


Multi-Task Learning and Temporal-Fusion-Transformer-Based Forecasting of Building Power Consumption

Abstract
:1. Introduction
2. Related Works
2.1. Multi-Task Learning
2.2. Temporal Fusion Transformer
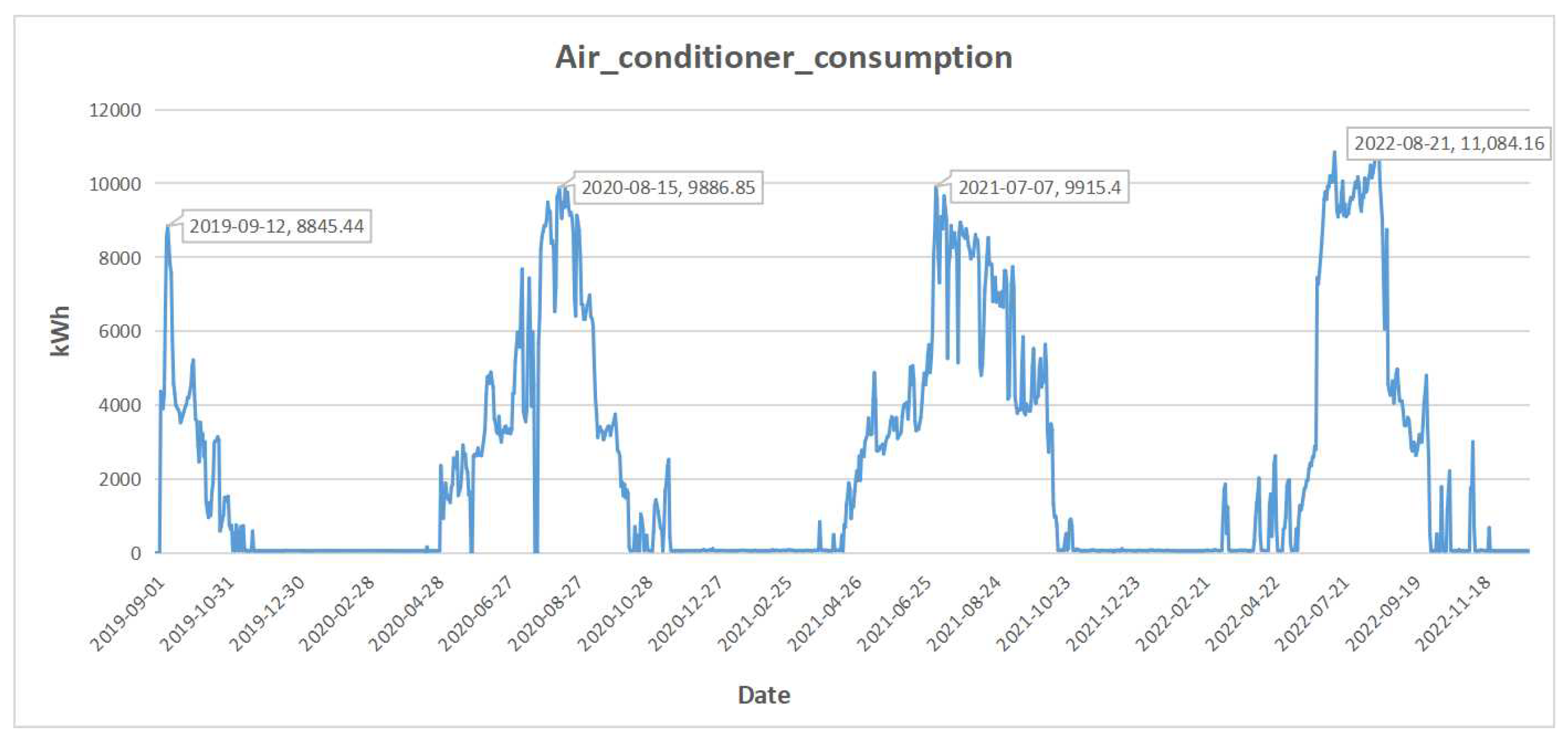
3. Dataset
4. Methodology
4.1. Simplified Temporal Fusion Transformer Model
4.2. Multi-Task Generation Strategy
4.3. Integration of Multi-Task Learning with Temporal Fusion Transformer
5. Experiments and Analysis
5.1. Experiments Setup
5.2. Results
6. Conclusions
- 1.
- Innovating a multi-task learning technique that serves dual purposes: data augmentation and efficient model training;
- 2.
- Customizing temporal fusion transformers to cater specifically to the nuances of building power consumption forecasting;
- 3.
- Authenticating the efficacy of MTLTFT through rigorous validation on a real-world dataset, establishing its superiority in the domain.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MTL | Multi-task Learning |
| TFT | Temporal Fusion Transformer |
| RNN | Recurrent Neural Networks |
| LSTM | Long Short-Term Memory |
| SVM | Support Vector Machine |
| GRU | Gated Recurrent Unit |
References
- Ürge-Vorsatz, D.; Cabeza, L.F.; Serrano, S.; Barreneche, C.; Petrichenko, K. Heating and cooling energy trends and drivers in buildings. Renew. Sustain. Energy Rev. 2015, 41, 85–98. [Google Scholar] [CrossRef]
- Li, W.; Xu, P.; Lu, X.; Wang, H.; Pang, Z. Electricity demand response in China: Status, feasible market schemes and pilots. Energy 2016, 114, 981–994. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Moon, J.; Park, S.; Rho, S.; Hwang, E. A comparative analysis of artificial neural network architectures for building energy consumption forecasting. Int. J. Distrib. Sens. Netw. 2019, 15, 1550147719877616. [Google Scholar] [CrossRef]
- Kaboli, S.H.A.; Fallahpour, A.; Kazemi, N.; Selvaraj, J.; Rahim, N. An expression-driven approach for long-term electric power consumption forecasting. Am. J. Data Min. Knowl. Discov. 2016, 1, 16–28. [Google Scholar]
- Chen, Y.; Mao, B.; Bai, Y.; Feng, Y.; Li, Z. Forecasting traction energy consumption of metro based on support vector regression. Syst. Eng. Eory Pract. 2016, 36, 2101–2107. [Google Scholar]
- Mehta, C.; Chandel, N.; Dubey, K. Smart Agricultural Mechanization in India—Status and Way Forward. In Smart Agriculture for Developing Nations: Status, Perspectives and Challenges; Springer: Singapore, 2023; pp. 1–14. [Google Scholar]
- Verma, J. Deep Technologies Using Big Data in: Energy and Waste Management. In Deep Learning Technologies for the Sustainable Development Goals: Issues and Solutions in the Post-COVID Era; Springer: Singapore, 2023; pp. 21–39. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Medsker, L.R.; Jain, L. Recurrent neural networks. Des. Appl. 2001, 5, 64–67. [Google Scholar]
- Graves, A.; Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Shao, X.; Pu, C.; Zhang, Y.; Kim, C.S. Domain fusion CNN-LSTM for short-term power consumption forecasting. IEEE Access 2020, 8, 188352–188362. [Google Scholar] [CrossRef]
- Yuniarti, E.; Nurmaini, N.; Suprapto, B.Y.; Rachmatullah, M.N. Short term electrical energy consumption forecasting using rnn-lstm. In Proceedings of the 2019 International Conference on Electrical Engineering and Computer Science (ICECOS), Batam, Indonesia, 2–3 October 2019; pp. 287–292. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep transformer models for time series forecasting: The influenza prevalence case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Zhang, J.; Zhang, H.; Ding, S.; Zhang, X. Power consumption predicting and anomaly detection based on transformer and K-means. Front. Energy Res. 2021, 9, 779587. [Google Scholar] [CrossRef]
- Yang, G.; Du, S.; Duan, Q.; Su, J. A Novel Data-Driven Method for Medium-Term Power Consumption Forecasting Based on Transformer-LightGBM. Mob. Inf. Syst. 2022, 2022, 5465322. [Google Scholar] [CrossRef]
- Qi, M.L. A highly efficient gradient boosting decision tree. In Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A 2021, 379, 20200209. [Google Scholar] [CrossRef] [PubMed]
- Sai Surya Teja, T.; Venkata Hari Prasad, G.; Meghana, I.; Manikanta, T. Publishing Temperature and Humidity Sensor Data to ThingSpeak. In Embracing Machines and Humanity Through Cognitive Computing and IoT; Springer: Singapore, 2023; pp. 1–9. [Google Scholar]
- Rashid, E.; Ansari, M.D.; Gunjan, V.K.; Ahmed, M. Improvement in extended object tracking with the vision-based algorithm. In Modern Approaches in Machine Learning and Cognitive Science: A Walkthrough: Latest Trends in AI; Springer: Cham, Switzerland, 2020; pp. 237–245. [Google Scholar]
- Somu, N.; MR, G.R.; Ramamritham, K. A deep learning framework for building energy consumption forecast. Renew. Sustain. Energy Rev. 2021, 137, 110591. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. An overview of multi-task learning. Natl. Sci. Rev. 2018, 5, 30–43. [Google Scholar] [CrossRef]
- Cirstea, R.G.; Micu, D.V.; Muresan, G.M.; Guo, C.; Yang, B. Correlated time series forecasting using deep neural networks: A summary of results. arXiv 2018, arXiv:1808.09794. [Google Scholar]
- Cheng, J.; Huang, K.; Zheng, Z. Towards better forecasting by fusing near and distant future visions. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3593–3600. [Google Scholar]
- Ye, R.; Dai, Q. MultiTL-KELM: A multi-task learning algorithm for multi-step-ahead time series prediction. Appl. Soft Comput. 2019, 79, 227–253. [Google Scholar] [CrossRef]
- Crawshaw, M. Multi-task learning with deep neural networks: A survey. arXiv 2020, arXiv:2009.09796. [Google Scholar]
- Chen, L.; Ding, Y.; Lyu, D.; Liu, X.; Long, H. Deep multi-task learning based urban air quality index modelling. Proc. Acm Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–17. [Google Scholar] [CrossRef]
- Liu, C.L.; Tseng, C.J.; Huang, T.H.; Yang, J.S.; Huang, K.B. A multi-task learning model for building electrical load prediction. Energy Build. 2023, 278, 112601. [Google Scholar] [CrossRef]
- Vandenhende, S.; Georgoulis, S.; Van Gansbeke, W.; Proesmans, M.; Dai, D.; Van Gool, L. Multi-task learning for dense prediction tasks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3614–3633. [Google Scholar] [CrossRef]
- Lim, B.; Arık, S.Ö.; Loeff, N.; Pfister, T. Temporal fusion transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Wu, B.; Wang, L.; Zeng, Y.R. Interpretable wind speed prediction with multivariate time series and temporal fusion transformers. Energy 2022, 252, 123990. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Wen, R.; Torkkola, K.; Narayanaswamy, B.; Madeka, D. A multi-horizon quantile recurrent forecaster. arXiv 2017, arXiv:1711.11053. [Google Scholar]
- Challu, C.; Olivares, K.G.; Oreshkin, B.N.; Garza, F.; Mergenthaler, M.; Dubrawski, A. N-hits: Neural hierarchical interpolation for time series forecasting. arXiv 2022, arXiv:2201.12886. [Google Scholar]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Koenker, R.; Hallock, K.F. Quantile regression. J. Econ. Perspect. 2001, 15, 143–156. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Consumption (kWh) | Max_Temperature (°C) | Min_Temperature (°C) | Area |
|---|---|---|---|---|
| 5 January 2022 | 59.39 | 11 | 6 | 1 |
| 16 November 2021 | 667.93 | 19 | 10 | 2 |
| 4 May 2020 | 2366.46 | 36 | 20 | 1 |
| 15 November 2021 | 584.63 | 19 | 9 | 2 |
| 3 October 2021 | 5894.18 | 34 | 21 | 0 |
| Method | Model Type | Training % | Features Selection | Parameters |
|---|---|---|---|---|
| Baseline | - | 0 | - | Minimal |
| N-HiTS [40] | CNN | 80 | Past and Future known combined | Moderate |
| LSTM [11] | RNN | 80 | Past and Future known combined | High |
| GRU [41] | RNN | 80 | Past and Future known combined | High |
| MTLTFT | RNN, Transformer | 80 | Past and Future known seperated | High |
| Method | Baseline/% | N-HiTS/% | LSTM/% | GRU/% | MTLTFT/% | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | 2292.52 | 0% | 1777.24 | −22% | 1796.1 | −22% | 1783.8 | −22% | 1761.2 | −23% |
| MAPE | 1.84 | 0% | 1.14 | −38% | 1.46 | −21% | 1.51 | −18% | 1.18 | −36% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, W.; Cao, Z.; Li, X. Multi-Task Learning and Temporal-Fusion-Transformer-Based Forecasting of Building Power Consumption. Electronics 2023, 12, 4656. https://doi.org/10.3390/electronics12224656
Ji W, Cao Z, Li X. Multi-Task Learning and Temporal-Fusion-Transformer-Based Forecasting of Building Power Consumption. Electronics. 2023; 12(22):4656. https://doi.org/10.3390/electronics12224656
Chicago/Turabian StyleJi, Wenxian, Zeyu Cao, and Xiaorun Li. 2023. "Multi-Task Learning and Temporal-Fusion-Transformer-Based Forecasting of Building Power Consumption" Electronics 12, no. 22: 4656. https://doi.org/10.3390/electronics12224656
APA StyleJi, W., Cao, Z., & Li, X. (2023). Multi-Task Learning and Temporal-Fusion-Transformer-Based Forecasting of Building Power Consumption. Electronics, 12(22), 4656. https://doi.org/10.3390/electronics12224656