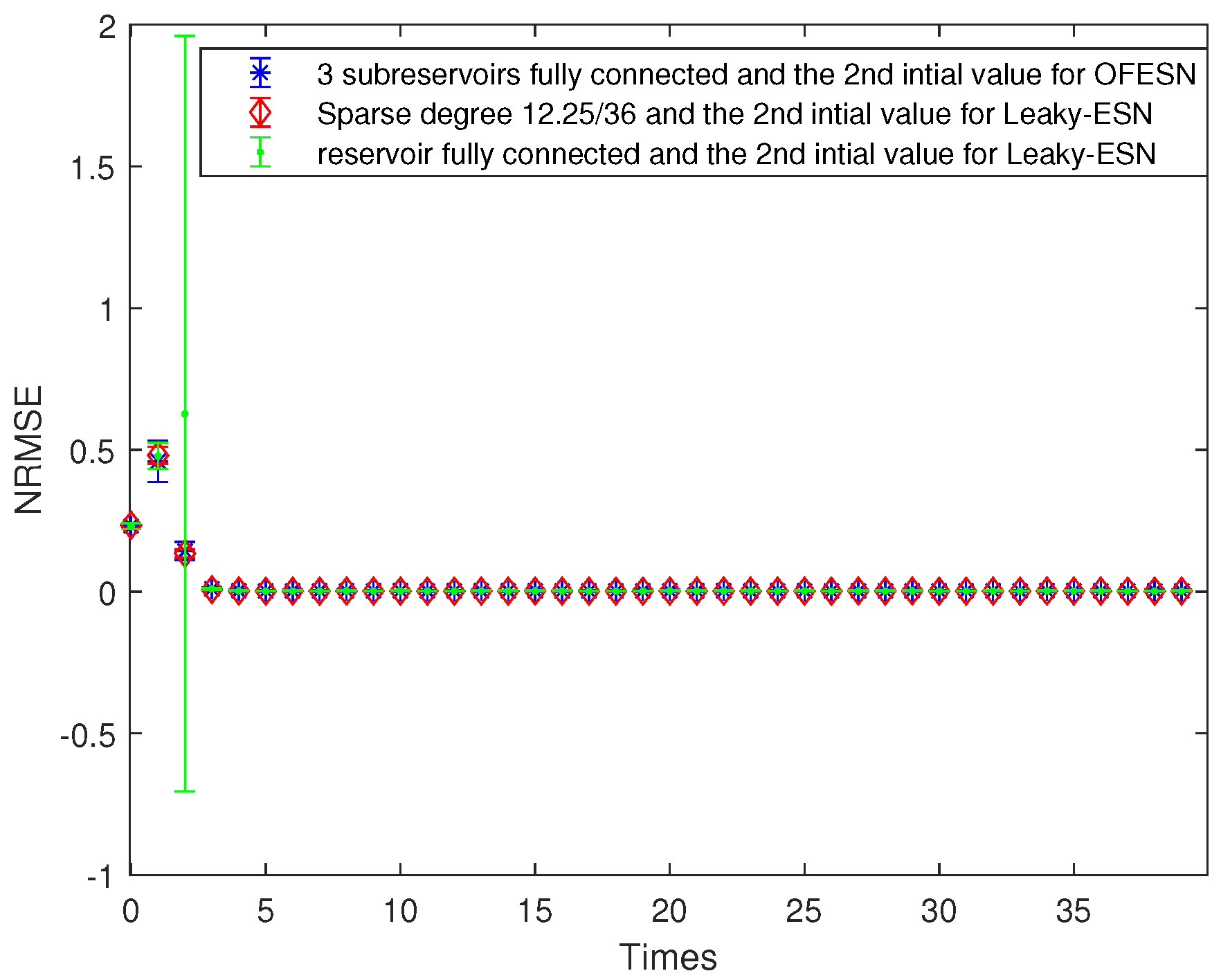
Comparison of Leaky-ESN with fully connected reservoir and the OFESN with all subreservoirs fully connected.
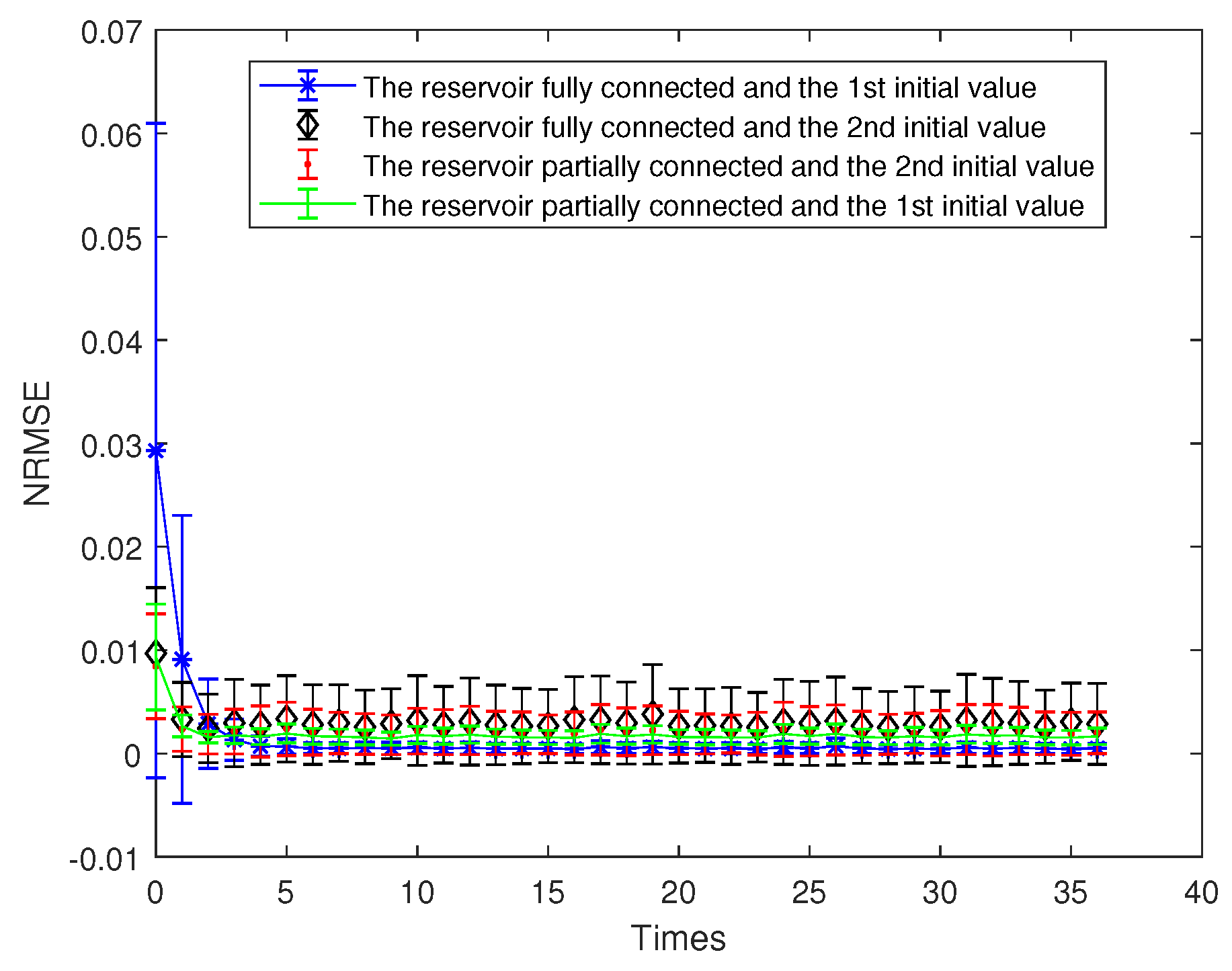
In the initial phase of network model, the prediction error is slightly larger. In order to see the details of subsequent prediction errors, the initial 3 prediction error points are usually not drawn in the figure; so, there are only 37 data points. In addition, usually data from the beginning of the training run are discarded (i.e., not used for learning ) since they are contaminated by initial transients. Figure 4 shows the prediction error diagram of the OFESN proposed in this paper when parameters are different initial values and the subreservoir is fully connected or partially connected.
- (i).
- The first initial value case and the subreservoir fully connected (called Case 1)
. The internal neurons of each subreservoir are fully connected, i.e., the sparse degree of each actual subreservoir is 1, and the sparse degree of the virtual subreservoir is also 1. Thus, the number of the nonzero internal connection weights in the whole reservoir is approximately calculated as follows:
According to Equation (25), . To make Leaky-ESN have the same number of nonzero internal connection weights, its corresponding sparse degree should be calculated as follows:
where represents the sparse degree of the reservoir. According to Equation (26) and , is obtained, and then Leaky-ESN has a sparse degree of . Figure 5 shows the prediction accuracy comparison between the OFESN and Leaky-ESN. In Figure 6, the performance of Leaky-ESN with a fully connected reservoir is given.
As can be seen from Figure 5 and Figure 6, the OFESN has higher error accuracy in the training process, and the error fluctuation range is smaller than Leaky-ESN, which verifies the effectiveness of the OFESN model.
- (ii).
- The firs initial value case and the partially connected subreservoir (called Case 2)
The sparse degree of the 3 subreservoirs of the OFESN is selected as , respectively, and the virtual subreservoir composed of 3 master neurons uses full connection. Then, the number of internal connection weights in the whole reservoir is calculated as follows:
According to Equation (27), . The Leaky-ESN with the same number of internal connection weights should have a sparse degree of reservoir as follows:
Solve Equation (28) and obtain . Thus, the sparse degree of the corresponding leaky-ESN should be set to , which is consistent with the number of neurons interconnections in the reservoir of the OFESN. Here, the neuron interconnections include the self-connection of neurons, the two-way connection between two neurons, and one-way connection between two neurons.
Figure 7 shows the comparison of prediction error bars between the OFESN and Leaky-ESN. It can be seen that in the training process, the OFESN is superior to Leaky-ESN in terms of error accuracy and error stability, which further verifies the effectiveness of the OFESN model.
- (iii).
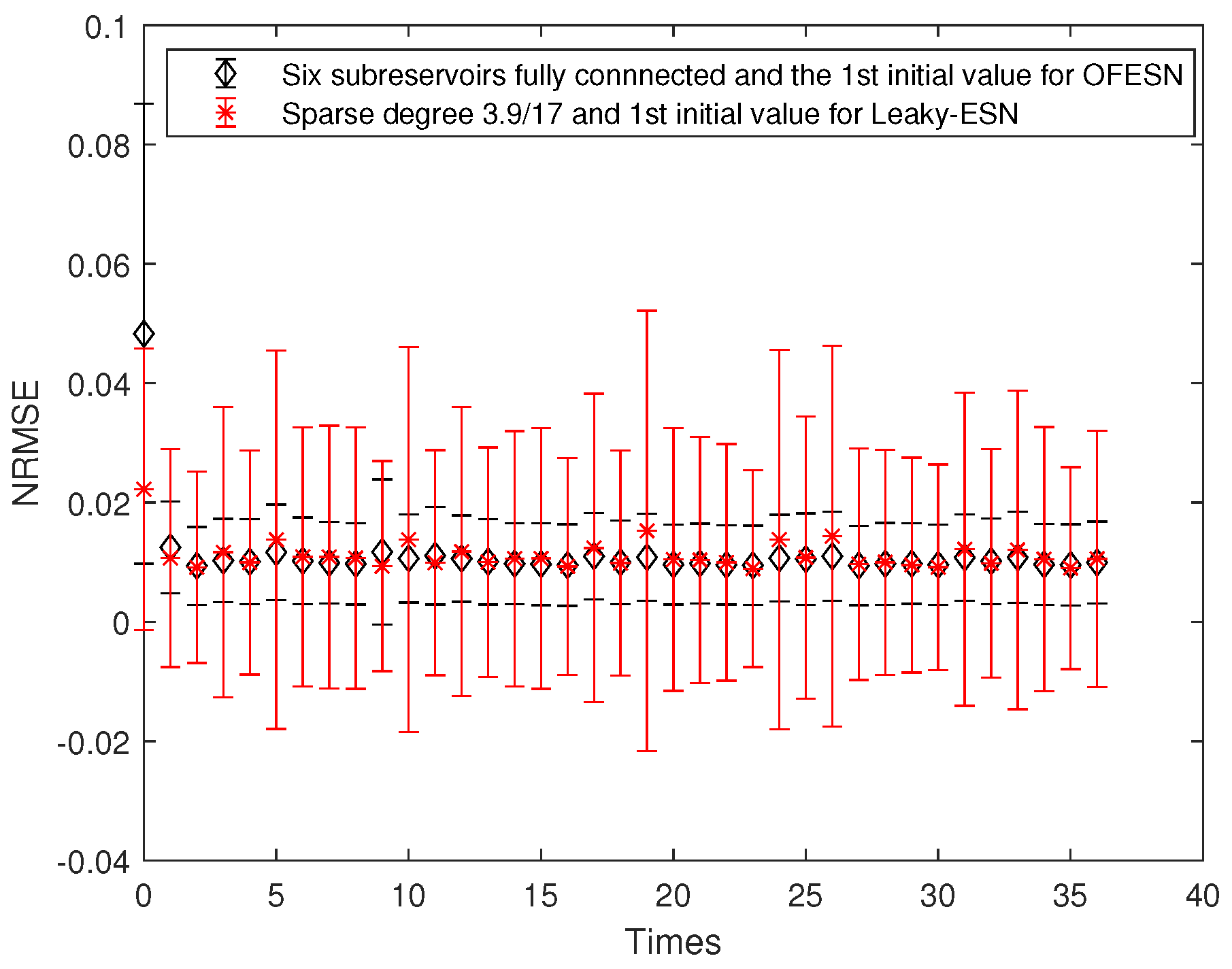
- The second initial value case and the fully connected subreservoir (called Case 3)
The initial value is the second case; that is, , and the sparse degree of the 3 actual subreservoirs is 1, and the sparse degree of the virtual subreservoir is also 1. Similar to Equations (25) and (26), the corresponding sparse degree of Leaky-ESN should be set to , which is the same as the number of neuron interconnections in the OFESN reservoir.
Figure 8 shows the prediction accuracy comparison between the OFESN and Leaky-ESN. Figure 9 shows the performance of Leaky-ESN with fully connected reservoir and the performance of the OFESN with all subreservoirs fully connected. As can be seen from Figure 8 and Figure 9, the prediction performance of the OFESN is better than Leaky-ESN, and the prediction error fluctuation is also much smaller than Leaky-ESN.
- (iv).
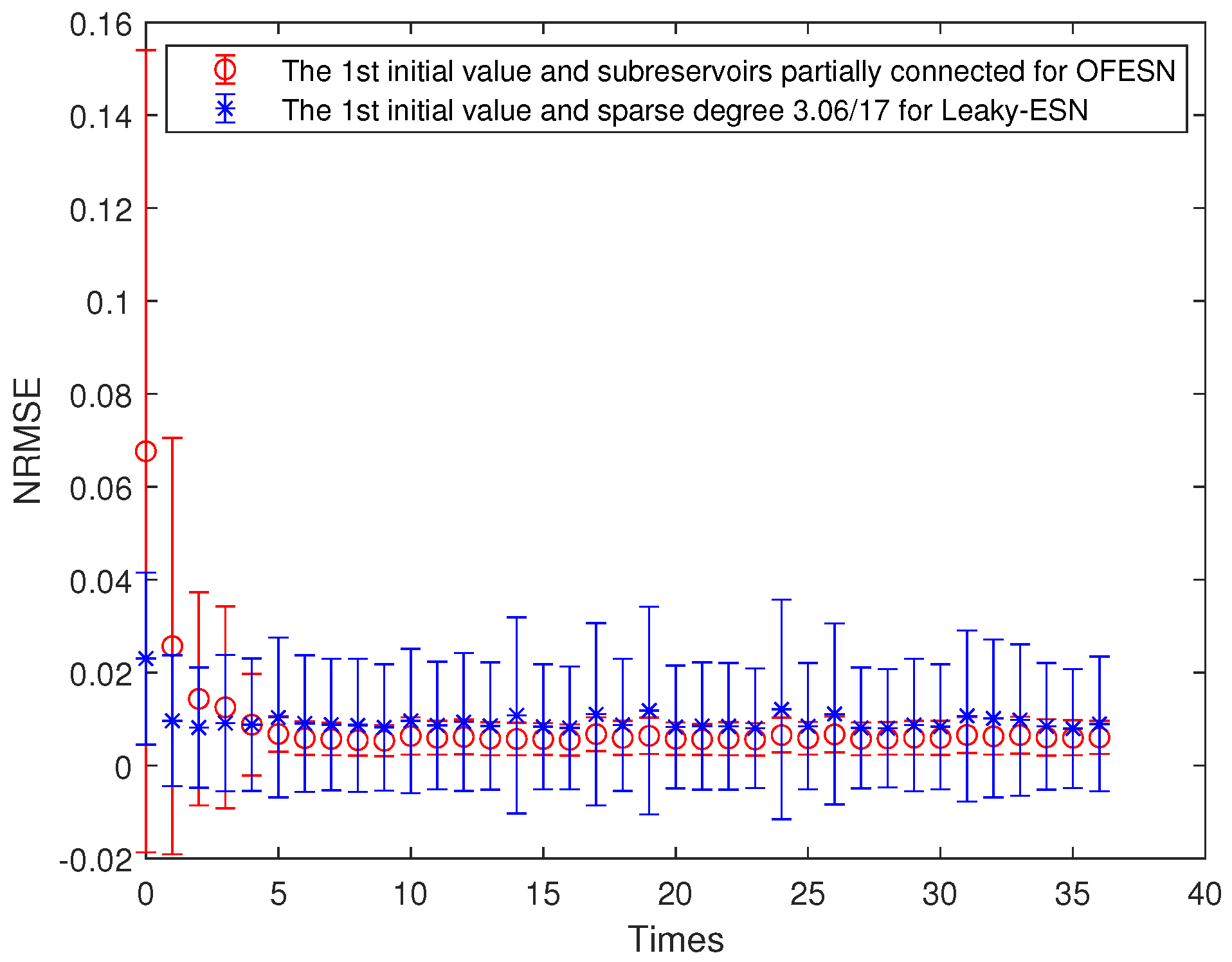
- The second initial value case and the partially connected subreservoir (called Case 4)
The sparse degree of the 3 actual subreservoirs is , respectively. The virtual subreservoir composed of the 3 master neurons is fully connection, and its sparse degree is 1. Similar to Equations (27) and (28), the corresponding sparse degree of Leaky-ESN should be set to . This makes leaky-ESN have the same number of nonzero internal connection weights as the OFESN. The comparison of train accuracy of the two models is shown in Figure 10. It can be seen that in the whole training process, the OFESN partially connected to the reservoir has better prediction performance than Leaky-ESN.
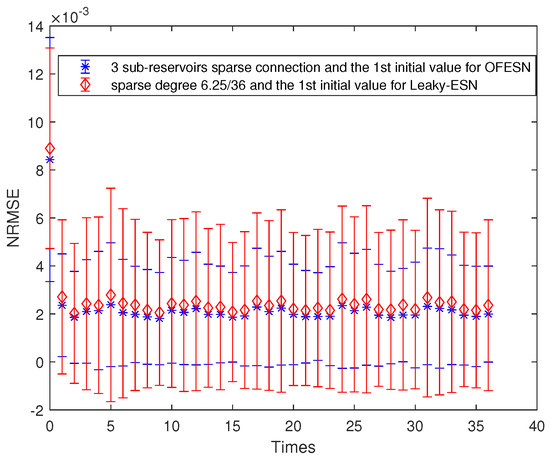
Figure 10.
Comparison between the OFESN and Leaky-ESN at the partially connected reservoir and the second initial value.
4.1.2. The Structure of Six Actual Subreservoirs
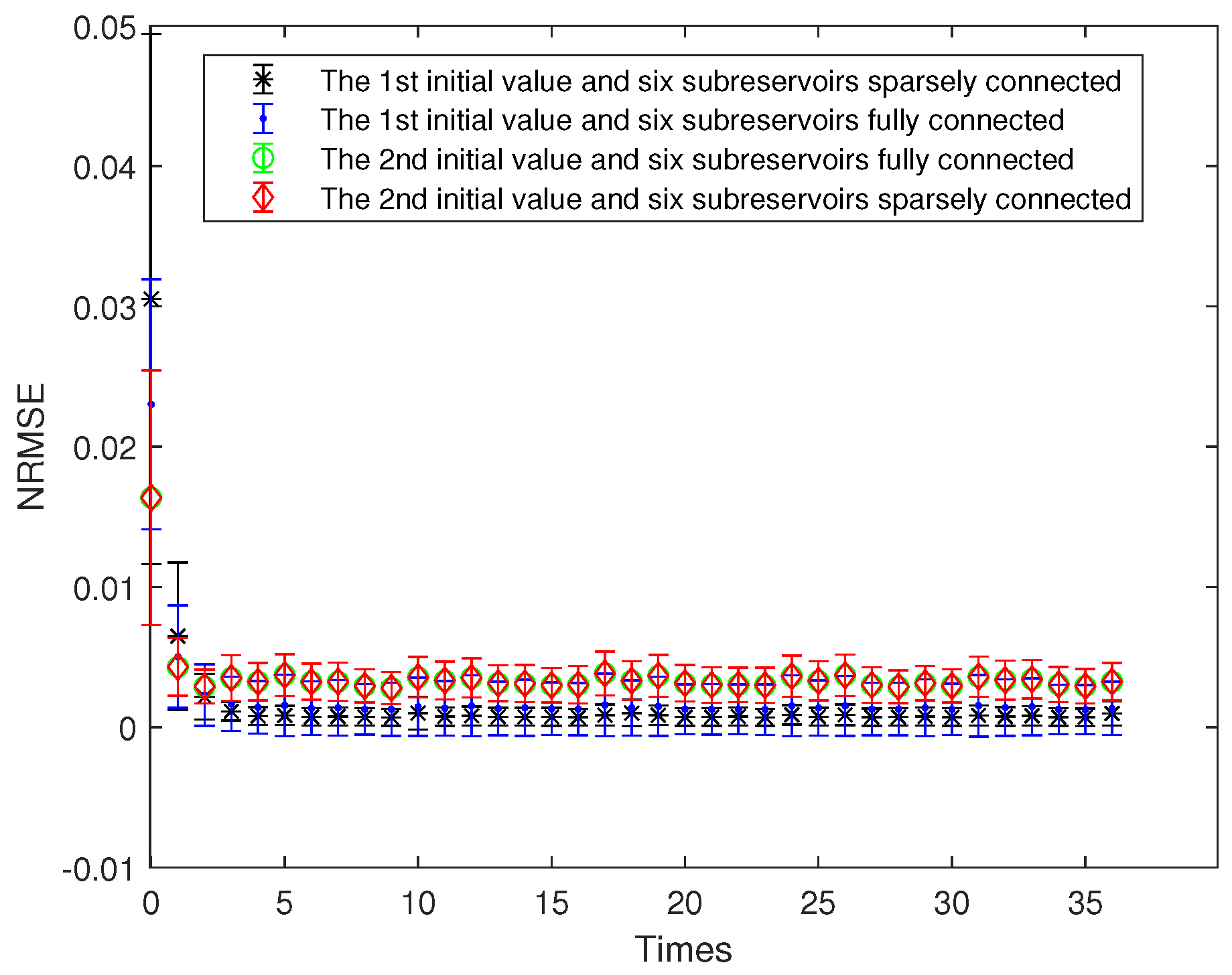
The OFESN reservoir is divided into 6 actual subreservoirs, and the number of neurons in the ith actual subreservoir is denoted by . Thus, the number of neurons in the virtual subreservoir, denoted by , is . The prediction accuracy of the OFESN and Leaky-ESN is compared for the two different initial values of parameters a, , and , respectively, and the two kinds of connections, including partial connection and full connection of the subreservoirs. Figure 11 shows the prediction accuracy of the OFESN under different conditions. It can be seen that under the condition of sparsely connected and fully connected, the OFESN is convergent, and the error is stable between 0 and 0.005.
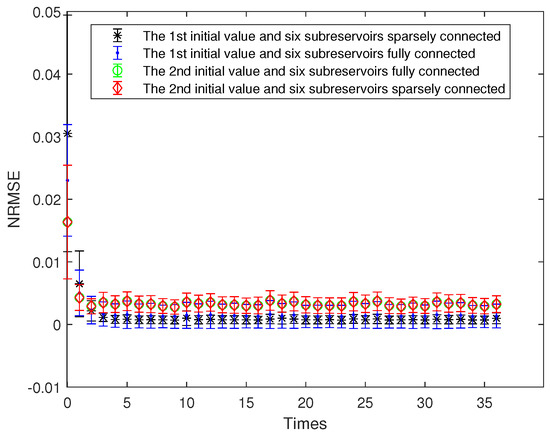
Figure 11.
Prediction error bars of the OFESN under different conditions.
- (i).
- The first initial value case and the fully connected subreservoir (called Case 1)
The sparse degree of each actual subreservoir is 1; that is, all the neurons in each actual subreservoir are connected, including interconnection and self-connection. The sparse degree of the virtual subreservoir is 1, and then the number of connections is 252. Thus, the corresponding sparse degree of Leaky-ESN should be set to . In this case, the number of connected reservoir neurons of the OFESN is approximately the same as that of Leaky-ESN. Figure 12 shows the comparison between the OFESN and Leaky-ESN. Figure 13 shows the comparison between the OFESN with each subreservoir fully connected and Leaky-ESN with fully connected reservoir.
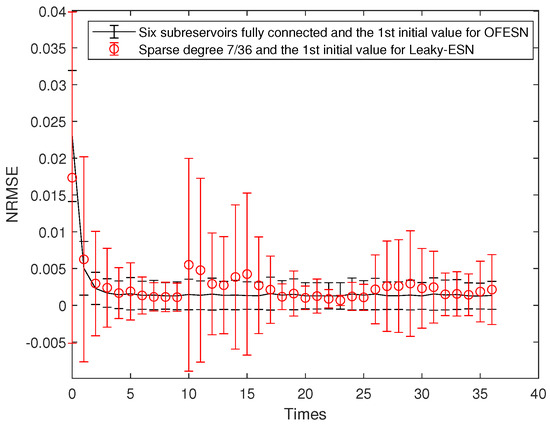
Figure 12.
Comparison between the OFESN and Leaky-ESN under the first initial value and full connection.
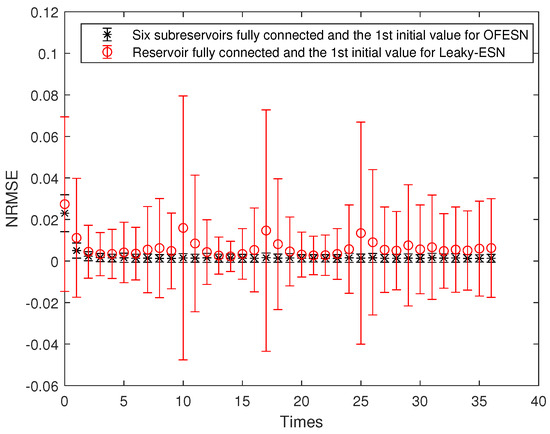
Figure 13.
Comparison between the OFESN with each subreservoir fully connected and Leaky-ESN with fully connected reservoir under the first initial value.
It can be seen that under the same conditions, compared with Leaky-ESN, the OFESN has higher prediction accuracy and smaller error fluctuation.
- (ii).
- The first initial value case and the partially connected subreservoir (called Case 2)
The sparse degrees of the subreservoirs are selected as , , and the sparse degree of the virtual subreservoir is . Thus, the connection number of neurons in the whole reservoir is approximately as follows:
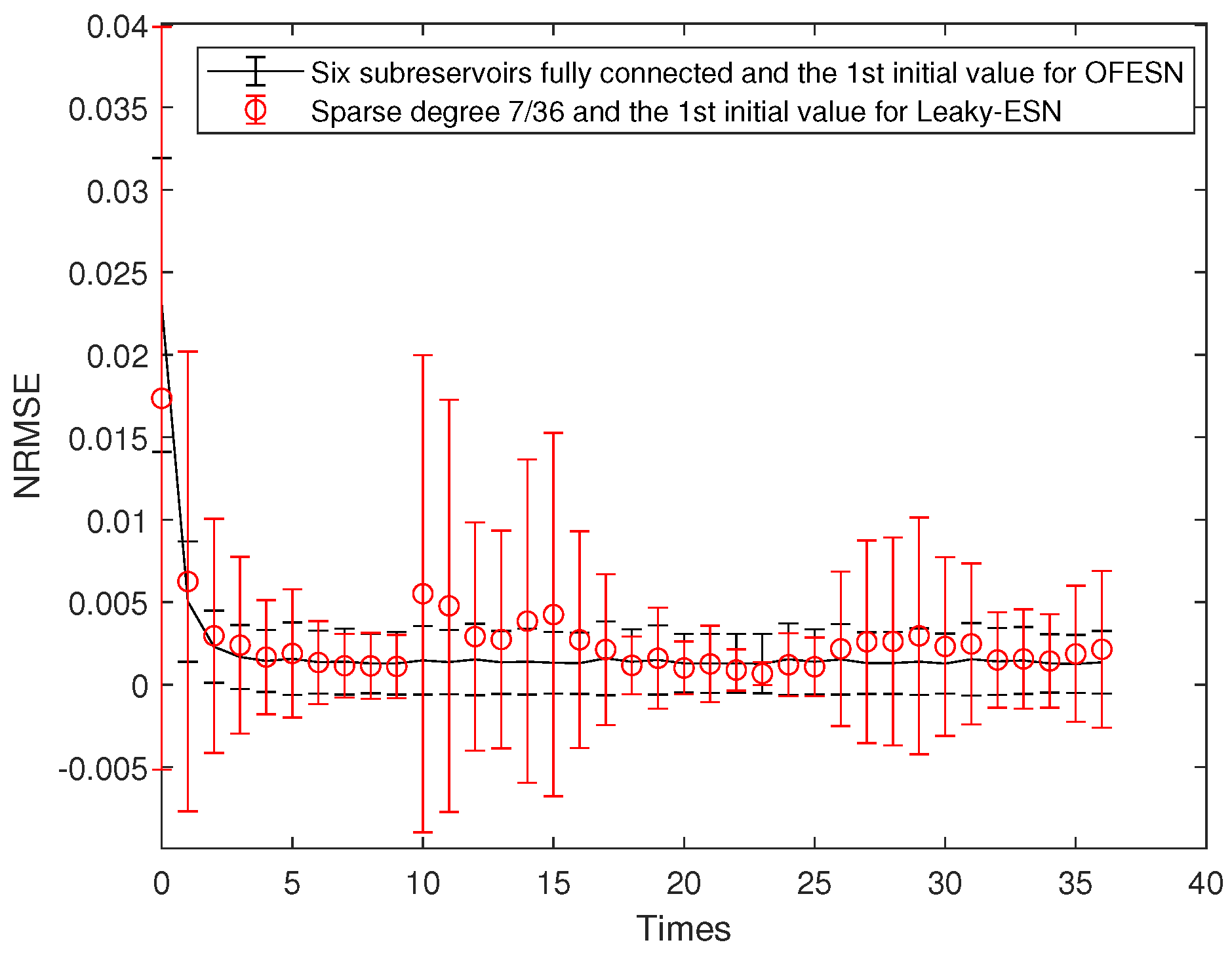
The corresponding approximate sparse degree of Leaky-ESN should be set to . When the initial value is , the comparison between the OFESN and Leaky-ESN is shown in Figure 14. It can be seen that under the condition of different sparsity, the OFESN and Leaky-ESN have a similar prediction effect.
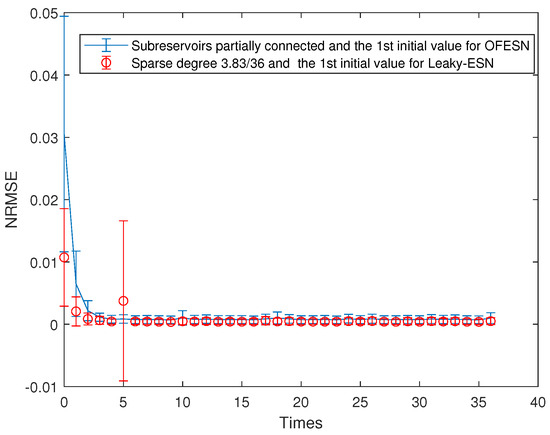
Figure 14.
Comparison between the OFESN and Leaky-ESN under partial connection and the first initial value.
- (iii).
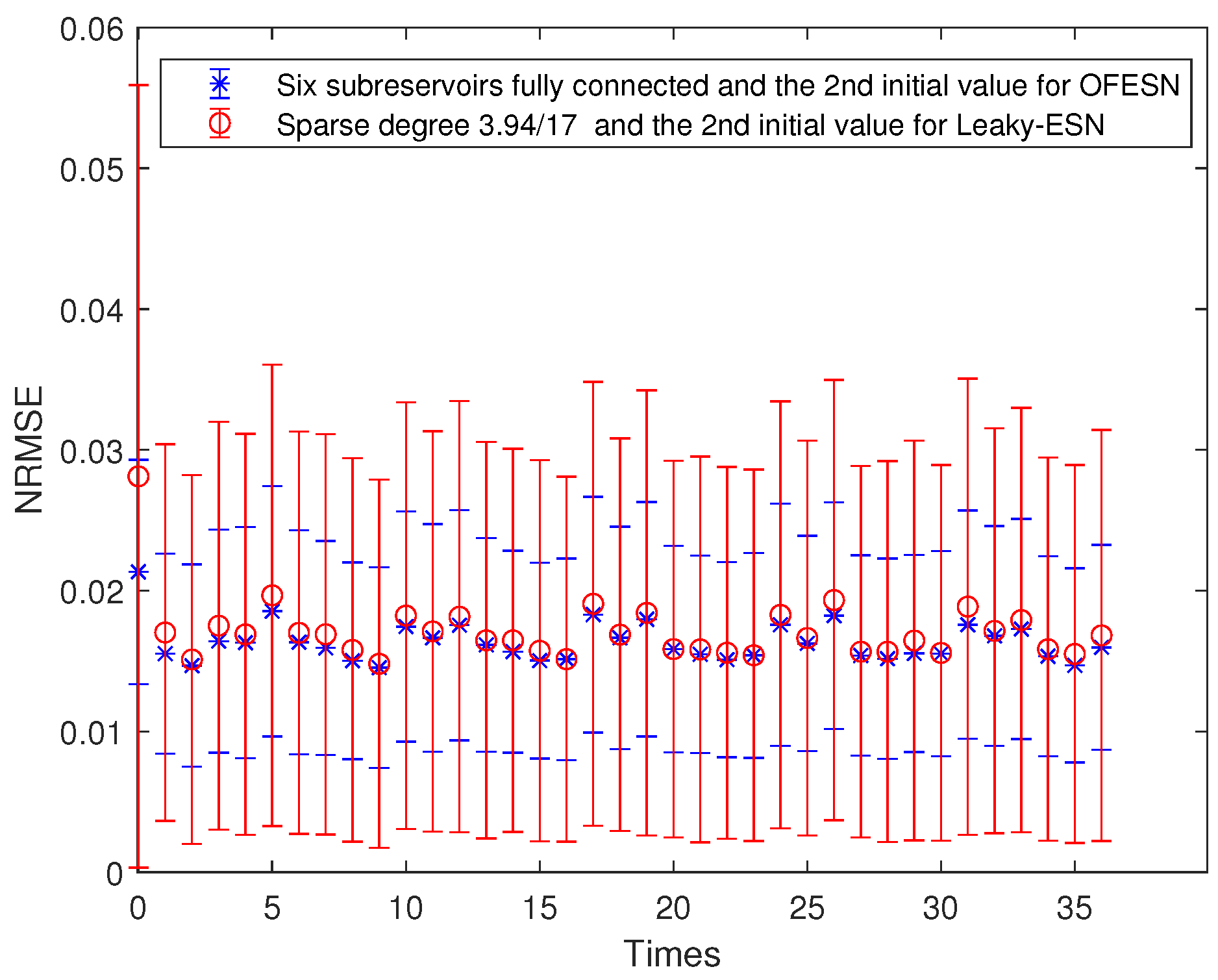
- The second initial value case and the fully connected subreservoir (called Case 3)
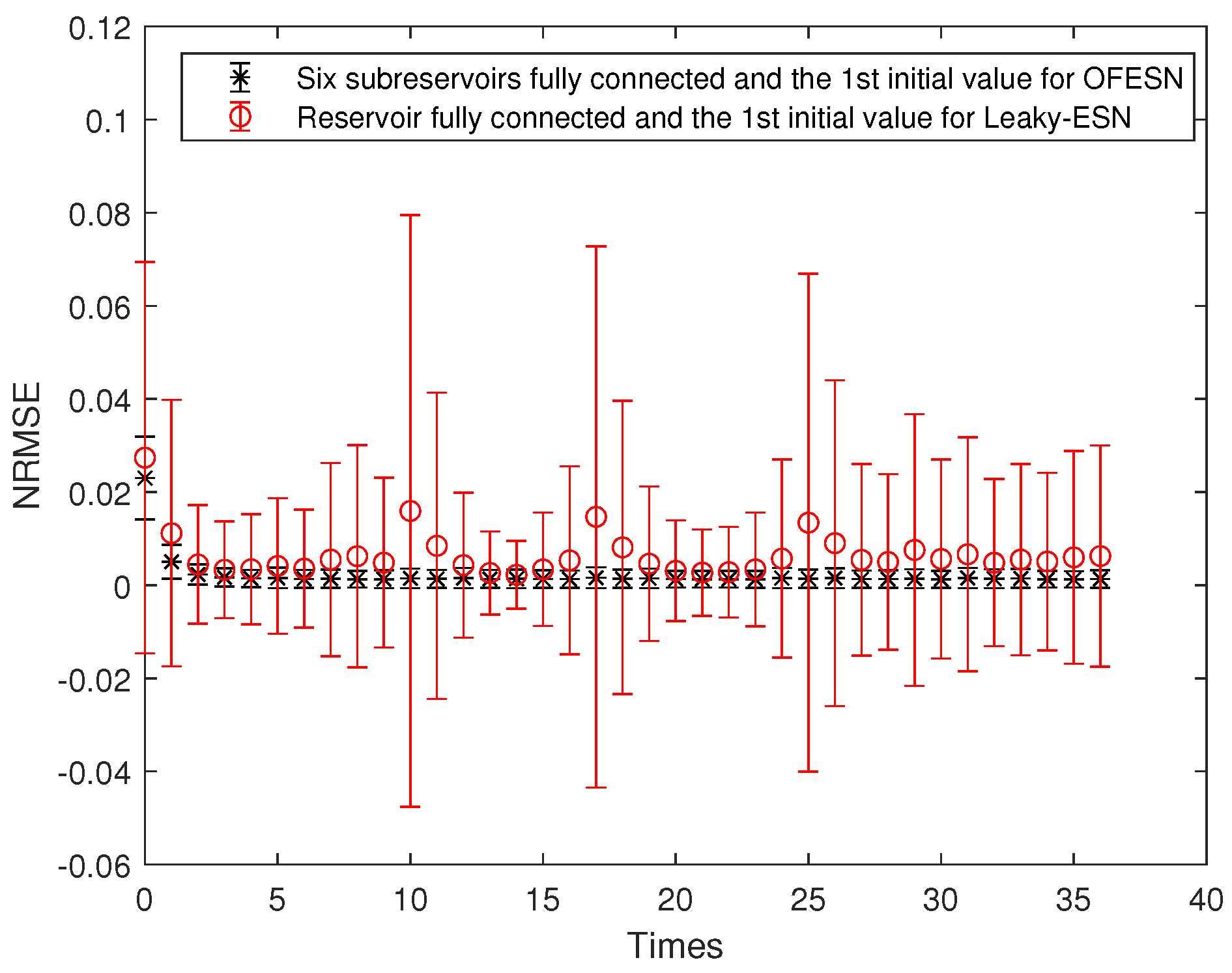
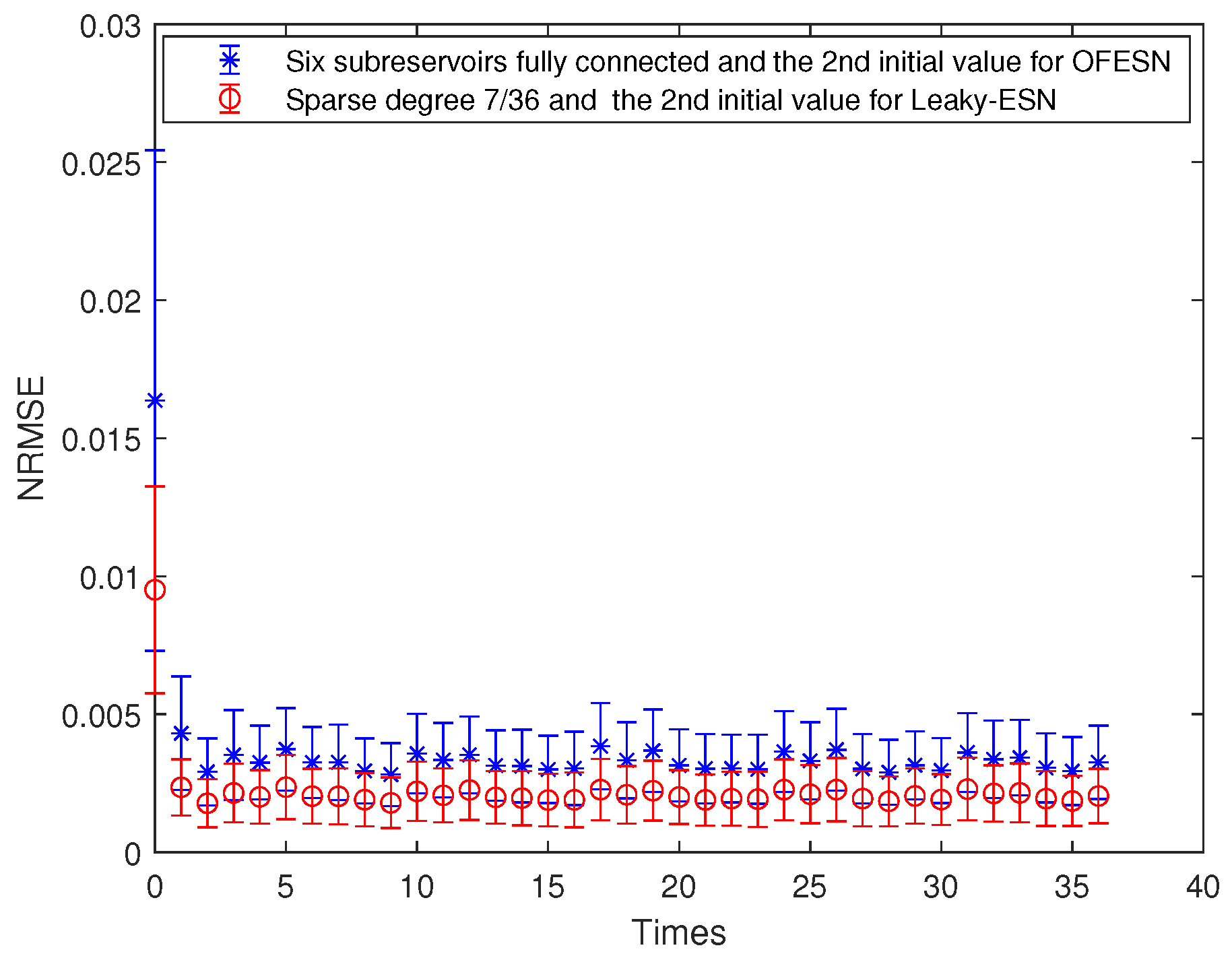
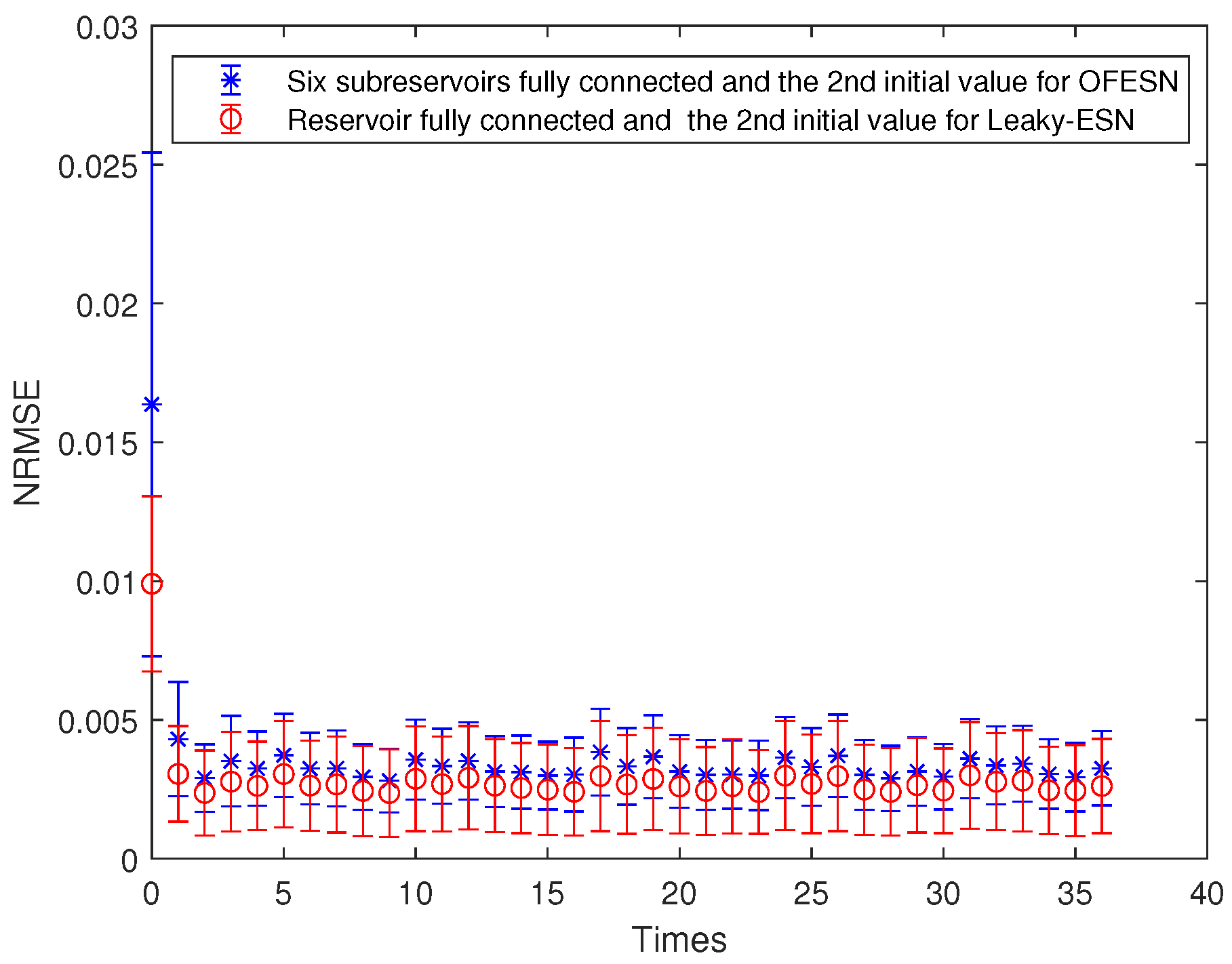
Each subreservoir is fully connected, and the corresponding sparse degree of Leaky-ESN should be set to . Figure 15 shows the comparison between Leaky-ESN and the OFESN with each subreservoir fully connected at the second initial value. Figure 16 shows the comparison between the OFESN with each subreservoir fully connected and Leaky-ESN with fully connected reservoir. It can be seen that under the condition of full connection, Leaky-ESN has higher prediction accuracy and smaller error fluctuation compared with the OFESN.
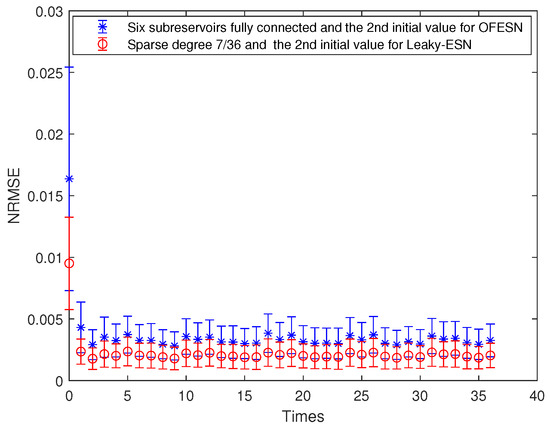
Figure 15.
Comparison between the OFESN with each subreservoir fully connected and Leaky-ESN with sparse degree at the second initial value.
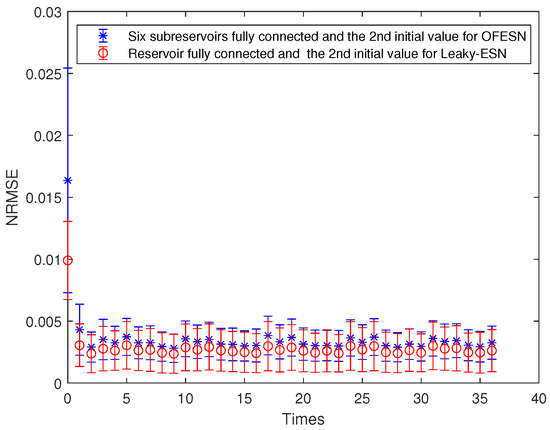
Figure 16.
Comparison between the OFESN with each subreservoir fully connected and Leaky-ESN with the reservoir fully connected at the second initial value.
- (iv).
- The second initial value case and the partially connected subreservoir (called Case 4)
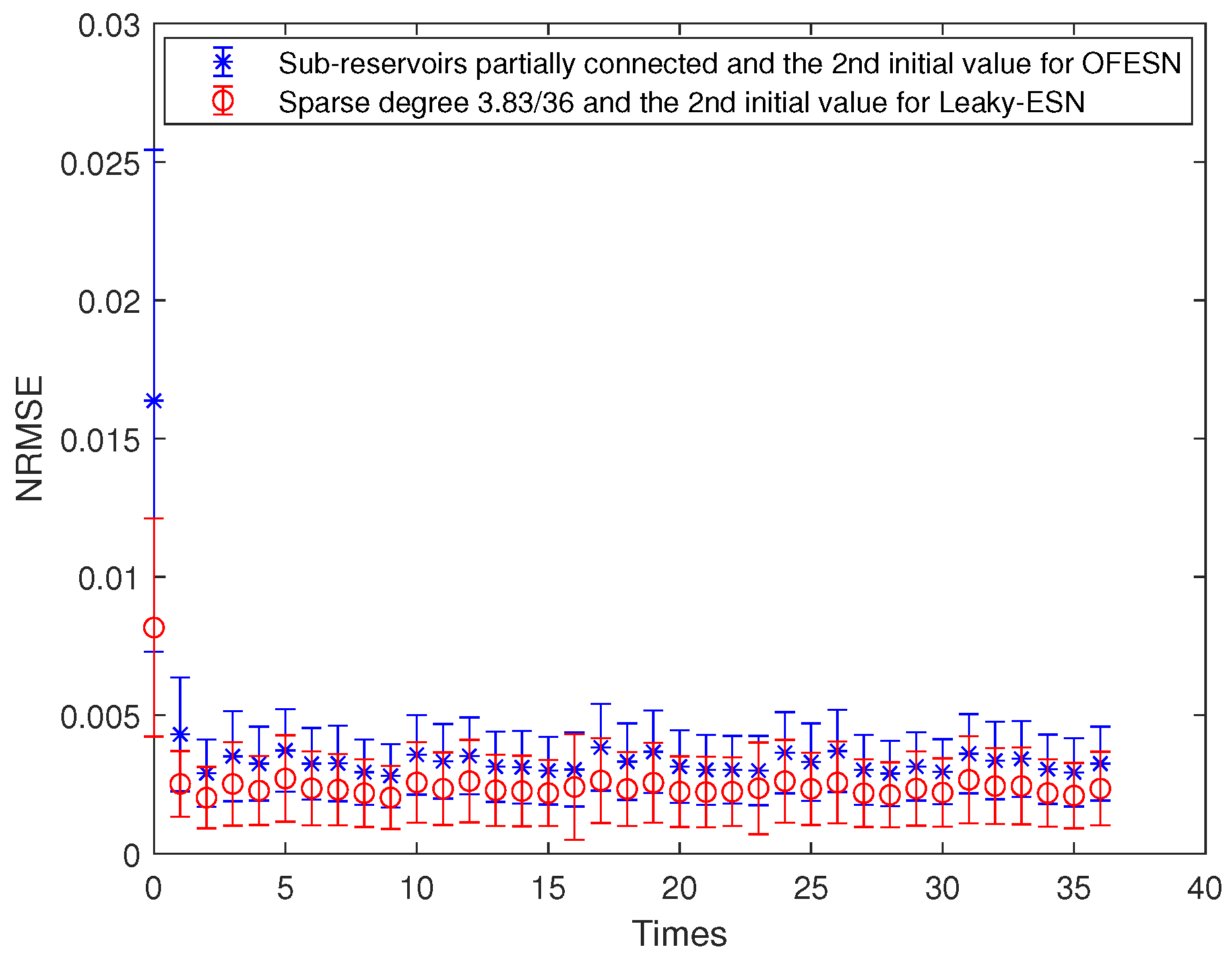
The sparse degree of each actual subreservoir is , and . The sparse degree of the virtual subreservoir is . Thus, the corresponding sparse degree of leaky-ESN should be set to . Figure 17 shows the comparison between the OFESN and Leaky-ESN at the second initial value and partially connected subreservoirs. It can be seen that under partial connection conditions, compared with Leaky-ESN, the OFESN has weaker prediction accuracy and greater error fluctuation.
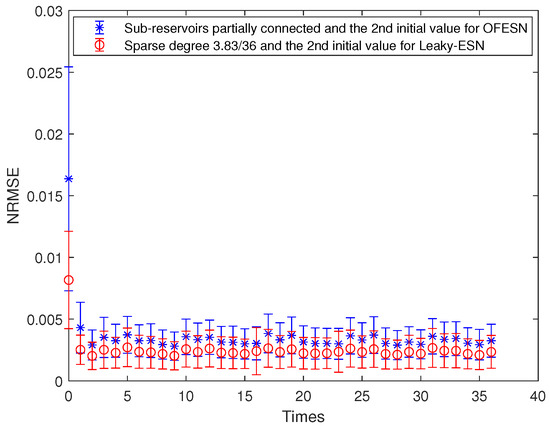
Figure 17.
Comparison between the OFESN and Leaky-ESN under partial connection and the second initial value.
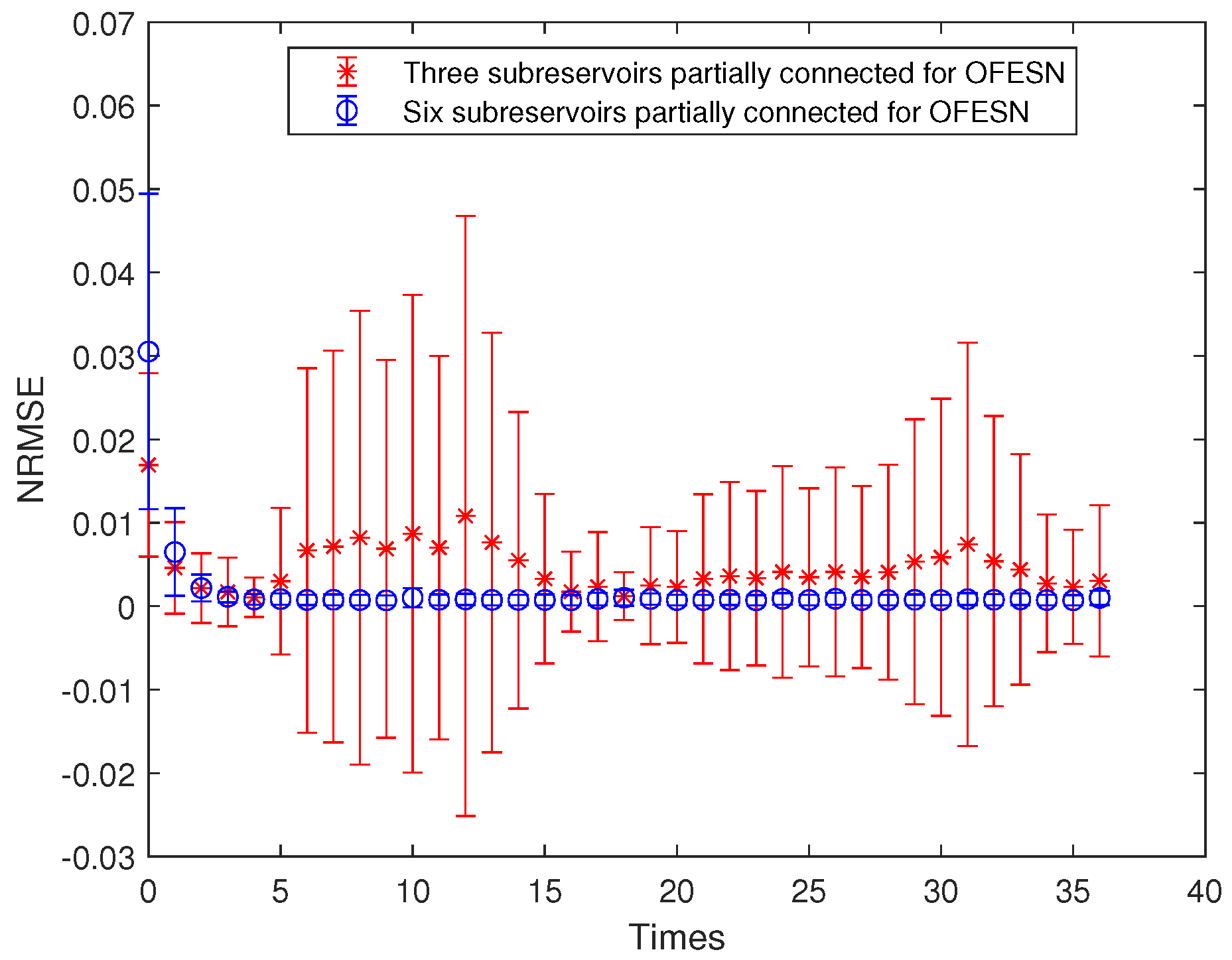
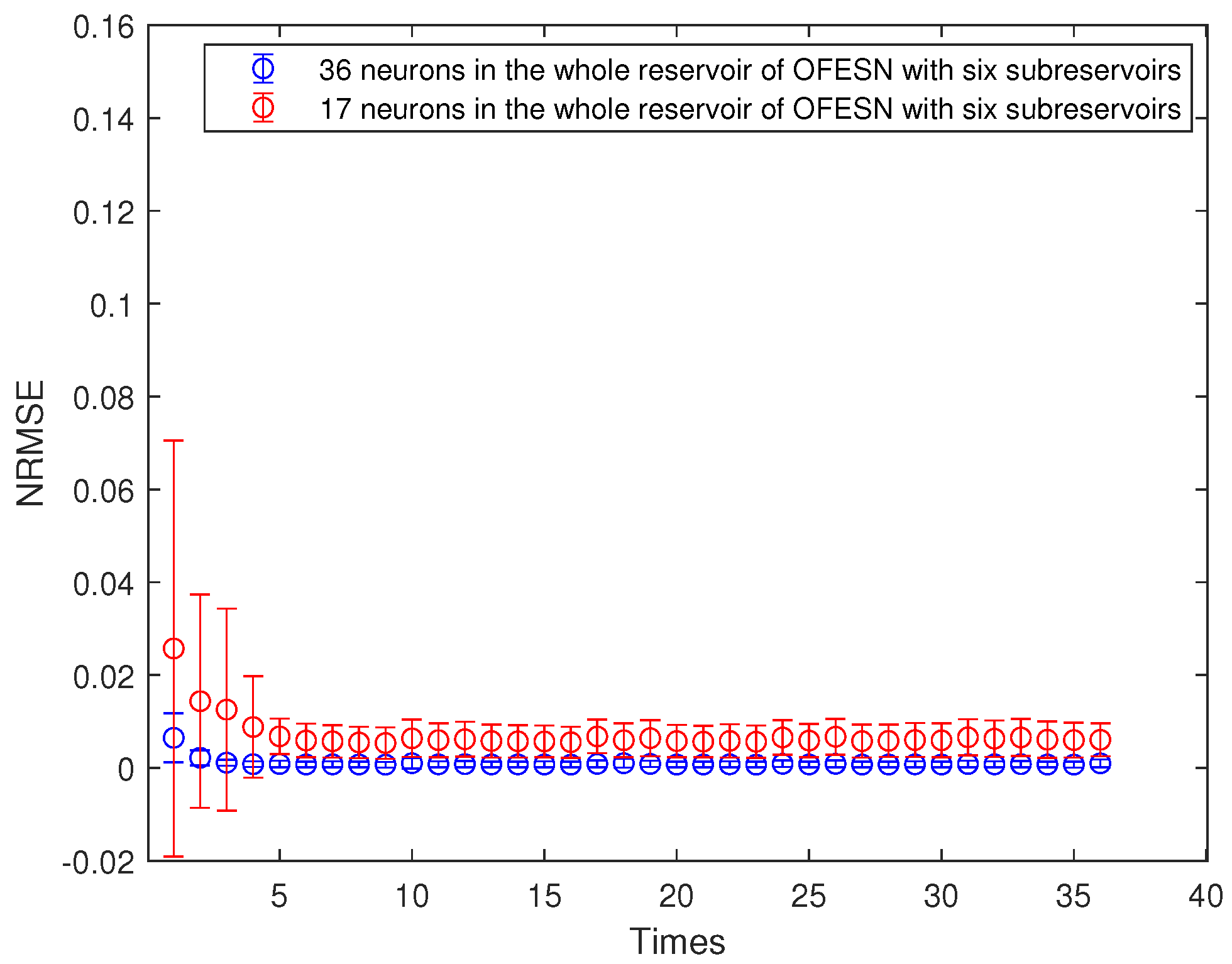
Under the same number of neurons in the whole reservoir, the performance comparison for the OFESN with a different number of subreservoirs is shown in Figure 18. In Figure 18, the red line with ∗ denotes the prediction error bars of the OFESN with three subreservoirs under the first initial value and subreservoirs partially connected, and the blue line with ∘ denotes the prediction error bars of the OFESN with six subreservoirs under the first initial value and subreservoirs partially connected.
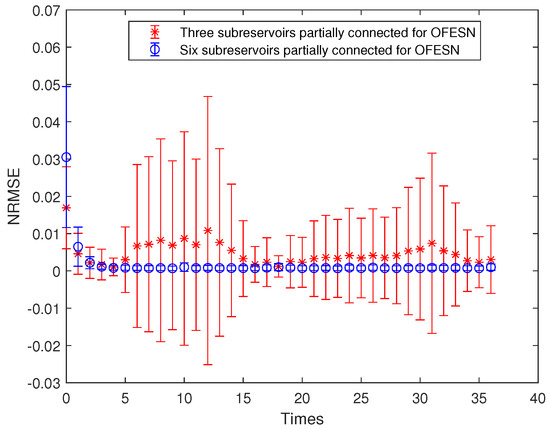
Figure 18.
Comparison of the OFESN with a different number of subreservoirs under the first initial value and partial connection.
The predicted time series length is 500, and the run time is shown in Table 1. Table 2 shows the comparison of the core parameter ratio in the OFESN and Leaky-ESN. In Table 1, similar to Table 3 and Table 4, represents training error, represents training time, represents testing error, and represents testing time. In Table 2, similar to Table 5 and Table 6, a represents Leaky rate, represents spectral radius, and represents input scaling factor. As can be seen from Table 1, the training and test time of the OFESN are slightly better than Leaky-ESN; the training and test errors are both improved by an order of magnitude, and the prediction accuracy is improved by 98% at most. As can be seen from Table 2, a, , and are closely related to the selection of initial values.

Table 1.
Comparison of running time and NRMSE between the OFESN and Leaky-ESN.
Table 2.
Comparison of parameter values between OFESN and Leaky-ESN.
Table 3.
Comparison of running time and NRMSE between the OFESN and Leaky-ESN.
Table 4.
Comparison of running time and NRMSE between the OFESN and Leaky-ESN for Mackey–Glass series.
Table 5.
Comparison of parameter values between the OFESN and Leaky-ESN.
Table 6.
Comparison of parameter values between the OFESN and Leaky-ESN for Mackey–Glass series.
4.1.3. The Reservoir with 17 Neurons
In order to test the performance of the OFESN when the reservoir contains only a small number of neurons, we select the total number of neurons in the reservoir in the following simulation. Assuming that the reservoir is divided into 6 actual subreservoirs, , , and then the number of neurons in the virtual reservoir is . The performance of the OFESN is tested on the case of the reservoir neurons with different connections and two different initial values of the reservoir parameters.
- (i).
- The first initial value case and the fully connected subreservoir (called Case 1)
The sparse degree of each actual subreservoirs of the OFESN is set to 1; that is, it is fully connected. The sparse degree of the virtual subreservoir is . Thus, the reservoir of the OFESN is equivalent to having 67 internal connection weights. Corresponding to Leaky-ESN, its sparse degree is . Figure 19 shows the performance of the OFESN and Leaky-ESN. It can be seen that the prediction performance of the OFESN is significantly better than Leaky-ESN, and it has smaller error fluctuation.
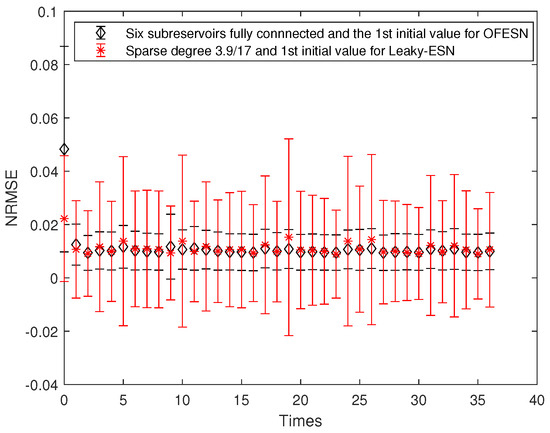
Figure 19.
Comparison between the OFESN with each subreservoir fully connected and Leaky-ESN under the first initial value.
- (ii).
- The first initial value case and the partially connected subreservoir (called Case 2)
The sparse degree of each subreservoir is set to , , respectively, and is equivalent to 52 internal connection weights. Thus, the corresponding sparse degree of leaky-ESN should be set to . The performance comparison between the OFESN and leaky-ESN is shown in Figure 20. It can be seen that in the whole training process, the prediction performance of Leaky-ESN is better than that of the OFESN, and the error fluctuation is smaller.
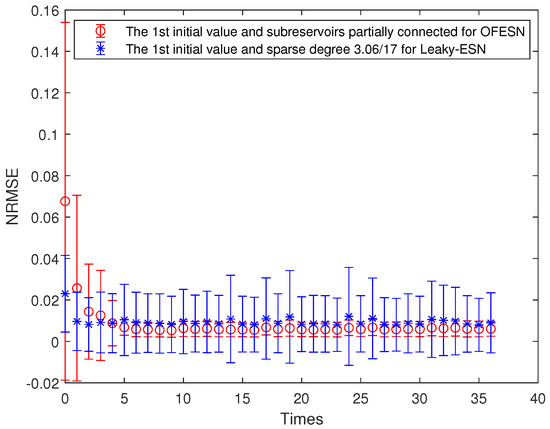
Figure 20.
Comparison between the OFESN with each subreservoir partially connected and Leaky-ESN under the first initial value.
- (iii).
- The second initial value case and the fully connected subreservoir (called Case 3)
The sparse degree of each actual subreservoir is set to 1; that is, it is fully connected. The sparse degree of the virtual subreservoir is , which is equivalent to having 67 internal connection weights in the whole reservoir., corresponding to Leaky-ESN, and its sparse degree is . Figure 21 shows the performance comparison between the OFESN and Leaky-ESN. It can be seen that the OFESN is slightly better than Leaky-ESN in terms of prediction accuracy and error fluctuation.
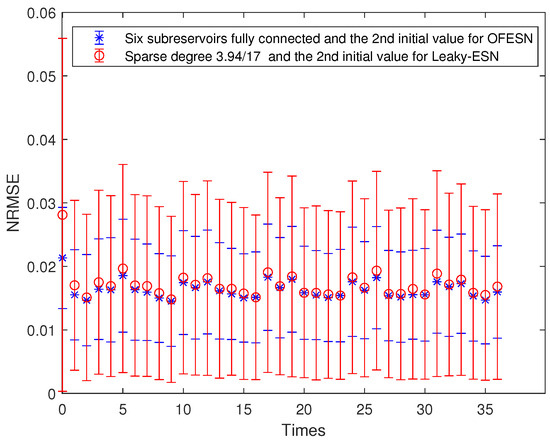
Figure 21.
Comparison between the OFESN with each subreservoir fully connected and Leaky-ESN under the first initial value.
- (iv).
- The second initial value case and the partially connected subreservoir (called Case 4)
The sparse degree of each actual subreservoir is set to ; that is, it is partially connected. The sparse degree of the virtual subreservoir is , which is equivalent to having 52 internal connection weights in the whole reservoir, which corresponds to Leaky-ESN, and its sparse degree is . Figure 22 shows the performance comparison between the OFESN and Leaky-ESN.
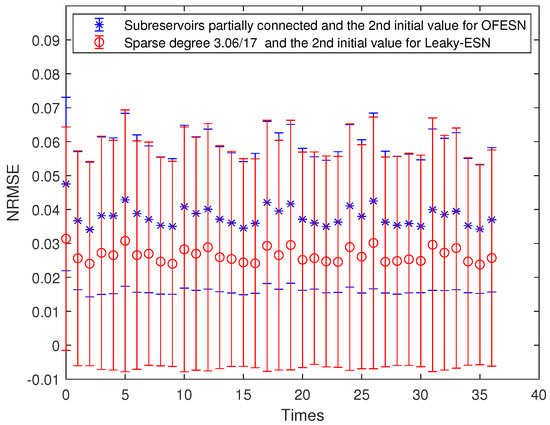
Figure 22.
Comparison between the OFESN and Leaky-ESN under partial connection and the second initial value.
Figure 23 shows the performance comparison between the OFESN with 36 neurons and the OFESN with 17 neurons in the case of the first initial value and partially connected subreservoirs. The predicted time series length is 20,000, and run time is shown in Table 3. Table 5 shows the comparison of the core parameter ratio in the OFESN and Leaky-ESN. As can be seen from Table 3, the training and test time of the OFESN is slightly better than Leaky-ESN; the training and test errors are both improved by an order of magnitude, and the prediction accuracy is improved by 96% at most. As can be seen from Table 5, a, , and are closely related to the selection of initial values.
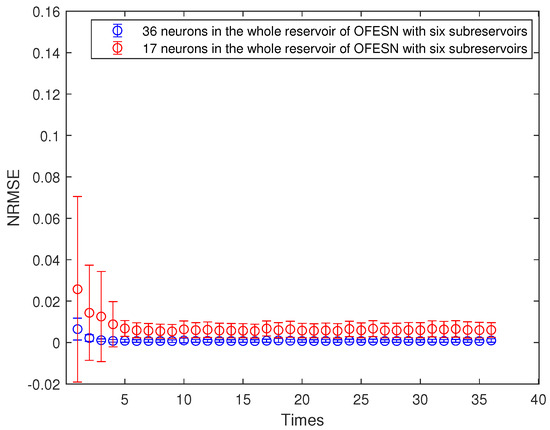
Figure 23.
Comparison between the OFESN with each subreservoir fully connected and Leaky-ESN with fully connected reservoir under the first initial value.
4.1.4. Analysis of the Simulation Results
We can see from the simulation figures that the prediction performance of the OFESN with the same number of internal connection weights is better than that of Leaky-ESN under more cases. Even if the prediction performance of the OFESN with the same number of connection weights is similar to that of the ESN, the prediction error volatility of the OFESN is much smaller than that of Leaky-ESN. In addition, we give comparisons between the OFESN with each subreservoir fully connected and Leaky-ESN with full connection, shown in Figure 6, Figure 9, Figure 13 and Figure 16, and the OFESN with each subreservoir fully connected has a better performance and less error fluctuation than Leaky-ESN with full connection. We can see from Figure 23 that the OFESN with 36 neurons and 3 subreservoirs has a prediction performance closer to the OFESN with 17 neurons and 6 subreservoirs in the whole reservoir. Thus, we can say, when the number of neurons is small, the greater the number of subreservoirs, the greater the number of neurons in the whole reservoir by adding a virtual reservoir. In a word, the OFESN has more stable performance and shorter run time.
4.2. Mackey–Glass Chaotic Time Series
The Mackey–Glass chaotic time series (MGS) is a classic nonlinear dynamical system, commonly used in fields such as time series analysis, signal processing, and chaos theory. For example, the Mackey–Glass equation can be used to describe the fluctuations and trends in market prices in economics and study the biological clock and rhythmic behavior within organisms in biology. The Mackey–Glass equation can be represented as
where , , , . denotes the delay factor, and the sequence has chaotic properties when . We normalize the dataset by the min-max scaling method so that all the data are between 0 and 1. We split the time series dataset by using of it for training purposes, for validation purposes, and the remaining for testing purposes. The first 100 samples are discarded during training to guarantee that the system is not affected by the initial transient, in accordance with the echo property. According to Equations (23) and (24), we generate 40,000 data samples, which are divided into three parts: 20,000 training samples, 10,000 testing sample points, and 100 initial washing out samples. The predicted time series length is 20,000, and the run time is shown in Table 4. Table 6 shows the comparison of core parameter ratio in the OFESN and Leaky-ESN.
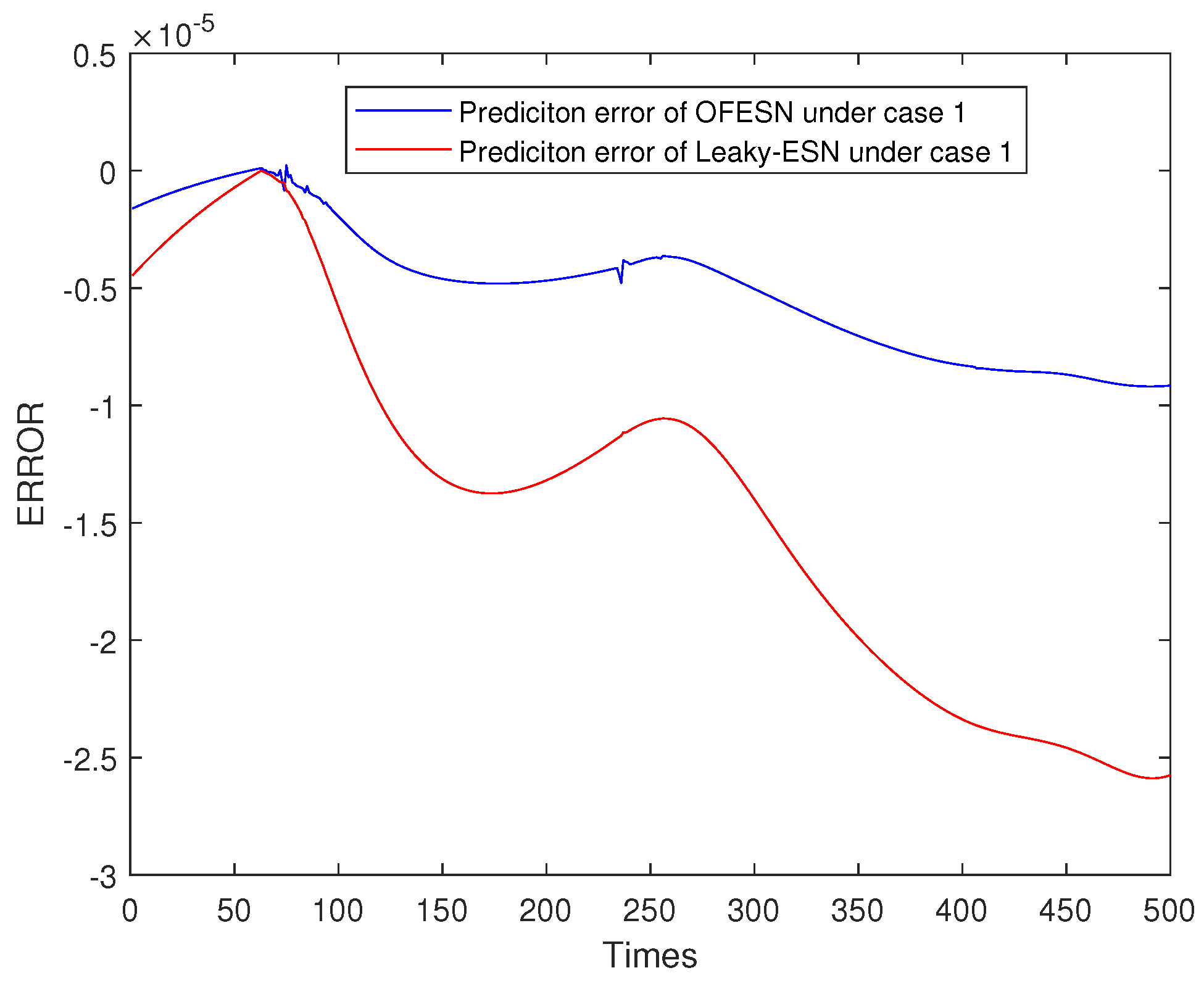
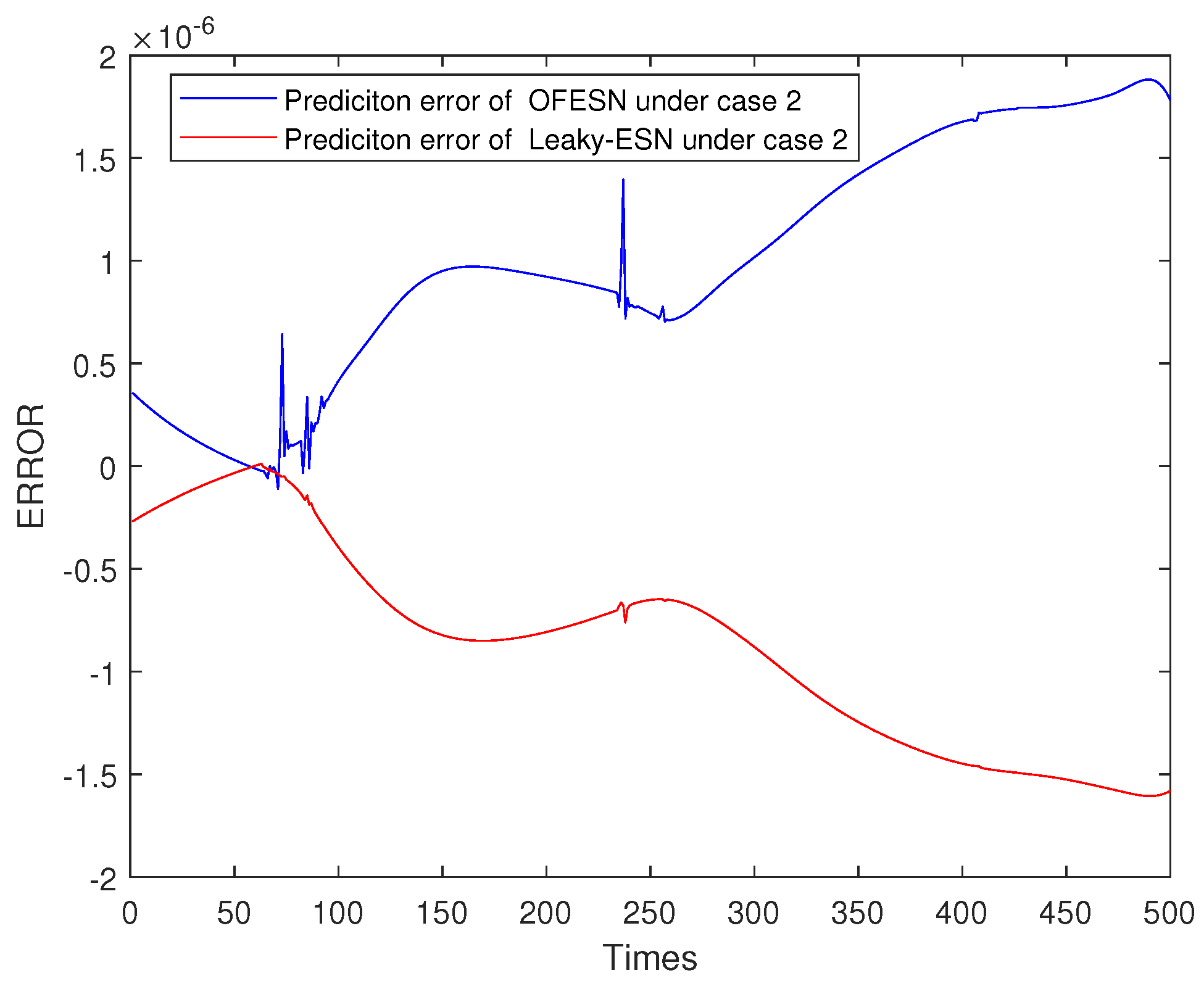
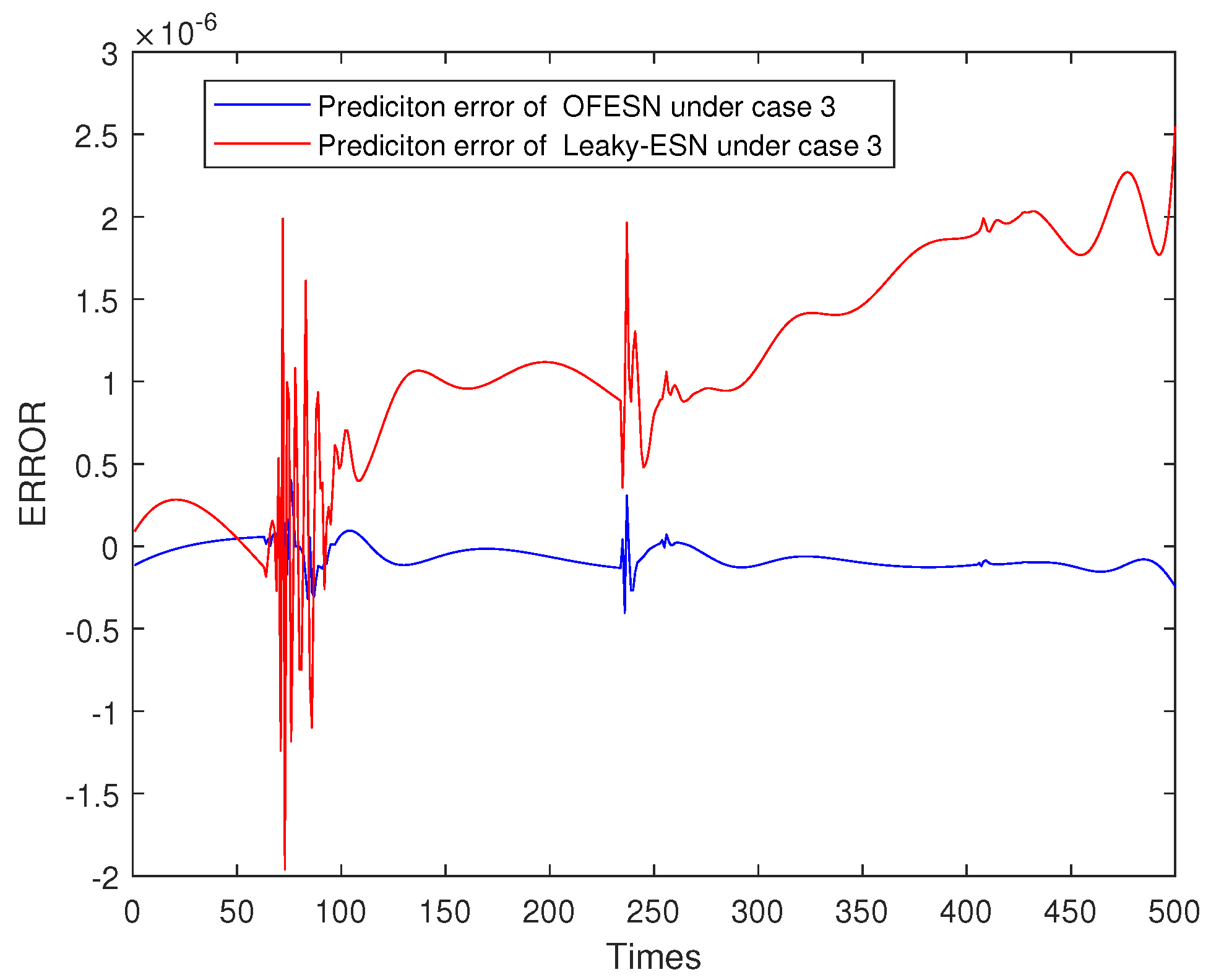
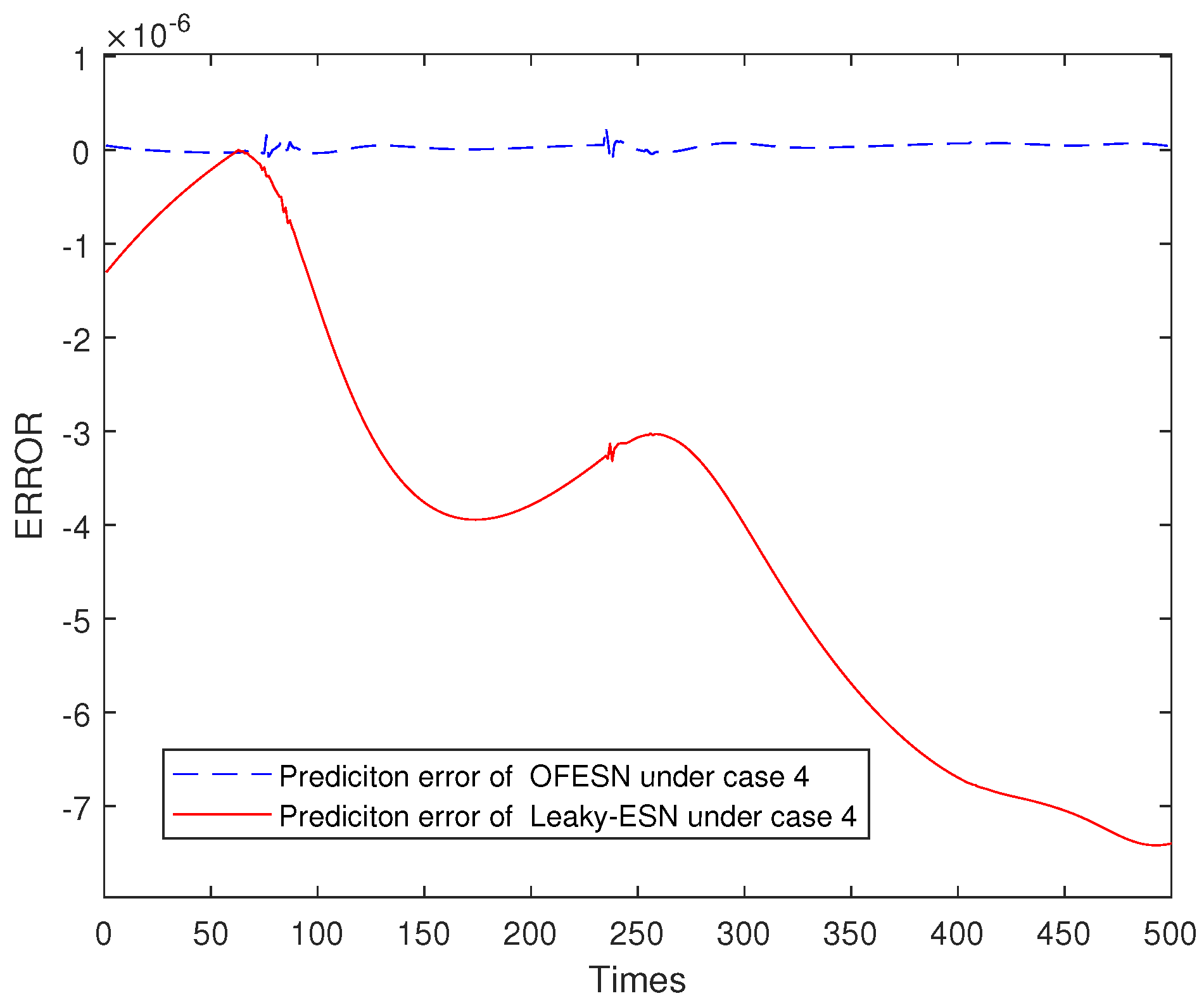
Figure 24, Figure 25, Figure 26 and Figure 27 shows the comparison of prediction error results of the OFESN and Leaky-ESN in different cases. As can be seen from the figure, in cases 1, 2, and 4, the prediction error of Leaky-ESN is significantly better than that of the OFESN, and it tends to converge, while the OFESN tends to diverge. In case 3, the prediction effect of the OFESN is better than Leaky-ESN. As can be seen from Table 4, the training and test time of the OFESN is slightly better than Leaky-ESN; the training and test errors are both improved by an order of magnitude, and the prediction accuracy is improved by 98% at most. As can be seen from Table 6, a, , and are closely related to the selection of initial values.
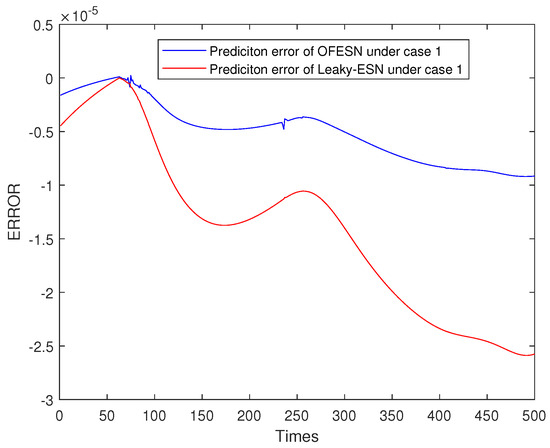
Figure 24.
Error result based on the OFESN and Leaky-ESN for Mackey–Glass.
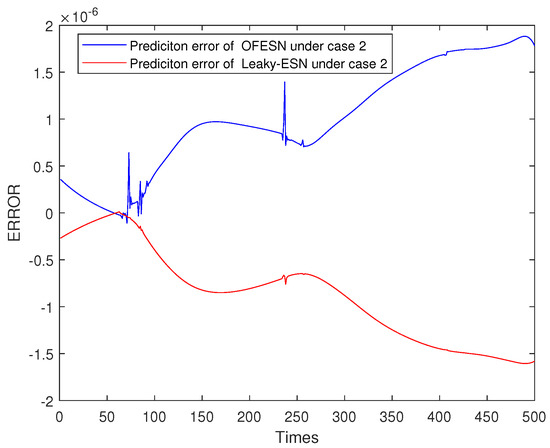
Figure 25.
Error result based on the OFESN and Leaky-ESN for Mackey–Glass.
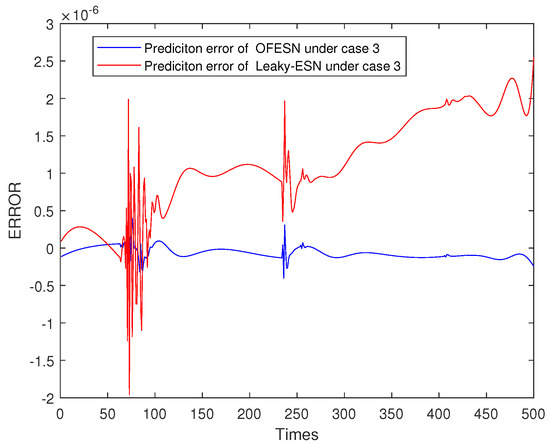
Figure 26.
Error result based on the OFESN and Leaky-ESN for Mackey–Glass.
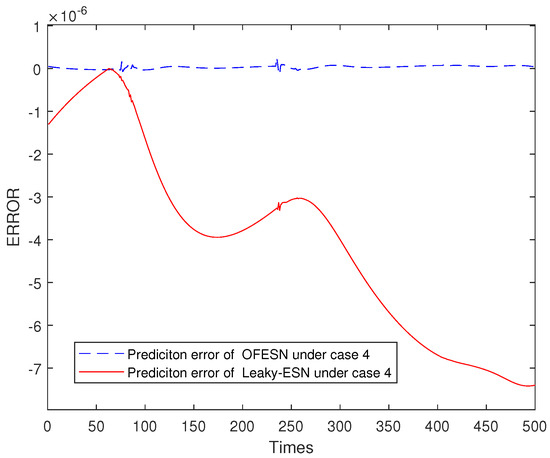
Figure 27.
Error result based on the OFESN and Leaky-ESN for Mackey–Glass.
5. Conclusions
This paper proposed a new multireservoir echo state network, namely the OFESN. The OFESN can transform the connections of a single reservoir into the connections of subreservoirs by their master neurons, greatly reducing the coupling connections between neurons in a reservoir, further increasing sparse degree, and reducing information redundancy. Compared with Leaky-ESN network, the OFESN network greatly reduces the internal coupling and correlation between different subreservoirs. Without increasing the number of neurons in the reservoir, introducing a sparse connection between the master neurons is actually equivalent to greatly increasing the number of neurons, especially the number of neurons with great dissimilarity. Therefore, when the number of neurons in each actual subreservoir is small and the number of subreservoirs is large, it is equivalent to obtaining more reservoir neurons and ensuring the dissimilarity of neuron states, which improves the prediction accuracy of Leaky-ESN and greatly reduces the amount of calculation. Prediction accuracy improved by 98% in some cases. However, there are some limitations to the OFESN and Leaky-ESN. The gradient descent optimization method is used to optimize parameters with constraint conditions (echo state characteristic conditions), which is sensitive to the initial value selection of parameters and cannot guarantee global optimization. Therefore, in the future, we will find a suitable swarm intelligence optimization algorithm to optimize its parameters to eliminate the impact of the initial parameter values. The performance comparison between the OFESN and LEAKY-ESN is not a comparison between the optimal performance of the two models but a comparison under the same parameters and equivalent conditions.
Author Contributions
Methodology, Q.W.; software, Q.W.; validation, Q.W.; data curation, Q.W.; writing—original draft preparation, Q.W.; writing—review and editing, S.L., J.C. and X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China grant number 61773074 and Key research projects of the Education Department in Liaoning Province grant number LJKZZ20220118.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Beritelli, F.; Capizzi, G.; Sciuto, G.L.; Napoli, C.; Tramontana, E.; Woźniak, M. Reducing interferences in wireless communication systems by mobile agents with recurrent neural networks-based adaptive channel equalization. Photonics Applications in Astronomy, Communications, Industry, and High-Energy Physics Experiments 2015. In Proceedings of the XXXVI Symposium on Photonics Applications in Astronomy, Communications, Industry, and High-Energy Physics Experiments (Wilga 2015), Wilga, Poland, 25 May 2015; Volume 9662, pp. 497–505. [Google Scholar]
- Jaeger, H. The “echo state” approach to analysing and training recurrent neural networks-with an erratum note. Bonn Ger. Ger. Natl. Res. Cent. Inf. Technol. GMD Tech. Rep. 2001, 148, 13. [Google Scholar]
- Jaeger, H.; Haas, H. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. Science 2004, 304, 78–80. [Google Scholar] [CrossRef]
- Jaeger, H. Tutorial on Training Recurrent Neural Networks, Covering BPPT, RTRL, EKF and the “Echo State Network” Approach; German National Research Center for Information Technology: Sankt Augustin, Germany, 2002. [Google Scholar]
- Soliman, M.; Mousa, M.A.; Saleh, M.A.; Elsamanty, M.; Radwan, A.G. Modelling and implementation of soft bio-mimetic turtle using echo state network and soft pneumatic actuators. Sci. Rep. 2021, 11, 12076. [Google Scholar] [CrossRef] [PubMed]
- Wootton, A.J.; Taylor, S.L.; Day, C.R.; Haycock, P.W. Optimizing echo state networks for static pattern recognition. Cogn. Comput. 2017, 9, 391–399. [Google Scholar] [CrossRef]
- Mahmoud, T.A.; Abdo, M.I.; Elsheikh, E.A.; Elshenawy, L.M. Direct adaptive control for nonlinear systems using a TSK fuzzy echo state network based on fractional-order learning algorithm. J. Frankl. Inst. 2021, 358, 9034–9060. [Google Scholar] [CrossRef]
- Wang, Q.; Pan, Y.; Cao, J.; Liu, H. Adaptive Fuzzy Echo State Network Control of Fractional-Order Large-Scale Nonlinear Systems With Time-Varying Deferred Constraints. IEEE Trans. Fuzzy Syst. 2023, 1–15. [Google Scholar] [CrossRef]
- Gao, R.; Du, L.; Duru, O.; Yuen, K.F. Time series forecasting based on echo state network and empirical wavelet transformation. Appl. Soft Comput. 2021, 102, 107111. [Google Scholar] [CrossRef]
- Bai, Y.; Liu, M.D.; Ding, L.; Ma, Y.J. Double-layer staged training echo-state networks for wind speed prediction using variational mode decomposition. Appl. Energy 2021, 301, 117461. [Google Scholar] [CrossRef]
- Tian, Z. Echo state network based on improved fruit fly optimization algorithm for chaotic time series prediction. J. Ambient Intell. Humaniz. Comput. 2022, 13, 3483–3502. [Google Scholar] [CrossRef]
- Ribeiro, G.T.; Santos, A.A.P.; Mariani, V.C.; dos Santos Coelho, L. Novel hybrid model based on echo state neural network applied to the prediction of stock price return volatility. Expert Syst. Appl. 2021, 184, 115490. [Google Scholar] [CrossRef]
- Qiao, J.; Li, F.; Han, H.; Li, W. Growing echo-state network with multiple subreservoirs. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 391–404. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Li, Y.; Shardt, Y.A.; Qiao, L.; Shi, M.; Yang, X. Error-driven chained multiple-subnetwork echo state network for time-series prediction. IEEE Sens. J. 2022, 22, 19533–19542. [Google Scholar] [CrossRef]
- Ma, Q.; Chen, E.; Lin, Z.; Yan, J.; Yu, Z.; Ng, W.W. Convolutional multitimescale echo state network. IEEE Trans. Cybern. 2019, 51, 1613–1625. [Google Scholar] [CrossRef] [PubMed]
- Gallicchio, C.; Micheli, A. Deep reservoir neural networks for trees. Inf. Sci. 2019, 480, 174–193. [Google Scholar] [CrossRef]
- Na, X.; Zhang, M.; Ren, W.; Han, M. Multi-step-ahead chaotic time series prediction based on hierarchical echo state network with augmented random features. IEEE Trans. Cogn. Dev. Syst. 2022, 15, 700–711. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Q.J.; Wang, D.; Xin, J.; Yang, Y.; Yu, K. Echo state network with a global reversible autoencoder for time series classification. Inf. Sci. 2021, 570, 744–768. [Google Scholar] [CrossRef]
- Lun, S.X.; Yao, X.S.; Qi, H.Y.; Hu, H.F. A novel model of leaky integrator echo state network for time-series prediction. Neurocomputing 2015, 159, 58–66. [Google Scholar] [CrossRef]
- Lun, S.; Zhang, Z.; Li, M.; Lu, X. Parameter Optimization in a Leaky Integrator Echo State Network with an Improved Gravitational Search Algorithm. Mathematics 2023, 11, 1514. [Google Scholar] [CrossRef]
- Ren, W.; Ma, D.; Han, M. Multivariate Time Series Predictor With Parameter Optimization and Feature Selection Based on Modified Binary Salp Swarm Algorithm. IEEE Trans. Ind. Inform. 2022, 19, 6150–6159. [Google Scholar] [CrossRef]
- Hu, H.; Wang, L.; Tao, R. Wind speed forecasting based on variational mode decomposition and improved echo state network. Renew. Energy 2021, 164, 729–751. [Google Scholar] [CrossRef]
- Wainrib, G.; Galtier, M.N. A local echo state property through the largest Lyapunov exponent. Neural Netw. 2016, 76, 39–45. [Google Scholar] [CrossRef] [PubMed]
- Gallicchio, C.; Micheli, A. Echo state property of deep reservoir computing networks. Cogn. Comput. 2017, 9, 337–350. [Google Scholar] [CrossRef]
- Yang, C.; Qiao, J.; Ahmad, Z.; Nie, K.; Wang, L. Online sequential echo state network with sparse RLS algorithm for time series prediction. Neural Netw. 2019, 118, 32–42. [Google Scholar] [CrossRef]
- Gallicchio, C.; Micheli, A.; Pedrelli, L. Deep reservoir computing: A critical experimental analysis. Neurocomputing 2017, 268, 87–99. [Google Scholar] [CrossRef]
- Wu, Z.; Li, Q.; Zhang, H. Chain-structure echo state network with stochastic optimization: Methodology and application. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 1974–1985. [Google Scholar] [CrossRef] [PubMed]
- Jaeger, H.; Lukoševičius, M.; Popovici, D.; Siewert, U. Optimization and applications of echo state networks with leaky-integrator neurons. Neural Netw. 2007, 20, 335–352. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).