
One-Dimensional Convolutional Wasserstein Generative Adversarial Network Based Intrusion Detection Method for Industrial Control Systems


Abstract
:1. Introduction
2. Related Work
2.1. Intrusion Detection Method Based on Machine Learning
2.2. Intrusion Detection Method Based on Deep Learning
3. ICS Intrusion Detection Method Based on 1D CWGAN
3.1. Overview of GAN
3.1.1. Generator
3.1.2. Discriminator
3.1.3. Network Training
3.2. Data Enhancement Method Based on 1D CWGAN
3.3. Description of Intrusion Detection Algorithm Based on 1D CWGAN
4. Experiment
4.1. Data Set
4.2. Data Preprocessing
4.2.1. Gas Pipeline Industrial Data Set
4.2.2. TON_IoT (UNSW-IoT20) Data Set
- Missing value filling. Missing values are common in ToN_IoT, and these missing values must be handled appropriately. In the proposed model, the imputation of missing values is replaced by the most frequent value in each feature containing missing data.
- Delete the attributes that cause overfitting. Multiple attributes such as timestamp, IP address, source port and target port in the data set are deleted because they may cause overfitting.
4.3. Evaluation Indicators of Intrusion Detection
4.4. Analysis of Experimental Results
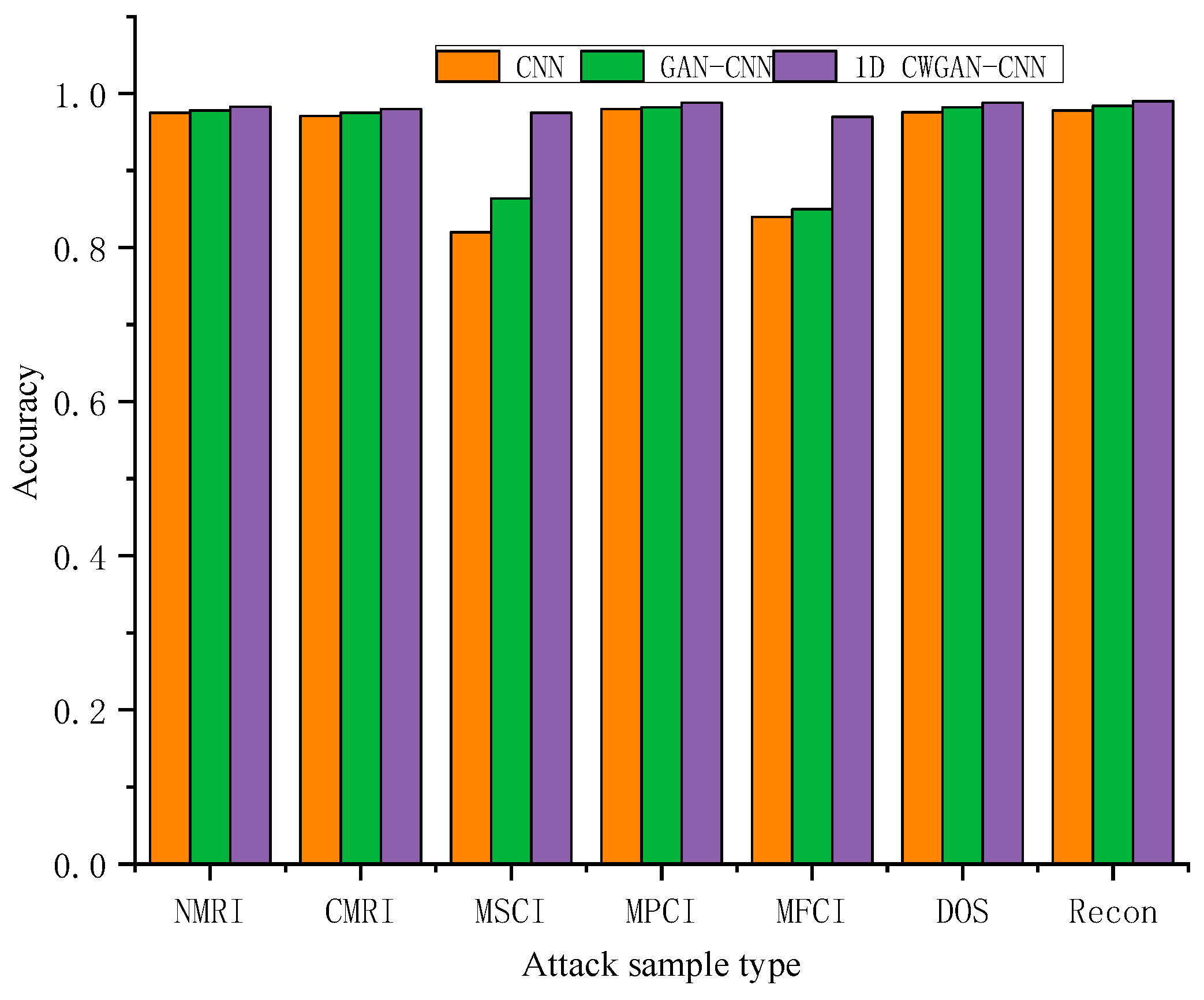
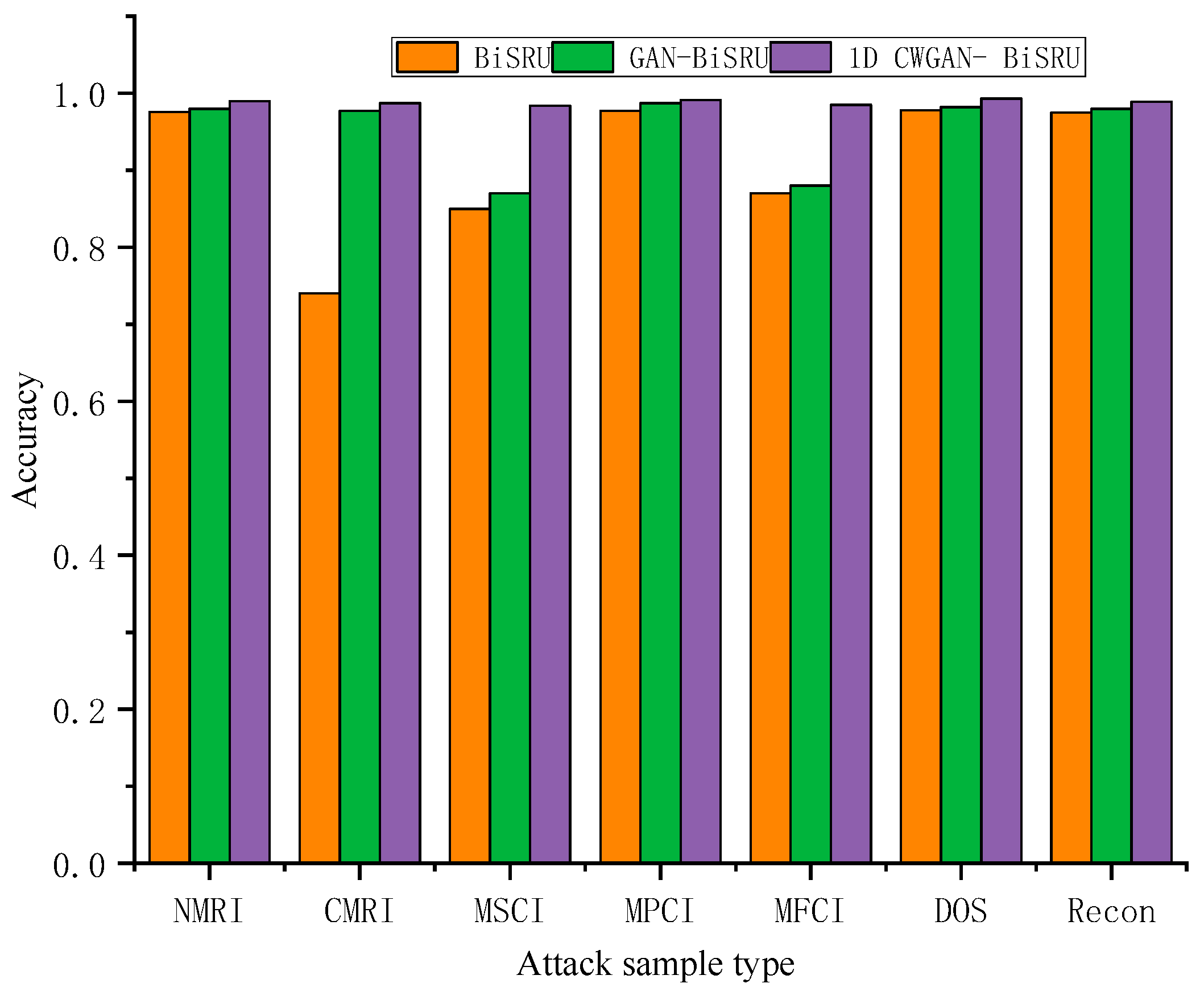
4.4.1. Verify the Gas Pipeline Data Set
4.4.2. Verify the TON_IoT Network Data Set
4.4.3. Verify the TON_IoT Linux Process Data Set
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Altunay, H.C.; Albayrak, Z.; Özalp, A.N.; Çakmak, M. Analysis of Anomaly Detection Approaches Performed Through Deep Learning Methods in SCADA Systems. In Proceedings of the 2021 3rd International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 11–13 June 2021; pp. 1–6. [Google Scholar]
- Balla, A.; Habaebi, M.H.; Elsheikh, E.A.; Islam, M.R.; Suliman, F.M. The Effect of Dataset Imbalance on the Performance of SCADA Intrusion Detection Systems. Sensors 2023, 23, 758. [Google Scholar] [CrossRef] [PubMed]
- Dusan, N.; Zivana, J. CNN based Method for the Development of Cyber-Attacks Detection Algorithms in Industrial Control Systems. Comput. Secur. 2022, 114, 102585. [Google Scholar]
- Qian, J.; Du, X.; Chen, B.; Qu, B.; Zeng, K.; Liu, J. Cyber-Physical Integrated Intrusion Detection Scheme in SCADA System of Process Manufacturing Industry. IEEE Access 2020, 8, 147471–147481. [Google Scholar] [CrossRef]
- Shen, C.; Liu, C.; Tan, H.; Wang, Z.; Xu, D.; Su, X. Hybrid-Augmented Device Fingerprinting for Intrusion Detection in Industrial Control System Networks. IEEE Wirel. Commun. 2018, 25, 26–31. [Google Scholar] [CrossRef]
- Jamoos, M.; Mora, A.M.; AlKhanafseh, M.; Surakhi, O. A New Data-Balancing Approach Based on Generative Adversarial Network for Network Intrusion Detection System. Electronics 2023, 12, 2851. [Google Scholar] [CrossRef]
- Reddy, R.R.; Ramadevi, Y.; Sunitha, K.V.N. Effective discriminant function for intrusion detection using SVM. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 1148–1153. [Google Scholar]
- Moon, D.; Im, H.; Kim, I.; Park, J.H. DTB-IDS: An intrusion detection system based on decision tree using behavior analysis for preventing APT attacks. J. Supercomput. 2017, 73, 2881–2895. [Google Scholar] [CrossRef]
- Mughal, M.O.; Kim, S. Signal classification and jamming detection in wide-band radios using Nave Bayes classifier. IEEE Commun. Lett. 2018, 22, 1398–1401. [Google Scholar] [CrossRef]
- Anton, S.D.D.; Sinha, S.; Schotten, H.D. Anomaly-based intrusion detection in industrial data with SVM and Random Forests. In Proceedings of the 27th International Conference on Software, Telecommunications and Computer Networks (SOFTCOM), Split, Croatia, 19–21 September 2019; pp. 465–470. [Google Scholar]
- Al-Asiri, M.; El-Alfy, E.-S.M. On Using Physical Based Intrusion Detection in SCADA Systems. Procedia Comput. Sci. 2020, 170, 34–42. [Google Scholar] [CrossRef]
- Khan, A.A.Z.; Serpen, G. Misuse intrusion detection using machine learning for Gas Pipeline SCADA networks. In Proceedings of the International Conference on Security and Management (SAM), Las Vegas, NV, USA, 29 July–1 August 2019; pp. 84–90. [Google Scholar]
- Tian, Q.; Li, J.; Liu, H. A Method for Guaranteeing Wireless Communication Based on a Combination of Deep and Shallow Learning. IEEE Access 2019, 7, 38688–38695. [Google Scholar] [CrossRef]
- Ding, P.; Li, J.; Wen, M.; Wang, L.; Li, H. Efficient BiSRU Combined with Feature Dimensionality Reduction for Abnormal Traffic Detection. IEEE Access 2020, 8, 164414–164427. [Google Scholar] [CrossRef]
- Mubarak, S.; Habaebi, M.H.; Islam, M.R.; Balla, A.; Tahir, M.; Elsheikh, A.; Suliman, F.M. Industrial Datasets with ICS Testbed and Attack Detection Using Machine Learning Techniques. Intell. Autom. Soft Comput. 2022, 31, 1345–1360. [Google Scholar] [CrossRef]
- Mubarak, S.; Habaebi, M.H.; Islam, M.R.; Rahman FD, A.; Tahir, M. Anomaly Detection in ICS Datasets with Machine Learning Algorithms. Comput. Syst. Sci. Eng. 2021, 37, 014384. [Google Scholar] [CrossRef]
- Liao, X.; Li, K.; Zhu, X.; Liu, K.J.R. Robust Detection of Image Operator Chain with Two-Stream Convolutional Neural Network. IEEE J. Sel. Top. Signal Process. 2020, 14, 955–968. [Google Scholar] [CrossRef]
- Yang, H.; Cheng, L.; Chuah, M. Deep-learning-based network intrusion detection for SCADA Systems. In Proceedings of the IEEE Conference on Communications and Network Security (CNS), Washington, DC, USA, 10–12 June 2019; pp. 1–7. [Google Scholar]
- Liu, J.; Yin, L.; Hu, Y.; Lv, S.; Sun, L. A novel intrusion detection algorithm for industrial control systems based on CNN and process state transition. In Proceedings of the 37th International Performance Computing and Communications Conference (IPCCC), Orlando, FL, USA, 17–19 November 2018; pp. 1–8. [Google Scholar]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A deep learning approach for intrusion detection using recurrent neural network. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Roy, B.; Cheung, H. A deep learning approach for intrusion detection in internet of things using bi-directional long short-term memory recurrent neural network. In Proceedings of the 28th International Telecommunication Networks and Applications Conference (ITNAC), Sydney, NSW, Australia, 21–23 November 2018; pp. 57–62. [Google Scholar]
- Sokolov, A.N.; Alabugin, S.K.; Pyatnitsky, I.A. Traffic modeling by recurrent neural networks for intrusion detection in industrial control systems. In Proceedings of the International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM), Sochi, Russia, 25–29 March 2019; pp. 1–5. [Google Scholar]
- Lei, T.; Zhang, Y.; Wang, S.I.; Dai, H.; Artzi, Y. Simple recurrent units for highly parallelizable recurrence. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Brussels, Belgium, 31 October–4 November 2018; pp. 4470–4481. [Google Scholar]
- Alotaibi, A.; Rassam, M.A. Enhancing the Sustainability of Deep-Learning-Based Network Intrusion Detection Classifiers against Adversarial Attacks. Sustainability 2023, 15, 9801. [Google Scholar] [CrossRef]
- Mari, A.G.; Zinca, D.; Dobrota, V. Development of a Machine-Learning Intrusion Detection System and Testing of Its Performance Using a Generative Adversarial Network. Sensors 2023, 23, 1315. [Google Scholar] [CrossRef] [PubMed]
- Du, P.H.; Nguyen, H.N. APELID: Enhancing real-time intrusion detection with augmented WGAN and parallel ensemble learning. Comput. Secur. 2024, 136, 103567. [Google Scholar]
- Ling, J.; Zhu, Z.H.; Luo, Y.; Wang, H. An intrusion detection method for industrial control systems based on bidirectional simple recurrent unit. Comput. Electr. Eng. 2021, 91, 107049. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack Type | Describe | Number |
|---|---|---|
| Normal | Normal (0) | 61,156 |
| Naïve malicious response injection | NMRI (1) | 2763 |
| Complex malicious response injection | CMRI (2) | 15,466 |
| Malicious state command injection | MSCI (3) | 782 |
| Malicious parameter command injection | MPCI (4) | 7637 |
| Malicious function code injection | MFCI (5) | 573 |
| Denial of service | DOS (6) | 1837 |
| Reconnaissance | Recon (7) | 6805 |
| Attack Type | Normal | DoS | Ransomware | Password | Scanning |
| Number | 300,000 | 20,000 | 20,000 | 20,000 | 20,000 |
| Attack type | Injection | DDoS | backdoor | XSS | mitm |
| Number | 20,000 | 20,000 | 20,000 | 20,000 | 1043 |
| Attack Type | Normal | DoS | Password | Scanning |
| Number | 100,000 | 10,000 | 10,000 | 10,000 |
| Attack type | Injection | DDoS | XSS | mitm |
| Number | 10,000 | 10,000 | 10,000 | 112 |
| Predictive Value = 1 | Predictive Value = 0 | |
|---|---|---|
| True value = 1 | TP | FN |
| True value = 0 | FP | TN |
| Attack Types | Normal | NMRI | CMRI | MSCI | MPCI | MFCI | DOS | Recon |
| Number of original samples | 61,156 | 2763 | 15,466 | 782 | 7637 | 573 | 1837 | 6805 |
| Number of samples generated | 0 | 0 | 0 | 468 | 0 | 677 | 0 | 0 |
| Total | 61,156 | 2763 | 15,466 | 1250 | 7637 | 1250 | 1837 | 6805 |
| Method | Accuracy (%) | Precision (%) | Recall (%) | F1(%) |
|---|---|---|---|---|
| CNN [27] | 97.58 | 90.42 | 89.97 | 90.30 |
| BiSRU [14] | 97.66 | 90.78 | 90.44 | 90.61 |
| GAN-CNN | 97.85 | 91.14 | 92.67 | 91.90 |
| GAN-BiSRU | 98.01 | 93.34 | 93.08 | 93.21 |
| 1D CWGAN-CNN | 98.33 | 93.34 | 93.08 | 93.19 |
| 1D CWGAN-BiSRU | 99.00 | 97.90 | 93.90 | 95.90 |
| Attack Types | Normal | Scanning | Injection | DDoS | Mitm |
| Number of original samples | 300,000 | 20,000 | 20,000 | 20,000 | 1043 |
| Number of samples generated | 0 | 0 | 0 | 0 | 957 |
| Total | 300,000 | 20,000 | 20,000 | 20,000 | 20,000 |
| Attack Types | Ransomware | DOS | XSS | Password | Backdoor |
| Number of original samples | 20,000 | 20,000 | 20,000 | 20,000 | 20,000 |
| Number of samples generated | 0 | 0 | 677 | 0 | 0 |
| Total | 20,000 | 20,000 | 20,000 | 20,000 | 20,000 |
| Method | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|---|
| CNN [27] | 92.76 | 84.42 | 84.66 | 84.54 |
| BiSRU [14] | 92.84 | 84.78 | 84.54 | 84.66 |
| GAN-CNN | 94.89 | 87.14 | 87.74 | 87.44 |
| GAN-BiSRU | 95.76 | 88.34 | 88.21 | 88.27 |
| 1D CWGAN-CNN | 97.39 | 90.34 | 90.45 | 90.39 |
| 1D CWGAN-BiSRU | 98.12 | 92.90 | 91.54 | 92.21 |
| Attack Types | Normal | Scanning | Injection | DDoS |
| Number of original samples | 60,112 | 10,000 | 10,000 | 10,000 |
| Attack Types | Mitm | DOS | XSS | Password |
| Number of original samples | 112 | 10,000 | 10,000 | 10,000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, Z.; Du, H.; Wang, H.; Zhang, J.; Si, Y.; Li, P. One-Dimensional Convolutional Wasserstein Generative Adversarial Network Based Intrusion Detection Method for Industrial Control Systems. Electronics 2023, 12, 4653. https://doi.org/10.3390/electronics12224653
Cai Z, Du H, Wang H, Zhang J, Si Y, Li P. One-Dimensional Convolutional Wasserstein Generative Adversarial Network Based Intrusion Detection Method for Industrial Control Systems. Electronics. 2023; 12(22):4653. https://doi.org/10.3390/electronics12224653
Chicago/Turabian StyleCai, Zengyu, Hongyu Du, Haoqi Wang, Jianwei Zhang, Yajie Si, and Pengrong Li. 2023. "One-Dimensional Convolutional Wasserstein Generative Adversarial Network Based Intrusion Detection Method for Industrial Control Systems" Electronics 12, no. 22: 4653. https://doi.org/10.3390/electronics12224653
APA StyleCai, Z., Du, H., Wang, H., Zhang, J., Si, Y., & Li, P. (2023). One-Dimensional Convolutional Wasserstein Generative Adversarial Network Based Intrusion Detection Method for Industrial Control Systems. Electronics, 12(22), 4653. https://doi.org/10.3390/electronics12224653